1. Introduction
Cloud computing is becoming a natural solution to the problem of expanding computational needs due to its on-demand, low-cost, and virtually unlimited resources for deploying various services [
1]. The NIST SPI [
2] classifies cloud services into three categories, namely Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Private and public clouds can be developed using different implementations of cloud software, with OpenStack [
3] being an open-source cloud management platform that offers a secure and reliable IaaS. To isolate workloads and regulate resource usage, cloud computing heavily employs virtual machines (VMs). Containers present a technology for improving the productivity and code portability in cloud infrastructures. Docker [
4] has emerged as the standard runtime, image format, and build system for Linux containers because its layered file system requires less disk space and I/O compared to the equivalent VM disk images.
The scalable cloud resources can be dynamically allocated on demand according to consumer requirements and preferences defined in service level agreement (SLA). However, cloud resources can cause severe degradation of SaaS performance due to their heterogeneity or co-location issues [
1]. Different types of heterogeneous VMs [
5] present challenges to load balancing of parallel MPI-based jobs that are in frequent communication. In resource-aware partitioning, the computational domain is divided into unequal partitions or subsets of particles according to weights of heterogeneous resources [
6]. Generally, heterogeneity weights of parallel computations cannot be exactly defined a priori according to the number of instructions performed by CPU per second because of domain decomposition issues, communication overhead, and limitations of memory bandwidth. Synthetic benchmarks conducted on cloud systems typically fail to consider all the essential factors. Therefore, the application-specific tests need to be performed to define heterogeneity weights before the production runs of parallel computations on heterogeneous resources.
Virtual resources can create further issues if they are co-located on the same machine and compete for the same resources, such as memory bandwidth [
7]. Common virtualization technologies do not ensure isolation of the cache usage and memory bandwidth of individual VMs accommodated by the same physical machine, leading to contention between them. If one of the VMs excessively uses memory bandwidth, the performance of memory bandwidth bound SaaS, running on the other VM, may significantly degrade. Few cloud providers [
8] offers L3 cash and memory bandwidth isolation based on existing hardware technologies [
9] or software solutions [
10]. Unfortunately, existing solutions cannot be easily used for managing memory bandwidth with all virtualization technologies in popular cloud environments.
The use of clouds to deploy computationally demanding scientific codes for high performance computations and visualization offers better resource exploitation and greater user mobility. Consequently, cloud resources are perceived as a promising avenue for future advances in the area of scientific computations [
11]. The discrete element method (DEM), originally developed by Cundall and Strack [
12], describes particulate media by considering the motion and deformation behavior of individual particles. Currently, the DEM is acknowledged to be an effective method not limited to the analysis of non-cohesive granular materials but extended to cohesive powders, fluidized environments, rock cutting, and couplings with different multiphysics. However, the simulation of systems at the particle level of detail has the disadvantage of making the DEM computationally very expensive. Naturally, to solve the industrial-scale problems, parallel computing on cloud infrastructures has become an obvious way to increase computational capabilities. However, cloud computing still lacks case studies and best practices on how to efficiently run parallel memory bandwidth bound SaaS on heterogeneous co-located virtual cloud resources.
This paper presents the runtime adaptation of parallel DEM SaaS to heterogeneous co-located resources of the private OpenStack cloud. The hybrid parallelization of memory bandwidth bound DEM SaaS was developed by using OpenCL for shared-memory multicore machines and MPI for weighted repartitioning on distributed-memory architectures. The remaining paper is organized as follows:
Section 2 analyzes the related works,
Section 3 describes the developed DEM SaaS based on hybrid parallelization,
Section 4 discusses the results of SaaS performance attained on heterogeneous co-located cloud resources, and the conclusions are given in
Section 5.
2. The Related Works
Previous studies [
13,
14,
15] have already examined the performance of computation-intensive benchmarks on virtual machines and lightweight containers. However, few studies include the performance analysis of parallel MPI-based applications on heterogeneous cloud resources. Gang applications [
16] are parallel jobs that frequently communicate and must execute simultaneously. Moschakis and Karatza [
17] evaluated gang scheduling performance in the Amazon EC2 cloud. Hao et al. [
18] proposed a 0–1 integer programming for the gang scheduling. Mohammadi et al. [
19] assessed the parallel performance of the Linpack benchmark on public clouds. The obtained results demonstrated that the performance per computing core on the public clouds could be comparable to modern traditional supercomputing systems. However, the discussed studies did not investigate the impact of heterogeneous cloud resources and partitioning issues on parallel performance.
In cloud computing, the task scheduling, virtual machine load balancing, and resource provisioning problems formulated from the cloud provider’s perspective have received a lot of attention. Shahid et al. [
20] evaluated the performance of existing load balancing algorithms with different service broker policies for cloud computing. Particle swarm optimization, round robin, equally spread current execution, and throttled load balancing algorithms were investigated, taking into account optimized response time, data center processing time, virtual machine costs, data transfer costs, and total cost. Heidari et al. [
21] introduced a deep post-decision-state learning algorithm for dynamic IoT-edge-cloud offloading scenarios. The proposed technique outperformed multiple benchmarks in terms of delay, job failure rate, cost, computational overhead, and energy consumption. Bojato et al. [
22] presented a flexible cloud-based software architecture engineered to provide an efficient and robust password guessability service. A comprehensive literature review [
23] addressed resilience and dependability management issues in distributed environments, namely cloud, edge, fog, internet of things, internet of drones, and internet of vehicles. However, parallel MPI-based applications with parallel frequently communicating jobs were rarely considered. Moreover, most researchers balanced the workload on virtual machines of an entire subsystem rather than the enhanced performance of a parallel frequently communicating application on heterogeneous virtual resources.
Early attempts to parallelize DEM computations were based on force decomposition techniques or simple variants of the domain decomposition methods. Washington and Meegoda [
24] divided the interparticle force computation among the processors. The domain decomposition methods partition the computational domain into particle subsets, each being assigned to a processor. Kačeniauskas et al. [
25] used the static domain decomposition with regular partitions for parallel DEM computations on gLite grid infrastructure. Wang et al. [
26] applied domain decomposition with ghost layers of particles for the DEM and large eddy simulation. However, the dynamically changing workload configuration may lead to load imbalance and low parallel efficiency. More flexible but more complicated dynamic domain decomposition is one of the solutions to this load balance problem that allows higher scalability in parallel computing performance. In the case of the DEM, Owen et al. [
27] used a topological dynamic domain decomposition method based on a dynamic graph repartitioning. Walther and Sbalzarini [
28] presented large-scale parallel simulations of granular flows, employing adaptive domain decomposition based on the multilevel k-way graph partitioning method [
29]. Markauskas and Kačeniauskas [
30] applied k-way graph partitioning and the recursive coordinate bisection (RCB) [
31] to solve the hopper discharge problem. Higher parallel speedup was achieved by using RCB, which confirmed the efficiency of conceptually simpler geometric methods for particle simulations [
6]. The parallel efficiency of 0.87 was achieved on 2048 cores, modeling the hopper filled with 5.1 × 10
6 particles.
Distributed hardware systems based on common multicore nodes have evolved to heterogeneous hybrid architectures, embodying both shared and distributed memories. Hybrid parallelization of DEM codes can lead to improved load balance, decreased communication overhead, and reduced memory consumption on contemporary shared- and distributed-memory systems. Liu et al. [
32] described a hybrid MPI/OpenMP parallelization of their MFIX-DEM solver, emphasizing the importance of data locality and thread placement policies in scaling OpenMP implementation to large core counts. The speed increased 185 times on 256 cores of their hybrid parallelization compared to 138 times of a standalone MPI computation with 5.12 million particles. The LIGGGHTS DEM software [
33] employed a recursive multi-sectioning algorithm for global domain decomposition and an RCB method for defining subsets of particles assigned to threads. Experiments of the load balancing with different MPI/OpenMP configurations with up to 128 threads were presented. Cintra et al. [
34] demonstrated a hybrid MPI/OpenMP parallelization of DEMOOP software, employing the RCB method for domain partitioning and various shared-memory implementations for particle sorting and distribution. However, the parallel efficiency of the software rapidly drops, increasing the number of cores up to 64. Incardona et al. [
35] presented the open-source framework OpenFPM for shared-memory and distributed-memory implementations of particle and particle-mesh codes. This scalable framework provides methods for domain decomposition, dynamic load balancing, and internode communication. Yan and Regueiro [
36] examined the hybrid MPI/OpenMP mapping schemes and influences of the memory/cache hierarchy for 3D DEM simulations of ellipsoidal and poly-ellipsoidal particles. However, the pure MPI implementation achieved a higher efficiency than the hybrid MPI/OpenMP software. In the discussed research, only OpenMP was used for shared-memory programming.
Compared to the CPU-based parallelization, GPU has a higher parallel structure, which makes it very efficient for particle-based algorithms, where large blocks of data can be processed in parallel. Software environments, such as CUDA or OpenCL [
37], are targeted at general-purpose GPU (GPGPU) programming. Govender et al. [
38] designed the modular Blaze-DEMGPU framework for the GPU architecture. Kelly et al. [
39] adopted a dimensionalization process combined with mixed-precision data to simulate 3D scenarios with up to 710 million spherical frictionless particles. To achieve a higher speedup ratio for a larger number of particles, a few efforts have been made to use the combined GPU and MPI technology. Xu et al. [
40] achieved the quasi-real-time simulation of an industrial rotating drum, when about 9.6 × 10
6 particles were treated with 270 GPUs. The one-dimensional domain decomposition with multiple GPUs was applied to the simulation of 128 million particles by Tian et al. [
41]. The GPU-based DEM combined with MPI has been applied by Gan et al. [
42] to study granular flows in the ironmaking industry. However, the communication overhead among GPUs significantly reduces the parallel performance because of the costly data transfer to the CPU memory and the MPI message passing among different nodes. It is worth noting that only CUDA was employed for shared-memory programming on the GPU together with MPI technology for distributed-memory communications in the case of DEM software.
Very few attempts to exploit low-cost flexible cloud resources for computationally demanding memory bandwidth bound DEM software [
43] have been reported in the academic literature [
44,
45,
46]. Rescale’s cloud platform offers the commercial EDEM software for computations of particle systems by the DEM [
44]. The open-source DEM code MercuryDPM [
45] was also deployed on a cloud computing platform. Bystrov et al. [
46] developed parallel MPI-based DEM software for distributed-memory architectures and deployed SaaS on the OpenStack cloud. The presented performance analysis revealed MPI communication issues and overhead caused by processes of the OpenStack services Nova and Zun. However, the heterogeneity of cloud resources and co-location issues were not considered.
DEM computations were rarely performed on heterogeneous resources, but heterogeneous architectures were often employed for computationally intensive applications in other research areas [
47]. Danovaro et al. [
47] analyzed the performance of widely used applications, such as FFT, convolution, and N-body simulation on a multicore cluster node with or without GPUs. In plasma plume simulations with the particle-in-cell model, Araki et al. [
48] proposed a patch-based dynamic load balancing method with over-decomposition and a Hilbert space-filling curve. For microscopy image analysis, Barreiros et al. [
49] developed a cost-aware data partitioning strategy, minimizing load imbalance on hybrid CPU-GPU machines. Zhong et al. [
50] optimally distributed the workload of data-parallel scientific applications between heterogeneous computing resources by using functional performance models of processing elements and relevant data partitioning algorithms. Meanwhile, Bystrov et al. [
51] explored the trade-off between execution time and consumed energy for aortic valve computations on a heterogeneous OpenStack cloud, comparing parallel speedups obtained through several partitioning techniques, but did not consider load imbalance and co-located resources.
The related works are listed and compared in
Table 1. The parallel applications that frequently communicate between nodes and must execute simultaneously are indicated in the column “Parallel (internode)”. The parallelization software is provided in the next column. The performance studies on heterogeneous and co-located resources are indicated in the columns named “Heterogeneous resources” and “Co-located resources”, respectively. It can be observed that parallel DEM computations are rarely performed on heterogeneous resources because of increased load imbalance or communication. In other research areas, the parallel frequently communicating applications are more often solved on heterogeneous cloud resources. In distributed cloud environments, parallel frequently communicating applications are rare because of their inherent limitations to achieve high parallel performance and scalability on heterogeneous or co-located resources. To the best of our knowledge, there are no articles on the adaptation of parallel frequently communicating applications to co-located cloud resources in the literature. Excessive usage of memory bandwidth by one virtual resource can substantially reduce the performance of parallel memory bandwidth bound DEM computations on the other resource co-located on the same physical machine.
4. Results and Discussion
To measure the performance of the parallel DEM SaaS, a gravity-packing problem was solved on heterogeneous co-located resources of the OpenStack cloud. The gravity-packing problem was considered because it is commonly employed as a performance benchmark [
33,
46]. The solution domain was assumed to be a cubic container with 1.0 m long edges. Half of the domain was filled with 500,000 monosized particles, using a cubic structure. Then, 10,000 time steps equal to 1.0 × 10
−8 s were performed, which resulted in the physical time interval of 0.0001 s. Physics of the considered problem with the skinning technique required performing repartitioning at each 1000 time steps. The size of the input data file with DEM parameters was negligibly small; therefore, the containers did not transfer data from the object storage in the performed benchmarks.
Six cases of heterogeneous or co-located resources were considered in the performed research. In Case 1, four containers, CN-6700-1, CN-6700-2, CN-6700-3, and CN-6700-4, with different numbers of cores were employed to make the benchmark. CN-6700-4 could perform four times more floating-point operations per second than CN-6700-1 in the case of CPU-bound applications. Thus, the computational performance of the fastest resource was significantly higher than that of the lowest resource. In Case 2, five faster CN-6700-4 containers were supplemented by two slower containers CN-4790-4. Thus, a higher number of faster resources worked together with a lower number of slower resources, but the difference in performance was not high. In Case 3, the powerful container CN-GPU with GPU was used with five CN-6700-4 containers. Thus, one resource, of which the computational performance was significantly higher than that of the others, worked together with a larger number of slower resources.
In the next three cases, each pair of containers was co-located on the same physical node. Parallel computations were carried out on several nodes, but only one of the containers co-located on each node was used by the MPI process. Synthetic stress tests were executed on another container co-located on the same node to investigate the performance decrease in parallel memory bandwidth bound computations on co-located containers. In Case 4, five CN-6700-2 containers solved the considered problem on five nodes of the cloud infrastructure. Five other CN-6700-2 containers were co-located on the same nodes to run stress tests and to verify isolation of containers. The CPU stress test [
56]
based on fast Fourier transform was performed on co-located containers. It was executed on a different number of containers to introduce different heterogeneities and to produce different load imbalances. In Case 5, the same configuration of containers was considered, but the synthetic memory stress test [
56] was carried out on co-located containers. The memory stress test
started two workers, continuously calling mmap/munmap and writing 2 Gbytes to the allocated memory. In Case 6, the same configuration of containers was also considered, but the memory stress test was periodically executed on one co-located container. The periodically variable load was generated, interrupting the fixed periods of the memory stress test by the sleep command lasting 50 s. The periodically executed memory stress test produces the periodically peaking load on co-located containers, which corresponds to a real-world scenario. The ratio of the memory stress time to the whole simulation time, including sleep periods, expresses load frequency and indirectly represents the heterogeneity of co-located resources.
In the performed research, the benchmark execution time was considered as the main metric to evaluate the performance of the runtime adaptive repartitioning. A comparison of the execution time obtained by using the runtime adapted repartitioning with variable weights with that attained by using unweighted repartitioning revealed the gain of runtime adapted repartitioning. The percentage load imbalance measure (1) was used to determine load imbalance and indicate the heterogeneity of resources. The time evolution of the percentage load imbalance measure also showed how efficiently the runtime adapted repartitioning worked. Computational load, particle count, weights, wait time, and communication time can be examined to understand various issues of the repartitioning procedure.
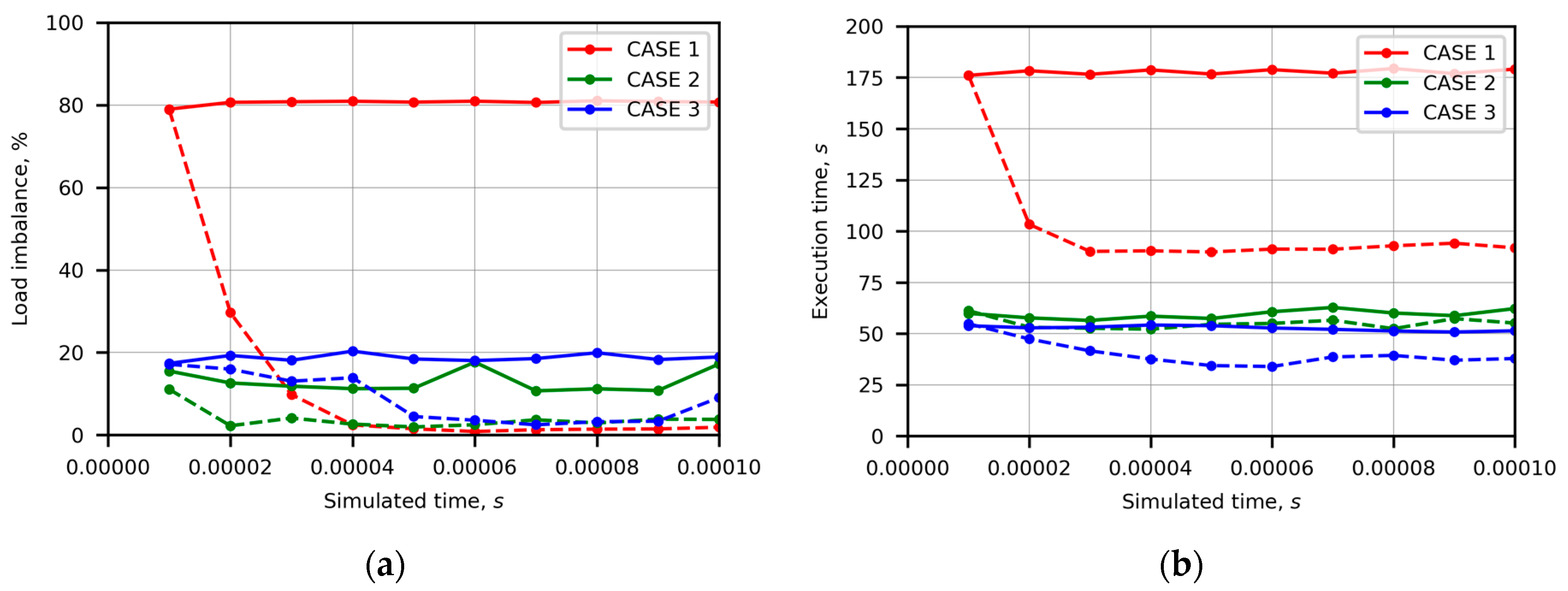
Figure 1 shows the time evolution of the load imbalance (
Figure 1a) and execution time (
Figure 1b) in the three first cases of heterogeneous cloud resources (Case 1, Case 2, and Case 3). The dashed curves represent the results of runtime adapted repartitioning with variable weights, while the solid lines represent that of unweighted repartitioning, which results in partitions of nearly equal size. In Case 1, load imbalance was very high because the theoretical performance of the fastest container CN-6700-4 was four times higher than that of the slowest container CN-6700-1. Runtime adapted repartitioning decreased the execution time up to 48.7% of the execution time obtained without using weights. In Case 2, the load imbalance of computations without weighting varied from 10.7% to 17.6%. The execution time was reduced from 4.9% to 6.7% of the execution time obtained without using weights. Thus, the low heterogeneity of resources indicated by low load imbalance percentage limited the gain of runtime adapted repartitioning. In Case 3, including the container CN-GPU, the load imbalance of computations without weighting was only slightly higher than that observed in Case 2. It varied from 18.0% to 20.3%, which was considerably lower than the load imbalance measured in Case 1. The decrease in the execution time up to 36.1% of the execution time obtained without weighting was observed, which was higher than the decrease obtained in Case 2 but lower than that attained in Case 1. Generally, the employed GPU performs DEM computations significantly faster than the CPU [
43]; therefore, a higher load imbalance percentage as well as a gain in execution time can be expected. Thus, a detailed investigation of other measures and communication issues is required.
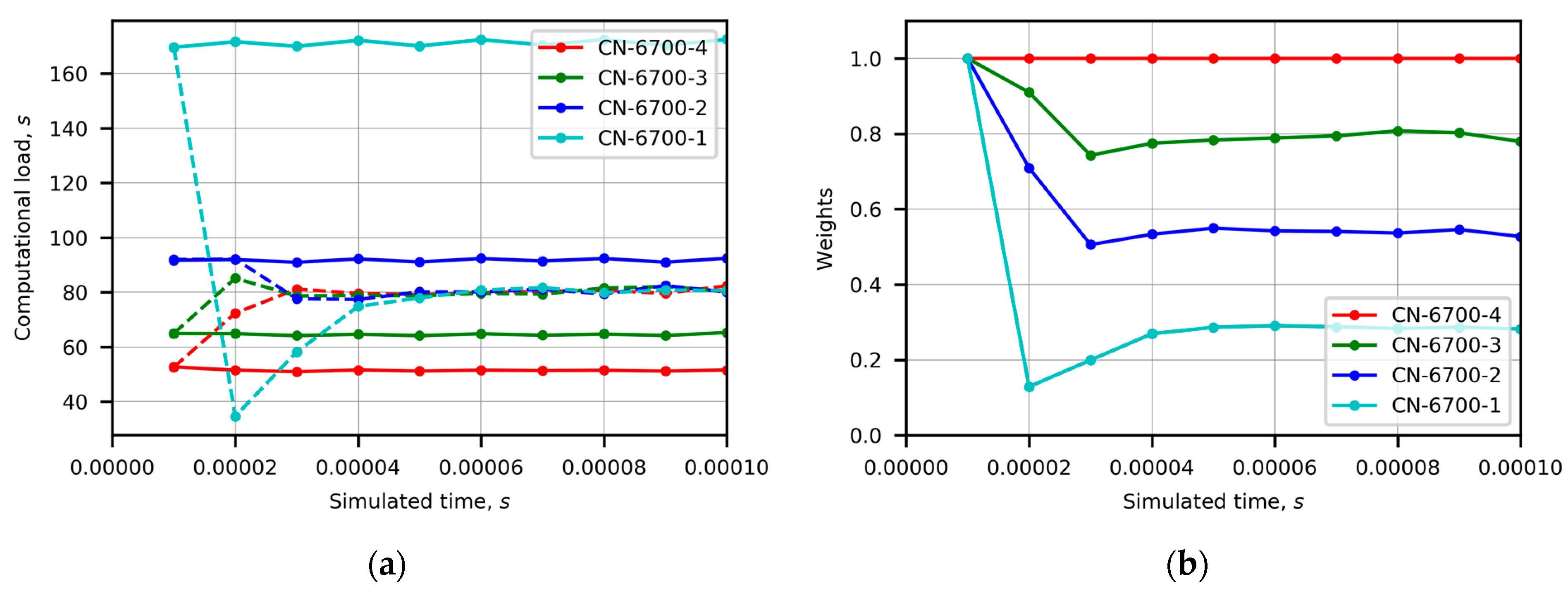
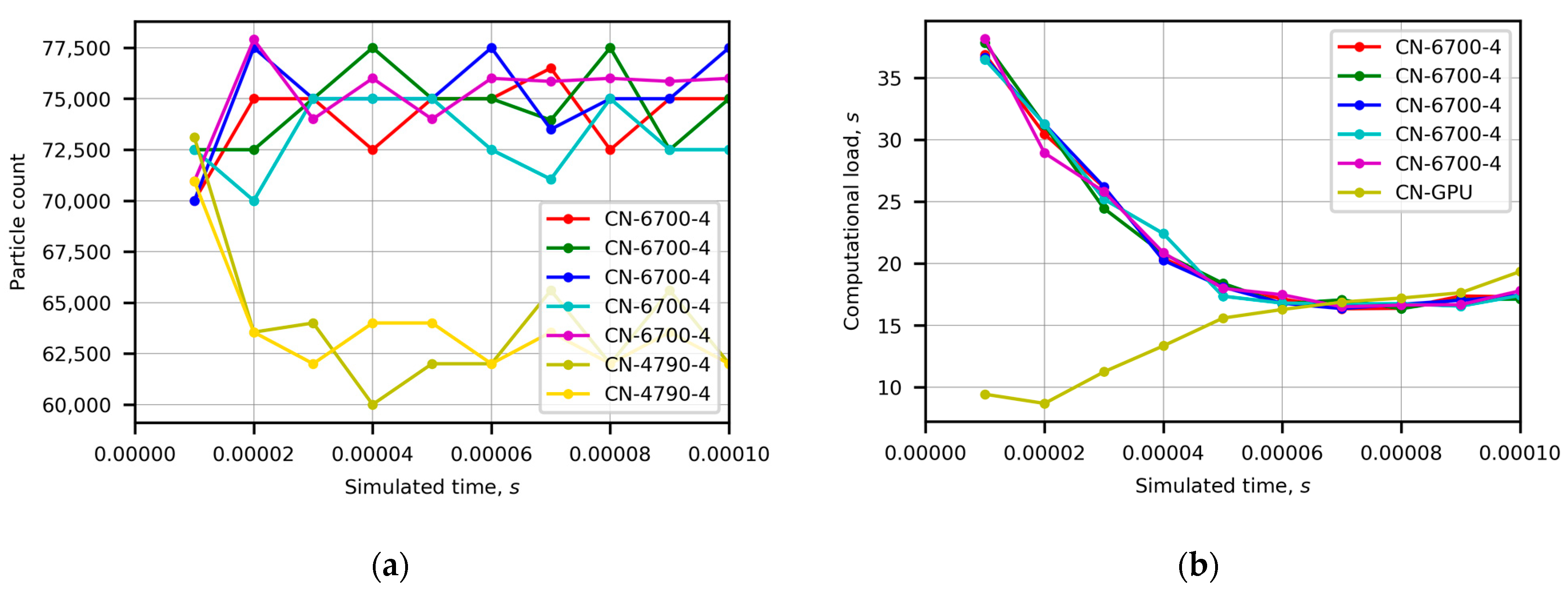
Figure 2 and
Figure 3 present the time evolution of additional measures, such as runtime measured computational load, weights, and particle count. In
Figure 2a, the time evolution of the runtime measured computational load perfectly illustrates runtime adapted repartitioning in comparison with the unweighted repartitioning. Nearly straight solid lines, representing unweighted repartitioning, show four different computational loads. It is worth noting that the load of the slowest container CN-6700-1 was only 3.3 times larger than that of the fastest container CN-6700-4, which was specific to memory bandwidth bound applications. The sudden decrease in one curve indicates severe changes in subsets of particles after repartitioning, which is also confirmed by the variation in weights in
Figure 2b. Three applications of the repartitioning procedure were required for the computational load of four containers to become nearly equal. In
Figure 3, the different heterogeneity cases can be observed.
Figure 3a shows the time evolution of particle count, which is directly related to the computational load, in Case 2. The lowest load imbalance (
Figure 1a) led to the close values of computational load and execution time (
Figure 1b). The observed oscillations of particle count uncovered the undesirable influence of chaotic variations in the system load and performance on the results of runtime adapted repartitioning.
Figure 3b shows the time evolution of the runtime measured computational load in Case 3. Initially, the load of any CN-6700-4 container is approximately 4 times larger than that of the powerful container CN-GPU. The difference in computational loads in Case 1 is lower than that in Case 3 despite the higher load imbalance of Case 1. This can be explained by the fact that the percentage load imbalance Formula (1) compares the maximal load with the averaged load. In Case 3, the load of any slower container serves as the maximal load, while the averaged load is highly influenced by five slower CN-6700-4 containers and reduced by only one powerful container CN-GPU. Anyway, all curves of the computational load approached the average, which was closer to the initial load of the container CN-GPU than the initial loads of the CN-6700-4 containers. It is worth noting that Case 3 required more applications of the repartitioning procedure than Case 1 to make the computational load of all containers nearly equal.
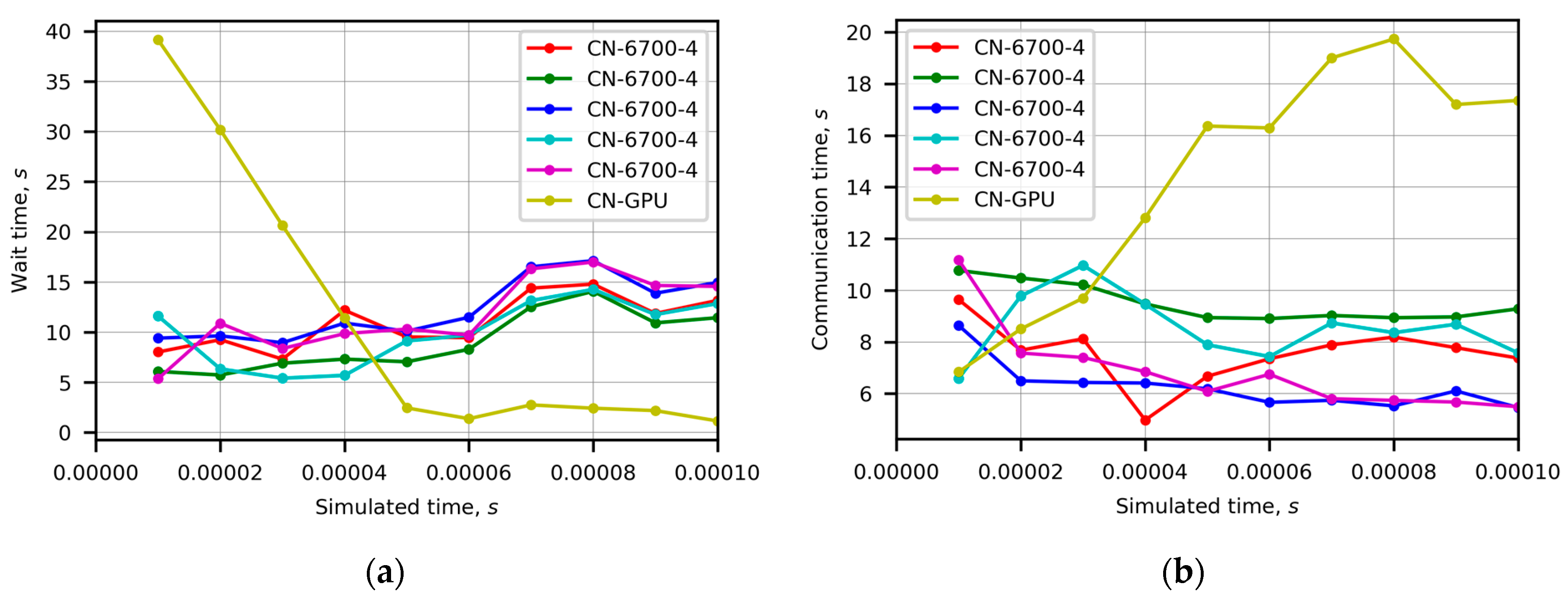
Figure 4 shows time evolution of wait time and communication time in Case 3. At the beginning of the simulation interval, the fastest container CN-GPU completed its computations and waited for the data. The runtime adapted weights increased the computational load of the container, which gradually decreased its wait time (
Figure 4a). However, the increased number of processed particles caused the rise in communication time (
Figure 4b). Communication times of slower containers differed from each other, which revealed partitioning challenges. In the time interval [0.00005, 0.00010] s, the container CN-GPU had so much data of ghost particles to send that other containers must wait for data longer than CN-GPU. In the time interval [0.00006, 0.00009] s, the most intensive communication of the container CN-GPU increased the wait time of other containers even more (
Figure 4a), which caused the rise in the execution time observable in
Figure 1b. Performing repartitioning, the RCB method does not directly optimize internode communication; therefore, communication issues can influence the load balance and overall performance.
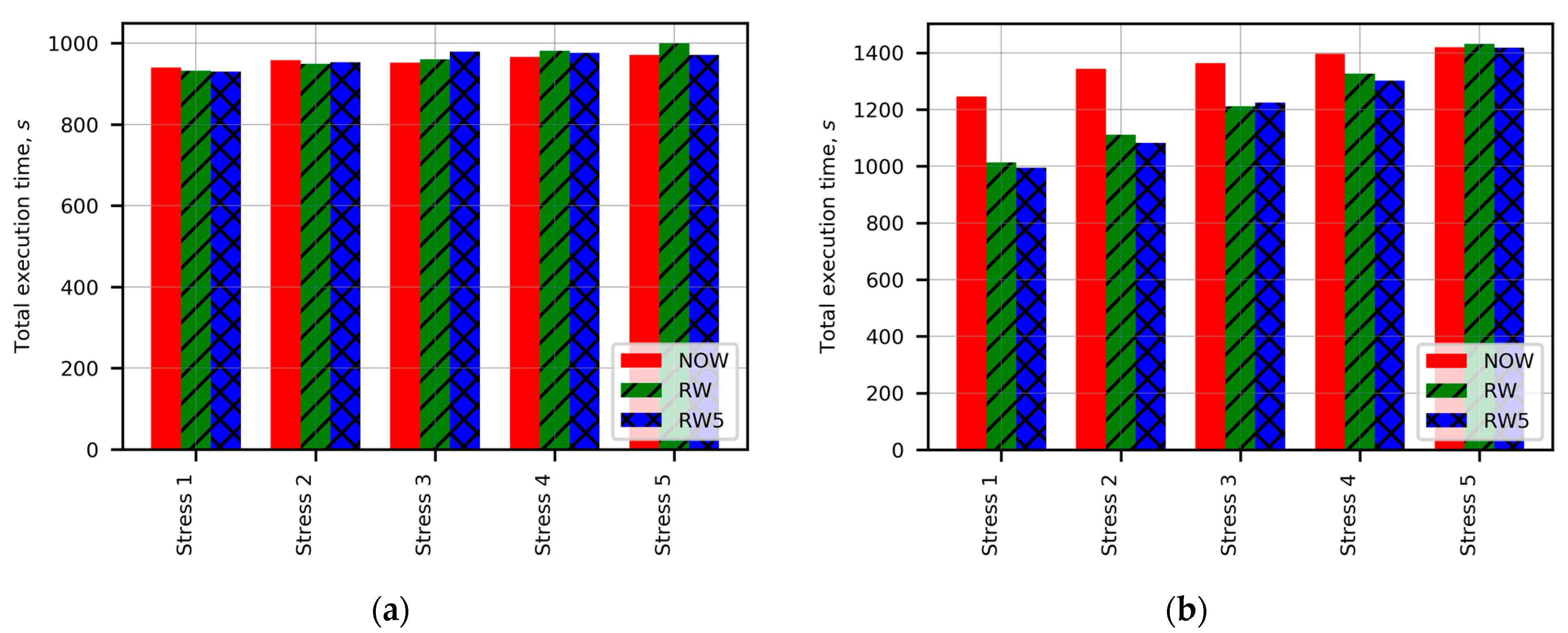
Figure 5a,b show total execution times of DEM SaaS, when the CPU stress test and memory stress test were performed on co-located containers in Case 4 and Case 5, respectively. Stress tests were executed on one, two, three, four, or five co-located containers, which were represented by five different cases on the horizontal axes of charts (the abbreviations “Stress” with relevant numbering). In the legend of columns, the abbreviations “NOW”, “RW”, and “RW5” represent unweighted repartitioning, runtime adapted repartitioning, and runtime adapted repartitioning when weights were updated only if the load imbalance was higher than 5%, respectively. The condition of 5% was used to damp oscillations of repartitioning results caused by small variations in the system load and performance. No significant difference in the results of unweighted and runtime adapted repartitioning can be observed in
Figure 5a. CPU cores of containers were well isolated; therefore, CPU stress tests did not influence the performance of benchmarks performed on co-located containers. In
Figure 5b, the total execution time of benchmarks with runtime adapted repartitioning is substantially shorter than that of benchmarks with unweighted repartitioning. The memory bandwidth of co-located containers was not isolated; therefore, memory stress tests reduced the performance of the co-located containers, causing heterogeneity of resources. It can be observed that the largest gain in runtime adapted repartitioning was achieved in the case of one stressed container. No substantial gain can be observed in the case of five stressed containers, because the performance of all containers was nearly homogeneous in the case of the same memory stress test executed on all five co-located containers. It is worth noting that the condition of 5% reduced the total execution time in the most cases, but the obtained improvement did not exceed 2.5% of the total execution time measured without the condition of 5%.
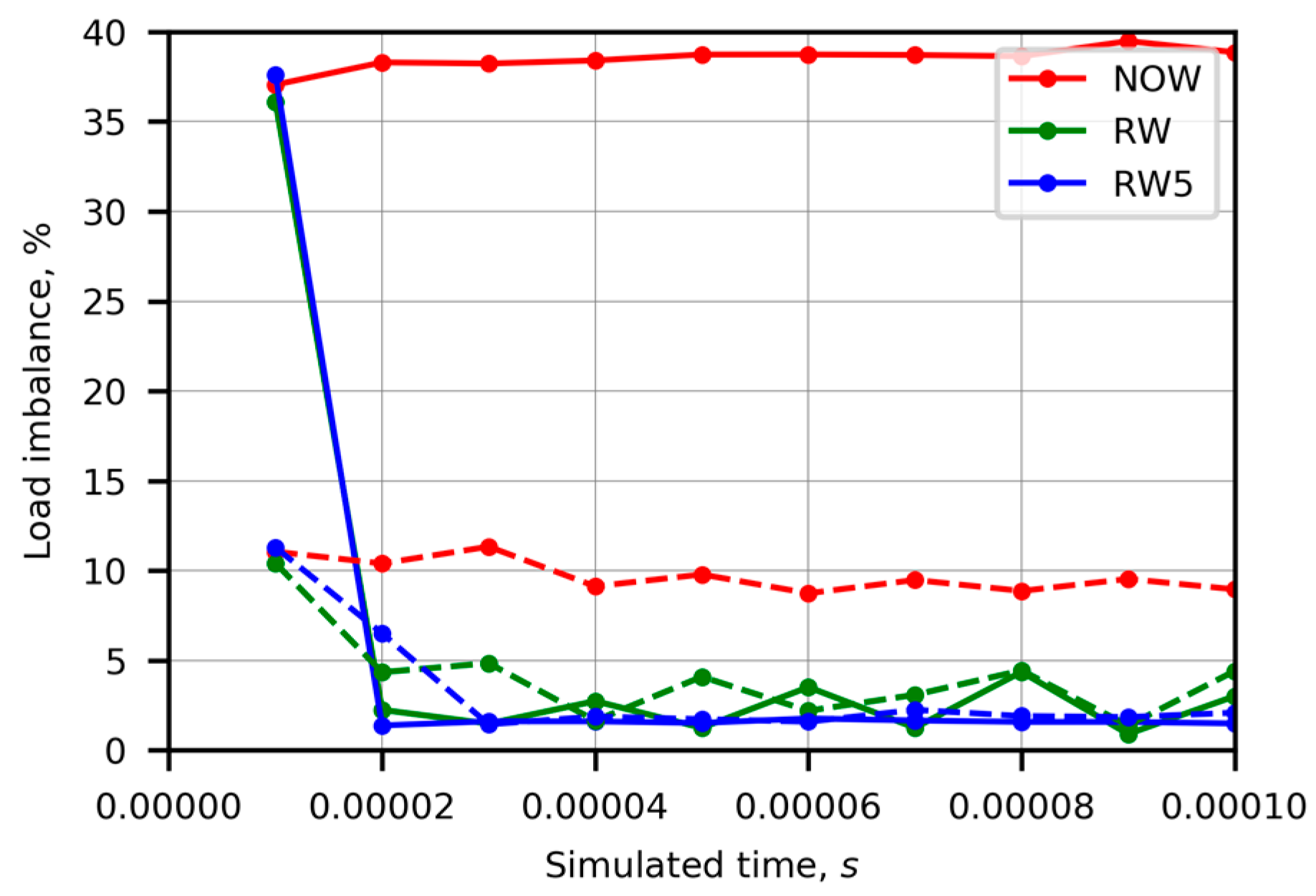
Figure 6 shows the time evolution of load imbalance when the memory stress test was performed on one (the solid curves) and four (the dashed curves) co-located containers in Case 5. In the legend, the abbreviations “NOW”, “RW”, and “RW5” again represent unweighted repartitioning, runtime adapted repartitioning, and runtime adapted repartitioning when weights were updated only if the load imbalance was higher than 5%, respectively. The load imbalance caused by one stressed co-located container was almost 4 times higher than that caused by four stressed co-located containers. Runtime adapted repartitioning required only one repartition to decrease the load imbalance up to 5%. In both stress cases, the additional condition of 5% perfectly reduced oscillations of the load imbalance and even slightly decreased the total execution time (
Figure 5b).
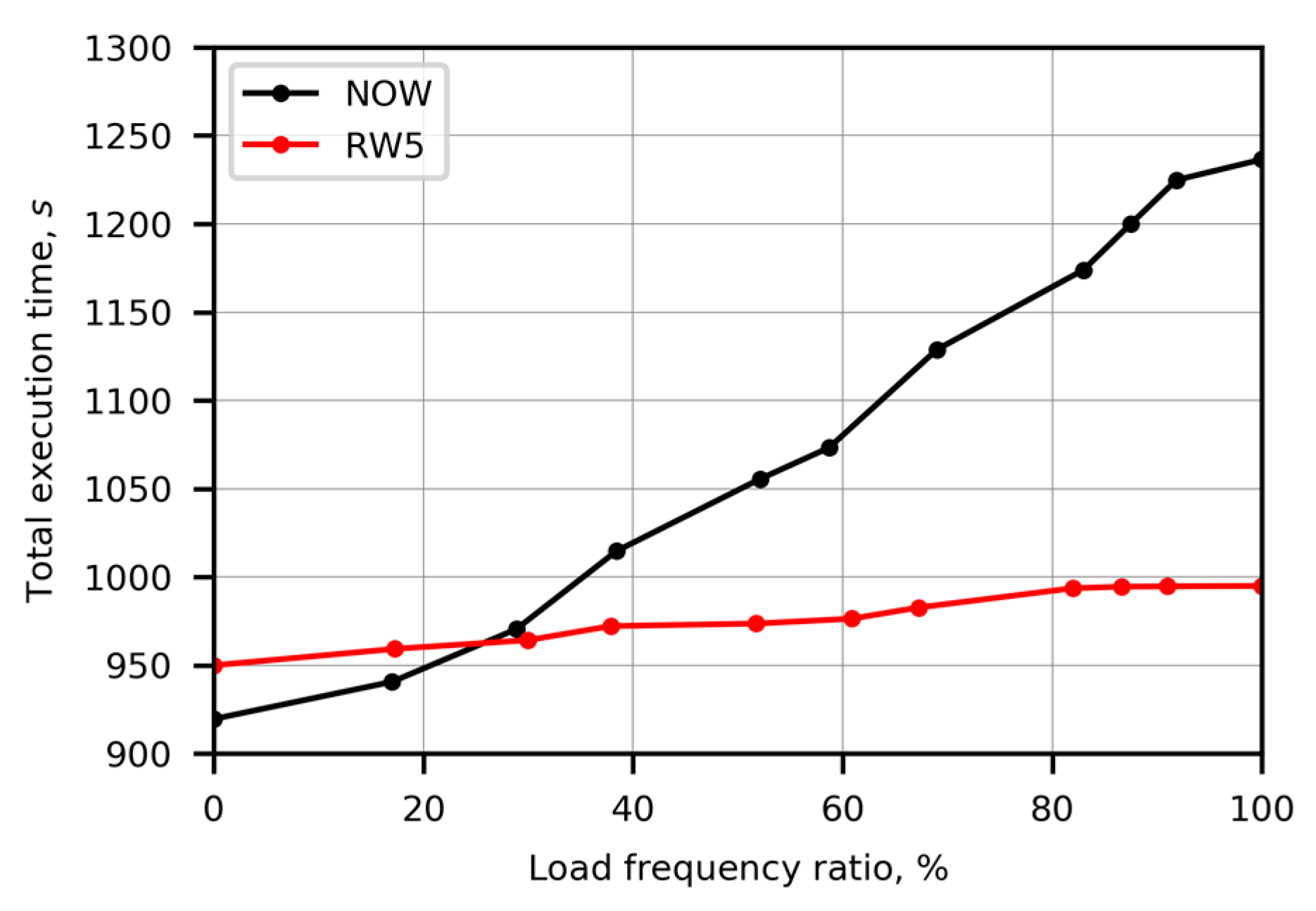
Figure 7 presents the dependency of the total execution time on the load frequency ratio in Case 6. The markers show the load frequency ratios of performed experiments that are connected by curves to improve visuality. The black curve represents the unweighted repartitioning and serves as the reference. It shows how the growing heterogeneity of co-located resources increases the total execution time of benchmarks when runtime computed weights are not applied. The red curve represents the runtime adapted repartitioning. A comparison of these curves reveals how much the total execution time can be reduced, applying the runtime adapted repartitioning. In the case of the load frequency ratio equal to zero, the memory stress test was not executed, which led to homogeneous containers. When the load frequency ratio varied from 0 to 30% of the whole simulation time, the memory stress test caused low load imbalance. Therefore, the gain in the runtime adapted repartitioning was smaller than the computational costs introduced by weighting and less regular partitions. When the load frequency ratio was larger than 30%, the load imbalance was high enough, and the substantial gain in the runtime adapted repartitioning could be observed. In the case of the load frequency ratio equal to 100%, the sleep command was not performed, and the total execution time of Case 5 (Stress 1) was obtained. Thus, the runtime adapted repartitioning handled the periodically variable performance of non-isolated resources and decreased the total execution time of benchmarks on co-located containers.
Because of the heterogeneity of non-isolated resources, the memory stress tests executed on one container substantially reduced the performance of parallel memory bandwidth bound DEM computations on the other container co-located on the same physical machine. To the best of our knowledge, there is no published research on the adaptation of parallel memory bandwidth bound applications to co-located cloud resources and relevant performance studies in the literature. In the present research, the developed runtime adapted repartitioning handled the constant and periodically variable performance of non-isolated resources and decreased the total execution time of benchmarks on co-located containers.
Chaotic variation in the system load and performance can be treated as the main limitation of runtime adapted repartitioning in the case of low load imbalance. The application of updated weights only if load imbalance is higher than 5% damps some oscillations of repartitioning results, but it is still difficult to substantially reduce the execution time. The frequently variable spiky load on co-located containers can also lead to a similar effect, when the unresolved trade-off between the spike capturing accuracy and oscillation damping limits the gain in runtime adapted repartitioning. Highly heterogeneous resources result in partitions of highly different sizes, which can significantly increase communication time. The RCB method does not directly optimize internode communication; therefore, performance analysis of a graph partitioning method might be beneficial to overcome communication issues in the future research.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}