1. Introduction
Given the subjective and multidimensional nature of evaluating the quality of color prints, this task becomes inherently complex. With the rapid evolution of the digital printing industry, ensuring high-quality prints has become a central concern, garnering increasing attention. Unlike expert measurements using technical means, the assessment of print image quality by the general public often relies on personal preferences and subjective perceptions [
1]. Consequently, there is a pressing need to develop an evaluation metric that closely aligns with human visual perception.
Numerous research teams have dedicated substantial efforts to evaluating both print quality and image quality. Jing et al. [
2] have developed an image processing and analysis metric employing a universal approach. This metric takes digital and scanned images as input and produces grayscale spatial visualizations indicating the location and severity of defects as output, effectively assessing various flaws. Eerola [
3] applied No-Reference image quality assessment (NR-IQA) metrics to print images and evaluated the performance of several cutting-edge NR-IQA metrics on a vast array of printed photographs. Notably, the Blind Image Quality Index (BIQI) and the Natural Image Quality Evaluator (NIQE) metrics outperformed other IQA methods. Of these, the NIQE displayed lower sensitivity to image content. In a related field of image processing pertinent to printing, Mittal [
4] proposed a distortion-agnostic no-reference (NR) quality assessment metric leveraging natural scene statistics. This spatial domain-based metric offers heightened computational efficiency. Liang [
5] introduced a pioneering deep blind IQA metric based on multiple instance regression to overcome the fundamental limitation of unavailable ground truth for local blocks in traditional convolutional neural network-based image quality assessment (CNN-based IQA) models. Additionally, Wang [
6] devised a multiscale information content-weighted approach based on the natural image gradient structural similarity metric (GSM) model. This novel weighting method enhances the performance of IQA metrics relying on the Peak Signal-to-Noise Ratio (PSNR) and the SSIM.
The researchers mentioned above have made significant advancements in their respective fields. However, methodologies for evaluating the quality of digital print images often assess images from a limited perspective. While addressing specific issues such as color deviation, spatial domain information may adequately characterize the problem. However, metrics representing image quality extend beyond color aspects alone. Different image contents emphasize various directions, and the importance of different aspects of image quality varies across different media. For example, while glossiness [
3] is not an intrinsic attribute of digital images, it significantly influences the perceived quality of printed images. Additionally, the unique characteristics of digital print images have been overlooked in image quality assessment: the color gamut range of digital print images is much smaller than that of digital images, and printed images are essentially halftone images, with grayscale variations influenced by the human eye’s low-pass characteristics, unlike continuous-tone digital images. Understanding the visual traits of the human eye reveals its ability to perceive diverse visual sensations through image contrast, brightness, and phenomena such as visual masking and brightness adaptation when viewing images. Therefore, evaluating print image quality requires considering not only objective assessments of print quality but also the influence of visual characteristics on print quality. Relying solely on a singular evaluation framework risks significant disparities between assessment conclusions on final print quality and intuitive visual perceptions, leading to notable discrepancies between objective and subjective quality assessments.
Hence, our study endeavors to develop a comprehensive print quality evaluation metric grounded in deep learning, aiming to reconcile subjective and objective assessment outcomes. To accomplish this, we initially gathered print images and meticulously aligned them with pre-press digital images to ensure commensurability. Subsequently, we conduct feature extraction from these processed datasets in both spatial and frequency domains, covering diverse aspects like the color, structure, and content of the images. Employing similarity measurement techniques enables us to quantitatively assess the distinctions between these features, thereby furnishing robust support for accurate print quality appraisal. Leveraging neural network models facilitates precise predictions of the objective quality assessment results for prints.
In the ensuing sections, we will delve into our research in greater detail.
Section 2 will focus on evaluating the performance of sampling devices to ensure the fidelity and dependability of data acquisition, while also establishing the theoretical underpinnings for spatial domain feature extraction.
Section 3 will delve deeper into methods for frequency domain feature extraction and devise effective tools for feature fusion.
Section 4 will present our experimental findings and undertake a thorough analysis to refine the proposed quality assessment metric. Finally,
Section 5 will encapsulate the outcomes and conclusions of our entire research endeavor.
2. Extraction of Spatial Domain Features from Digital Print Images
For assessing the quality of printed images, there exist several methods that can capture post-print images, including the use of multispectral cameras, CCD line scan cameras, and scanners. In this study, we opted for the Epson Expression 13000XL scanner (Epson, Suwa, Japan) to acquire image data due to its high precision, which facilitates the faithful reproduction of real data, along with its user-friendly and efficient operation. The specific parameters are detailed in
Table 1. The acquired images are in the RGB color space.
We derived the modulation transfer function (MTF) of the scanner by scanning the ISO 12233 [
7] test chart, as illustrated in
Figure 1 The scanning results allowed us to determine the scanner’s MTF, as shown in
Figure 2. At lower spatial frequencies, the MTF values are higher, indicating that the scanner performs well when reproducing larger details and overall image contrast. The curve drops gently, so we can conclude that the device’s performance is relatively stable.
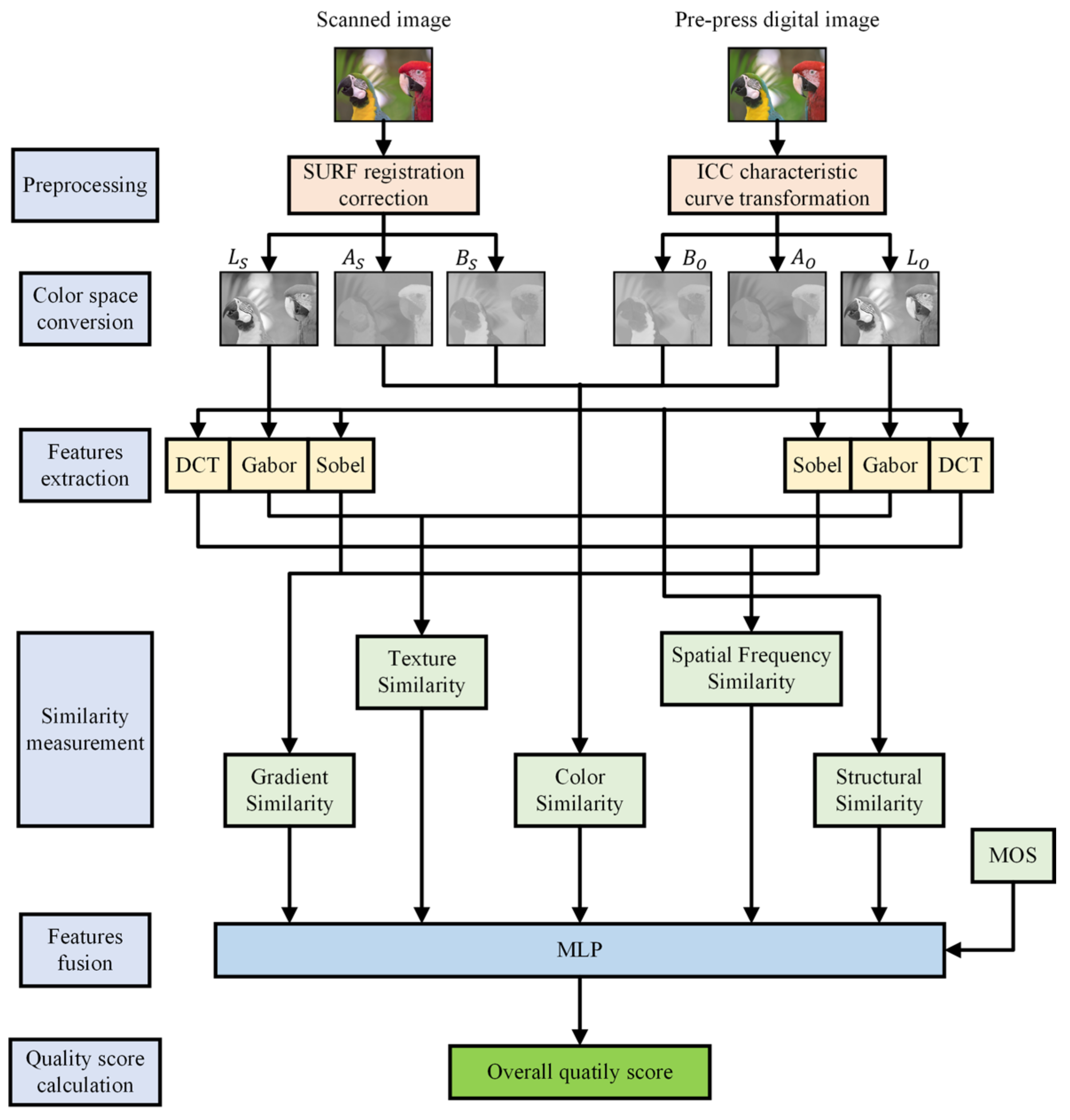
Figure 3 presents a novel metric proposed for assessing the quality of digital print images, termed Spatial-Frequency Domain Feature Fusion (FFSF). The preprocessing stage involves the feature curve transformation of pre-print digital images, wherein the images undergo processing using device ICC curves. Additionally, post-scan images undergo registration and correction. Subsequently, the preprocessed images are subjected to spatial transformation, transitioning from the original color space to the CIELAB color space. Features are then extracted from the L, A, and B channels, with chromaticity features being extracted from channels A and B. In the L channel, gradient features are computed using Sobel filters, structural features are evaluated using the structural similarity index (SSIM) metric, texture features are extracted via a Gabor filter bank, and spatial frequency features are derived by analyzing discrete cosine transform (DCT) coefficients of image blocks. Following feature extraction, similarity metrics are applied to quantify the differences between features extracted from pre-print digital images and scanned print images. Finally, an MLP neural network model trained on standard datasets is employed to predict the objective quality scores of the print images.
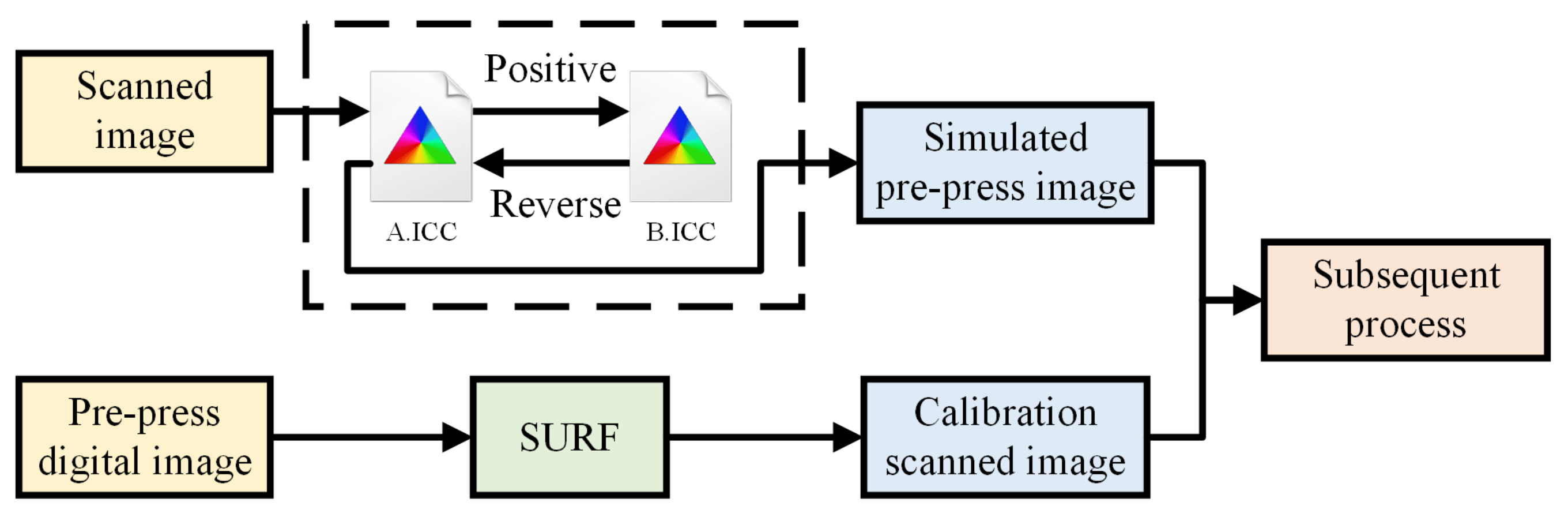
Due to inevitable issues like positional shifts and rotations during the scanning process, image registration is necessary to ensure more accurate scanned images. In this study, we utilized the SURF (Speeded-Up Robust Features) metric. Extensive research by Pang [
8] has shown this metric to be highly reliable. Since the imaging principles of pre-press digital images and post-scan images differ, it is illogical to directly compare them. Spatial transformations and device characteristic curve transformations were applied to pre-press images, including both forward and inverse transformations, as depicted in
Figure 4. Here, A.ICC represents the spatial transformation curve, while B.ICC denotes the device characteristic curve. The forward and reverse transformations do not preserve the original image; instead, they introduce color alterations due to the application of different ICC curves, thereby simulating the printing imaging process accurately.
For color image prints, accurately reproducing colors serves as a critical benchmark for quality control. In color image printing, challenges often arise in mapping color information between different color spaces. For instance, in digital printing, original information is typically presented in RGB or CMYK mode on a monitor, while printing involves transferring ink onto a substrate in the form of ink dots. Due to the human eye’s low-pass characteristics, it primarily perceives the overall appearance and cannot discern ink dots at a microscopic level. This underscores the essence of printing, where color gradation is manifested by the density of ink dots.
When conducting quality assessment, the selection of an appropriate color space holds significant importance in the evaluation process. We opt for the classic color space for conversion, namely the CIELAB [
9,
10,
11] color space. If the original image is in the CMYK color space and needs to be converted to the CIELAB color space, it must first be converted to the RGB color space. However, direct conversion from the RGB color space to the CIELAB color space is not possible; instead, it necessitates the use of the XYZ color space as an intermediary. The CIELAB color space comprises a luminance channel and two chromaticity channels. The conversion formula is as follows:
Based on the device’s ICC file, the following information is obtained, including the
,
,
,
,
, and
, as shown in
Table 2 and
Figure 5. Furthermore, it is noted that in Equation (3),
, and
values can be queried through the ICC file,
,
,
.
For clarity in subsequent discussions, the following explanation is provided: The experimental objects are a preprocessed, pre-print digital image, denoted as , and a post-scanned image, denoted as . After color space transformation, the three-channel image information of includes , and , while the three-channel image information of includes , and .
2.1. Extraction of Chromaticity Features
Chroma refers to the saturation or purity of a color, indicating its intensity. Changes in chroma can reflect the accuracy and consistency of color reproduction during printing. Color features are extracted from the A and B channels. The similarity of the A channel is as follows:
In this equation,
represents the index of the image pixel, and
denotes the total number of pixels in the image.
serves as a stabilizing constant for the fractional term to prevent division by zero. Similarly, the chromaticity similarity in the
channel is described as follows:
The calculation of color feature similarity between
and
is outlined as follows:
Different values of
will lead to differences in chromaticity similarity. In order to optimize the chromaticity metrics, the TID2013 dataset was tested to judge the effect of
values on chromaticity values via the Spearman Rank Order Correlation Coefficient (SROCC) metrics. The SROCC is used as a measure of the correlation between two variables. The SROCC value range is [−1, 1]; the closer it is to 1 or −1, the more monotonicity is achieved. The results are shown in
Figure 6.
Figure 6a shows the change curve of the SROCC metrics with
taking the value of
Figure 6b, which shows the change rate of the curve. From this analysis, it is concluded that the SROCC increases rapidly when the value of
increases from 0 to about 40, which indicates that the monotonicity between the color similarity and the true value increases as the value of the parameter increases. The rate of increase of the SROCC starts to slow down when the value of
is about 40, and enters into a smooth growth phase. When the parameter value continues to increase, the SROCC still shows a slow increasing trend, but the increase is smaller and close to linear growth. In practical applications, it may be necessary to find a balance between the performance improvement induced by the parameter value increase and the computational complexity. Too high a parameter value may not significantly improve the performance, while the computational cost will increase. All things considered,
is chosen in this paper.
2.2. Gradient Features of Digital Print Images Based on the Sobel Filter
In print quality assessment, gradient refers to the rate of change in color or brightness within an image. Gradient features reveal the sharpness of edges and details, as well as variations in texture. This information is essential for evaluating print quality. Image edges play a vital role in conveying visual information, with gradient features widely utilized in image quality assessment due to their ability to capture both edge structure and contrast variations effectively [
12]. Various forms of gradient features have been integrated into image quality assessment metrics. For example, the Feature Similarity Index (FSIM) incorporates gradient and phase consistency features to evaluate the local quality of distorted images [
13], while the Directional Similarity Measure (DASM) combines gradient magnitude, anisotropy, and local orientation features [
14,
15,
16,
17]. Commonly employed edge detection filters include those created by Sobel, Prewitt, and Scharr [
18]. The advantage of the Sobel operator lies in its robustness to noise and its relatively accurate computation of edge direction. In this study, the Sobel filter was chosen to compute the gradient of the luminance channel in both
and
. The gradient magnitude calculation formulas for these images using the Sobel filter on the L channel are as follows:
where
and
denote the gradient magnitude values at position index
of the pre-press digital image and the printed and scanned image, respectively. The symbol
indicates the convolution operation.
and
represent the horizontal and vertical Sobel filter templates, defined as follows:
The similarity between the gradient magnitudes of
and
is quantified using the standard deviation of the similarity:
In this context,
serves as a stabilizing constant within the fraction to prevent division by zero. The relationship strength between gradient similarity and the Mean Opinion Score (MOS) was assessed using the SROCC metric across various
values, as illustrated in
Figure 7. A higher SROCC value approaching one signifies a stronger correlation between the two datasets. Notably, the maximum SROCC value is achieved when
is set to 66. Thus, for this study,
is determined to be 66. The red number and dot line indicate the positions of the inflection points of the curve, which are the turning points where the curve transitions from an upward trend to a downward trend.
2.3. Printing Image Structural Features Based on the SSIM
Structure refers to the layout and organization of textures, details, and patterns within an image. The quality of structure significantly influences the visual quality of the image and the overall perception of printed materials. Based on the premise that the CIELAB color space is well suited for extracting structural information from the scene, Wang et al. [
14] introduced a novel concept for measuring image quality known as the SSIM. This concept defines separate functions to measure the luminance, contrast, and structural similarity between two images,
and
, in the L channel. Their similarity is calculated as the product of the luminance similarity
, the contrast similarity
, and the structural similarity
, resulting in an overall measure of image similarity:
where:
Let the parameters
, and
be expressed as follows:
The equations demonstrate that
and
represent the luminance features using the mean value. Taking
as an example, the calculation is as follows:
Similarly, the calculation for is as follows.
and
represent the contrast feature using normalized variance. For instance, the calculation for
is as follows:
Similarly, the calculation for is as follows.
represents the covariance used to characterize the structural feature, which is calculated as follows:
and are constants employed to ensure stability. Here, denotes the number of grayscale levels in the image. For an 8-bit grayscale image, , with and . Substituting these values, we obtain and .
4. Experimental Results and Analysis
To assess the effectiveness of the proposed metrics, experiments were conducted on two standard databases: TID2013 [
37] and TID2008 [
38]. Both datasets comprise a selection of distorted images that are utilized to evaluate the perceptual quality of images. The TID2008 dataset comprises 25 reference images along with their respective distorted versions. The distortions in TID2008 encompass noise, blur, compression artifacts, and various other types of distortions. The TID2013 dataset comprises 3000 reference images paired with their corresponding distorted versions. The distortions applied to these images encompass a range of common types, including noise, blur, compression artifacts, and others. Four key performance metrics were employed for a quantitative evaluation: the Pearson Linear Correlation Coefficient (PLCC), SROCC, the Kendall Rank Order Correlation Coefficient (KROCC), and the Root Mean Square Error (RMSE). The PLCC gauges the model’s prediction accuracy, reflecting its ability to predict subjective assessments with minimal error. The RMSE measures the consistency of the model’s predictions. The SROCC and the KROCC indicate the monotonicity of the model’s predictions, showcasing how well it can predict subjective assessments. The proposed method underwent comparison with nine classical Full-Reference image quality assessment (FR-IQA) methods, including GMSD [
17], GSM [
16], IFC [
39], MAD [
40], MSSIM [
41], PSNR [
42], SSIM [
14], VIF [
43], and VSI [
44].
The color space transformation is performed on both the original digital image and the scanned print image, as illustrated in
Figure 12:
Using the TID2013 dataset as an example, the images in the TID2013 dataset were printed and subsequently scanned to obtain scanned images. The relationship between the chromaticity similarity index in the CIELAB space and the MOS was validated, utilizing the MOS provided by the dataset itself, according to the method described in
Section 2.1.
Figure 13 illustrates the distribution of the chromaticity similarity and the MOS for printed images in the CIELAB color space:
The scatter plot depicts a consistently distributed set of data points, which are densely clustered, suggesting the precision of the method outlined in
Section 2.1.
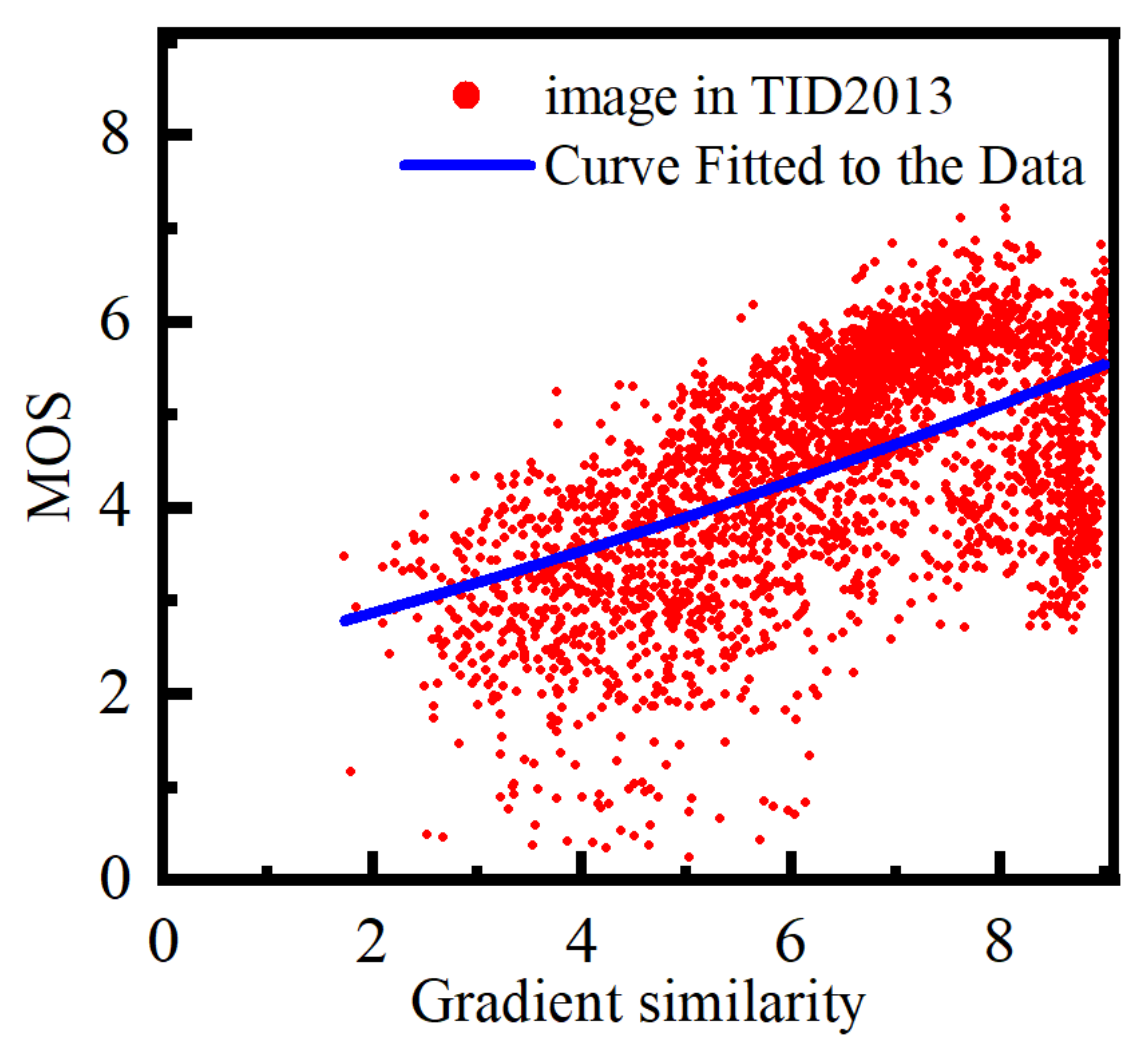
Similarly, this study examines the correlation between the gradient similarity metric proposed in
Section 2.2 and the MOS.
Figure 14 illustrates the distribution of gradient similarity against the MOS:
The scatter plot shows a relatively uniform distribution of data points with high concentrations, indicating the accuracy of the method proposed in
Section 2.2.
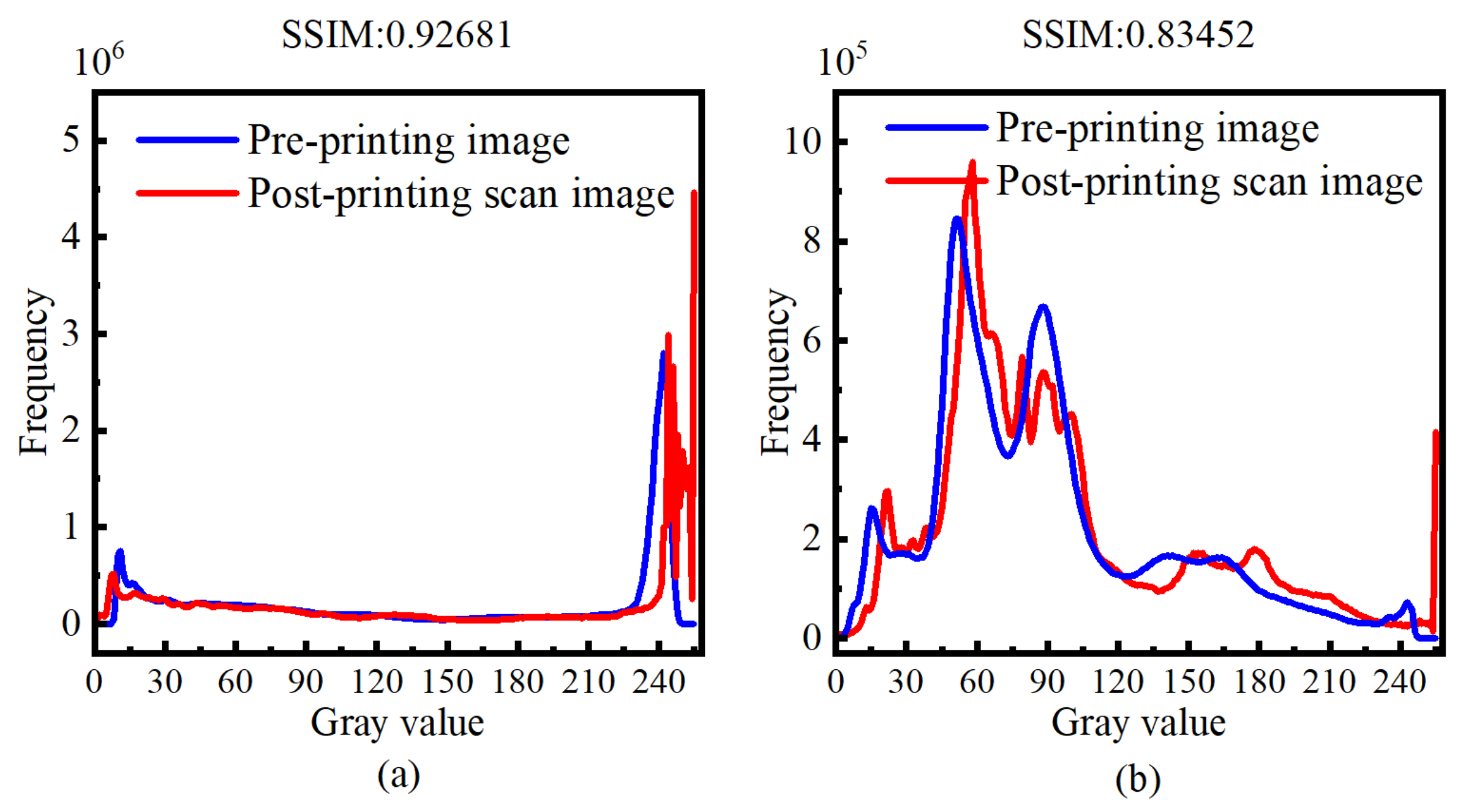
Randomly selected images from the TID2008 and TID2013 standard datasets were used to measure the SSIM values of the pre-print digital images and the scanned images, along with their energy histograms, as shown in
Figure 15. It can be observed that the energy distribution of the two images is nearly identical in the low-frequency region. However, in the high-frequency region, the energy of the pre-print digital image is higher than that of the scanned image. This is because printing cannot perfectly reproduce continuous-tone images. Additionally, it can be concluded that the printing quality is poorer in the color depth region. This is reasonable because printing machines have a saturation point: once the ink density reaches a certain level, the color becomes saturated, and further increasing the ink amount will not change the color.
This paper selects features from Gabor filters with four orientations and five scales. The selection method for the orientation parameter
is as follows:
Here, represents the total number of filter orientations. In this paper, we select four orientations, so the angles are, respectively, , , , .
The parameter
of the Gabor filter represents the frequency of the filter, and it is calculated as follows:
represents the bandwidth of the filter, typically set as
, then
. For a filter bank, its frequency can be expressed as follows:
represents the total number of frequencies for the filter, where . In this study, five scales are chosen, and thus .
As shown in
Figure 16, the real and imaginary parts of the Gabor filter are illustrated.
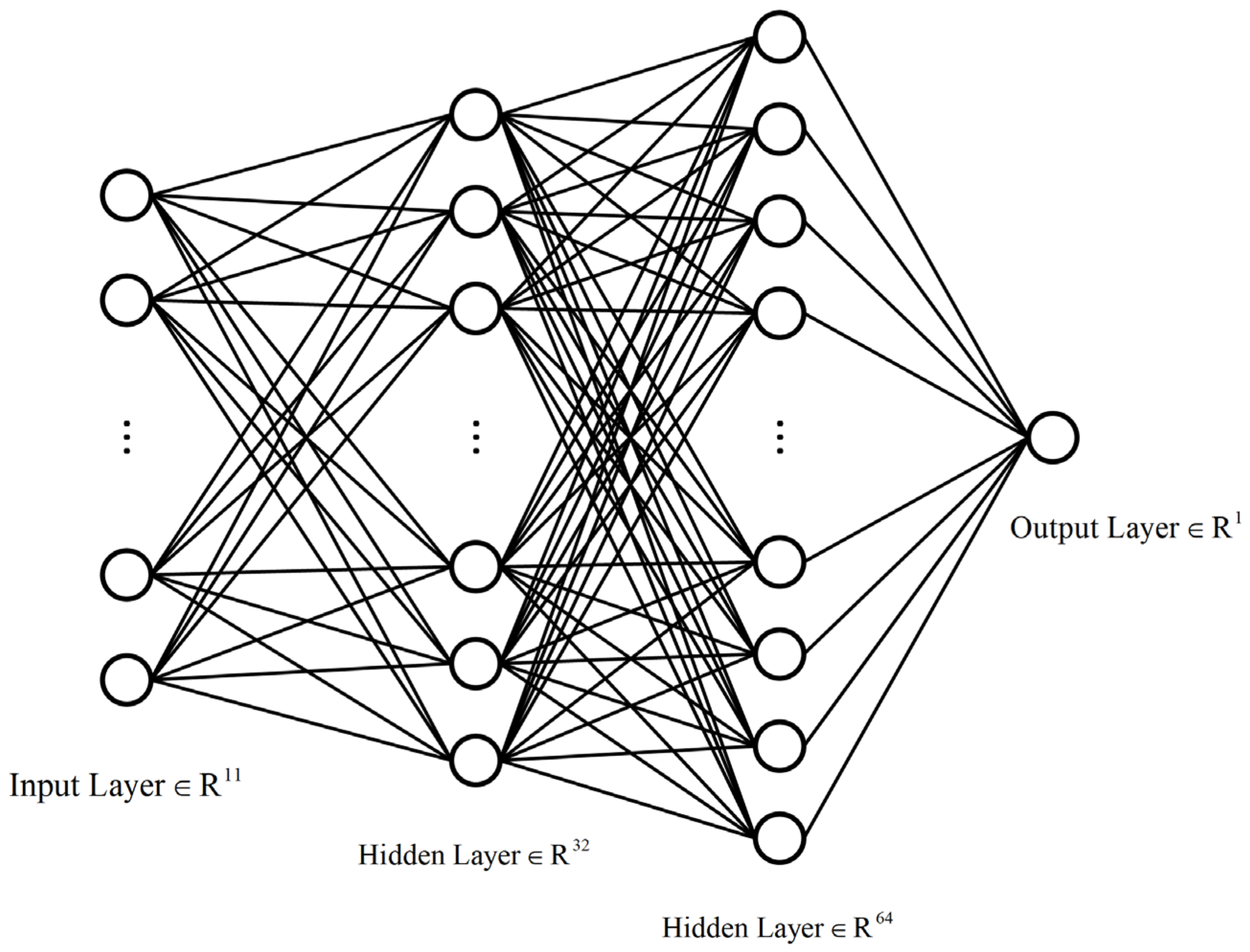
In the process of image learning, 80% of the images from each database were randomly selected for training, and the remaining 20% were used for testing. To ensure fair comparisons, the training–testing process was repeated 1000 times, and the median of the results after 1000 iterations was taken as the final outcome to eliminate performance biases. The indicators for measuring the strengths and weaknesses of the quality evaluation metrics are shown below:
The SROCC metric evaluates the monotonic relationship between the image quality assessment metrics and the subjective evaluation, indicating whether the objective assessment maintains a consistent trend with changes in the subjective evaluation. The SROCC value ranges from −1 to 1, with values closer to 1 or −1 indicating stronger monotonicity.
The PLCC metric assesses the linear correlation between the image quality assessment metrics and the subjective evaluation, with values ranging from −1 to 1. Positive values denote a positive correlation, negative values signify a negative correlation, and 0 indicates no correlation. The closer the absolute value is to one, the more accurate the metric’s evaluation.
The KROCC metric measures the rank correlation between two variables, with values ranging from −1 to 1. A value close to 1 indicates a strong correlation, while a value of 0 implies independence.
The RMSE quantifies the deviation between the image quality assessment metrics and the subjective evaluation, with smaller values indicating higher consistency. An RMSE value approaching 0 signifies the high accuracy of the metrics.
This paper compares nine commonly used FR-IQA metrics, including GMSD, GSM, IFC, MAD, MSSIM, PSNR, SSIM, VIF, and VSI.
Table 4 presents the results of testing these nine common metrics along with the proposed metric on two standard databases. The bolded numbers denote the evaluation metrics with the best performance. Based on the descriptions of the SROCC, PLCC, KROCC, and RMSE, combined with the data in the table, it is evident that the performance of the proposed FFSF metric is superior.
The selection of various regression methods leads to diverse evaluation outcomes. To identify a suitable regression approach for feature fusion, this section conducts a comparison between random forest (RF) and the MLP neural network. As shown in
Table 5, except for the RMSE metric, the results for the remaining three metrics are all superior in the MLP compared to the RF. The results of the SVR are comparatively less favorable. Furthermore, since RMSE ranges from 0 to positive infinity, both methods fall within a similar, small range, indicating comparable performance. In summary, the evaluation metrics obtained through regression using the MLP neural network surpass those obtained using the RF. The bolded numbers denote the evaluation metrics with the best performance.
The study concurrently compared results from the same model using different loss functions. Experiments were conducted using an MLP neural network model with various loss functions, and the findings are summarized in
Table 6, showing that MSE outperforms MAE in terms of results.
To illustrate the consistency between the proposed metrics in this paper and human subjective ratings, scatter plots were generated, as shown in
Figure 17. These plots display the evaluation results of nine commonly used metrics relative to the MOS in the TID2013 database. It is evident that the results obtained from individual evaluation methods exhibit considerable dispersion in the scatter distribution of image MOSs, lacking a clear trend. Further analysis through curve fitting accentuates the inconsistency between subjective and objective assessments. This outcome unequivocally indicates significant disparities between the objective quality assessment results obtained and the subjective ratings. To demonstrate the alignment between the metrics proposed in this study and human subjective ratings, scatter plots were generated, as depicted in
Figure 17. These plots illustrate the evaluation outcomes of nine commonly used metrics relative to the Mean Opinion Score (MOS) in the TID2013 database. The GMSD metric shows poor monotonicity and a weak trend in the fitted curve, indicating varied GMSD scores for the same MOS. GMSD, primarily assessing image gradient magnitude similarity as an objective metric, does not fully encompass subjective image quality perception, which is influenced by factors like color, contrast, and noise. Hence, different GMSD scores may occur for identical MOS values. Similar issues are observed with the IFC metric. In contrast, GSM, MAD, MSSIM, SSIM, VIF, and VSI metrics exhibit relatively better performance, showing more pronounced growth trends in scatter plots and fitted curves. Among them, SSIM performs notably well despite its high data dispersion. Conversely, PSNR performs the least favorably, analyzing images solely from a pixel perspective and neglecting their multidimensional attributes, diverging from real-world conditions. Clearly, individual evaluation methods yield notably dispersed results in MOS scatter plots, lacking definitive trends. Further curve fitting analysis underscores the disparity between subjective and objective assessments, distinctly highlighting substantial differences between objective quality assessment results and subjective ratings.
Compared to other methods, the metrics proposed in this paper demonstrate significant advantages in their evaluation results. As shown in the scatter plot in
Figure 18, the data distribution is more concentrated, and the curve fitting shows a good linear relationship. This result indicates a high level of consistency between the objective evaluation scores of the metrics proposed in this paper and the subjective scores.
Taking the TID2013 dataset as an example,
Figure 19 clearly illustrates the variations in the loss functions of nine popular metrics and the metric proposed in this paper during the training of the MLP neural network.
Table 7 provides detailed convergence values of each loss function. Through comparative analysis, it is evident that although the loss functions of individual evaluation methods can converge, their effectiveness is not satisfactory. This indicates that a single evaluation method is insufficient to fully meet the complex requirements of printing image quality assessment. In contrast, the metrics proposed in this paper demonstrate significant advantages in the performance of the loss function. Not only is the training effect more ideal, but the final convergence values are also superior compared to other metrics.
5. Conclusions
This paper presents an effective and reliable metric for assessing the quality of printed images that closely mimic human visual perception. Compared to mainstream single-dimensional evaluation metrics, the metrics proposed in this paper offer a comprehensive evaluation of printed images from multiple dimensions, significantly improving the accuracy and reliability of the assessment. It combines spatial and frequency domain features, starting with data analysis in the CIELAB color space. In the spatial domain, it extracts color and gradient features, calculates the similarity of different features using similarity measures, and then computes structural similarity. Subsequently, it applies Gabor transform and discrete cosine transform (DCT) to the images, utilizing texture and spatial frequency features as complementary aspects of printed image quality. Multiscale and multi-directional texture features, along with spatial frequency features, are employed for a comprehensive analysis of the frequency domain information of the images, and similarity measures are used to assess similarity at the frequency domain level. Finally, an MLP neural network regression tool is utilized to train a stable model through extensive training, predicting the overall quality scores of the printed images. Extensive experiments on publicly available databases demonstrate that the selected parameters and this method highly conform to subjective perception, exhibiting high consistency with human visual characteristics.
Samples in publicly available databases may lack diversity in certain aspects, as some databases might focus primarily on specific types of prints or particular printing conditions. This limitation could result in inadequate generalization of the results to different types of prints or conditions. Future research should employ more diverse and comprehensive databases to ensure the broader applicability of the findings. Future research directions include enhancing the accuracy and robustness of evaluation models to more comprehensively reflect print quality. One promising avenue is to explore the application of deep learning and reinforcement learning in print quality assessment. For instance, convolutional neural networks (CNN) can be used to extract image features, while reinforcement learning can be employed to optimize the evaluation process. Improving the self-learning and adaptive capabilities of these models will further enhance the efficiency and effectiveness of the assessments.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}