

A Domain-Driven Framework to Analyze Learning Dynamics in MOOCs through Event Abstraction


Abstract
1. Introduction
- RQ1: What are the characteristics of the sessions that involve learning dynamics in which a resource is revisited?
- RQ2: Are there differences in terms of learning dynamics between the first and final sessions carried out by students?
- RQ3: What types of MOOC sessions do successful students go through and how do they differ from each other?
2. Related Work
2.1. Process Mining and MOOCs
2.2. Process Mining and Event Abstraction
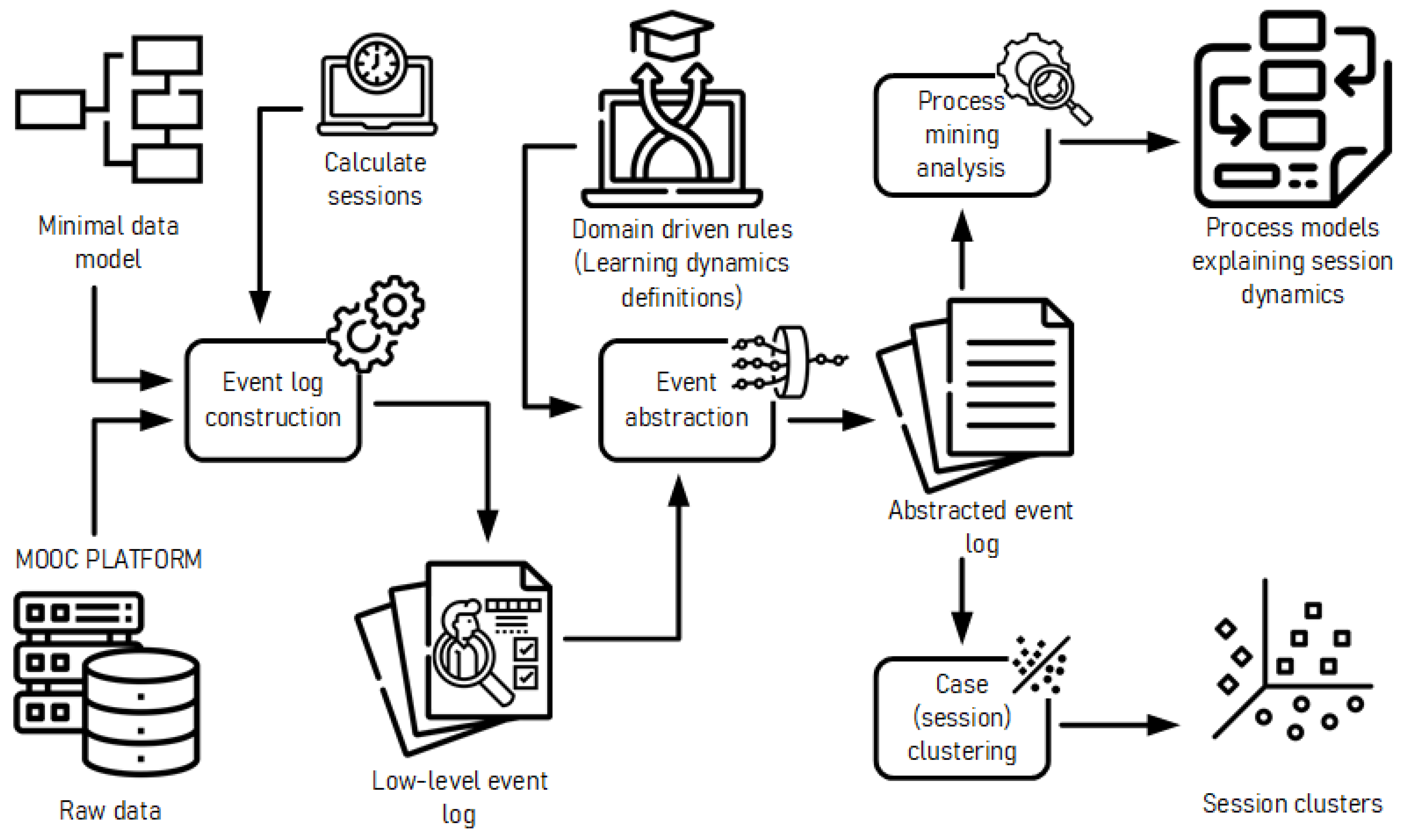
3. Domain-Driven Event Abstraction Framework
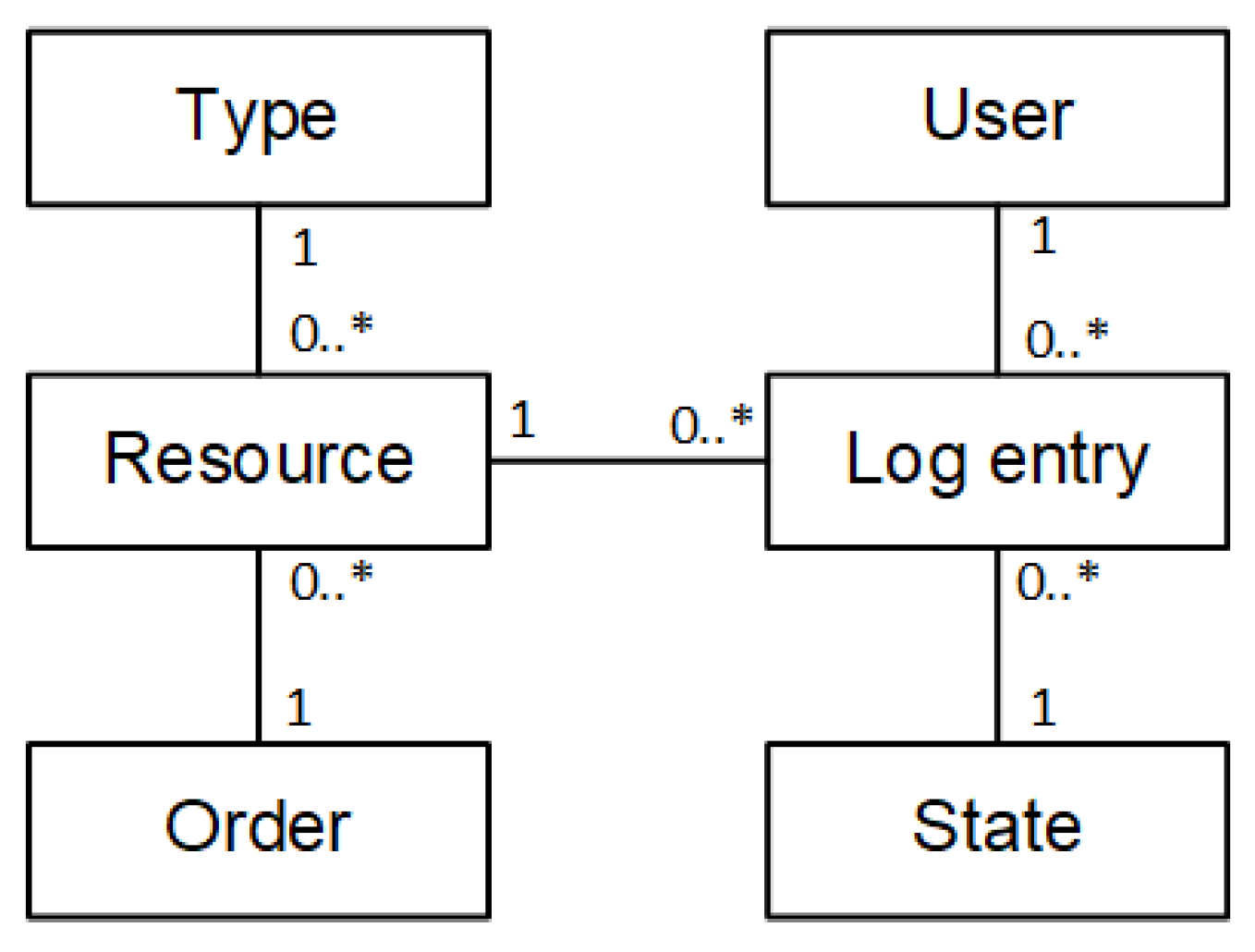
3.1. Stage 1: Minimal Data Model
3.2. Stage 2: Low-Level Log
3.3. Stage 3: High-Level Log
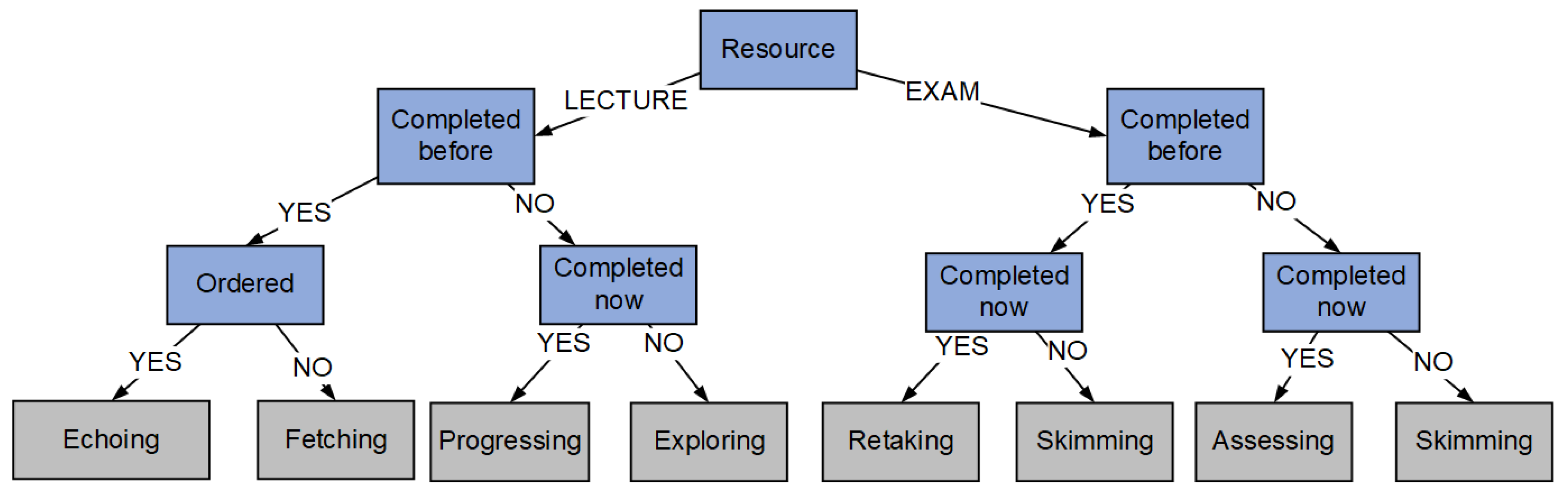
- Progressing: This shows the learning dynamic of a student who consumes a resource and then moves on to the next resource in the course in the right order. In other words, there is an interaction with a content-type resource that has either not been interacted with or in which the interaction was not previously completed; this interaction is then completed, and the student subsequently moves on to interact with the next resource, in the correct order. This dynamic recognizes a succession of behaviors similar to those described in [4,6] as “Content Access”, in [32] as “V-V sequences”, and “Study” in [33], but only on content that has begun and concluded in the same session and for the first time in the course.
- Exploring: This illustrates the learning dynamic of a student who engages with new content in a shallow fashion just to know what to expect, for example, to calculate the time required to study that content. In other words, an interaction is initiated but not completed with a content-type resource that has not previously been interacted with or with which the engagement has not previously been completed. This dynamic detects actions similar to those defined in [4,6] as “Search”, “Content Access”, or “Overview”; or “Skipping” in [33], but only on content that has not been completed previously and has not been completed this time.
- Echoing: This portrays the learning dynamic of a student who consumes a resource and then moves on to the next resource in the correct order. However, this is for resources that have already been completed. A relevant example is a learner who decides to review content before taking an exam. In other words, there is an interaction with a content-type resource that has already been accessed; this new interaction is then done again, and the learner moves on to the next resource in the correct order. This dynamic recognizes activities similar to those specified as “Content Revision” in [4,6], “V-V sequences” in [32], or “Rewatch” in [33], but it considers an organized sequence of this sort of activity, where the contents begin and conclude in an orderly manner.
- Fetching: This depicts the learning dynamics of a learner interacting with a previously completed material, with or without completion, in any order. An excellent example would be a student who, after failing an assessment question, rewatches (parts of or all of) a certain video to get the correct answer. In other words, there is an encounter with a previously finished content-type resource that does not follow the designated course sequence. This dynamic takes into account behaviors that are comparable to “Content revision” and “Search” actions described in [4,6] or “Rewatch” in [33].
- Assessing: This shows the learning dynamic of a student who interacts with and completes a previously uncompleted assessment-type resource. A block of many assessment activities in a row are crushed into a single dynamic, regardless of their sequence. In other words, an interaction occurs with an assessment-type resource that has not previously been engaged with or whose previous engagement was not finished, and this interaction is then completed. This dynamic recognizes activities similar to those specified as “Assessment” in [4,6],“Q-Q sequences” in [32], and “Taking quizzes” in [31], but only for evaluations that had not previously been completed.
- Retaking: This shows the learning dynamic of a student who initiates and completes previously completed assessments. For example, consider a user who did not receive a sufficient score and decides to retry in order to improve on their earlier performance. In other words, there is an interaction with an assessment-type resource that has already been finished, and this new interaction is then completed again. This dynamic considers groups of the same actions as the previous dynamic but distinguishes whether the evaluation was previously carried out by the student.
- Skimming: This reflects a student’s learning dynamic in which he or she initiates but does not complete interactions with evaluations. For example, the student might be reading the questions before taking an examination seriously, or he or she might be examining an assessment to figure out where he or she went wrong. In other words, there is contact with an assessment-type resource that has been started but not finished. This dynamic takes into account behaviors that are comparable to “View the quiz” and “Refer to quiz answers” described in [34] and “Viewing quiz results” described by [31].
4. Learning Session Classification
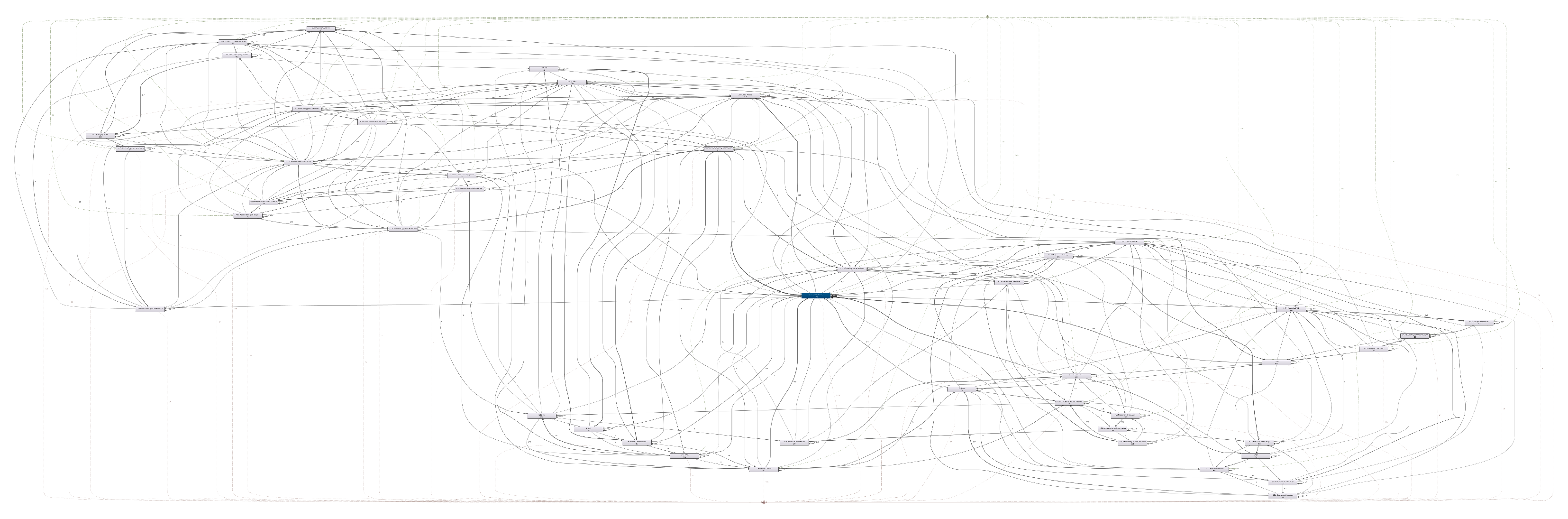
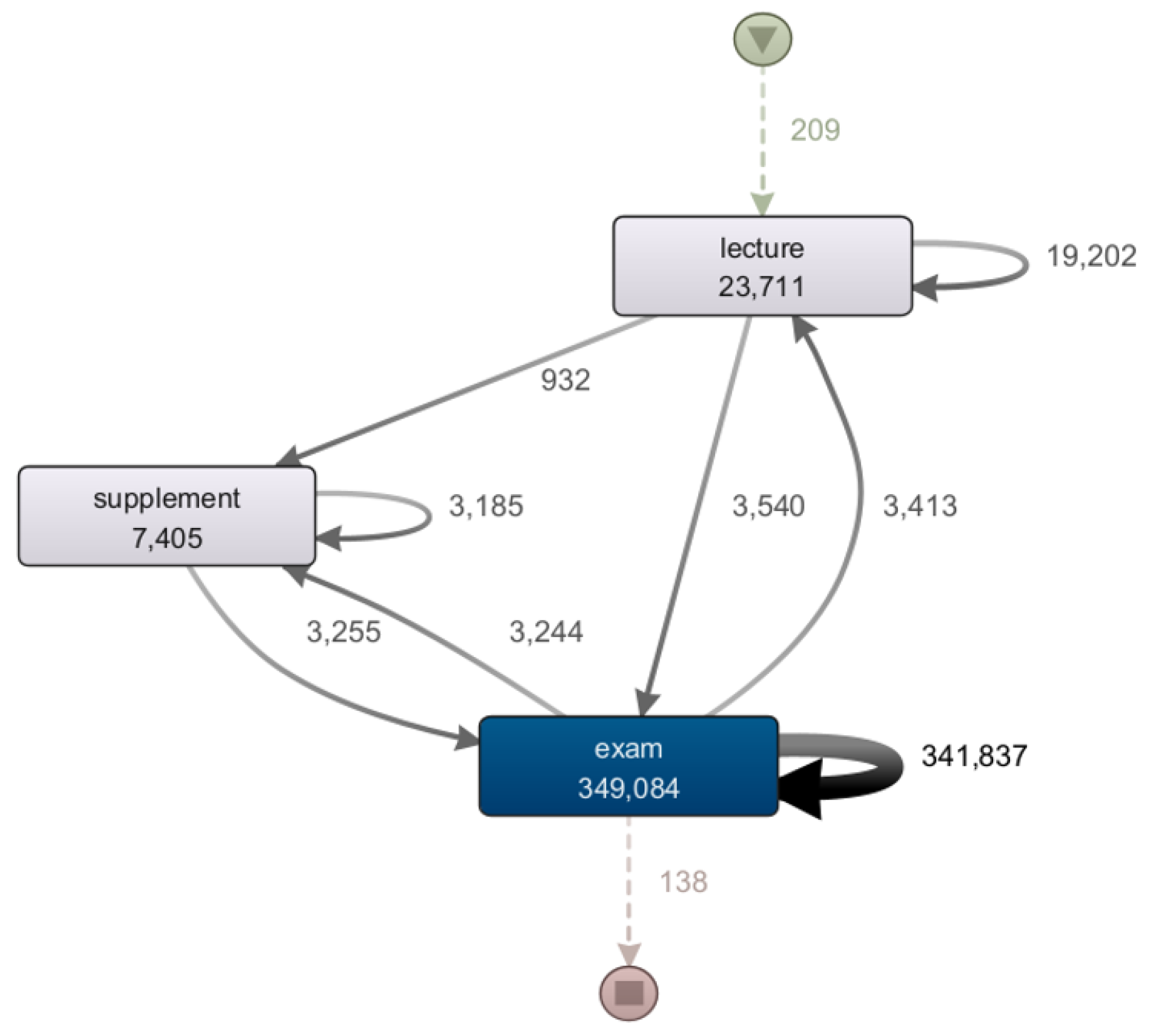
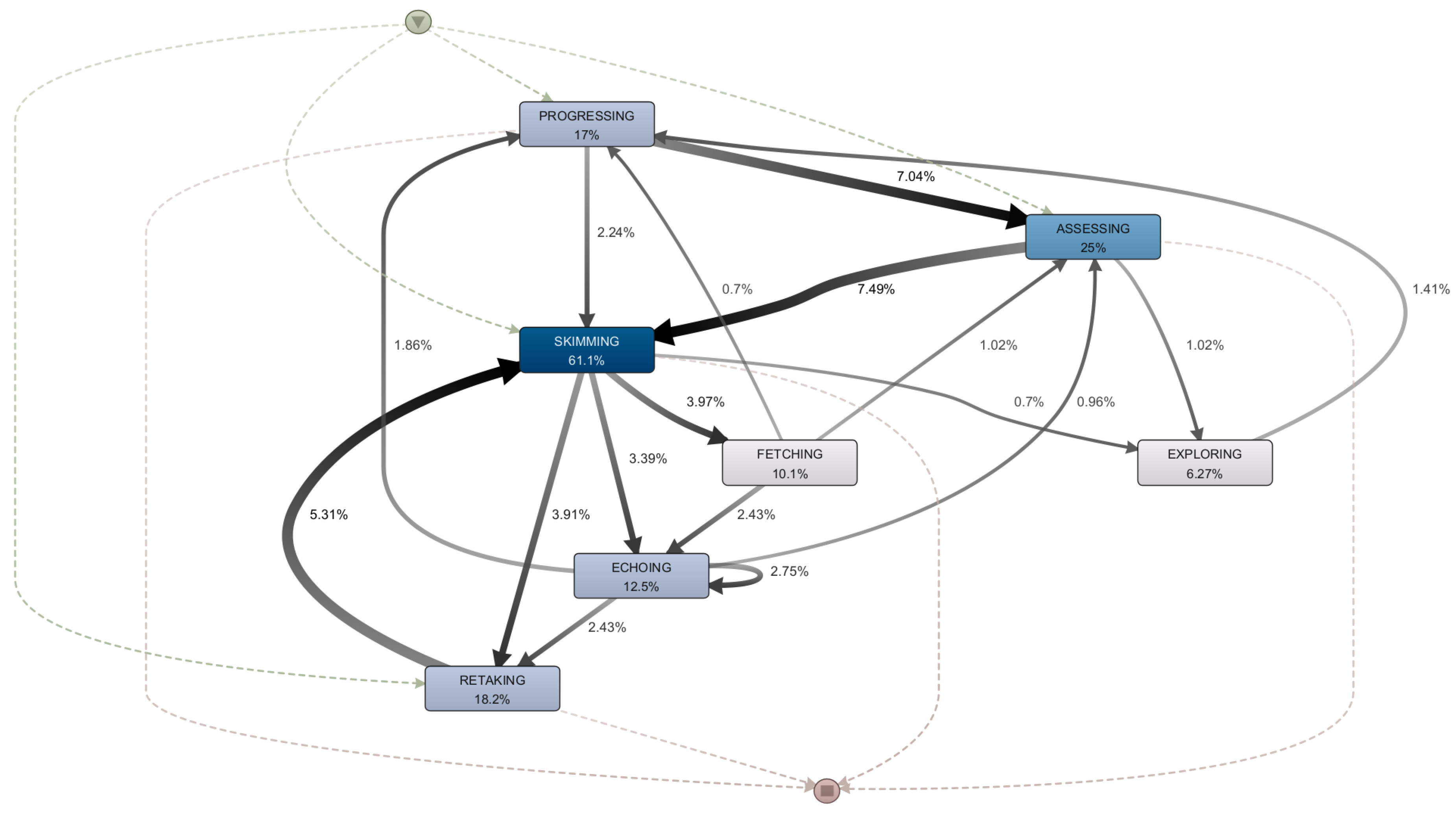
5. Case Study: Successful Student Sessions in Coursera
5.1. Case Study & Framework
5.2. RQ1: What Are the Characteristics of the Sessions That Involve Learning Dynamics in Which a Resource Is Revisited?
5.3. RQ2: Are There Differences in Terms of Learning Dynamics between the First and Final Sessions Carried out by Students?
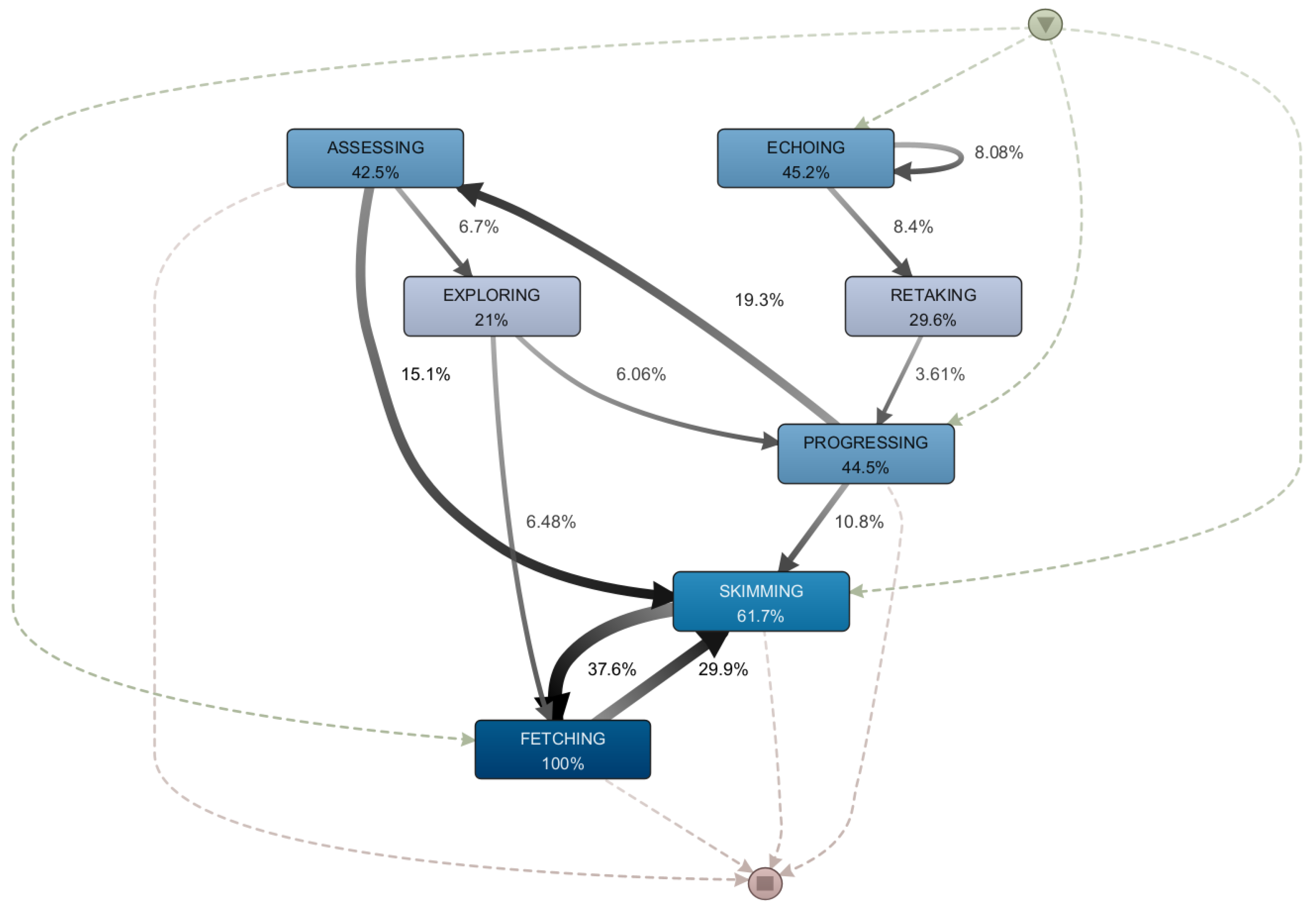
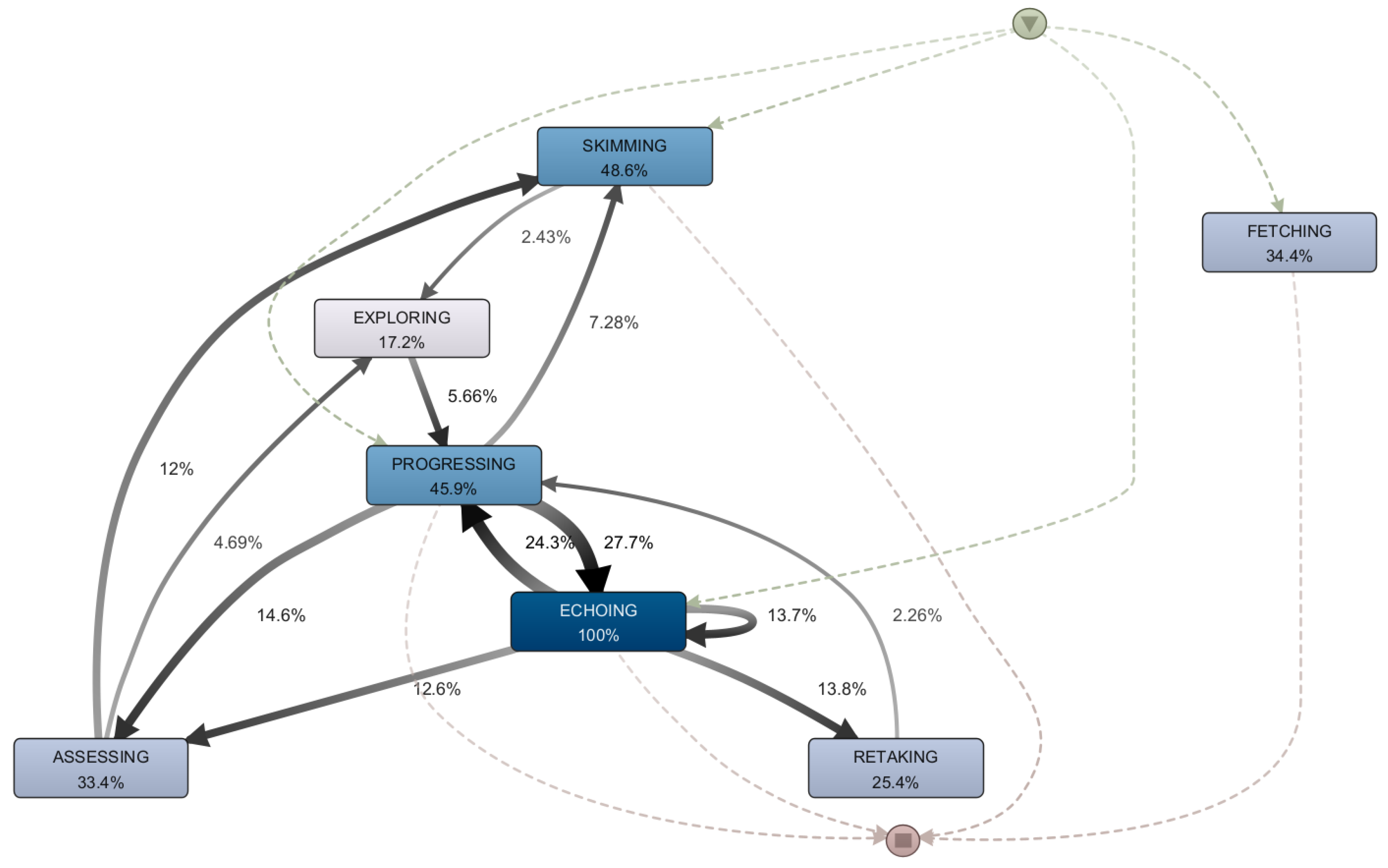
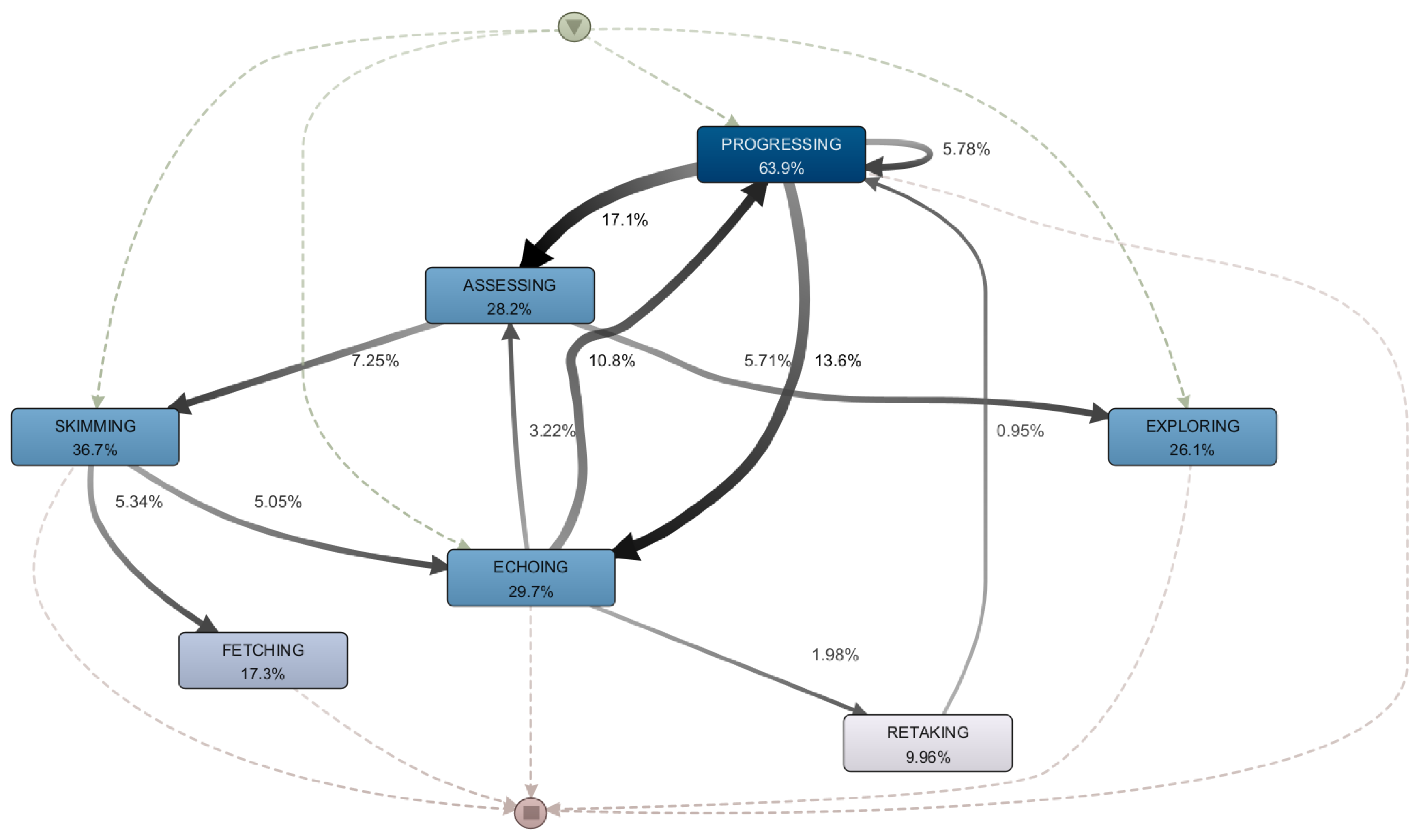
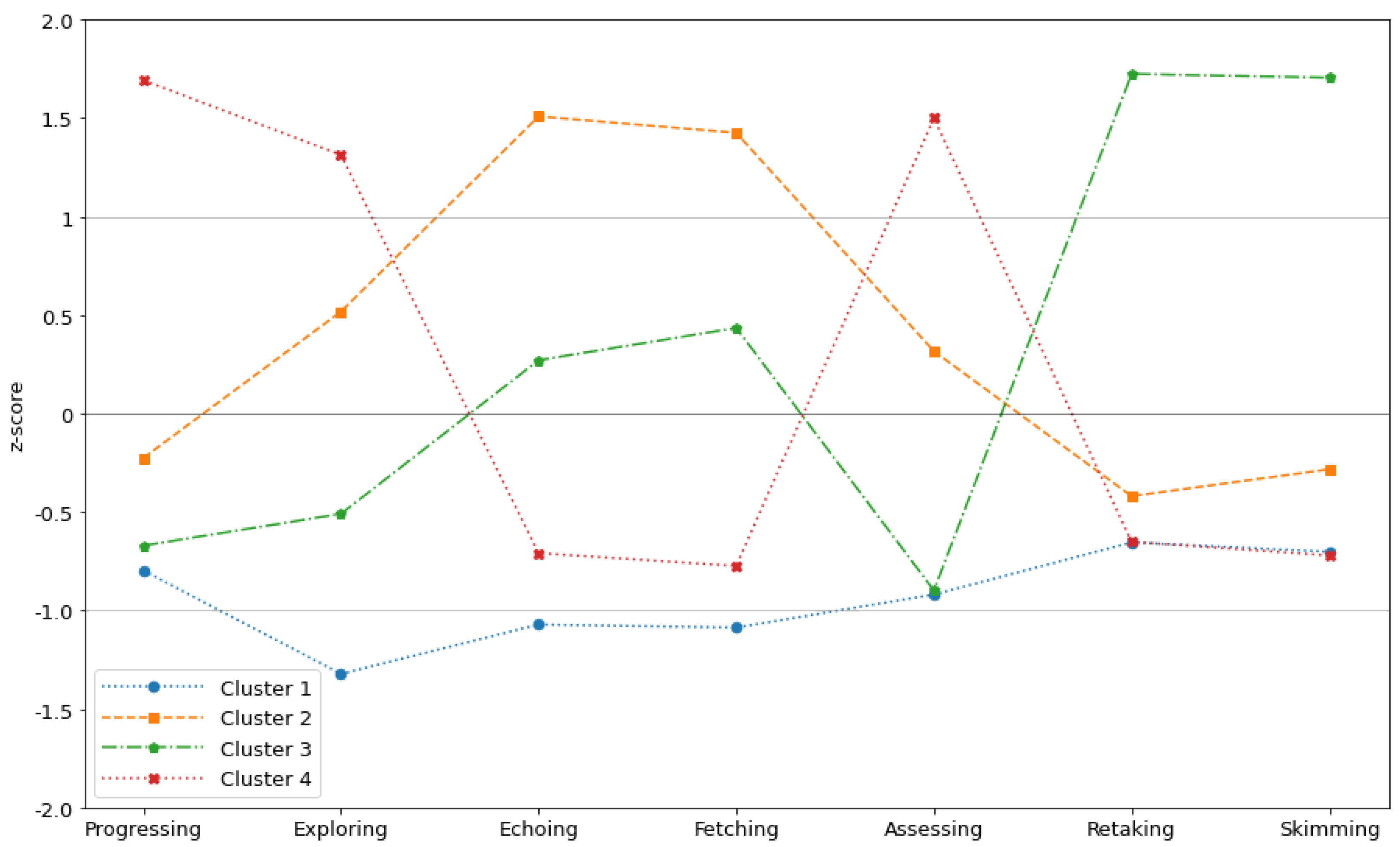
5.4. RQ3: What Types of Mooc Sessions Do Successful Students Go through and How Do They Differ from Each Other?
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| B-learning | Blended Learning |
| ID | Identifier |
| LMS | Learning Management System |
| MOOC | Massive Open Online Courses |
| MOODLE | Modular Object-Oriented Dynamic Learning Environment |
| RQ | Research Question |
References
- Reich, J.; Ruipérez-Valiente, J.A. The MOOC pivot. Science 2019, 363, 130–131. [Google Scholar] [CrossRef]
- Bernal, F.; Maldonado-Mahauad, J.; Villalba-Condori, K.; Zúñiga-Prieto, M.; Veintimilla-Reyes, J.; Mejía, M. Analyzing Students’ Behavior in a MOOC Course: A Process-Oriented Approach. In Proceedings of the HCI International 2020 – Late Breaking Papers: Cognition, Learning and Games; Springer International Publishing: Cham, Switzerland, 2020; pp. 307–325. [Google Scholar] [CrossRef]
- Zhu, M.; Sari, A.R.; Lee, M.M. A comprehensive systematic review of MOOC research: Research techniques, topics, and trends from 2009 to 2019. Educ. Technol. Res. Dev. 2020, 68, 1685–1710. [Google Scholar] [CrossRef]
- Fan, Y.; Matcha, W.; Uzir, N.A.; Wang, Q.; Gašević, D. Learning Analytics to Reveal Links Between Learning Design and Self-Regulated Learning. Int. J. Artif. Intell. Educ. 2021, 31, 980–1021. [Google Scholar] [CrossRef]
- Maldonado-Mahauad, J.; Pérez-Sanagustín, M.; Kizilcec, R.F.; Morales, N.; Munoz-Gama, J. Mining theory-based patterns from Big data: Identifying self-regulated learning strategies in Massive Open Online Courses. Comput. Hum. Behav. 2018, 80, 179–196. [Google Scholar] [CrossRef]
- Fan, Y.; Tan, Y.; Raković, M.; Wang, Y.; Cai, Z.; Shaffer, D.W.; Gašević, D. Dissecting Learning Tactics in MOOC Using Ordered Network Analysis. J. Comput. Assist. Learn. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1111/jcal.12735 (accessed on 10 January 2023). [CrossRef]
- Rizvi, S.; Rienties, B.; Rogaten, J. Temporal Dynamics of MOOC Learning Trajectories. In Proceedings of the First International Conference on Data Science, E-Learning and Information Systems; DATA ’18; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- de Barba, P.G.; Malekian, D.; Oliveira, E.A.; Bailey, J.; Ryan, T.; Kennedy, G. The importance and meaning of session behaviour in a MOOC. Comput. Educ. 2020, 146, 103772. [Google Scholar] [CrossRef]
- van der Aalst, W.M.P. Process Mining: Data Science in Action, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- van der Aalst, W.M.P.; Carmona, J. (Eds.) Process Mining Handbook; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2022; Volume 448. [Google Scholar] [CrossRef]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process Mining Manifesto. In Proceedings of the Business Process Management Workshops—BPM 2011 International Workshops, Clermont-Ferrand, France, 29 August 2011; Daniel, F., Barkaoui, K., Dustdar, S., Eds.; Revised Selected Papers, Part I; Springer: Berlin/Heidelberg, Germany, 2011; Volume 99, pp. 169–194. [Google Scholar] [CrossRef]
- Wambsganss, T.; Schmitt, A.; Mahnig, T.; Ott, A.; Soellner, S.; Ngo, N.A.; Geyer-Klingeberg, J.; Naklada, J. The potential of technology-mediated learning processes: A taxonomy and research agenda for educational process mining. In Proceedings of the International Conference on Information Systems (ICIS), Austin, TX, USA, 12–15 December 2021. [Google Scholar]
- van Zelst, S.J.; Mannhardt, F.; de Leoni, M.; Koschmider, A. Event abstraction in process mining: Literature review and taxonomy. Granul. Comput. 2021, 6, 719–736. [Google Scholar] [CrossRef]
- Hidalgo, L.; Munoz-Gama, J. Domain-Driven Event Abstraction Framework for Learning Dynamics in MOOCs Sessions. In Proceedings of the International Workshop on Education Meets Process Mining (EduPM); Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Mukala, P.; Buijs, J.; Van Der Aalst, W. Exploring Students’ Learning Behaviour in Moocs Using Process Mining Techniques. BPM Rep. 2015, 1510. Available online: https://research.tue.nl/nl/publications/exploring-students-learning-behaviour-in-moocs-using-process-mini (accessed on 18 January 2023).
- Rizvi, S.; Rienties, B.; Rogaten, J.; Kizilcec, R.F. Investigating variation in learning processes in a FutureLearn MOOC. J. Comput. High. Educ. 2020, 32, 162–181. [Google Scholar] [CrossRef]
- Deeva, G.; Smedt, J.D.; Koninck, P.D.; Weerdt, J.D. Dropout Prediction in MOOCs: A Comparison Between Process and Sequence Mining. In Proceedings of the Business Process Management Workshops; Springer International Publishing: Cham, Switzerland, 2018; pp. 243–255. [Google Scholar] [CrossRef]
- Arpasat, P.; Premchaiswadi, N.; Porouhan, P.; Premchaiswadi, W. Applying Process Mining to Analyze the Behavior of Learners in Online Courses. Proc. Int. J. Inf. Educ. Technol. 2021, 11, 436–443. [Google Scholar] [CrossRef]
- Van den Beemt, A.; Buijs, J.; Van der Aalst, W. Analysing structured learning behaviour in massive open online courses (MOOCs): An approach based on process mining and clustering. Int. Rev. Res. Open Distrib. Learn. 2018, 19, 37–60. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, D.; Liu, C. MOOC Video Personalized Classification Based on Cluster Analysis and Process Mining. Sustainability 2020, 12, 3066. [Google Scholar] [CrossRef]
- Maldonado-Mahauad, J.; Alario-Hoyos, C.; Delgado Kloos, C.; Perez-San Agustin, M. Adaptation of a Process Mining Methodology to Analyse Learning Strategies in a Synchronous Massive Open Online Course. In Proceedings of the Information and Communication Technologies; Springer International Publishing: Cham, Switzerland, 2022; pp. 117–136. [Google Scholar] [CrossRef]
- Beerepoot, I.; Di Ciccio, C.; Reijers, H.A.; Rinderle-Ma, S.; Bandara, W.; Burattin, A.; Calvanese, D.; Chen, T.; Cohen, I.; Depaire, B.; et al. The biggest business process management problems to solve before we die. Comput. Ind. 2023, 146, 103837. [Google Scholar] [CrossRef]
- Sánchez-Charles, D.; Carmona, J.; Muntés-Mulero, V.; Solé, M. Reducing Event Variability in Logs by Clustering of Word Embeddings. In Proceedings of the Business Process Management Workshops; Teniente, E., Weidlich, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 191–203. [Google Scholar] [CrossRef]
- Rehse, J.R.; Fettke, P. Clustering Business Process Activities for Identifying Reference Model Components. In Proceedings of the Business Process Management Workshops; Daniel, F., Sheng, Q.Z., Motahari, H., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 5–17. [Google Scholar] [CrossRef]
- Mannhardt, F.; Tax, N. Unsupervised Event Abstraction using Pattern Abstraction and Local Process Models. arXiv 2017, arXiv:1704.03520. [Google Scholar] [CrossRef]
- Gúnther, C.W.; Rozinat, A.; van der Aalst, W.M.P. Activity Mining by Global Trace Segmentation. In Proceedings of the Business Process Management Workshops; Rinderle-Ma, S., Sadiq, S., Leymann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 128–139. [Google Scholar] [CrossRef]
- Leonardi, G.; Striani, M.; Quaglini, S.; Cavallini, A.; Montani, S. Towards Semantic Process Mining Through Knowledge-Based Trace Abstraction. In Proceedings of the Data-Driven Process Discovery and Analysis; Ceravolo, P., van Keulen, M., Stoffel, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 45–64. [Google Scholar] [CrossRef]
- Baier, T.; Mendling, J.; Weske, M. Bridging abstraction layers in process mining. Inf. Syst. 2014, 46, 123–139. [Google Scholar] [CrossRef]
- de Leoni, M.; Dündar, S. Event-Log Abstraction Using Batch Session Identification and Clustering. In Proceedings of the 35th Annual ACM Symposium on Applied Computing; SAC ’20; Association for Computing Machinery: New York, NY, USA, 2020; pp. 36–44. [Google Scholar] [CrossRef]
- Kovanović, V.; Gašević, D.; Dawson, S.; Joksimović, S.; Baker, R.S.; Hatala, M. Penetrating the Black Box of Time-on-Task Estimation. In Proceedings of the Fifth International Conference on Learning Analytics Furthermore, Knowledge; LAK ’15; Association for Computing Machinery: New York, NY, USA, 2015; pp. 184–193. [Google Scholar] [CrossRef]
- Liu, B.; Wu, Y.; Xing, W.; Cheng, G.; Guo, S. Exploring behavioural differences between certificate achievers and explorers in MOOCs. Asia Pac. J. Educ. 2022, 42, 802–814. [Google Scholar] [CrossRef]
- Rabin, E.; Silber-Varod, V.; Kalman, Y.M.; Kalz, M. Identifying Learning Activity Sequences that Are Associated with High Intention-Fulfillment in MOOCs. In Proceedings of the Transforming Learning with Meaningful Technologies; Scheffel, M., Broisin, J., Pammer-Schindler, V., Ioannou, A., Schneider, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 224–235. [Google Scholar] [CrossRef]
- Chen, H.M.; Nguyen, B.a.; Dow, C.R.; Hsueh, N.L.; Liu, A.C. Exploring Time-Related Micro-Behavioral Patterns in a Python Programming Online Course. J. Inf. Sci. Eng. 2022, 38, 1109–1131. [Google Scholar]
- Li, S.; Du, J.; Sun, J. Unfolding the learning behaviour patterns of MOOC learners with different levels of achievement. Int. J. Educ. Technol. High. Educ. 2022, 19, 1–20. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Suwanda, R.; Syahputra, Z.; Zamzami, E.M. Analysis of Euclidean Distance and Manhattan Distance in the K-Means Algorithm for Variations Number of Centroid K. J. Phys. Conf. Ser. 2020, 1566, 12058. [Google Scholar] [CrossRef]
- Faisal, M.; Zamzami, E.M.; Sutarman. Comparative Analysis of Inter-Centroid K-Means Performance using Euclidean Distance, Canberra Distance and Manhattan Distance. J. Phys. Conf. Ser. 2020, 1566, 12112. [Google Scholar] [CrossRef]
- Saputra, D.M.; Saputra, D.; Oswari, L.D. Effect of Distance Metrics in Determining K-Value in K-Means Clustering Using Elbow and Silhouette Method. In Proceedings of the Sriwijaya International Conference on Information Technology and Its Applications (SICONIAN 2019); Atlantis Press: Dordrecht, The Netherlands, 2020; pp. 341–346. [Google Scholar] [CrossRef]
- Boroujeni, M.S.; Dillenbourg, P. Discovery and Temporal Analysis of Latent Study Patterns in MOOC Interaction Sequences. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge; LAK ’18; Association for Computing Machinery: New York, NY, USA, 2018; pp. 206–215. [Google Scholar] [CrossRef]
- Alshar’e, M.; Albadi, A.; Jawarneh, M.; Tahir, N.; Al Amri, M. Usability evaluation of educational games: An analysis of culture as a factor Affecting children’s educational attainment. Adv. Hum. Comput. Interact. 2022, 2022, 9427405. [Google Scholar] [CrossRef]
- Alshar’e, M.; Albadi, A.; Mustafa, M.; Tahir, N.; Al Amri, M. A framework of the training module for untrained observers in usability evaluation motivated by COVID-19: Enhancing the validity of usability evaluation for children’s educational games. Adv. Hum. Comput. Interact. 2022, 2022, 7527457. [Google Scholar] [CrossRef]
- Alshar’e, M.; Mustafa, M.; Bsoul, Q. Evaluation of E-Learning Method as a Mean to Support Autistic Children Learning in Oman. J. Posit. Sch. Psychol. 2022, 6, 3040–3048. [Google Scholar]
- Salazar-Fernandez, J.P.; Munoz-Gama, J.; Maldonado-Mahauad, J.; Bustamante, D.; Sepúlveda, M. Backpack Process Model (BPPM): A Process Mining Approach for Curricular Analytics. Appl. Sci. 2021, 11, 4265. [Google Scholar] [CrossRef]
- Cameranesi, M.; Diamantini, C.; Genga, L.; Potena, D. Students’ Careers Analysis: A Process Mining Approach. In Proceedings of the Proceedings of the 7th International Conference on Web Intelligence, Mining and Semantics; WIMS ’17; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Juhaňák, L.; Zounek, J.; Rohlíková, L. Using process mining to analyze students’ quiz-taking behavior patterns in a learning management system. Comput. Hum. Behav. 2019, 92, 496–506. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, N.; Peng, X.; Liu, S.; Yang, Z.; Peng, J.; Su, Z.; Chen, J. Exploring the Relationship Between Social Interaction, Cognitive Processing and Learning Achievements in a MOOC Discussion Forum. J. Educ. Comput. Res. 2022, 60, 132–169. [Google Scholar] [CrossRef]
- Gamage, D.; Perera, I.; Fernando, S. Exploring MOOC User Behaviors Beyond Platforms. Int. J. Emerg. Technol. Learn. 2020, 15, 161–179. [Google Scholar] [CrossRef]
- Wong, J.; Khalil, M.; Baars, M.; de Koning, B.B.; Paas, F. Exploring sequences of learner activities in relation to self-regulated learning in a massive open online course. Comput. Educ. 2019, 140, 103595. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User | Resource | Timestamp | Order | Type | State | Session |
|---|---|---|---|---|---|---|
| Johnny | Guitar Basics: Guitar parts | 2020/05/28 13:05:10 | 1 | Content | Started | 1 |
| Johnny | Guitar Basics: Posture | 2020/05/28 13:05:18 | 2 | Content | Started | 1 |
| Johnny | Guitar Basics: Picking | 2020/05/28 13:06:02 | 3 | Content | Started | 1 |
| Johnny | Guitar basics: Identifying notes | 2020/05/28 13:06:30 | 4 | Content | Started | 1 |
| Johnny | Guitar Basics: Guitar parts | 2020/05/30 12:30:22 | 1 | Content | Started | 2 |
| Johnny | Guitar Basics: Guitar parts | 2020/05/30 12:33:01 | 1 | Content | Completed | 2 |
| Johnny | Guitar Basics: Posture | 2020/05/30 12:35:18 | 2 | Content | Started | 2 |
| Johnny | Guitar Basics: Posture | 2020/05/30 12:37:55 | 2 | Content | Completed | 2 |
| Johnny | Guitar Basics: Picking | 2020/05/30 12:38:25 | 3 | Content | Started | 2 |
| Johnny | Guitar Basics: Picking | 2020/05/30 12:40:32 | 3 | Content | Completed | 2 |
| Johnny | Guitar basics: Left hand technique | 2020/05/30 12:45:49 | 5 | Content | Started | 2 |
| Johnny | Guitar basics: Left hand technique | 2020/05/30 12:49:42 | 5 | Content | Completed | 2 |
| Johnny | Guitar Basics: Guitar parts | 2020/05/30 12:58:12 | 1 | Content | Started | 2 |
| Johnny | Guitar Basics: Posture | 2020/05/30 12:59:01 | 2 | Content | Started | 2 |
| Johnny | Guitar Basics: Picking | 2020/05/30 12:59:37 | 3 | Content | Started | 2 |
| Johnny | Guitar Basics: Picking | 2020/05/30 13:05:09 | 3 | Content | Completed | 2 |
| Mary | Chord diagrams | 2020/06/01 16:58:51 | 10 | Content | Started | 5 |
| Mary | Cowboy Chords | 2020/06/01 17:19:13 | 11 | Content | Started | 5 |
| Mary | Cowboy Chords | 2020/06/01 17:28:13 | 11 | Content | Completed | 5 |
| Mary | Recognizing Chords | 2020/06/01 17:30:00 | 12 | Assessment | Started | 5 |
| Mary | Recognizing Chords | 2020/06/01 17:36:28 | 12 | Assessment | Completed | 5 |
| Mary | Recognizing Power Chords | 2020/06/01 17:37:23 | 13 | Assessment | Started | 5 |
| Mary | Recognizing Power Chords | 2020/06/01 17:45:59 | 13 | Assessment | Completed | 5 |
| Mary | Recognizing Power Chords | 2020/06/01 17:47:39 | 13 | Assessment | Started | 5 |
| Mary | Recognizing Chords | 2020/06/02 09:10:29 | 12 | Assessment | Started | 6 |
| Mary | Recognizing Power Chords | 2020/06/02 09:12:22 | 13 | Assessment | Started | 6 |
| Mary | Recognizing Power Chords | 2020/06/02 09:15:41 | 13 | Assessment | Started | 6 |
| Mary | Recognizing Power Chords | 2020/06/02 09:18:41 | 13 | Assessment | Completed | 6 |
| ... | ... | ... | ... | ... | ... | ... |
| User | Session | Activity | Started | Completed |
|---|---|---|---|---|
| Johnny | 1 | Exploring | 2020/05/28 13:05:10 | 2020/05/28 13:06:30 |
| Johnny | 2 | Exploring | 2020/05/30 12:30:22 | 2020/05/30 12:30:22 |
| Johnny | 2 | Progressing | 2020/05/30 12:30:22 | 2020/05/30 12:40:32 |
| Johnny | 2 | Progressing | 2020/05/30 12:45:49 | 2020/05/30 12:49:42 |
| Johnny | 2 | Fetching | 2020/05/30 12:58:12 | 2020/05/30 12:59:01 |
| Johnny | 2 | Echoing | 2020/05/30 12:59:37 | 2020/05/30 13:05:09 |
| Mary | 5 | Fetching | 2020/06/01 16:58:51 | 2020/06/01 16:58:51 |
| Mary | 5 | Echoing | 2020/06/01 17:19:13 | 2020/06/01 17:28:13 |
| Mary | 5 | Assessing | 2020/06/01 17:30:00 | 2020/06/01 17:45:59 |
| Mary | 5 | Skimming | 2020/06/01 17:47:39 | 2020/06/01 17:47:39 |
| Mary | 6 | Skimming | 2020/06/02 09:10:29 | 2020/06/02 09:12:22 |
| Mary | 6 | Retaking | 2020/06/02 09:15:41 | 2020/06/02 09:18:41 |
| ... | ... | ... | ... | ... |
| Table Name | Field Name | Data Type | Description |
|---|---|---|---|
| Course Progress | course_id | ID | ID of the course in which an interaction occur. Foreign key to uniquely identify the course. |
| course_item_id | ID | ID of the resource queried in the interaction. Foreign key to uniquely identify the resource. | |
| user_id | ID | ID of the user who makes the interaction. Foreign key to uniquely identify the user. | |
| course_progress_state_type_id | ID | ID of the state type of the interaction performed. Foreign key to uniquely identify the type of interaction performed. | |
| course_progress_ts | Timestamp | Moment in which the interaction is performed. | |
| Course Item Types | course_item_type_id | ID | ID to uniquely identify a type of item. In this case there were only three different types of items but Coursera defines 19 possible ones. |
| course_item_type_desc | String | Name of the resource type. | |
| course_item_type_category | String | Category to which the resource type belongs. Only items from the lecture and quiz categories were used. | |
| course_item_type_graded | Boolean | Boolean indicating whether or not the resource type has a grade associated with it. | |
| Course Items | course_id | ID | ID of the course in which an item is placed. Foreign key to uniquely identify the course. |
| course_item_id | ID | ID to uniquely identify a resource. | |
| course_lesson_id | ID | ID of the lesson in which the item is placed. Foreign key to uniquely identify a lesson. | |
| course_item_order | Integer | Integer to indicate the order of each resource within the lesson. | |
| course_item_type_id | ID | ID of the type to which the resource belongs. Foreign key to uniquely identify the type of resource. | |
| course_item_name | String | Name of the resource, written in Spanish originally. | |
| course_item_optional | Boolean | Boolean indicating whether or not the item if optional. | |
| Course Lessons | course_id | ID | ID of the course in which a lesson is placed. Foreign key to uniquely identify the course. |
| course_lesson_id | ID | ID to uniquely identify a lesson. | |
| course_module_id | ID | ID of the module in which the lesson is placed. Foreign key to uniquely identify the lesson. | |
| course_lesson_order | Integer | Integer to indicate the order of each resource within the module. | |
| course_lesson_name | String | Name of the lesson, written in Spanish originally. | |
| Course Modules | course_id | ID | ID of the course in which a module is placed. Foreign key to uniquely identify the course. |
| course_module_id | ID | ID to uniquely identify a module. | |
| course_module_order | Integer | Integer to indicate the order of each module within the course. | |
| course_module_name | String | Name of the module, written in Spanish originally. | |
| course_module_desc | Strings | A description of the module’s contents and learning objectives. Written in Spanish originally. | |
| Course Progress State Types | course_progress_state_type_id | ID | ID to uniquely identify a state type. |
| course_progress_state_type_desc | String | “Name of the state. The table has only two states: 1 for “started” and 2 for “completed". |
| Q1 | Q2 | Q3 | Q4 | Q5 | |
|---|---|---|---|---|---|
| % of cases | 19% | 20% | 19% | 19% | 22% |
| % of events | 23% | 23% | 20% | 18% | 16% |
| N° of cases | 1366 | 1429 | 1371 | 1359 | 1562 |
| N° of events | 4120 | 4097 | 3655 | 3303 | 2854 |
| Mean case duration | 49 min | 46.9 min | 38.3 min | 36 min | 28.9 min |
| Median case durations | 28 min | 16.5 min | 8.9 min | 5.8 min | 0 min |
| Variants | 446 | 395 | 336 | 298 | 228 |
| Most common variant | Progressing (18.23%) | Skimming (21.27%) | Skimming (27.64%) | Skimming (32.52%) | Skimming (40.4%) |
| Mean activities per case | 3.02 | 2.81 | 2.61 | 2.43 | 1.83 |
| Median activities per case | 2 | 2 | 1 | 1 | 1 |
| Cluster | N° of Sessions | Percentage | Average Time (Minutes) | Average Activities |
|---|---|---|---|---|
| Cluster 1 | 5288 | 74.6% | 19.4 | 1.4 |
| Cluster 2 | 435 | 6.1% | 108.9 | 8.2 |
| Cluster 3 | 33 | 0.5% | 163.5 | 26.2 |
| Cluster 4 | 1329 | 18.8% | 93.8 | 4.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hidalgo, L.; Munoz-Gama, J. A Domain-Driven Framework to Analyze Learning Dynamics in MOOCs through Event Abstraction. Appl. Sci. 2023, 13, 3039. https://doi.org/10.3390/app13053039
Hidalgo L, Munoz-Gama J. A Domain-Driven Framework to Analyze Learning Dynamics in MOOCs through Event Abstraction. Applied Sciences. 2023; 13(5):3039. https://doi.org/10.3390/app13053039
Chicago/Turabian StyleHidalgo, Luciano, and Jorge Munoz-Gama. 2023. "A Domain-Driven Framework to Analyze Learning Dynamics in MOOCs through Event Abstraction" Applied Sciences 13, no. 5: 3039. https://doi.org/10.3390/app13053039
APA StyleHidalgo, L., & Munoz-Gama, J. (2023). A Domain-Driven Framework to Analyze Learning Dynamics in MOOCs through Event Abstraction. Applied Sciences, 13(5), 3039. https://doi.org/10.3390/app13053039