1. Introduction
The exponential distribution has been repeatedly used to represent lifetime data in life testing trials or for reliability research. The reason for this is because it possesses a constant hazard rate function that can depict the attributes of the units being tested. However, the exponential distribution may not be flexible enough in more complex situations. Ref. [
1] discussed another alternative called the inverted exponential distribution (IED) and calculated the estimates of the parameters of IED. In [
2], the Bayesian method was used for estimating the risk function and parameters of IED. As an additional technique to improve the IED, the generalized inverted exponential distribution (GIED) was suggested by [
3]. GIED has an additional shape parameter, making it more flexible and suitable for various applications.
Consider a random variable
X conforming to GIED. It is characterized by its probability density function (PDF), cumulative distribution function (CDF), survival function (SF), and hazard rate function (HRF) shown below:
where
are called the scale and shape parameter separately. It is worth noting that when
, GIED is simplified to a special case: IED.
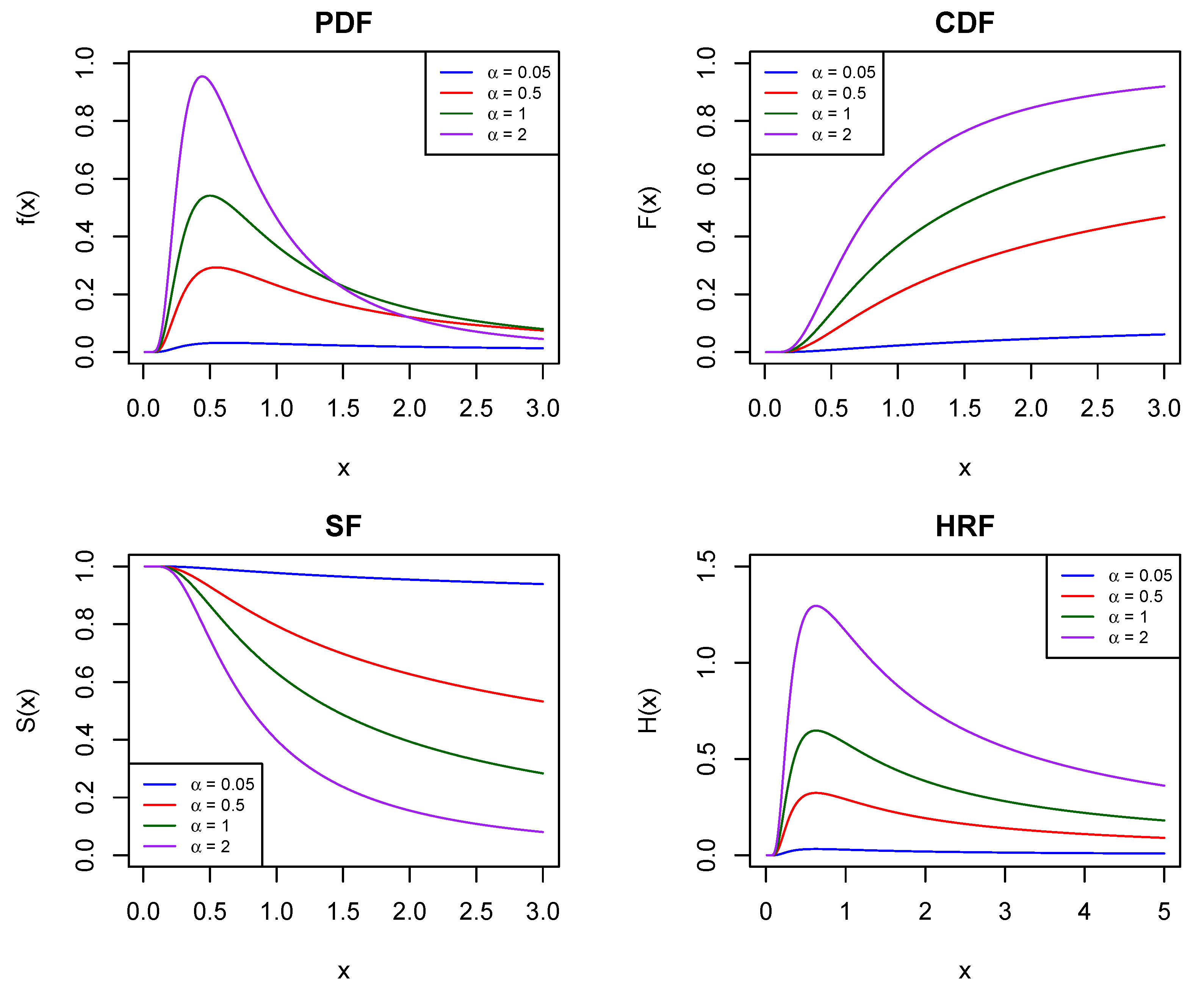
Figure 1 displays various curves illustrating PDF, CDF, SF, and HRF of GIED, featuring
(the scale parameter) across different scenarios featuring distinct values for
, namely the shape parameter. Compared with the exponential distribution with a constant hazard rate function, GIED features a versatile hazard rate function, the value of which varies according to the parameter
, see [
3]. Different works were presented on GIED, ref. [
4] considered the maximum likelihood estimation of the two parameters involved and derived reliability and failure rate functions under progressively type II censoring scheme in view of time cost. Ref. [
5] obtained estimation of the parameters of GIED from both classical and Bayesian views and discussed a method of obtaining the optimum hybrid censoring scheme. Ref. [
6] proposed a two-stage group acceptance sampling plan for generalized inverted exponential distribution under truncated life test.
As technology advances, modern products are becoming more reliable and have longer lifetimes. This makes it difficult for experimenters to conduct tests that accurately determine the actual lifetime of the products within a reasonable time frame. To solve this issue, accelerated life test (ALT) has been devised as an option. These tests subject the units to more extreme conditions than normal, such as higher pressure, temperature, voltage, etc., in order to expedite failure. There are various models under accelerated life tests (ALTs) according to different ways how the stress is exerted. In a constant stress model, all the products endure an unvarying stress level until the experiment concludes or all the units fail. This type of model has been thoroughly investigated by numerous scholars. For example, ref. [
7] developed a constant stress ALT model for data that follows the Lindley distribution, while ref. [
8] developed a constant stress model for exponential and Weibull data to predict how much time could the products remain. In contrast, with a step stress model, the stress level changes at specific times or when a designated number of units fail. As a result, the stress on all the products increases gradually according to some type of rule. Many authors have extensively researched the step stress models. For recent literature on this topic, ref. [
9] provided a procedure of determining optimal designs of simple step-stress accelerated life tests. Ref. [
10] considered a simple step-stress life test in the presence of exponentially distributed competing risks with Type-II censored data. Ref. [
11] considered a simple step-stress model based on a complete sample that follows the Weibull distribution and derived the maximum likelihood estimation and Bayesian estimation. Ref. [
12] provided a comprehensive exploration of accelerated life models and discussed the theoretical foundations of the models.
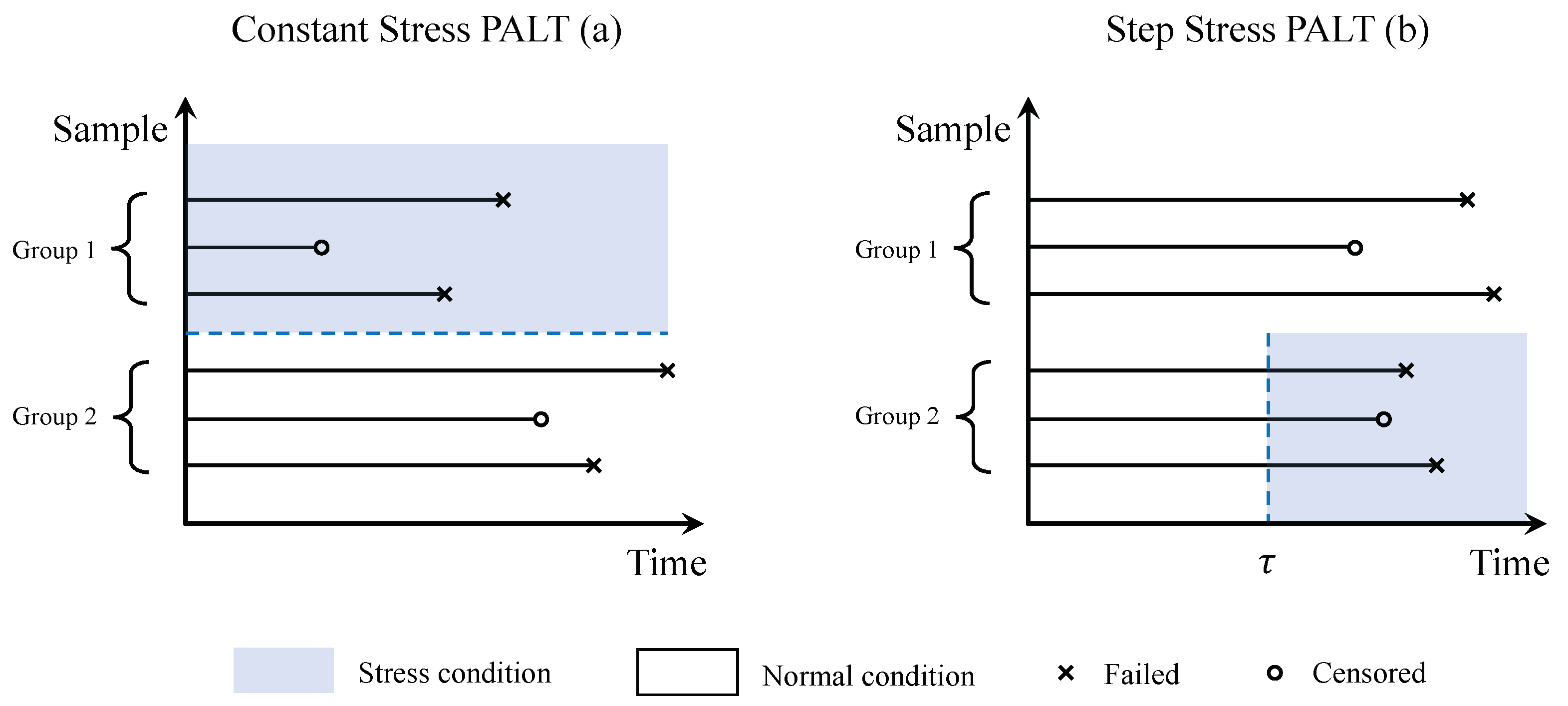
To better extrapolate the lifetime under normal use conditions, partially accelerated life test (PALT) was developed. It divides all products into groups and test each in normal and accelerated environments. Two sorts of prevalent PALTs are known as the constant stress partially accelerated life tests (CSPALTs) and the step stress partially accelerated life tests (SSPALTs). CSPALTs set different groups of units under use and stress condition respectively. By comparison, SSPALTs start with normal conditions and switch to accelerated conditions if the unit does not cease to function before a prefixed point in time
. The specific illustration of the differences between the two PALTs are displayed in
Figure 2. Many researchers have studied PALTs, ref. [
13] considered the CSPALTs with type-I censoring under Weibull distribution and minimized the asymptotic variance of the maximum likelihood estimators. Ref. [
14] developed a SSPALT under adaptive type-II progressive hybrid censoring scheme with test items following the inverted Lomax distribution and obtained the maximum likelihood estimation of the model parameters.
Censoring is another strategy of important use that can significantly reduce the test time and cost. It involves knowing only parts of all the units’ exact failure times while the other units are removed or lost from the experiment before they fail. This helps experimenters save time and reduce costs. There exist numerous censoring schemes (CSs), with the prevalent ones being Type-I and Type-II censoring. For the former, the experiment concludes after a predetermined duration, and for the latter, the test stops upon a specific number of unit failures. Moreover, a broader, more adaptable, and efficient approach known as progressive Type-II censoring was introduced into practical problems by [
15]. In this censoring scheme (CS), suppose there are
n units undergoing a lifetime test, and
represents some predetermined CS. Immediately following the initial failure, a random elimination of
units is made from the
units which are still functioning. Then
units are withdrawn from those
still working ones. This process is repeated until the
mth failure takes place, at which instant the experimenter eliminates all of the
remaining units, then this test concludes. Researchers have done a lot of work on these CSs. In [
16], CSPALTs using adaptive progressively Type I censored samples are taken into account and the estimation of model parameters are derived using maximum likelihood, maximum product and Bayesian method. Ref. [
17] considered different methodologies for estimating the parameters of the gamma distribution using progressive Type-II censored data, and further present an optimal progressive censoring plan using three optimality criteria.
As for general progressive Type-II censoring (referenced in [
15], Chapter 1.5, page 9), it is a more general and flexible form of the progressive Type-II censoring, which allows the experimenters to lose the first
r observations (which means they only know the number but without exact time of the failures) before they start to perform the progressive censoring. Consequently, the censoring scheme evolved into
, signifying that censoring initiates upon the
th failure. The entire procedure is explained in
Figure 3. Many scholars have discussed this type of CS. For example, ref. [
18] estimated the exponential parameters by utilizing classical and Bayesian perspectives. Ref. [
19] investigated a competing risks model utilizing the general censored samples, while ref. [
20] introduced a novel solution to assess if the general progressively Type-II censored samples follow the exponential distribution.
In this study, given the well flexibility and extensibility of both GIED and the general progressive Type-II censoring, and on the purpose of further reduce the cost and minimizing the time of the life tests, we consider a combination of ALT and censoring, focusing on the statistical inferences on the generalized inverted exponential distribution using general progressively censored data under a constant stress partially accelerated life test. It is worth noting that although this framework is useful and important, it has not been well studied. Ref. [
21] studied the statistical inferences of the GIED based on joint progressively type-II censoring, which did not involve the CSPALT. In the next section, we will discuss the specific model and relevant assumptions, and then we derive the point and interval estimation of the parameters of GIED as well as the acceleration factor from both classical and Bayesian view. For comparison, we conduct Monte-Carlo simulations to evaluate the performance of different methods. In the end, a real lifetime dataset is utilized to justify the applicability of the proposed model and methods.
5. Numerical Simulation
5.1. Monte-Carlo Studies
For this part, we carry out comprehensive Monte-Carlo simulations for the purpose of evaluating the various approaches for estimating the three parameters. For the point estimation, we adopt the mean squared error (MSE) and average bias (AB) since MSE is able to measure the volatility of data, and AB makes up for the disadvantage of MSE that it is sensitive to some extreme values. For the interval estimation, we select average interval length (AL) and the coverage probability (CP), as shorter ALs mean the confidence or credible intervals are more accurate under a fixed significance level, and higher CPs indicates that the confidence or credible intervals are more likely to include the true values of the parameters. The evaluating criteria for assessing the performance of the estimates outlined are shown below:
- (1)
Mean squared error (MSE) of the point estimation , which is calculated by , where represents each of the three parameters discussed in this model. The number of replications is denoted by N;
- (2)
Average bias (AB) of the point estimation , which is calculated by ;
- (3)
Average length (AL) of the confidence or credible intervals (CIs) of with a significance level ;
- (4)
Coverage probability (CP) of the CIs of , which reflects the proportion of instances where the actual parameter values lie in the calculated intervals.
To be concise, we take , and , running simulations under both normal and accelerated conditions with the following CSs:
- CS [1]:
, , , , ;
- CS [2]:
, , , , ;
- CS [3]:
, , , , ;
- CS [4]:
, , , , ;
- CS [5]:
, , , , ;
- CS [6]:
, , , , ;
- CS [7]:
, , , , ;
- CS [8]:
, , , , ;
- CS [9]:
, , , , .
Based on the above evaluating criteria and the censoring schemes, two sets of parameter values are taken into consideration for our Monte-Carlo studies, which are
and
, respectively. In terms of the Bayesian estimate, the corresponding hyper-parameters are chosen as
and
, which indicate the expectations of the three Gamma distributions as the prior, respectively. It makes sense that when choosing the more accurate priors, we may obtain better estimates. It is to be noted that the hyper-parameters should not be too large, since it may mask the effects of the three newly-constructed Gamma distributions, which led us to setting the hyper-parameters as above. The method in [
15] is performed regarding the production of the general progressively censored sample under the pre-determined CS
, and the specific algorithms are shown below:
Since this sort of censored sample can be obtained based on Algorithm 1, it is possible to generate sample under general progressive censoring by Algorithm 2.
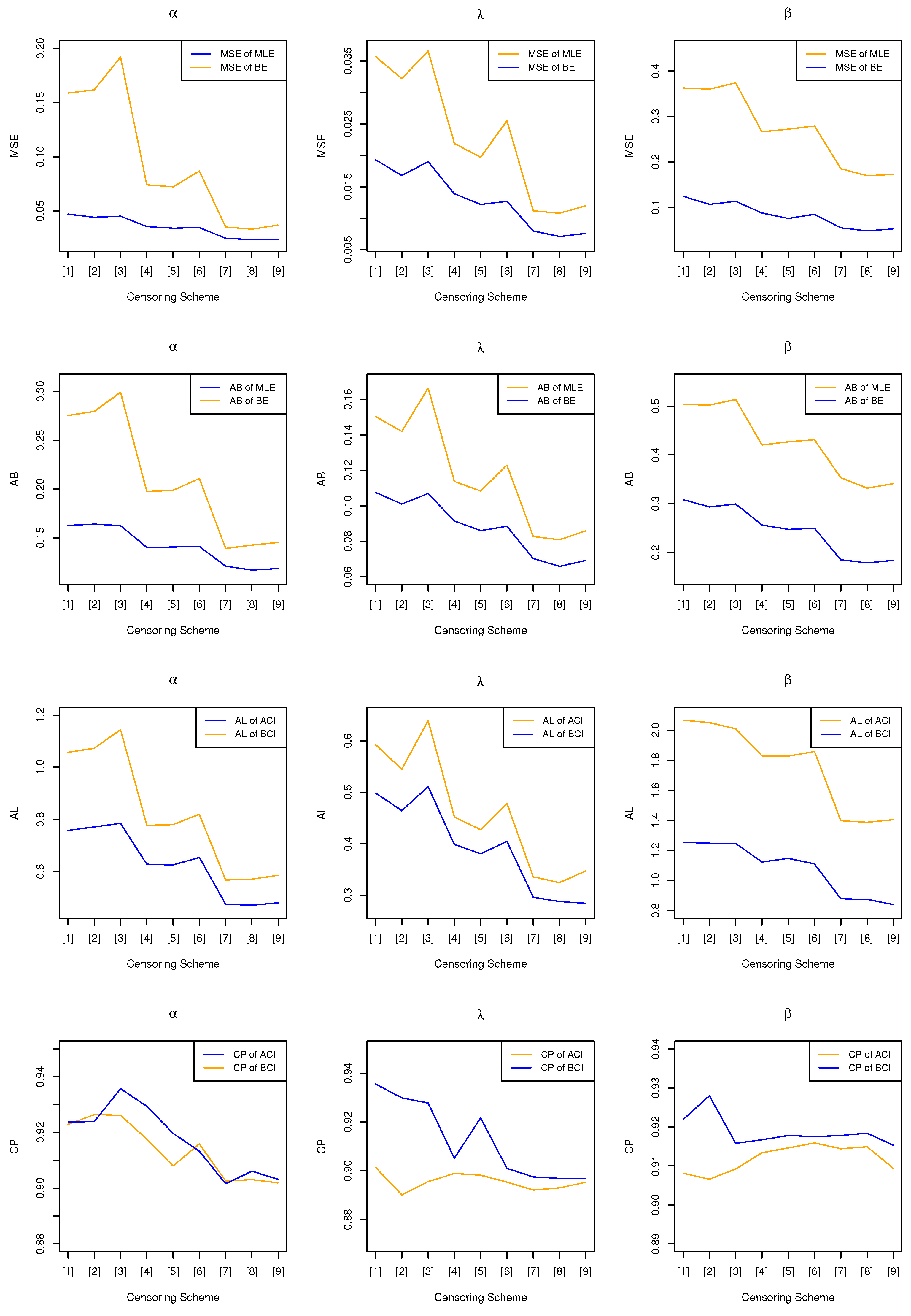
Different estimates adopting both classical and Bayesian viewpoint for the three parameters and the corresponding evaluating criteria (EC) are calculated with sample generated from both normal and accelerated conditions utilizing general progressively Type-II censoring under multiple CSs. Specifically, the MSEs and ABs of the point estimation are shown in
Table 1, and the ALs and CPs of the interval estimation are given in
Table 2. In addition, the related plots of the criteria for different parameters are presented in
Figure 4 and
Figure 5 as well.
| Algorithm 1: Generating Progressively Type-II Censored Samples |
- Step 1:
Generate m random variables as observations; - Step 2:
Let , . - Step 3:
Let , . Consequently, ’s form the progressively Type-II right censored sample of . - Step 4:
Let for each i. denotes the inverse CDF corresponding to the lifetime distribution being studied. Consequently, constitute the necessary progressively Type-II censored sample of .
|
| Algorithm 2: Generating General Progressively Type-II Censored Samples |
- Step 1:
Generate from ; - Step 2:
By adopting Algorithm 1, generate progressively Type-II censored samples using CS , and they are denoted by ; - Step 3:
Let , , in which is as derived according to Step 2; - Step 4:
Let , for each i. Consequently, constitute a general progressively Type-II censored sample of .
|
The findings of the simulation, which are shown in the tables and figures, allow for the formation of several different conclusions:
- (1)
In most of the cases, for point estimation and interval estimation, Bayesian method performs better than the classical estimation, with smaller MSEs and ABs, shorter ALs and higher CPs. For example, in terms of the parameter
of
under CS 7-9, one can find from
Table 1 that the MSEs for MLE lie around 0.0210 whereas for BE is around 0.0160, with the ALs being about 0.4480 and 0.3739 respectively, which can be seen as a significant advantage of Bayesian method.
- (2)
For fixed CSs, both point and interval estimation see a considerable progress when the number of valid samples accumulates. One can see from the two tables that when 10 samples are censored, CS 8 providing valid failure times has much smaller MSEs (0.0210, 0.0160) and ALs (0.4485, 0.3728) than CS 5 and CS 2 (considering in , for other parameters we can also obtain similar findings), which indicates the consistency of the corresponding estimation.
- (3)
However, the performances of both classical and Bayesian method are not satisfying with small samples, providing relatively large MSEs (for instance, around 0.25 for MLE of in ) and long intervals (over 1.6 for ACI of in ). BEs and BCIs using small samples are slightly better.
It is to be noted that Bayesian method has a distinct advantage over the classical method in the small sample cases, where BEs have much smaller MSEs and ABs and BCIs give much shorter intervals together with relatively higher CPs. In several cases, the CPs can be a bit higher since the CIs are bad with long interval lengths, but with the increasing number of the valid sample, most of the coverage probabilities (CPs) for different CIs are getting closer to the nominal confidence level. For example, the CP of BCI for in was higher than 90% under CS 1, but gets closer to 90% (0.8975) due to more valid data under CS 7, with a shorter AL (from 0.4984 to 0.2961). In several situations where the quantity of the units is relatively large, it can be better to have more samples censored at the same time, compared with CSs with less censored samples. In terms of point estimation, for pre-specified valid sample size, the MSEs and ABs of censoring samples at the last five failures are slightly less than those of censoring at the first five failures. In general, both point and interval estimates for parameter performed the best, featuring considerably small MSEs and ABs, whereas the two estimates of parameter performed the worst, with relatively larger MSEs and longer interval lengths. To be specific, considering the figure of BE for , one can find that the MSE and AB for under CS 9 are 0.0063 and 0.0661, while for are 0.0427 and 0.1576, which means more deviation on than .
5.2. Real Data Examples
For this part, we examine a real lifetime dataset that records a series of oil breakdown times of a kind of insulating fluid under different stress levels (voltages, KV) as documented by [
23], Chapter 3, Table 3.1, to validate the previously proposed methods. To determine whether the GIED could be an appropriate lifetime distribution in terms of this real dataset, we first derive the AIC (Akaike information criterion) of several commonly utilized lifetime distributions. The results for AICs are presented in
Table 3.
From the table results, we can conclude that GIED provides a better goodness of fit over the other frequently used models since it has the smallest AIC.
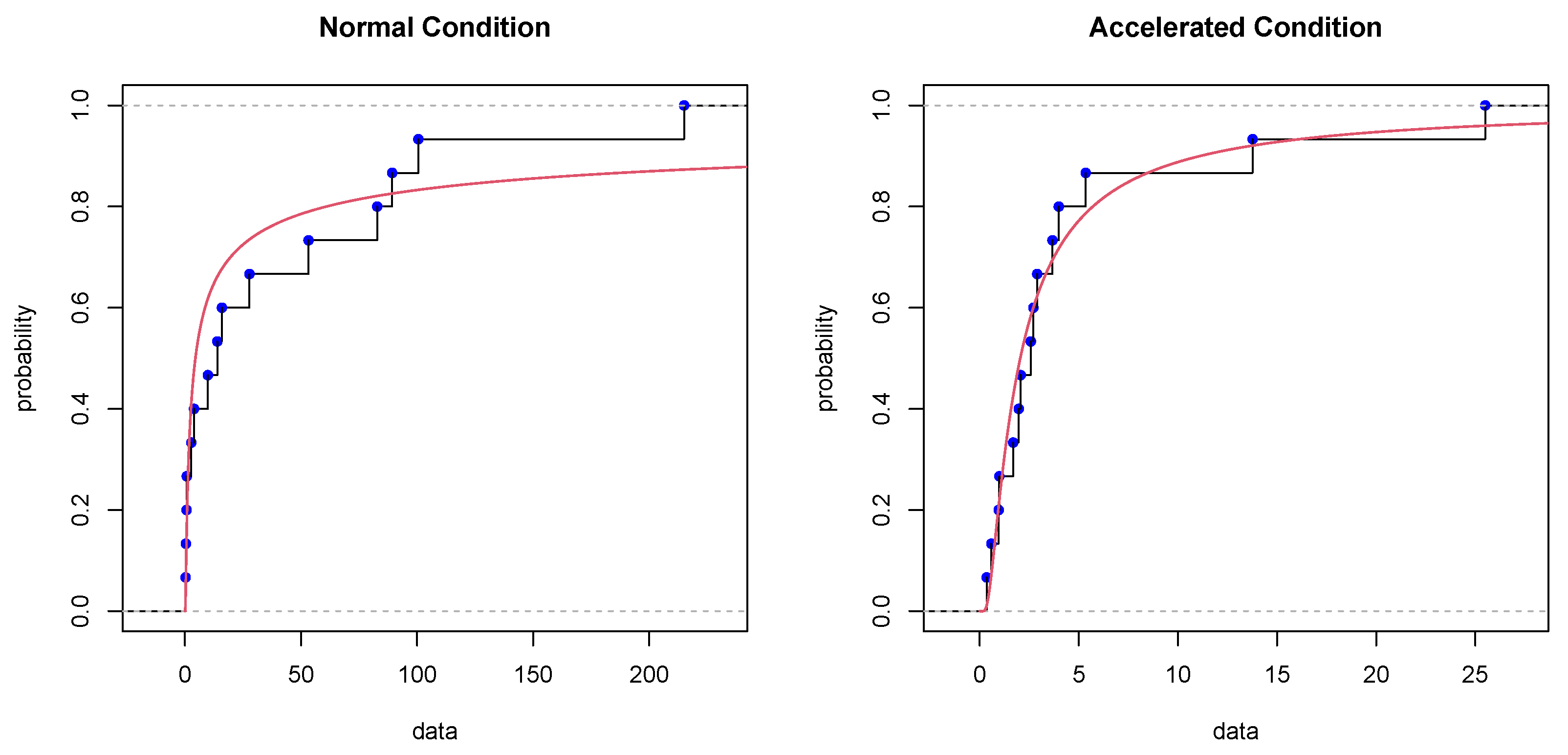
To further demonstrate the appropriateness of the GIED, the Kolmogorov-Smirnov (K-S) test is utilized. The specific samples under two levels of stress (32 KV as normal condition and 36 KV as accelerated condition) is offered in
Table 4. According to the results in
Table 3, the data are assumed to follow GIED, thus one can further conduct the K-S test:
then the corresponding K-S distances as well as
p-values are calculated and shown in
Table 4 as well. When the
p-values are larger than the significance level, one have good reason to accept the null hypothesis, which means determining the samples are from a GIED. Under normal and the accelerated condition, the calculated
p-values are
and
respectively, which means that one should accept the null hypothesis
, leading to a fundamental conclusion that GIED is well-fitting to this dataset. In addition, the empirical cumulative distribution plots of both normal (32 KV) and accelerated (36 KV) condition with the fitted CDF curves where the unknown parameters are given by MLEs are shown in
Figure 6, which can be a further illustration of the validity of using GIED model.
Based on
Table 4, we generate two new sets of general progressively Type-II censored samples using a specified CS where
and
. The new data sets are shown in
Table 5. Hence, one can conduct the classical and Bayesian methods mentioned above on the new data set to derive point and interval estimation of
,
as well as
. For Bayesian methods, because there is no available extra informative knowledge about the three parameters, we set all the hyper-parameters as
, which indicates that the pre-determined priors are nearly non-informative.
Table 6 and
Table 7 display the outcomes of different methods, which clearly demonstrate that the effectiveness of MLEs and BEs is highly comparable since they have produced similar estimates of the parameters, whereas for the interval estimation, BCIs works better than ACIs featuring much shorter interval lengths.
Through an analysis of the practical oil breakdown times data set, one can conclude that both classical and Bayesian method are helpful for estimating the parameters of GIED by utilizing general progressively censored samples in a CSPALT, and additionally, Bayesian estimates performed better in terms of the interval lengths.
6. Conclusions
With the modern products becoming more and more durable, researchers have proposed different methods to cut the experimental time and cost, including the accelerated life tests and censoring. This study focuses on combining the CSPLAT and general progressive Type-II censoring to further reduce the time and money cost. Additionally, by adopting GIED (which has a versatile HRF) as the lifetime distribution and utilizing the general censoring methodology, we manage to provide extra flexibility in more complicated situations for the experimenters.
We explore diverse approaches for estimating the parameters of GIED within the framework of a CSPALT based on general progressively censored samples. We delve into both classical and Bayesian perspectives for estimating and , representing the scale and shape parameter of GIED, as well as the acceleration factor . We devise maximum likelihood estimates and provide correlated ACIs by using the Fisher information matrix. Additionally, we derive point and interval estimates through Bayesian methods, leveraging importance sampling for point estimation and establishing Bayesian credible intervals. Monte-Carlo simulations are conducted under multiple censoring schemes to assess the validity and performance of the different methodologies. The results underscore the effectiveness of the mentioned approaches, with Bayesian point and interval estimates demonstrating better performance across most scenarios. The results also reveal the fact that both classical and Bayesian methods are not satisfying enough with small samples, but BEs and BCIs are slightly more effective since they have used the prior information. Finally, the proposed methods are applied on a real lifetime dataset, BCIs outperform the ACIs with shorter interval lengths, justifying that the Bayesian view is more suitable for this dataset, which is consistent with the previous results of the simulation and supports the suitability and applicability of our model.
Moving forward, we aim to extend our investigation to encompass more intricate scenarios, such as step-stress partially accelerated life tests with general progressive Type-II censoring. We remain committed to exploring and developing more effective methods for estimating unknown parameters under diverse scenarios.




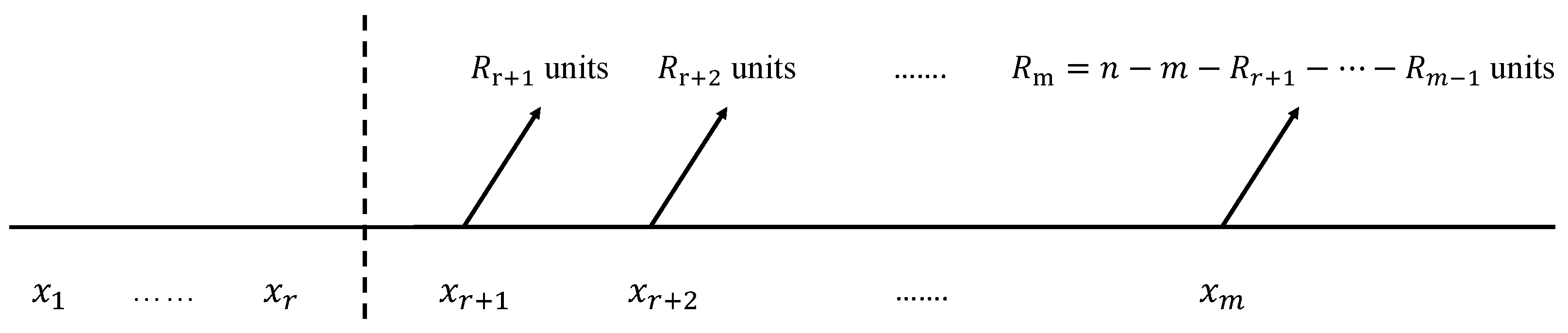


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}