

Multi-View Surgical Camera Calibration with None-Feature-Rich Video Frames: Toward 3D Surgery Playback

 , , and
, , and 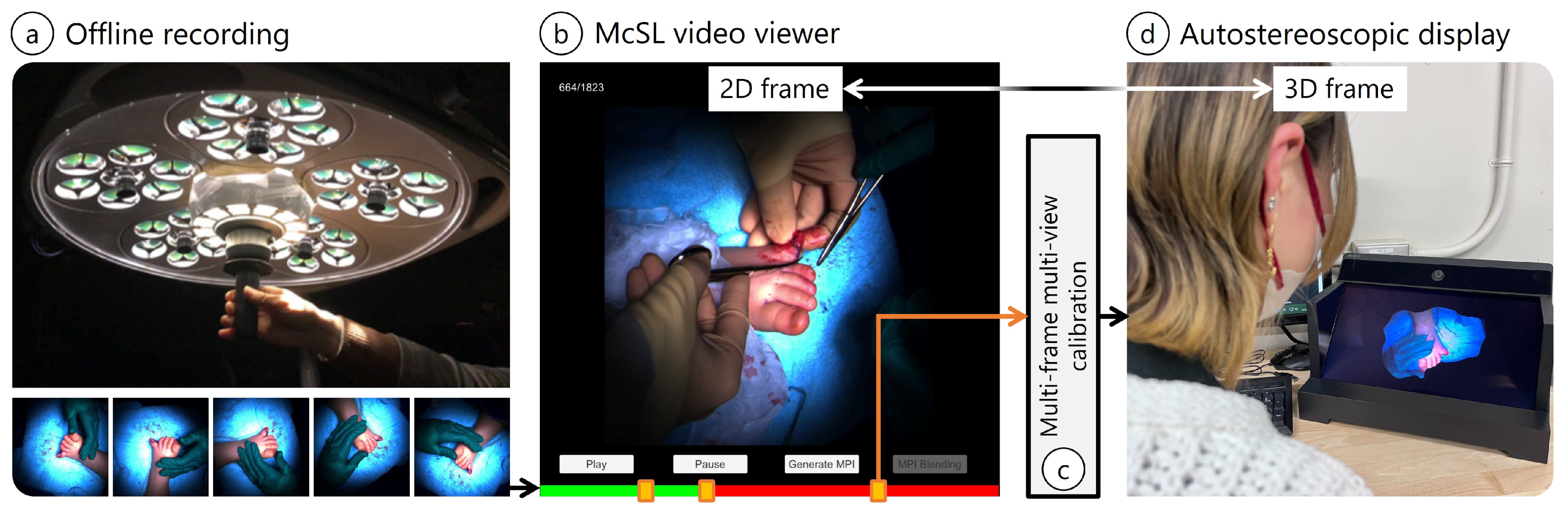{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivation
1.2. Background and Related Work
1.3. Contributions
- We propose a video player that allows the user to selectively convert a portion of a long-shot McSL video into free viewpoint images to minimize time and data until playbacks.
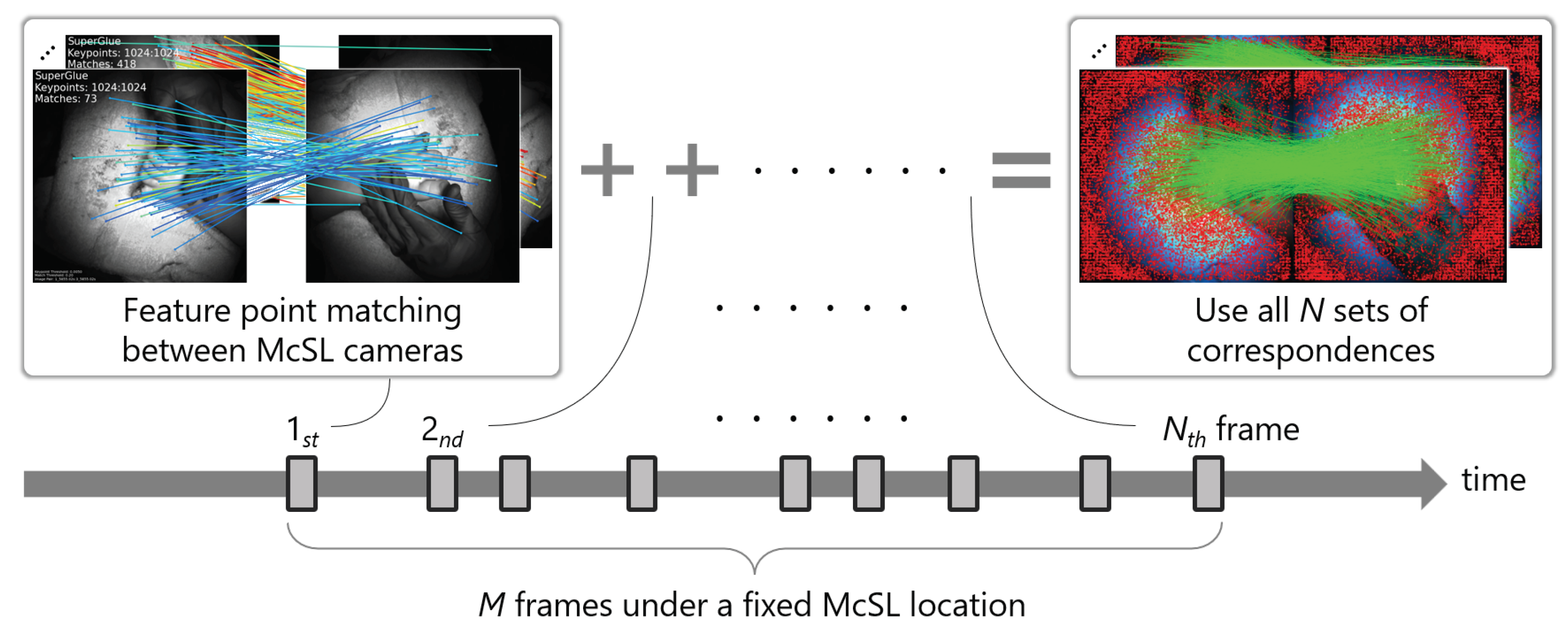
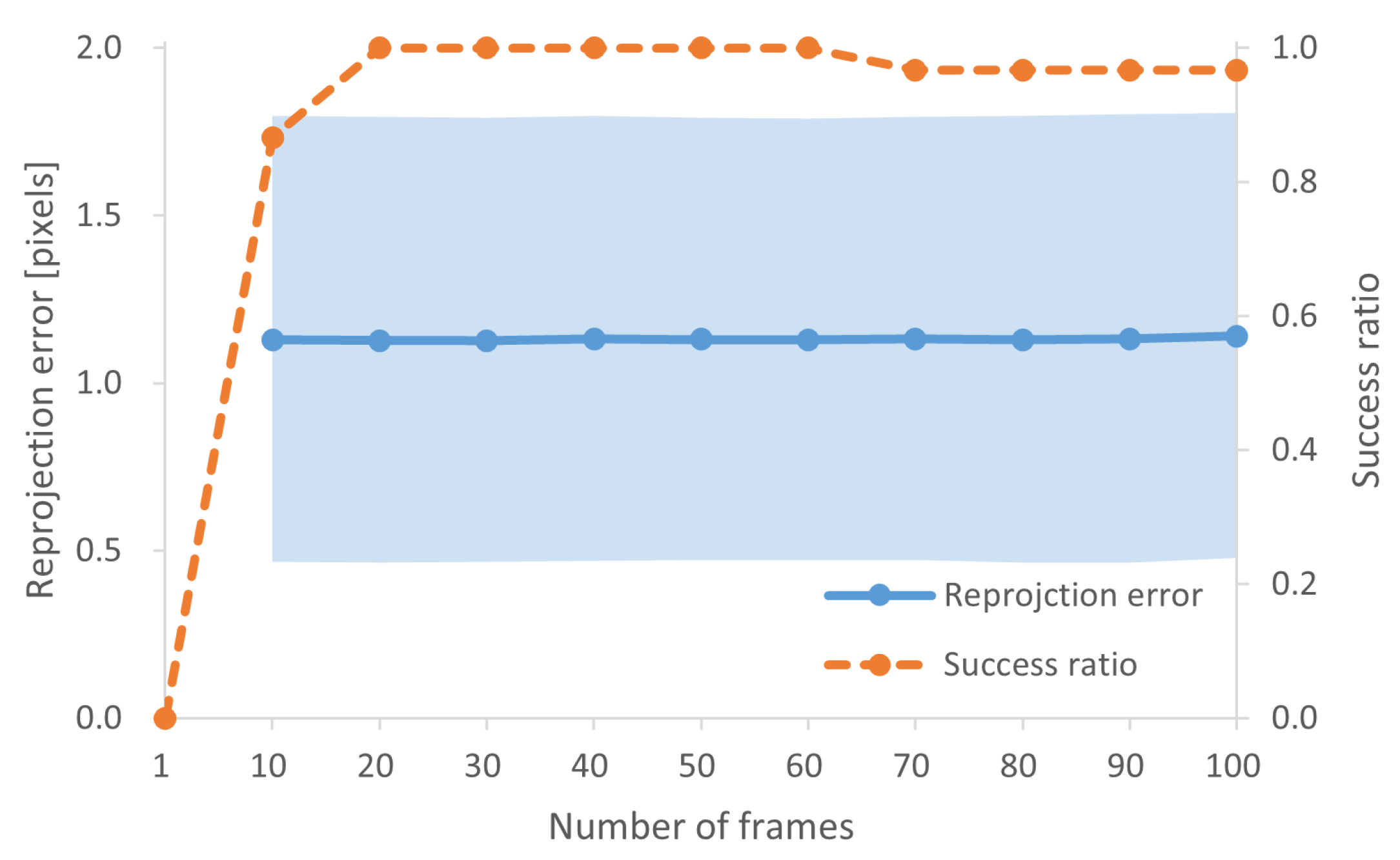
- We propose a multi-frame multi-view feature matching strategy to estimate intrinsic and extrinsic camera parameters from a set of McSL video frames. This process is always required after the independent movement of internal cameras (e.g., when surgeons touch the surgical light during the operation). We also analyze the number of frames to achieve stable calibration results using real surgical videos.
- With the robustly estimated camera parameters, we demonstrate a 3D mesh and a recently emerged 3D multi-layer reconstruction. The latter enables disocclusion rendering to remove foregrounds in the generated 3D scene representation for better surgical field visibility.
- We reviewed comments from surgeons to discuss the differences between those 3D representations with respect to medical usage.
2. Materials and Methods
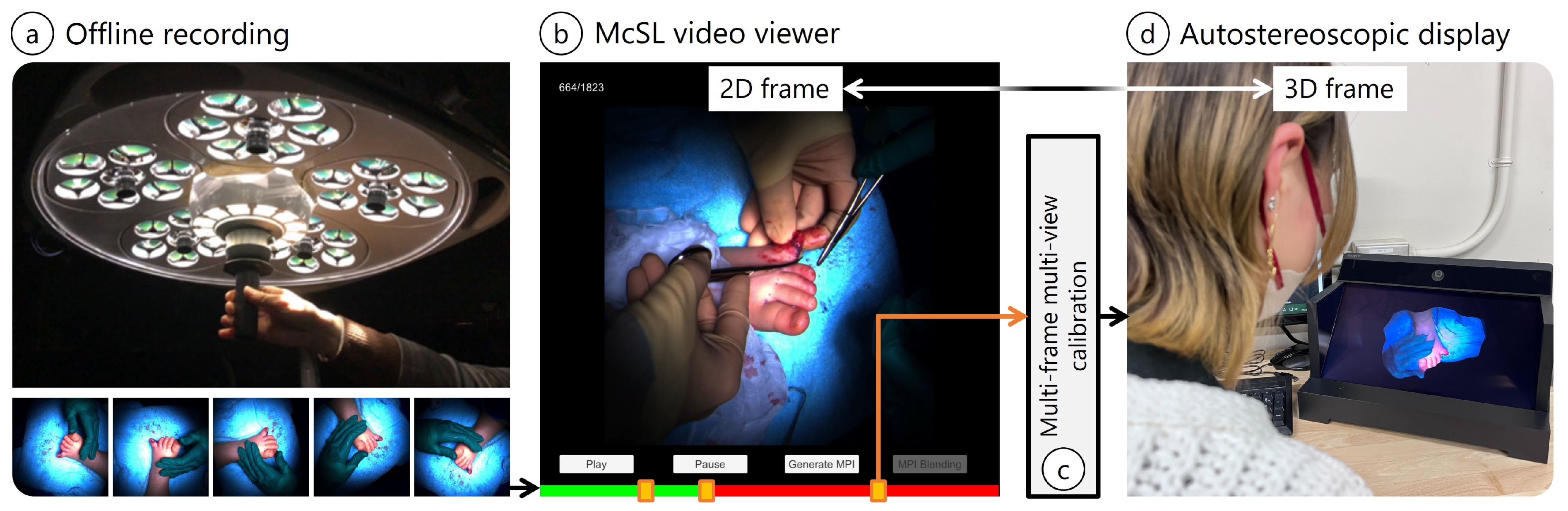
- On-site McSL video recording: We record a surgery case with a McSL (Figure 1a). At this point, no additional effort is required (e.g., no calibration pattern recording is necessary).
- Playback with our McSL video player: The user (e.g., medical trainees) plays the video and selects a frame to be reconstructed in 3D (Figure 1b, Section 2.3).
- McSL calibration: Upon frame selection, we run our calibration algorithm to calculate the cameras’ intrinsic and extrinsic parameters (Figure 1c, Section 2.1).
- View synthesis: The 3D frame data are generated and saved (Section 2.2), and the selected frame is highlighted in the player. Therefore, the user can switch between the 2D and 3D viewers. We provide ways to avoid occlusions in surgical fields. Given that the frame is in 3D representation, we can display the frame on an autostereoscopic display (Figure 1d).
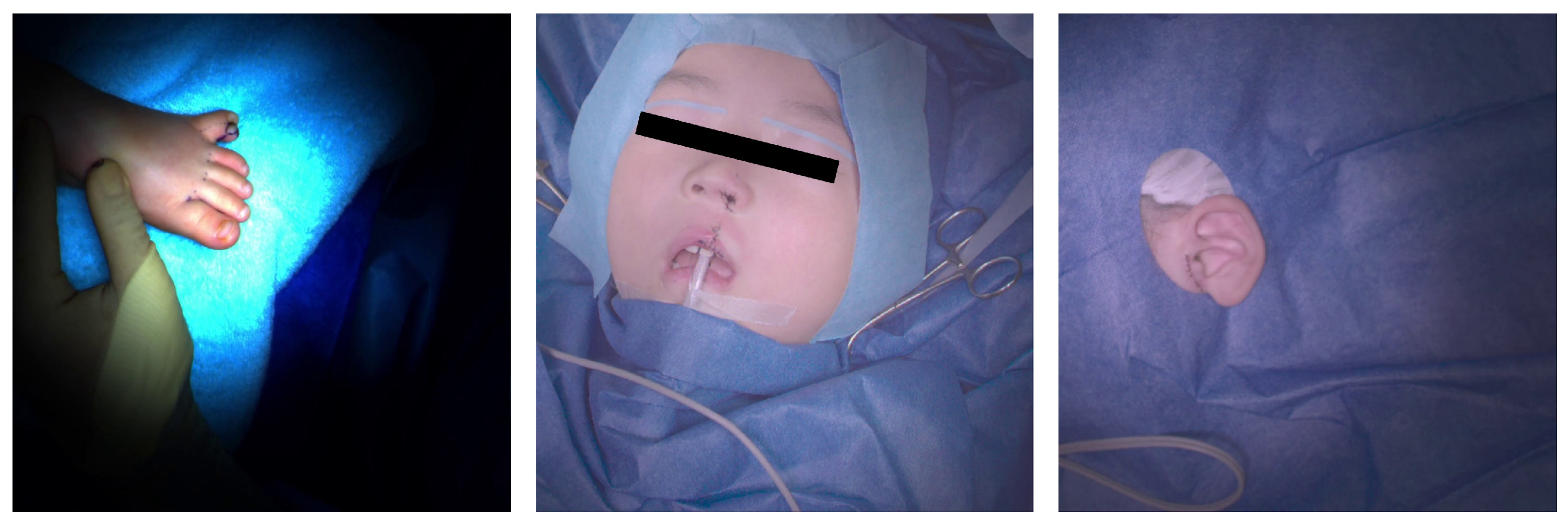
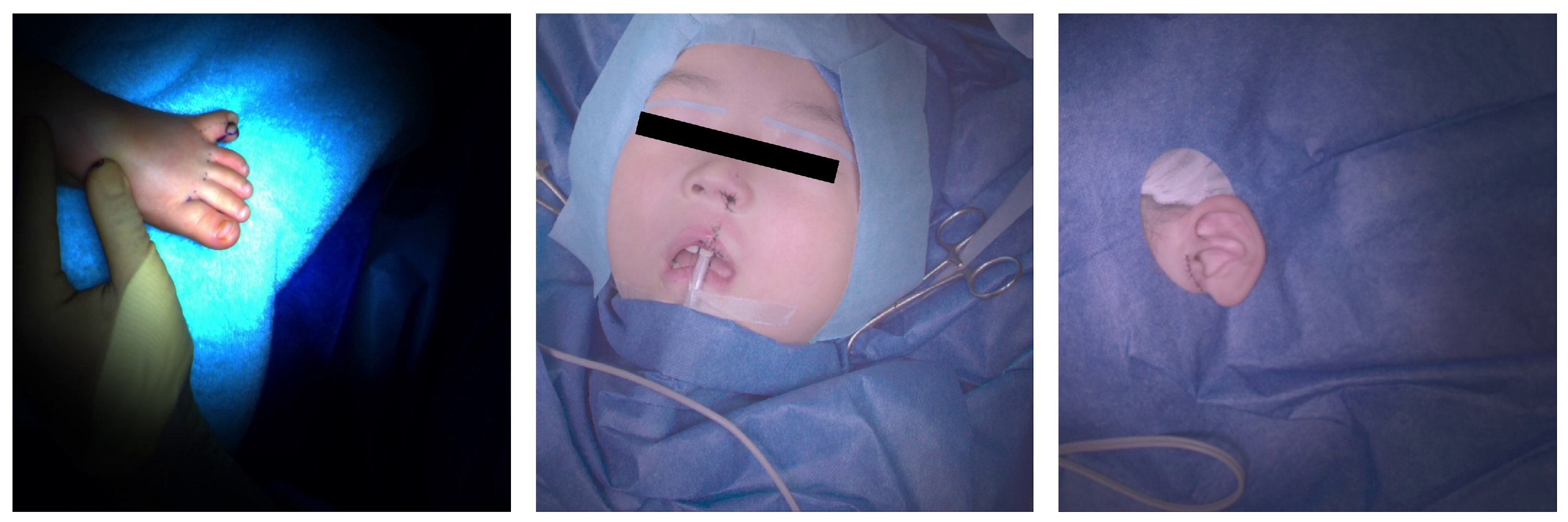
- The one used to capture the polysyndactyly surgery and the cleft lip surgery: stand-alone shadowless lamp (DAI-ICHI SHOMEI CO., LTD., LEDXII 5S) + camera (LUCID Vision Labs, PHX032S-CC) × 5 units;
- The one used to capture the cleft lip surgery and the accessory auricle surgery: stand-alone shadowless lamp (DAI-ICHI SHOMEI CO., LTD., LEDXIV 5S) + HDR camera (LUCID Vision Labs, TritonHDR) × 5 units.
2.1. Calibration with a McSL Video
2.2. Three-Dimensional Frame Generation
2.3. McSL Video Player
3. Results
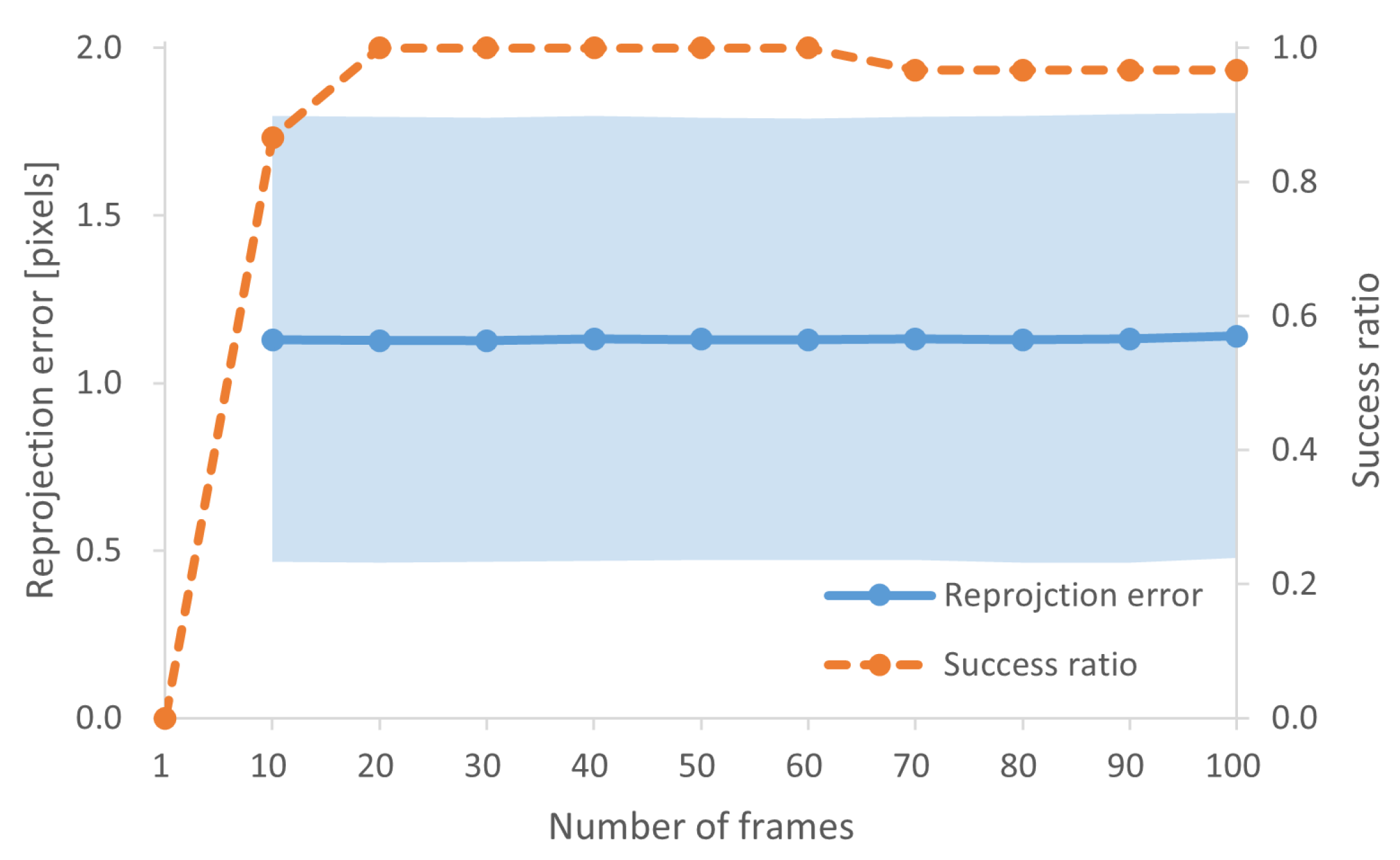
3.1. McSL Calibration Accuracy
3.2. Three-Dimensional Mesh Rendering
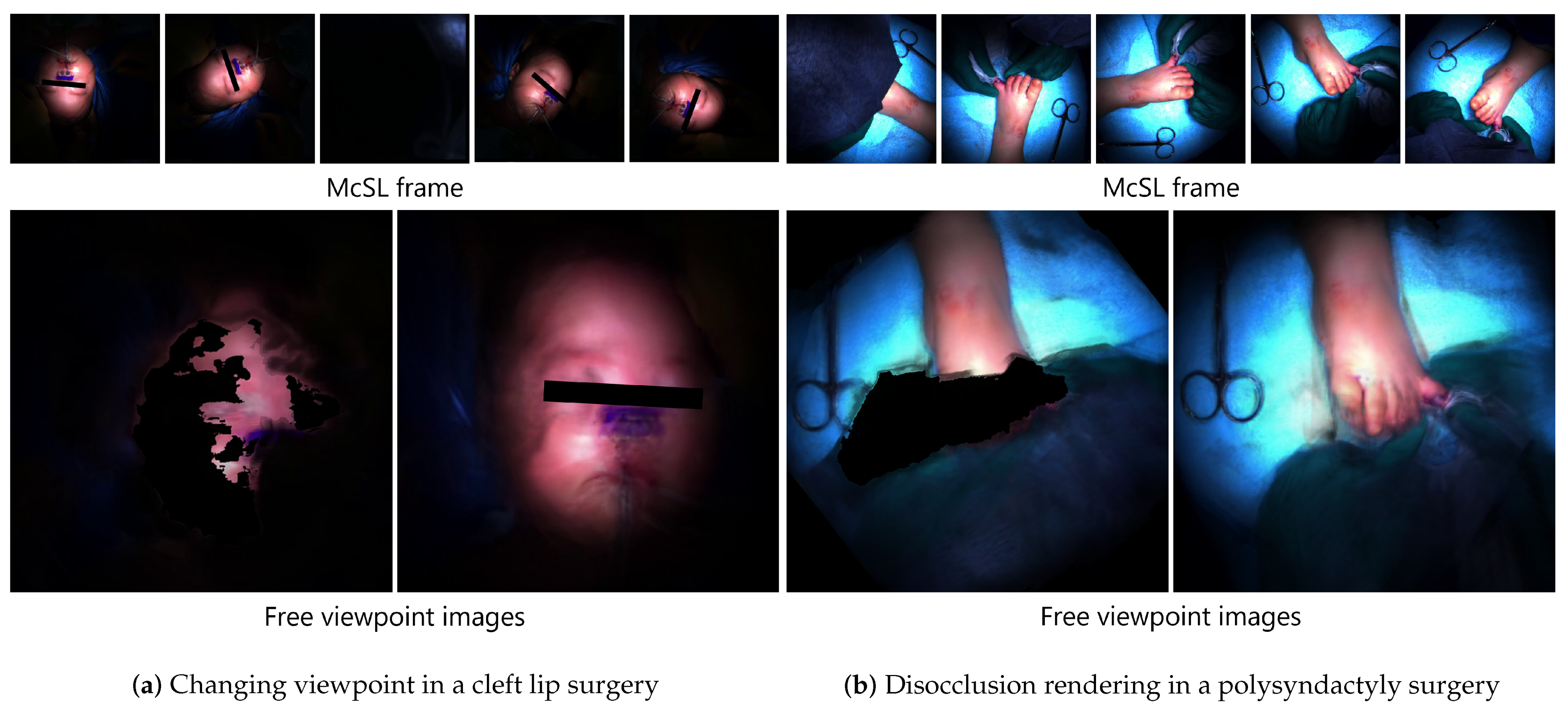
3.3. Occlusion-Free View Synthesis Using MPI
3.4. Experts’ Comments
- (P1) Very close impression to what we see in actual surgeries regarding appearance and shape;
- (N1) The blind spots on the sides are sharply vertical, unlike the actual shape;
- (N2) The scale should be adjusted.
- (P1) Feeling of being there, however, worse than 3D mesh;
- (P2) Interesting to see “images” in 3D;
- (N1) Blurry and unclear;
- (N2) Only rough shapes can be grasped;
- (N3) Planes are obvious from a steep angle (i.e., stack-of-cards artifacts);
- (N4) The scale should be adjusted.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| McSL | Multi-camera shadowless lamp |
| SfM | Structure from motion |
| LLFF | Local light field fusion |
| MPI | Multi-plane image |
| SRD | Spatial reality display |
References
- Shimizu, T.; Oishi, K.; Hachiuma, R.; Kajita, H.; Saito, H.; Takatsume, Y. Surgery recording without occlusions by multi-view surgical videos. In Proceedings of the International Conference on Computer Vision Theory and Applications, Valletta, Malta, 27–29 February 2020. [Google Scholar]
- Matsumoto, S.; Sekine, K.; Yamazaki, M.; Funabiki, T.; Orita, T.; Shimizu, M.; Kitano, M. Digital video recording in trauma surgery using commercially available equipment. Scand. J. Trauma Resusc. Emerg. Med. 2013, 21, 27. [Google Scholar] [CrossRef] [PubMed]
- Sadri, A.; Hunt, D.; Rhobaye, S.; Juma, A. Video recording of surgery to improve training in plastic surgery. J. Plast. Reconstr. Aesthet. Surg. 2013, 66, e122–e123. [Google Scholar] [CrossRef]
- Hachiuma, R.; Shimizu, T.; Saito, H.; Kajita, H.; Takatsume, Y. Deep selection: A fully supervised camera selection network for surgery recordings. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Lima, Peru, 4–8 October 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 419–428. [Google Scholar]
- Hu, M.; Penney, G.; Figl, M.; Edwards, P.; Bello, F.; Casula, R.; Rueckert, D.; Hawkes, D. Reconstruction of a 3D surface from video that is robust to missing data and outliers: Application to minimally invasive surgery using stereo and mono endoscopes. Med. Image Anal. 2012, 16, 597–611. [Google Scholar] [CrossRef] [PubMed]
- Cano González, A.M.; Sánchez-González, P.; Sánchez-Margallo, F.M.; Oropesa, I.; del Pozo, F.; Gómez, E.J. Video-endoscopic image analysis for 3D reconstruction of the surgical scene. In Proceedings of the International Federation for Medical and Biological Engineering (IFMBE), Miami, FL, USA, 15–17 May 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 923–926. [Google Scholar]
- Murala, J.S.K.; Singappuli, K.; Swain, S.K.; Nunn, G.R. Digital video recording of congenital heart operations with “surgical eye”. Ann. Thorac. Surg. 2010, 90, 1377–1378. [Google Scholar] [CrossRef] [PubMed]
- Nair, A.G.; Kamal, S.; Dave, T.V.; Mishra, K.; Reddy, H.S.; Della Rocca, D.; Della Rocca, R.C.; Andron, A.; Jain, V. Surgeon point-of-view recording: Using a high-definition head-mounted video camera in the operating room. Indian J. Ophthalmol. 2015, 63, 771–774. [Google Scholar] [CrossRef] [PubMed]
- Graves, S.N.; Shenaq, D.S.; Langerman, A.J.; Song, D.H. Video capture of plastic surgery procedures using the GoPro HERO 3+. Plast. Reconstr. Surg. Glob. Open 2015, 3, e312. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.S.; Pal, H. Digital video recording of cardiac surgical procedures. Ann. Thorac. Surg. 2004, 77, 1063–1065; discussion 1065. [Google Scholar] [CrossRef]
- Byrd, R.J.; Ujjin, V.M.; Kongchan, S.S.; Reed, H.D. Surgical Lighting System with Integrated Digital Video Camera. U.S. Patent 6,633,328, 14 October 2003. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 405–421. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (TOG) 2022, 41, 102:1–102:15. [Google Scholar] [CrossRef]
- Tretschk, E.; Tewari, A.; Golyanik, V.; Zollhöfer, M.; Lassner, C.; Theobalt, C. Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 12959–12970. [Google Scholar]
- Li, Z.; Niklaus, S.; Snavely, N.; Wang, O. Neural scene flow fields for space-time view synthesis of dynamic scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6498–6508. [Google Scholar]
- Zhang, J.; Liu, X.; Ye, X.; Zhao, F.; Zhang, Y.; Wu, M.; Zhang, Y.; Xu, L.; Yu, J. Editable free-viewpoint video using a layered neural representation. ACM Trans. Graph. (TOG) 2021, 40, 1–18. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Z.; Lin, P.; Jiang, Y.; Suo, X.; Wu, M.; Xu, L.; Yu, J. IButter: Neural interactive bullet time generator for human free-viewpoint rendering. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021. [Google Scholar]
- Broxton, M.; Flynn, J.; Overbeck, R.; Erickson, D.; Hedman, P.; Duvall, M.; Dourgarian, J.; Busch, J.; Whalen, M.; Debevec, P. Immersive light field video with a layered mesh representation. ACM Trans. Graph. (TOG) 2020, 39, 86:1–86:15. [Google Scholar] [CrossRef]
- DuVall, M.; Flynn, J.; Broxton, M.; Debevec, P. Compositing light field video using multiplane images. In Proceedings of the 12th ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia, Los Angeles, CA, USA, 28 July–1 August 2019. [Google Scholar]
- Mori, S.; Ikeda, S.; Saito, H. A survey of diminished reality: Techniques for visually concealing, eliminating, and seeing through real objects. IPSJ Trans. Comput. Vis. Appl. (CVA) 2017, 9. [Google Scholar] [CrossRef]
- Barnum, P.; Sheikh, Y.; Datta, A.; Kanade, T. Dynamic seethroughs: Synthesizing hidden views of moving objects. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Orlando, FL, USA, 19–22 October 2009; pp. 111–114. [Google Scholar]
- Meerits, S.; Saito, H. Real-time diminished reality for dynamic scenes. In Proceedings of the International Symposium on Mixed and Augmented Reality Workshop (ISMAR-Workshop), Fukuoka, Japan, 29 September–3 October 2015; pp. 53–59. [Google Scholar]
- Ienaga, N.; Bork, F.; Meerits, S.; Mori, S.; Fallavollita, P.; Navab, N.; Saito, H. First deployment of diminished reality for anatomy education. In Proceedings of the International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Merida, Mexico, 19–23 September 2016; pp. 294–296. [Google Scholar]
- Kawai, N.; Sato, T.; Yokoya, N. Diminished Reality Based on Image Inpainting Considering Background Geometry. IEEE Trans. Vis. Comput. Graph. (TVCG) 2016, 22, 1236–1247. [Google Scholar] [CrossRef] [PubMed]
- Mori, S.; Herling, J.; Broll, W.; Kawai, N.; Saito, H.; Schmalstieg, D.; Kalkofen, D. 3d pixmix: Image inpainting in 3d environments. In Proceedings of the International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Bari, Italy, 4–8 October 2021; pp. 1–2. [Google Scholar]
- Mori, S.; Erat, O.; Broll, W.; Saito, H.; Schmalstieg, D.; Kalkofen, D. InpaintFusion: Incremental RGB-D inpainting for 3D scenes. IEEE Trans. Vis. Comput. Graph. (TVCG) 2020, 26, 2994–3007. [Google Scholar] [CrossRef] [PubMed]
- Cernea, D. OpenMVS: Multi-View Stereo Reconstruction Library. 2020. Available online: https://cdcseacave.github.io/openMVS (accessed on 19 January 2023).
- Penner, E.; Zhang, L. Soft 3D reconstruction for view synthesis. ACM Trans. Graph. (TOG) 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Ortiz-Cayon, R.; Kalantari, N.K.; Ramamoorthi, R.; Ng, R.; Kar, A. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (TOG) 2019, 38, 1–14. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-supervised interest point detection and description. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning feature matching with graph neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Schönberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9907, pp. 501–518. [Google Scholar]
- Flynn, J.; Broxton, M.; Debevec, P.; DuVall, M.; Fyffe, G.; Overbeck, R.; Snavely, N.; Tucker, R. Deepview: View synthesis with learned gradient descent. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2367–2376. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Sony Corporation. SPATIAL REALITY DISPLAY|White Paper. 2022. Available online: https://www.sony.net/Products/Developer-Spatial-Reality-display/en/develop/WhitePaper.html (accessed on 19 January 2023).



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Obayashi, M.; Mori, S.; Saito, H.; Kajita, H.; Takatsume, Y. Multi-View Surgical Camera Calibration with None-Feature-Rich Video Frames: Toward 3D Surgery Playback. Appl. Sci. 2023, 13, 2447. https://doi.org/10.3390/app13042447
Obayashi M, Mori S, Saito H, Kajita H, Takatsume Y. Multi-View Surgical Camera Calibration with None-Feature-Rich Video Frames: Toward 3D Surgery Playback. Applied Sciences. 2023; 13(4):2447. https://doi.org/10.3390/app13042447
Chicago/Turabian StyleObayashi, Mizuki, Shohei Mori, Hideo Saito, Hiroki Kajita, and Yoshifumi Takatsume. 2023. "Multi-View Surgical Camera Calibration with None-Feature-Rich Video Frames: Toward 3D Surgery Playback" Applied Sciences 13, no. 4: 2447. https://doi.org/10.3390/app13042447
APA StyleObayashi, M., Mori, S., Saito, H., Kajita, H., & Takatsume, Y. (2023). Multi-View Surgical Camera Calibration with None-Feature-Rich Video Frames: Toward 3D Surgery Playback. Applied Sciences, 13(4), 2447. https://doi.org/10.3390/app13042447