1. Introduction
Deep learning-based recommendation systems usually take data related to various kinds of users or items as model input, represent the hidden mapping relationship between the users and items, and generate the recommendation results. Three models named Generalized Matrix Factorization (GMF), Multilayer Perceptron (MLP), and Neural Matrix Factorization (NeuMF) are proposed [
1]. One of the most common forms for constructing deep learning recommendation is MLP [
2]. By increasing the number of layers and complexity of the deep neural network structure, Autoencoder is proposed [
3]. Neural collaborative filtering (NCF) [
4] has evolved through a rich feature crossover mode. In NCF, the simple inner product operations in the matrix decomposition have been dropped, more nonlinear features are introduced, which improves the learning ability of the sparse features. In addition, the deep interest network [
5], as well as the deep interest evolution network [
6], and the dynamic path selection multi-interest network [
7] using the capsule network to extract the diverse interests of users all represent the current optimal deep learning recommendation model.
Federated learning is a distributed machine learning environment. Under the coordination of central servers, multiple entities (clients) collaborate to complete the learning problems. Each client’s raw data are stored locally, not exchanged or transmitted, and only in the aggregated update model. With the public attention on personal data privacy, it becomes increasingly important how the recommendation system to seek the optimal solution between personalization and privacy protection and data perturbation technology have been widely used in recommendation. Dwork [
8] has proposed differential privacy (DP, including local DP and global DP) by adding Laplacian noise, which is used for the collaborative filtering algorithm. A localized DP-based perturbations on federated recommendation is proposed recently [
9]. The traditional recommendation system is designed to protect the privacy of individual users by preventing the leakage of their original data and by encrypting the transmission of recommended original inputs. The federated recommendation system employs encryption of the gradient update of the recommendation model to safeguard privacy [
10]. It also avoids the significant computational overhead of directly training the global model on the original data cipheric domain. Furthermore, it effectively reduces the numerous privacy risks associated with data aggregation in traditional machine learning sources. The current federal recommendation system is still afflicted by two significant shortcomings: firstly, the addition of LDP has resulted in a reduction in the accuracy of recommendations, and secondly, the incorporation of Laplace noise has led to an increase in communication overhead [
10].
Locality sensitive hash (LSH) is an approximate nearest neighbor (ANN) search and mapping technique. The locality hashing technique is employed to protect the client-uploaded model parameters throughout the training process of federated learning. The LSH primarily safeguards the local parameters of the model, which comprise sensitive information from the user. By hashing these local parameters, namely converting them to hash values, it is possible to ensure that when uploaded to the central server, even if the parameters are intercepted or leaked, the user-specific information cannot be directly obtained due to the unidirectional nature of the hash function. Consequently, LSH can safeguard user privacy and model security, even when federated learning clients are not deemed trustworthy or at risk.
This paper presents three joint locality sensitive hashing (LSH) models combined with recommendation systems: GMF, MLP, and NeuMF. The LSH-enhanced federated learning model is the result of this combination. Firstly, the participation weight of the model is determined according to the participation degree of joint learning customers, with the objective of improving the efficiency of joint learning. Secondly, the local parameters of the joint aggregation model are divided into two groups in order to protect the user embedding. Finally, rapid mapping and similarity retrieval of the upload parameters are performed using LSH in order to protect user privacy and to reduce the training time.
2. Related Works
2.1. Neural Cooperative Filtering and Differential Privacy
Deep neural networks are widely used to represent the relationship between the mapping functions and the hidden factor of users and items. Three models named Generalized Matrix Factorization (GMF), Multilayer Perceptron (MLP), and Neural Matrix Factorization (NeuMF) are proposed, in which, GMF can learn the linear characteristics in the recommendation model, while MLP excels at getting more detailed and nonlinear characteristics. Neural network-based collaborative filtering (NCF) utilizes implicit feedback, meaning the historical interaction of users with the items. This approach avoids revealing user rating, but the historical interaction records of users are necessary during training. The deep interest network (DIN) [
5] is evolved by importing the attention layer between the embedded layer and the perceptron layer. The deep interest evolution network (DIEN) [
6] incorporates sequential models to simulate the evolution of users’ preferences. In contrast, capsule networks are explored to extract users’ diverse interests, and label-based attention mechanisms are also proposed in multi-interest network with dynamic routing (MIND) [
7].
The parameters of the federated recommender system models are encrypted by privacy protection methods during the gradient updates [
10]. It is unnecessary to exchange local parameters of different recommendation services respectively and to train the global model directly in plain text, which effectively reduces the privacy risks during the aggregation process. During the aggregation of federated learning, users’ information can also be restored based on model parameters or gradient information. Orekondy [
10] and Wang proposed that simple federated learning without privacy-preserving mechanisms still suffers from gradient information attacks, which can leak private information. To avoid this kind of attack, differential privacy (DP) is combined into the model via adding noise [
11]. The DPGAN framework proposed by Xu [
12] makes use of DP to invalidate GAN-based attacks when inferring the training data of users in deep learning networks. McSherry [
13] proposed improved collaborative filtering algorithms applying DP and obtained a blinded item–item covariance matrix by adding Laplace noise to count and sum up the user rating data. And K-Nearest Neighbor (KNN) and Singular Value Decomposition (SVD) algorithms have been implemented based on the above scheme. The DPFedAvgGAN [
14] framework also has been proposed in federated learning. The input layer data of the model are divided into two parts, the matrix factorization (MF) and the multi-layer perceptron (MLP). In the MF part, the input users’ data and items’ data are mapped into the user hidden vectors and item hidden vectors. In the MLP part, the input user data and item data also do the same mapping. The MF part and the MLP parts share the same embedding layer and learn the embedding layers separately with two different models providing better flexibility.
2.2. Neural Cooperative Filtering Framework and Process
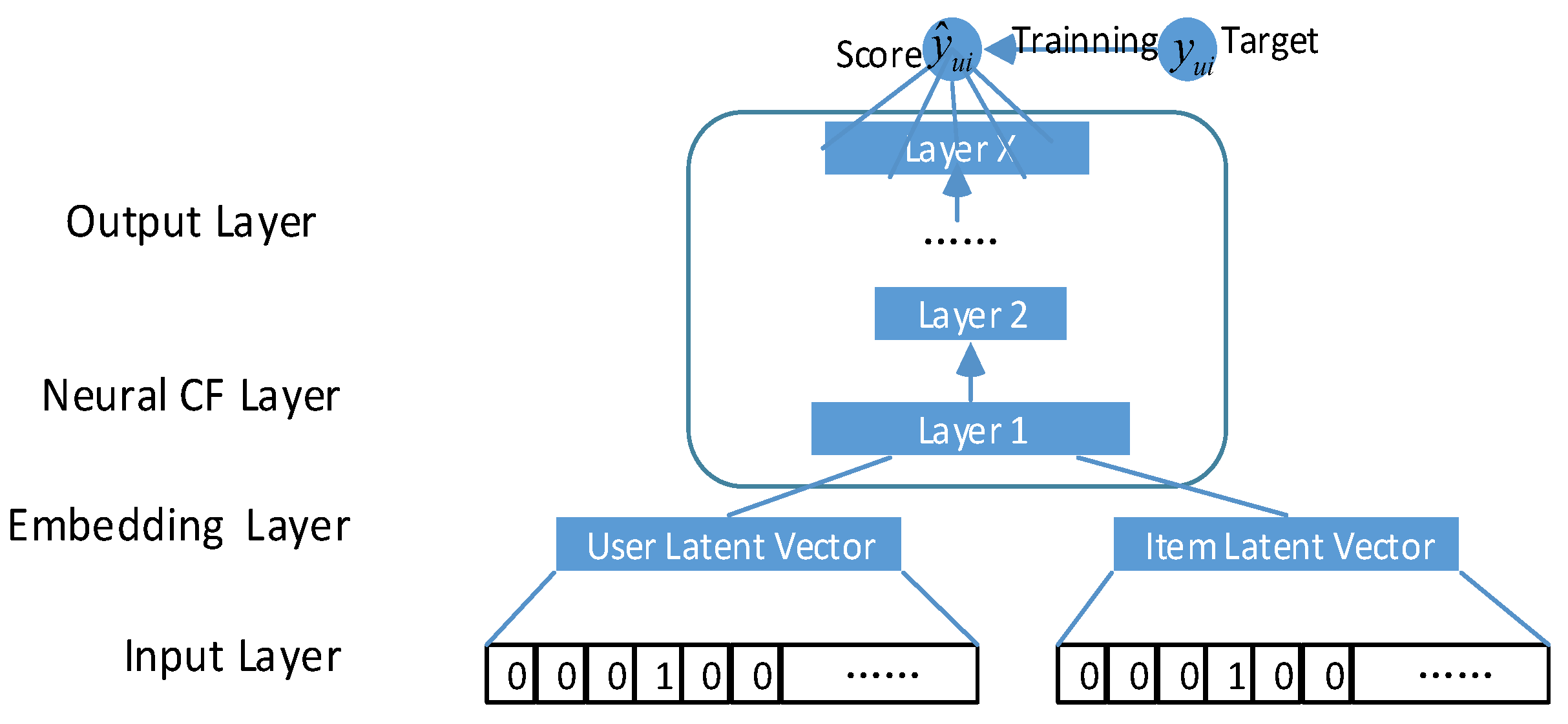
The overall framework of the NCF is shown in
Figure 1; the first layer of the model accepts two inputs, namely, the user input layer and the item input layer.
The input layers require only binary labelling (0 or 1) to reflect the historical interaction of users and items. Therefore, one-hot encoding is sufficient. The user and item embedding layer is the second layer.
The input layer is mapped to the embedding layer to generate hidden vectors for both the user and item. These vectors are then used as inputs to the NCF network, resulting in a prediction score. The model recommendation effect is determined by the dimension and number of the network layers. The NCF model can be formulated as follows:
where
represents the
i-th layer in the NCF, with a total layers of X;
represents the output layer.
P and
Q are the user embedding layer parameters and the item embedding layer parameters, respectively.
and
represent the user input vectors and the item input vectors after one-hot encoding, respectively. The model uses cross-entropy as a loss function, as follows:
where
represents the historical interaction results of user
u for item
i; if user
u has a scoring record for item
i in the dataset,
is equal to 1, otherwise it is 0. The loss function can obtain the optimal results through random gradient descent or the Adam algorithm. In the training process, a positive sample is created using the interaction record between the user and the item, labeled as 1. If there is no historical interaction between the user and the item, it is considered a negative sample and labeled as 0.
Horizontal federated learning is used in NCF to aggregate user privacy data on distributed sides and integrate the model on the server side. A round of federated learning training includes four steps: (1) model initialization, where a model and various parameters are initialized by the central server and sent to each client; (2) local model training, where all online clients train the model delivered by the server on their own local dataset; (3) model aggregation, where after each client has finished their training and uploading, the central server aggregates the model based on the level of client involvement; (4) model update, where the central server distributes the aggregated model to each client, updates the client’s model, and then repeats step 2. The formal performance is shown in Equation (3).
where
is the local loss function for the
i-th client; usually,
is set by local experience;
is the aggregation weight of the model for the
i-th client.
2.3. Introduction of Locality Sensitive Hashing (LSH)
LSH is a randomization algorithm for the nearest neighbour problem, which is significantly faster than the other existing methods, especially in high-dimensional space. It uses the hash method to hash the data from the original space into a new space, so that similar data in the original spacehave a large probability in the new space, while dissimilar data in the original space have a small probability of being similar in the new space.
The basic idea of LSH is the following:
To randomly select the hash function from the family of LSH functions and hash each data point into the hash table;
When finding the nearest neighbor, LSH only scans the points with the same hash index as the query point.
Definition and Algorithmic Process are as follows:
Definition 1. For r1 ≤ r2 and p2 ≤ p1, a hash family H is (r1, r2, p1, p2)-sensitive if for all x,y ∈ Sd−1.
If the hash collision probability of a point that is close is greater than that of a point that is far away, it is a locality sensitive hash, that is, t The hash function is sensitive to the distance between data points, locally close points can be hashed into a bucket as much as possible. According to the above definition, two points are considered close if the distance is not greater than ; if the minimum distance is (c > 1), c is the distance coefficient between the farand near points.
The quality of the hash function is defined by two key parameters: represents the hash conflict probability of proximity points, while represents the hash conflict probability of distance points. The difference between these two probabilities determines the sensitivity of the hash function to distance in changes and can usually be expressed as a function of the distance gap.
3. NCF Federated Recommendation Based on DP Results
3.1. NCF Recommendations Based on Federated Learning
The NCF recommendation system based on federated learning can pre-train GMF and MLP to obtain the NeuMF model, that is, the trained GMF and MLP can be applied to initialize and train NeuMF. Firstly, GMF and MLP are randomly initialized. Subsequently, the two models are trained by using idle online clients to acquire the client model parameters. Lastly, the models are merged and submitted to the central server; the connection between the two parts can be established using the following formula:
where
h represents the parameters of the NCF,
represents the parameters of the GMF part, and
represents the parameters of the MLP part.
is the proportion of the parameters of the GMF part in the final NeuMF model.
3.2. Model Weight Setting Based on Participation
In the parameter aggregation of the federated recommendation system, the weight of the model parameters uploaded by all clients is equal. However the quality of the uploaded models varies due to the randomness of the federated learning training parameters. The quality of client-side data, the level of participation in federated learning, user hardware equipment, and other factors can impact the quality of the aggregated model. To enhance the recommendation effect, it becomes necessary to elevate the weight of the optimal model and diminish the weight of other models. In each round of federated learning, a portion of users is randomly selected as samples to participate in the training. Due to the random nature of the training process, some clients have participated in multiple rounds of training while others have only recently started. Consequently, models with low engagement are likely to underfit their own data. Therefore, during the aggregation stage of federated learning, weight parameters can be assigned to the model uploaded by the client based on their level of training participation. The core idea of the model weight setting based on participation is to adjust the weight of each client by recording the participation number . Then, the function is explored to determine the weight value. The specific process is as follows:
The recommendation system server initializes the participation number of the client side;
Calculates the aggregate weight wi = f(xi) of each client and saves it on the server side;
The participation number of all clients in this round is increased once, .
The recommendation system recalculates the aggregation weights according to the participation number and updates the weights on the server side.
The choice of function determines the convergence effect of this federated learning algorithm, and a better function is conducive to the training of the federated recommendation model; conversely, a poorer function may hinder the training process. In this paper, a simple liner function is conducive to speeding up the training of the federated recommendation model; the specific formula is as follows:
where
is the threshold of the weight to prevent excessive growth of a user’s weight. According to Formula (5), the clients’ aggregation weights are linearly positively correlated with the number of users participating in federated training. In other words, the more times a user participates, the greater the weight. Once the weight reaches the threshold
, it is set to
and remains constant.
3.3. Local Parameter NCF Recommendation
In order to prevent getting the user’s rating or other data from the historical interaction by back propagation attacks, a local parameter training method is proposed for NCF federated recommendation. This is as shown in Equation (6):
where
is the local optimization target for user
i;
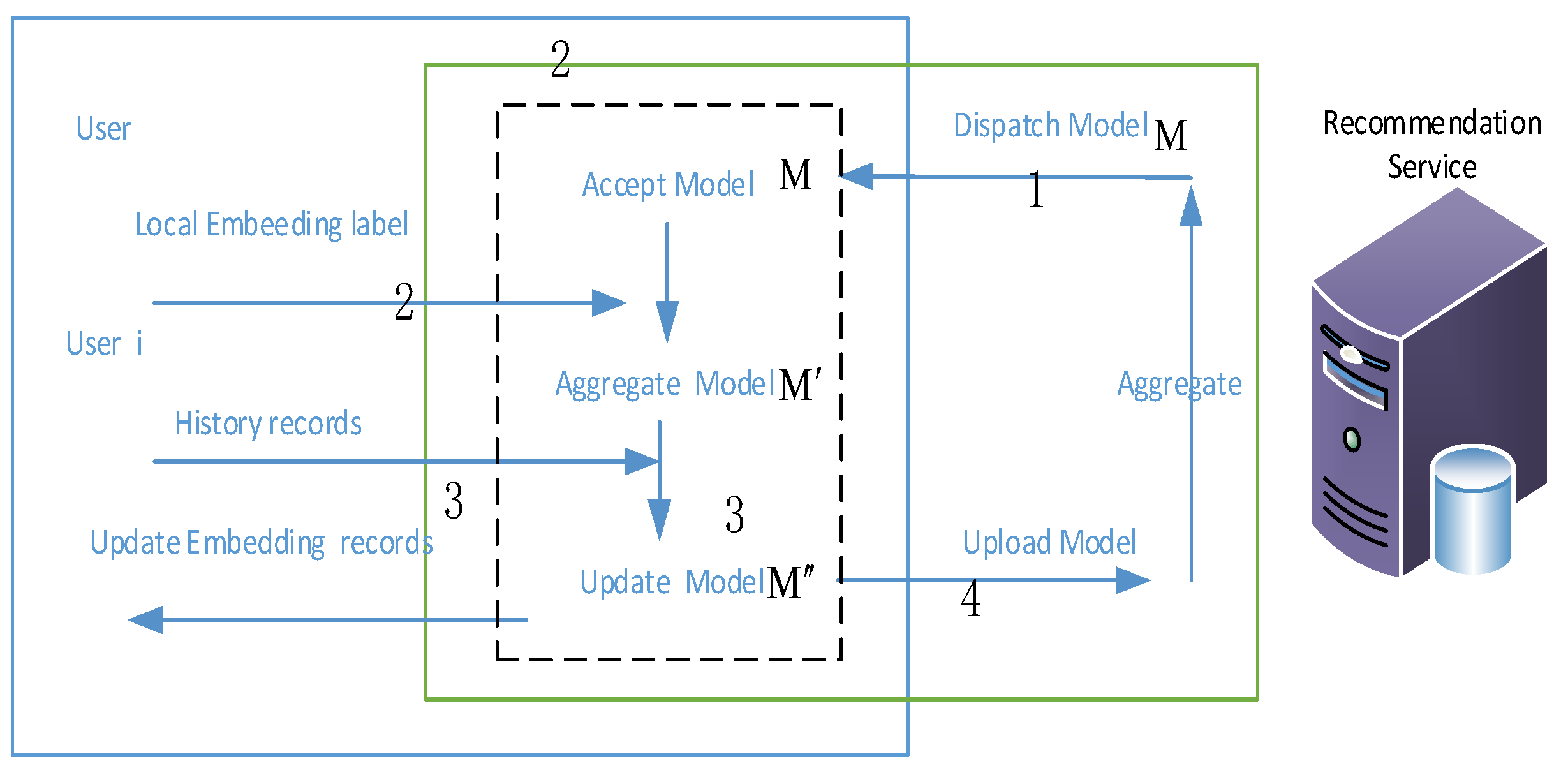
x is the vector of model parameters with dimension d; and p is the probability distribution for the clients. Some parameters in this model are stored locally, not transmitted, and do not participate in the aggregation process of federated learning. These parameters are referred to as the local parameters of the federated learning. In the NCF model, the embedding layer maps the user ID and the item ID to the hidden layer using one-hot encoding. Therefore, its parameters can be considered as local parameters that do not participate in the aggregation and the issue process of the federated learning. Each user’s or item’s ID is independent during both the training and prediction processes. Only the correct user hidden feature vector is required as input. As a result, the user embedding layer can serve as a local model parameter, saved and updated locally on each client. The training process is shown in
Figure 2 below:
As depicted in
Figure 3, the process unfolds as follows: firstly, the recommendation system server dispatches the initialized NeuMF model
, excluding the embedding layer, to each online client. Secondly, each client initializes its own embedding layer and combines model
into a complete recommendation model
. Thirdly, the newly trained model
is obtained by training local data on the client side based on
, and the embedding layer parameters of
will be replaced by those of the model
. Fourthly, the model
excluding the user embedding layer is uploaded to the recommendation system server. Finally, the recommendation system server aggregates the uploaded parameters according to each client’s weight.
In this local parameter NCF federated recommendation, the local model needs to be updated, and the model issued by the recommendation system server does not contain the user embedding layer. After updating and merging with the embedding layer, the model has been evolved into the model . The local parameter NCF federated recommendation reduces the transmission or communication cost, but improves the data privacy.
3.4. NCF Federated Recommendation with DP
To further prevent the attacks on the uploaded model, the algorithm uses the Laplace mechanism in DP to safeguard the model’s parameters during the federated learning. In the Laplace mechanism, the noise size is , where f is the sensitivity, and can gauge the level of privacy protection. The Laplace machine satisfies -differential privacy; with smaller , the greater the noise and the higher the security of the data. Given that the sensitivity impacts the effect of the parameters in Laplace mechanism, the model incorporates two schemes, namely, overall sensitivity and hierarchical sensitivity. There is no requirement to safeguard the embedding layer and local parameters in the NCF recommendation within the privacy schemes for these two sensitivities, as these parameters are not uploaded.
Stratified Sensitivity Scheme
The models uploaded contain different datasets according to different layers and calculate f in Laplace noise respectively.
where
and
correspond to the
i-th layer of the model, adding noise of size
to the
i-th layer. In contrast to the overall sensitivity scheme, the stratified sensitivity scheme takes into account the distinction of each layer’s parameters, resulting in the addition of relatively less noise to individual layers. This scheme can achieve equivalent privacy protection, and introducing varying levels of noise to different layers provides greater flexibility and enhances training effectiveness.
3.5. LSH Models in Federated Recommendation
To improve the efficiency and level of privacy protection, we recommend combining NCF with LSH. The NCF can be used to make personalized recommendations. Meanwhile, LSH can be used to accelerate the approximate nearest neighbor search, thereby reducing the computational complexity of the recommendation system and improving the efficiency of the recommendation.
The specific implementation method is as follows:
The NCF model is used to represent the data: first, the data are analyzed using the neural network model. These represent the complex relationships therein, thereby improving the accuracy of the recommendations.
Accelerate nearest neighbor search with LSH: LSH hash the resulting data processed, mapping similar users and items to the same hash bucket. In the recommendation process, only the users or items in the same hash bucket need to be considered, thus reducing the size of the candidate set and improving the recommendation efficiency.
Protecting user privacy: In federated learning, use local hash technology to protect the model parameters uploaded by clients. By hashing the local parameters of the model, we ensure that even if the parameters are intercepted or leaked, the user’s specific information cannot be directly obtained, so as to protect the user’s privacy.
Comparative differential privacy techniques: Local hash techniques may be more suitable to solve communication costs and privacy issues than the differential privacy technologies using Laplace noise. Partial hashing technology can reduce traffic, reduce communication costs, and provide stronger privacy protection.
By combining NCF with LSH and adopting local hashing technology to protect user privacy, we can improve the efficiency and privacy protection level of the recommendation system at the same time, so as to provide a better recommendation experience for users’ hash family of functions.
4. Comparative Analysis of Experiment
This paper utilizes the MovieLens 1M dataset, compiled by the GroupLens team at the University of Minnesota, to gather users’ movie ratings without collecting personal information. The MovieLens 1M dataset consists of rating data from one million users for movies, with each user providing ratings for a minimum of 20 movies on a scale of 1 to 5. The data processing procedure involves the following steps: firstly, 90% of the data are randomly allocated as the training set, while the remaining 10% are assigned to the test set. Secondly, the NCF model handles implicit interactions and does not require explicit ratings. Therefore, all ratings in the MovieLens dataset are standardized to 1 as labels to indicate user interaction with or rating of those movies. Moreover, for the training set, unrated data points are chosen, assuming that the user has not seen the movie, and are assigned a value of 0. These two sets of data are then combined to form the training set, while the remaining unrated data are used to create the test set.
4.1. Evaluation Metrics
For the traditional Matrix Factorization (MF) model, the Root Mean Square Error (
RMSE) is used as the evaluation index, and the smaller the
RMSE, the more accurate the prediction result. The
RMSE is as follows:
where |
R| denotes the number of valid ratings in the dataset.
For the NCF model, the prediction output is a list of recommended rankings. This paper employs Leave-One-Out Cross-Validation (LOOCV) as the evaluation metric. The rankings are determined based on the ratings, and these rankings are then used to calculate the Hit Rate (HR) for positive samples. For instance, with a Top-K value of 10, the top ten recommendations are examined to identify the presence of positive samples. If a positive sample is found, it is considered a hit; otherwise, it is classified as a miss. A higher HR value indicates a more accurate recommendation performance. Additionally, based on the ranking outcomes, the Normalized Discounted Cumulative Gain (
NDCG) is computed to assess the predictive effectiveness. A higher
NDCG value signifies an enhanced recommendation performance. The
NDCG is as follows:
where
k represents the number of top
k;
is the normalization parameter.
The
score is the harmonic average of
Precision and
Recall, and it is particularly useful in binary classification problems. When the positive and negative sample categories in the dataset are not balanced, the
score can evaluate the model performance more comprehensively, because it considers the effects of both false positive (False Positives,
FP) and false negative (False Negatives,
FN). The
score is calculated as follows:
where
Precision represents the proportion of all samples predicted to be positive, using the formula
.
Recall represents the proportion of all samples that are actually positive, according to the formula
.
TP is the number of true cases, the number the model correctly predicts as a positive class.
scores range from 0 to 1, with higher values indicating better performance of the model. When the score approaches 1, the representation model achieves a good balance between Precision and Recall.
4.2. The Influence of Federated Learning on Traditional Matrix Decomposition
Federated learning was separately incorporated into the traditional matrix decomposition model, MLP, GMF, and NeuMF, and the hidden vector dimension was set to 8. The federated matrix factorization model and the traditional models are compared. Each round of federated learning involved five participating samples, and the RMSE was used to evaluate the recommendation performance. The experimental results are shown in
Table 1 below:
The results show that the RMSE of matrix factorization (MF) and other models increases after using federated learning, which implies a decrease in recommendation performance. Essentially, all the models sacrifice the validity of the recommendation in the context of federated learning, highlighting the trade-off between data privacy and accurate recommendation. Maintaining precise recommendations while protecting data privacy becomes very difficult. At the same time, the RMSE values of mlp, gmf, and neumf are less than the matrix factorization model, indicating that their recommended effect is better than that of matrix factorization.
4.3. NCF Federated Recommendation
The NCF federated recommendation framework comprises three models: GMF, MLP, and NeuMF. The ratio of negative samples to positive samples in the training sets of these models is 4:1, with K set to 10 for top-K evaluation. In the GMF model, user and item embedding layers are mapped to hidden vectors of length 8 using one-hot encoding. For the MLP model, the hidden vector length is also eight, incorporating a hidden perceptron layer with a dimension of 10. In the NeuMF model, embedding layers of length 8 are established in both the MLP and GMF parts. Additionally, a hidden layer is introduced in the GMF component. NeuMF integrates these two parts and employs federated learning. Each round of federated learning involves five participating users, and the experimental results are detailed in
Table 2:
The results indicate that while federated learning offers some level of data privacy protection, it significantly diminishes the recommendation accuracy of the GMF and NeuMF models. On the other hand, the recommendation accuracy of the MLP model with a single hidden layer remains relatively stable, demostrates minimal impact from federated learning.
4.4. The Choice of Sample Number
In the context of the NCF federated recommendation framework, the choice of sample number plays a crucial role in the speed of federated learning. The experiment results showing in
Table 3 involves traditional MF federated recommendation with varying sample numbers randomly selected for each round of federated learning. As the number of samples per round increases, the duration of each round also lengthens, leading to potential delays in client model uploads in real-world scenarios. To address this, the product of the sample number per round and the number of federated learning training rounds are kept constant to maintain consistency in the total number of samples used for training.
The experimental findings demonstrate that, with a consistent total dataset size for training, lower sample numbers per round correspond to reduced RMSE values and improved recommendation accuracy. While fewer samples enhance accuracy, they also increase communication frequency between clients and the server in practical applications. Therefore, in a federated recommendation model, striking a balance between communication costs and recommendation effectiveness is essential. Opting for a smaller sample size in a conducive communication environment can enhance recommendation accuracy.
4.5. Weight Setting Based on Participation
This experiment validates the model weighting algorithm based on participation. In
Figure 3, the ablation experiment utilized a traditional MF model with a hidden vector dimension of eight and five samples per round. For the selection of
, when Equation (5) is chosen, the federated recommendation based on participation performs worse than that of the random parameter, resulting in a higher RMSE after 100 iterations. This indicates a decrease in recommendation accuracy, suggesting that the weight setting function hampers federated learning. On the other hand, when Formula (6) is utilized, the federated recommendation based on participation improves, achieving the lowest RMSE after 100 iterations. In conclusion, Formula (6) represents a weight setting algorithm that enhances federated recommendation.
4.6. Local Parameter NCF Recommendation
In this experiment, GMF, MLP, and NeuMF are individually trained using local parameters in federated learning. The ratio of negative to positive training samples for all three models is set at 4:1, with a value of K set to 10. The model incorporates a hidden vector layer of length 8, while the MLP component includes a hidden layer with a dimensionality of 10. Each round involves the participation of five entities. The experiment compares the HR and NDCG metrics across different models, and the results are presented in
Table 4.
The results indicate a decrease in the recommendation effectiveness of the local parameter NCF federated recommendation. Specifically, the embedding layer, serving as the local parameter, exhibits some adverse effects. However, the decrease in the recommendation effectiveness of MLP is less pronounced, suggesting that the local parameter scheme has a relatively minor impact on MLP.
4.7. NCF Federated Recommendation with DP
Experiments were conducted on NCF federated recommendation with DP, employing overall and stratified sensitivity schemes with various parameters. The federated recommendation performance of three models (GMF, MLP, and NeuMF) was compared under different levels of noise.
The ratio of negative to positive training samples for all three models was set to 4:1, with a value of K equal to 10. Each model utilized a hidden vector layer of length 8, and the MLP component included a hidden layer with a dimensionality of 10. Five participants were involved in each round. In this experiment, we explored the joint recommendation performance of the NCF model with different differential privacy (DP) parameters. The experiments involved three models, GMF, MLP, and NeuMF, and Laplace noise was introduced to achieve DP. We recorded the HR, NDCG, and F1 scores under different DP parameters ε. The following results in
Table 5 is a summary of the experimental data.
The results indicate that the three NCF models under the overall sensitivity scheme can maintain a certain level of recommendation accuracy only when ε is large, such as setting ε to 60. At small ε, the recommendation accuracy is far below the requirements. However, as ε increases, the HR, NDCG, and F1 scores of all the three models improved, but the increase gradually decreased; not only is privacy protection not guaranteed, but the recommendation effectiveness also deteriorates under the overall sensitivity scheme.
Under the stratified sensitivity scheme, the recommendation effectiveness of GMF improves relatively as ε increases. However, it remains less effective than the model without DP. It shows that DP has little effect on the MLP recommendation. And the recommendation effectiveness of NeuCF with DP noise is initially relatively poor, but as ε increases, its recommendation effectiveness improves. Overall, as ε increases, the recommendation effectiveness of GMF and NeuMF also improves relatively, but this comes at the cost of deteriorating privacy protection. Therefore, to better protect privacy while meeting the recommendation requirements, it is advisable to choose a smaller ε if possible, even though recommendations may be less effective. This ensures that models uploaded by clients are well protected.
4.8. NCF Federated Recommendation with LSH
The experiment was conducted on federated recommendation using locality sensitive hashing (LSH) with different dimensions of hash vectors. Three models (GMF, MLP, and NeuMF) were compared across various vector dimension levels to evaluate their federated recommendation performance.
The negative–positive training sample ratio was set to 4:1 with a K value equal to 10. Each model uses a hidden vector layer of length 8, while the MLP component includes a hidden layer of dimension 10. Each round of the survey had five participants. The specific structure mainly follows the framework of experiment 3.6, where the noise addition mechanism is replaced by the hash vector, and the results are shown in
Table 6.
The experimental results indicate that reducing the dimensionality of hash vectors leads to decreases in both HR and NDCG, resulting in degraded model performance and reduced recommendation accuracy. However, it may also contribute to reducing overfitting and improving computational efficiency. In practical applications, the choice of hash vector dimensionality needs to be balanced according to specific circumstances to achieve the optimal recommendation effectiveness.
4.9. Comparison of the LSH and the DP
In this section, we compare the recommended performance of using LSH and DP methods in a federated learning framework. By analyzing the data in
Table 5 and
Table 6, the following is generated:
Table 7, showing the recommended performance comparison of the LSH and DP methods under a federated learning framework.
These results suggest that the LSH method may have some advantages in recommendation performance, especially when using the hash vectors of higher dimensions, to improve the discrimination of recommendation systems. However, this promotion may come at the expense of privacy protection, as the LSH method does not provide quantifiable privacy protection as the DP method does. The DP method protects user privacy by introducing noise, but this noise reduces the learning ability of the model and thus affects the recommendation performance. However, with appropriate selection of the privacy protection parameter ε, a balance is achieved between protecting privacy and maintaining recommendation performance. In practical application, the choice of the LSH or DP method, or how to combine the two, should be comprehensively considered according to the specific requirements of the recommendation system and the requirements of privacy protection, so as to achieve the optimal recommendation effect and privacy protection level.
5. Conclusions
In this paper, we have explored the application of federated learning to the neural collaborative filtering (NCF) recommendation model. Our study began by comparing the federated recommendation model based on NCF with traditional recommendation systems, highlighting the trade-offs between privacy and recommendation accuracy. We then examined the impact of participant numbers on federated learning and demonstrated the benefits of pre-training, particularly with the NeuMF model. Secondly, we proposed a model weight setting scheme based on participation levels and investigated the effects of different weight-setting functions on the federated learning process. Thirdly, we introduced a local parameter NCF recommendation scheme to study the influence of embedding layer local parameters on federated recommendations. Fourthly, we proposed an NCF federated recommendation model with a differential privacy (DP) scheme to enhance model privacy, achieving a balance between privacy and recommendation effectiveness through parameter tuning. Our fifth contribution involved the introduction of locality sensitive hashing (LSH) to the NCF collaborative recommendation model, aiming to improve privacy protection. By adjusting the dimensionality of hash vectors, we were able to enhance the system’s performance. In summary, our research combines pre-training, local parameters, DP, and LSH techniques to improve federated learning in recommender systems. These enhancements have not only improved the federated learning process, efficiency, and recommendation accuracy but also bolstered data privacy and protected client data. Comparative experiments have validated the proposed models and assessed their recommendation effectiveness and privacy protection capabilities. Despite the progress made, there are several limitations to this study that warrant further investigation:
The model weight setting function is linear and may not capture the complexity of real-world user participation patterns. Non-linear or adaptive functions could be explored in future work.
Our experiments were conducted using the MovieLens 1M dataset, which may not be representative of all recommendation scenarios. A broader range of datasets should be considered to generalize the findings.
The MLP and the MLP component within the NeuMF model were limited to a single hidden layer with a fixed vector length of eight. The impact of varying the layer structure and vector dimensions requires further study.
The ratio of positive to negative samples was fixed at 1:4 in our experiments. Investigating the effects of different ratios could provide insights into model robustness.
The total number of training participations was constrained to ensure timely experiment completion. Real-world federated learning scenarios may involve more dynamic participation patterns.
The optimal dimensionality of hash vectors for LSH, which ensures both system recommendation effectiveness and privacy protection, remains to be determined. Future research could focus on finding this balance through a more rigorous analysis.





{kind=link}
{kind=link}
{kind=link}