
A Novel Method for Wheat Spike Phenotyping Based on Instance Segmentation and Classification

 ,
, 

Abstract
1. Introduction
2. Materials and Methods
2.1. Wheat Sample
2.2. Spikelet Instance Segmentation Method
2.2.1. Image Perspective Transformation
2.2.2. Image Augmentation
- Scaling: Randomly scaling the image within a range of 0.8 to 1.2 times its original size;
- Translation: Randomly translating the image horizontally and vertically up to 20% of pixels;
- Rotation: Randomly rotating the image within a range of −15 to +15 degrees;
- Shear: Randomly applying shear transformations up to 10 degrees;
- Horizontal Flip: Each image had a 50% chance of being flipped horizontally;
- Brightness: Randomly adjusting the brightness by a factor ranging from 0.8 to 1.2;
- Contrast: Randomly adjusting the contrast by a factor ranging from 0.8 to 1.2;
- Gaussian Blur: Applying Gaussian blur with a kernel size of 5 × 5 with a probability of 30%;
- Gaussian Noise: Adding Gaussian noise with a variance of 0.01 with a probability of 30%.
2.2.3. Image Optimization
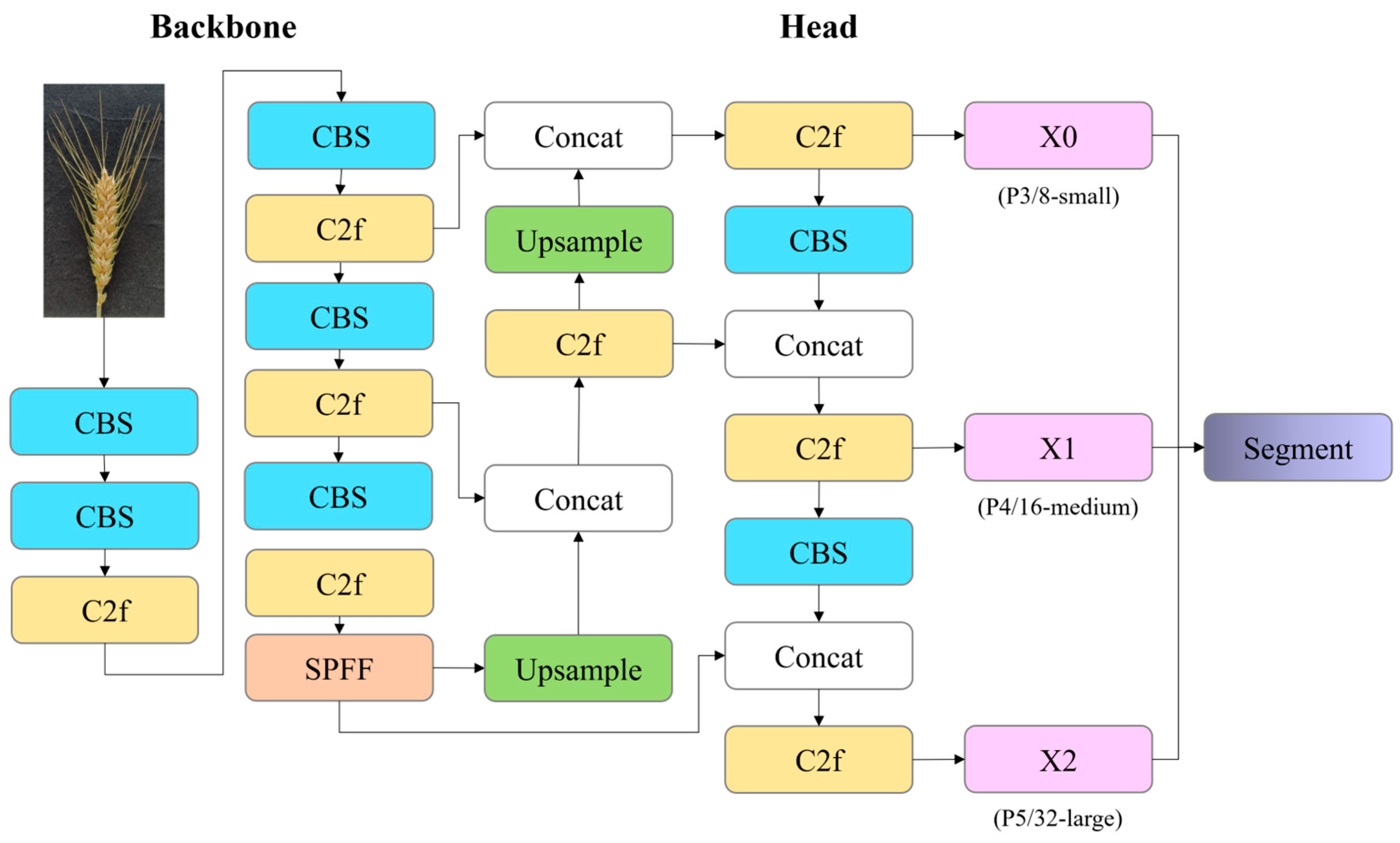
2.2.4. Instance Segmentation Model
2.3. Wheat Grain Counting Method
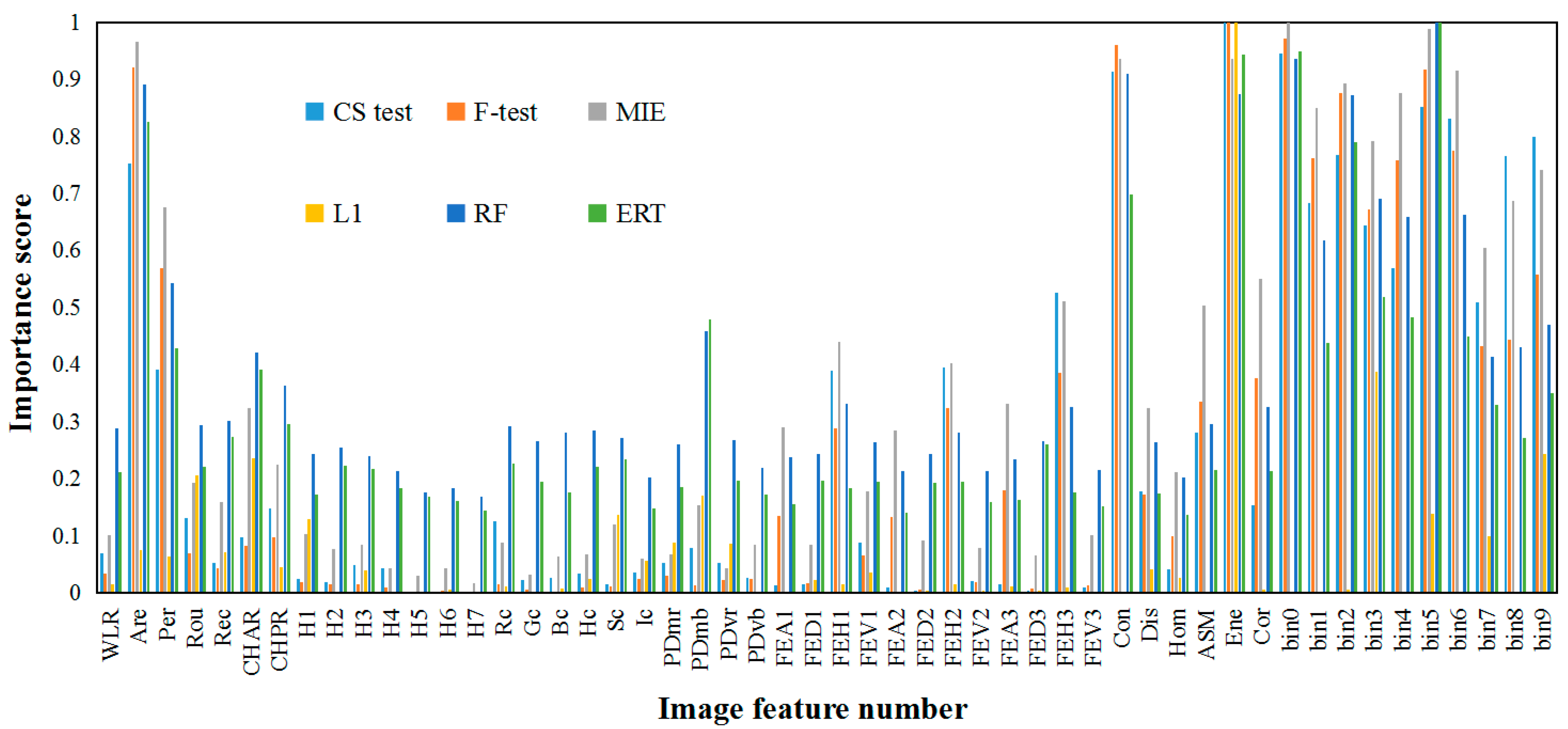
2.3.1. Image Feature Extraction and Selection
2.3.2. Grain Counting Model
2.4. Model Evaluation
2.4.1. Evaluation of Instance Segmentation Model
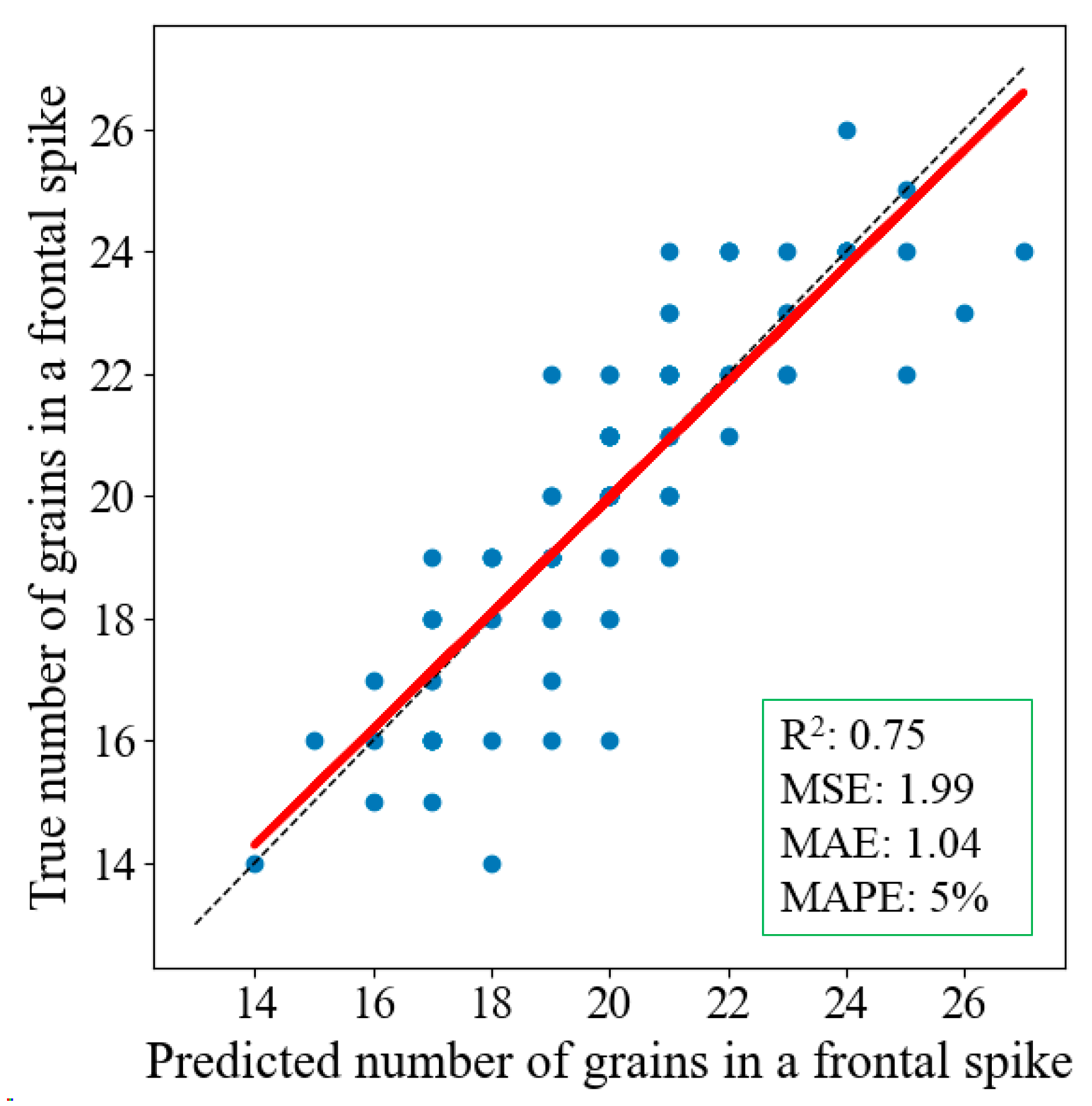
2.4.2. Evaluation of Grain Counting Model
3. Results and Discussion
3.1. Segmentation Results of Wheat Spike
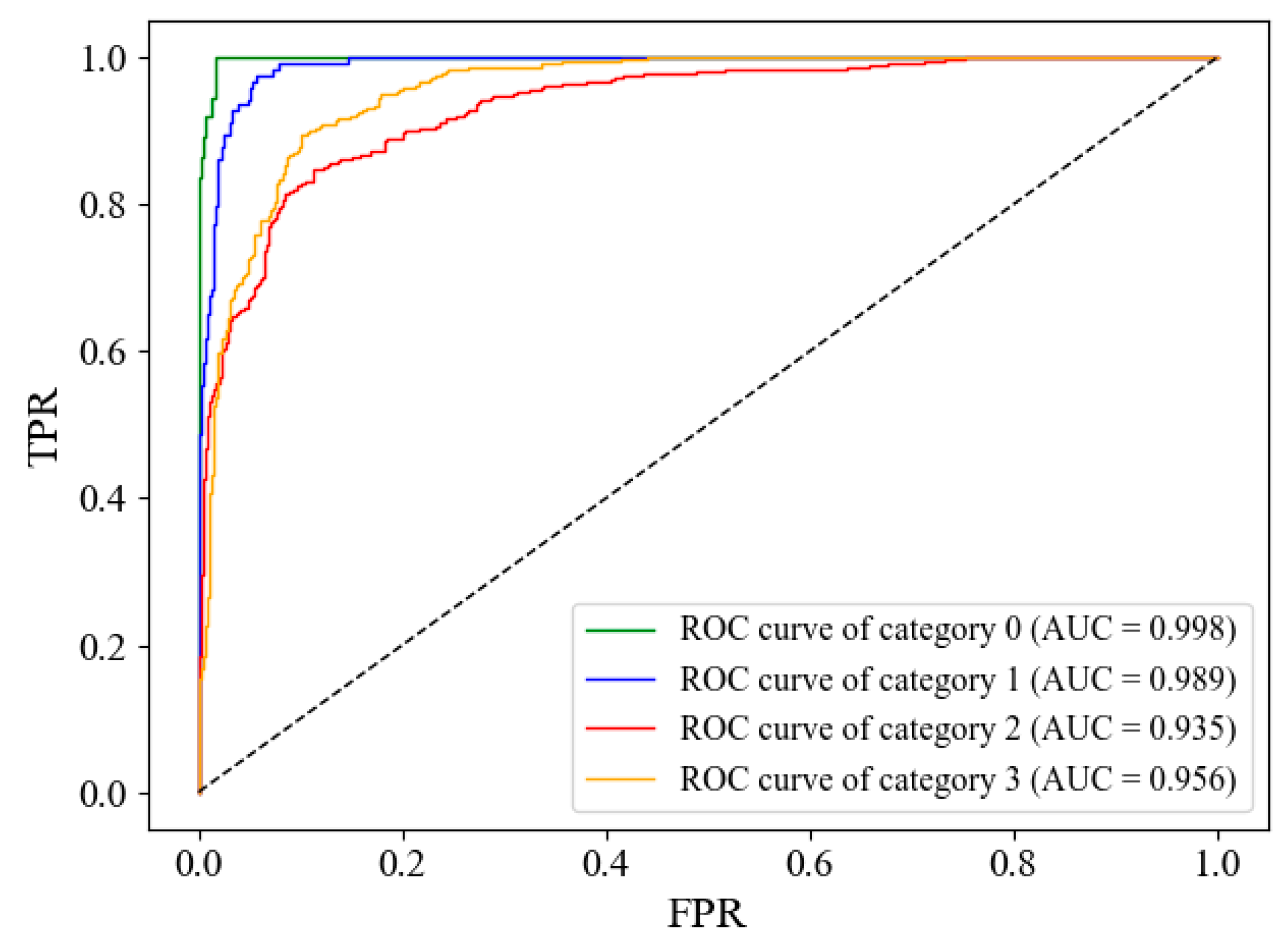
3.2. Classification Results of Spikelets
3.3. Counting Results of Wheat Grains
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, B.; Jiao, Y. Grain size control in wheat: Toward a molecular understanding. Seed Biol. 2024, 3, e007. [Google Scholar] [CrossRef]
- Yang, G.; Li, X.; Liu, P.; Yao, X.; Zhu, Y.; Cao, W.; Cheng, T. Automated in-season mapping of winter wheat in China with training data generation and model transfer. ISPRS J. Photogramm. Remote Sens. 2023, 202, 422–438. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, Y.; Ni, P.; Ni, Z.; Sun, Q.; Zong, Y. CRISPR-mediated acceleration of wheat improvement: Advances and perspectives. J. Genet. Genom. 2023, 50, 815–834. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, A.K.; Safaei, N.; Khaki, S.; Lopez, G.; Zeng, W.; Ewert, F.; Gaiser, T.; Rahimi, J. Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 2022, 12, 3215. [Google Scholar] [CrossRef] [PubMed]
- Genaev, M.A.; Komyshev, E.G.; Smirnov, N.V.; Kruchinina, Y.V.; Goncharov, N.P.; Afonnikov, D.A. Morphometry of the Wheat Spike by Analyzing 2D Images. Agronomy 2019, 9, 390. [Google Scholar] [CrossRef]
- Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution RGB imagery using deep learning technique. Agric. For. Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
- Xiong, B.; Wang, B.; Xiong, S.; Lin, C.; Yuan, X. 3D Morphological Processing for Wheat Spike Phenotypes Using Computed Tomography Images. Remote Sens. 2019, 11, 1110. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, F.; Li, K.; Feng, X.; Hou, W.; Liu, L.; Chen, L.; He, Y.; Wang, Y. Low-light wheat image enhancement using an explicit inter-channel sparse transformer. Comput. Electron. Agric. 2024, 224, 109169. [Google Scholar] [CrossRef]
- Zhang, K.; Yan, F.; Liu, P. The application of hyperspectral imaging for wheat biotic and abiotic stress analysis: A review. Comput. Electron. Agric. 2024, 221, 109008. [Google Scholar] [CrossRef]
- Liu, T.; Wu, F.; Mou, N.; Zhu, S.; Yang, T.; Zhang, W.; Wang, H.; Wu, W.; Zhao, Y.; Sun, C.; et al. The estimation of wheat yield combined with UAV canopy spectral and volumetric data. Food Energy Secur. 2024, 13, e527. [Google Scholar] [CrossRef]
- Ning, L.; Sun, S.; Zhou, L.; Zhao, N.; Taha, M.; He, Y.; Qiu, Z. High-throughput instance segmentation and shape restoration of overlapping vegetable seeds based on sim2real method. Measurement 2022, 207, 112414. [Google Scholar] [CrossRef]
- Fernandez-Gallego, J.A.; Lootens, P.; Borra-Serrano, I.; Derycke, V.; Haesaert, G.; Roldán-Ruiz, I.; Araus, J.L.; Kefauver, S.C. Automatic wheat ear counting using machine learning based on RGB UAV imagery. Plant J. 2020, 103, 1603–1613. [Google Scholar] [CrossRef] [PubMed]
- Carlier, A.; Dandrifosse, S.; Dumont, B.; Mercatoris, B. Wheat Ear Segmentation Based on a Multisensor System and Superpixel Classification. Plant Phenomics 2022, 2022, 9841985. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Luo, H.; Wang, D.; Zhou, X.; Li, W.; Gu, C.; Zhang, G.; He, F. Assessment of the levels of damage caused by Fusarium head blight in wheat using an improved YoloV5 method. Comput. Electron. Agric. 2022, 198, 107086. [Google Scholar] [CrossRef]
- Zang, H.; Wang, Y.; Ru, L.; Zhou, M.; Chen, D.; Zhao, Q.; Zhang, J.; Li, G.; Zheng, G. Detection method of wheat spike improved YOLOv5s based on the attention mechanism. Front. Plant Sci. 2022, 13, 993244. [Google Scholar] [CrossRef] [PubMed]
- Batin, M.A.; Islam, M.; Hasan, M.M.; Azad, A.; Alyami, S.A.; Hossain, M.A.; Miklavcic, S.J. WheatSpikeNet: An improved wheat spike segmentation model for accurate estimation from field imaging. Front. Plant Sci. 2023, 14, 1226190. [Google Scholar] [CrossRef] [PubMed]
- Qiu, R.; He, Y.; Zhang, M. Automatic Detection and Counting of Wheat Spikelet Using Semi-Automatic Labeling and Deep Learning. Front. Plant Sci. 2022, 13, 872555. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Jia, Z.; Wang, R.; Yao, S.; Zhang, J. Phenotypic Parameter Extraction for Wheat Ears Based on an Improved Mask-rcnn Algorithm. Inmateh-Agric. Eng. 2022, 66, 267–278. [Google Scholar] [CrossRef]
- Xu, X.; Geng, Q.; Gao, F.; Xiong, D.; Qiao, H.; Ma, X. Segmentation and counting of wheat spike grains based on deep learning and textural feature. Plant Methods 2023, 19, 77. [Google Scholar] [CrossRef]
- Geng, Q.; Zhang, H.; Gao, M.; Qiao, H.; Xu, X.; Ma, X. A rapid, low-cost wheat spike grain segmentation and counting system based on deep learning and image processing. Eur. J. Agron. 2024, 156, 127158. [Google Scholar] [CrossRef]
- Liu, Y.; Noguchi, N.; Liang, L. Development of a positioning system using UAV-based computer vision for an airboat navigation in paddy field. Comput. Electron. Agric. 2019, 162, 126–133. [Google Scholar] [CrossRef]
- Alkhudaydi, T.; Reynolds, D.; Griffiths, S.; Zhou, J.; de la Iglesia, B. An Exploration of Deep-Learning Based Phenotypic Analysis to Detect Spike Regions in Field Conditions for UK Bread Wheat. Plant Phenomics 2019, 2019, 7368761. [Google Scholar] [CrossRef] [PubMed]
- Syed, S.H.; Muralidharan, V. Feature extraction using Discrete Wavelet Transform for fault classification of planetary gearbox—A comparative study. Appl. Acoust. 2022, 188, 108572. [Google Scholar] [CrossRef]
- Elsherbiny, O.; Zhou, L.; Feng, L.; Qiu, Z. Integration of Visible and Thermal Imagery with an Artificial Neural Network Approach for Robust Forecasting of Canopy Water Content in Rice. Remote Sens. 2021, 13, 1785. [Google Scholar] [CrossRef]
- Xia, M.; Li, S.; Chen, W.; Yang, G. Perceptual image hashing using rotation invariant uniform local binary patterns and color feature. Adv. Comput. 2023, 130, 163–205. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mask Image | Category | |||
|---|---|---|---|---|---|
| Precision | Recall | AP@[0.50] | AP@[0.50:0.95] | A | |
| Z618 | 0.994 | 0.989 | 0.995 | 0.850 | 100% |
| Y19 | 0.998 | 0.988 | 0.993 | 0.855 | 100% |
| S8 | 0.995 | 0.973 | 0.987 | 0.857 | 100% |
| TV | 0.994 | 0.979 | 0.993 | 0.858 | 100% |
| Model | A of Training Dataset | A of Test Dataset | P of Test Dataset | R of Test Dataset | F1 Score of Test Dataset |
|---|---|---|---|---|---|
| NB | 0.734 | 0.713 | 0.710 | 0.761 | 0.724 |
| LDA | 0.805 | 0.797 | 0.786 | 0.823 | 0.801 |
| DT | 0.818 | 0.801 | 0.793 | 0.778 | 0.780 |
| KNN | 0.841 | 0.823 | 0.839 | 0.828 | 0.832 |
| GBDT | 0.861 | 0.835 | 0.827 | 0.826 | 0.827 |
| RF | 0.863 | 0.833 | 0.845 | 0.841 | 0.843 |
| SVM | 0.870 | 0.855 | 0.860 | 0.865 | 0.863 |
| Feature Selection Methods | A of Training Dataset | A of Test Dataset | P of Test Dataset | R of Test Dataset | F1 Score of Test Dataset |
|---|---|---|---|---|---|
| CS test | 0.742 | 0.760 | 0.785 | 0.738 | 0.756 |
| F-test | 0.742 | 0.758 | 0.784 | 0.737 | 0.755 |
| MIE | 0.798 | 0.819 | 0.827 | 0.833 | 0.830 |
| L1 | 0.791 | 0.805 | 0.807 | 0.811 | 0.809 |
| RF | 0.838 | 0.840 | 0.843 | 0.845 | 0.844 |
| ERT | 0.801 | 0.812 | 0.812 | 0.821 | 0.815 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Z.; Liang, N.; He, Y.; Xu, C.; Sun, S.; Zhou, Z.; Qiu, Z. A Novel Method for Wheat Spike Phenotyping Based on Instance Segmentation and Classification. Appl. Sci. 2024, 14, 6031. https://doi.org/10.3390/app14146031
Niu Z, Liang N, He Y, Xu C, Sun S, Zhou Z, Qiu Z. A Novel Method for Wheat Spike Phenotyping Based on Instance Segmentation and Classification. Applied Sciences. 2024; 14(14):6031. https://doi.org/10.3390/app14146031
Chicago/Turabian StyleNiu, Ziang, Ning Liang, Yiyin He, Chengjia Xu, Sashuang Sun, Zhenjiang Zhou, and Zhengjun Qiu. 2024. "A Novel Method for Wheat Spike Phenotyping Based on Instance Segmentation and Classification" Applied Sciences 14, no. 14: 6031. https://doi.org/10.3390/app14146031
APA StyleNiu, Z., Liang, N., He, Y., Xu, C., Sun, S., Zhou, Z., & Qiu, Z. (2024). A Novel Method for Wheat Spike Phenotyping Based on Instance Segmentation and Classification. Applied Sciences, 14(14), 6031. https://doi.org/10.3390/app14146031