
An Attention-Based Full-Scale Fusion Network for Segmenting Roof Mask from Satellite Images

Abstract
1. Introduction
2. Related Work
2.1. Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery
2.2. Visual Attention Mechanism
3. The Proposed Attention-Based Full-Scale Fusion Network
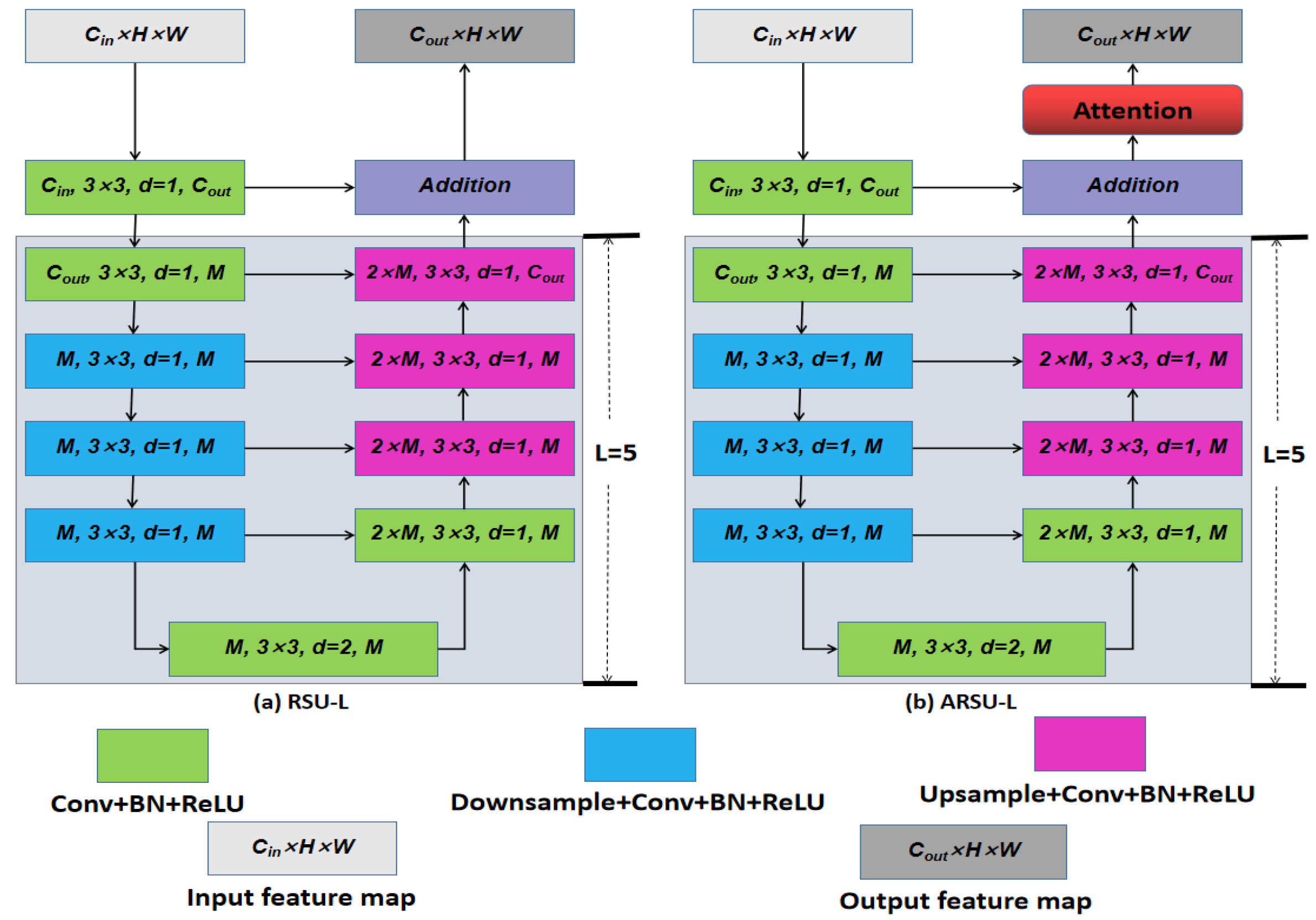
3.1. Attention-Based Residual Ublock
3.2. Full-Scale Fusion with Attention (FSFA)
3.3. Roof Discrimination
3.4. Loss Function
3.5. Implementation Details
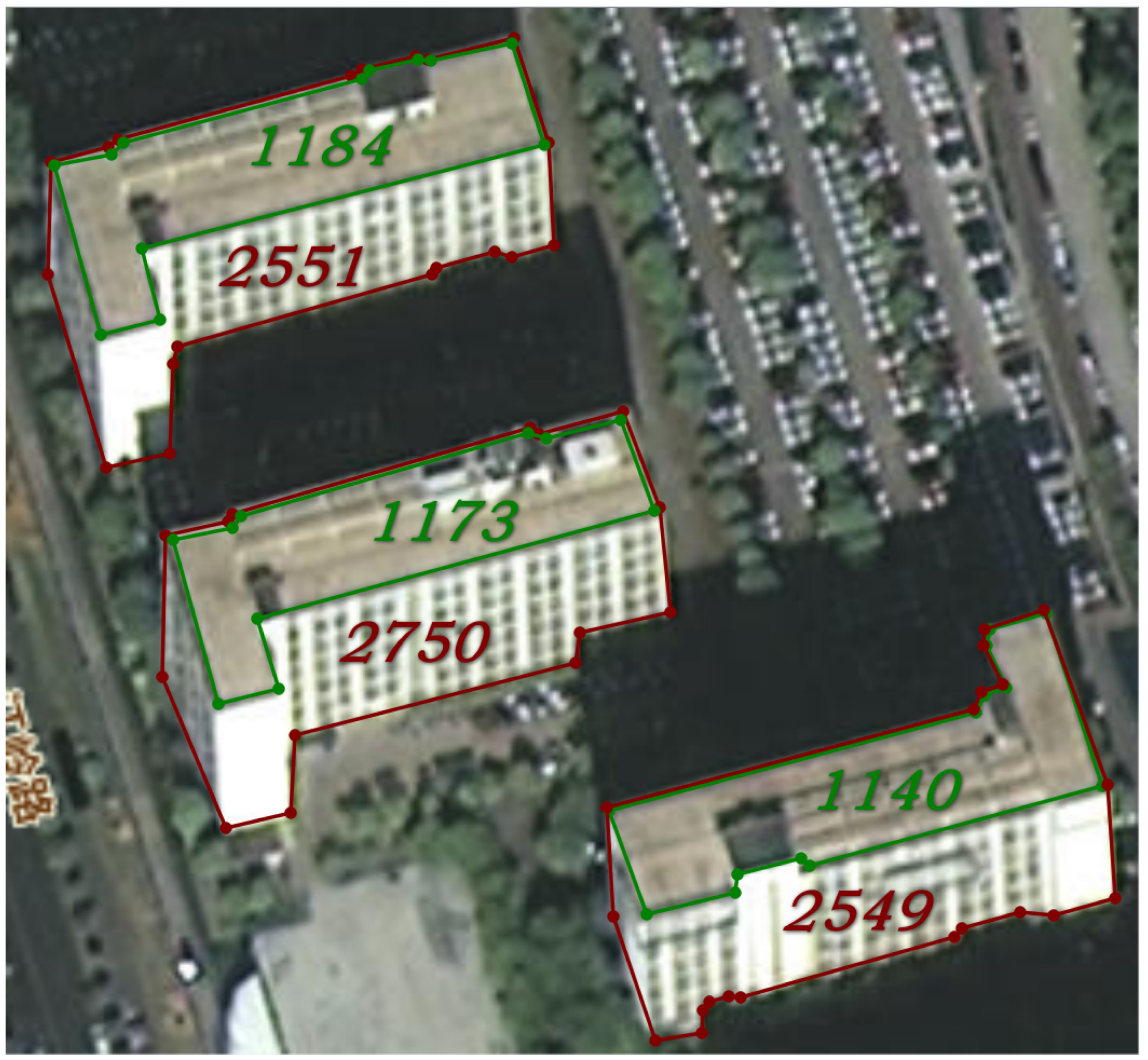
4. Roof Segmentation Dataset
5. Experiments
5.1. Evaluation Metrics
5.2. Ablation Study
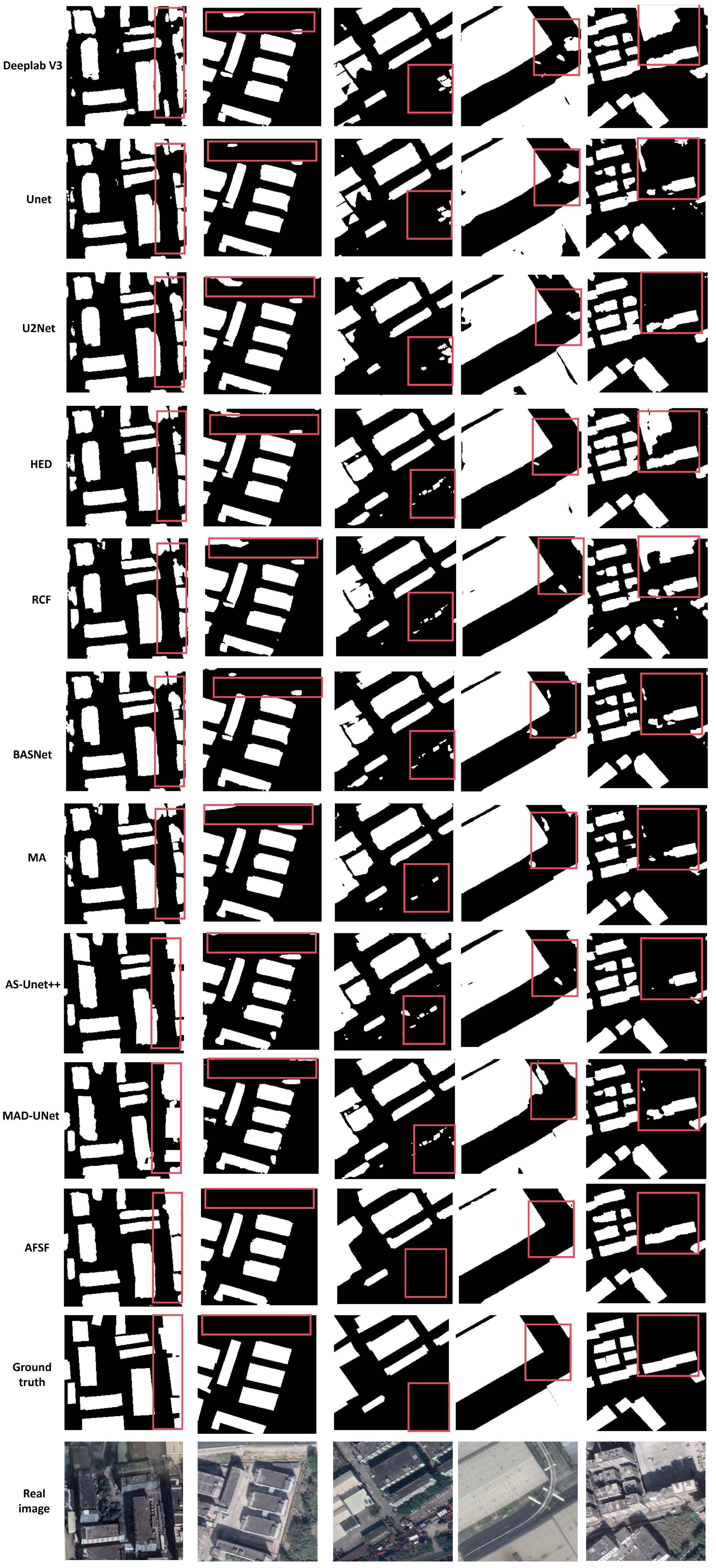
5.3. Comparison with the State of the Art
6. Limitations of the Model and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, X.; Ma, X.; Chen, B.; Shang, Y.; Song, M. Challenges toward carbon neutrality in China: Strategies and countermeasures. Resour. Conserv. Recycl. 2022, 176, 105959. [Google Scholar] [CrossRef]
- Liu, J.; Yin, M.; Xia-Hou, Q.; Wang, K.; Zou, J. Comparison of sectoral low-carbon transition pathways in China under the nationally determined contribution and 2 °C targets. Renew. Sustain. Energy Rev. 2021, 149, 111336. [Google Scholar] [CrossRef]
- Zhou, N.; Khanna, N.; Feng, W.; Ke, J.; Levine, M. Scenarios of energy efficiency and CO2 emissions reduction potential in the buildings sector in China to year 2050. Nat. Energy 2018, 3, 978–984. [Google Scholar] [CrossRef]
- Huo, T.; Cao, R.; Du, H.; Zhang, J.; Cai, W.; Liu, B. Nonlinear influence of urbanization on China’s urban residential building carbon emissions: New evidence from panel threshold model. Sci. Total Environ. 2021, 772, 145058. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Lu, N.; Wang, X. Assessing Carbon Reduction Potential of Rooftop PV in China through Remote Sensing Data-Driven Simulations. Sustainability 2023, 15, 3380. [Google Scholar] [CrossRef]
- Jiang, H.; Yao, L.; Lu, N.; Qin, J.; Liu, T.; Liu, Y.; Zhou, C. Geospatial assessment of rooftop solar photovoltaic potential using multi-source remote sensing data. Energy AI 2022, 10, 100185. [Google Scholar] [CrossRef]
- Bódis, K.; Kougias, I.; Jäger-Waldau, A.; Taylor, N.; Szabó, S. A high-resolution geospatial assessment of the rooftop solar photovoltaic potential in the European Union. Renew. Sustain. Energy Rev. 2019, 114, 109309. [Google Scholar] [CrossRef]
- Sacchelli, S.; Garegnani, G.; Geri, F.; Grilli, G.; Paletto, A.; Zambelli, P.; Ciolli, M.; Vettorato, D. Trade-off between photovoltaic systems installation and agricultural practices on arable lands: An environmental and socio-economic impact analysis for Italy. Land Use Policy 2016, 56, 90–99. [Google Scholar] [CrossRef]
- Wang, D.; Qi, T.; Liu, Y.; Wang, Y.; Fan, J.; Wang, Y.; Du, H. A method for evaluating both shading and power generation effects of rooftop solar PV panels for different climate zones of China. Sol. Energy 2020, 205, 432–445. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Cha, S.H. Review of geographic information systems-based rooftop solar photovoltaic potential estimation approaches at urban scales. Appl. Energy 2021, 291, 116817. [Google Scholar] [CrossRef]
- Jurasz, J.K.; Dąbek, P.B.; Campana, P.E. Can a city reach energy self-sufficiency by means of rooftop photovoltaics? Case study from Poland. J. Clean. Prod. 2020, 245, 118813. [Google Scholar] [CrossRef]
- Schallenberg-Rodríguez, J. Photovoltaic techno-economical potential on roofs in regions and islands: The case of the Canary Islands. Methodological review and methodology proposal. Renew. Sustain. Energy Rev. 2013, 20, 219–239. [Google Scholar] [CrossRef]
- Byrne, J.; Taminiau, J.; Kurdgelashvili, L.; Kim, K.N. A review of the solar city concept and methods to assess rooftop solar electric potential, with an illustrative application to the city of Seoul. Renew. Sustain. Energy Rev. 2015, 41, 830–844. [Google Scholar] [CrossRef]
- Tsinghua University Building Energy Efficiency Research Center. Annual Development Research Report on Building Energy Efficiency in China; China Architecture and Building Press: Beijing, China, 2022. [Google Scholar]
- Zhong, T.; Zhang, Z.; Chen, M.; Zhang, K.; Zhou, Z.; Zhu, R.; Wang, Y.; Lü, G.; Yan, J. A city-scale estimation of rooftop solar photovoltaic potential based on deep learning. Appl. Energy 2021, 298, 117132. [Google Scholar] [CrossRef]
- Sampath, A.; Bijapur, P.; Karanam, A.; Umadevi, V.; Parathodiyil, M. Estimation of rooftop solar energy generation using Satellite Image Segmentation. In Proceedings of the 2019 IEEE 9th International Conference on Advanced Computing (IACC), Tiruchirappalli, India, 13–14 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 38–44. [Google Scholar]
- Zhang, Z.; Qian, Z.; Zhong, T.; Chen, M.; Zhang, K.; Yang, Y.; Zhu, R.; Zhang, F.; Zhang, H.; Zhou, F.; et al. Vectorized rooftop area data for 90 cities in China. Sci. Data 2022, 9, 66. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Azimi, S.M.; Henry, C.; Sommer, L.; Schumann, A.; Vig, E. Skyscapes fine-grained semantic understanding of aerial scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7393–7403. [Google Scholar]
- Lee, M.; Hong, T. Hybrid agent-based modeling of rooftop solar photovoltaic adoption by integrating the geographic information system and data mining technique. Energy Convers. Manag. 2019, 183, 266–279. [Google Scholar] [CrossRef]
- Mainzer, K.; Fath, K.; McKenna, R.; Stengel, J.; Fichtner, W.; Schultmann, F. A high-resolution determination of the technical potential for residential-roof-mounted photovoltaic systems in Germany. Sol. Energy 2014, 105, 715–731. [Google Scholar] [CrossRef]
- Mainzer, K.; Killinger, S.; McKenna, R.; Fichtner, W. Assessment of rooftop photovoltaic potentials at the urban level using publicly available geodata and image recognition techniques. Sol. Energy 2017, 155, 561–573. [Google Scholar] [CrossRef]
- Ohleyer, S. Building Segmentation on Satellite Images. 2018. Available online: https://project.inria.fr/aerialimagelabeling/files/2018/01/fp_ohleyer_compressed.pdf (accessed on 25 March 2024).
- Sun, T.; Shan, M.; Rong, X.; Yang, X. Estimating the spatial distribution of solar photovoltaic power generation potential on different types of rural rooftops using a deep learning network applied to satellite images. Appl. Energy 2022, 315, 119025. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Yan, Z. Deep-learning-enhanced multitarget detection for end–edge–cloud surveillance in smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 7 2015; pp. 3431–3440. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Pan, X.; Gao, L.; Zhang, B.; Yang, F.; Liao, W. High-resolution aerial imagery semantic labeling with dense pyramid network. Sensors 2018, 18, 3774. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Yang, R.; Qi, Y.; Su, Y. U-Net neural networks and its application in high resolution satellite image classification. Remote Sens. Technol. Appl. 2020, 35, 767–774. [Google Scholar]
- Priyanka; Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DIResUNet: Architecture for multiclass semantic segmentation of high resolution remote sensing imagery data. Appl. Intell. 2022, 52, 15462–15482. [Google Scholar] [CrossRef]
- An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685.
- Jia, J.; Song, J.; Kong, Q.; Yang, H.; Teng, Y.; Song, X. Multi-Attention-Based Semantic Segmentation Network for Land Cover Remote Sensing Images. Electronics 2023, 12, 1347. [Google Scholar] [CrossRef]
- Sravya, N.; Priyanka; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DPPNet: An Efficient and Robust Deep Learning Network for Land Cover Segmentation From High-Resolution Satellite Images. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 128–139. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual attention methods in deep learning: An in-depth survey. arXiv 2022, arXiv:2204.07756. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Compute Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Shen, D.; Ji, Y.; Li, P.; Wang, Y.; Lin, D. Ranet: Region attention network for semantic segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 13927–13938. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6798–6807. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. arXiv 2020, arXiv:2004.08790. [Google Scholar]
- de Boer, P.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. 2017. Available online: https://api.semanticscholar.org/CorpusID:40027675 (accessed on 25 March 2024).
- Riba, E.; Mishkin, D.; Ponsa, D.; Rublee, E.; Bradski, G. Kornia: An Open Source Differentiable Computer Vision Library for PyTorch. In Proceedings of the Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Bian, J.W.; Zhang, L.; Bai, X.; Tang, J. Richer Convolutional Features for Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1939–1946. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. BDCN: Bi-Directional Cascade Network for Perceptual Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 100–113. [Google Scholar] [CrossRef] [PubMed]
- Nan, G.; Li, H.; Du, H.; Liu, Z.; Wang, M.; Xu, S. A Semantic Segmentation Method Based on AS-Unet++ for Power Remote Sensing of Images. Sensors 2024, 24, 269. [Google Scholar] [CrossRef]
- Xue, H.; Liu, K.; Wang, Y.; Chen, Y.; Huang, C.; Wang, P.; Li, L. MAD-UNet: A Multi-Region UAV Remote Sensing Network for Rural Building Extraction. Sensors 2024, 24, 2393. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Definition |
|---|---|
| A convolutional layer with a kernel size of and a stride size of 1 | |
| Batch-norm layer | |
| activation function | |
| Max pooling with a stride of | |
| A layer that uses the bilinear interpolation algorithm to expand the length and width of the input image twice, respectively |
| Metric | Definition |
|---|---|
| TP | The number of positive pixels predicted as positive by the model |
| TN | The number of negative pixels predicted as negative by the model |
| FP | The number of negative pixels predicted as positive by the model |
| FN | The number of positive pixels predicted as negative by the model |
| Method | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| U2Net | 76.3 | 80.7 | 78.4 |
| U2Net+ARU | 79.0 | 84.3 | 81.6 |
| U2Net+ARU+FSFA | 83.0 | 86.7 | 84.8 |
| AFSF | 83.3 | 88.9 | 86.0 |
| Method | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| Deeplab V3 | 44.8 | 53.7 | 48.8 |
| UNet | 72.9 | 82.2 | 77.2 |
| U2Net | 76.3 | 80.7 | 78.4 |
| HED [56] | 65.3 | 72.6 | 52.4 |
| RCF [57] | 70.5 | 81.3 | 60.7 |
| BASNet [58] | 80.2 | 85.4 | 70.6 |
| MA [42] | 81.1 | 85.6 | 71.3 |
| AS-UNet++ [59] | 81.5 | 86.3 | 72.4 |
| MAD-UNet [60] | 81.0 | 85.3 | 70.8 |
| AFSF | 83.3 | 88.9 | 75.5 |
| Method | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| UNet | 83.1 | 81.1 | 69.7 |
| U2Net | 84.8 | 81.5 | 71.1 |
| BASNet [58] | 86.3 | 83.2 | 73.5 |
| HED [56] | 82.5 | 80.2 | 68.5 |
| RCF [57] | 84.3 | 80.9 | 70.3 |
| MA [42] | 87.1 | 85.7 | 76.0 |
| AS-UNet++ [59] | 87.3 | 86.1 | 76.5 |
| MAD-UNet [60] | 86.6 | 85.2 | 75.3 |
| AFSF | 88.0 | 86.8 | 77.6 |
| Method | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| UNet | 94.6 | 90.7 | 86.2 |
| U2Net | 95.0 | 91.2 | 87.0 |
| BASNet [58] | 95.9 | 92.9 | 89.3 |
| HED [56] | 94.2 | 90.4 | 85.6 |
| RCF [57] | 95.0 | 90.7 | 86.6 |
| MA [42] | 96.0 | 93.2 | 89.7 |
| AS-UNet++ [59] | 96.1 | 93.4 | 90.1 |
| MAD-UNet [60] | 95.9 | 93.0 | 89.6 |
| AFSF | 96.7 | 93.9 | 90.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, L.; Liu, Z.; Ma, Q.; Qi, H.; Qi, F.; Zhang, Y. An Attention-Based Full-Scale Fusion Network for Segmenting Roof Mask from Satellite Images. Appl. Sci. 2024, 14, 4371. https://doi.org/10.3390/app14114371
Cheng L, Liu Z, Ma Q, Qi H, Qi F, Zhang Y. An Attention-Based Full-Scale Fusion Network for Segmenting Roof Mask from Satellite Images. Applied Sciences. 2024; 14(11):4371. https://doi.org/10.3390/app14114371
Chicago/Turabian StyleCheng, Li, Zhang Liu, Qian Ma, He Qi, Fumin Qi, and Yi Zhang. 2024. "An Attention-Based Full-Scale Fusion Network for Segmenting Roof Mask from Satellite Images" Applied Sciences 14, no. 11: 4371. https://doi.org/10.3390/app14114371
APA StyleCheng, L., Liu, Z., Ma, Q., Qi, H., Qi, F., & Zhang, Y. (2024). An Attention-Based Full-Scale Fusion Network for Segmenting Roof Mask from Satellite Images. Applied Sciences, 14(11), 4371. https://doi.org/10.3390/app14114371