
Research on Rapid Recognition of Moving Small Targets by Robotic Arms Based on Attention Mechanisms

Abstract
1. Introduction
2. Related Work
2.1. Introduction to the YOLOv8 Algorithm
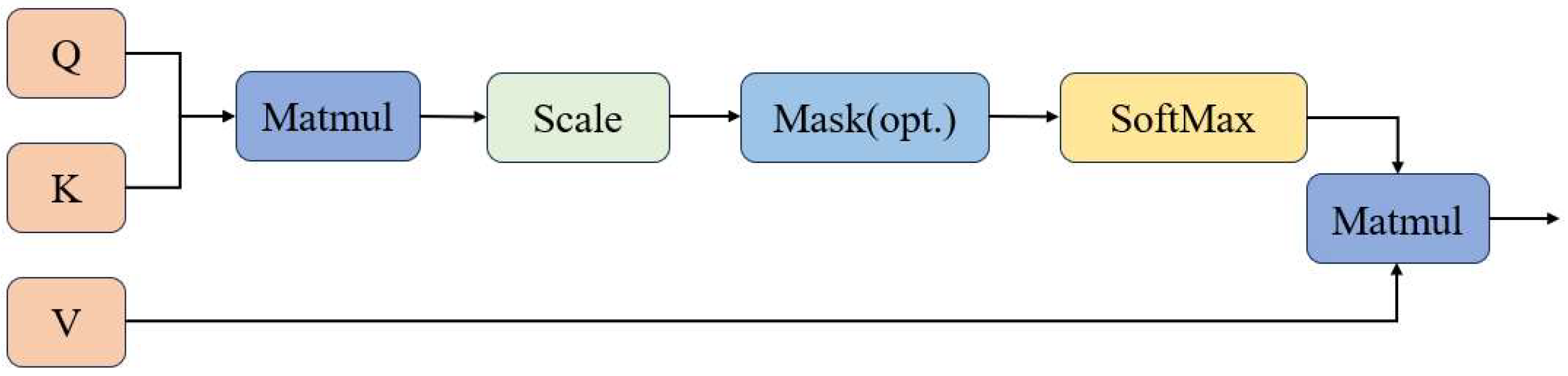
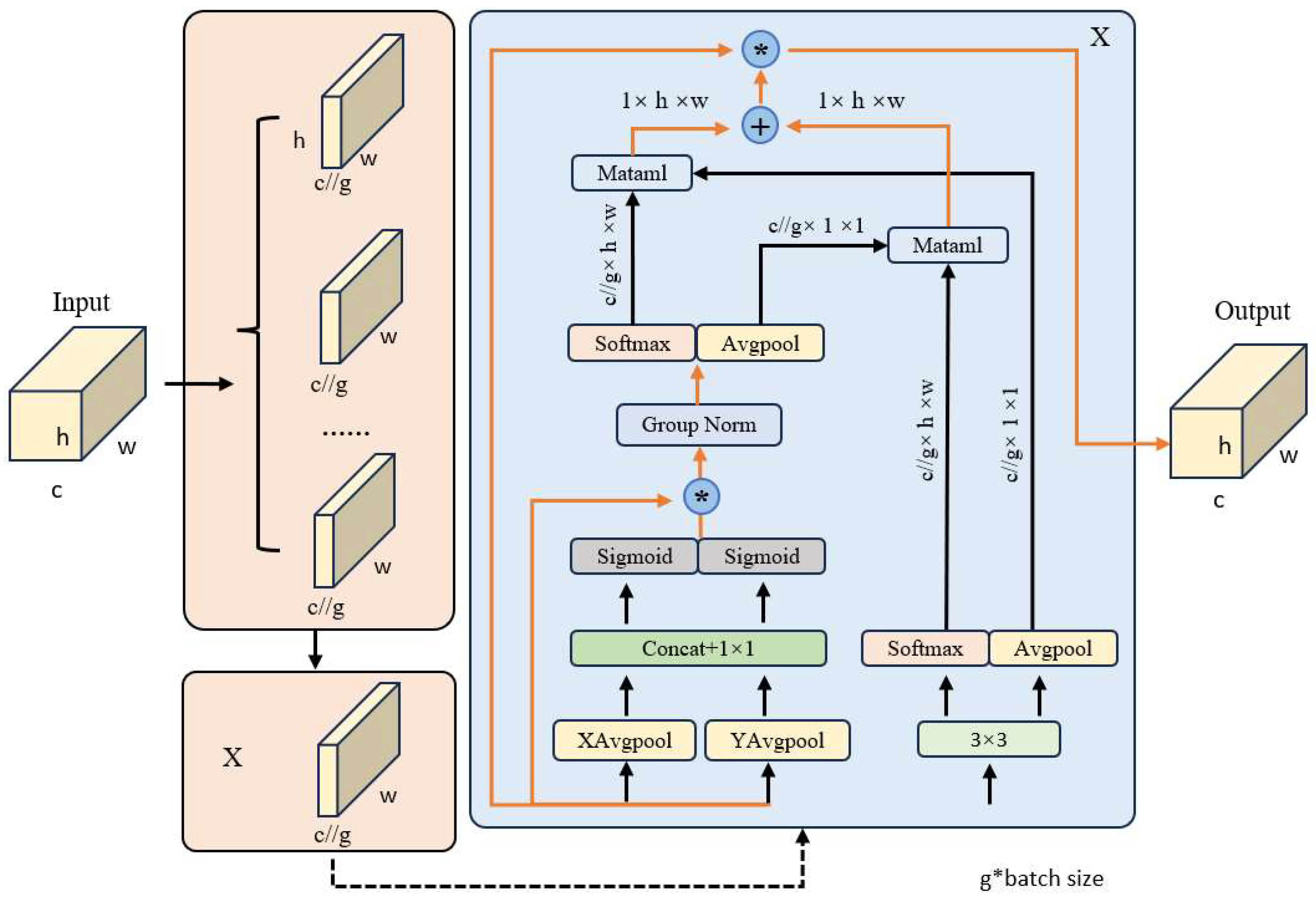
2.2. Introduction to the Attention Mechanism
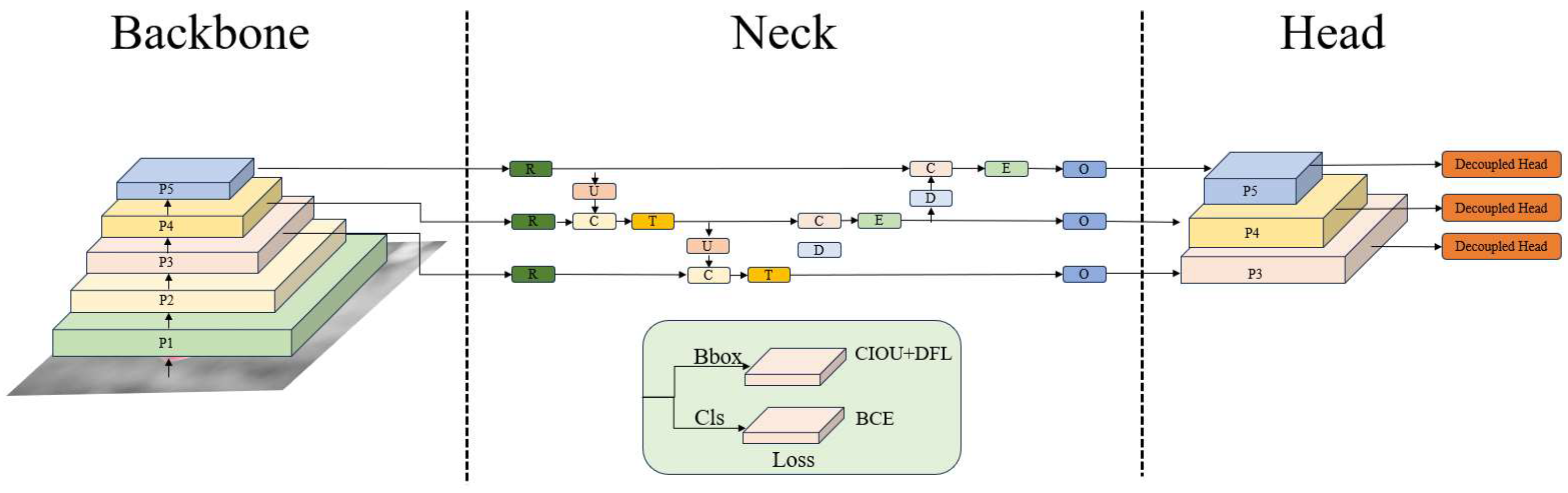
3. YOLOv8 Model Improvements
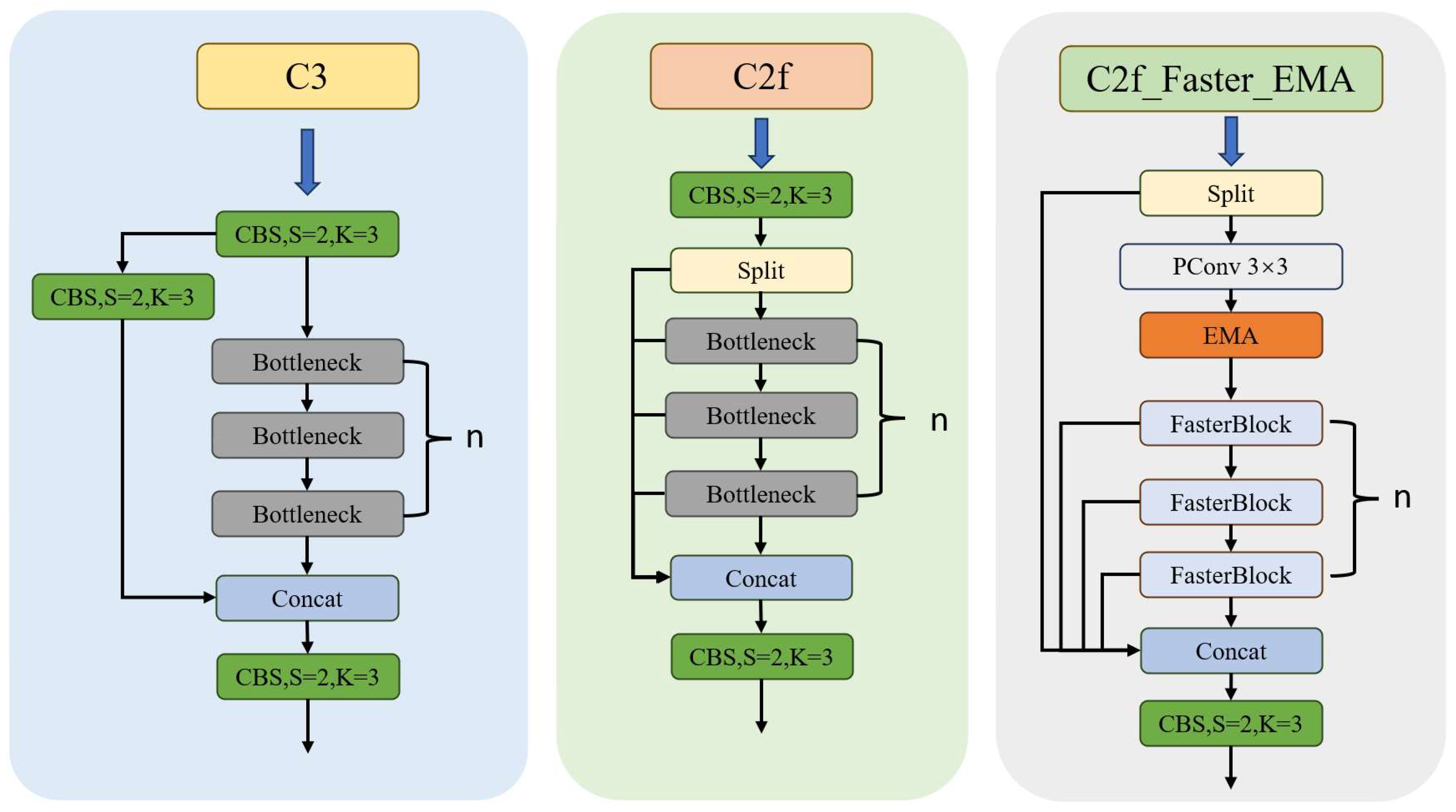
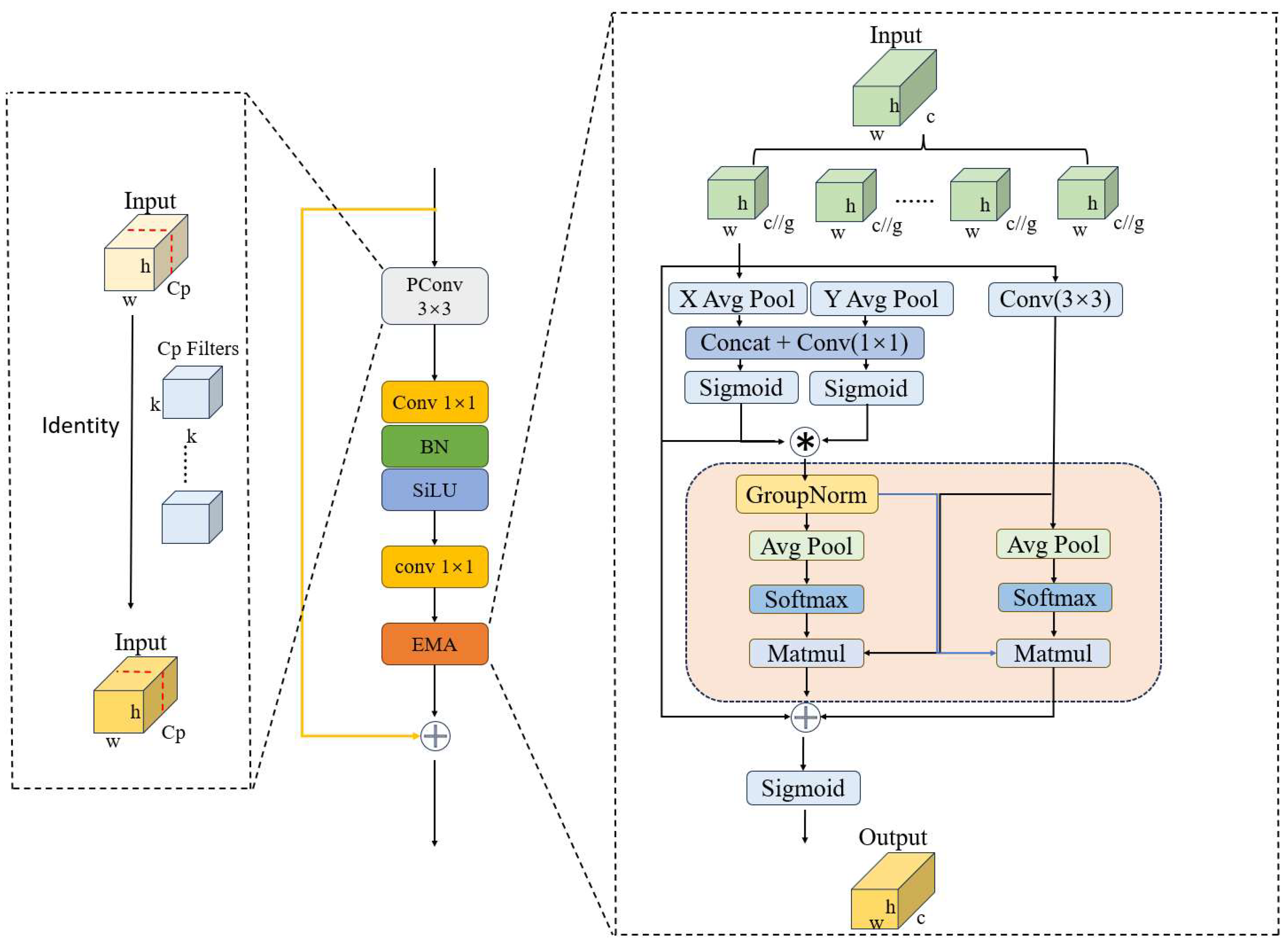
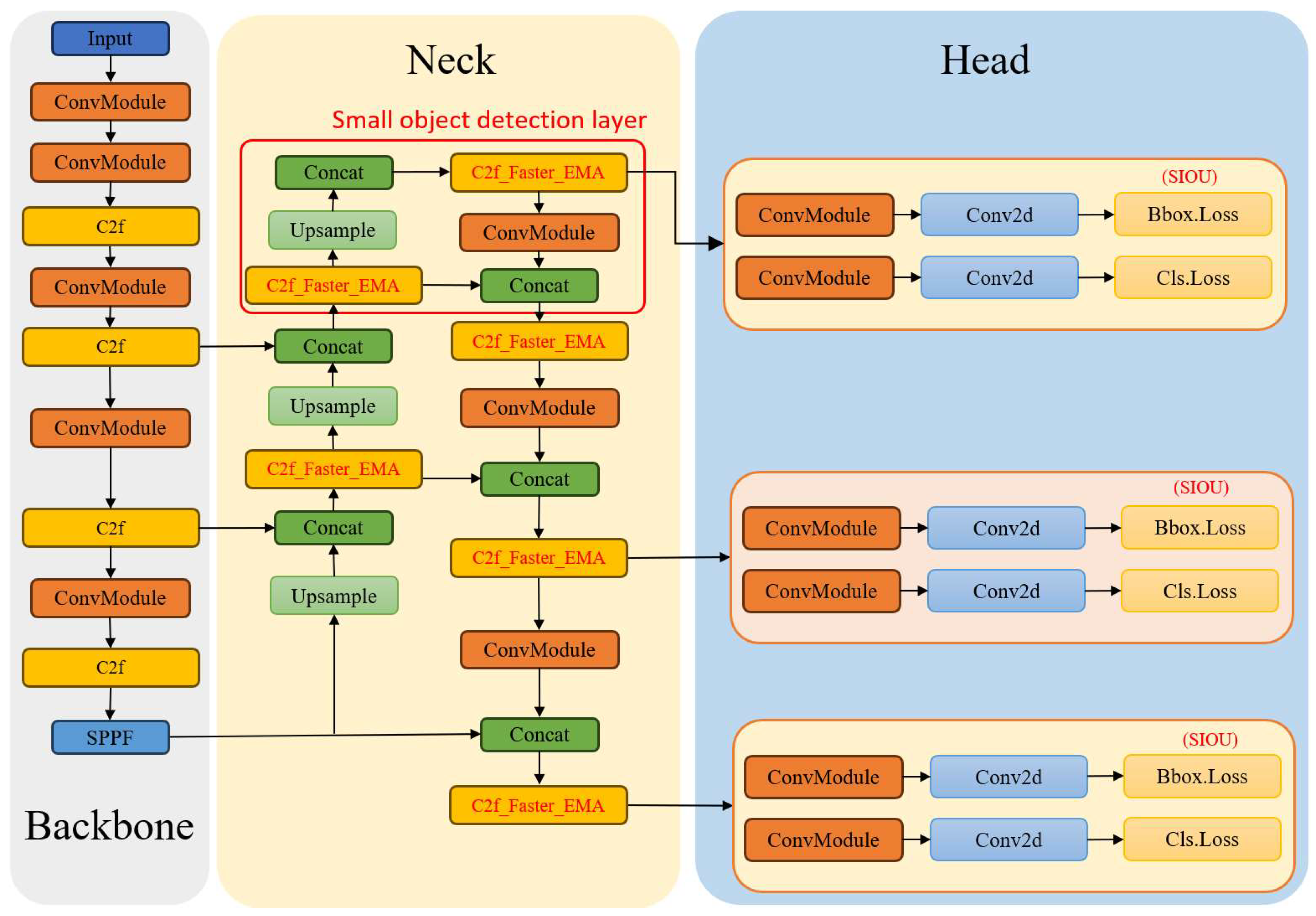
3.1. Incorporating Attention Mechanism in the Network Structure
3.2. Improving the Regression Loss Function
3.3. Incorporating a Small Object Detection Layer into the Network Architecture
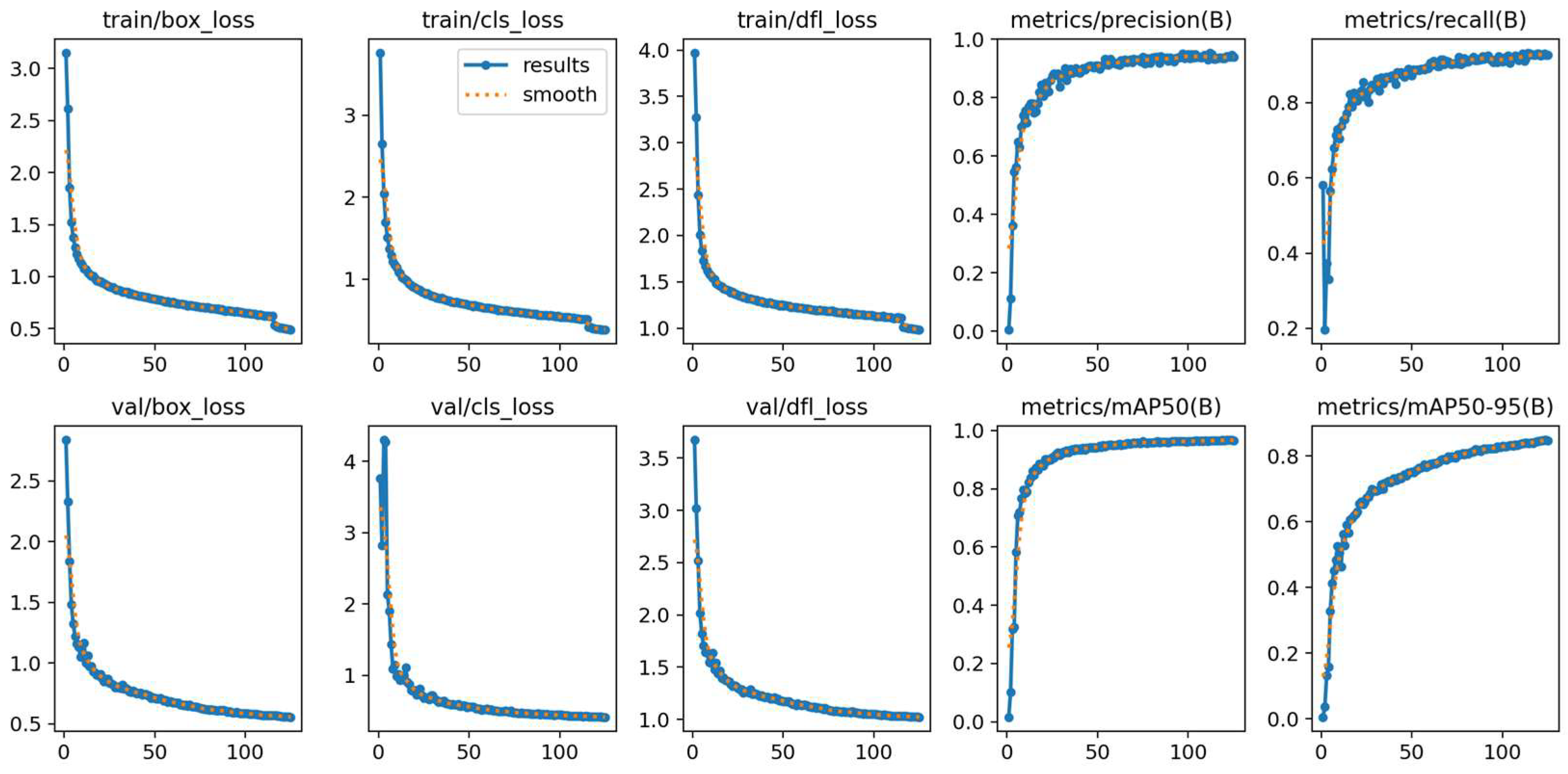
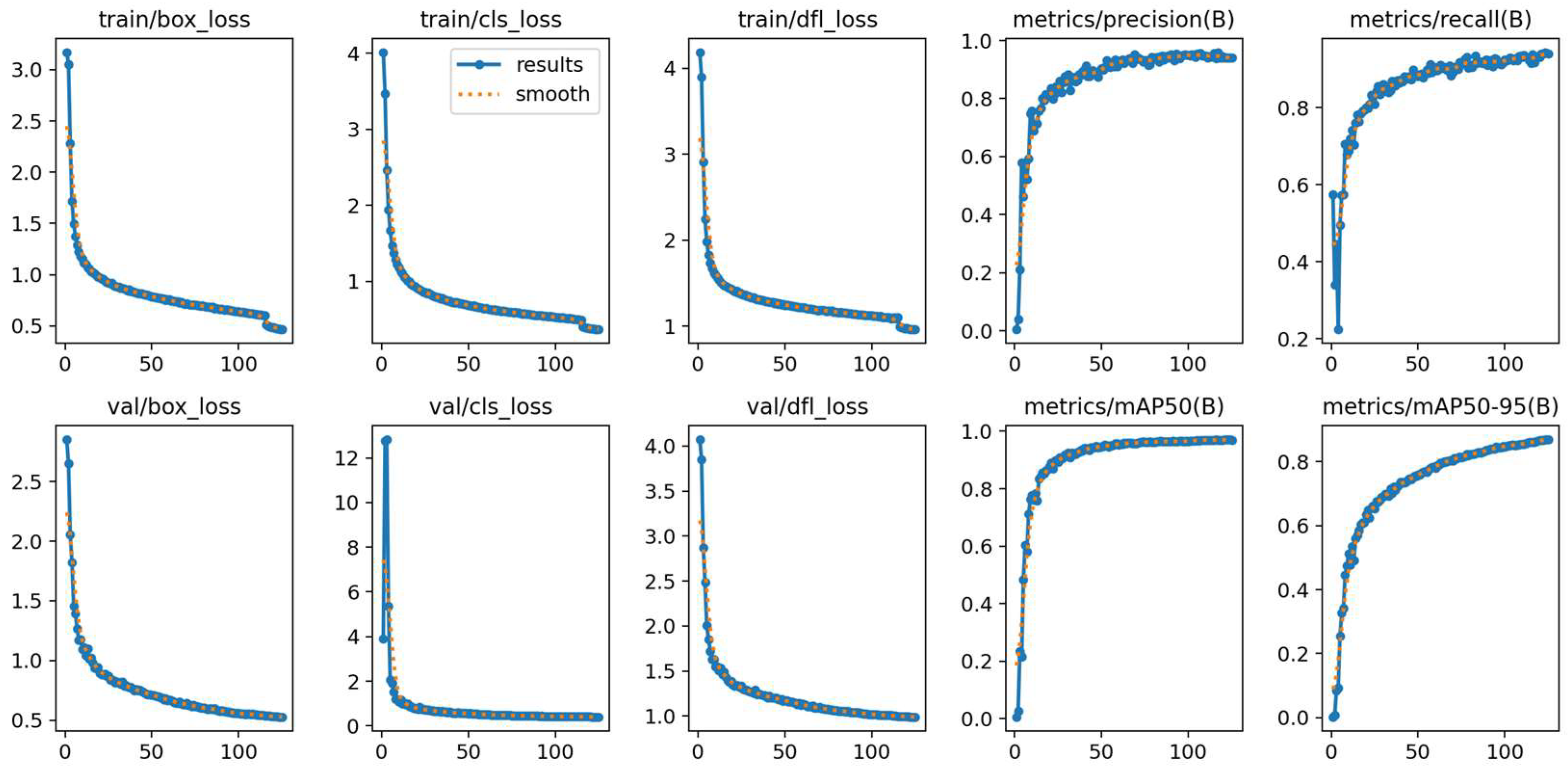
4. Experimental Results and Discussion
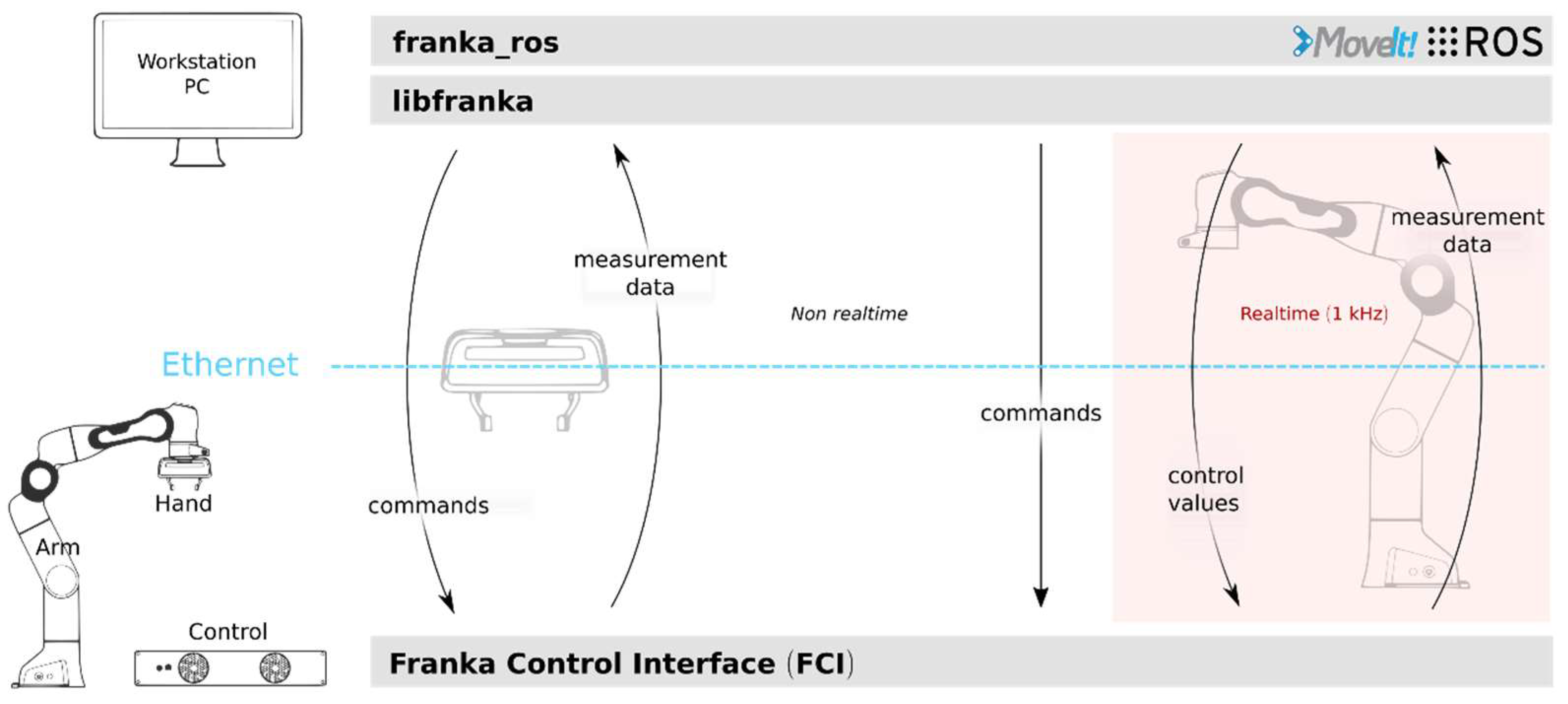
4.1. Experimental Setup for Reliability
4.2. Dataset Preparation
4.3. Experimental Environment Configuration
4.4. Comparative Analysis of Experimental Indicators
- ●
- TP (true positives): the number of positive instances correctly predicted as positive.
- ●
- TN (true negatives): the number of negative instances correctly predicted as negative.
- ●
- FP (false positives): the number of negative instances incorrectly predicted as positive, also known as false alarms.
- ●
- FN (false negatives): the number of positive instances incorrectly predicted as negative, also known as missed detections.
- ●
- Precison: measures the overall proportion of correct predictions (both positive and negative) made by the model.
- ●
- Recall: measures the proportion of actual positives that are correctly identified by the model. While accuracy focuses on the overall correctness of the model’s predictions, recall emphasizes the model’s ability to capture positive instances.
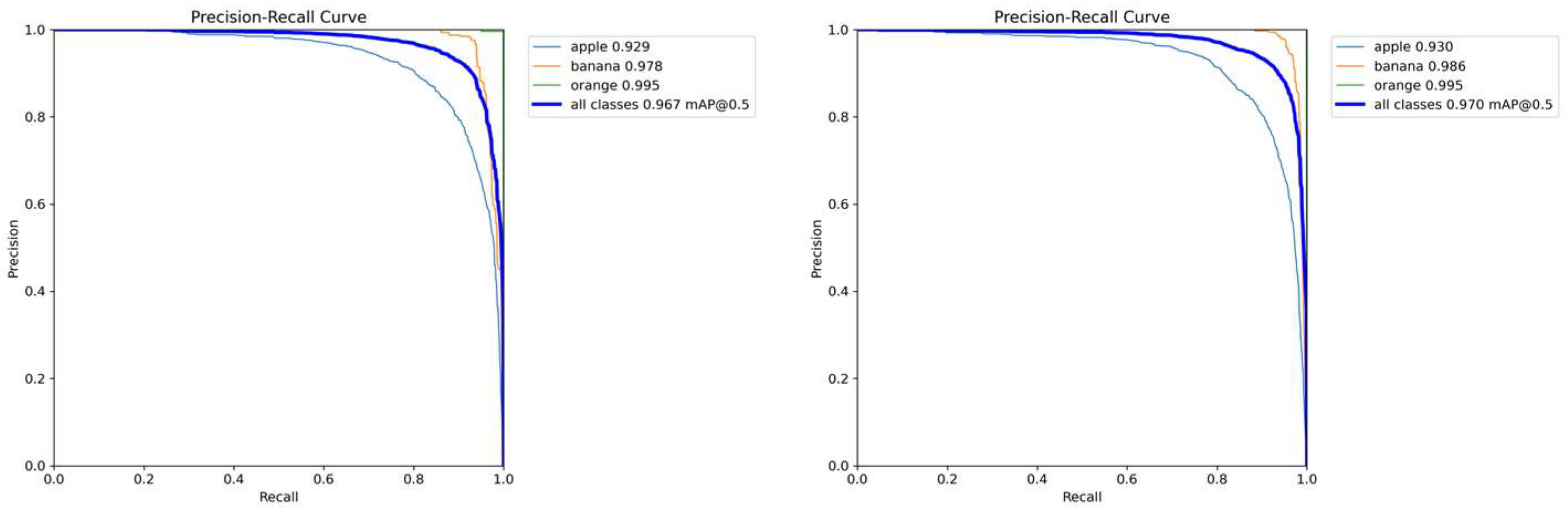
4.5. Comparative Experiment
4.6. Ablation Experiment
4.7. Heatmaps for Object Recognition
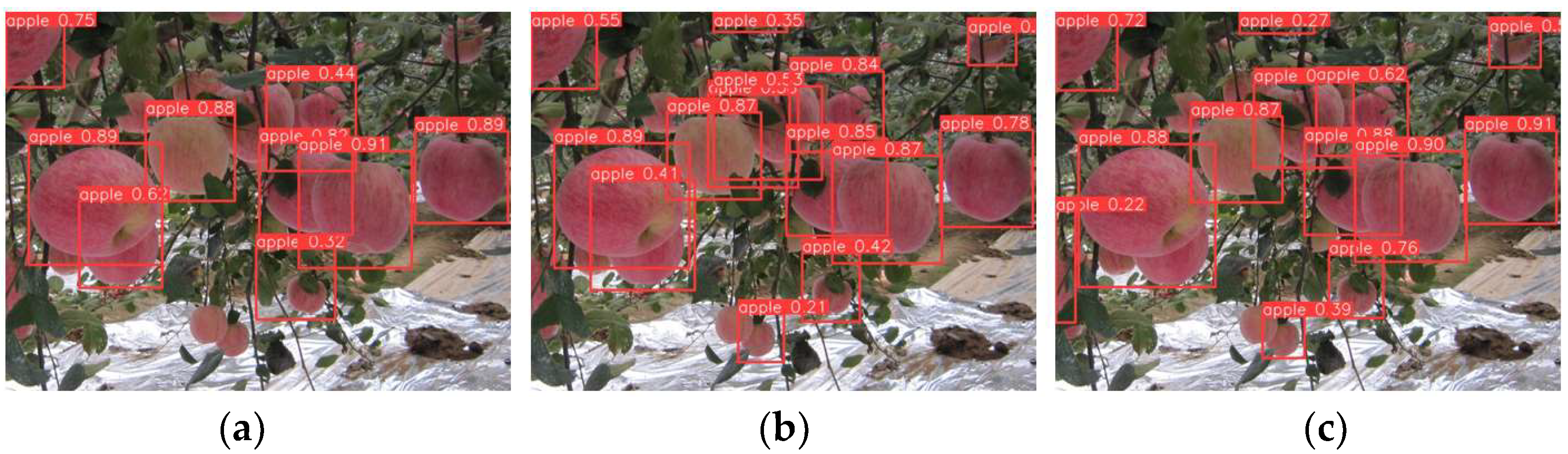
4.8. Object Recognition Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pagonis, K.; Zacharia, P.; Kantaros, A.; Ganetsos, T.; Brachos, K. Design, Fabrication and Simulation of a 5-Dof Robotic Arm Using Machine Vision. In Proceedings of the 2023 17th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 9–10 June 2023; IEEE: Oradea, Romania, 2023; pp. 1–4. [Google Scholar]
- Jijesh, J.J.; Shankar, S.; Ranjitha; Revathi, D.C.; Shivaranjini, M.; Sirisha, R. Development of Machine Learning Based Fruit Detection and Grading System. In Proceedings of the 2020 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 12–13 November 2020; IEEE: Bangalore, India, 2020; pp. 403–407. [Google Scholar]
- Tan, H. Line Inspection Logistics Robot Delivery System Based on Machine Vision and Wireless Communication. In Proceedings of the 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Chongqing, China, 29–30 October 2020; IEEE: Chongqing, China, 2020; pp. 366–374. [Google Scholar]
- Li, G.; Zhu, D. Research on Road Defect Detection Based on Improved YOLOv8. In Proceedings of the 2023 IEEE 11th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 8–10 December 2023; IEEE: Chongqing, China, 2023; pp. 143–146. [Google Scholar]
- Zhixin, L.; Yubo, H.; Tianding, Z.; Yueming, W.; Haoyuan, Y.; Wei, Z.; Yang, W. Discussion on the Application of Artificial Intelligence in Computer Network Technology. In Proceedings of the 2023 2nd International Conference on Artificial Intelligence and Autonomous Robot Systems (AIARS), Bristol, UK, 9–31 July 2023; IEEE: Bristol, UK, 2023; pp. 51–55. [Google Scholar]
- Pedro, R.; Oliveira, A.L. Assessing the Impact of Attention and Self-Attention Mechanisms on the Classification of Skin Lesions. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Li, W.; Zhang, Z.; Li, C.; Zou, J. Small Target Detection Algorithm Based on Two-Stage Feature Extraction. In Proceedings of the 2023 6th International Conference on Software Engineering and Computer Science (CSECS), Chengdu, China, 22–24 December 2023; IEEE: Chengdu, China, 2023; pp. 1–5. [Google Scholar]
- Singh, R.; Singh, D. Quality Inspection with the Support of Computer Vision Techniques. In Proceedings of the 2022 International Interdisciplinary Humanitarian Conference for Sustainability (IIHC), Bengaluru, India, 18–19 November 2022; IEEE: Bengaluru, India, 2022; pp. 1584–1588. [Google Scholar]
- Umanandhini, D.; Devi, M.S.; Beulah Jabaseeli, N.; Sridevi, S. Batch Normalization Based Convolutional Block YOLOv3 Real Time Object Detection of Moving Images with Backdrop Adjustment. In Proceedings of the 2023 9th International Conference on Smart Computing and Communications (ICSCC), Kochi, India, 17–19 August 2023; IEEE: Kochi, India, 2023; pp. 25–29. [Google Scholar]
- Du, J.; Lu, H.; Zhang, L.; Hu, M.; Shen, X. Infrared Small Target Detection and Tracking Method Suitable for Different Scenes. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; IEEE: Chongqing, China, 2020; pp. 664–668. [Google Scholar]
- Chen, X.; Guan, J.; Wang, Z.; Zhang, H.; Wang, G. Marine Targets Detection for Scanning Radar Images Based on Radar- YOLONet. In Proceedings of the 2021 CIE International Conference on Radar (Radar), Haikou, China, 5–19 December 2021; IEEE: Haikou, China, 2021; pp. 1256–1260. [Google Scholar]
- Duth, S.; Vedavathi, S.; Roshan, S. Herbal Leaf Classification Using RCNN, Fast RCNN, Faster RCNN. In Proceedings of the 2023 7th International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 18 August 2023; IEEE: Pune, India, 2023; pp. 1–8. [Google Scholar]
- Wu, Z.; Yu, H.; Zhang, L.; Sui, Y. AMB:Automatically Matches Boxes Module for One-Stage Object Detection. In Proceedings of the 2023 IEEE International Conference on Image Processing and Computer Applications (ICIPCA), Changchun, China, 11–13 August 2023; IEEE: Changchun, China, 2023; pp. 1516–1522. [Google Scholar]
- Gai, R.; Li, M.; Chen, N. Cherry Detection Algorithm Based on Improved YOLOv5s Network. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; IEEE: Haikou, China, 2021; pp. 2097–2103. [Google Scholar]
- Pandey, S.; Chen, K.-F.; Dam, E.B. Comprehensive Multimodal Segmentation in Medical Imaging: Combining YOLOv8 with SAM and HQ-SAM Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 2–6 October 2023; IEEE: Paris, France, 2023; pp. 2584–2590. [Google Scholar]
- Gunawan, F.; Hwang, C.-L.; Cheng, Z.-E. ROI-YOLOv8-Based Far-Distance Face-Recognition. In Proceedings of the 2023 International Conference on Advanced Robotics and Intelligent Systems (ARIS), Taipei, Taiwan, 30 August–1 September 2023; IEEE: Taipei, Taiwan, 2023; pp. 1–6. [Google Scholar]
- Samaniego, L.A.; Peruda, S.R.; Brucal, S.G.E.; Yong, E.D.; De Jesus, L.C.M. Image Processing Model for Classification of Stages of Freshness of Bangus Using YOLOv8 Algorithm. In Proceedings of the 2023 IEEE 12th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 10–13 October 2023; IEEE: Nara, Japan, 2023; pp. 401–403. [Google Scholar]
- Shetty, A.D.; Ashwath, S. Animal Detection and Classification in Image & Video Frames Using YOLOv5 and YOLOv8. In Proceedings of the 2023 7th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 22–24 November 2023; IEEE: Coimbatore, India, 2023; pp. 677–683. [Google Scholar]
- Zhou, F.; Guo, D.; Wang, Y.; Zhao, C. Improved YOLOv8-Based Vehicle Detection Method for Road Monitoring and Surveillance. In Proceedings of the 2023 5th International Symposium on Robotics & Intelligent Manufacturing Technology (ISRIMT), Changzhou, China, 22–24 September 2023; IEEE: Changzhou, China, 2023; pp. 208–212. [Google Scholar]
- Peri, S.D.B.; Palaniswamy, S. A Novel Approach To Detect and Track Small Animals Using YOLOv8 and DeepSORT. In Proceedings of the 2023 4th IEEE Global Conference for Advancement in Technology (GCAT), Bangalore, India, 6–8 October 2023; IEEE: Bangalore, India, 2023; pp. 1–6. [Google Scholar]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. MATNet: Motion-Attentive Transition Network for Zero-Shot Video Object Segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef]
- Yang, H.; Lin, L.; Zhong, S.; Guo, F.; Cui, Z. Aero Engines Fault Diagnosis Method Based on Convolutional Neural Network Using Multiple Attention Mechanism. In Proceedings of the 2021 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Weihai, China, 13–15 August 2021; pp. 13–18. [Google Scholar]
- Luo, Z.; Li, J.; Zhu, Y. A Deep Feature Fusion Network Based on Multiple Attention Mechanisms for Joint Iris-Periocular Biometric Recognition. IEEE Signal Process. Lett. 2021, 28, 1060–1064. [Google Scholar] [CrossRef]
- Shi, Y.; Hidaka, A. Attention-YOLOX: Improvement in On-Road Object Detection by Introducing Attention Mechanisms to YOLOX. In Proceedings of the 2022 International Symposium on Computing and Artificial Intelligence (ISCAI), Beijing, China, 16–18 December 2022; pp. 5–14. [Google Scholar]
- Dong, Y. Research on Performance Improvement Method of Dynamic Object Detection Based on Spatio-Temporal Attention Mechanism. In Proceedings of the 2023 IEEE International Conference on Image Processing and Computer Applications (ICIPCA), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1558–1563. [Google Scholar]
- Du, D.; Cai, H.; Chen, G.; Shi, H. Multi Branch Deepfake Detection Based on Double Attention Mechanism. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–26 September 2021; pp. 746–749. [Google Scholar]
- Liang, C.; Dong, J.; Li, J.; Meng, J.; Liu, Y.; Fang, T. Facial Expression Recognition Using LBP and CNN Networks Integrating Attention Mechanism. In Proceedings of the 2023 Asia Symposium on Image Processing (ASIP), Tianjin, China, 15–17 June 2023; pp. 1–6. [Google Scholar]
- Wu, M.; Zhao, J. Siamese Network Object Tracking Algorithm Combined with Attention Mechanism. In Proceedings of the 2023 International Conference on Intelligent Media, Big Data and Knowledge Mining (IMBDKM), Changsha, China, 17–19 March 2023; pp. 20–24. [Google Scholar]
- Yang, Y.; Sun, L.; Mao, X.; Dai, L.; Guo, S.; Liu, P. Using Generative Adversarial Networks Based on Dual Attention Mechanism to Generate Face Images. In Proceedings of the 2021 International Conference on Computer Technology and Media Convergence Design (CTMCD), Sanya, China, 23–25 April 2021; pp. 14–19. [Google Scholar]
- Chen, C.; Wu, X.; Chen, A. A Semantic Segmentation Algorithm Based on Improved Attention Mechanism. In Proceedings of the 2020 International Symposium on Autonomous Systems (ISAS), Guangzhou, China, 6–8 December 2020; pp. 244–248. [Google Scholar]
- Osama, M.; Kumar, R.; Shahid, M. Empowering Cardiologists with Deep Learning YOLOv8 Model for Accurate Coronary Artery Stenosis Detection in Angiography Images. In Proceedings of the 2023 International Conference on IoT, Communication and Automation Technology (ICICAT), Gorakhpur, India, 23–24 June 2023; pp. 1–6. [Google Scholar]
- Wang, Z.; Luo, X.; Li, F.; Zhu, X. Lightweight Pig Face Detection Method Based on Improved YOLOv8. In Proceedings of the 2023 13th International Conference on Information Science and Technology (ICIST), Cairo, Egypt, 8–14 December 2023; pp. 259–266. [Google Scholar]
- Gonthina, N.; Katkam, S.; Pola, R.A.; Pusuluri, R.T.; Prasad, L.V.N. Parking Slot Detection Using Yolov8. In Proceedings of the 2023 3rd International Conference on Mobile Networks and Wireless Communications (ICMNWC), Tumkur, India, 8–10 December 2023; pp. 1–7. [Google Scholar]
- Haimer, Z.; Mateur, K.; Farhan, Y.; Madi, A.A. Pothole Detection: A Performance Comparison Between YOLOv7 and YOLOv8. In Proceedings of the 2023 9th International Conference on Optimization and Applications (ICOA), Abu Dhabi, India, 5–6 October 2023; pp. 1–7. [Google Scholar]
- Orchi, H.; Sadik, M.; Khaldoun, M.; Sabir, E. Real-Time Detection of Crop Leaf Diseases Using Enhanced YOLOv8 Algorithm. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023; pp. 1690–1696. [Google Scholar]
- Tan, Y.K.; Chin, K.M.; Ting, T.S.H.; Goh, Y.H.; Chiew, T.H. Research on YOLOv8 Application in Bolt and Nut Detection for Robotic Arm Vision. In Proceedings of the 2024 16th International Conference on Knowledge and Smart Technology (KST), Krabi, Thailand, 28 February–2 March 2024; pp. 126–131. [Google Scholar]
- Xie, S.; Chuah, J.H.; Chai, G.M.T. Revolutionizing Road Safety: YOLOv8-Powered Driver Fatigue Detection. In Proceedings of the 2023 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Nadi, Fiji, 4–6 December 2023; pp. 1–6. [Google Scholar]
- Afonso, M.H.F.; Teixeira, E.H.; Cruz, M.R.; Aquino, G.P.; Vilas Boas, E.C. Vehicle and Plate Detection for Intelligent Transport Systems: Performance Evaluation of Models YOLOv5 and YOLOv8. In Proceedings of the 2023 IEEE International Conference on Computing (ICOCO), Langkawi, Malaysia, 9–12 October 2023; pp. 328–333. [Google Scholar]
- Afrin, Z.; Tabassum, F.; Kibria, H.B.; Imam, M.D.R.; Hasan, M.d.R. YOLOv8 Based Object Detection for Self-Driving Cars. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Toronto, ON, Canada, 13–15 December 2023; pp. 1–6. [Google Scholar]
- Abyasa, J.; Kenardi, M.P.; Audrey, J.; Jovanka, J.J.; Justino, C.; Rahmania, R. YOLOv8 for Product Brand Recognition as Inter-Class Similarities. In Proceedings of the 2023 3rd International Conference on Electronic and Electrical Engineering and Intelligent System (ICE3IS), Yogyakarta, Indonesia, 9–10 August 2023; pp. 514–519. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| STRUCTURE | YOLOv8N | YOLOv8S | YOLOv8M | YOLOv8L | YOLOv8X |
|---|---|---|---|---|---|
| Depth | 0.33 | 0.33 | 0.67 | 1.00 | 1.00 |
| width | 0.5 | 0.50 | 0.75 | 1.00 | 1.25 |
| Max_channels | 1024 | 1024 | 768 | 512 | 512 |
| Configuration Name | Version Parameters |
|---|---|
| Camera | RealSense-D435i |
| Robotic arm | Franka Emika Panda |
| GPU | GeForce RTX 4090 24GB |
| CPU | AMD EPYC 9654 96-Core Processor |
| operating system | Ubuntu 20.04 |
| GPU acceleration library | Cuda11.0 |
| programming language | Python3.8.10 |
| Group ID | Camera 3D Coordinate Values (X, Y, Z)/mm | Actual Measured Value Zr/mm | Error /% | Grab Results |
|---|---|---|---|---|
| 1 | (193.1, 66.2, 50.2) | 49.5 | 1.55 | Yes |
| 2 | (169.0, 82.6, 57.9) | 57.2 | 1.32 | Yes |
| 3 | (175.7, 67.6, 86.3) | 83.6 | 3.26 | No |
| 4 | (210.5, 78.5, 69.5) | 67.9 | 2.36 | Yes |
| 5 | (203.2, 53.2, 57.2) | 56.3 | 1.63 | Yes |
| 6 | (206.6, 77.9, 84.5) | 82.1 | 3.01 | Yes |
| 7 | (221.3, 86.2, 73.0) | 71.0 | 2.85 | Yes |
| 8 | (190.5, 59.6, 77.7) | 76.2 | 2.06 | Yes |
| 9 | (186.9, 65.4, 83.3) | 60.9 | 1.98 | Yes |
| 10 | (200.1, 86.8, 62.1) | 59.6 | 1.88 | Yes |
| Parameter | Specifications |
|---|---|
| Scope of use/(m) | 0.3~3.0 |
| interface | USB Type-C 3.1 Gen 1 |
| Length, width, height/(mm * mm * mm) | 90*25*25 |
| Field of View/(°) | 69.4*42.5 |
| Resolution/Pixel | 1920*1080 |
| Evaluating Indicator | Precision | Recall | mAP@0.5-0.95 | FPS |
|---|---|---|---|---|
| YOLOv5n | 0.88 | 0.88 | 0.82 | 180 |
| YOLOv8n | 0.91 | 0.90 | 0.84 | 202 |
| YOLOv8n—SEattention | 0.92 | 0.90 | 0.85 | 204 |
| YOLOv8n—Dattention | 0.90 | 0.91 | 0.84 | 205 |
| YOLOv8n—LocalWindowAttention | 0.87 | 0.89 | 0.82 | 198 |
| Improved YOLOv8 | 0.93 | 0.92 | 0.86 | 212 |
| Model | mAP@0.5/% | mAP@0.5-0.95/% | FPS |
|---|---|---|---|
| YOLOv8n+CIOU | 96.7 | 84.6 | 202 |
| YOLOv8n+DIOU | 96.8 | 85.7 | 206 |
| YOLOv8n+GIOU | 96.5 | 84.2 | 208 |
| YOLOv8n+SIOU | 96.9 | 86.3 | 209 |
| AFN | SODL | SIOU | AP50(%) | FPS |
|---|---|---|---|---|
| × | × | × | 96.7 | 210 |
| √ | × | × | 96.8 | 215 |
| × | √ | × | 96.6 | 156 |
| × | × | √ | 96.9 | 201 |
| √ | √ | √ | 97.0 | 212 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, B.; Jiang, A.; Shen, J.; Liu, J. Research on Rapid Recognition of Moving Small Targets by Robotic Arms Based on Attention Mechanisms. Appl. Sci. 2024, 14, 3975. https://doi.org/10.3390/app14103975
Cao B, Jiang A, Shen J, Liu J. Research on Rapid Recognition of Moving Small Targets by Robotic Arms Based on Attention Mechanisms. Applied Sciences. 2024; 14(10):3975. https://doi.org/10.3390/app14103975
Chicago/Turabian StyleCao, Boyu, Aishan Jiang, Jiacheng Shen, and Jun Liu. 2024. "Research on Rapid Recognition of Moving Small Targets by Robotic Arms Based on Attention Mechanisms" Applied Sciences 14, no. 10: 3975. https://doi.org/10.3390/app14103975
APA StyleCao, B., Jiang, A., Shen, J., & Liu, J. (2024). Research on Rapid Recognition of Moving Small Targets by Robotic Arms Based on Attention Mechanisms. Applied Sciences, 14(10), 3975. https://doi.org/10.3390/app14103975