
Cascaded Vehicle Matching and Short-Term Spatial-Temporal Network for Smoky Vehicle Detection



Abstract
1. Introduction
2. Related Work
2.1. Visual Smoke Detection
2.2. Smoky Vehicle Detection
3. Smoky Vehicle Datasets
3.1. Dataset Collection and Annotation
3.2. Dataset Comparison
4. Approach
4.1. Overview of Our Framework
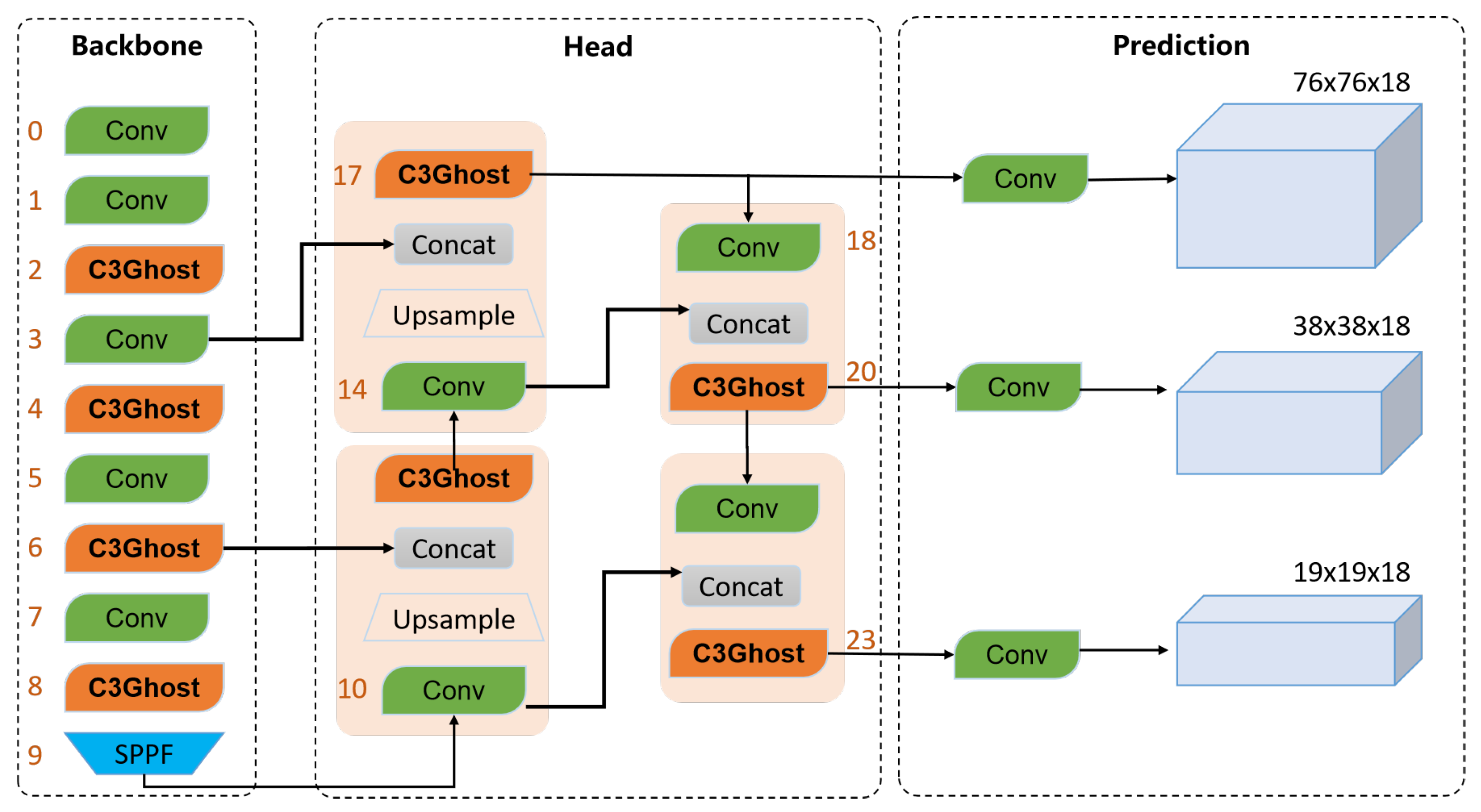
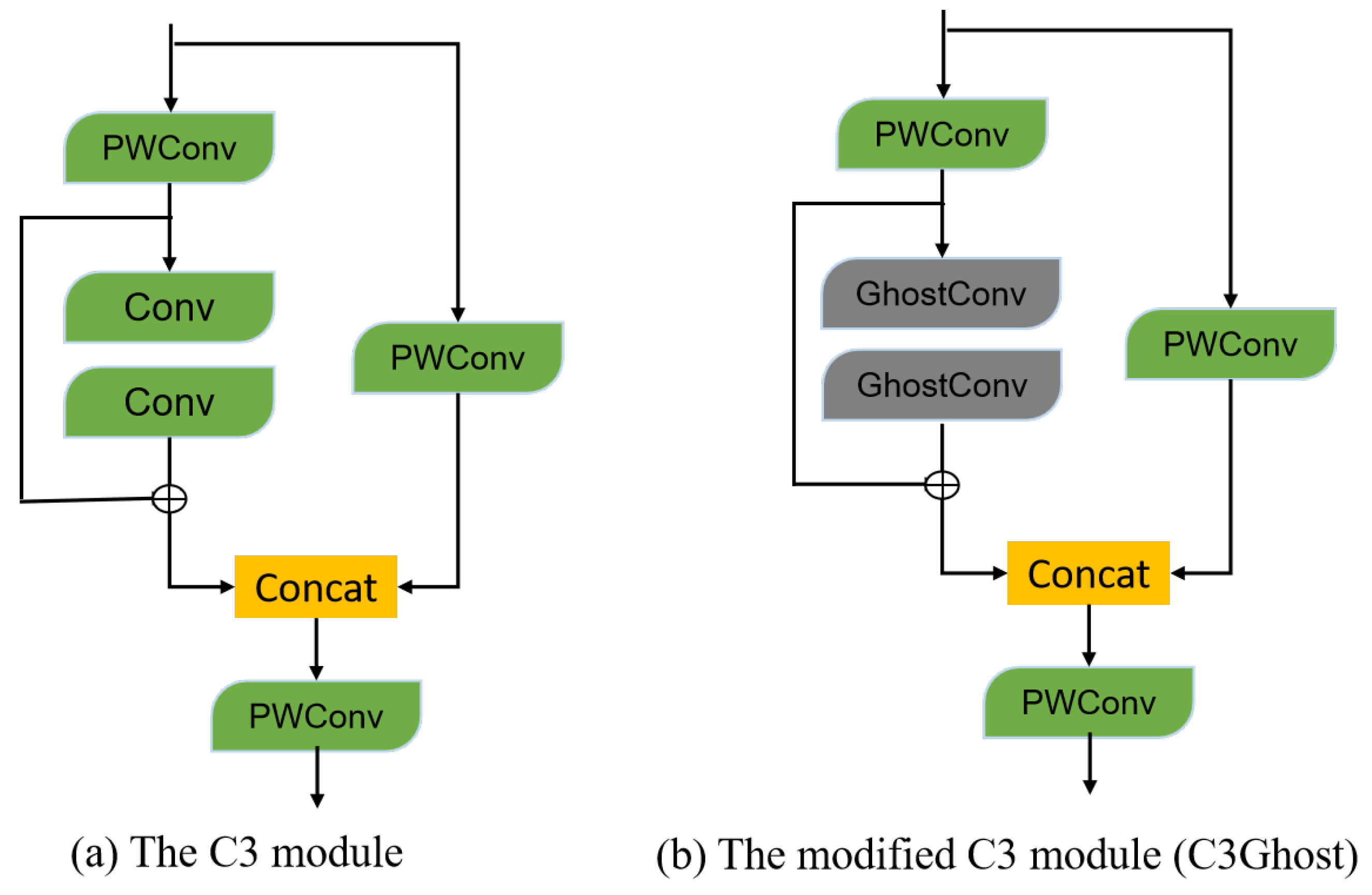
4.2. YOLOv5tiny Smoke Detector
4.3. Vehicle Matching
4.4. Short-Term Spatial-Temporal Network
5. Experiments
5.1. Data Splits and Metrics
5.2. Implementation Details
5.3. Detector Evaluation on LaSSoV
5.4. Comparison to the State of the Art on LaSSoV-Video
5.5. Ablation Study
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Beaton, S.P.; Bishop, G.A.; Zhang, Y.; Stedman, D.H.; Ashbaugh, L.L.; Lawson, D.R. On-Road Vehicle Emissions: Regulations, Costs, and Benefits. Science 1995, 268, 991–993. [Google Scholar] [CrossRef]
- Ropkins, K.; Beebe, J.; Li, H.; Daham, B.; Tate, J.; Bell, M.; Andrews, G. Real-World Vehicle Exhaust Emissions Monitoring: Review and Critical Discussion. Crit. Rev. Environ. Sci. Technol. 2009, 39, 79–152. [Google Scholar] [CrossRef]
- Tao, H.; Zheng, P.; Xie, C.; Lu, X. A three-stage framework for smoky vehicle detection in traffic surveillance videos. Inf. Sci. 2020, 522, 17–34. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Smoky vehicle detection based on multi-scale block Tamura features. Signal Image Video Process. 2018, 12, 1061–1068. [Google Scholar] [CrossRef]
- Cao, Y.; Lu, C.; Lu, X.; Xia, X. A Spatial Pyramid Pooling Convolutional Neural Network for Smoky Vehicle Detection. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9170–9175. [Google Scholar]
- Tao, H.; Lu, X. Automatic smoky vehicle detection from traffic surveillance video based on vehicle rear detection and multi-feature fusion. IET Intell. Transp. Syst. 2019, 13, 252–259. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Smoke vehicle detection based on robust codebook model and robust volume local binary count patterns. Image Vis. Comput. 2019, 86, 17–27. [Google Scholar] [CrossRef]
- Cao, Y.; Lu, X. Learning spatial-temporal representation for smoke vehicle detection. Multimed. Tools Appl. 2019, 78, 27871–27889. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Smoke Vehicle Detection Based on Spatiotemporal Bag-Of-Features and Professional Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3301–3316. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Smoke vehicle detection based on multi-feature fusion and hidden Markov model. J. Real-Time Image Process. 2020, 17, 745–758. [Google Scholar] [CrossRef]
- Wang, C.; Wang, H.; Yu, F.; Xia, W. A High-Precision Fast Smoky Vehicle Detection Method Based on Improved Yolov5 Network. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Industrial Design (AIID), Guangzhou, China, 28–30 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 255–259. [Google Scholar]
- Hashemzadeh, M.; Farajzadeh, N.; Heydari, M. Smoke detection in video using convolutional neural networks and efficient spatio-temporal features. Appl. Soft Comput. 2022, 128, 109496. [Google Scholar] [CrossRef]
- Sun, B.; Xu, Z.D. A multi-neural network fusion algorithm for fire warning in tunnels. Appl. Soft Comput. 2022, 131, 109799. [Google Scholar] [CrossRef]
- Töreyin, B.U.; Dedeoğlu, Y.; Cetin, A.E. Wavelet based real-time smoke detection in video. In Proceedings of the 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 1–4. [Google Scholar]
- Xiong, Z.; Caballero, R.; Wang, H.; Finn, A.M.; Lelic, M.A.; Peng, P.Y. Video-based smoke detection: Possibilities, techniques, and challenges. In Proceedings of the IFPA, Fire Suppression and Detection Research and Applications—A Technical Working Conference (SUPDET), Orlando, FL, USA, 11–13 March 2007. [Google Scholar]
- Yuan, F. A fast accumulative motion orientation model based on integral image for video smoke detection. Pattern Recognit. Lett. 2008, 29, 925–932. [Google Scholar] [CrossRef]
- Zhou, Z.; Shi, Y.; Gao, Z.; Li, S. Wildfire smoke detection based on local extremal region segmentation and surveillance. Fire Saf. J. 2016, 85, 50–58. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Zhang, Q.; Jia, Y.; Wang, J. Smoke detection in video sequences based on dynamic texture using volume local binary patterns. Ksii Trans. Internet Inf. Syst. 2017, 11, 5522–5536. [Google Scholar]
- Yuan, F.; Xia, X.; Shi, J.; Zhang, L.; Huang, J. Learning multi-scale and multi-order features from 3D local differences for visual smoke recognition. Inf. Sci. 2018, 468, 193–212. [Google Scholar] [CrossRef]
- Yuan, F.; Shi, J.; Xia, X.; Zhang, L.; Li, S. Encoding pairwise Hamming distances of Local Binary Patterns for visual smoke recognition. Comput. Vis. Image Underst. 2019, 178, 43–53. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Wan, B.; Xia, X.; Shi, J. Convolutional neural networks based on multi-scale additive merging layers for visual smoke recognition. Mach. Vis. Appl. 2019, 30, 345–358. [Google Scholar] [CrossRef]
- Yuan, F.; Li, G.; Xia, X.; Lei, B.; Shi, J. Fusing texture, edge and line features for smoke recognition. IET Image Process. 2019, 13, 2805–2812. [Google Scholar] [CrossRef]
- Yuan, F.; Li, G.; Xia, X.; Shi, J.; Zhang, L. Encoding features from multi-layer Gabor filtering for visual smoke recognition. Pattern Anal. Appl. 2020, 23, 1117–1131. [Google Scholar] [CrossRef]
- Yuan, F. A double mapping framework for extraction of shape-invariant features based on multi-scale partitions with AdaBoost for video smoke detection. Pattern Recognit. 2012, 45, 4326–4336. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory. Encycl. Sci. Learn. 1998, 41, 3185. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Carson, NV, USA, 3–6 December 2012. [Google Scholar]
- Filonenko, A.; Kurnianggoro, L.; Jo, K.H. Comparative study of modern convolutional neural networks for smoke detection on image data. In Proceedings of the International Conference on Human System Interactions, Portsmouth, UK, 6–8 July 2017. [Google Scholar]
- Li, X.; Chen, Z.; Wu, Q.; Liu, C. 3D Parallel Fully Convolutional Networks for Real-time Video Wildfire Smoke Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 89–103. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke Detection on Video Sequences Using 3D Convolutional Neural Networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Gu, K.; Xia, Z.; Qiao, J.; Lin, W. Deep Dual-Channel Neural Network for Image-Based Smoke Detection. IEEE Trans. Multimed. 2019, 22, 311–323. [Google Scholar] [CrossRef]
- Yin, M.; Lang, C.; Li, Z.; Feng, S.; Wang, T. Recurrent convolutional network for video-based smoke detection. Multimed. Tools Appl. 2019, 78, 237–256. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, X. Real-time video fire smoke detection by utilizing spatial-temporal ConvNet features. Multimed. Tools Appl. 2018, 77, 29283–29301. [Google Scholar] [CrossRef]
- Luo, Y.; Zhao, L.; Liu, P.; Huang, D. Fire smoke detection algorithm based on motion characteristic and convolutional neural networks. Multimed. Tools Appl. 2018, 77, 15075–15092. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Guillemant, P.; Vicente, J.R.M. Real-time identification of smoke images by clustering motions on a fractal curve with a temporal embedding method. Opt. Eng. 2001, 40, 554–563. [Google Scholar] [CrossRef]
- Gomez-Rodriguez, F.; Pascual-Pena, S.; Arrue, B.; Ollero, A. Smoke detection using image processing. In Proceedings of the International Conference on Forest Fire Research &17th International Wildland Fire Safety Summit (ICFFR), Coimbra, Portugal, 11–18 November 2002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016. [Google Scholar]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the Conference of the IEEE Industrial Electronics Society, Florence, Italy, 24–27 October 2016; pp. 877–882. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Tao, C.; Jian, Z.; Pan, W. Smoke Detection Based on Deep Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Industrial Informatics—Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Wuhan, China, 3–4 December 2016; pp. 2818–2826. [Google Scholar]
- Ko, B.; Kwak, J.Y.; Nam, J.Y. Wildfire smoke detection using temporospatial features and random forest classifiers. Opt. Eng. 2012, 51, 7208. [Google Scholar]
- Foggia, P.; Saggese, A.; Vento, M. Real-time Fire Detection for Video Surveillance Applications using a Combination of Experts based on Color, Shape and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Yuan, F.; Shi, J.; Xia, X.; Fang, Y.; Fang, Z.; Mei, T. High-order local ternary patterns with locality preserving projection for smoke detection and image classification. Inf. Sci. 2016, 372, 225–240. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Smoky vehicle detection based on range filtering on three orthogonal planes and motion orientation histogram. IEEE Access 2018, 6, 57180–57190. [Google Scholar] [CrossRef]
- Ng, Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Type | Total Samples | Annotation | Available |
|---|---|---|---|---|
| KMU Fire-Smoke [45] | video | 10 | category | public |
| Mivia Fire-Smoke [46] | video | 149 | category | public |
| SmokeVideos in [18] | video | 25 | block labels | public |
| VSD(Set4) [47] | patches | 10,617 | category | public |
| SEU-SmokeVeh [7] | videos | 102 | temporal segments | private |
| LaSSoV (Ours) | image | 75,000 | bounding boxes | public |
| LaSSoV-video (Ours) | video | 163 | temporal segments | public |
| Detector | mAP@0.5 | mAP@0.5:0.95 | Params (M) | FLOPs | Speed-CPU (ms) | Speed-GPU (ms) |
|---|---|---|---|---|---|---|
| MobileNetv2-YOLOv5s | 64.52 | 22.96 | 4.6 | 36.7 | 470.6 | 13.1 |
| YOLOv5s | 87.3 | 39.8 | 7.2 | 16.5 | 134.5 | 18.5 |
| YOLOv5n | 80.9 | 33.1 | 1.9 | 4.5 | 61.5 | 13.2 |
| Our YOLOv5tiny | 79.8 | 32.1 | 1.2 | 2.8 | 48.9 | 12.8 |
| Method | DR | FAR (↓) | Precision | F1 | Time/ms |
|---|---|---|---|---|---|
| YOLOv5s(0.2) | 0.9368 | 0.1349 | 0.4064 | 0.5580 | 134.5 |
| YOLOv5s(0.5) | 0.8471 | 0.0453 | 0.6379 | 0.7206 | 134.5 |
| YOLOv5tiny(0.2) | 0.9087 | 0.1436 | 0.3967 | 0.5370 | 48.9 |
| YOLOv5tiny(0.5) | 0.7168 | 0.0287 | 0.7000 | 0.6949 | 48.9 |
| Ours((ST)Net-prefix) | 0.7381 | 0.0297 | 0.7045 | 0.7200 | 68.2 + 61.5 |
| Ours((ST)Net-suffix) | 0.7713 | 0.0192 | 0.7936 | 0.7801 | 72.2 + 61.5 |
| R-VLBC [7] | 0.8453 | 0.1893 | 0.3171 | 0.4623 | 160.56 |
| R-VLBC [7] | 0.9253 | 0.0893 | – | – | |
| LBP [3] | 0.8674 | 0.3103 | – | – | – |
| NR-RLBP [3] | 0.9125 | 0.1610 | – | – | 140.34 |
| RF-TOP [48] | 0.8757 | 0.1236 | – | – | – |
| YOLOv5tiny | Vehicle Matching | (ST)Net | DR | FAR (↓) | Precision | F1 |
|---|---|---|---|---|---|---|
| √ | 0.9087 | 0.1436 | 0.3967 | 0.5370 | ||
| √ | √ | 0.8815 | 0.1211 | 0.4255 | 0.5616 | |
| √ | √ | √ | 0.7713 | 0.0192 | 0.7936 | 0.7801 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Fan, X.; Wu, Q.; Zhao, J.; Gao, P. Cascaded Vehicle Matching and Short-Term Spatial-Temporal Network for Smoky Vehicle Detection. Appl. Sci. 2023, 13, 4841. https://doi.org/10.3390/app13084841
Peng X, Fan X, Wu Q, Zhao J, Gao P. Cascaded Vehicle Matching and Short-Term Spatial-Temporal Network for Smoky Vehicle Detection. Applied Sciences. 2023; 13(8):4841. https://doi.org/10.3390/app13084841
Chicago/Turabian StylePeng, Xiaojiang, Xiaomao Fan, Qingyang Wu, Jieyan Zhao, and Pan Gao. 2023. "Cascaded Vehicle Matching and Short-Term Spatial-Temporal Network for Smoky Vehicle Detection" Applied Sciences 13, no. 8: 4841. https://doi.org/10.3390/app13084841
APA StylePeng, X., Fan, X., Wu, Q., Zhao, J., & Gao, P. (2023). Cascaded Vehicle Matching and Short-Term Spatial-Temporal Network for Smoky Vehicle Detection. Applied Sciences, 13(8), 4841. https://doi.org/10.3390/app13084841