
Deep Learning Applications for Dyslexia Prediction


Abstract
1. Introduction
- -
- The types of datasets that are used by prediction models.
- -
- Different DL models that are utilized to predict dyslexia disorder.
- -
- The performance of DL models in dyslexia prediction.
2. Related Work
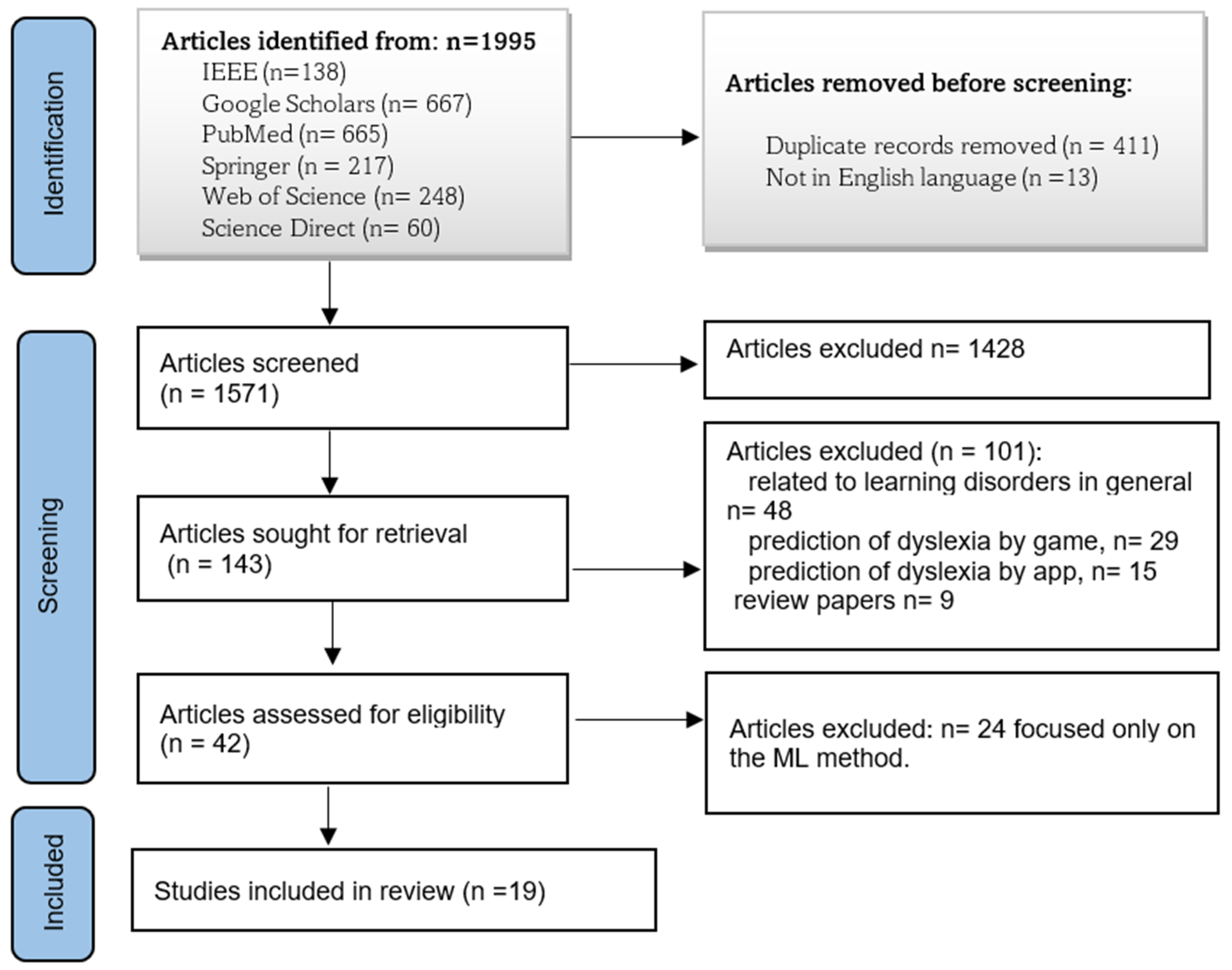
3. Research Strategy
4. Research Results
4.1. Data Acquisition
4.2. Data Preprocessing
4.3. Feature Extraction and Selection
4.4. Classification and Performance of Deep Learning Models
5. Discussion and Challenges
- -
- The dropout technique that commonly employs the method of generalization. Throughout each training period, the neurons are randomly eliminated. In doing so, the power of feature selection is divided uniformly over the entire group of neurons, and the model is forced to learn multiple independent features [48].
- -
- Data augmentation: Training the model on a substantial amount of data is the simplest method for avoiding overfitting [49]. Several strategies are employed to augment the size of the training dataset, such as cropping, translation, and rotation. Rotation and noise injection techniques have been used in the study [29]; they contributed to enlarging the training size dataset and solved the imbalanced class problem.
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICT | Information and Communication Technologies |
| CASL | Comprehensive Assessment of Spoken Language |
| CTOPP-2 | Comprehensive Test of Phonological Processing-2 |
| WRMT | Woodcock Reading Mastery Test |
| GSRT | Gray Silent Reading Test |
| MRI | Magnetic Resonance Imaging |
| DTI | Diffusion Tensor Imaging |
| GPUs | Graphics Processing Units |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Networks |
| MLP | Multi-layer Perception |
| PRISMA | Preferred Reporting Items for Systematic review and Meta-Analyses |
| ERP | Event-Related Potentials |
| RFE-CV | Recursive feature Elimination with Cross-Validation |
| BET | Brain Extraction Tool |
| TBSS | Track-Based Spatial Statistics |
| OCR | Optical Character Recognition |
| ADM | Association of Dyslexia Malaysia |
| SSA | Singular Spectrum Analysis SSA |
| PCA | Principal Component Analysis |
| ML | Machine Learning |
| SVM | Support Vector Machine |
| DL | Deep Learning |
| 3D | Three-Dimensional. |
| TEWL | Test of Early Written Language |
| fMRI | Functional MRI |
| EEG | Electroencephalography |
| IEEE | Institute of Electrical and Electronic |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| RNNs | Recurrent Neural Networks |
| PCA | Principal Component Analysis |
| FA | Fractional Anisotropy |
| FEAT | FMRI Expert Analysis Tool |
| FDT | FMRIB Diffusion Toolbox |
| EOG | Electrooculogram |
| STFT | Short-Time Fourier Transform |
| PSD | Power Spectral Density |
References
- Granet, D.B. Learning disabilities, dyslexia, and vision: The role of the pediatric ophthalmologist. J. AAPOS 2011, 15, 119–120. [Google Scholar] [CrossRef]
- Wajuihian, S.O.; Od, O.; Pgcertmod, U. Dyslexia : An overview. Afr. Vis. Eye Health 2011, 43, 24–33. [Google Scholar] [CrossRef]
- Laffey, J.L.; Siffin, C.F. ERIC/CRIER Reading Review Series. 1969. Available online: https://files.eric.ed.gov/fulltext/ED032453.pdf (accessed on 26 January 2023).
- Isa, I.S.; Zahir, M.A.; Ramlan, S.A.; Li-Chih, W.; Sulaiman, S.N. CNN Comparisons Models on Dyslexia Handwriting Classification. ESTEEM Acad. J. 2021, 17, 12–25. [Google Scholar]
- Drigas, A.S.; Politi-Georgousi, S. ICTs as a distinct detection approach for dyslexia screening: A contemporary view. Int. J. Online Biomed. Eng. 2019, 15, 46–60. [Google Scholar] [CrossRef]
- Jankovic, M.M. Biomarker-based approaches for dyslexia screening: A review. IEEE Zooming Innov. Consum. Technol. Conf. 2022, 2022, 28–33. [Google Scholar] [CrossRef]
- Habib, M. The neurological basis of developmental dyslexia an overview and working hypothesis. Brain 2000, 123, 2373–2399. [Google Scholar] [CrossRef]
- Blau, V.; Reithler, J.; Van Atteveldt, N.; Seitz, J.; Gerretsen, P.; Goebel, R.; Blomert, L. Deviant processing of letters and speech sounds as proximate cause of reading failure: A functional magnetic resonance imaging study of dyslexic children. Brain 2010, 133, 868–879. [Google Scholar] [CrossRef]
- Vandermosten, M.; Cuynen, L.; Vanderauwera, J.; Wouters, J.; Ghesquière, P. White matter pathways mediate parental effects on children’s reading precursors. Brain Lang. 2017, 173, 10–19. [Google Scholar] [CrossRef]
- Alvarez, T.A.; Fiez, J.A. Current perspectives on the cerebellum and reading development. Neurosci. Biobehav. Rev. 2018, 92, 55–66. [Google Scholar] [CrossRef]
- Arns, M.; Peters, S.; Breteler, R.; Verhoeven, L. Different brain activation patterns in dyslexic children: Evidence from EEG power and coherence patterns for the double-deficit theory of dyslexia. J. Integr. Neurosci. 2007, 6, 175–190. [Google Scholar] [CrossRef]
- Usman, O.L.; Muniyandi, R.C. CryptoDL: Predicting dyslexia biomarkers from encrypted neuroimaging dataset using energy-efficient residue number system and deep convolutional neural network. Symmetry 2020, 12, 836. [Google Scholar] [CrossRef]
- Sharma, D.K.; Chatterjee, M.; Kaur, G.; Vavilala, S. Deep Learning Applications for Disease Diagnosis; Elsevier: Amsterdam, The Netherlands, 2022; pp. 31–51. [Google Scholar] [CrossRef]
- Carin, L.; Pencina, M.J. On deep learning for medical image analysis. J. Am. Med. Assoc. 2018, 320, 1192–1193. [Google Scholar] [CrossRef]
- Prabha, A.J.; Bhargavi, R. Prediction of Dyslexia Using Machine Learning—A Research Travelogue. Res. Travel. Lect. Notes Electr. Eng. 2019, 556, 1–8. [Google Scholar] [CrossRef]
- Kaisar, S. Developmental dyslexia detection using machine learning techniques: A survey. ICT Express 2020, 6, 181–184. [Google Scholar] [CrossRef]
- Vanitha, G.; Kasthuri, M. Dyslexia Prediction Using Machine Learning Algorithms—A Review. Int. J. Aquat. Sci. 2021, 12, 3372–3380. Available online: http://www.journal-aquaticscience.com/article_135190.html%0Ahttp://www.journal-aquaticscience.com/article_135190_a14355942a6a1ab5eebf9c4eae0aa078.pdf (accessed on 26 January 2023).
- Dhas, J.; Jose, S.H. A Study on Dyslexia Using Machine Learning-Review. EasyChair Prepr. 2021. Available online: https://easychair.org/publications/preprint/gLjk (accessed on 26 January 2023).
- Usman, O.L.; Muniyandi, R.C.; Omar, K.; Mohamad, M. Advance Machine Learning Methods for Dyslexia Biomarker Detection: A Review of Implementation Details and Challenges. IEEE Access 2021, 9, 36879–36897. [Google Scholar] [CrossRef]
- Kothapalli, P.K.V.; Rathikarani, V.; Nookala, G.K.M. A Comprehensive Survey on Predicting Dyslexia and ADHD Using Machine Learning Approaches. In Inventive Systems and Control; Springer: Singapore, 2022; pp. 105–121. [Google Scholar] [CrossRef]
- Ahire, N.; Awale, R.; Patnaik, S.; Wagh, A. A comprehensive review of machine learning approaches for dyslexia diagnosis. Multimed. Tools Appl. 2022, 1–12. [Google Scholar] [CrossRef]
- Poornappriya, T.; Gopinath, R. Application of Machine Learning Techniques for Improving Learning Disabilities. Int. J. Electr. Eng. Technol. 2020, 11, 403–411. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. J. Clin. Epidemiol. 2009, 62, 1006–1012. [Google Scholar] [CrossRef]
- Hebert, M.; Kearns, D.M.; Hayes, J.B.; Bazis, P.; Cooper, S. Why children with dyslexia struggle with writing and how to help them. Lang. Speech Hear. Serv. Sch. 2018, 49, 843–863. [Google Scholar] [CrossRef]
- Spoon, K.; Crandall, D.; Siek, K. Towards Detecting Dyslexia in Children’s Handwriting Using Neural Networks. In Proceedings of the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, CA, USA, 9–15 June 2019; pp. 1–5. [Google Scholar]
- Spoon, K.; Siek, K.; Crandall, D.; Fillmore, M. Can We (and Should We) Use AI to Detect Dyslexia in Children’s Handwriting? In Proceedings of the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, CA, USA, 9–15 June 2019; pp. 1–6. [Google Scholar]
- Isa, I.S.; Rahimi, W.N.S.; Ramlan, S.A.; Sulaiman, S.N. Automated Detection of Dyslexia Symptom Based on Handwriting Image for Primary School Children. Procedia Comput. Sci. 2019, 163, 440–449. [Google Scholar] [CrossRef]
- Yogarajah, P. Deep Learning Approach to Automated Detection of Dyslexia-Dysgraphia. In Proceedings of the 25th IEEE International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 1–12. Available online: https://www.micc.unifi.it/icpr2020/ (accessed on 12 November 2020).
- Bin Rosli, M.S.A.; Isa, I.S.; Ramlan, S.A.; Sulaiman, S.N.; Maruzuki, M.I.F. Development of CNN Transfer Learning for Dyslexia Handwriting Recognition. In Proceedings of the 2021 11th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–28 August 2021; pp. 194–199. [Google Scholar] [CrossRef]
- Kohli, M.; Prasad, T.V. Identifying dyslexic students by using artificial neural networks. In Proceedings of the World Congress on Engineering 2010, London, UK, 30 June–2 July 2010; Volume 1, pp. 118–121. [Google Scholar]
- Perera, H.; Shiratuddin, M.F.; Wong, K.W. Review of EEG-based pattern classifcation frameworks for dyslexia. Brain Inform. 2018, 5, 4. [Google Scholar] [CrossRef]
- Karim, I.; Abdul, W.; Kamaruddin, N. Classification of Dyslexic and Normal Children during resting condition using KDE and MLP. In Proceedings of the 2013 5th International Conference on Information and Communication Technology for the Muslim World, Rabat, Morocco, 26–27 March 2013. [Google Scholar] [CrossRef]
- Al-Barhamtoshy, H.M.; Motaweh, D.E.M. Diagnosis of Dyslexia using Computing Analysis. In Proceedings of the 2017 International Conference on Informatics, Health & Technology (ICIHT), Riyadh, Saudi Arabia, 21–23 February 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Frid, A.; Manevitz, L.M. Features and Machine Learning for Correlating and Classifying between Brain Areas and Dyslexia. arXiv 2018, arXiv:1812.10622. [Google Scholar]
- Ortiz, A.; Martínez-Murcia, F.J.; Formoso, M.A.; Luque, J.L.; Sánchez, A. Dyslexia detection from EEG signals using SSA component correlation and Convolutional Neural Networks. In Hybrid Artificial Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 655–664. [Google Scholar]
- Elnakib, A.; Soliman, A.; Nitzken, M.; Casanova, M.F.; Gimel’Farb, G.; El-Baz, A. Magnetic resonance imaging findings for dyslexia: A review. J. Biomed. Nanotechnol. 2014, 10, 2778–2805. [Google Scholar] [CrossRef]
- Zahia, S.; Garcia-Zapirain, B.; Saralegui, I.; Fernandez-Ruanova, B. Dyslexia detection using 3D convolutional neural networks and functional magnetic resonance imaging. Comput. Methods Programs Biomed. 2020, 197, 105726. [Google Scholar] [CrossRef]
- Chimeno, Y.G.; Zapirain, B.G.; Prieto, I.S.; Fernandez-Ruanova, B. Automatic classification of dyslexic children by applying machine learning to fMRI images. Bio-Med. Mater. Eng. 2014, 24, 2995–3002. [Google Scholar] [CrossRef]
- Da Silva, L.T.; Esper, N.B.; Ruiz, D.D.; Meneguzzi, F.; Buchweitz, A. Visual Explanation for Identification of the Brain Bases for Developmental Dyslexia on fMRI Data. Front. Comput. Neurosci. 2021, 15, 594659. [Google Scholar] [CrossRef]
- Nerušil, B.; Polec, J.; Škunda, J.; Kačur, J. Eye tracking based dyslexia detection using a holistic approach. Sci. Rep. 2021, 11, 15687. [Google Scholar] [CrossRef]
- Appadurai, J.P.; Bhargavi, R. Eye Movement Feature Set and Predictive Model for Dyslexia: Feature Set and Predictive Model for Dyslexia. Int. J. Cogn. Inform. Nat. Intell. 2021, 15, 22. [Google Scholar] [CrossRef]
- Benfatto, M.N.; Seimyr, G.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for dyslexia using eye tracking during reading. PLoS ONE 2016, 11, e0165508. [Google Scholar]
- Vajs, I.; Kovic, V.; Papic, T.; Savic, A.M.; Jankovic, M.M. Dyslexia detection in children using eye tracking data based on VGG16 network. In Proceedings of the European Signal Processing Conference, Belgrade, Serbia, 29 August–2 September 2022; pp. 1601–1605. [Google Scholar]
- Ileri, R.; Latifoğlu, F.; Demirci, E. A novel approach for detection of dyslexia using convolutional neural network with EOG signals. Med. Biol. Eng. Comput. 2022, 60, 3041–3055. [Google Scholar] [CrossRef]
- Xing, L.; Qiao, Y. DeepWriter: A multi-stream deep CNN for text-independent writer identification. In Proceedings of the International Conference on Frontiers in Handwriting Recognition, ICFHR, Shenzhen, China, 23–26 October 2016; pp. 584–589. [Google Scholar] [CrossRef]
- Dara, S.; Tumma, P. Feature Extraction By Using Deep Learning: A survey. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 1795–1801. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks; Springer: Cham, The Netherlands, 2020; Volume 53. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Articles released between 2010 and 2022 in English (AND) | Articles not relevant to dyslexia classification (AND) |
| Articles that utilized DL methods (OR) DL methods combined with traditional ML for the identification of dyslexia | Articles that used only traditional ML methods to prediction dyslexia (AND) |
| (AND) Articles that utilized datasets related to dyslexia | Articles that did not meet the inclusion criteria |
| Reference | Dataset | Feature Extraction Method and Selected Features |
|---|---|---|
| [30] | Test score | The study extracted features manually based on cognitive and evaluation test results. These included an IQ test, rapid naming test, evaluation of short-term memory, sequencing skills, and non-word reading to evaluate phonological coding skills. |
| [32] | EGG | Using a kernel density estimation process, brain activity features were extracted from EGG signals (353 features). The ksdensity () function in MATLAB was used to derive features depending on the normal kernel function. |
| [35] | To extract features from the EGG signals, the study used SSA, which divides the raw signal into additive components representing various oscillatory manners. Five components were generated that might be utilized to explain the data. For each component, Pearson’s correlation among various channels of the PSD of each singular SSA component was calculated. Pearson’s correlation represents the degree of similarity between two channels, thus helping to differentiate between dyslexia and normal functioning. | |
| [33] | Brain electrical signal features were extracted from EGG signals utilizing Fourier transform algorithms and statistical functions. The algorithms used the rule-based model to filter non-related features and eliminate noise from the electrical signal records. | |
| [34] | The study used discrete wavelet transform techniques to extract the most beneficial ERP signals from EGG, which have a waveform linked both in frequency and time domain. The signal was divided into low pass and high pass. A group of temporal features were extracted from the low-pass portion such as latency, absolute amplitude, positive area, and entropy, while a group of statistical and spectral features were extracted from the high-pass portion such as mean, skewness ratios, standard deviation, and zero crossing rate. Moreover, some features relevant to the frequencies’ structure were extracted such as spectral flatness measure, spectral centroid as well as power spectral density. | |
| [41] | Eye Tracking | The various eye movement events for preprocessed data have been analyzed, such as saccades and fixations. Different features relevant to these events have been extracted using major statistical measures, dispersion, and approaches velocity-based. Two algorithms for feature selection have been used in this study, which are Recursive feature Elimination with Cross-Validation (RFE-CV) and PCA. |
| [40] | In this study, the CNN model extracted, implicitly, substantial features scattered either in time or frequency from preprocessed eye-tracking data and nonlinearly bound them using machine learning to minimize detection error. | |
| [43] | The velocity features which extracted from eye-tracking events discriminate between dyslexic and control. | |
| [44] | EOG | The study used a 1D CNN model that generated feature maps through operations in layers. These feature maps contained significant features from the vertical and horizontal EOG signals, allowing the differentiation of dyslexic and normal readers. |
| [12] | MRI and fMRI | Features of the phonological and cognitive brain systems related to gray matter, white matter, and cerebrospinal fluid were extracted from fMRI utilizing CAT12 implemented in MATLAB. |
| [38] | The study used FDT, BET, and TBSS to extract FA from DTS signals, and used two tools (BET and FEAT) to elicit features from fMRI. These two features (activation pattern and FA) are associated with speech, language, and lexical decisions. | |
| [37] | After preprocessing fMRI dataset, SMP12 has been implemented in MATLAP 2018b to extract cognitive features pertaining to grey and white matter and the volumetric biomarkers of cerebrospinal tissues. | |
| [39] | This study was considered unique due to its visualization of features, which differentiated dyslexic readers from normal ones, such as activation patterns of anterior right-hemisphere prefrontal areas as well as activation patterns in the left occipital and inferior parietal areas that distinguished groups based on brain networks related to lexical and phonological processes in reading. The feature extraction has been carried out in the layers of the LeNet-5 model. | |
| [25,26] | Handwriting | These studies used behavioral and cognitive biomarkers (picture patches of handwriting features) to differentiate between dyslexic and normal readers. A CNN model extracted high features from processed handwriting images when implemented in Python. |
| [28] | Hindi words have some prodigious features, such as diacritics (matras), conjoined consonants, and killer strokes (halants). The study used patches of handwriting features to differentiate between dyslexics and normal readers, which have been extracted in the CNN model | |
| [27] | The study used an OCR technology to identify letters in handwriting images. The rectified characters are displayed in the command box after picture extraction and character recognition, manually the total of correct detection was been calculated. | |
| [4,29] | These studies used a CNN model to extract features and predict dyslexia from handwriting images. The preprocessed handwriting images were fed to the CNN model, and a feature map was created through the convolution layer, which contained highly informative features. |
| Reference | Datasets | DL Model | No. of Subjects | Performance |
|---|---|---|---|---|
| [30] | Test score | ANN | Not mentioned | Accuracy: 75% |
| [32] | EGG | MLP | N = 6 kids Normal = 3 Dyslexics = 3 | Accuracy: 86% for eye opened and 85% for eye closed. |
| [38] | fMRI and DTI | ANN | N = 56 kids aged (9–12 years) | Accuracy: 94.8%, Sensitivity: 94.7%, Specificity: 95% |
| [33] | EGG scan | ANN | N = 80 kids (7 to 13 ages) | Accuracy: 89.9% |
| [34] | EGG | ANN | N = 32 Normal = 15 Dyslexics = 17 | Accuracy: 78% |
| [25] | Handwriting image | CNN | N = 88 Normal = 62 Dyslexics = 11 | Accuracy: 55.7% |
| [26] | Handwriting image | CNN | N = 100 | Accuracy: 77.6% |
| [27] | Handwriting image | ANN/MLP | N = 30 | Accuracy: 73.33% |
| [12] | MRI | CNN | N = 45 | Accuracy: 73.2% |
| [37] | fMRI | 3D CNN | N = 66 children (9 and 12 years) | Accuracy: 72.7%, F1 score: 67%, Sensitivity: 75.0%, Specificity: 71.4%, Precision: 60%% |
| [28] | Handwriting image | CNN | N = 54 children (267 samples) | Accuracy: 86.14 ± 1.02% |
| [35] | EEG | CNN | N = 48 32 skilled readers 16 dyslexic readers | The study did not mention the accuracy but stated the effectiveness of CNN for eliciting informative features to diagnose dyslexia. |
| [4] | Handwriting image | CNN | Normal = 78,275 letters Dyslexic = 52,196 letters | Accuracy of CNN1: 86% Accuracy of CNN2: 87% Accuracy of CNN3: 86.5% Accuracy of LeNet-5: 86% |
| [29] | Handwriting image | CNN | Accuracy: 95.34% | |
| [40] | Eye tracking | CNN | N = 185 88 low risks 97 high risks | Accuracy: 96.6% |
| [39] | fMRI | CNN | N = 32 children 16 typical readers 16 dyslexic readers | Accuracy: 94.8% |
| [41] | Eye tracking | CNN | N = 185 97 dyslexics 88 non-dyslexics | Accuracy of CNN: 87% |
| [43] | Eye tracking | CNN (VGG 16) | N = 30 15 dyslexics 15 normal | Accuracy: 87% |
| [44] | EOG | CNN | N = 33 20 dyslexics 13 normal | Accuracy for horizontal channel EOG signals: 98.70% Accuracy for vertical channel EOG signals: 80.94% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alqahtani, N.D.; Alzahrani, B.; Ramzan, M.S. Deep Learning Applications for Dyslexia Prediction. Appl. Sci. 2023, 13, 2804. https://doi.org/10.3390/app13052804
Alqahtani ND, Alzahrani B, Ramzan MS. Deep Learning Applications for Dyslexia Prediction. Applied Sciences. 2023; 13(5):2804. https://doi.org/10.3390/app13052804
Chicago/Turabian StyleAlqahtani, Norah Dhafer, Bander Alzahrani, and Muhammad Sher Ramzan. 2023. "Deep Learning Applications for Dyslexia Prediction" Applied Sciences 13, no. 5: 2804. https://doi.org/10.3390/app13052804
APA StyleAlqahtani, N. D., Alzahrani, B., & Ramzan, M. S. (2023). Deep Learning Applications for Dyslexia Prediction. Applied Sciences, 13(5), 2804. https://doi.org/10.3390/app13052804