


A Comprehensive Study of Machine Learning Application to Transmission Quality Assessment in Optical Networks


Abstract
1. Introduction
2. Related Work
3. Problem Formulation
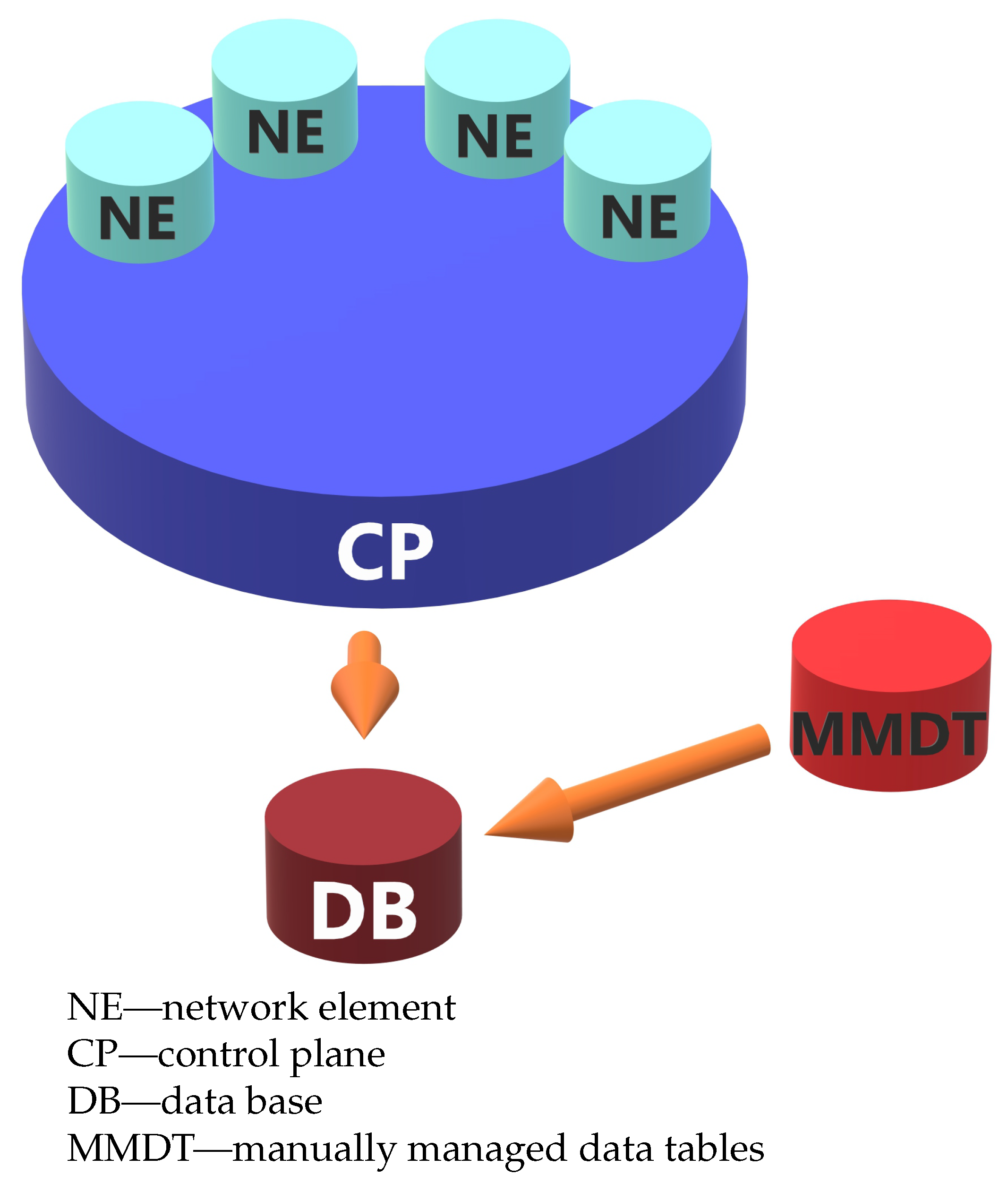
3.1. Data
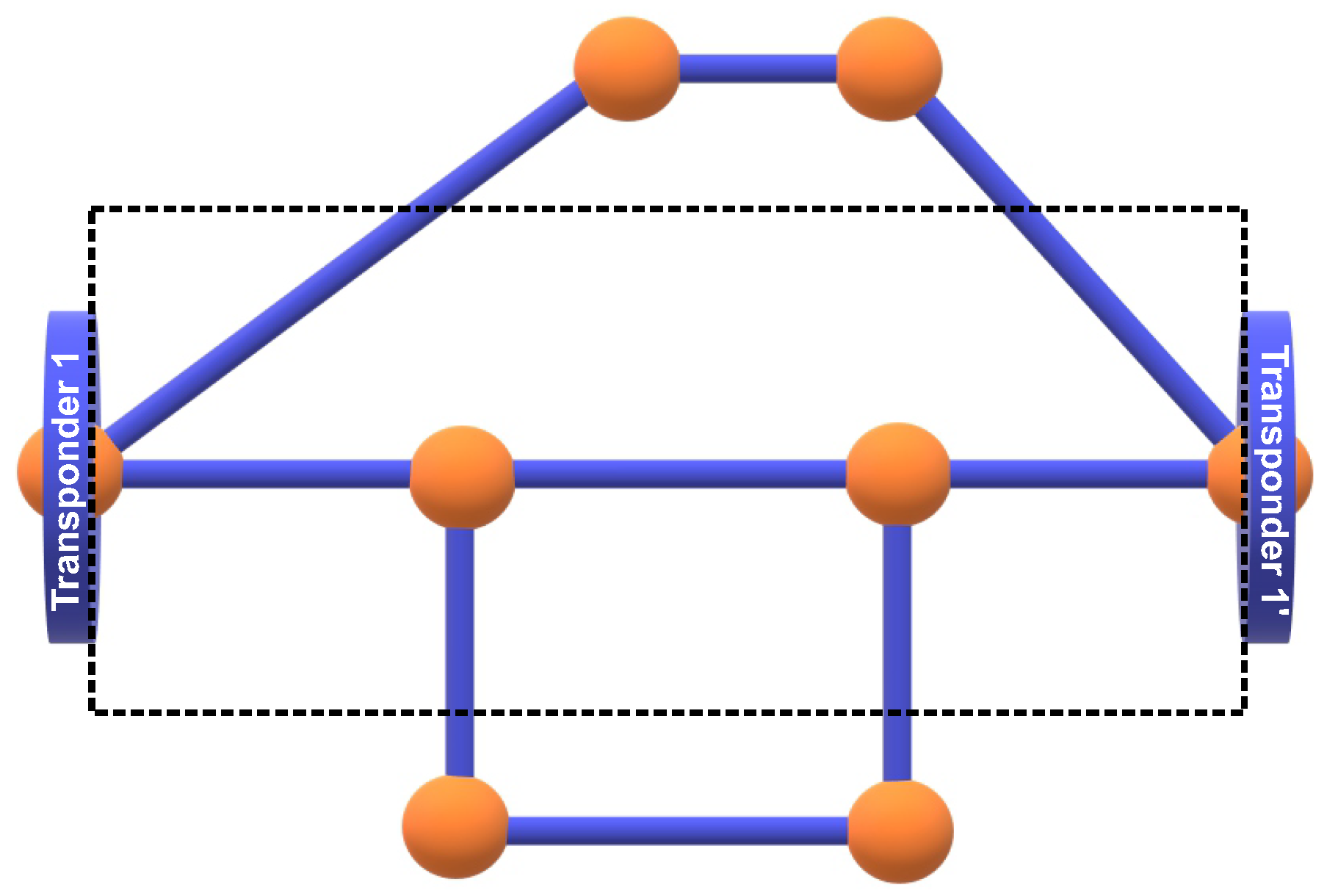
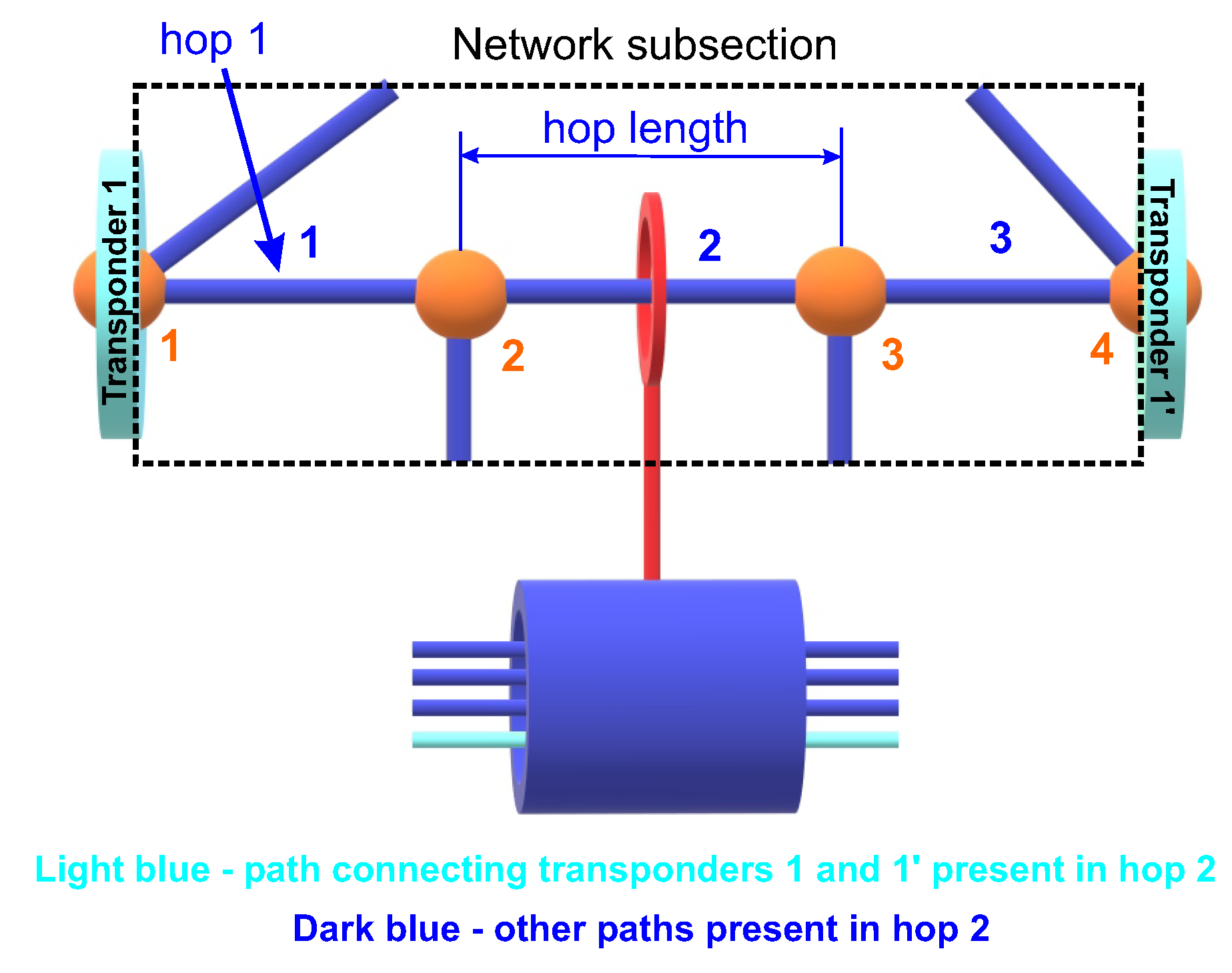
3.1.1. Path Description
3.1.2. Vector Representation
- sum (*edge property name*.sum);
- mean (*edge property name*.avg);
- median (*edge property name*.med);
- standard dev. (*edge property name*.std);
- minimum (*edge property name*.min);
- maximum (*edge property name*.max);
- first quartile (*edge property name*.q1);
- third quartile (*edge property name*.q3);
- linear correlation with the edge’s ordinal number in the path:(*edge property name*.cor).
3.1.3. Attribute Subsets
4. Machine Learning Algorithms
4.1. Logistic Regression
4.2. Support Vector Machines
4.3. Random Forest
4.4. Gradient Boosting
4.5. k-Nearest Neighbors
4.6. Multilayer Perceptron
4.7. Model Evaluation
5. Results
- LR: LogisticRegression:
- class_weight—weights for handling class imbalance;
- solver—the algorithm to use in the optimization problem;
- penalty—regularization type;
- c—the inverse of regularization strength.
- SVC: SupportVectorClassifier:
- class_weight—weights for handling class imbalance;
- c—the cost of constraint violation;
- gamma—the kernel parameter;
- kernel—the kernel type to be used in the algorithm.
- RFC: RandomForestClassifier:
- class_weight—weights for handling class imbalance;
- n_estimators—the number of trees in the forest;
- min_samples_split—the number of samples required to split a node;
- max_depth—the maximum tree depth.
- GBC: GradientBoostingClassifier:
- n_estimators—the number of trees (boosting iterations);
- min_samples_split—the number of samples required to split a node;
- max_depth—the maximum tree depth.
- KNC: KNeighborsClassifier:
- n_neighbors—the number of neighbors considered when making prediction;
- leaf_size—the size of the leaf in the neighor search tree;
- p—the power parameter for the Minkowski metric.
- MLPC: MLPClassifier:
- hidden_layer_sizes—the number and shapes of hidden layers;
- activation—the activation function of neurons;
- solver—the optimization algorithm;
- alpha—the regularization parameter;
- learning_rate—the learning step size.
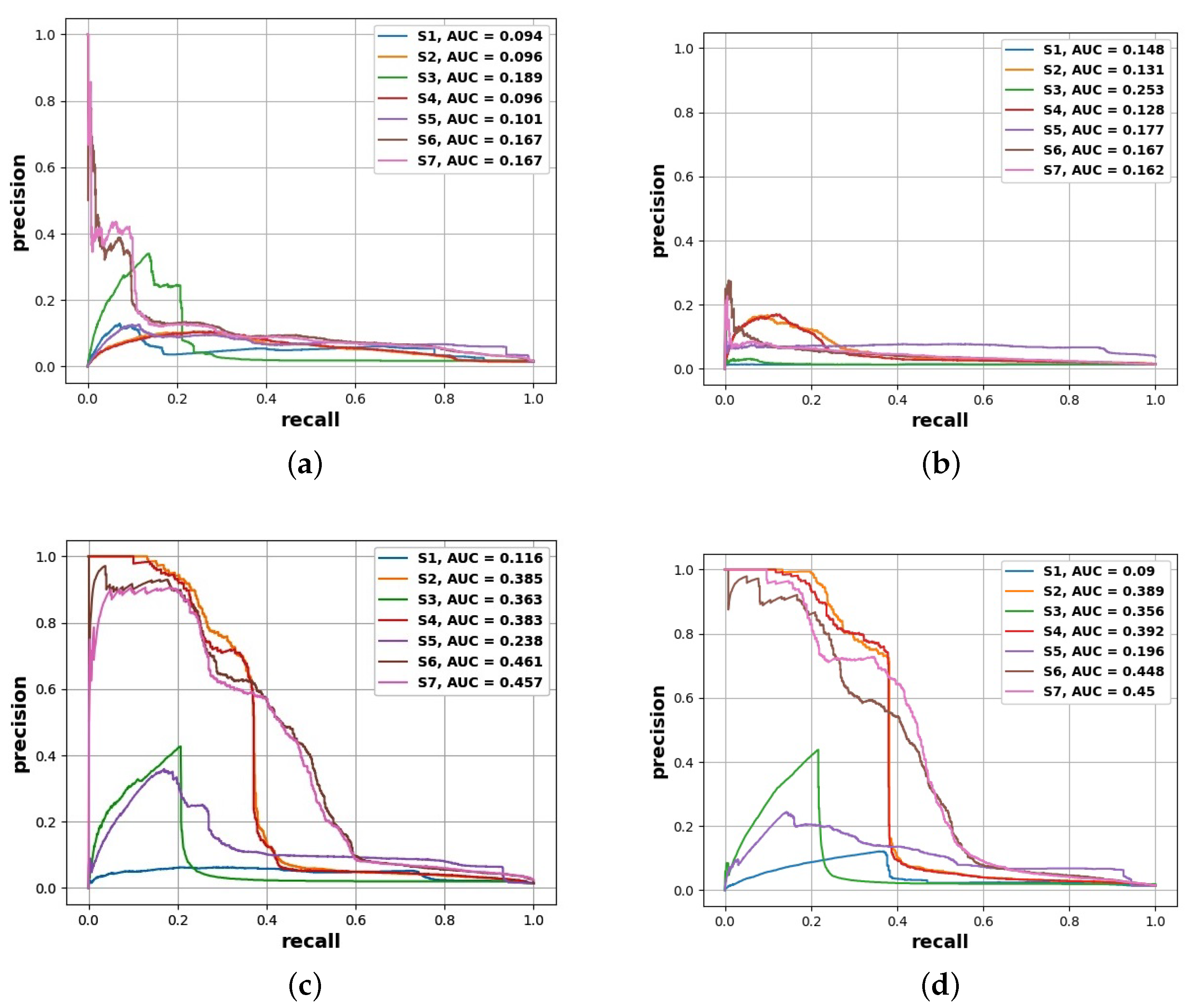
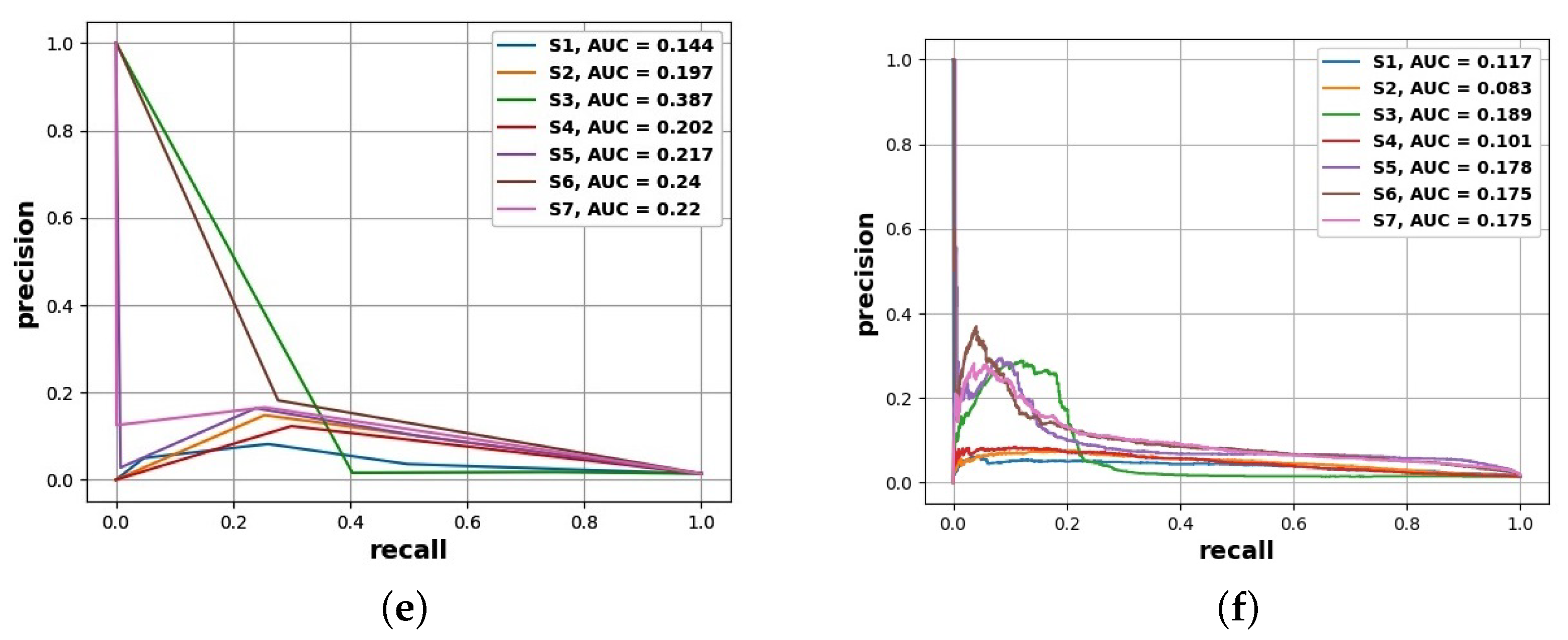
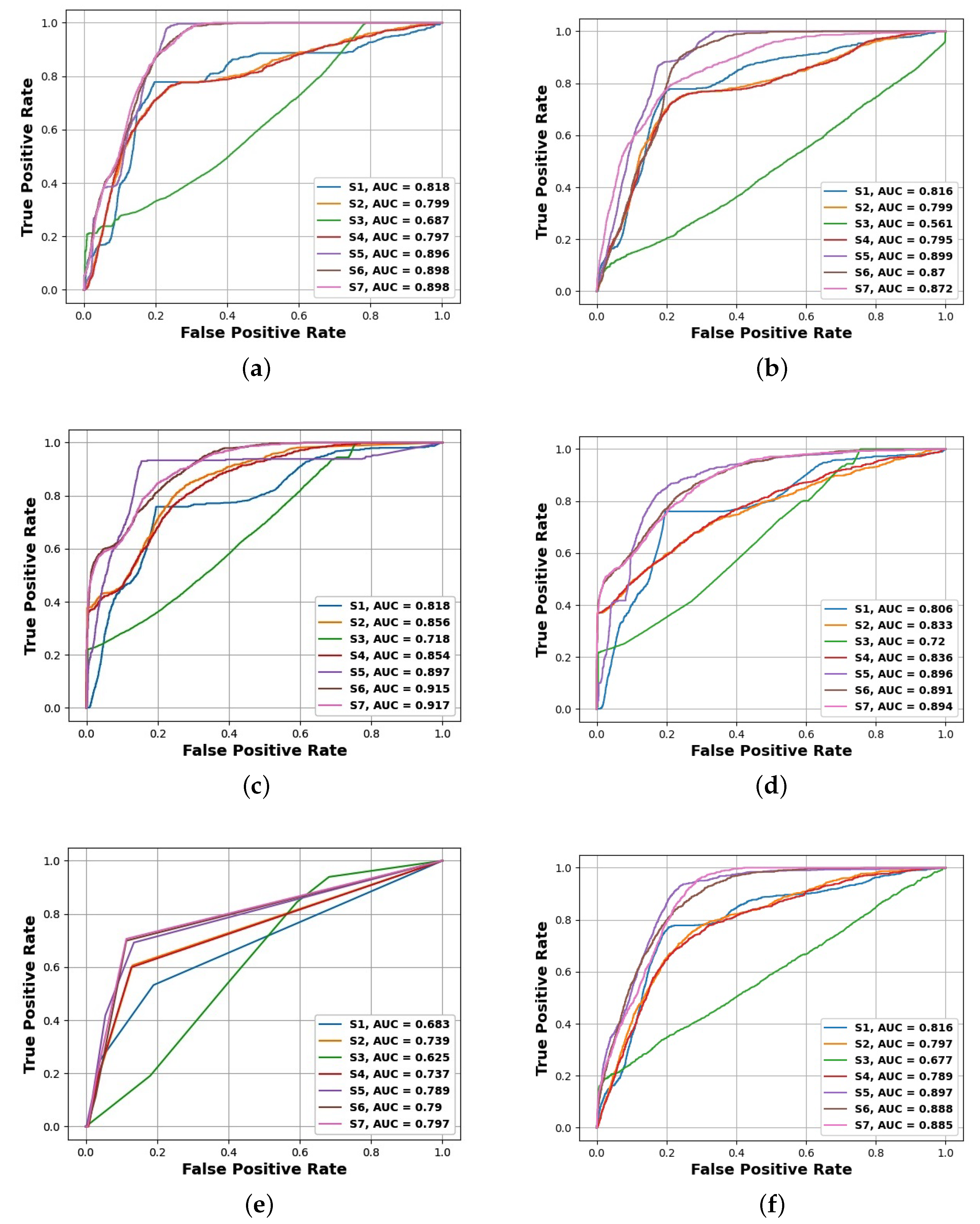
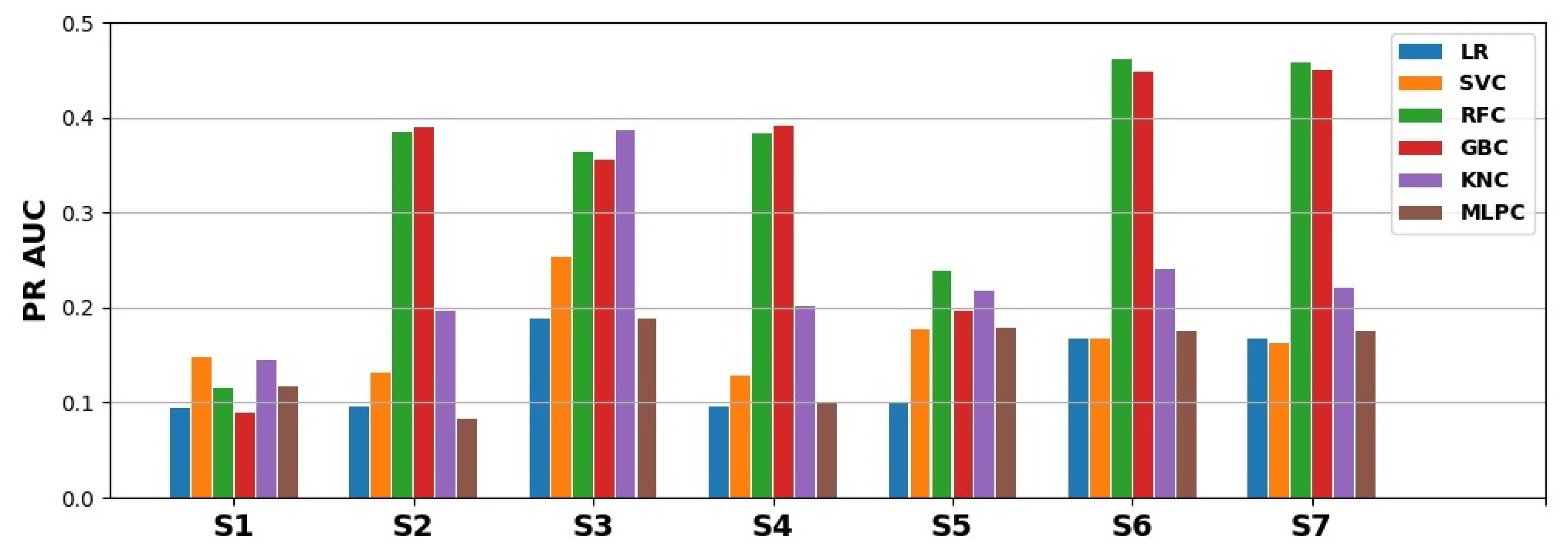
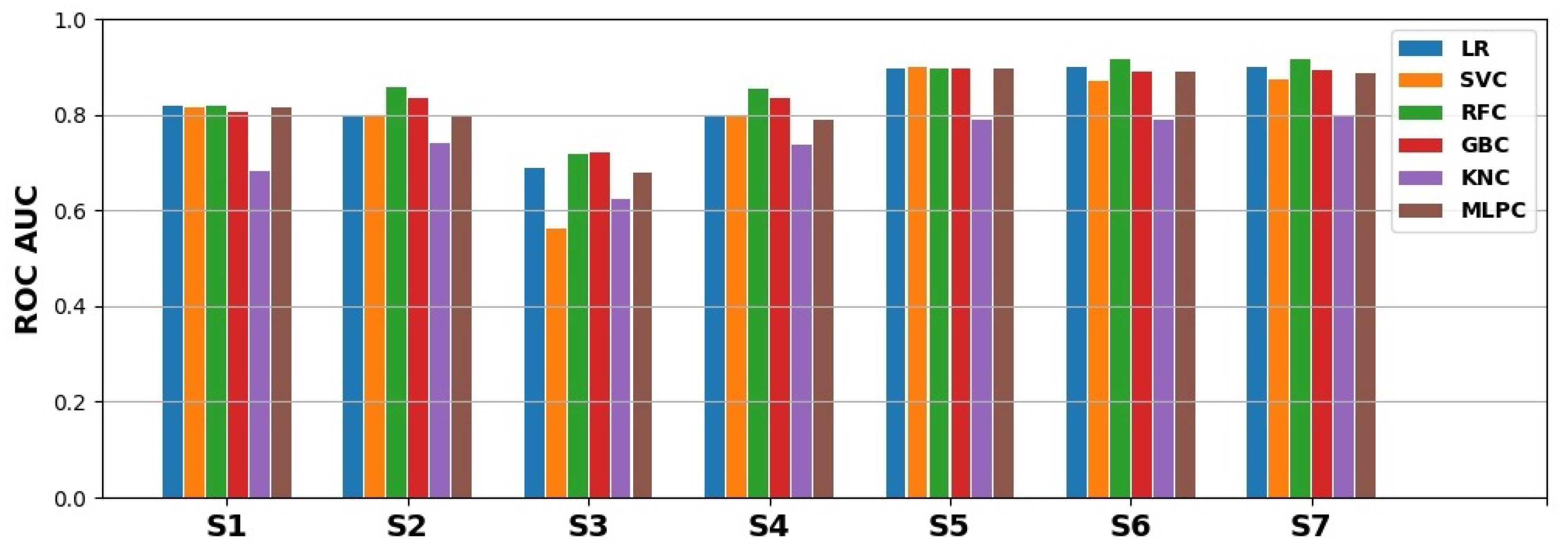
- The best prediction corresponds to a PR AUC of about and an ROC AUC of about ;
- Depending on the choice of cutoff thresholds, model, operating points are possibly achieving the true-positive rate of more than with the false-positive rate below or both the recall and precision above ;
- PR curves and PR AUC values reveal more substantial predictive performance differences than do ROC curves and ROC AUC values, which is to be expected for heavily imbalanced data;
- The best models are obtained using the random forest and gradient boosting algorithms, which seem to deal best with the problems of small data size and class imbalance;
- Subsets and were found to be the most useful in the experiments carried out;
- The utility of smaller attribute subsets depends more on the adopted performance measure than on the algorithm, and in particular, attribute subsets and are the least useful with respect to PR AUC, while attribute subset is the least useful with respect to ROC AUC.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Ultra-Wideband WDM Optical Network Optimization. Photonics 2020, 7, 16. [Google Scholar] [CrossRef]
- Klinkowski, M.; Żotkiewicz, M.; Walkowiak, K.; Pióro, M.; Ruiz, M.; Velasco, L. Solving large instances of the RSA problem in flexgrid elastic optical networks. IEEE/OSA J. Opt. Commun. Netw. 2016, 8, 320–330. [Google Scholar] [CrossRef]
- Ruiz, M.; Pióro, M.; Żotkiewicz, M.; Klinkowski, M.; Velasco, L. Column generation algorithm for RSA problems in flexgrid optical networks. Photonic Netw. Commun. 2013, 26, 53–64. [Google Scholar] [CrossRef]
- Dallaglio, M.; Giorgetti, A.; Sambo, N.; Velasco, L.; Castoldi, P. Routing, Spectrum, and Transponder Assignment in Elastic Optical Networks. J. Light. Technol. 2015, 33, 4648–4658. [Google Scholar] [CrossRef]
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Resource optimization in fully flexible optical node architectures. In Proceedings of the 20th International Conference on Transparent Optical Networks (ICTON), Bucharest, Romania, 1–5 July 2018. [Google Scholar]
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Optimization of Optical Networks Based on CDC-ROADM Tech. Appl. Sci. 2019, 9, 399. [Google Scholar] [CrossRef]
- Kozdrowski, S.; Cichosz, P.; Paziewski, P.; Sujecki, S. Machine Learning Algorithms for Prediction of the Quality of Transmission in Optical Networks. Entropy 2021, 23, 7. [Google Scholar] [CrossRef]
- Cichosz, P.; Kozdrowski, S.; Sujecki, S. Application of ML Algorithms for Prediction of the QoT in Optical Networks with Imbalanced and Incomplete Data. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 23–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Mestres, A.; Rodríguez-Natal, A.; Carner, J.; Barlet-Ros, P.; Alarcón, E.; Solé, M.; Muntés, V.; Meyer, D.; Barkai, S.; Hibbett, M.J.; et al. Knowledge-Defined Networking. arXiv 2016, arXiv:1606.06222. [Google Scholar] [CrossRef]
- Żotkiewicz, M.; Szałyga, W.; Domaszewicz, J.; Bak, A.; Kopertowski, Z.; Kozdrowski, S. Artificial Intelligence Control Logic in Next-Generation Programmable Networks. Appl. Sci. 2021, 11, 9163. [Google Scholar] [CrossRef]
- Morais, R.M.; Pedro, J. Machine learning models for estimating quality of transmission in DWDM networks. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, D84–D99. [Google Scholar] [CrossRef]
- Musumeci, F.; Rottondi, C.; Nag, A.; Macaluso, I.; Zibar, D.; Ruffini, M.; Tornatore, M. An Overview on Application of Machine Learning Techniques in Optical Networks. IEEE Commun. Surv. Tutor. 2019, 21, 1383–1408. [Google Scholar] [CrossRef]
- Rottondi, C.; Barletta, L.; Giusti, A.; Tornatore, M. Machine-learning method for quality of transmission prediction of unestablished lightpaths. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, A286–A297. [Google Scholar] [CrossRef]
- Panayiotou, T.; Manousakis, K.; Chatzis, S.P.; Ellinas, G. A Data-Driven Bandwidth Allocation Framework With QoS Considerations for EONs. J. Light. Technol. 2019, 37, 1853–1864. [Google Scholar] [CrossRef]
- Pan, X.; Wang, X.; Tian, B.; Wang, C.; Zhang, H.; Guizani, M. Machine-Learning-Aided Optical Fiber Communication System. IEEE Netw. 2021, 35, 136–142. [Google Scholar] [CrossRef]
- Lu, J.; Fan, Q.; Zhou, G.; Lu, L.; Yu, C.; Lau, A.P.T.; Lu, C. Automated training dataset collection system design for machine learning application in optical networks: An example of quality of transmission estimation. J. Opt. Commun. Netw. 2021, 13, 289–300. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, Z.; Sun, Q.; Yu, C.; Yu, C. An artificial intelligence model based on multi-step feature engineering and deep attention network for optical network performance monitoring. Optik 2023, 273, 170443. [Google Scholar] [CrossRef]
- Memon, K.A.; Butt, R.A.; Mohammadani, K.H.; Das, B.; Ullah, S.; Memon, S.; ul Ain, N. A Bibliometric Analysis and Visualization of Passive Optical Network Research in the Last Decade. Opt. Switch. Netw. 2020, 39, 100586. [Google Scholar] [CrossRef]
- Ali, K.; Zhang, Q.; Butt, R.; Mohammadani, K.; Faheem, M.; Ain, N.; Feng, T.; Xin, X. Traffic-Adaptive Inter Wavelength Load Balancing for TWDM PON. IEEE Photonics J. 2020, 12, 7200408. [Google Scholar] [CrossRef]
- Mata, J.; de Miguel, I.; Durán, R.J.; Aguado, J.C.; Merayo, N.; Ruiz, L.; Fernández, P.; Lorenzo, R.M.; Abril, E.J. A SVM approach for lightpath QoT estimation in optical transport networks. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4795–4797. [Google Scholar]
- Thrane, J.; Wass, J.; Piels, M.; Medeiros Diniz, J.; Jones, R.; Zibar, D. Machine Learning Techniques for Optical Performance Monitoring from Directly Detected PDM-QAM Signals. J. Light. Technol. 2017, 35, 868–875. [Google Scholar] [CrossRef]
- Barletta, L.; Giusti, A.; Rottondi, C.; Tornatore, M. QoT estimation for unestablished lighpaths using machine learning. In Proceedings of the 2017 Optical Fiber Communications Conference and Exhibition (OFC), Los Angeles, CA, USA, 19–23 March 2017; pp. 1–3. [Google Scholar]
- Seve, E.; Pesic, J.; Delezoide, C.; Bigo, S.; Pointurier, Y. Learning Process for Reducing Uncertainties on Network Parameters and Design Margins. J. Optital Commun. Netw. 2018, 10, A298–A306. [Google Scholar] [CrossRef]
- Japkowicz, N. Learning from Imbalanced Data Sets: A Comparison of Various Strategies; AAAI Press: Menlo Park, CA, USA, 2000. [Google Scholar]
- Bellinger, C.; Sharma, S.; Zaïane, O.R.; Japkowicz, N. Sampling a Longer Life: Binary versus One-Class Classification Revisited. Proc. Mach. Learn. Res. 2017, 74, 64–78. [Google Scholar]
- Lee, H.; Cho, S. The Novelty Detection Approach for Different Degrees of Class Imbalance. In Proceedings of the 13th International Conference on Neural Information Processing, ICONIP-2006, Hong Kong, China, 3–6 October 2006; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Menardi, G.; Torelli, N. Training and Assessing Classification Rules with Imbalanced Data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- Mo, W.; Huang, Y.K.; Zhang, S.; Ip, E.; Kilper, D.C.; Aono, Y.; Tajima, T. ANN-Based Transfer Learning for QoT Prediction in Real-Time Mixed Line-Rate Systems. In Proceedings of the Optical Fiber Communication Conference, San Diego, CA, USA, 11–15 March 2018; Optica Publishing Group: Massachusetts, NW, USA, 2018; p. 4. [Google Scholar]
- Proietti, R.; Chen, X.; Castro, A.; Liu, G.; Lu, H.; Zhang, K.; Guo, J.; Zhu, Z.; Velasco, L.; Yoo, S.J.B. Experimental Demonstration of Cognitive Provisioning and Alien Wavelength Monitoring in Multi-domain EON. In 2018 Optical Fiber Communications Conference and Exposition (OFC); Optical Society of America: Washington, DC, USA, 2018; pp. 1–3. [Google Scholar]
- Hilbe, J.M. Logistic Regression Models; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Platt, J.C. Fast Training of Support Vector Machines using Sequential Minimal Optimization. In Advances in Kernel Methods: Support Vector Learning; Schölkopf, B., Burges, C.J.C., Smola, A.J., Eds.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Hamel, L.H. Knowledge Discovery with Support Vector Machines; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Platt, J.C. Probabilistic Outputs for Support Vector Machines and Comparison to Regularized Likelihood Methods. In Advances in Large Margin Classifiers; Smola, A.J., Barlett, P., Schölkopf, B., Schuurmans, D., Eds.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef]
- Schapire, R.E. The Strength of Weak Learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and Algorithms; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS-2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Hinton, G.E. Connectionist Learning Procedures. Artif. Intell. 1989, 40, 185–234. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS-2011), Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cichosz, P.; Kozdrowski, S.; Sujecki, S. Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data. Entropy 2021, 23, 1504. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Name | Attributes |
|---|---|
| G1 (path-related) | number_of_hops |
| G2 (hop-related) | hop_length |
| hop_losses | |
| number_of paths_in_hops | |
| G3 (trans-related) | transponder_bitrate |
| transponder_modulation |
| Groups Combination | Attribute Subsets |
|---|---|
| G1 | S1 |
| G2 | S2 |
| G3 | S3 |
| G1 + G2 | S4 |
| G1 + G3 | S5 |
| G2 + G3 | S6 |
| G1 + G2 + G3 | S7 |
| Algorithm | Hyperparameter | Values | Default |
|---|---|---|---|
| LR | class_weigth | ‘balanced’ | None |
| solver | ‘lbfgs’, ‘liblinear’ | ‘lbfgs’ | |
| penalty | ‘l1’, ‘l2’, ‘elasticnet’ | ‘l2’ | |
| c | 100, 10, 1.0, 0.1, 0.01 | 1 | |
| SVC | class_weigth | None, ‘balanced’ | None |
| c | 0.1, 1, 10, 100 | 1 | |
| gamma | `scale’, ‘auto’ | `scale’ | |
| kernel | ‘linear’, ‘rbf’ | ‘rbf’ | |
| RFC | class_weight | None, ‘balanced’ | None |
| n_estimators | 25, 100, 250, 500 | 100 | |
| min_samples_split | 3, 7, 10, 13 | 2 | |
| max_depth | None, 2, 3, 5 | None | |
| GBC | n_estimators | 25, 100, 250, 500 | 100 |
| min_samples_split | 3, 7, 10, 13 | 2 | |
| max_depth | 1, 2, 3, 5 | 3 | |
| KNC | n_neighbors | 2, 3, 5, 10, 15 | 5 |
| leaf_size | 20, 25, 30, 35 | 30 | |
| p | 1, 2 | 2 | |
| MCPL | hidden_layer_sizes | (100), (50), (50,50) | (100) |
| activation | ‘tanh’, ‘relu’ | ‘relu’ | |
| solver | ‘sgd’, ‘adam’ | ‘adam’ | |
| alpha | 0.0001, 0.05 | 0.0001 | |
| learning_rate | ‘constant’, ‘adaptive’ | ‘constant’ |
| Model | Subset | Best PR Parameters | Best ROC Parameters |
|---|---|---|---|
| LR | C = 0.1, class_weight = ‘balanced’, penalty = ‘l1’, solver = ‘liblinear’ | C = 100, class_weight = ‘balanced’ | |
| C = 0.01, class_weight = ‘balanced’ | C = 0.01, class_weight = ‘balanced’, penalty = ‘l1’, solver = ‘liblinear’ | ||
| C = 0.01, class_weight = ‘balanced’, penalty = ‘l1’, solver = ‘liblinear’ | C = 0.01, class_weight = ‘balanced’, penalty = ‘l1’, solver = ‘liblinear’ | ||
| C = 0.01, class_weight = ‘balanced’ | C = 0.01, class_weight = ‘balanced’, penalty = ‘l1’, solver = ‘liblinear’ | ||
| C = 10, class_weight = ‘balanced’ | C = 0.01, class_weight = ‘balanced’ | ||
| class_weight = ‘balanced’, solver = ‘liblinear’ | C = 0.01, class_weight = ‘balanced’, solver = ‘liblinear’ | ||
| class_weight = ‘balanced’, solver = ‘liblinear’ | C = 0.01, class_weight = ‘balanced’, solver = ‘liblinear’ | ||
| SVC | C = 0.1, gamma = ‘auto’ | C = 0.1, class_weight = ‘balanced’, kernel = ‘linear’ | |
| C = 100 | C = 0.1, class_weight = ‘balanced’, gamma = ‘auto’ | ||
| C = 100, kernel = ‘linear’ | C = 0.1, class_weight = ‘balanced’, kernel = ‘linear’ | ||
| C = 100 | C = 0.1, class_weight = ‘balanced’ | ||
| C = 1, class_weight = ‘balanced’, gamma = ‘auto’ | C = 1, class_weight = ‘balanced’, gamma = ‘auto’ | ||
| C = 0.1, gamma = ‘auto’, kernel = ‘linear’ | C = 0.1, class_weight = ‘balanced’ | ||
| C = 0.1, kernel = ‘linear’ | C = 0.1, class_weight = ‘balanced’, gamma = ‘auto’ | ||
| RFC | class_weight = ‘balanced’, max_depth = 2, min_samples_split = 10, n_estimators = 25 | max_depth = 2, min_samples_split = 3, n_estimators = 500 | |
| min_samples_split = 13 | min_samples_split = 7, n_estimators = 500 | ||
| class_weight = ‘balanced’, min_samples_split = 10 | class_weight = ‘balanced’, max_depth = 2, min_samples_split = 10, n_estimators = 500 | ||
| min_samples_split = 13, n_estimators = 250 | max_depth = 5, min_samples_split = 3, n_estimators = 250 | ||
| max_depth = 3, min_samples_split = 10, n_estimators = 250 | max_depth = 5, min_samples_split = 10 | ||
| min_samples_split = 13, n_estimators = 250 | max_depth = 5, min_samples_split = 13, n_estimators = 500 | ||
| min_samples_split = 13, n_estimators = 500 | max_depth = 5, min_samples_split = 3, n_estimators = 500 | ||
| GBC | max_depth = 5, min_samples_split = 12 | max_depth = 2, min_samples_split = 12, n_estimators = 25 | |
| min_samples_split = 12 | min_samples_split = 3, n_estimators = 500 | ||
| max_depth = 2, min_samples_split = 3, n_estimators = 25 | max_depth = 2, min_samples_split = 3, n_estimators = 25 | ||
| min_samples_split = 8 | max_depth = 5, min_samples_split = 3 | ||
| max_depth = 2, min_samples_split = 12 | max_depth = 5, min_samples_split = 8 | ||
| max_depth = 2, min_samples_split = 12 | max_depth = 2, min_samples_split = 3 | ||
| max_depth = 2, min_samples_split = 12, n_estimators = 250 | min_samples_split = 8 | ||
| KNC | leaf_size = 25, n_neighbors = 15 | n_neighbors = 15 | |
| n_neighbors = 2 | leaf_size = 35, n_neighbors = 15, p = 1 | ||
| n_neighbors = 2, p = 1 | leaf_size = 20, n_neighbors = 10, p = 1 | ||
| leaf_size = 20, n_neighbors = 3 | leaf_size = 20, n_neighbors = 15, p = 1 | ||
| p = 1 | n_neighbors = 15, p = 1 | ||
| n_neighbors = 2 | leaf_size = 25, n_neighbors = 15, p = 1 | ||
| leaf_size = 35, n_neighbors = 2 | leaf_size = 20, n_neighbors = 15, p = 1 | ||
| MLPC | solver = ‘sgd’ | activation = ‘tanh’, solver = ‘sgd’ | |
| activation = ‘tanh’, alpha = 0.05, hidden_layer_sizes = (50), learning_rate = ‘adaptive’ | activation = ‘tanh’, learning_rate = ‘adaptive’ | ||
| activation = ‘tanh’, hidden_layer_sizes = (50,) | activation = ‘tanh’ | ||
| activation = ‘tanh’, hidden_layer_sizes = (50,50) | activation = ‘tanh’, learning_rate = ‘adaptive’ | ||
| hidden_layer_sizes = (50,50) | activation = ‘tanh’, hidden_layer_sizes = (50,50) | ||
| activation = ‘tanh’ | activation = ‘tanh’, hidden_layer_sizes = (50), | ||
| learning_rate = ‘adaptive’ | |||
| activation = ‘tanh’, alpha = 0.05 | activation = ‘tanh’, alpha = 0.05, solver = ‘sgd’ |
| Model | S1 | S2 | S3 | S4 | S5 | S6 | S7 |
|---|---|---|---|---|---|---|---|
| LR | 0.094 | 0.096 | 0.189 | 0.096 | 0.101 | 0.167 | 0.167 |
| SVC | 0.148 | 0.131 | 0.253 | 0.128 | 0.177 | 0.167 | 0.162 |
| RFC | 0.116 | 0.385 | 0.363 | 0.383 | 0.238 | 0.461 | 0.457 |
| GBC | 0.09 | 0.389 | 0.356 | 0.392 | 0.196 | 0.448 | 0.45 |
| KNC | 0.144 | 0.197 | 0.387 | 0.202 | 0.217 | 0.24 | 0.22 |
| MLPC | 0.117 | 0.083 | 0.189 | 0.101 | 0.178 | 0.175 | 0.175 |
| Model | S1 | S2 | S3 | S4 | S5 | S6 | S7 |
|---|---|---|---|---|---|---|---|
| LR | 0.818 | 0.799 | 0.687 | 0.797 | 0.896 | 0.898 | 0.898 |
| SVC | 0.816 | 0.799 | 0.561 | 0.795 | 0.899 | 0.87 | 0.872 |
| RFC | 0.818 | 0.856 | 0.718 | 0.854 | 0.897 | 0.915 | 0.917 |
| GBC | 0.806 | 0.833 | 0.72 | 0.836 | 0.896 | 0.891 | 0.894 |
| KNC | 0.683 | 0.739 | 0.625 | 0.737 | 0.789 | 0.79 | 0.797 |
| MLPC | 0.816 | 0.797 | 0.677 | 0.789 | 0.897 | 0.888 | 0.885 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kozdrowski, S.; Paziewski, P.; Cichosz, P.; Sujecki, S. A Comprehensive Study of Machine Learning Application to Transmission Quality Assessment in Optical Networks. Appl. Sci. 2023, 13, 4657. https://doi.org/10.3390/app13084657
Kozdrowski S, Paziewski P, Cichosz P, Sujecki S. A Comprehensive Study of Machine Learning Application to Transmission Quality Assessment in Optical Networks. Applied Sciences. 2023; 13(8):4657. https://doi.org/10.3390/app13084657
Chicago/Turabian StyleKozdrowski, Stanisław, Piotr Paziewski, Paweł Cichosz, and Sławomir Sujecki. 2023. "A Comprehensive Study of Machine Learning Application to Transmission Quality Assessment in Optical Networks" Applied Sciences 13, no. 8: 4657. https://doi.org/10.3390/app13084657
APA StyleKozdrowski, S., Paziewski, P., Cichosz, P., & Sujecki, S. (2023). A Comprehensive Study of Machine Learning Application to Transmission Quality Assessment in Optical Networks. Applied Sciences, 13(8), 4657. https://doi.org/10.3390/app13084657