
Dynamic Offloading Loading Optimization in Distributed Fault Diagnosis System with Deep Reinforcement Learning Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (1)
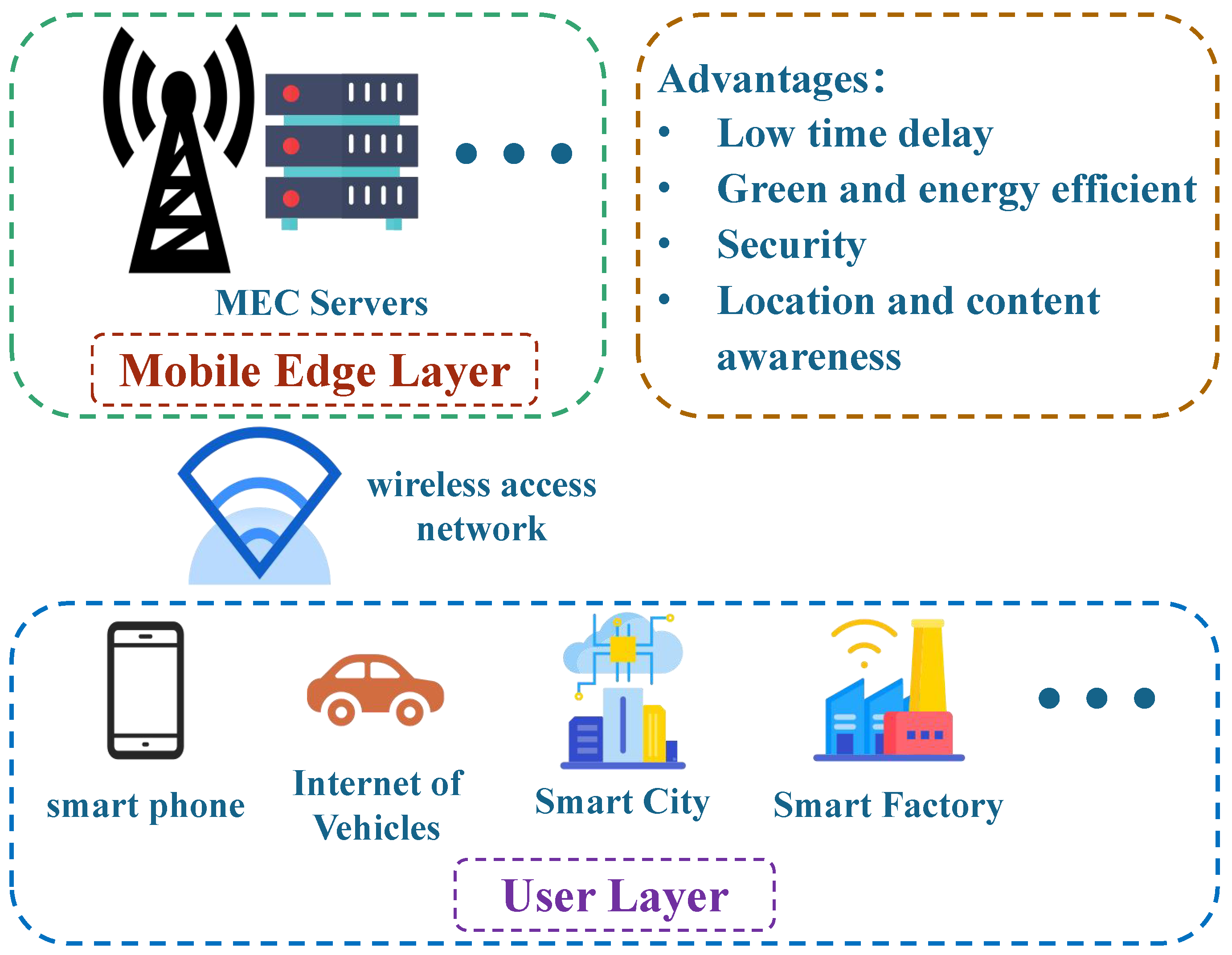
- A new framework for the intelligent fault diagnosis system based on the MEC framework is proposed, in which MEC servers and intelligent terminals can process monitoring data and the ratio determined by the offload policy of the agent server. Compared with the traditional fault diagnosis system, the intelligent fault diagnosis system solves the problems of limited computing resources and network delay and increases the intelligence of the equipment.
- (2)
- Two offloading scenarios of the intelligent fault diagnosis system are modeled: one-to-one and one-to-multiple. One-to-one means that one MEC server can only be connected by one intelligent terminal simultaneously, and one-to-multiple implies that multiple intelligent terminals can be connected to the same MEC server simultaneously. The optimization goal is taking the maximum time delay for the system to complete the computation task at each time slot. Every intelligent terminal and MEC server has its energy constraints, and the agent determines the power allocation during the offloading process.
- (3)
- The offloading decision optimization algorithm based on the combination of convex optimization and deep reinforcement learning is designed. Firstly, the convex optimization methods are used to solve the connection problem of the intelligent terminal needing to choose which MEC server. Then, the resource allocation of intelligent fault diagnosis system offloading is given by the DQN and DDPG algorithm.
2. The Intelligent Fault Diagnosis System Model
2.1. Network Model of Intelligent Fault Diagnosis System
2.2. Communication Model of MEC Servers and Intelligent Terminals
2.3. Computing Model of Intelligent Fault Diagnosis System
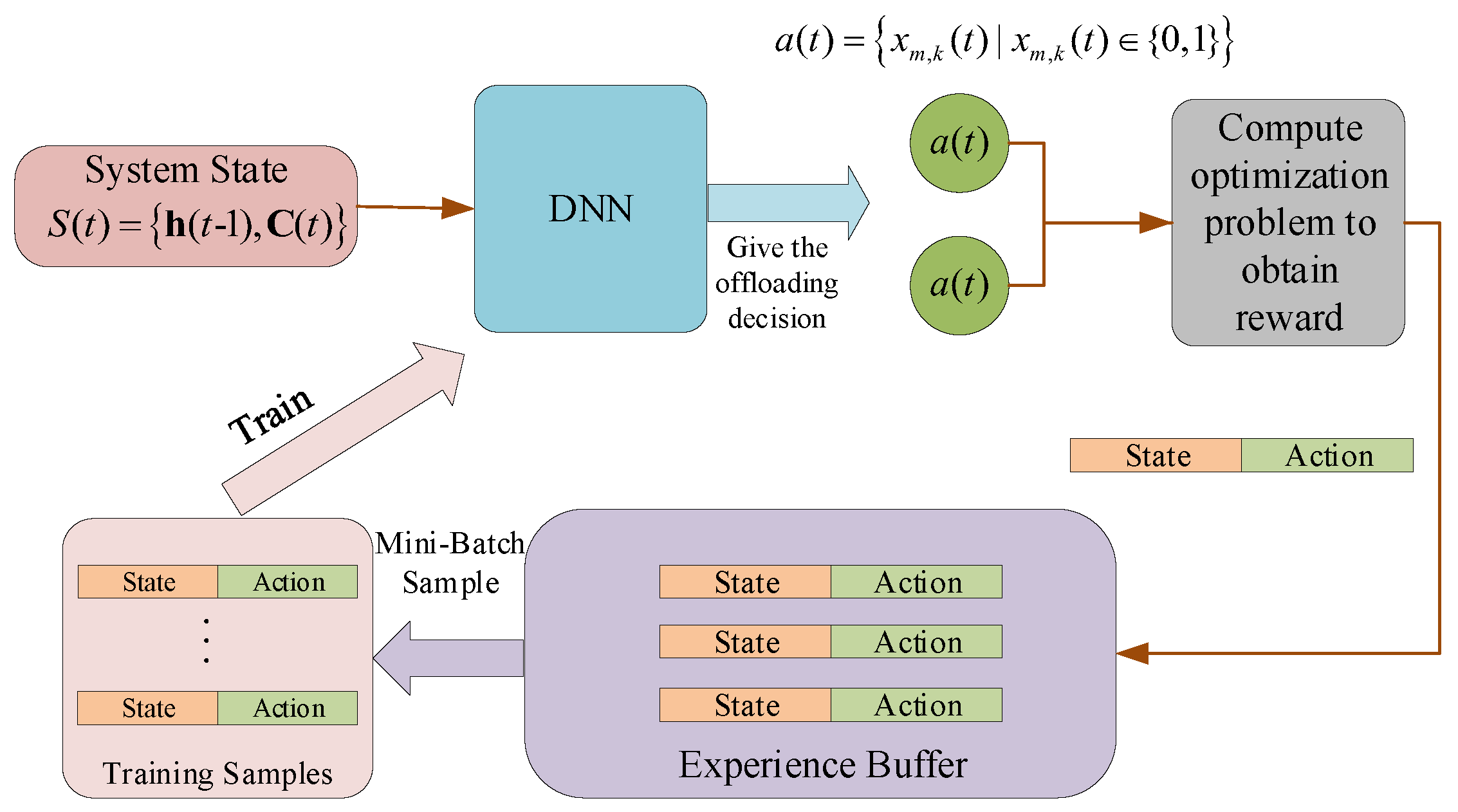
3. DQN-Based Offloading Design
3.1. System State and Action Spaces
3.2. Reward Function
- (1)
- Scenario 1: one MEC server serves one intelligent terminal
- (2)
- Scenario 2: one MEC server serves two intelligent terminals
| Algorithm 1 The DQN-based Offloading Algorithm |
|
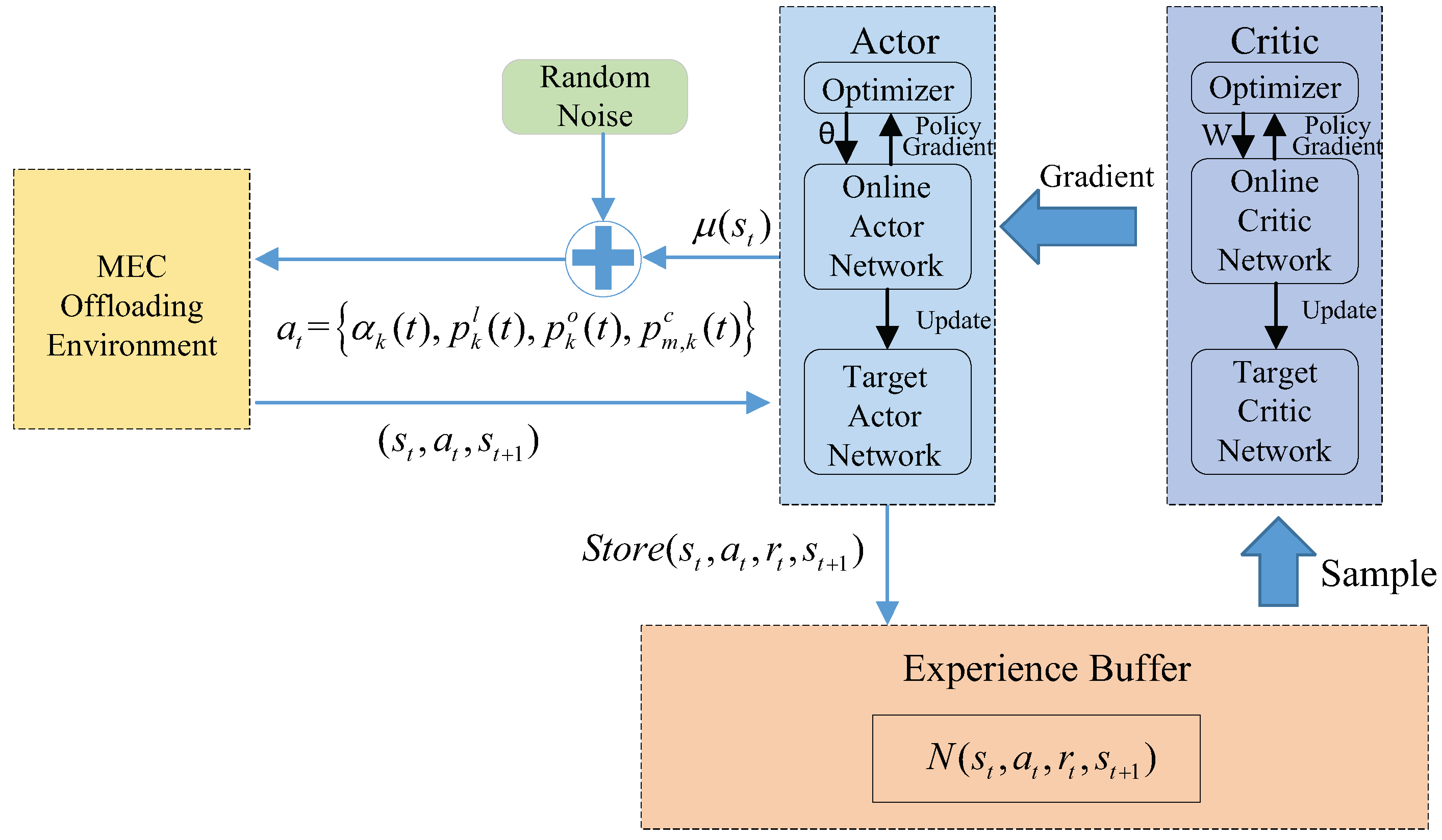
4. DDPG-Based Offloading Design
| Algorithm 2 The DDPG-based Offloading Algorithm |
|
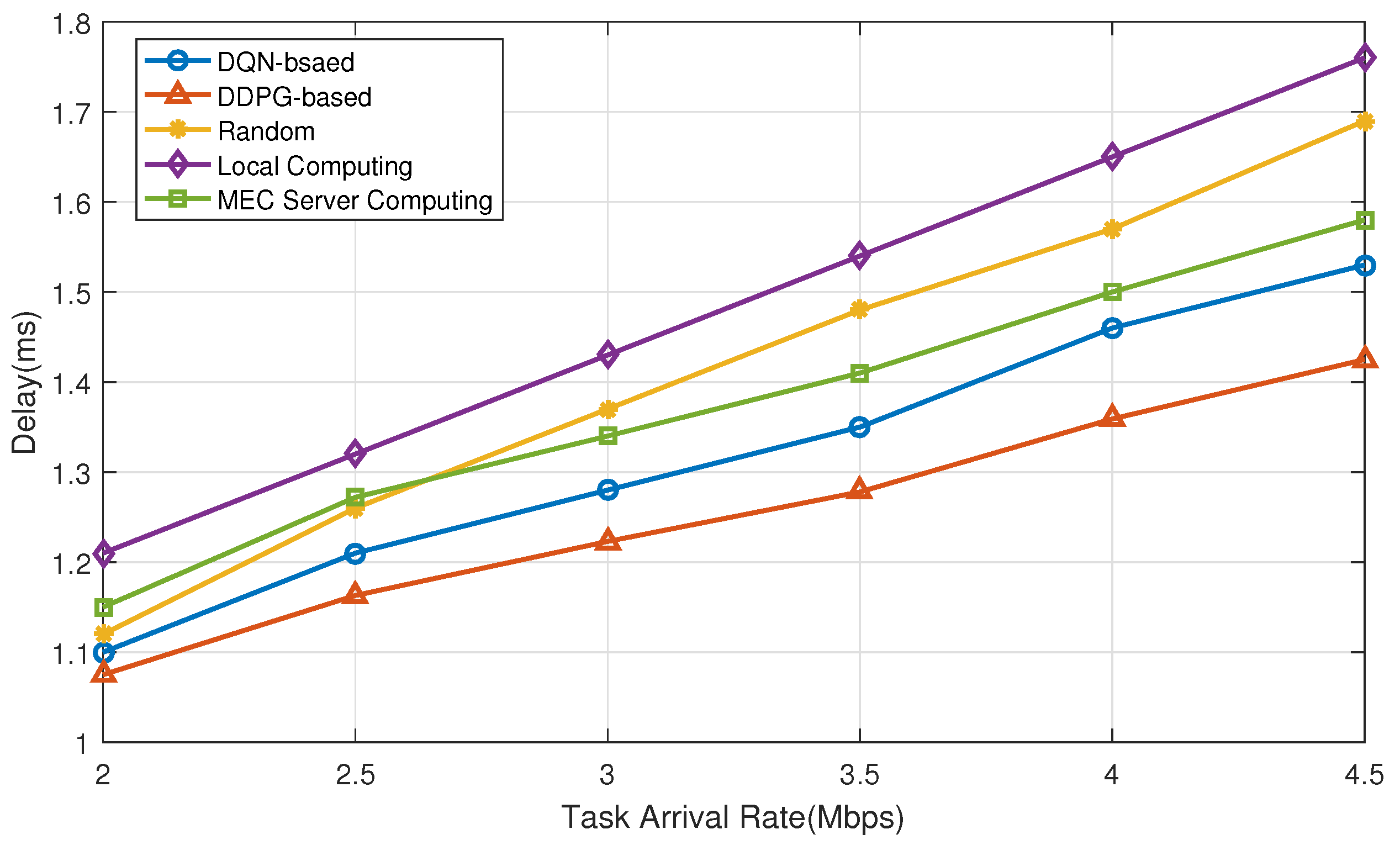
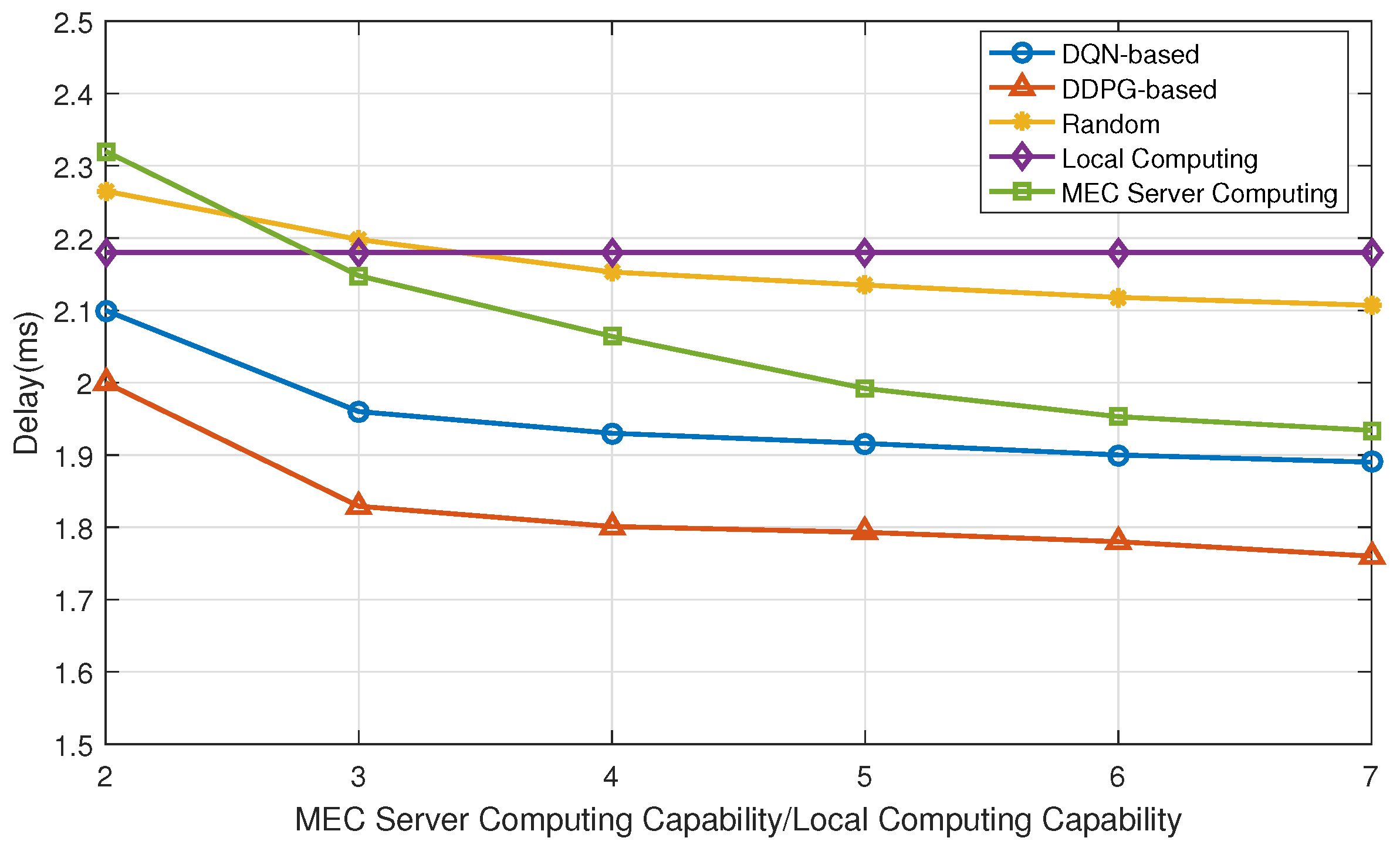
5. Numerical Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zhang, M.; Chen, J.; He, S.; Yang, L.; Gong, X.; Zhang, J. Privacy-preserving database assisted spectrum access for industrial internet of things: A distributed learning approach. IEEE Trans. Ind. Electron. 2019, 67, 7094–7103. [Google Scholar] [CrossRef]
- Yang, B.; Xu, S.; Lei, Y.; Lee, C.G.; Stewart, E.; Roberts, C. Multi-source transfer learning network to complement knowledge for intelligent diagnosis of machines with unseen faults. Mech. Syst. Signal Process. 2022, 162, 108095. [Google Scholar] [CrossRef]
- Azamfar, M.; Li, X.; Lee, J. Intelligent ball screw fault diagnosis using a deep domain adaptation methodology. Mech. Mach. Theory 2020, 151, 103932. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, C.; Yu, L.; Fang, H.; Hu, X. Rolling Bearing Weak Fault Feature Extraction under Variable Speed Conditions via Joint Sparsity and Low-Rankness in the Cyclic Order-Frequency Domain. Appl. Sci. 2022, 12, 2449. [Google Scholar] [CrossRef]
- Qin, C.; Jin, Y.; Zhang, Z.; Yu, H.; Tao, J.; Sun, H.; Liu, C. Anti-noise diesel engine misfire diagnosis using a multi-scale CNN-LSTM neural network with denoising module. CAAI Trans. Intell. Technol. 2023, 1–24. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Du, W.; Wang, S. Intelligent Diagnosis of Rotating Machinery Based on Optimized Adaptive Learning Dictionary and 1DCNN. Appl. Sci. 2021, 11, 11325. [Google Scholar] [CrossRef]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A perspective survey on deep transfer learning for fault diagnosis in industrial scenarios: Theories, applications and challenges. Mech. Syst. Signal Process. 2022, 167, 108487. [Google Scholar] [CrossRef]
- Wang, X.; Wang, T.; Ming, A.; Zhang, W.; Li, A.; Chu, F. Semi-supervised hierarchical attribute representation learning via multi-layer matrix factorization for machinery fault diagnosis. Mech. Mach. Theory 2022, 167, 104445. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, J.; Deng, C.; Wang, C.; Wang, Y. Residual deep subdomain adaptation network: A new method for intelligent fault diagnosis of bearings across multiple domains. Mech. Mach. Theory 2022, 169, 104635. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Jiang, D.; Jiang, Z. Collaborative deep learning framework for fault diagnosis in distributed complex systems. Mech. Syst. Signal Process. 2021, 156, 107650. [Google Scholar] [CrossRef]
- Deng, H.; Diao, Y.; Wu, W.; Zhang, J.; Ma, M.; Zhong, X. A high-speed D-CART online fault diagnosis algorithm for rotor systems. Appl. Intell. 2020, 50, 29–41. [Google Scholar] [CrossRef]
- Zhang, Z.; Guan, C.; Chen, H.; Yang, X.; Gong, W.; Yang, A. Adaptive Privacy-Preserving Federated Learning for Fault Diagnosis in Internet of Ships. IEEE Internet Things J. 2021, 9, 6844–6854. [Google Scholar] [CrossRef]
- Iqbal, R.; Maniak, T.; Doctor, F.; Karyotis, C. Fault detection and isolation in industrial processes using deep learning approaches. IEEE Trans. Ind. Inform. 2019, 15, 3077–3084. [Google Scholar] [CrossRef]
- Pan, T.; Chen, J.; Zhou, Z.; Wang, C.; He, S. A novel deep learning network via multiscale inner product with locally connected feature extraction for intelligent fault detection. IEEE Trans. Ind. Inform. 2019, 15, 5119–5128. [Google Scholar] [CrossRef]
- Liu, S.; Guo, C.; Al-Turjman, F.; Muhammad, K.; de Albuquerque, V.H.C. Reliability of response region: A novel mechanism in visual tracking by edge computing for IIoT environments. Mech. Syst. Signal Process. 2020, 138, 106537. [Google Scholar] [CrossRef]
- Kumar, K.; Liu, J.; Lu, Y.H.; Bhargava, B. A survey of computation offloading for mobile systems. Mob. Netw. Appl. 2013, 18, 129–140. [Google Scholar] [CrossRef]
- Nilsen, J.M.; Park, J.H.; Yun, S.; Kang, J.M.; Jung, H. Competing Miners: A Synergetic Solution for Combining Blockchain and Edge Computing in Unmanned Aerial Vehicle Networks. Appl. Sci. 2022, 12, 2581. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Li, D.; Zhang, H. Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sens. 2022, 14, 4016. [Google Scholar] [CrossRef]
- Huda, S.A.; Moh, S. Survey on computation offloading in UAV-Enabled mobile edge computing. J. Netw. Comput. Appl. 2022, 201, 103341. [Google Scholar] [CrossRef]
- Liao, L.; Lai, Y.; Yang, F.; Zeng, W. Online Computation Offloading with Double Reinforcement Learning Algorithm in Mobile Edge Computing. J. Parallel Distrib. Comput. 2023, 171, 28–39. [Google Scholar] [CrossRef]
- Lu, W.; Mo, Y.; Feng, Y.; Gao, Y.; Zhao, N.; Wu, Y.; Nallanathan, A. Secure transmission for multi-UAV-assisted mobile edge computing based on reinforcement learning. IEEE Trans. Netw. Sci. Eng. 2022, 1–12. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, R.; Lai, S.; Fan, L.; Lei, X.; Karagiannidis, G.K. Distributed machine learning for multiuser mobile edge computing systems. IEEE J. Sel. Top. Signal Process. 2022, 16, 460–473. [Google Scholar] [CrossRef]
- Esposito, C.; Castiglione, A.; Pop, F.; Choo, K.K.R. Challenges of connecting edge and cloud computing: A security and forensic perspective. IEEE Cloud Comput. 2017, 4, 13–17. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, M.; Shou, G.; Chen, Y.; Chen, S. Toward edge intelligence: Multiaccess edge computing for 5G and Internet of Things. IEEE Internet Things J. 2020, 7, 6722–6747. [Google Scholar] [CrossRef]
- Wu, D.; Huang, X.; Xie, X.; Nie, X.; Bao, L.; Qin, Z. LEDGE: Leveraging edge computing for resilient access management of mobile IoT. IEEE Trans. Mob. Comput. 2019, 20, 1110–1125. [Google Scholar] [CrossRef]
- Cui, Q.; Zhang, J.; Zhang, X.; Chen, K.C.; Tao, X.; Zhang, P. Online anticipatory proactive network association in mobile edge computing for IoT. IEEE Trans. Wirel. Commun. 2020, 19, 4519–4534. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Barbarossa, S.; Sardellitti, S.; Di Lorenzo, P. Communicating while computing: Distributed mobile cloud computing over 5G heterogeneous networks. IEEE Signal Process. Mag. 2014, 31, 45–55. [Google Scholar] [CrossRef]
- Zhang, W.; Wen, Y.; Guan, K.; Kilper, D.; Luo, H.; Wu, D.O. Energy-optimal mobile cloud computing under stochastic wireless channel. IEEE Trans. Wirel. Commun. 2013, 12, 4569–4581. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Jiao, L.; Fu, X. To offload or not to offload: An efficient code partition algorithm for mobile cloud computing. In Proceedings of the 2012 IEEE 1st International Conference on Cloud Networking (CLOUDNET), Paris, France, 28–30 November 2012; pp. 80–86. [Google Scholar]
- Mahmoodi, S.E.; Uma, R.; Subbalakshmi, K. Optimal joint scheduling and cloud offloading for mobile applications. IEEE Trans. Cloud Comput. 2016, 7, 301–313. [Google Scholar] [CrossRef]
- Lu, H.; Gu, C.; Luo, F.; Ding, W.; Liu, X. Optimization of lightweight task offloading strategy for mobile edge computing based on deep reinforcement learning. Future Gener. Comput. Syst. 2020, 102, 847–861. [Google Scholar] [CrossRef]
- Wang, D.; Tian, X.; Cui, H.; Liu, Z. Reinforcement learning-based joint task offloading and migration schemes optimization in mobility-aware MEC network. China Commun. 2020, 17, 31–44. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep reinforcement learning based mobile edge computing for intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Ren, Y.; Sun, Y.; Peng, M. Deep reinforcement learning based computation offloading in fog enabled industrial Internet of Things. IEEE Trans. Ind. Inform. 2020, 17, 4978–4987. [Google Scholar] [CrossRef]
- Min, M.; Xiao, L.; Chen, Y.; Cheng, P.; Wu, D.; Zhuang, W. Learning-based computation offloading for IoT devices with energy harvesting. IEEE Trans. Veh. Technol. 2019, 68, 1930–1941. [Google Scholar] [CrossRef]
- Le Thanh, T.; Hu, R.Q. Mobility-aware edge caching and computing in vehicle networks: A deep reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 10190–10203. [Google Scholar]
- Wei, Z.; Zhao, B.; Su, J.; Lu, X. Dynamic edge computation offloading for Internet of Things with energy harvesting: A learning method. IEEE Internet Things J. 2018, 6, 4436–4447. [Google Scholar] [CrossRef]
- Zhang, J.; Du, J.; Shen, Y.; Wang, J. Dynamic computation offloading with energy harvesting devices: A hybrid-decision-based deep reinforcement learning approach. IEEE Internet Things J. 2020, 7, 9303–9317. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Guo, Q.; Wang, R.; Shi, M.; Yan, F.; Wang, R. Dynamic Offloading Loading Optimization in Distributed Fault Diagnosis System with Deep Reinforcement Learning Approach. Appl. Sci. 2023, 13, 4096. https://doi.org/10.3390/app13074096
Yu L, Guo Q, Wang R, Shi M, Yan F, Wang R. Dynamic Offloading Loading Optimization in Distributed Fault Diagnosis System with Deep Reinforcement Learning Approach. Applied Sciences. 2023; 13(7):4096. https://doi.org/10.3390/app13074096
Chicago/Turabian StyleYu, Liang, Qixin Guo, Rui Wang, Minyan Shi, Fucheng Yan, and Ran Wang. 2023. "Dynamic Offloading Loading Optimization in Distributed Fault Diagnosis System with Deep Reinforcement Learning Approach" Applied Sciences 13, no. 7: 4096. https://doi.org/10.3390/app13074096
APA StyleYu, L., Guo, Q., Wang, R., Shi, M., Yan, F., & Wang, R. (2023). Dynamic Offloading Loading Optimization in Distributed Fault Diagnosis System with Deep Reinforcement Learning Approach. Applied Sciences, 13(7), 4096. https://doi.org/10.3390/app13074096