



Audio Steganalysis Estimation with the Goertzel Algorithm

 , , ,
, , ,  and
and
Abstract
:1. Introduction
- By detecting the differences in frequency of the audio signals, the fingerprints of the files are located to compare the audio files.
- The method proposed here can detect files of the same type as well as text or image files.
- Minimum implementation complexity, unlike methods based on neural networks. The potential frequency range of the alteration of the original audio is identified.
2. Materials and Methods
2.1. Stegoanalyzer Process
Proposed Stegoanalyzer
- Step 1. Goertzel algorithm
- Linear Prediction
- Pseudocode
- Separation of audio vectors into their respective left and right channels.
- The audio vectors and are entered according to the Goertzel algorithm. The length of each vector is in accordance with the sampling frequency of 44,100 samples per second, which is the standard for audio files with the *.wav extension.
- From step 1, the audio vector and samples are subdivided into sets with length N = 100. Corresponding to the sliding window of the Goertzel algorithm:
- The vectors obtained from points 1 and 2 are subtracted to obtain the vector resulting from its frequency spectrum.
- In Step 3, the statistical parameters are applied as the mean, variance, covariance, skewness, kurtosis, energy, and AQM of the signals are calculated to evaluate the performance of the proposed stegoanalyzer.
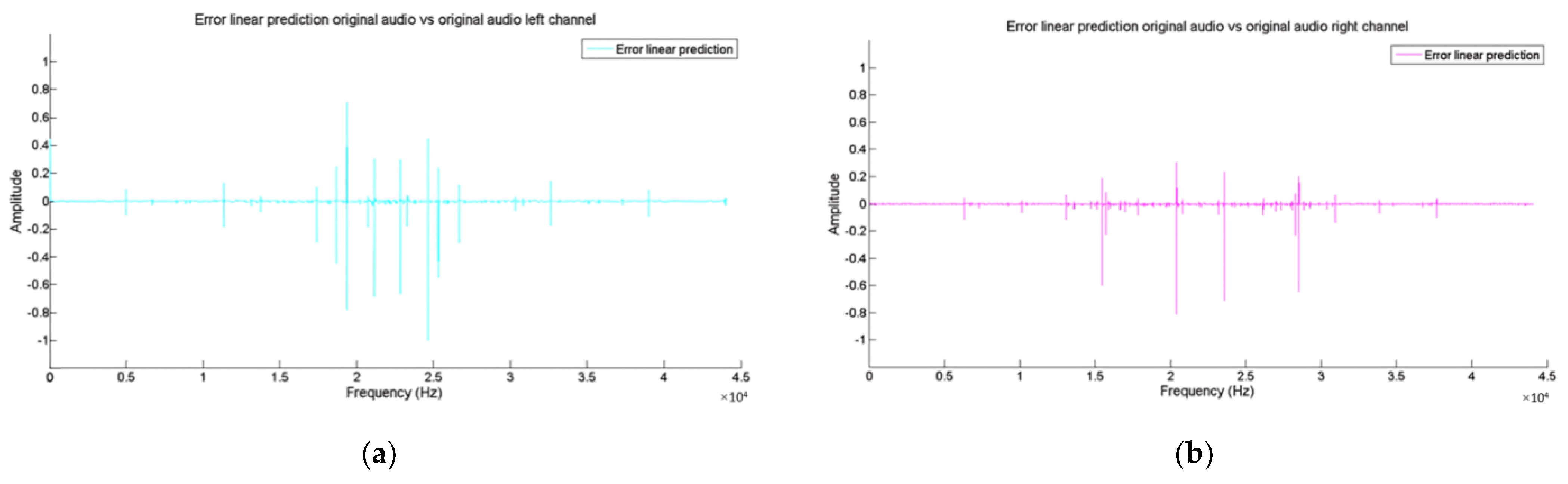
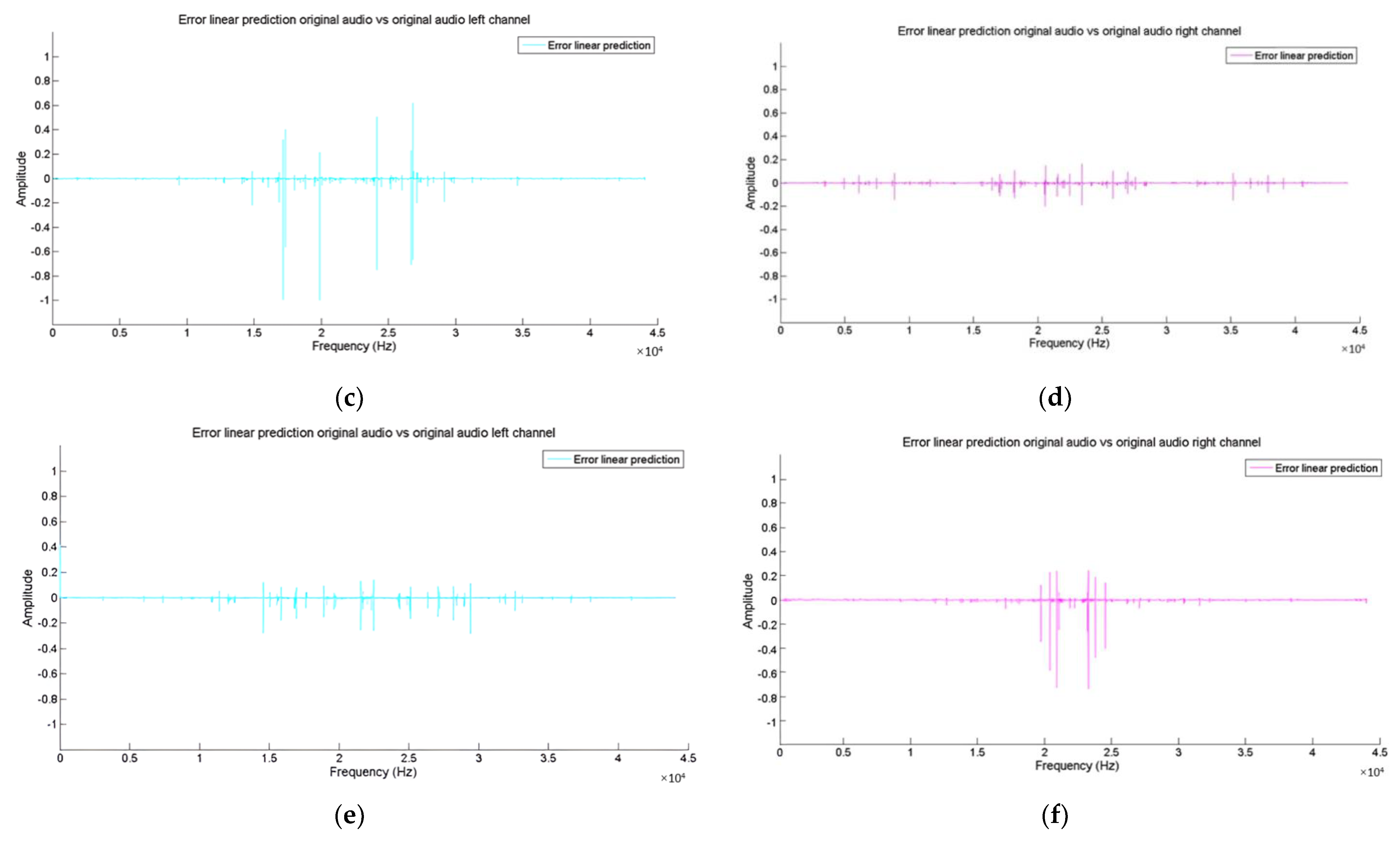
- Finally, as a final step, the error values obtained from step 4 are compared to perform the linear prediction for the vectors and .
3. Performance Evaluation
3.1. Vector Audio Decomposition
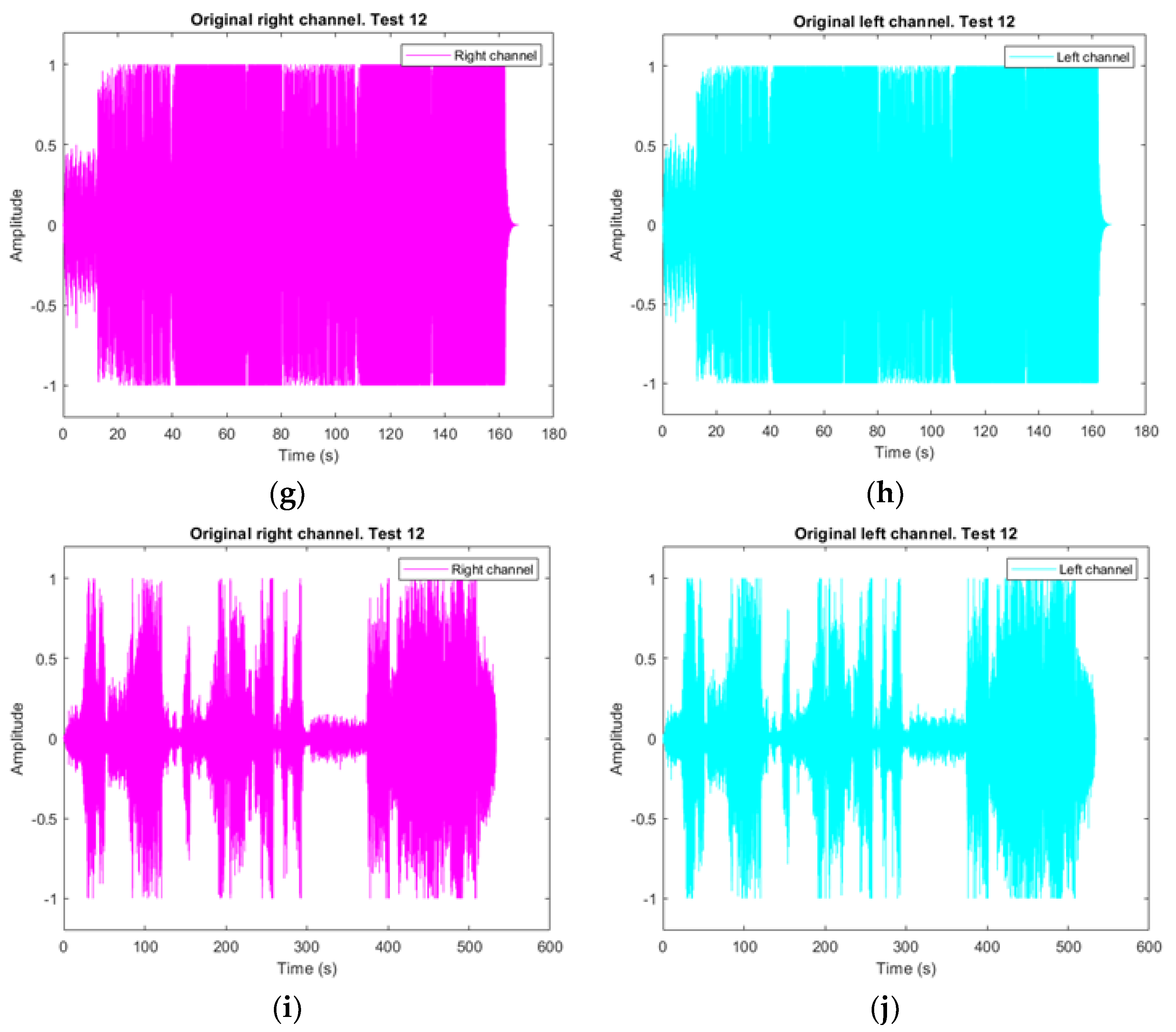
3.1.1. Original Audio Vector Decomposition
3.1.2. First Test. Audio Files with Audio File Attacks
3.1.3. Test 2. Audio Files with Text and Image File Attacks
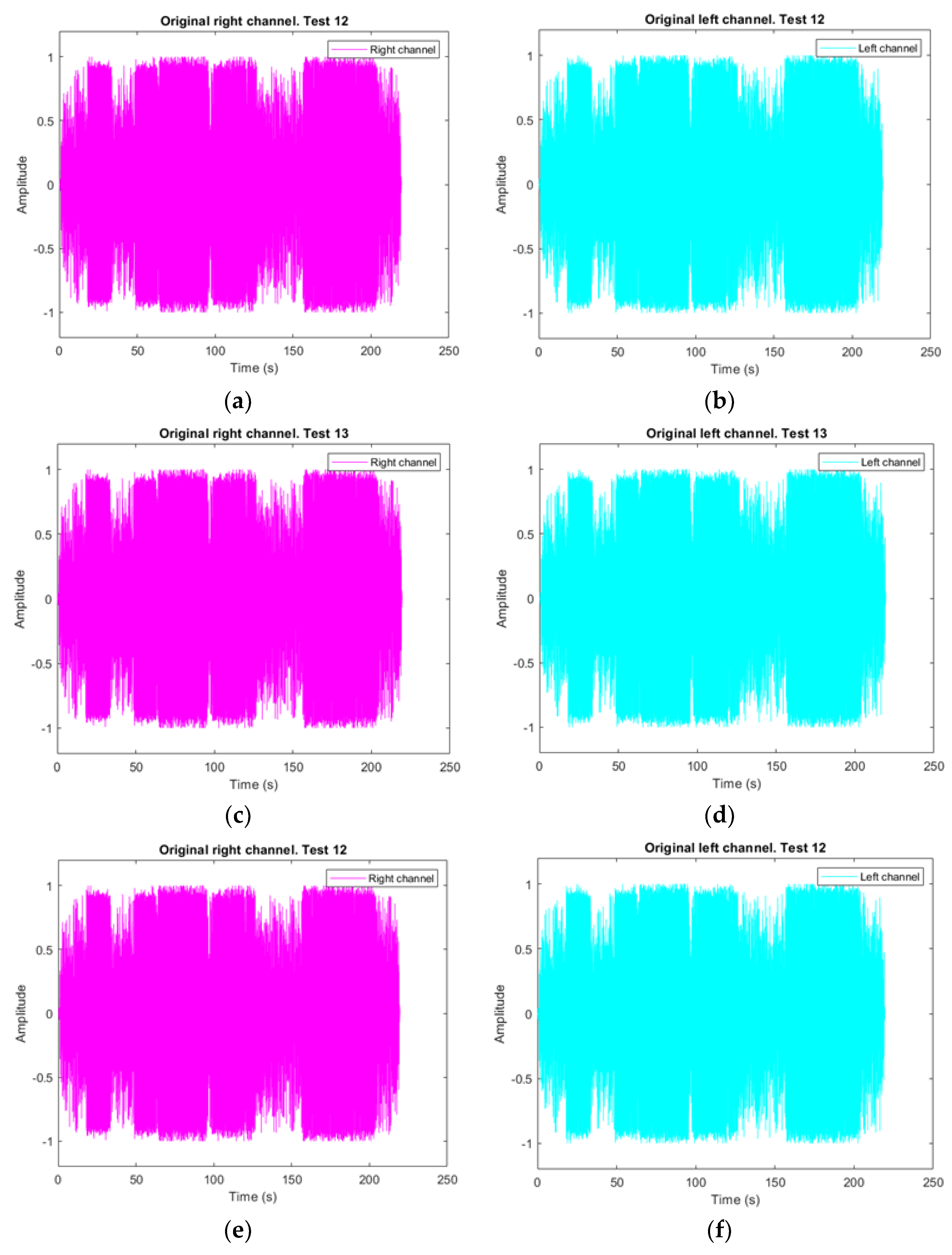
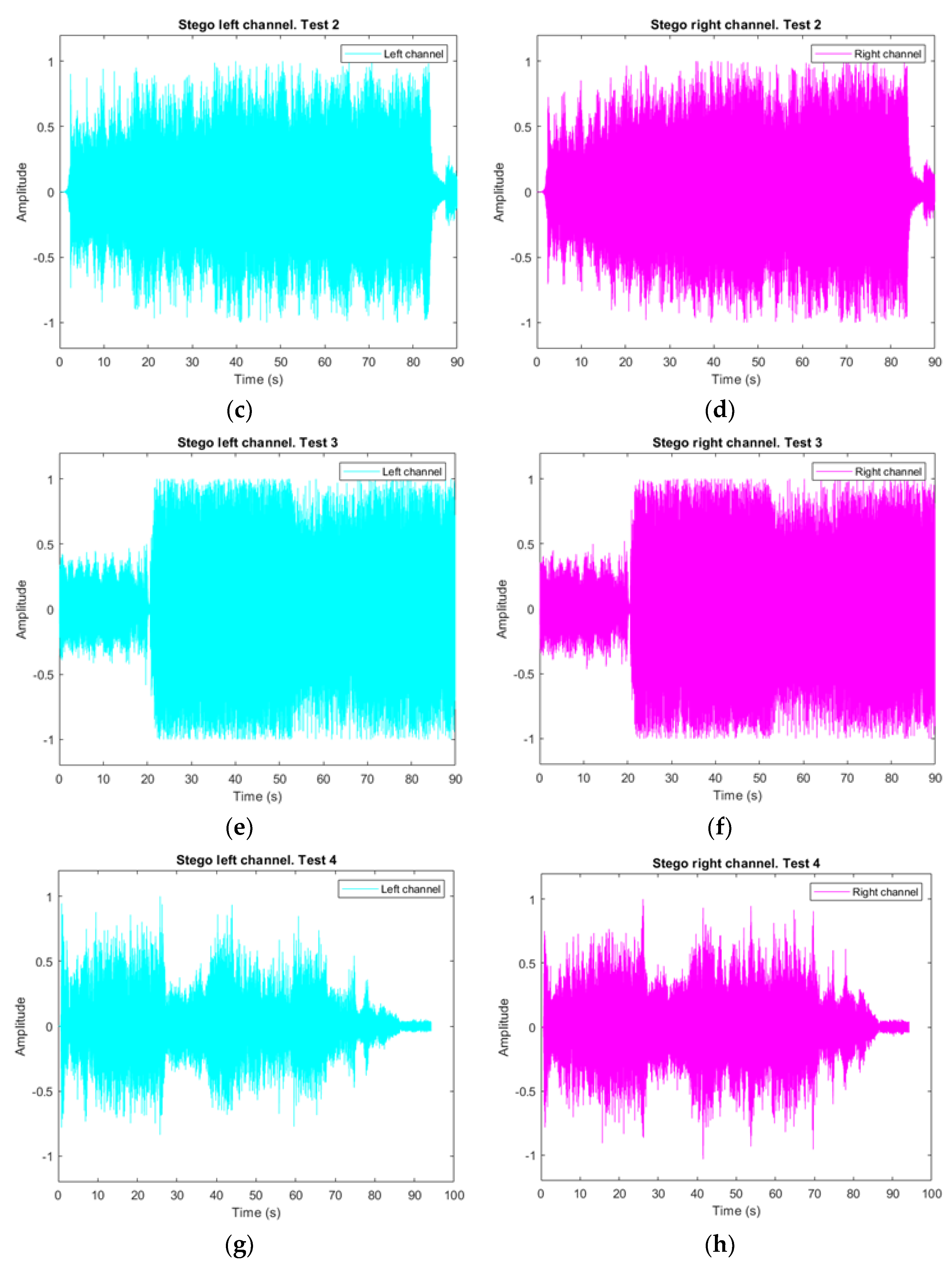
3.2. Stegoaudio Vector Decomposition
3.3. Vector Audio Comparison




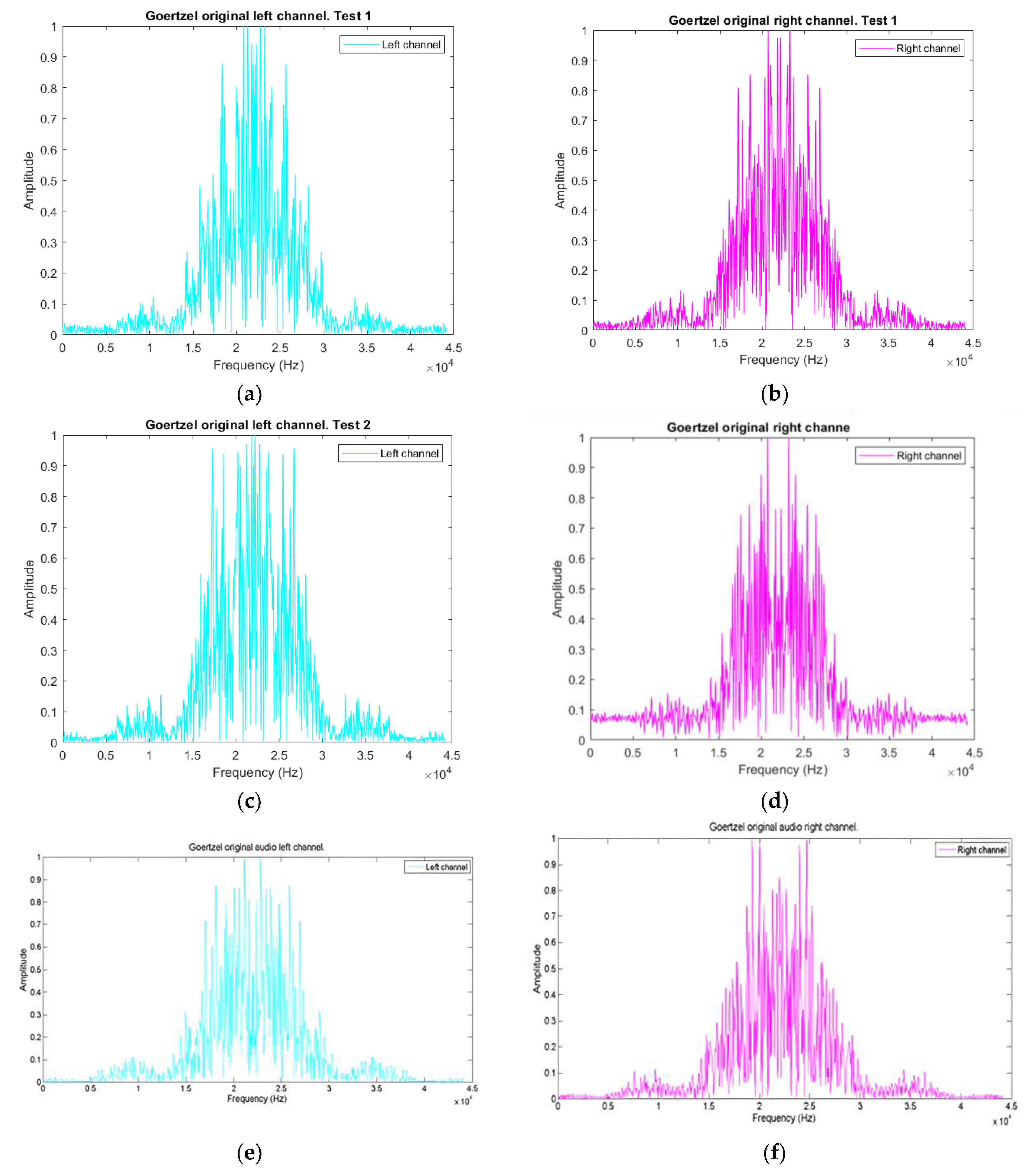
3.4. Frequency Analysis Decomposition
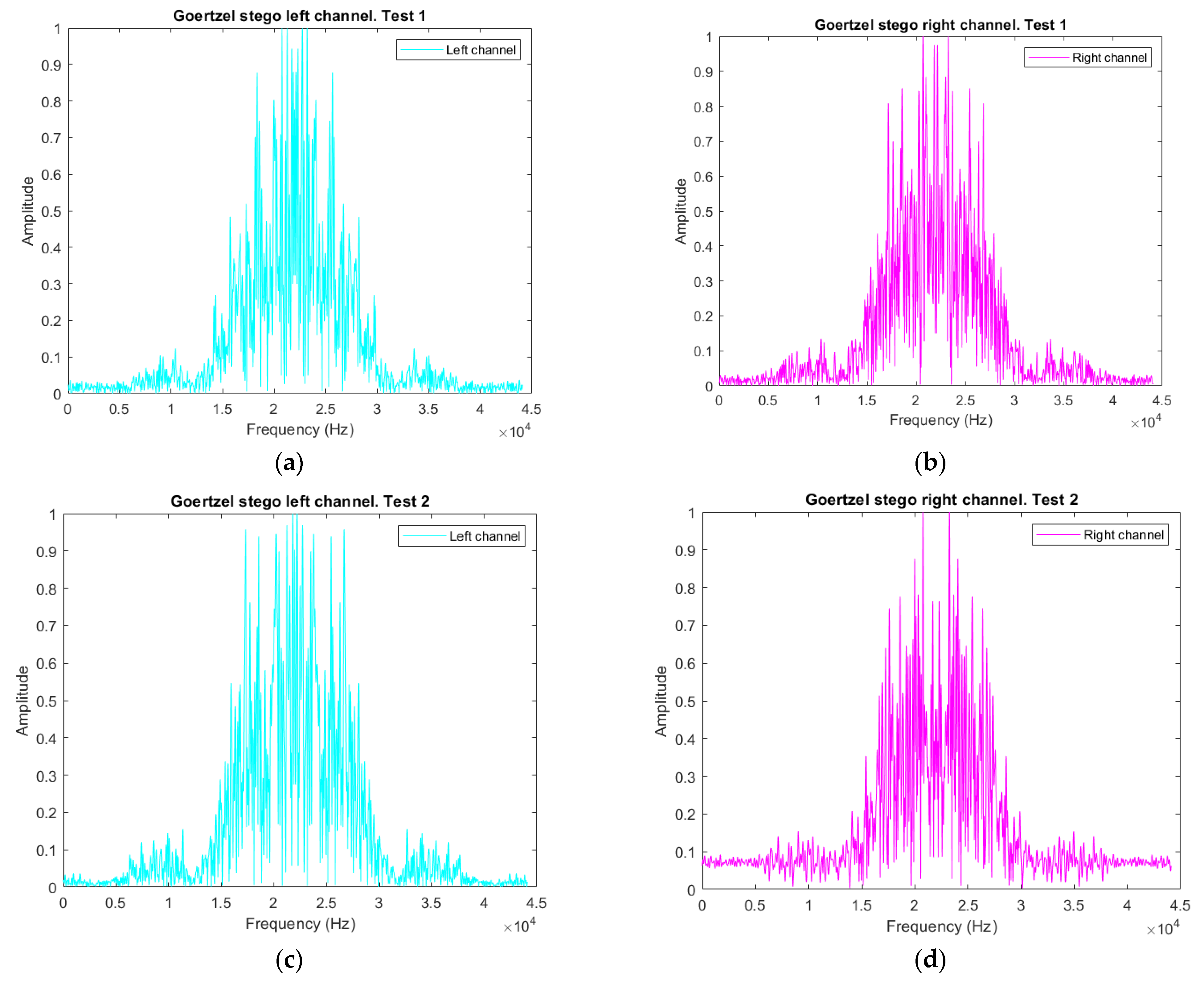
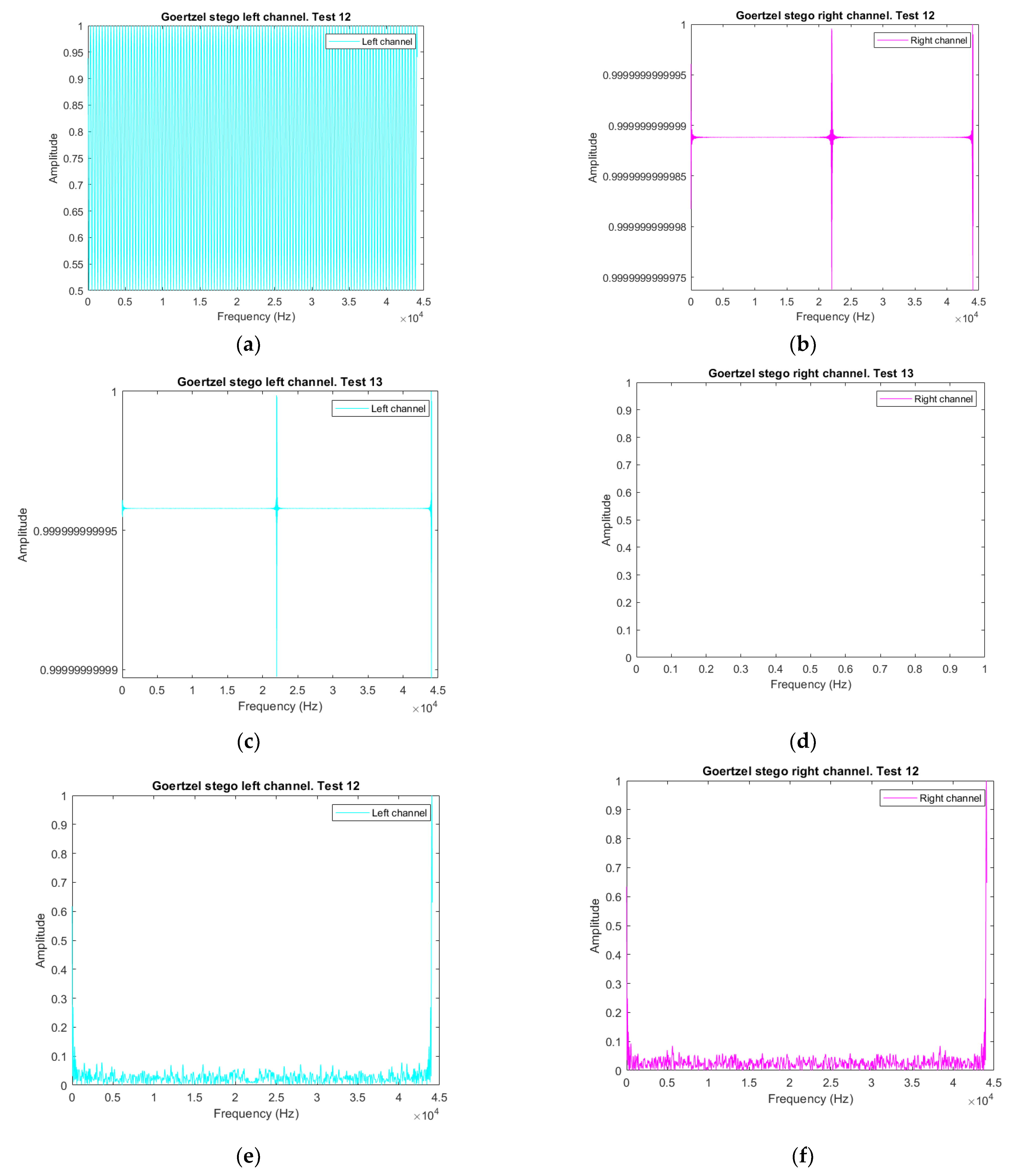
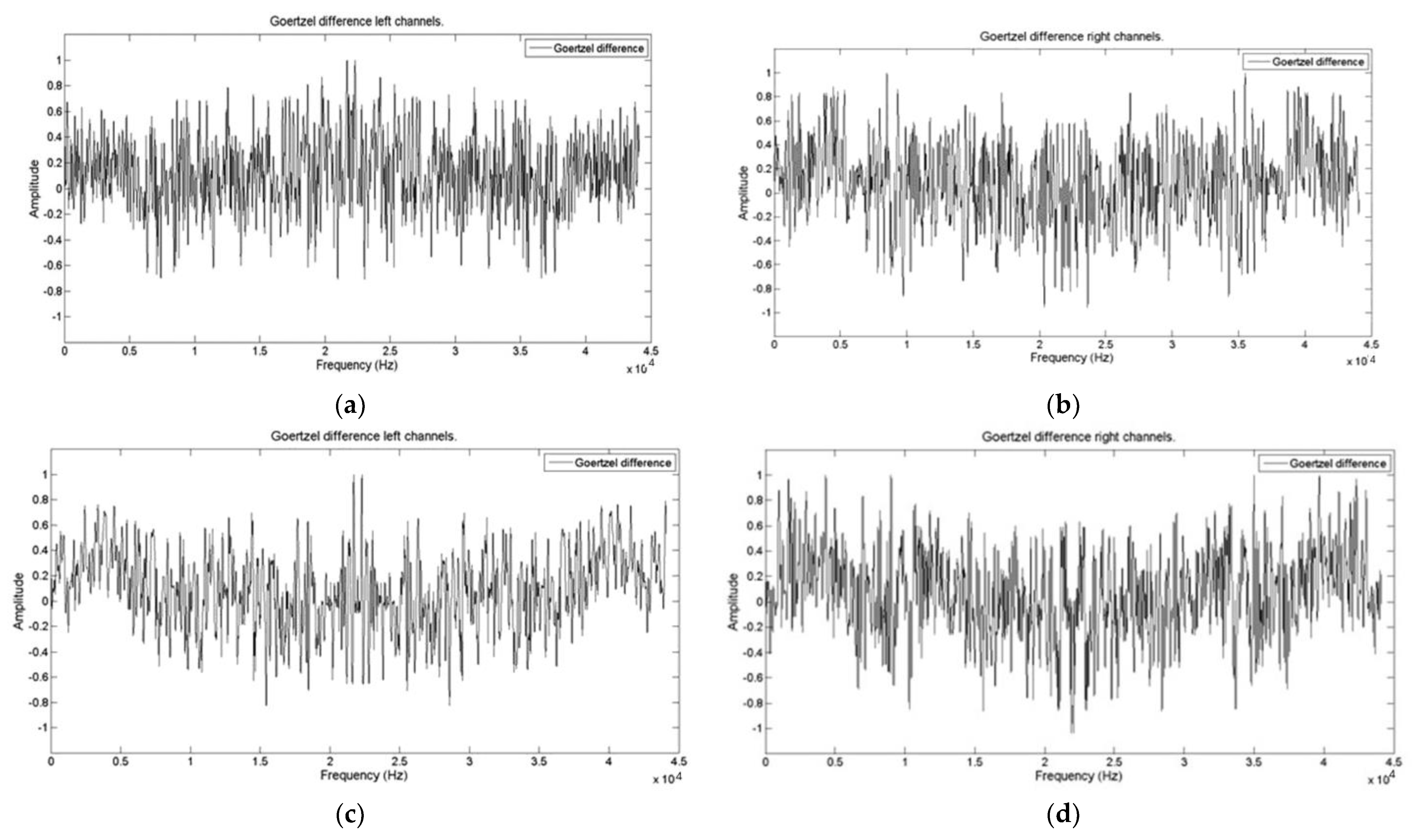
3.4.1. Goertzel Algorithm for Frequency Scanning Audio Vectors
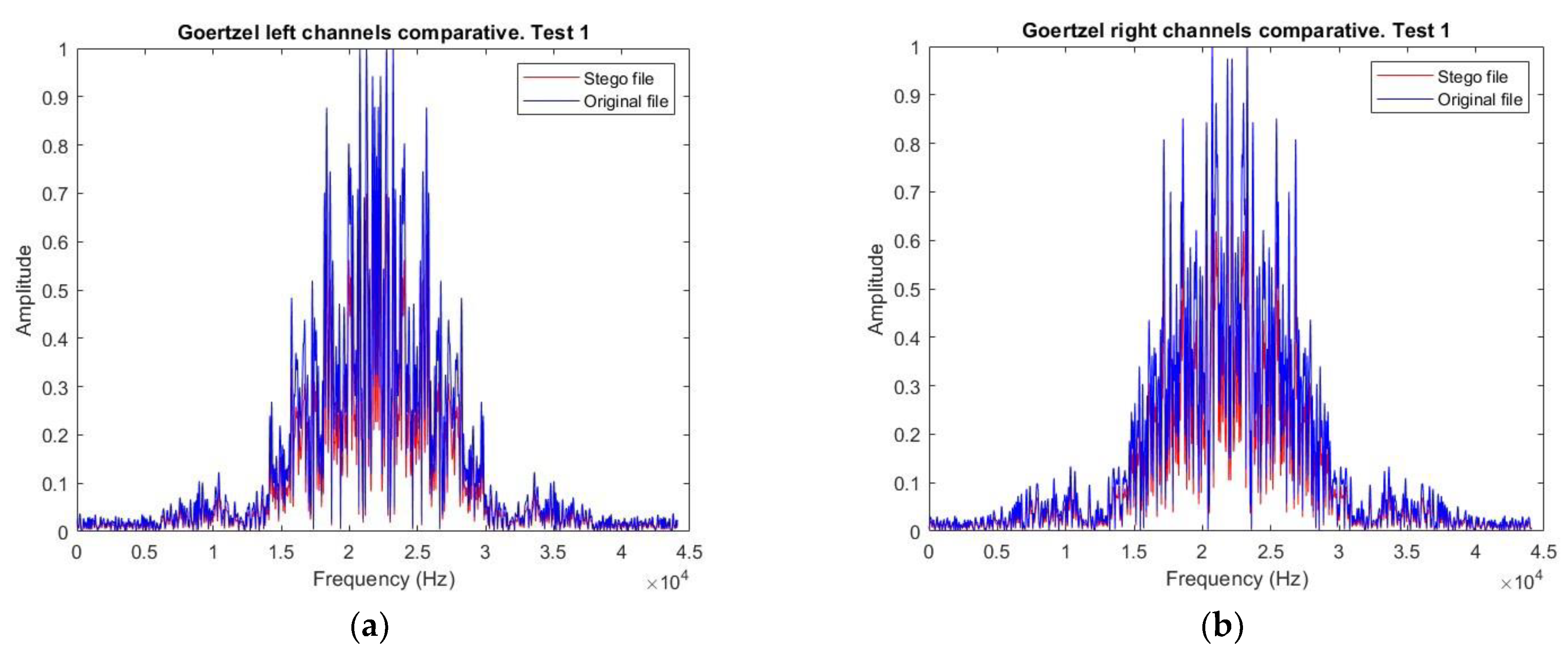
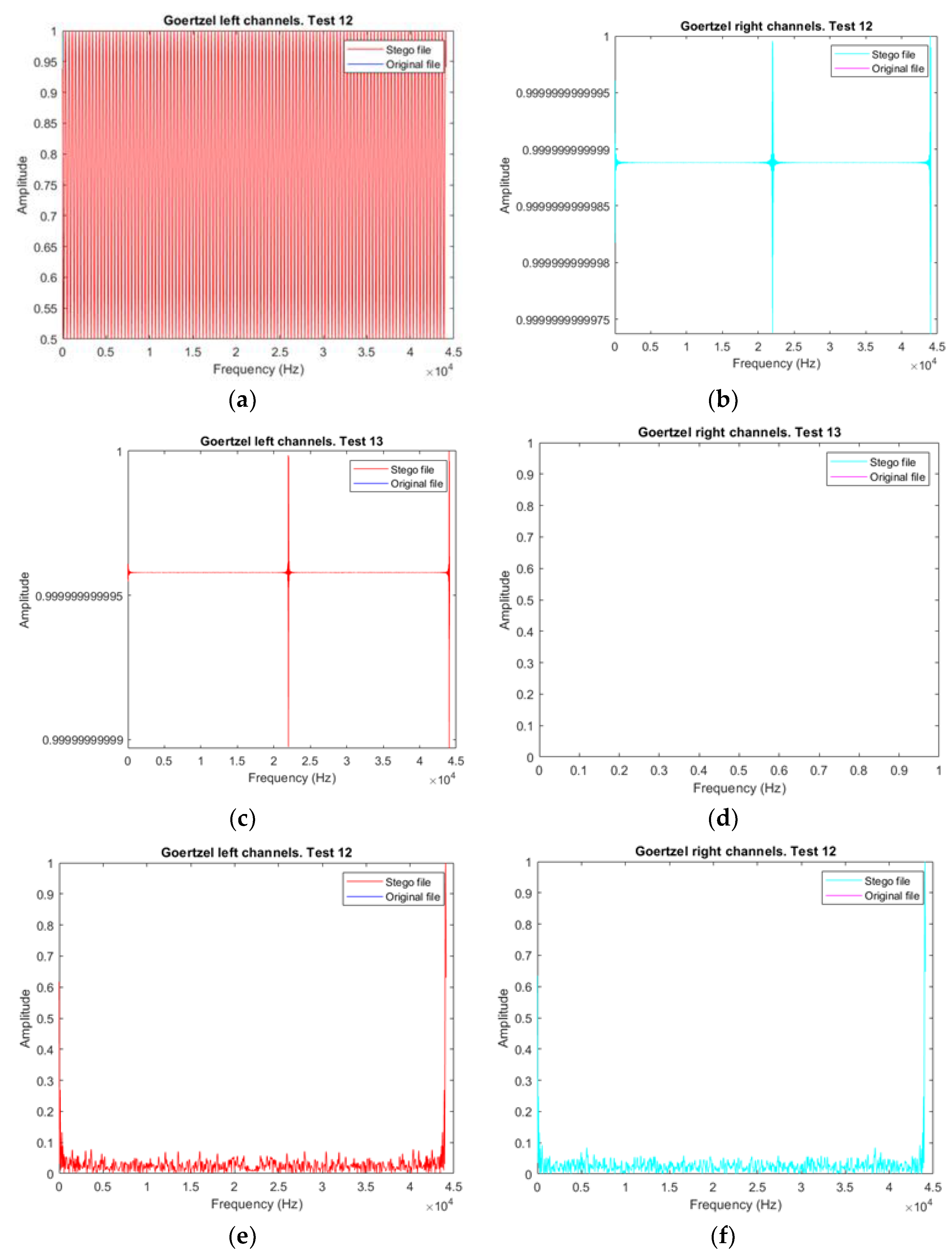
3.4.2. Audio Vector Comparison
3.4.3. Goertzel Vector Audio Comparison
4. Statistical Coefficient Results
4.1. Linear Prediction Coefficient Algorithm
4.2. Audio Quality Metrics Comparative Results
4.2.1. Estimates in the Time Domain
4.2.2. Estimates in the Frequency Domain
4.2.3. Perceptual Estimates
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chaharlang, J.; Mosleh, M.; Rasouli-Heikalabad, S. A novel quantum steganography-Steganalysis system for audio signals. Multimed. Tools Appl. 2020, 79, 17551–17577. [Google Scholar] [CrossRef]
- Zhang, Q.; Xu, F.; Bai, J. Audio Fingerprint Retrieval Method Based on Feature Dimension Reduction and Feature Combination. KSII Trans. Internet Inf. Syst. 2021, 15, 522–539. [Google Scholar] [CrossRef]
- Gong, C.; Zhang, J.; Yang, Y.; Yi, X.; Zhao, X.; Ma, Y. Detecting fingerprints of audio steganography software. Forensic Sci. Int. Rep. 2020, 2, 100075. [Google Scholar] [CrossRef]
- Dhawan, S.; Gupta, R. Analysis of various data security techniques of steganography: A survey. Inf. Secur. J. A Glob. Perspect. 2020, 30, 63–87. [Google Scholar] [CrossRef]
- Han, C.; Xue, R.; Zhang, R.; Wang, X. A new audio steganalysis method based on linear Prediction. Multimed. Tools Appl. 2018, 77, 15431–15455. [Google Scholar] [CrossRef]
- Chicharo, J.F.; Kilani, M.T. A sliding Goertzel algorithm. Signal Process. 1996, 52, 283–297. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, J.G.; Ji, Y.H.; Jung, Y.C.; Won, C.Y. An Islanding Detection Method for a Grid-Connected System Based on the Goertzel Algorithm. IEEE Trans. Power Electron. 2011, 26, 1049–1055. [Google Scholar] [CrossRef]
- Özer, H.; Avcıbas, İ.; Sankur, B.; Memon, N. Steganalysis of Audio Based on Audio Quality Metrics. Secur. Watermarking Multimed. Contents V 2003, 5020, 55–60. [Google Scholar] [CrossRef]
- Bohme, R.; Westfeld, A. Statistical Characterisation of MP3 Encoders for Steganalysis. In Proceedings of the 2004 Multimedia and Security Workshop on Multimedia and Security MM&Sec ’04, Magdeburg, Germany, 20–21 September 2004; pp. 25–34. [Google Scholar] [CrossRef]
- Johnson, M.; Lyu, S.; Farid, H. Steganalysis of recorded speech. In Security, Steganography, and Watermarking of Multimedia Contents VII; SPIE: Washington, DC, USA, 2005; Volume 5681, pp. 664–672. [Google Scholar] [CrossRef]
- Kuriakose, R.; Premalatha, P. A Novel Method for MP3 Steganalysis. In Intelligent Computing, Communication and Devices; Advances in Intelligent Systems and Computing; Jain, L., Patnaik, S., Ichalkaranje, N., Eds.; Springer: New Delhi, India, 2015; Volume 308, pp. 605–611. [Google Scholar] [CrossRef]
- Ren, Y.; Liu, D.; Liu, C.; Fu Xiong, J.; Wang, L. A Universal Audio Steganalysis Scheme Based on Multiscale Spectrograms and DeepResNet. IEEE Trans. Dependable Secur. Comput. 2022, 20, 665–679. [Google Scholar] [CrossRef]
- Dalal, M.; Juneja, M. Steganography and Steganalysis (in digital forensics): A Cybersecurity guide. Multimed. Tools Appl. 2020, 80, 5723–5771. [Google Scholar] [CrossRef]
- Medium. Available online: https://medium.com/@ece11106.sbit/steghide-tool-ec74edd69de4 (accessed on 19 June 2024).
- Dutta, H.; Das, R.K.; Nandi, S.; Prasanna, S.R.M. An Overview of Digital Audio Steganography. IETE Tech. Rev. 2019, 37, 632–650. [Google Scholar] [CrossRef]
- Djebbar, F.; Ayad, B.; Meraim, K.A.; Hamam, H. Comparative study of digital audio steganography techniques. EURASIP J. Audio Speech Music. Process. 2012, 25, 2012. [Google Scholar] [CrossRef]
- Sysel, P.; Rajmic, P. Goertzel algorithm generalized to non-integer multiples of fundamental frequency. EURASIP J. Adv. Signal Process. 2012, 2012, 56. [Google Scholar] [CrossRef]
- Onchis, D.; Rajmic, P. Generalized Goertzel algorithm for computing the natural frequencies of cantilever beams. Signal Process. 2014, 96, 45–50. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, L.; Wen, H.; Xu, L. A sliding-window DFT based algorithm for parameter estimation of multi-frequency signal. Digit. Signal Process. 2020, 97, 102617. [Google Scholar] [CrossRef]
- Chauhan, A.; Singh, K. Recursive sliding DFT algorithms: A review. Digit. Signal Process. 2022, 127, 103560. [Google Scholar] [CrossRef]
- Hariharan, M.; Chee, L.; Ai, O.; Yaacob, S. Classification of Speech Dysfluencies Using LPC Based Parameterization Techniques. J. Med Syst. 2012, 36, 1821–1830. [Google Scholar] [CrossRef] [PubMed]
- Grosicki, E.; Abed-Meraim, K.; Hua, Y. A weighted linear prediction method for near-field source localization. IEEE Trans. Signal Process. 2005, 53, 3651–3660. [Google Scholar] [CrossRef]
- Viswanathan, R.; Makhoul, J. Quantization properties of transmission parameters in linear predictive systems. IEEE Trans. Acoust. Speech Signal Process. 1975, 23, 309–321. [Google Scholar] [CrossRef]
- Steghide. Available online: https://steghide.sourceforge.net/ (accessed on 16 May 2024).
- Norouzi, L.S.; Mosleh, M.; Kheyrandish, M. Quantum Audio Steganalysis Based on Quantum Fourier Transform and Deutsch–Jozsa Algorithm. Circuits Syst. Signal Process. 2023, 42, 2235–2258. [Google Scholar] [CrossRef]
- Geetha, S.; Ishwarya, N.; Kamaraj, N. Audio steganalysis with Hausdorff distance higher order statistics using a rule based decision tree paradigm. Expert Syst. Appl. 2010, 37, 7469–7482. [Google Scholar] [CrossRef]
- Qiao, M.; Sung Andrew, H.; Liu, Q. MP3 audio steganalysis. Inf. Sci. 2013, 231, 123–134. [Google Scholar] [CrossRef]
- Thimmaraja, Y.G.; Nagaraja, B.G.; Jayanna, H.S. Speech enhancement and encoding by combining SS-VAD and LPC. Int. J. Speech Technol. 2021, 24, 165–172. [Google Scholar] [CrossRef]
- Krishnamoorthy, P. An Overview of Subjective and Objective Quality Measures for Noisy Speech Enhancement Algorithms. IETE Tech. Rev. 2011, 28, 292–301. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou Philipos, C. Evaluation of Objective Quality Measures for Speech Enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
- Kondo, K. Subjective Quality Measurement of Speech, Signals and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2012; pp. 7–20. [Google Scholar] [CrossRef]
- Rahmeni, R.; Aicha, A.B.; Ayed, Y.B. Voice spoofing detection based on acoustic and glottal flow features using conventional machine learning techniques. Multimedia Tools Appl. 2022, 81, 31443–31467. [Google Scholar] [CrossRef]
- Bedoui, R.A.; Mnasri, Z.; Benzarti, F. Phase Retrieval: Application to Audio Signal Reconstruction. In Proceedings of the 19th International Multi-Conference on Systems, Signals & Devices (SSD), Sétif, Algeria, 6–10 May 2022; pp. 21–30. [Google Scholar] [CrossRef]
- Gray, A.; Markel, J. Distance measures for speech processing. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 380–391. [Google Scholar] [CrossRef]
- Tohkura, Y. A weighted cepstral distance measure for speech recognition. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1414–1422. [Google Scholar] [CrossRef]
- Hicsonmez, S.; Uzun, E.; Sencar, H.T. Methods for identifying traces of compression in audio. In Proceedings of the 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, W.; Benbouchta, M.; Yantorno, R. Performance of the modified Bark spectral distortion as an objective speech quality measure. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP ‘98 (Cat. No.98CH36181), Seattle, WA, USA, 15 May 1998; Volume 1, pp. 541–544. [Google Scholar] [CrossRef]
- Ru, X.-M.; Zhang, H.-J.; Huang, X. Steganalysis of audio: Attacking the Steghide. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18 August 2005. [Google Scholar] [CrossRef]
- Wei, Z.; Wang, K. Lightweight AAC Audio Steganalysis Model Based on ResNeXt. Commun. Mob. Comput. 2022, 2022, 1. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Mean | Standard Deviation | Variance | Skewness | Kurtosis | Average Difference Per layer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Left | Right | Left | Right | Left | Right | Left | Right | Left | Right | Left | Right | |
| 1 | 0.1331 | 0.1412 | 0.1920 | 0.1962 | 0.0369 | 0.0385 | 2.0433 | 1.8591 | 6.9245 | 6.0740 | 1.8659 | 1.6618 |
| 0.1383 | 0.1444 | 0.1941 | 0.1942 | 0.0377 | 0.0377 | 2.0488 | 1.8774 | 6.9224 | 6.1448 | 1.8682 | 1.6797 | |
| 2 | 0.1557 | 0.1309 | 0.2170 | 0.1860 | 0.0471 | 0.0346 | 1.7994 | 1.9302 | 5.5369 | 6.4662 | 1.5512 | 1.7495 |
| 0.1565 | 0.1611 | 0.2158 | 0.1643 | 0.0466 | 0.0270 | 1.8125 | 2.0356 | 5.5893 | 6.8439 | 1.5641 | 1.8463 | |
| 3 | 0.1275 | 0.1313 | 0.1862 | 0.1766 | 0.0347 | 0.0312 | 2.1355 | 1.9504 | 7.4058 | 6.5890 | 1.9779 | 1.7757 |
| 0.1335 | 0.1353 | 0.1816 | 0.1732 | 0.0330 | 0.0300 | 2.2027 | 2.0194 | 7.7986 | 6.9441 | 2.0698 | 1.8604 | |
| 4 | 0.1263 | 0.1205 | 0.1854 | 0.1764 | 0.0344 | 0.0311 | 2.0611 | 2.1085 | 6.8736 | 7.3121 | 1.8561 | 1.9497 |
| 0.1272 | 0.1309 | 0.1841 | 0.1766 | 0.0339 | 0.0312 | 2.0738 | 2.1370 | 6.9456 | 7.3841 | 1.8729 | 1.9633 | |
| 5 | 0.1034 | 0.1415 | 0.1555 | 0.2102 | 0.0242 | 0.0442 | 2.2328 | 1.9909 | 8.1453 | 6.3936 | 2.1142 | 1.7560 |
| 0.1055 | 0.1446 | 0.1536 | 0.2098 | 0.0236 | 0.0440 | 2.2692 | 1.9909 | 8.3542 | 6.3640 | 2.1812 | 1.7506 | |
| 6 | 0.1331 | 0.1412 | 0.1920 | 0.1962 | 0.0369 | 0.0385 | 2.0433 | 1.8591 | 6.9245 | 6.0740 | 1.8659 | 1.6618 |
| 0.1361 | 0.1420 | 0.1876 | 0.1944 | 0.0352 | 0.0378 | 2.0567 | 1.8777 | 7.0045 | 6.1407 | 1.8840 | 1.6785 | |
| 7 | 0.1557 | 0.1309 | 0.2170 | 0.1860 | 0.0471 | 0.0346 | 1.7994 | 1.9302 | 5.5369 | 6.4662 | 1.5512 | 1.7495 |
| 0.1555 | 0.1317 | 0.2140 | 0.1852 | 0.0458 | 0.0343 | 1.8278 | 1.9390 | 5.6717 | 6.5146 | 1.5829 | 1.7609 | |
| 8 | 0.1275 | 0.1313 | 0.1862 | 0.1766 | 0.0347 | 0.0312 | 2.1355 | 1.9504 | 7.4058 | 6.5890 | 1.9779 | 1.7757 |
| 0.1332 | 0.1380 | 0.1827 | 0.1764 | 0.0334 | 0.0311 | 2.1572 | 2.0062 | 7.4645 | 6.8348 | 1.9942 | 1.8373 | |
| 9 | 0.1263 | 0.1205 | 0.1854 | 0.1764 | 0.0344 | 0.0311 | 2.0611 | 2.1085 | 6.8736 | 7.3121 | 1.8561 | 1.9497 |
| 0.1272 | 0.1222 | 0.1854 | 0.1772 | 0.0344 | 0.0314 | 2.0689 | 2.1083 | 6.9027 | 7.3051 | 1.8637 | 1.9488 | |
| 10 | 0.1034 | 0.1415 | 0.1555 | 0.2102 | 0.0242 | 0.0442 | 2.2328 | 1.9909 | 8.1453 | 6.3936 | 2.1322 | 1.7560 |
| 0.1076 | 0.1478 | 0.1539 | 0.2105 | 0.0237 | 0.0443 | 2.2941 | 2.0060 | 8.4384 | 6.4523 | 2.1035 | 1.7721 | |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 1 | SNR | ✔ | |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ✔ | |
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ||
| CD | ✔ | ✔ | |
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 7/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 2 | SNR | ✔ | ✔ |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ✔ | |
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ✔ | |
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 9/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 3 | SNR | ✔ | |
| CDZ | ✔ | ||
| LLR | ✔ | ✔ | |
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ||
| CD | ✔ | ✔ | |
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 6/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 4 | SNR | ✔ | ✔ |
| CDZ | ✔ | ||
| LLR | ✔ | ✔ | |
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ||
| CD | ✔ | ✔ | |
| STFRT | ✔ | ||
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 6/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 5 | SNR | ✔ | ✔ |
| CDZ | ✔ | ||
| LLR | ✔ | ✔ | |
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ||
| CD | ✔ | ✔ | |
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 7/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 1 | SNR | ✔ | ✔ |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ||
| LAR | ✔ | ||
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ||
| STFRT | ✔ | ||
| SP | ✔ | ✔ | |
| SPM | ✔ | ||
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 5/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 2 | SNR | ✔ | |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ||
| LAR | ✔ | ✔ | |
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ||
| STFRT | ✔ | ||
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 6/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 3 | SNR | ✔ | |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ||
| LAR | ✔ | ✔ | |
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ||
| STFRT | ✔ | ||
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ✔ | |
| MBSD | ✔ | ✔ | |
| WSSD | ✔ | ||
| Hit | 7/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 4 | SNR | ✔ | |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ✔ | |
| LAR | ✔ | ✔ | |
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ||
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ||
| WSSD | ✔ | ||
| Hit | 7/13 | 13/13 |
| Test | AQM | Without Goertzel Algorithm | With Goertzel Algorithm |
|---|---|---|---|
| 5 | SNR | ✔ | |
| CDZ | ✔ | ✔ | |
| LLR | ✔ | ||
| LAR | ✔ | ✔ | |
| ISD | ✔ | ||
| COSH | ✔ | ✔ | |
| CD | ✔ | ||
| STFRT | ✔ | ✔ | |
| SP | ✔ | ✔ | |
| SPM | ✔ | ✔ | |
| BSD | ✔ | ||
| MBSD | ✔ | ||
| WSSD | ✔ | ||
| Hit | 6/13 | 13/13 |
| Stegoanalysis Method | Steganography Method | HIT |
|---|---|---|
| Proposed in [25] | LSFQ | 95.97% |
| Proposed in [38] | Steghide | 90–98% |
| Proposed in [39] | MIN SING HCM | 99.90% 99.87% 99.50% |
| Proposed in [5] | S-tools Hide4PGP | 99.5% 98.3% |
| Proposed in [12] | -------- | 91.63% |
| Our proposed method | Steghide Hide4PGP | 100% |
| Test | Time Processing (s) |
|---|---|
| 1 | 0.265 |
| 2 | 0.422 |
| 3 | 0.262 |
| 4 | 0.257 |
| 5 | 0.251 |
| 6 | 0.257 |
| 7 | 0.254 |
| 8 | 0.275 |
| 9 | 0.251 |
| 10 | 0.294 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carvajal-Gámez, B.E.; Castillo-Martínez, M.A.; Castañeda-Briones, L.A.; Gallegos-Funes, F.J.; Díaz-Casco, M.A. Audio Steganalysis Estimation with the Goertzel Algorithm. Appl. Sci. 2024, 14, 6000. https://doi.org/10.3390/app14146000
Carvajal-Gámez BE, Castillo-Martínez MA, Castañeda-Briones LA, Gallegos-Funes FJ, Díaz-Casco MA. Audio Steganalysis Estimation with the Goertzel Algorithm. Applied Sciences. 2024; 14(14):6000. https://doi.org/10.3390/app14146000
Chicago/Turabian StyleCarvajal-Gámez, Blanca E., Miguel A. Castillo-Martínez, Luis A. Castañeda-Briones, Francisco J. Gallegos-Funes, and Manuel A. Díaz-Casco. 2024. "Audio Steganalysis Estimation with the Goertzel Algorithm" Applied Sciences 14, no. 14: 6000. https://doi.org/10.3390/app14146000
APA StyleCarvajal-Gámez, B. E., Castillo-Martínez, M. A., Castañeda-Briones, L. A., Gallegos-Funes, F. J., & Díaz-Casco, M. A. (2024). Audio Steganalysis Estimation with the Goertzel Algorithm. Applied Sciences, 14(14), 6000. https://doi.org/10.3390/app14146000