
ADLBiLSTM: A Semantic Generation Algorithm for Multi-Grammar Network Access Control Policies

Abstract
1. Introduction
2. Related Work
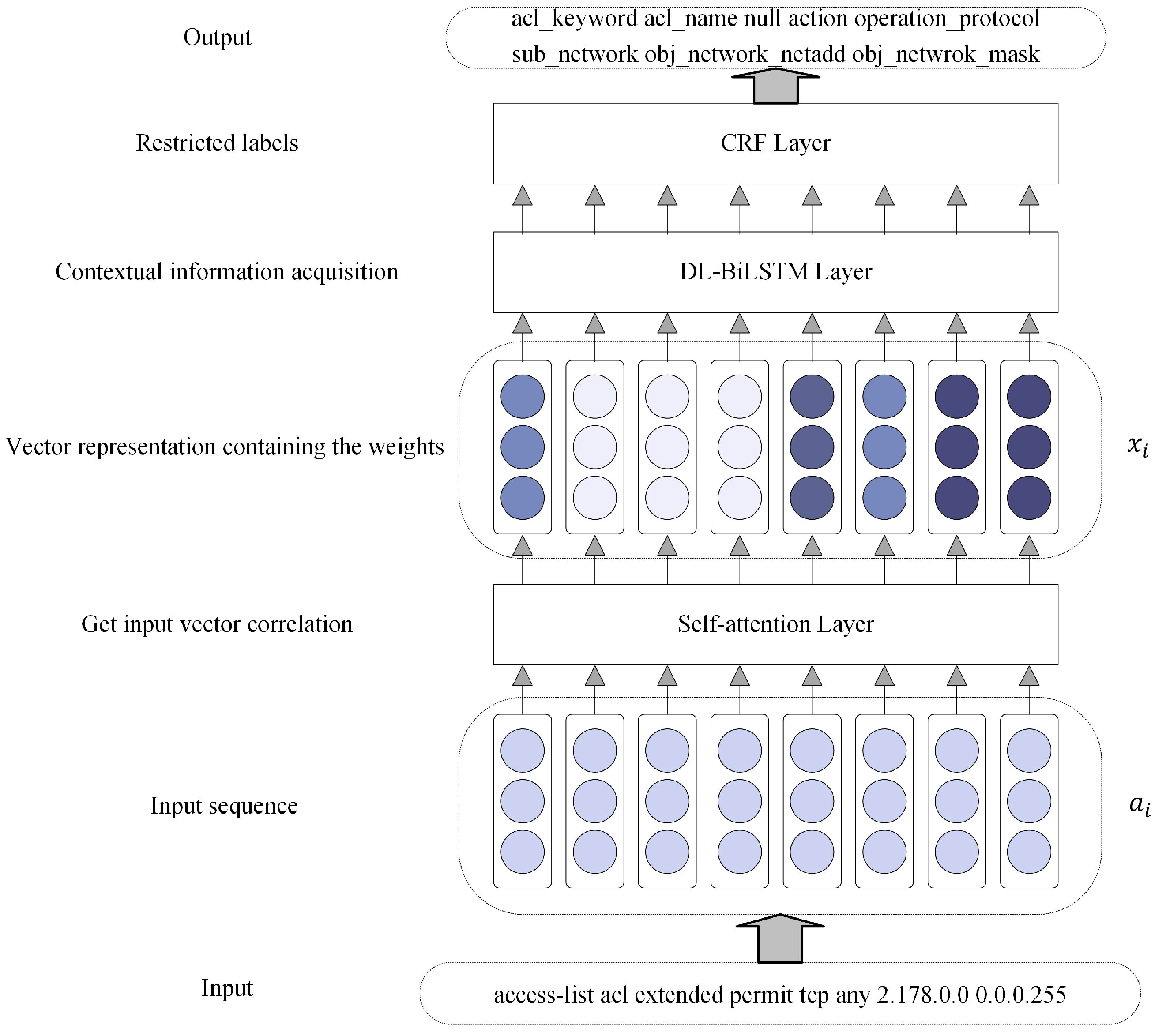
3. The Semantic Generation Algorithm
3.1. Self-Attention Layer
3.2. DL-BiLSTM Layer
3.3. CRF Layer
4. Experiments
4.1. Dataset
4.2. Network Parameters
4.3. Model Structure and Evaluation Metrics
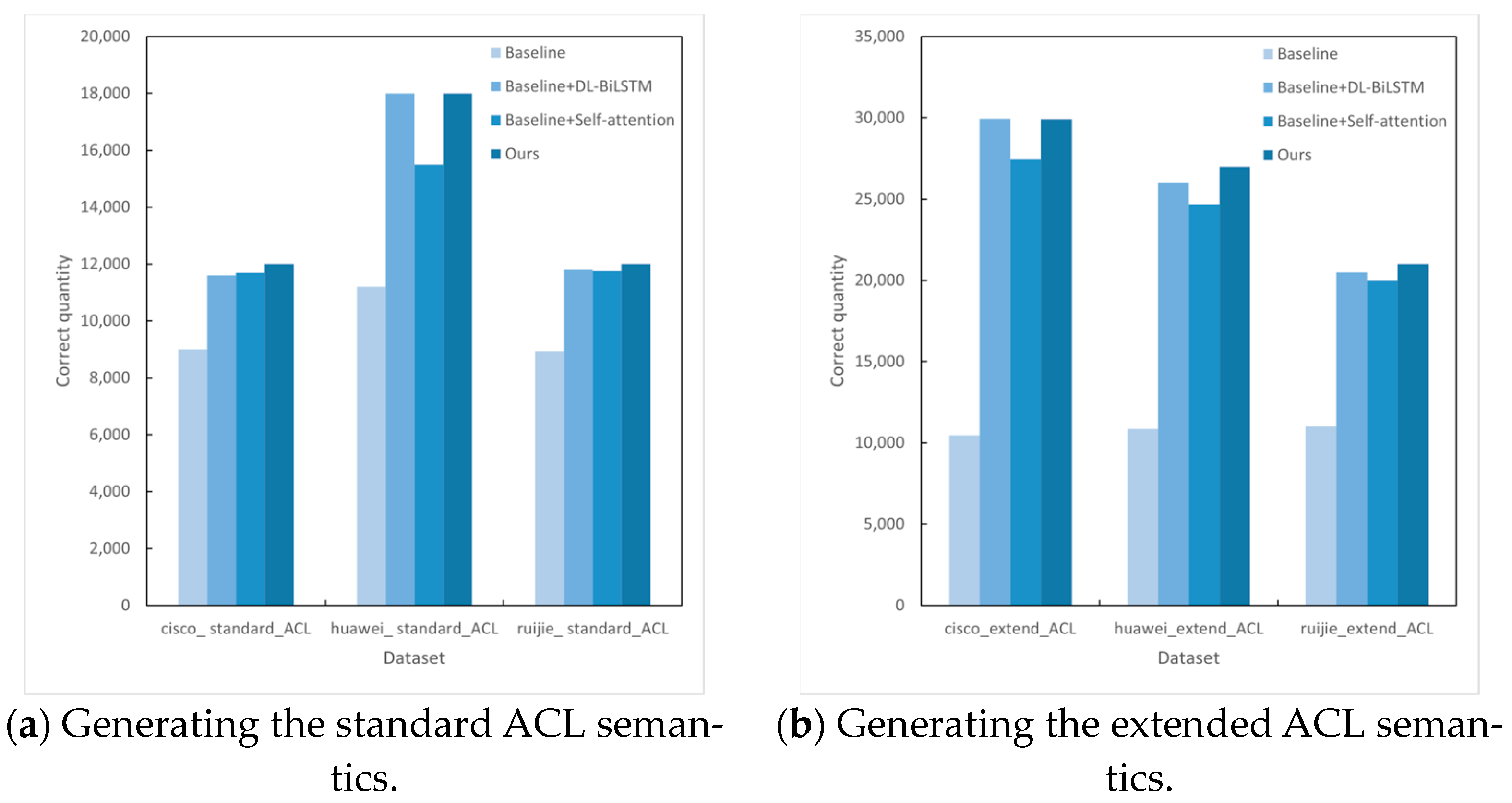
4.4. Semantic Generation for ACLs
4.5. Semantic Generation for Firewalls
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kovacevic, I.; Stengl, B.; Gros, S. Systematic review of automatic translation of high-level security policy into firewall rules. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022. [Google Scholar] [CrossRef]
- Krumay, B.; Klar, J. Readability of Privacy Policies. In Data and Applications Security and Privacy XXXIV, Proceedings of the 34th Annual IFIP WG 11.3 Conference on Data and Applications Security and Privacy (DBSec 2020), Regensburg, Germany, 25–26 June 2020; Lecture Notes in Computer Science; Singhal, A., Vaidya, J., Eds.; Springer: Cham, Switzerland, 2020; Volume 12122. [Google Scholar] [CrossRef]
- Angraini; Alias, R.A.; Okfalisa. Information Security Policy Compliance: Systematic Literature Review. Procedia Comput. Sci. 2019, 161, 1216–1224. [Google Scholar] [CrossRef]
- Ermakova, T.; Krasnova, H.; Fabian, B. Exploring the Impact of Readability of Privacy Policies on Users’ Trust. In Proceedings of the European Conference on Information Systems, Istanbul, Turkey, 12–15 June 2016; Available online: https://api.semanticscholar.org/CorpusID:6072616 (accessed on 15 September 2016).
- Voronkov, A.; Martucci, L.A.; Lindskog, S. Measuring the usability of firewall rule sets. IEEE Access 2020, 8, 27106–27121. [Google Scholar] [CrossRef]
- Arthur, J.K.; Kwadwo, E.; Doh, R.F.; Mantey, E.A. Firewall rule anomaly detection and resolution using particle swarm optimization algorithm. Int. J. Comput. Appl. 2019, 975, 8887. [Google Scholar]
- Liang, X.; Xia, C.; Jiao, J.; Hu, J.; Li, X. Modeling and global conflict analysis of firewall policy. China Commun. 2014, 11, 124–135. [Google Scholar] [CrossRef]
- Al-Shaer, E.; Hamed, H.; Boutaba, R.; Hasan, M. Conflict classification and analysis of distributed firewall policies. IEEE J. Sel. Areas Commun. 2005, 23, 2069–2084. [Google Scholar] [CrossRef]
- Mukhtar, A.S.S.; Mukhtar, G.F.S. Deep learning powered firewall anomaly management environment using convolution and recurrent neural network. Int. J. Res. Biosci. Agric. Technol. 2023, II, 64–66. [Google Scholar]
- Chavanon, C.; Besson, F.; Ninet, T. PfComp: A Verified Compiler for Packet Filtering Leveraging Binary Decision Diagrams. In Proceedings of the 13th ACM SIGPLAN International Conference on Certified Programs and Proofs, London, UK, 15–16 January 2024. [Google Scholar]
- Choudhary, A.R. Policy-based network management. Bell Labs Tech. J. 2004, 9, 19–29. [Google Scholar] [CrossRef]
- Elfaki, A.O.; Aljaedi, A. Deep analysis and detection of firewall anomalies using knowledge graph. In Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods, Lisbon, Portugal, 22–24 February 2023. [Google Scholar]
- Hamilton, A.; Roughan, M.; Nguyen, G.T. Boolean expressions in firewall analysis. arXiv 2022, arXiv:2205.04210. [Google Scholar]
- Liu, A.X. Formal verification of firewall policies. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 1494–1498. [Google Scholar]
- Hamed, H.; Al-Shaer, E.; Marrero, W. Modeling and verification of ipsec and vpn security policies. In Proceedings of the 13th IEEE International Conference on Network Protocols (ICNP’05), Boston, MA, USA, 6–9 November 2005; p. 10. [Google Scholar]
- Heaps, J.; Krishnan, R.; Huang, Y.; Niu, J.; Sandhu, R. Access Control Policy Generation from User Stories Using Machine Learning. In Proceedings of the 35th IFIP Annual Conference on Data and Applications Security and Privacy (DBSec), Calgary, AB, Canada, 19–20 July 2021; pp. 171–188. [Google Scholar]
- Cambria, E.; White, B. Jumping NLP Curves: A Review of Natural Language Processing Research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Arkhangelskaya, E.O.; Nikolenko, S.I. Deep Learning for Natural Language Processing: A Survey. J. Math. Sci. 2023, 273, 533–582. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association (Interspeech 2010), Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014. [Google Scholar] [CrossRef]
- Lin, J.C.-W.; Shao, Y.; Djenouri, Y.; Yun, U. ASRNN: A recurrent neural network with an attention model for sequence labeling. Knowl.-Based Syst. 2021, 212, 106548. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Wang, M.; Zhou, T.; Wang, H.; Zhai, Y.; Dong, X. Chinese power dispatching text entity recognition based on a double-layer BiLSTM and multi-feature fusion. Energy Rep. 2022, 8, 980–987. [Google Scholar] [CrossRef]
- Wu, K.; Wu, J.; Feng, L.; Yang, B.; Liang, R.; Yang, S.; Zhao, R. An attention-based CNN-LSTM-BiLSTM model for short-term electric load forecasting in integrated energy system. Int. Trans. Electr. Energy Syst. 2020, 31, e12637. [Google Scholar] [CrossRef]
- Zhangjing, Data. 2024. Available online: https://gitee.com/ainer4869/data/tree/master/ (accessed on 25 April 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ACL | Firewall | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Standard_ACL | Extend_ACL | Data_Mix | Firewall_Test | Firewall_Train | ||||||
| Num | Labels | Num | Labels | Num | Labels | Num | Labels | Num | Labels | |
| Huawei | 3000 | 6 | 3000 | 9 | 3437 | 13 | 2000 | 10 | 668 | 10 |
| Cisco | 3000 | 4 | 3000 | 10 | ||||||
| Ruijie | 3000 | 4 | 3000 | 7 | ||||||
| Type | Example | Label |
|---|---|---|
| cisco_standard_ACL | access-list 1 deny 10.64.0.0 | keyword id action source_network |
| huawei_standard_ACL | rule 1 deny source 14.45.178.0 255.255.255.192 | keyword id action keyword sub_network_netadd sub_network_mask |
| ruijie_standard_ACL | 1 permit 10.92.96.0 0.0.31.255 | id action obj_network_netadd obj_network_mask |
| cisco_extend_ACL | access-list aaa extended deny udp any 172.22.118.248 192.168.0.0 | keyword id null action operation_protocol sub_network obj_network_netadd obj_network_mask |
| huawei_extend_ACL | rule 1 deny tcp destination 178.23.144.0 0.0.7.255 mrdkp 99483 | keyword id action operation_protocol keyword dest_host_ip dest_host_ip_mask port_operaor port_name |
| ruijie_extend_ACL | 1 permit udp host 10.176.0.0 host 192.168.0.0 | id action operation_protocol keyword sub_network_netadd keyword obj_network_netadd |
| Firewall_test | defaddr add 1 10.92.96.0 255.255.255.255 | define operation id sub_network_netadd sub_network_mask |
| defaddrgrp addmbr first 540 | define operation id id |
| Network Structure | Name |
|---|---|
| BiLSTM + CRF | Baseline |
| Double-layer BiLSTM + CRF | Baseline + DL-BiLSTM |
| Self-attention + BiLSTM + CRF | Baseline + Self-attention |
| Self-attention+ double-layer BiLSTM + CRF | Ours |
| Dataset | Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| cisco_standard_ACL | Baseline | 74.96 | 76.15 | 75.53 |
| Baseline + DL-BiLSTM | 99.99 | 99.99 | 99.99 | |
| Baseline + Self-attention | 99.9 | 99.9 | 99.9 | |
| Ours | 100 | 100 | 100 | |
| huawei_standard_ACL | Baseline | 62.37 | 75.47 | 68.24 |
| Baseline + DL-BiLSTM | 100 | 100 | 100 | |
| Baseline + Self-attention | 86.59 | 86.59 | 86.59 | |
| Ours | 100 | 100 | 100 | |
| ruijie_standard_ACL | Baseline | 74.44 | 75.58 | 75.0 |
| Baseline + DL-BiLSTM | 99.99 | 99.99 | 99.99 | |
| Baseline + Self-attention | 99.42 | 99.42 | 99.42 | |
| Ours | 100 | 100 | 100 |
| Dataset | Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| cisco_extend_ACL | Baseline | 34.92 | 45.99 | 39.48 |
| Baseline + DL-BiLSTM | 99.8 | 99.8 | 99.8 | |
| Baseline + Self-attention | 91.51 | 91.31 | 91.31 | |
| Ours | 99.74 | 99.74 | 99.74 | |
| huawei_extend_ACL | Baseline | 40.31 | 45.65 | 42.53 |
| Baseline + DL-BiLSTM | 97.68 | 97.68 | 97.68 | |
| Baseline + Self-attention | 91.41 | 89.75 | 86.26 | |
| Ours | 100 | 100 | 100 | |
| ruijie_extend_ACL | Baseline | 52.58 | 58.96 | 55.56 |
| Baseline + DL-BiLSTM | 98.99 | 98.89 | 98.93 | |
| Baseline + Self-attention | 95.3 | 95.24 | 95.14 | |
| Ours | 100 | 100 | 100 |
| Dataset | Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| Firewall_test | Baseline | 64.74 | 68.4 | 66.51 |
| Baseline + DL-BiLSTM | 89.76 | 91.53 | 90.63 | |
| Baseline + Self-attention | 94.54 | 94.54 | 94.54 | |
| Ours | 96.09 | 96.18 | 96.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liang, X. ADLBiLSTM: A Semantic Generation Algorithm for Multi-Grammar Network Access Control Policies. Appl. Sci. 2024, 14, 4555. https://doi.org/10.3390/app14114555
Zhang J, Liang X. ADLBiLSTM: A Semantic Generation Algorithm for Multi-Grammar Network Access Control Policies. Applied Sciences. 2024; 14(11):4555. https://doi.org/10.3390/app14114555
Chicago/Turabian StyleZhang, Jing, and Xiaoyan Liang. 2024. "ADLBiLSTM: A Semantic Generation Algorithm for Multi-Grammar Network Access Control Policies" Applied Sciences 14, no. 11: 4555. https://doi.org/10.3390/app14114555
APA StyleZhang, J., & Liang, X. (2024). ADLBiLSTM: A Semantic Generation Algorithm for Multi-Grammar Network Access Control Policies. Applied Sciences, 14(11), 4555. https://doi.org/10.3390/app14114555