
Event Detection Using a Self-Constructed Dependency and Graph Convolution Network

Abstract
:1. Introduction
- We designed a novel graph construction method by pruning the dependency parsing tree and combining the named entity features.
- We used the multi-head attention mechanism to improve the GCN model, and we dynamically fused the semantic representation of the sentence and structural dependency information through a gating mechanism.
- The experiments conducted on the ACE2005 benchmark verified that our proposed method can improve the event detection effect of the model and has certain rationality.
2. Related Work
3. Methods
3.1. Embedding Layer
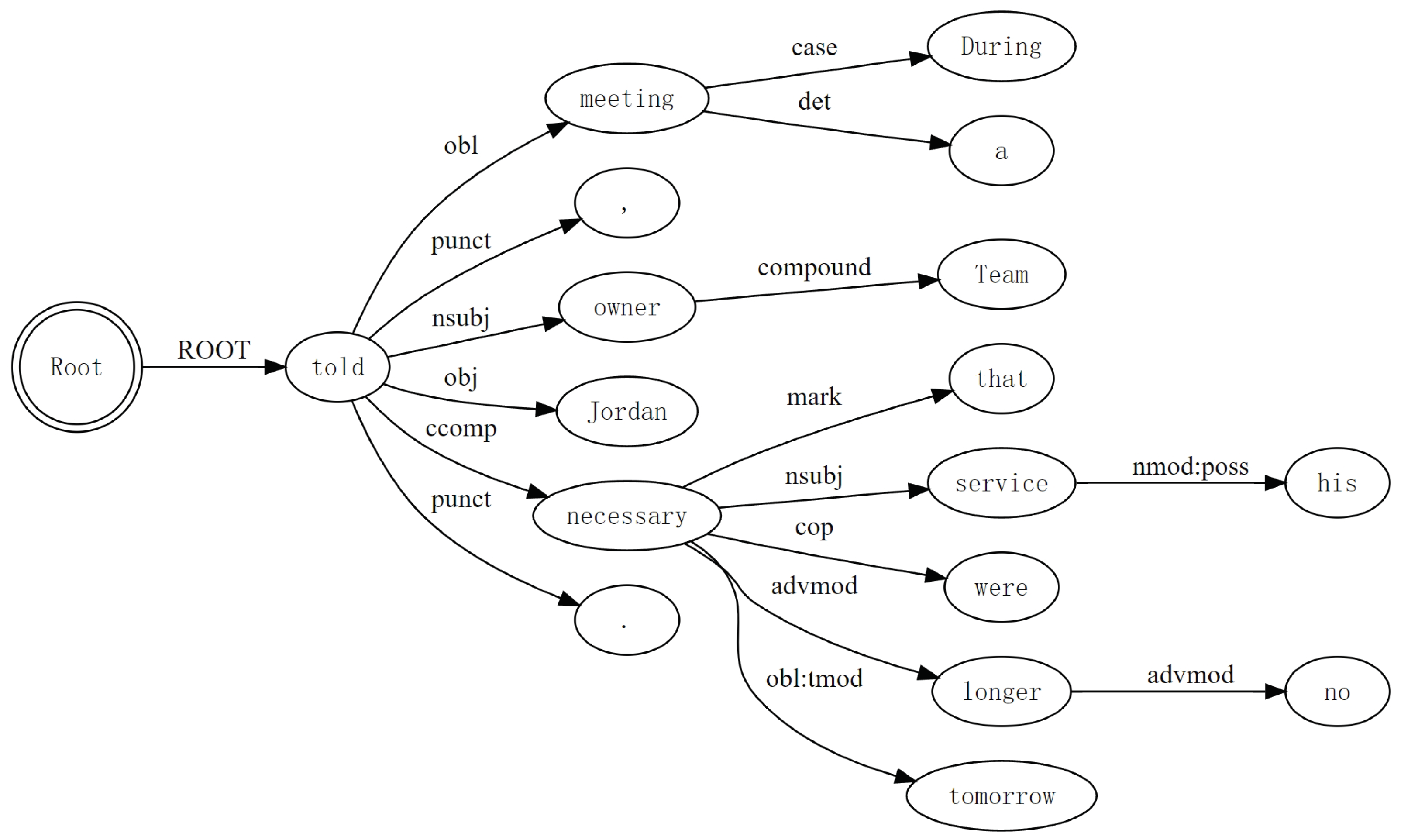
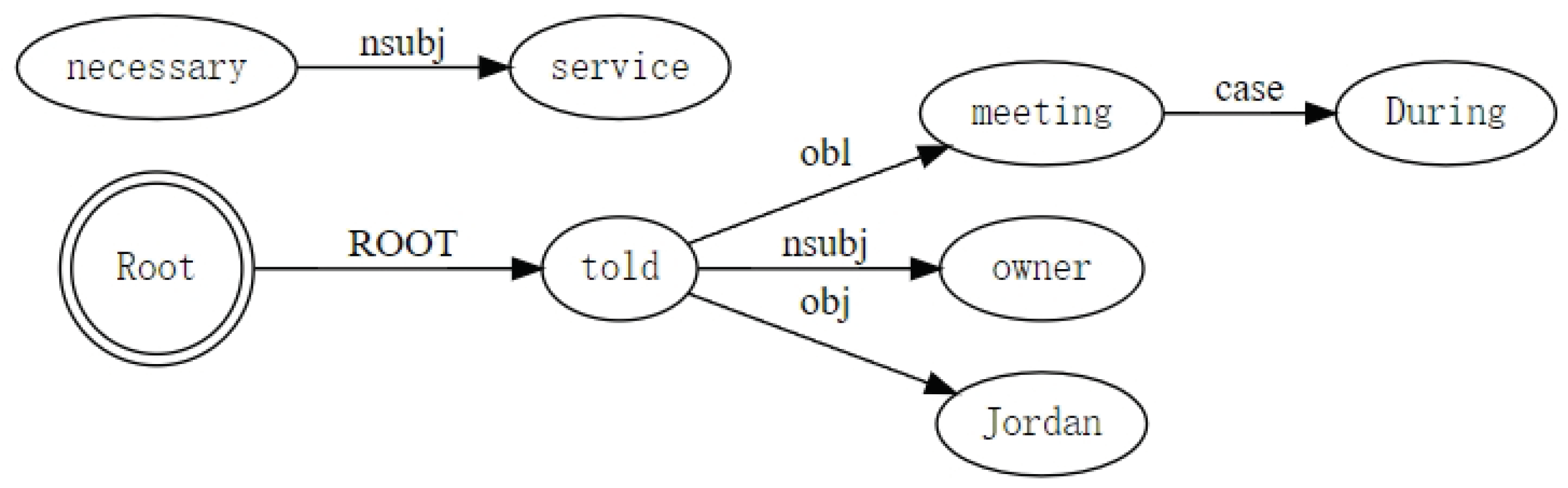
3.2. Dependency Graph Construction Method
- (1)
- Reverse edges (): To strengthen the flow of dependency information in the opposite direction on the edge of the graph, and better capture the relationship between entities, we add the corresponding reverse edge for each edge generated by dependency parsing.
- (2)
- Sequence edges (): To restore the integrity of the sentence and capture the adjacency relationship in time sequence, we add an adjacency edge to each adjacency word.
- (3)
- Entity edges (): To enhance the model’s understanding of the entity features in the sentence, the named entity recognition method is used to extract the entities in the sentence and connect them with each other.
- (4)
- Self-connected edges (): We add self-connected edges to each character to prevent nodes from ignoring their own characteristics.
3.3. Multi-GCN
3.4. Gating Mechanism Fusion
3.5. Event Detection
4. Experiments
4.1. Datasets
4.2. Experiment Setting
4.3. Comparison Experiment
- (1)
- (2)
- Sequence-based model: Event detection is performed by processing and analyzing word sequences in sentences. DMCNN [8] builds a dynamic multi-pool CNN to learn sentence features, JRNN [9] uses bidirectional RNN to learn dependencies in sequences, and DBRNN [13] uses bidirectional RNN based on a syntax dependency tree to capture the dependencies between words.
- (3)
- GCN-based model: A graph is built according to the dependency of sentences, syntactic information is extracted through GCN, and events are detected. JMEE [5] combines an attention mechanism with GCN to improve the performance. RGCN [25] uses an adjacency matrix and a convolution filter of a specific relationship to model data to perform tasks. MOGANED [20] updates the node representation by aggregating the attention of each layer on GCN with an attention mechanism; EE-GCN [7] uses GCN to learn semantic information and add dependency information to dynamically update the representation of nodes and edges.
4.4. Ablation Experiments
4.4.1. Analysis of Impact of Different Graph Structures on the Model
4.4.2. Analysis of Influence of GCN Layers L and Attention Heads K on Model Effect
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiang, W.; Wang, B. A Survey of Event Extraction From Text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Nguyen, T.; Grishman, R. Graph convolutional networks with argument-aware pooling for event detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Liu, X.; Luo, Z.; Huang, H. Jointly multiple events extraction via attention-based graph information aggregation. arXiv 2018, arXiv:1809.09078. [Google Scholar]
- Song, L.; Zhang, Y.; Wang, Z.; Gildea, D. N-ary relation extraction using graph state lstm. arXiv 2018, arXiv:1808.09101. [Google Scholar]
- Cui, S.; Yu, B.; Liu, T.; Zhang, Z.; Wang, X.; Shi, J. Edge-enhanced graph convolution networks for event detection with syntactic relation. arXiv 2020, arXiv:2002.10757. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Liu, K.; He, S.; Zhao, J. A probabilistic soft logic based approach to exploiting latent and global information in event classification. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Yang, B.; Mitchell, T. Joint extraction of events and entities within a document context. arXiv 2016, arXiv:1609.03632. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring pre-trained language models for event extraction and generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5284–5294. [Google Scholar]
- Ramponi, A.; van der Goot, R.; Lombardo, R.; Plank, B. Biomedical event extraction as sequence labeling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 19–20 November 2020; pp. 5357–5367. [Google Scholar]
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Doc2EDAG: An end-to-end document-level framework for Chinese financial event extraction. arXiv 2019, arXiv:1904.07535. [Google Scholar]
- Yang, H.; Chen, Y.; Liu, K.; Xiao, Y.; Zhao, J. Dcfee: A document-level chinese financial event extraction system based on automatically labeled training data. In Proceedings of the ACL 2018, System Demonstrations, Melbourne, Australia, 15–20 July 2018; pp. 50–55. [Google Scholar]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event detection with multi-order graph convolution and aggregated attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5766–5770. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10–48550. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hong, Y.; Zhang, J.; Ma, B.; Yao, J.; Zhou, G.; Zhu, Q. Using cross-entity inference to improve event extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1127–1136. [Google Scholar]
- Li, Q.; Ji, H.; Huang, L. Joint event extraction via structured prediction with global features. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 73–82. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dependency Parsing Labels | Percentage of Labels in the Corpus (%) | Probability of Label Associated with Trigger Words (%) | Ranking |
|---|---|---|---|
| nsubj:pass (nominal subject) | 1.01 | 31.66 | 1 |
| aux:pass (auxiliary) | 1.18 | 27.96 | 2 |
| obl (oblique nominal) | 5.38 | 27.78 | 3 |
| advcl (adverbial clause modifier) | 1.34 | 27.76 | 4 |
| det (determiner) | 8.81 | 8.98 | 26 |
| case (case marking) | 11.11 | 7.82 | 31 |
| Methods | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| MaxEnt | 74.5 | 59.1 | 65.9 |
| CrossEntity | 68.7 | 68.9 | 68.8 |
| DMCNN | 75.6 | 63.6 | 69.1 |
| JRNN | 66.0 | 73.0 | 69.3 |
| DBRNN | 74.1 | 69.8 | 71.9 |
| RGCN | 68.4 | 79.3 | 73.4 |
| JMEE | 76.3 | 71.3 | 73.7 |
| MOGANED | 79.5 | 72.3 | 75.7 |
| EEGCN | 76.7 | 78.6 | 77.6 |
| Ours | 79.7 | 77.2 | 78.4 |
| Methods | Precision (%) | Pecall (%) | F1 (%) |
|---|---|---|---|
| - | 78.3 | 76.8 | 77.5 |
| Pruning | 78.9 | 76.5 | 77.7 |
| Entity Edges | 78.1 | 76.2 | 77.1 |
| Pruning + Entity Edges | 79.7 | 77.2 | 78.4 |
| GCN Layers | F1-Score (%) | Attention Heads | F1-Score (%) |
|---|---|---|---|
| 1 | 75.8 | 1 | 76.1 |
| 2 | 77.4 | 2 | 77.6 |
| 3 | 78.4 | 3 | 78.4 |
| 4 | 77.8 | 4 | 78.0 |
| 5 | 76.7 | 5 | 76.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Meng, Q.; Zhang, Q.; Duan, J.; Wang, H. Event Detection Using a Self-Constructed Dependency and Graph Convolution Network. Appl. Sci. 2023, 13, 3919. https://doi.org/10.3390/app13063919
He L, Meng Q, Zhang Q, Duan J, Wang H. Event Detection Using a Self-Constructed Dependency and Graph Convolution Network. Applied Sciences. 2023; 13(6):3919. https://doi.org/10.3390/app13063919
Chicago/Turabian StyleHe, Li, Qingxin Meng, Qing Zhang, Jianyong Duan, and Hao Wang. 2023. "Event Detection Using a Self-Constructed Dependency and Graph Convolution Network" Applied Sciences 13, no. 6: 3919. https://doi.org/10.3390/app13063919
APA StyleHe, L., Meng, Q., Zhang, Q., Duan, J., & Wang, H. (2023). Event Detection Using a Self-Constructed Dependency and Graph Convolution Network. Applied Sciences, 13(6), 3919. https://doi.org/10.3390/app13063919