


Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities

 ,
,
Abstract
1. Introduction
2. Related Work
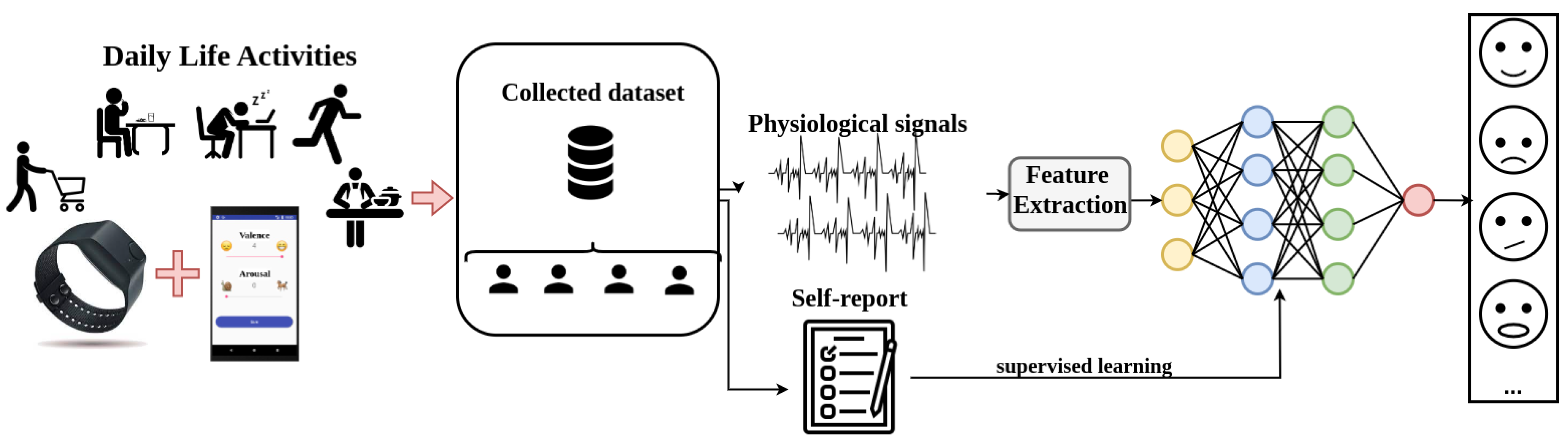
3. Emotional State Monitoring Methodology
3.1. Sensor Description
- Photoplethysmogram (PPG) sensor. This sensor measures the blood volume pulse (BVP), i.e., the variation of volume of arterial blood under the skin resulting from the heart cycle, which is sampled at . This signal is used to derive the heart rate variability (HRV) which is computed by a built-in internal function within the wearable device. The sampling rate corresponding to the HRV signal is 1 .
- Electrodermal activity (EDA) sensor. This sensor measures the variations in electrical conductance of the skin as a response to sweat secretion, which is a potential response of the autonomic nervous system to a stimulus. Data are sampled at a fixed frequency of 4 . This signal is filtered using a 3rd order low-pass Butterworth filter with a cut-off frequency of . In addition, the signal is decomposed into two signals: the skin conductance level (SCL), and the skin conductance response (SCR) [38].
- Infrared thermophile sensor. This sensor measures the peripheral skin temperature variations. Data are sampled at a frequency of 4 .
- 3-axis accelerometer. This sensor records wrist motion data in the carrier’s x, y, and z axes, which are sampled at 32 . Additionally, we calculate the Euclidean norm of the three collected axes. Finally, we apply a Butterworth filter with cut-off frequencies of and 410 [39].
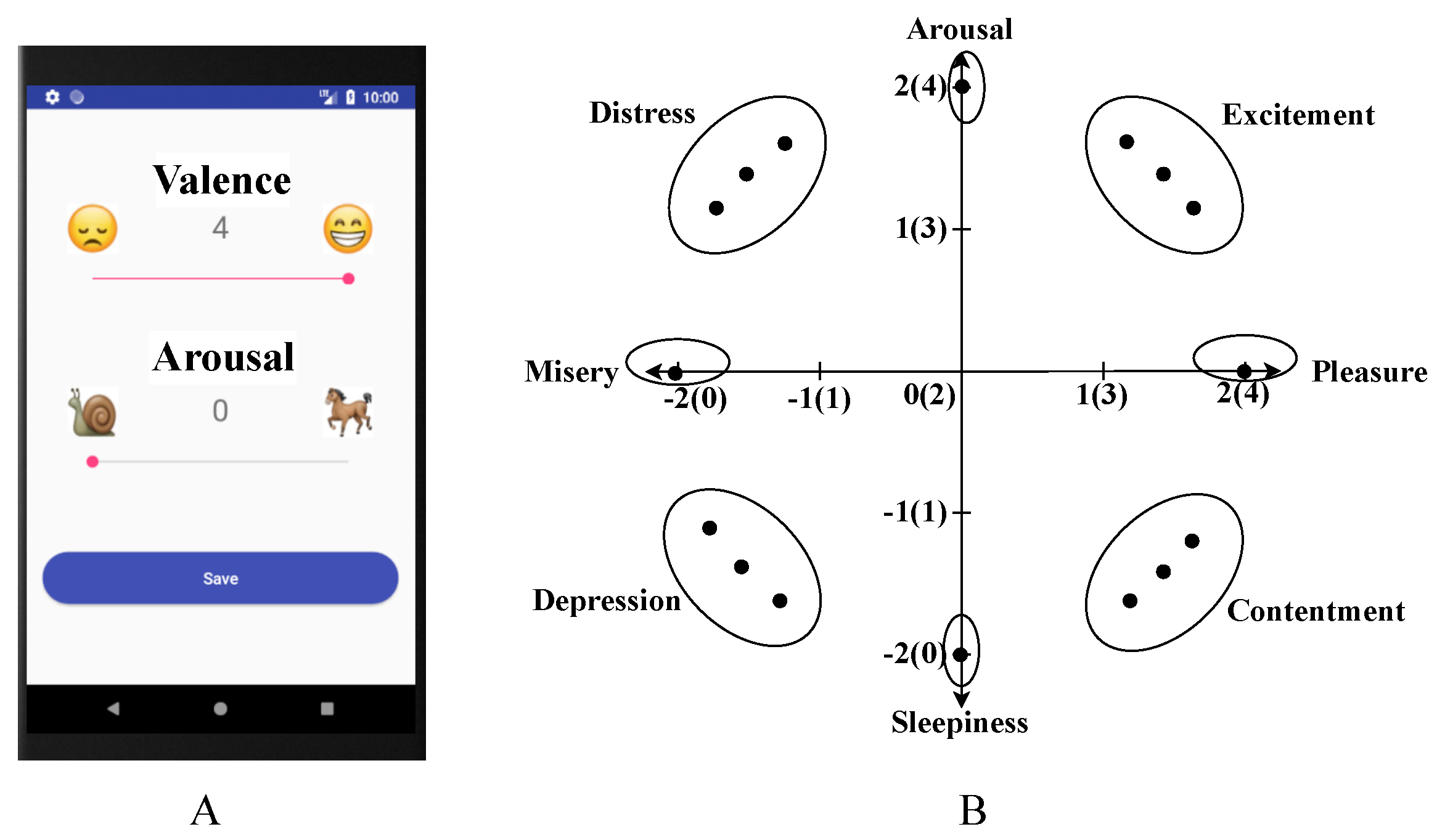
3.2. Data Annotation
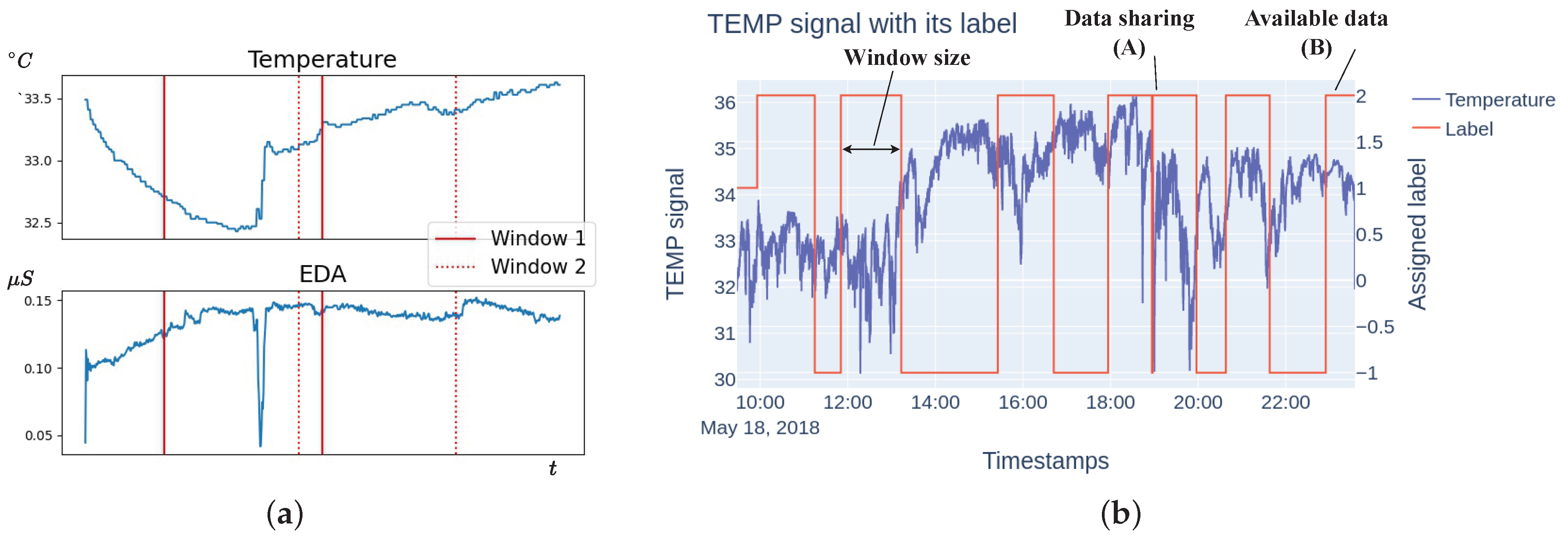
3.3. Dataset Construction
4. Feature Engineering for Affection Recognition
4.1. Feature Extraction and Labeling
4.2. Feature Selection
4.2.1. Scalable Hypothesis Test Feature Selection
- The training set with feature size 7083, is bagged into Z disjoints subsets .
- We select features from each subset and obtained Z vectors of selected features using the scalable hypothesis method.
- We search for the common features among all vectors obtaining the final feature vector .
4.2.2. Mutual Information Feature Selection
| Algorithm 1 Feature selection based on mutual information |
|
5. Emotional Predictive Models
5.1. Classification
5.2. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- United Nations. Population Division. Available online: https://www.un.org/development/desa/pd/ (accessed on 14 May 2021).
- Mozos, O.M.; Galindo, C.; Tapus, A. Guest-Editorial Computer-Based Intelligent Technologies for Improving the Quality of Life. IEEE J. Biomed. Health Inform. (JBHI) 2015, 19, 4–5. [Google Scholar] [CrossRef] [PubMed]
- EUROSTAT. EUROSTAT Statistics Explained. Available online: https://ec.europa.eu/eurostat/statistics-explained (accessed on 12 May 2021).
- Pech, H.G.C.; Rena, E.K.C. Depression, self-esteem and anxiety in the elderly: A comparative study. Enseñanza E Investig. En Psicol. 2004, 9, 257–270. [Google Scholar]
- World Health Organization. Mental Health. Available online: https://www.who.int (accessed on 14 May 2021).
- Clair, R.; Gordon, M.; Kroon, M.; Reilly, C. The effects of social isolation on well-being and life satisfaction during pandemic. Humanit. Soc. Sci. Commun. 2021, 8, 28. [Google Scholar] [CrossRef]
- McCollam, A.; O’Sullivan, C.; Mukkala, M.; Stengård, E.; Rowe, P. Mental Health in the EU—Key Facts, Figures, and Activities; European Communities: Brussels, Belgium, 2016. [Google Scholar]
- Mental Health Europe. Ageing and Mental Health—A Forgotten Matter. Available online: https://www.mhe-sme.org/ageing-and-mental-health-a-forgotten-matter/ (accessed on 14 May 2021).
- Organisation for Economic Co-Operation and Development. Health Workforce. Available online: https://www.oecd.org/health/health-systems/workforce.htm (accessed on 14 May 2021).
- Picard, R.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef]
- Munezero, M.; Montero, C.S.; Sutinen, E.; Pajunen, J. Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Trans. Affect. Comput. 2014, 5, 101–111. [Google Scholar] [CrossRef]
- Empatica. Available online: https://www.empatica.com (accessed on 1 March 2022).
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Bautista-Salinas, D.; González, J.R.; Méndez, I.; Mozos, O.M. Monitoring and Prediction of Mood in Elderly People during Daily Life Activities. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 6930–6934. [Google Scholar] [CrossRef]
- Kosti, R.; Alvarez, J.M.; Recasens, A.; Lapedriza, A. Emotion recognition in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1667–1675. [Google Scholar]
- Badal, V.D.; Graham, S.A.; Depp, C.A.; Shinkawa, K.; Yamada, Y.; Palinkas, L.A.; Kim, H.C.; Jeste, D.V.; Lee, E.E. Prediction of loneliness in older adults using natural language processing: Exploring sex differences in speech. Am. J. Geriatr. Psychiatry 2021, 29, 853–866. [Google Scholar] [CrossRef] [PubMed]
- Bhakre, S.K.; Bang, A. Emotion recognition on the basis of audio signal using Naive Bayes classifier. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 2363–2367. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Shah, R.V.; Grennan, G.; Zafar-Khan, M.; Alim, F.; Dey, S.; Ramanathan, D.; Mishra, J. Personalized machine learning of depressed mood using wearables. Transl. Psychiatry 2021, 11, 338. [Google Scholar] [CrossRef]
- Domínguez-Jiménez, J.A.; Campo-Landines, K.C.; Martínez-Santos, J.C.; Delahoz, E.J.; Contreras-Ortiz, S.H. A machine learning model for emotion recognition from physiological signals. Biomed. Signal Process. Control 2020, 55, 101646. [Google Scholar] [CrossRef]
- Shu, L.; Yu, Y.; Chen, W.; Hua, H.; Li, Q.; Jin, J.; Xu, X. Wearable emotion recognition using heart rate data from a smart bracelet. Sensors 2020, 20, 718. [Google Scholar] [CrossRef]
- Fernández, A.P.; Leenders, C.; Aerts, J.M.; Berckmans, D. Emotional States versus Mental Heart Rate Component Monitored via Wearables. Appl. Sci. 2023, 13, 807. [Google Scholar] [CrossRef]
- Pollreisz, D.; TaheriNejad, N. A simple algorithm for emotion recognition, using physiological signals of a smart watch. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Republic of Korea, 11–15 July 2017; pp. 2353–2356. [Google Scholar] [CrossRef]
- Li, R.; Liu, Z. Stress detection using deep neural networks. BMC Med. Inform. Decis. Mak. 2020, 20, 285. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 400–408. [Google Scholar]
- Daher, K.; Fuchs, M.; Mugellini, E.; Lalanne, D.; Abou Khaled, O. Reduce stress through empathic machine to improve HCI. In Proceedings of the International Conference on Human Interaction and Emerging Technologies, Virtual, 27–29 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 232–237. [Google Scholar]
- Bulagang, A.F.; Mountstephens, J.; Teo, J. Multiclass emotion prediction using heart rate and virtual reality stimuli. J. Big Data 2021, 8, 12. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, Z.; Yu, Z.; Guo, B. EmotionSense: Emotion recognition based on wearable wristband. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 346–355. [Google Scholar]
- Larradet, F.; Niewiadomski, R.; Barresi, G.; Caldwell, D.G.; Mattos, L.S. Toward Emotion Recognition From Physiological Signals in the Wild: Approaching the Methodological Issues in Real-Life Data Collection. Front. Psychol. 2020, 11, 1111. [Google Scholar] [CrossRef]
- Menghini, L.; Gianfranchi, E.; Cellini, N.; Patron, E.; Tagliabue, M.; Sarlo, M. Stressing the accuracy: Wrist-worn wearable sensor validation over different conditions. Psychophysiology 2019, 56, e13441. [Google Scholar] [CrossRef]
- Can, Y.S.; Chalabianloo, N.; Ekiz, D.; Fernández-Álvarez, J.; Repetto, C.; Riva, G.; Iles-Smith, H.; Ersoy, C. Real-Life Stress Level Monitoring Using Smart Bands in the Light of Contextual Information. IEEE Sens. J. 2020, 20, 8721–8730. [Google Scholar] [CrossRef]
- Pedrelli, P.; Fedor, S.; Ghandeharioun, A.; Howe, E.; Ionescu, D.F.; Bhathena, D.; Fisher, L.B.; Cusin, C.; Nyer, M.; Yeung, A.; et al. Monitoring Changes in Depression Severity Using Wearable and Mobile Sensors. Front. Psychiatry 2020, 11, 584711. [Google Scholar] [CrossRef]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time Series Feature Extraction on basis of Scalable Hypothesis tests (tsfresh—A Python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, T.; Li, T. Detecting epileptic seizures in EEG signals with complementary ensemble empirical mode decomposition and extreme gradient boosting. Entropy 2020, 22, 140. [Google Scholar] [CrossRef] [PubMed]
- Geraedts, V.; Koch, M.; Contarino, M.; Middelkoop, H.; Wang, H.; van Hilten, J.; Bäck, T.; Tannemaat, M. Machine learning for automated EEG-based biomarkers of cognitive impairment during Deep Brain Stimulation screening in patients with Parkinson’s Disease. Clin. Neurophysiol. 2021, 132, 1041–1048. [Google Scholar] [CrossRef]
- Spathis, D.; Servia-Rodriguez, S.; Farrahi, K.; Mascolo, C.; Rentfrow, J. Passive mobile sensing and psychological traits for large scale mood prediction. In Proceedings of the 13th EAI International Conference on Pervasive Computing Technologies for Healthcare, Trento, Italy, 20–23 May 2019; pp. 272–281. [Google Scholar]
- Bertsimas, D.; Mingardi, L.; Stellato, B. Machine Learning for Real-Time Heart Disease Prediction. IEEE J. Biomed. Health Inform. 2021, 25, 3627–3637. [Google Scholar] [CrossRef]
- Zangróniz, R.; Martínez-Rodrigo, A.; Pastor, J.M.; López, M.T.; Fernández-Caballero, A. Electrodermal Activity Sensor for Classification of Calm/Distress Condition. Sensors 2017, 17, 2324. [Google Scholar] [CrossRef]
- Vandecasteele, K.; Lázaro, J.; Cleeren, E.; Claes, K.; Van Paesschen, W.; Van Huffel, S.; Hunyadi, B. Artifact Detection of Wrist Photoplethysmograph Signals. In Proceedings of the BIOSIGNALS, 2018, Funchal, Madeira, Portugal, 19–21 January 2018; pp. 182–189. [Google Scholar]
- Shiffman, S.; Stone, A.A.; Hufford, M.R. Ecological Momentary Assessment. Annu. Rev. Clin. Psychol. 2008, 4, 1–32. [Google Scholar] [CrossRef]
- Carson, R.L.; Weiss, H.M.; Templin, T.J. Ecological momentary assessment: A research method for studying the daily lives of teachers. Int. J. Res. Method Educ. 2010, 33, 165–182. [Google Scholar] [CrossRef]
- Sultana, M.; Al-Jefri, M.; Lee, J. Using machine learning and smartphone and smartwatch data to detect emotional states and transitions: Exploratory study. JMIR MHealth UHealth 2020, 8, e17818. [Google Scholar] [CrossRef] [PubMed]
- Giannakaki, K.; Giannakakis, G.; Farmaki, C.; Sakkalis, V. Emotional state recognition using advanced machine learning techniques on EEG data. In Proceedings of the 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; pp. 337–342. [Google Scholar]
- Likamwa, R.; Liu, Y.; Lane, N.D.; Zhong, L. MoodScope: Building a Mood Sensor from Smartphone Usage Patterns. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications and Services, Taipei, Taiwan, 25–28 June 2013; pp. 257–270. [Google Scholar]
- Lang, P.J. Cognition in emotion: Concept and action. Emot. Cogn. Behav. 1984, 191, 228. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Plarre, K.; Raij, A.; Hossain, S.M.; Ali, A.A.; Nakajima, M.; Al’Absi, M.; Ertin, E.; Kamarck, T.; Kumar, S.; Scott, M.; et al. Continuous inference of psychological stress from sensory measurements collected in the natural environment. In Proceedings of the 10th ACM/IEEE International Conference on Information Processing in Sensor Networks, Milano, Italy, 4–6 May 2011; pp. 97–108. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Healey, J.; Nachman, L.; Subramanian, S.; Shahabdeen, J.; Morris, M. Out of the lab and into the fray: Towards modeling emotion in everyday life. In Proceedings of the International Conference on Pervasive Computing, Helsinki, Finland, 17–20 May 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 156–173. [Google Scholar]
- Christ, M.; Kempa-Liehr, A.; Feindt, M. Distributed and parallel time series feature extraction for industrial big data applications. arXiv 2016, arXiv:1610.07717. [Google Scholar]
- Frijda, N.H.; Mesquita, B.; Sonnemans, J.; Van Goozen, S. The Duration of Affective Phenomena or Emotions, Sentiments and Passions; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Stitson, M.; Weston, J.; Gammerman, A.; Vovk, V.; Vapnik, V. Theory of support vector machines. Univ. Lond. 1996, 117, 188–191. [Google Scholar]
- Massey Jr, F.J. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Schaffernicht, E.; Gross, H.M. Weighted mutual information for feature selection. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 181–188. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Bao, G.; Zhuang, N.; Tong, L.; Yan, B.; Shu, J.; Wang, L.; Zeng, Y.; Shen, Z. Two-level domain adaptation neural network for EEG-based emotion recognition. Front. Hum. Neurosci. 2021, 14, 605246. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, J.; Morris, R.R.; Picard, R.W. Call center stress recognition with person-specific models. In Proceedings of the Affective Computing and Intelligent Interaction: 4th International Conference, ACII 2011, Memphis, TN, USA, 9–12 October 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 125–134. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P1 | P2 | P3 | P4 | |
|---|---|---|---|---|
| Age | 67 | 55 | 60 | 63 |
| Gender | Male | Female | Male | Female |
| Days | 9 | 15 | 12 | 13 |
| Total EMAs | 42 | 57 | 64 | 46 |
| Avg. EMAs | 4.67 | 3.80 | 5.33 | 3.54 |
| Model | Parameter Setting |
|---|---|
| SVM | C:[1,3,5,7,9]; :[1e-2, 1, in steps of 0.1] |
| RF | n_estimators: [200, 500]; max_features: [’sqrt’]; max_depth: [2, 4, 8]; criterion: [’gini’,’entropy’] |
| MLP | hidden_layer_sizes: [(250, 150), (150,)]; activation: [’tanh’, ’relu’]; solver: [’adam’]; learning_rate: [’adaptive’] |
| SVM | RF | MLP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | ||||||||||||
| P2 | ||||||||||||
| P3 | ||||||||||||
| P4 | ||||||||||||
| Average | ||||||||||||
| SVM | RF | MLP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | ||||||||||||
| P2 | ||||||||||||
| P3 | ||||||||||||
| P4 | ||||||||||||
| Average | ||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutierrez Maestro, E.; De Almeida, T.R.; Schaffernicht, E.; Martinez Mozos, Ó. Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities. Appl. Sci. 2023, 13, 5637. https://doi.org/10.3390/app13095637
Gutierrez Maestro E, De Almeida TR, Schaffernicht E, Martinez Mozos Ó. Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities. Applied Sciences. 2023; 13(9):5637. https://doi.org/10.3390/app13095637
Chicago/Turabian StyleGutierrez Maestro, Eduardo, Tiago Rodrigues De Almeida, Erik Schaffernicht, and Óscar Martinez Mozos. 2023. "Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities" Applied Sciences 13, no. 9: 5637. https://doi.org/10.3390/app13095637
APA StyleGutierrez Maestro, E., De Almeida, T. R., Schaffernicht, E., & Martinez Mozos, Ó. (2023). Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities. Applied Sciences, 13(9), 5637. https://doi.org/10.3390/app13095637