Abstract
Multilingual neural machine translation (MNMT) models are theoretically attractive for low- and zero-resource language pairs with the impact of cross-lingual knowledge transfer. Existing approaches mainly focus on English-centric directions and always underperform compared to their pivot-based counterparts for non-English directions. In this work, we aim to build a many-to-many MNMT system with an emphasis on the quality of non-English directions by exploring selective and aligned online data augmentation algorithms. Based on our findings showing that the augmented synthetic samples are not “the more, the better” we propose selective online back-translation (SOBT) and thoroughly study different selection criteria to pick suitable samples for training. Furthermore, we boost SOBT with cross-lingual online substitution (CLOS) to align token representations and encourage transfer learning. Our intuition is based on the hypothesis that a universal cross-lingual representation leads to a better multilingual translation performance, especially for non-English directions. Comparing to previous state-of-the-art many-to-many MNMT models and conventional pivot-based methods, experiments on IWSLT2014 and OPUS-100 translation benchmarks show that our approach achieves a competitive or even better performance on English-centric directions and achieves up to ∼12 BLEU for non-English directions. All of our models and codes are publicly available.
1. Introduction
In recent years, neural machine translation (NMT) has achieved remarkable progress in bilingual settings with rich parallel resources [1,2,3,4], but still faces great challenges for practical applications in low- and zero-resource scenarios where there are few or no parallel sentences for training [5,6]. Recent studies show the promise in encapsulating more than one translation direction in a single model and training multilingual neural machine translation (MNMT) systems [7,8,9,10]. Using MNMT models can reduce the cost of model training and deployment [6], encourage knowledge transfer between language pairs to improve low-resource translation [11,12,13,14] and even show the possibility of zero-shot translation (direct translation between language pairs unseen during training) [10,15,16]. Despite the potential translation ability in low- and zero-resource scenarios, MNMT models consistently underperform compared to their bilingual pivot-based counterparts, resulting in considerably poorer translations [16,17,18,19]. In addition, an optimal setting for MNMT should be effective for all language pairs, while most previous works focus on English-centric directions and non-English directions still lag behind [10,20,21]. Researchers ascribe this deteriorated performance to the model’s sensitivity to training conditions and spurious correlations between the input and output language [21,22]. As shown in Table 1, the major source of the inferior zero-shot translation performance comes from the off-target problem, where MNMT models tend to translate into a wrong target language or simply copy the source sentence in zero-shot directions.

Table 1.
Comparison between zero-shot translation with a baseline MNMT model and a pivot-based translation (English as the pivot language) for Spanish → German. The baseline MNMT model often translates into an incorrect language, such as translating into English rather than German or copying the source sentence.
As back-translation has aroused more and more interests for improving NMT [23,24,25], a commonly used method for improving massively MNMT is to generate synthetic sentence pairs for all language directions and train a many-to-many MNMT model from scratch on the merged datasets of both real and synthetic sentence pairs [16,17]. As decoding the whole training set for all language directions makes the scalability to massively MNMT questionable, Zhang et al. [21] proposed the random online back-translation (ROBT) algorithm, fine-tuning a pre-trained MNMT model for unseen language pairs with pseudo sentence pairs generated by back-translating the target-side sentences during training. However, the vanilla ROBT algorithm generates pool sentence pairs in non-English directions intuitively and has a low upper bound for improving multilingual translation. Some other researchers reported improving massively MNMT performance with data augmentation by building code-switched sentence pairs [26,27]. They generated augmented samples on both parallel and monolingual data by replacing words with the same meaning in synonym dictionaries. However, prepared synonym dictionaries or word alignment models are needed in these methods, which are always unreachable for non-English directions.
In this paper, we mainly focus on improving the translation quality of massively MNMT systems, in particular non-English directions. We explore reasons and solutions for two specific problems that still remain unsolved:
- Low-quality synthetic sentence pairs, such as samples generated by the vanilla ROBT algorithm, are not very useful for many-to-many MNMT models. Therefore, how can we generate suitable augmented samples to deliver greater and continued benefits?
- Another limitation of many-to-many MNMT is the language variant encoder representations, which means the encoder representations of parallel sentences generated by the model are dissimilar. Therefore, how can we align token representations and encourage transfer learning utilizing synthetic sentences?
We address these problems by investigating selective and aligned online data augmentation algorithms. Firstly, we analyse the shortcomings of ROBT and find that it can be easily surpassed by a simple but effective pivot online back-translation (POBT) algorithm, where sentences of the pivot language (mostly English) are back-translated rather than the translated to the target language. Secondly, we propose selective online back-translation (SOBT) by dynamically selecting suitable training samples from synthetic sentence pairs and fine-tuning the MNMT model with contrastive loss to achieve continued improvements, especially for non-English directions. We thoroughly investigate several selection strategies involving cross-entropy and quality estimation. Thirdly, to minimize encoder representation divergence between different languages, we further propose cross-lingual online substitution (CLOS) by generating hard or soft code-switched source sentences on-the-fly with implicit alignment information instead of explicit multilingual dictionaries or word alignment models. CLOS can be combined with SOBT to greatly improve the performance of many-to-many MNMT systems.
To our best knowledge, we are the first to investigate and establish a complete online data augmentation algorithm for massively many-to-many MNMT. The main contributions of our work can be summarized as follows:
- We propose the POBT and SOBT algorithms to generate and select suitable training samples to improve massively many-to-many MNMT, especially for non-English directions.
- We thoroughly study different selection criteria, such as CE loss and QE score, concluding that the combination of CE loss and QE scores performs best.
- We boost the SOBT algorithm with CLOS utilizing implicit alignment information instead of external resources to strengthen transfer learning between non-English directions.
- We conduct experiments on two multilingual translation benchmarks with detailed analysis, showing that our algorithms can achieve significant improvements in both English-centric and non-English directions compared with previous works.
2. Related Work
2.1. Pivot Translation
In practice, it is almost impossible to train NMT models between arbitrary language pairs, because most language pairs have no parallel corpora, and training models is resource-consuming. A simple but commonly used solution is pivot translation, given that most languages share a parallel corpus with a pivot language, such as English (due to its widespread global usage). Concretely, source–pivot (S-P) and pivot–target (P-T) models have been built, with the source sentence cascading through the S-P andP-T systems to generate the target sentence. Sometimes, more than one pivot language may be required in the translation route:
where are the pivot languages. Previous studies have proven pivot translation an effective and practical way for translation between unseen language pairs and can be applied to different architectures, such as statistical machine translation (SMT) [28,29] and NMT [19,30,31]. Despite its convenience and practicability, pivot translation has two disadvantages: (a) translation error propagation in the cascaded pipeline, which is exacerbated when the translation route path increases and (b) an inference time and computation cost nearly double that of a direct translation model.
2.2. Zero-Shot Translation
Johnson et al. [10] shows that MNMT models, exposed to zero bilingual resources between the source and target languages during training, are able to generate reasonable translations on zero-shot directions as long as both source and target languages were included in training. The possibility comes from MNMT models’ language-agnostic encoder representation ability, encoding different languages into one shared space. Compared with pivot translation, zero-shot translation can halve the inference time and circumvent error propagation, making it attractive both theoretically and practically. However, zero-shot translation is still lagging behind pivot translation, due to:
- Spurious correlations between input and output language. During training, MNMT models are not exposed to unseen language pairs and can only learn associations between the observed language pairs. During testing, models tend to output languages observed together with the source languages during training [16,17].
- Language variant encoder representations. The encoder representations generated by MNMT models for equivalent source and target languages are dissimilar, partly because transfer learning performs worse between unrelated zero-shot language pairs [22].
To address these limitations, several methods have been proposed including minimizing divergence between encoder representations [13,14], encouraging output agreement [15,18], addressing wrong language generation [32], etc.
2.3. Back-Translation
Back-translation [24] is an effective way to improve translation performance by translating target-side monolingual data to generate synthetic sentence pairs, widely used in research and industrial scenarios. Most studies on back-translation for zero-shot translation generate synthetic sentence pairs for all language pairs in an offline manner [16,33], making it more computationally expensive and not very scalable for massively multilingual translation. For example, in the OPUS-100 settings, there are 9900 language directions, of which 9702 are zero-shot translation directions. Zhang et al. [21] addressed this problem by performing online back-translation paired with randomly sampled intermediate languages. They generated synthetic sentence pairs by back-translating target-side sentence y from language into from language where is randomly sampled, named random online back-translation (ROBT). They empirically demonstrated, for the first time, the feasibility of back-translation in massively multilingual settings to improve zero-shot translation. Other studies investigated the pros and cons of online back-translation for unsupervised machine translation, proving the effectiveness and scalability of online back-translation [34,35]. The study by Zhang et al. [21] is closest to ours, having an emphasis on massively many-to-many machine translation. Our work mainly investigates ROBT’s shortcomings and improves it with a more effective and complete algorithm.
2.4. Aligned Augmentation
Most traditional studies have proven cross-lingual language model pre-training as an effective way for representation learning [36,37], while cross-lingual information is mostly obtained from shared subword vocabulary during pre-training. Mikolov et al. [38] first introduced dictionaries to align word representations from different languages. Following studies improved massively MNMT performance with data augmentation by building code-switched sentence pairs in multilingual pre-training [26] or directly in NMT model training [27]. They explicitly substituted a source word with the same meaning in a synonym dictionary. In this way, prepared synonym dictionaries or word alignment models are needed, which are always unreachable in low- and zero-resource scenarios. Different from these studies, we generate code-switched sentence pairs with back-translation on-the-fly, with no explicit dictionaries or word alignment models, making it effective and suitable for zero-shot translation in massively MNMT scenarios.
3. Methodology
3.1. Many-to-Many MNMT
Neural machine translation systems handling translation between multiple language pairs are referred as many-to-many MNMT systems. The ultimate goal of many-to-many MNMT research is to develop one model for translation between as many languages as possible by effectively using the available training datasets [5]. This is conducted in order to reduce the need for multiple models and to make the translation process between languages more efficient and cost-effective. Formally, we define where L is a collection of M languages. denotes a parallel dataset of and D denotes the collection of all parallel datasets. Given and from as source and target sentences, MNMT translates with the encoder–decoder framework [1]:
where denote the encoder–decoder output and d is the model dimension.
We train the initial MNMT model with the following cross-entropy loss:
where is the model parameter.
3.2. Pivot Online Back-Translation
Prior work has scaled back-translation to massively many-to-many NMT by performing online back-translation paired with randomly sampled intermediate languages during training [21], called random online back-translation (ROBT). However, with a poor zero-shot initialization (translations are produced on-the-fly by the MNMT model being trained, which initially performs poorly between unseen language pairs), ROBT converges to a sub-optimal state with only a few thousand steps.
Most sentence pairs for MNMT models are commonly English-centric (i.e., English either as the source or target language) and non-English directions can be pivoted through English. Therefore, we turn to back-translate English sentences (either the source or target side) into a randomly sampled intermediate language, named pivot online back-translation (POBT), which is detailed in Algorithm 1. For each training sample , we uniformly sample an intermediate language where ≠ and ≠, and back-translate (if = ) or (if = ) into to obtain a new synthetic sample. Both real and synthetic sentence pairs are merged for training. With a better initial performance of English-centric language pairs adequately seen during training, POBT can generate high-quality synthetic sentence pairs and deliver larger benefits for non-English directions than ROBT. Following Zhang et al. [21], we used batch-based greedy decoding to reduce the computational cost.
| Algorithm 1: Algorithm for Pivot Online Back-Translation |
Input : Training data, D; Initialized MNMT model, M; Language set, L; Output: Zero-shot improved MNMT model, M 17 end 18 return M |
3.3. Selective Online Back-Translation
The key idea of ROBT or POBT is to generate synthetic sentence pairs for non-English directions so that many-to-many NMT models can adequately learn associations between all language pairs. However, both ROBT and POBT have their limitation for continued improvements: (1) ROBT quickly converges to a sub-optimal state because of MNMT model’s poor initialization in non-English directions and (2) POBT has an error propagation problem of the source–pivot–target pipeline. Fortunately, we observe that synthetic sentence pairs produced by ROBT and POBT differ in quality during the whole training period: sentence pairs produced by POBT are of relatively high-quality and suitable for training at the beginning, while those produced by ROBT have a rapid and continuous growth in quality and similarity at later stages with an improved MNMT model. Thus, we propose a more effective online back-translation algorithm for non-English directions by combining the advantages of ROBT and POBT, called selective online back-translation (SOBT). Concretely, we generate back-translated candidates with both ROBT and POBT in each mini-batch and select the final sentence pairs for training based on batch- and global-level selection criteria.
3.3.1. Batch-Level Selection Criterion
Given the synthetic mini-batch generated by ROBT and the synthetic mini-batch generated by POBT, we sort all sentence pairs in the current batch and select better ones according to CE loss and QE scores.
CE-based selection criterion. We compute the cross-entropy of each sentence pair from and in the reverse direction, which denotes how much of the synthetic sentences can be translated to ground-truth sentences on the target side. We refer to synthetic sentence pairs with lower cross-entropy as high-quality and semantically similar, which are more suitable for model training. Therefore, the selection criterion in each mini-batch can be formulated as:
where for example, denotes synthetic samples in , and denotes its sentence cross-entropy (mean of the cross-entropy of all words in the sentence).
QE-based selection criterion. Recent works on quality estimation (QE) has demonstrated that it is possible to achieve high levels of correlation with human judgments without a reference translation [39]. Intuitively, we utilize COMET [40], a neural framework for training multilingual machine translation evaluation models which obtains new state-of-the-art levels of correlation with human judgments, to assess the quality of sentence pairs generated by POBT and ROBT. The formulations of the QE-based selection criterion are the same as the CE-based selection criterion; however, we refer to synthetic sentence pairs with high QE scores as suitable training samples.
3.3.2. Global-Level Selection Criterion
Within the batch-level selection criterion, synthetic sentence pairs from related languages are always preferred partly because transfer learning works better with related languages, which leads to severe performance imbalances across all language pairs. An effective approach to improve and balance performance globally is to apply proper data sampling strategies based on the performance of each language pair. However, calculating all training samples’ cross-entropy as global performance at each update brings a formidable computational cost and is not realistic in training. In addition, cross-entropy of one mini-batch only reflects the performance on the current batch.
Therefore, we propose a global-level selection criterion by calculating and normalizing the cross-entropy and QE score of a GSC dataset at each update, and sample synthetic sentence pairs based on the normalized distribution. The GSC dataset is dynamically composed of previous N mini-batches where the “oldest” mini-batch is replaced by the current mini-batch at each update. This dexterously dynamic dataset makes it possible to involve all samples during training and avoid inaccuracy loss or score from fixed mini-batches. The key insight of the global-level selection criterion is that language pairs with higher global cross-entropy and lower QE scores are starved for more training samples. For a language pair , let denote its global cross-entropy and denote its global QE score, which can be calculated from the GSC dataset. The probability of sampling for can be formulated as:
To control the ratio of samples from different language pairs, we select with the probability proportional to , where T is the sampling temperature, set as 2 in our experiments.
3.3.3. Fine-Tuning with Contrastive Loss
Batch-level and global-level selection criteria can be combined for balanced and continuous improvements by selecting synthetic samples with the batch-level criterion, and then sampling with the global-level criterion. During training, we further derive language-agnostic sentence embeddings with a contrastive loss on the basis of the selection criteria. Formally, given two synthetic sentence pairs generated by POBT and ROBT, respectively, we choose the selected sentence pair as the positive sample and the rest as the negative sample . The objective of contrastive learning is to minimize the following loss:
where calculates the similarity of different sentences and denotes the mean-pooling of encoded output.
3.4. Cross-Lingual Online Substitution
Inspired by constructive learning, recent work generates code-switched samples with multilingual dictionaries or through word alignment models [26,27], trying to close the representation gap between different languages. However, these data augmentation methods need other explicit cross-lingual dictionaries (which is hard to obtain for zero-shot language pairs) or additional models such as MUSE [41] (which is computationally expensive). Differently, we propose to bridge the representation gap among different languages through cross-lingual online substitution (CLOS) without external resources. Given a training sample and a sampled intermediate language , we attempt to generate code-switched synthetic sentences rather than sentences of which all words are from language . Concretely, we investigate two variants in our work:
Hard substitution. We build vocabulary for each language and V as the joint vocabulary of all languages for training. At the decoding step t of online back-translation, the decoded word is randomly substituted for its synonym of another language with a probability of p. We use cosine similarity of a word’s encoder output to determine the most semantically similar word. As illustrated in Figure 1, the German word l“Katze” and “Tisch” in the back-translated sentence are replaced by the French word “chat” and Spanish word “mesa”, respectively. The new code-switched synthetic sentence is paired with the original Chinese sentence for training. Since the word representation depends on the context, the word with similar meanings across different languages can share a similar representation.
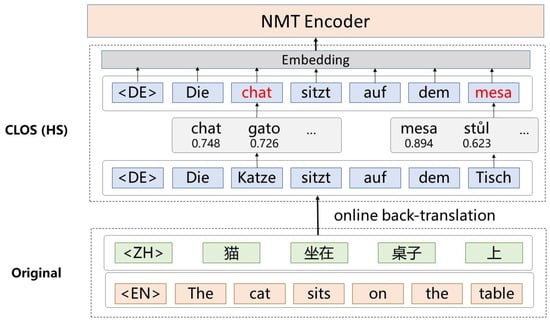
Figure 1.
Cross-lingual online substitution by randomly replacing words with their synonyms from other languages. Hard substitution determines the synonyms by ranking the embedded similarities.
Soft substitution. Different from the discrete nature of hard substitution, we randomly replace with a soft word, which is a probabilistic distribution over the vocabulary, as shown in Figure 2. Soft substitution can capture a mixture of multiple candidate words with adequate variations. Suppose E is the embedding matrix of all V words, the embedding of soft word w is:
where is the normalized cosine similarity of with the ith word in the word set of , and .
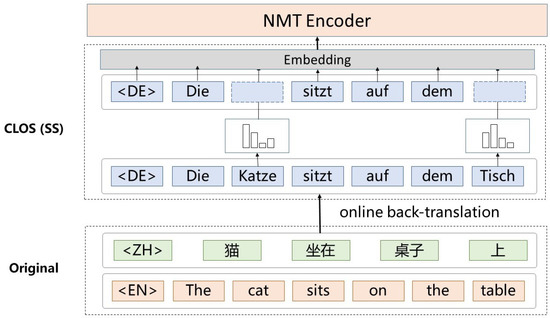
Figure 2.
Cross-lingual online substitution by randomly replacing words with their synonyms from other languages. Soft substitution replaces the embedding of one word by a weighted combination of multiple semantically similar words.
3.5. Training Schedule
To achieve optimal performance, we break down the whole training schedule into three stages: pre-training stage, augmentation fine-tuning stage, and substitution fine-tuning stage. The pre-training stage is equivalent to vanilla MNMT model training. In the augmentation and substitution fine-tuning stage, each training update contains four steps: input, augmentation, selection, and optimization, as illustrated in Figure 3. We utilize POBT and ROBT to generate synthetic augmented sentence pairs at both fine-tuning stages while only using the CLOS method at the substitution fine-tuning stage based on a better model initialization. The synthetic candidates are then selected with the batch-level selection criterion and successively sampled with the global-level selection criterion. Finally, the model M will be optimized on the merged datasets of both real and synthetic sentence pairs. The and are auto-regressively translated while and originate from them with substitution operations. Although the cost of our training schedule is more computationally expensive than vanilla MNMT training with two additional fine-tuning stages, it is comparable to MNMT systems with augmentation methods, such as ROBT, because we implement data augmentation in parallel and the fine-tuning stages cost much lower than the pre-training stage.
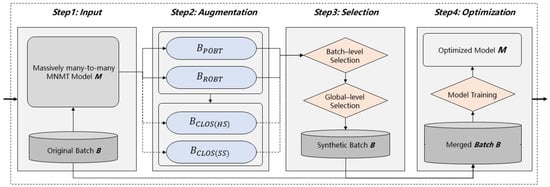
Figure 3.
One update in the augmentation and substitution fine-tuning stages. The dash arrows in the augmentation step mean that CLOS(HS) and CLOS(SS) are only optional in the substitution fine-tuning stage.
4. Experiments
We choose an English-centric experimental setup, where multilingual translation models are trained on X ↔ English parallel data. This scenario has the potential to handle translation directions with training only on directions. Translation directions between all non-English languages are regarded as zero-shot translations, and English-centric directions are regarded as supervised translations.
4.1. Datasets and Evaluation
We conduct our experiments against two benchmarks: IWSLT-8 and OPUS-100. For IWSLT-8, we collect eight English-centric language pairs (including English to/from Farsi, Arabic, Hebrew, Dutch, German, Italian, Spanish and Polish) from the IWSLT2014 (https://wit3.fbk.eu/2014-01 (accessed on 1 March 2023)) following Lin et al. [42], resulting in a total of 2.7 M sentence pairs, as illustrated in Table 2. For the OPUS-100, the dataset, created by Zhang et al. [21], consists of 110 M sentence pairs and covers 100 languages (198 language pairs, either into or from English), whose size ranges from 0.6 k to 1 M.
Table 2.
Statistics of the IWSLT-8 dataset collected from IWSLT2014.
At the pre-processing stage, we employ the langdetect library (https://github.com/Mimino666/langdetect (accessed on 1 March 2023)) to retain sentences predicted as the desired language, remove sentences longer than 250 tokens and with a source/target length ratio exceeding three. Then subwords are generated via byte pair encoding (BPE) [43] with 30 k merged operations for IWSLT-8 and 64 k merged operations for OPUS-100. We train many-to-many MNMT systems throughout our experiments, by adding corresponding language tokens at the beginning of the source and target sentences.
We adopt case-sensitive BLEU [44] for the translation evaluation with the toolkit SacreBLEU (Signature: BLEU+case.mixed+numrefs.1+smooth.exp+tok.13a+version.1.4.1) [45] for its ease of use and is independent of language. We also use METEOR [46] and TER [47] to test the translation performance, as METEOR correlates well with human evaluation compared to BLEU, and TER is very intuitive. All statistical results were computed via paired bootstrap resampling [48]. In the IWSLT-8 experiments, we use tst2013 and tst2014 as the development and test sets for eight English-centric language pairs, respectively. For non-English directions, we extract the test set from the FLORES-101 benchmark [49], which is widely used in multilingual translation evaluation. In the OPUS-100 experiments, all the development and test sets are public and available (https://opus.nlpl.eu/opus-100.php (accessed on 1 March 2023)), including all English-centric supervised language pairs and 15 non-English zero-shot language pairs of Arabic, Chinese, Dutch, French, German, and Russian. Rather than providing results for each language pair, we report the supervised and zero-shot average results, respectively, due to the large number of translation directions.
4.2. Training Details
Following the settings in Vaswani et al. [4], we conducted our experiments with transformer architecture using the fairseq toolkit [50], while our methods are model-agnostic and can be applied to other machine translation frameworks. Considering the diversity of the dataset volume, we used the transformer-small settings (512/1024, 4 heads, 6 layers) for IWSLT-8 experiments and the transformer-base settings (512/2048, 8 heads, 6 layers) for OPUS-100 experiments by default. To verify the effectiveness of our approaches with stronger modelling capacity, we further validated with the transformer-big (1024/4096, 16 heads, 6 layers) and some other hyperparameters. In the training process, we used the Adam optimizer with , , learning rate = and warm-up steps = 4000. Dropout was 0.1 in the transformer-small/base settings, and 0.3 in the transformer-big settings. Experiments were conducted using eight NVIDIA A100 GPUs for the OPUS-100 dataset and one GPU for the IWSLT-8 dataset, where the batch size of each GPU was set to 4096 tokens. We accumulate the gradient of parameters and update every two steps, with half-precision floating point (FP16) training.
4.3. Comparison of Methods
We compare our results with those of the following methods:
- MNMT baseline. Previous research shows that a well-trained multilingual model can directly perform zero-shot translation [8,10].
- ROBT. Zhang et al. [21] first demonstrated the feasibility of back-translation in massively multilingual settings and greatly increased zero-shot translation performance.
- mRASP2. Pan et al. [27] proposed a multilingual contrastive learning framework for translation, generating synthetic aligned sentence pairs to improve multilingual translation quality in a unified training framework.
- Pivot translation. This method first translates one source sentence into English (X → English), and then into the target language (English → Y). The pivoting can be performed by the baseline multilingual model or separately trained bilingual models, both of which are compared in this work.
4.4. Main Results
This section shows that our algorithms provide substantial and consistent performance gains for massively MNMT translation in both the IWSLT-8 and OPUS-100 experiments.
4.4.1. Results on the IWSLT-8
Table 3 presents the experimental results on the IWSLT-8 dataset, proving that our methods clearly improve massively many-to-many translation compared with previous state-of-the-art methods. We first build a strong baseline MNMT model with robust hyperparameters, surpassing the previous MNMT baseline [42] (1.33 BLEU, (1) → (3)) in supervised directions. Unsurprisingly, the baseline MNMT model severely lags behind both the bilingual pivot (6.62 BLEU, (3) → (2)) and MNMT pivot (6.47 BLEU, (3) → (4)) systems in zero-shot directions due to the off-target problem. mRASP2 and ROBT both outperform the baseline MNMT model in zero-shot directions at the sacrifice of 0.43–1.01 BLEU score losses in supervised directions, as shown in line (5) and (6). However, due to the poor zero-shot initialization of the pre-trained MNMT model, ROBT can be outperformed easily by the simple but effective POBT (0.72 BLEU, (6) → (7)). With our methods, we can substantially improve zero-shot translation, outperforming mRASP2 with 4.45 BLEU((9) → (5)) and ROBT with 5.06 BLEU((9) → (6)), respectively. Except for the BLEU metric, we also observes consistent performance improvements with the METOER and TER metrics in Table 3. It is worth noting that our methods also surpass the bilingual pivot and MNMT pivot systems in both zero-shot and supervised directions, achieving state-of-the-art performance. We attribute this to a better cross-lingual knowledge transfer from suitable training samples and aligned augmentations.
Table 3.
Performance on the IWSLT-8 dataset. “Supervised” means English-centric language directions seen during training. “Zero-shot” means all other 56 non-English directions unseen during training. “Bilingual and Pivot” means separately trained bilingual models for supervised directions and pivot translation based on bilingual models for zero-shot directions. The best results, indicated in bold, are statistically significant against all other results, for p < 0.05.
4.4.2. Results on OPUS-100
We summarize the experimental results of the OPUS-100 dataset in Table 4 and observe consistent performance gains with the IWSLT-8 experiments. Our strong MNMT model and bilingual pivot translation surpass previous baselines [21] in zero-shot translations (0.84 BLEU, (1) → (4)). We also present pivot translation based on the multilingual model, which is slightly worse than the bilingual pivot system (0.37 BLEU, (6) → (4)). For zero-shot translation, mRASP2 and ROBT provide substantial performance gains (9.35 BLEU, (5) → (7) and 7.51 BLEU, (5) → (8)), but still lag behind POBT (0.30 BLEU, (7) → (9) and 2.14 BLEU, (8) → (9)). For zero-shot directions, our data augmentation algorithm significantly outperforms mRASP2 and ROBT (3.36 BLEU, (7) → (11) and 5.20 BLEU, (8) → (11)), even surpassing strong pivot translation (1.98 BLEU, (4) → (11)). For supervised directions, our algorithm also achieves the best performance surpassing bilingual NMT systems on average, while mRASP2 and ROBT achieve BLEU score improvements on zero-shot translations at the sacrifice of BLEU score loss on supervised directions. We also observe consistent performance improvements with the METOER and TER metrics in Table 4.
Table 4.
Performance on the OPUS-100 dataset. The dataset only present 15 zero-shot directions for Arabic, Chinese, Dutch, French, German, and Russian, as applying bilingual NMT to each language pair is resource-consuming. The best results, indicated in bold, are statistically significant against all other results, for p < 0.05.
4.5. Analysis and Discussion
4.5.1. Ablation Study
To better understanding the effectiveness of our methods, we conducted an ablation study with our proposed methods on the OPUS-100 dataset, as shown in Table 5. In the first three rows, we analysed the impact of SOBT with different selection criteria. The first row shows zero-shot translation results based on ROBT. From (1) to (3), SOBT with both the batch-level selection criterion (BLS) and the global-level selection criterion (GLS) brings a significant improvement of 3.28 BLEU. We attribute this improvement to SOBT generating more suitable training examples for zero-shot translation than ROBT. From (2) to (3), GLS can deliver a decent performance gain of 1.36 BLEU with proper data sampling strategies. In the last three rows, we study the advantages of CLOS with hard substitution (HS) and soft substitution (SS), respectively. As detailed in Section 3.5, we only use CLOS methods in the substitution fine-tuning stage based on a better initialization obtained with SOBT. We observed that CLOS can provide improvements up to 1.92 BLEU with soft substitution from (3) to (5). Hard substitution performs worse compared to soft substitution due to its discrete nature. The result of (6) confirms our claim before: without ROBT, the BLEU score of CLOS severely degrades from 15.80 to 3.38 with a poor initialization for zero-shot directions.
Table 5.
Ablation study based on the OPUS-100 dataset. Evaluations are performed with BLEU metric. We compare the transformer-base model performances with different combinations of SOBT(BLS), SOBT(GLS), CLOS(HS), and CLOS(SS). BLS denotes batch-level selection criterion, GLS denotes global-level selection criterion, HS denotes hard substitution, SS denotes soft substitution.
4.5.2. Convergence of SOBT
ROBT only takes a few thousand steps to converge, empirically proven to be sub-optimal. The curve in Figure 4 shows that our method can deliver greater and continued benefits with more steps and high-quality training samples. To achieve the optimal performance, we break down the whole training schedule into three stage. We utilize SOBT to generate back-translated sentence pairs at both fine-tuning stages while only using CLOS methods at the substitution fine-tuning stage based on a better initialization to achieve the optimal performance.
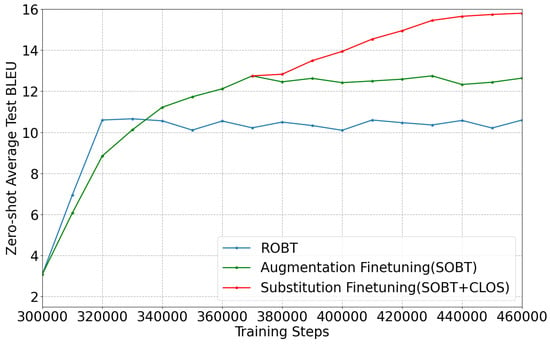
Figure 4.
Zero-shot average test BLEU for multilingual NMT models fine-tuned within different methods.
4.5.3. Effect of Model Capacity
MNMT models always suffer from insufficient modelling capacity and result in a reduction in translation quality when including more languages. We verify the generalization and effectiveness of our approaches with different capacities by increasing model depth and hidden size. As shown in Table 6, we observe consistent improvements with our methods in various experiment settings.
Table 6.
Performance (BLEU) on the OPUS-100 dataset. We thoroughly evaluate our methods with different model capacities.
4.5.4. Case Study
As shown in Table 7, we observe that the baseline MNMT model has severe off-target issues, while our method significantly alleviates the problem and translates it into the correct target language, especially in non-English directions. We attribute the success of “on-target” in zero-shot translation to the suitable augmented training samples and transfer learning with better aligned representations.
Table 7.
Case Study.
4.5.5. Practical Applications
In addition, to evaluate the practicability of our many-to-many NMT system, we translate the OPUS-100 test sets using commercial translation systems, such as Google Translate and DeepL. The BLEU/METEOR/TER scores of these translations were calculated and compared, as illustrated in Table 8. While commercial machine translation systems are always optimized with more supervised training data and larger model capacities, our models achieve comparable performances to Google Translate and DeepL in zero-shot directions. Hence, we think our models are usable in business applications, especially in non-English directions.
Table 8.
The BLEU, METEOR and TER scores of different systems in the OPUS-100 test sets. The best results, indicated in bold, are statistically significant against all other results, for p < 0.05, except where indicated as *; differences between top-performing systems in bold were not statistically significant.
5. Conclusions and Future Work
In this paper, we proposed a selective and aligned online data augmentation algorithm to improve massively many-to-many machine translation, especially in non-English directions. The algorithm introduces a selective online back-translation method to pick suitable and high-quality training samples with appropriate selection criteria based on the combination of CE loss and QE scores. During training, we fine-tune the baseline MNMT model with contrastive learning to represent similar sentences across languages in a shared space and minimize the representation distance of similar sentences. In addition, we further boost the SOBT algorithm with cross-lingual online substitution, generating code-switched source sentences on-the-fly to strengthen transfer learning between zero-shot language pairs. Based on a better MNMT initialization fine-tuned with the SOBT algorithm, CLOS can further bring continued and significant improvements without any explicit external training resources. We thoroughly evaluated our experiments on two widely used multilingual translation benchmarks: IWSLT2014 and OPUS-100. Experimental results show that our approach substantially improves translation performance of both English-centric and non-English directions, outperforming previous state-of-the-art methods, such as mRASP2 and ROBT.
In the future, we will extend our methods by leveraging both source- and target-side monolingual data since monolingual data is abundant and easy-to-access. We also intend to investigate the benefits of pre-trained models in massively many-to-many translations. In addition, we will also work on how to reduce the computational costs of multi-step fine-tuning.
Author Contributions
Conceptualization, W.Z. and L.D.; data curation, S.W.; formal analysis, W.Z. and L.D.; funding acquisition; investigation, W.Z. and S.W.; methodology, W.Z., L.D. and J.L.; project administration; resources, W.Z. and J.L.; software, W.Z.; supervision, L.D.; validation, W.Z.; visualization, W.Z.; writing—original draft, W.Z.; writing—review and editing, L.D. and J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Key R&D Program of China (2020AAA0107905).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this paper can be accessed by https://wit3.fbk.eu/2014-01 and https://opus.nlpl.eu/opus-100.php (accessed on 1 March 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7 May 2015. [Google Scholar]
- Barrault, L.; Bojar, O.; Costa-Jussà, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; et al. Findings of the 2019 Conference on Machine Translation (WMT19). In Proceedings of the Association for Computational Linguistics, Florence, Italy, 1 August 2019. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dabre, R.; Chu, C.; Kunchukuttan, A. A survey of multilingual neural machine translation. ACM Comput. Surv. (CSUR) 2020, 53, 1–38. [Google Scholar] [CrossRef]
- Wang, R.; Tan, X.; Luo, R.; Qin, T.; Liu, T.Y. A Survey on Low-Resource Neural Machine Translation. arXiv 2021, arXiv:2107.04239. [Google Scholar]
- Aharoni, R.; Johnson, M.; Firat, O. Massively Multilingual Neural Machine Translation. arXiv 2019, arXiv:1903.00089. [Google Scholar]
- Firat, O.; Cho, K.; Bengio, Y. Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism. arXiv 2016, arXiv:1601.01073. [Google Scholar]
- Firat, O.; Sankaran, B.; Al-onaizan, Y.; Yarman Vural, F.T.; Cho, K. Zero-Resource Translation with Multi-Lingual Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1 November 2016; pp. 268–277. [Google Scholar] [CrossRef]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef]
- Lakew, S.M.; Cettolo, M.; Federico, M. A Comparison of Transformer and Recurrent Neural Networks on Multilingual Neural Machine Translation. In Proceedings of the International Conference on Computational Linguistics, Santa Fe, NM, USA, 20 August 2018. [Google Scholar]
- Tan, X.; Chen, J.; He, D.; Xia, Y.; Qin, T.; Liu, T.Y. Multilingual Neural Machine Translation with Language Clustering. arXiv 2019, arXiv:1908.09324. [Google Scholar]
- Ji, B.; Zhang, Z.; Duan, X.; Zhang, M.; Chen, B.; Luo, W. Cross-lingual pre-training based transfer for zero-shot neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; pp. 115–122. [Google Scholar]
- Sen, S.; Gupta, K.K.; Ekbal, A.; Bhattacharyya, P. Multilingual unsupervised NMT using shared encoder and language-specific decoders. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 3083–3089. [Google Scholar]
- Al-Shedivat, M.; Parikh, A. Consistency by Agreement in Zero-Shot Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2 June 2019; Volume 1, pp. 1184–1197. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Y.; Cho, K.; Li, V.O. Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 1258–1268. [Google Scholar] [CrossRef]
- Arivazhagan, N.; Bapna, A.; Firat, O.; Aharoni, R.; Johnson, M.; Macherey, W. The missing ingredient in zero-shot neural machine translation. arXiv 2019, arXiv:1903.07091. [Google Scholar]
- Pham, N.Q.; Niehues, J.; Ha, T.L.; Waibel, A. Improving Zero-shot Translation with Language-Independent Constraints. In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 1 August 2019; Volume 1, pp. 13–23. [Google Scholar] [CrossRef]
- Lakew, S.M.; Lotito, Q.F.; Negri, M.; Turchi, M.; Federico, M. Improving Zero-Shot Translation of Low-Resource Languages. In Proceedings of the 14th International Conference on Spoken Language Translation, Tokyo, Japan, 26 May 2017; pp. 113–119. [Google Scholar]
- Aharoni, R.; Johnson, M.; Firat, O. Massively Multilingual Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2 June 2019; Volume 1, pp. 3874–3884. [Google Scholar] [CrossRef]
- Zhang, B.; Williams, P.; Titov, I.; Sennrich, R. Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 1628–1639. [Google Scholar] [CrossRef]
- Kudugunta, S.; Bapna, A.; Caswell, I.; Firat, O. Investigating Multilingual NMT Representations at Scale. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3 November 2019; pp. 1565–1575. [Google Scholar] [CrossRef]
- Sánchez-Cartagena, V.M.; Esplà-Gomis, M.; Pérez-Ortiz, J.A.; Sánchez-Martínez, F. Rethinking Data Augmentation for Low-Resource Neural Machine Translation: A Multi-Task Learning Approach. arXiv 2021, arXiv:2109.03645. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7 August 2016; Volume 1, pp. 86–96. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, W.; Wang, F.; Xu, B. Effectively training neural machine translation models with monolingual data. Neurocomputing 2019, 333, 240–247. [Google Scholar] [CrossRef]
- Lin, Z.; Pan, X.; Wang, M.; Qiu, X.; Feng, J.; Zhou, H.; Li, L. Pre-training Multilingual Neural Machine Translation by Leveraging Alignment Information. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16 November 2020; pp. 2649–2663. [Google Scholar] [CrossRef]
- Pan, X.; Wang, M.; Wu, L.; Li, L. Contrastive Learning for Many-to-many Multilingual Neural Machine Translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1 August 2021; Volume 1, pp. 244–258. [Google Scholar] [CrossRef]
- Utiyama, M.; Isahara, H. A comparison of pivot methods for phrase-based statistical machine translation. In Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics, Rochester, NY, USA, 22 July 2007; pp. 484–491. [Google Scholar]
- Wu, H.; Wang, H. Revisiting pivot language approach for machine translation. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2 August 2009; pp. 154–162. [Google Scholar]
- Chen, Y.; Liu, Y.; Cheng, Y.; Li, V.O. A Teacher-Student Framework for Zero-Resource Neural Machine Translation. In Proceedings of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July 2017. [Google Scholar]
- Cheng, Y.; Yang, Q.; Liu, Y.; Sun, M.; Xu, W. Joint training for pivot-based neural machine translation. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19 August 2017. [Google Scholar]
- Ha, T.L.; Niehues, J.; Waibel, A. Effective Strategies in Zero-Shot Neural Machine Translation. In Proceedings of the 14th International Conference on Spoken Language Translation, Tokyo, Japan, 14 December 2017; pp. 105–112. [Google Scholar]
- Lakew, S.M.; Federico, M.; Negri, M.; Turchi, M. Multilingual neural machine translation for zero-resource languages. arXiv 2019, arXiv:1909.07342. [Google Scholar]
- Edman, L.; Üstün, A.; Toral, A.; van Noord, G. Unsupervised Translation of German–Lower Sorbian: Exploring Training and Novel Transfer Methods on a Low-Resource Language. In Proceedings of the Sixth Conference on Machine Translation, Online, 10 November 2021; pp. 982–988. [Google Scholar]
- Garcia, X.; Siddhant, A.; Firat, O.; Parikh, A. Harnessing Multilinguality in Unsupervised Machine Translation for Rare Languages. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6 June 2021; pp. 1126–1137. [Google Scholar] [CrossRef]
- Huang, H.; Liang, Y.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Zhou, M. Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks. arXiv 2019, arXiv:1909.00964. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Le, Q.V. Exploiting Similarities among Languages for Machine Translation. arXiv 2013, arXiv:1309.4168. [Google Scholar]
- Kepler, F.; Trénous, J.; Treviso, M.; Vera, M.; Góis, A.; Farajian, M.A.; Lopes, A.V.; Martins, A.F.T. Unbabel’s Participation in the WMT19 Translation Quality Estimation Shared Task. In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 1 August 2019; Volume 3, pp. 78–84. [Google Scholar] [CrossRef]
- Rei, R.; Stewart, C.; Farinha, A.C.; Lavie, A. COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16 November 2020; pp. 2685–2702. [Google Scholar] [CrossRef]
- Conneau, A.; Lample, G.; Ranzato, M.; Denoyer, L.; Jégou, H. Word Translation without Parallel Data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Lin, Z.; Wu, L.; Wang, M.; Li, L. Learning Language Specific Sub-network for Multilingual Machine Translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1 August 2021; pp. 293–305. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7 August 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6 July 2002; pp. 311–318. [Google Scholar]
- Post, M. A call for clarity in reporting BLEU Scores. In Proceedings of the WMT 2018, Brussels, Belgium, 31 October 2018. [Google Scholar]
- Lavie, A.; Agarwal, A. METEOR: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; pp. 228–231. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A Study of Translation Edit Rate with Targeted Human Annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, Cambridge, MA, USA, 8 August 2006; pp. 223–231. [Google Scholar]
- Koehn, P. Statistical Significance Tests for Machine Translation Evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25 July 2004; pp. 388–395. [Google Scholar]
- Goyal, N.; Gao, C.; Chaudhary, V.; Chen, P.J.; Wenzek, G.; Ju, D.; Krishnan, S.; Ranzato, M.; Guzmán, F.; Fan, A. The Flores-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation. Trans. Assoc. Comput. Linguist. 2022, 10, 522–538. [Google Scholar] [CrossRef]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2 June 2019; pp. 48–53. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).