
Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph



Abstract
:1. Introduction
- We propose a novel course recommendation method based on heterogeneous graph embedding, and our experiments prove that the performance of this method is better than existing methods.
- We propose a novel solution for enhancing the embedding of the meta-path in HG.
- Extensive experiments on four real-world datasets demonstrate the effectiveness of the proposed approach. In addition, we show that the proposed approach can maintain good performance even in the absence of meta-path data.
2. Related Work
2.1. Course Recommendation System
2.2. Heterogeneous Information Network Embedding-Based Recommendation
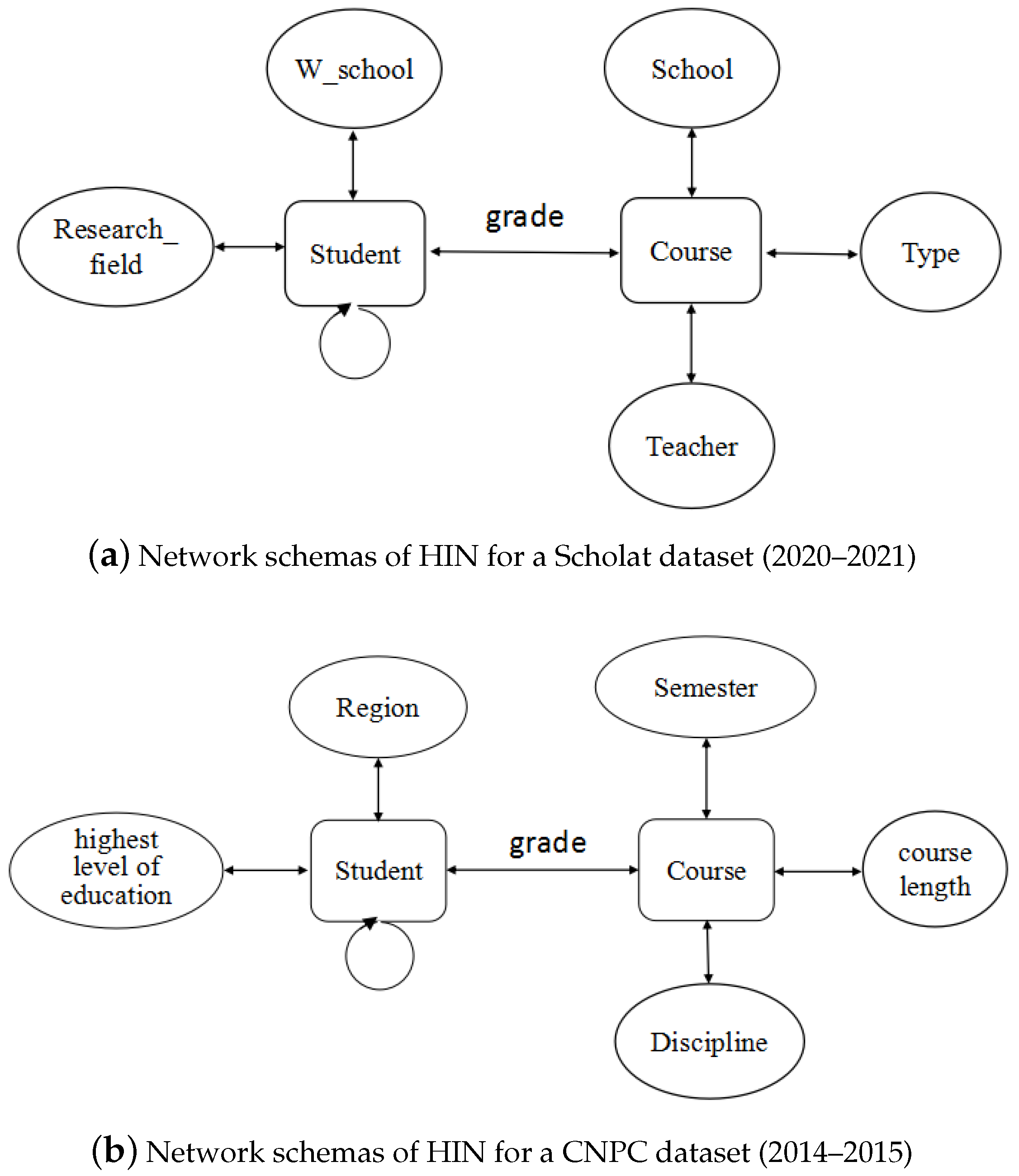
3. Preliminary
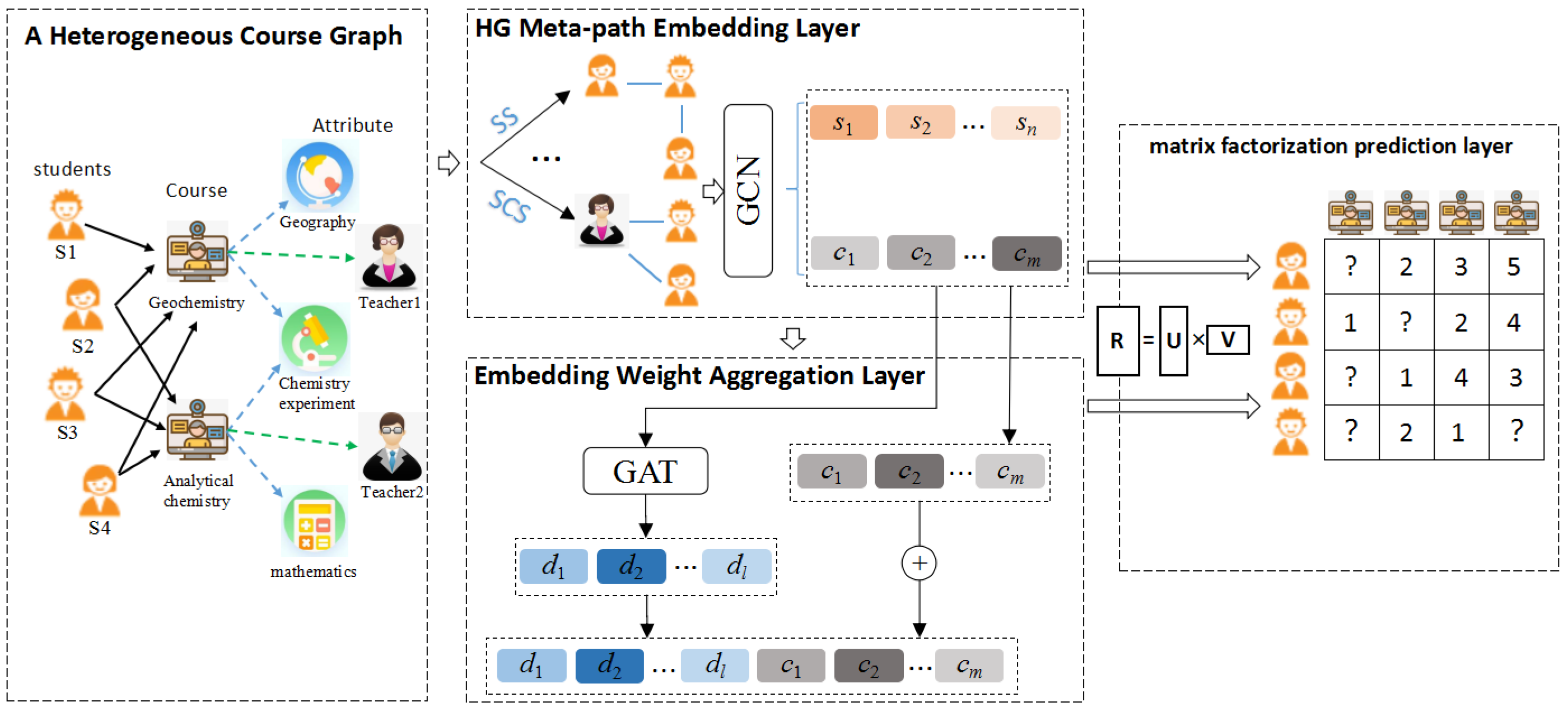
4. Proposed Approach for Course Recommendation
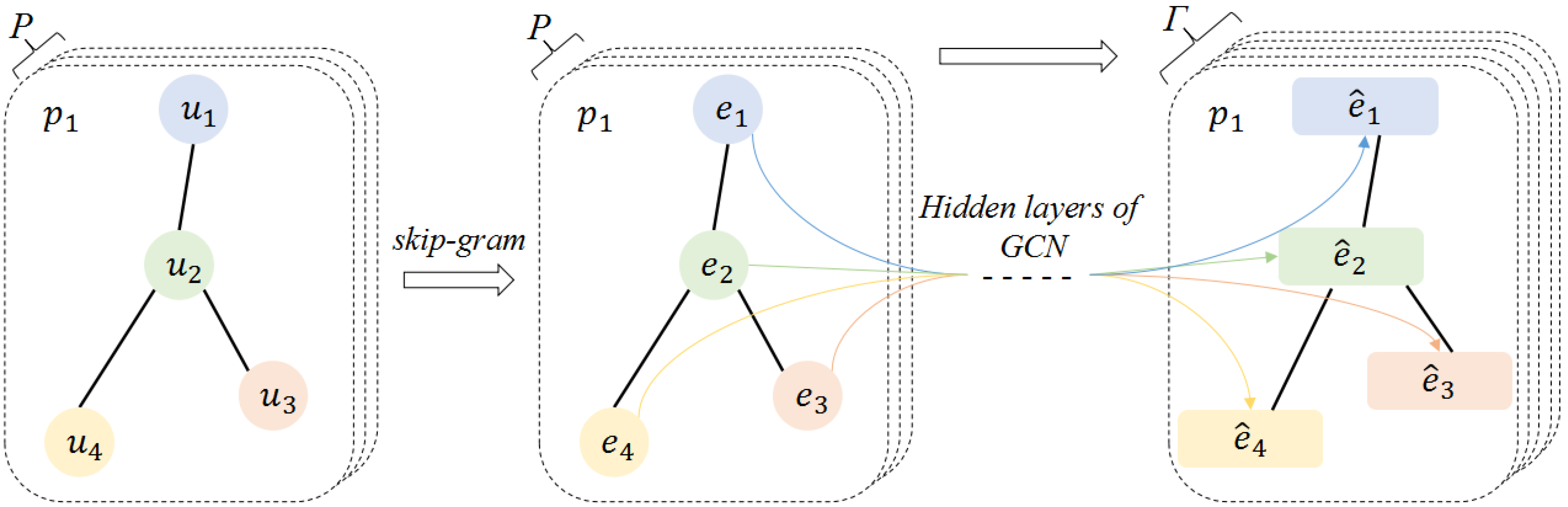
4.1. Meta-Path Embedding Layer
4.1.1. Original Meta-Path Embedding
4.1.2. Simulated Meta-Path Embedding
4.2. Embedding Weight Aggregation Layer
4.2.1. Aggregation of Meta-Path Embedding Based on Attention Mechanism
4.2.2. Fusion of Meta-Path Embedding
| Algorithm 1: Algorithm for enhancing meta-path embedding |
| Input: the heterogeneous graph G; the adjacency matrix ; the meta-path sets for users and for items. Output: the enhanced meta-path embedding set of users and items: ,.
|
4.3. Matrix Factorization-Based Prediction Layer
| Algorithm 2: HGE-CRec training algorithm |
Input: the heterogeneous graph G; the adjacency matrix ; the rating matrix ; the adjustable parameters , ; the regularization parameter ; the learning rate coefficients for integrating embedding features; the enhanced meta-path embedding sets for users and for items. Output: , the users and items feature matrices U and V; the weights of users and items HG embedding; the weights of feature interaction matrix and; the parameters in the fusion function of embedding
|
5. Experiments
5.1. Datasets
- ScholatThis dataset is from a real academic social course platform (scholat.com) which provides courses offered by Chinese universities, including undergraduate and graduate courses. The courses involve computer science, economics, pedagogy, and other disciplines. The student profiles include the school, grade, major, courses learned, etc. The dataset used in our experiment contains 3168 courses, 150,563 users, and 1,237,485 course visit records for the 2020–2021 academic year. The frequency of students’ attendance of courses represents information about student interest in the course. In this experiment, we scaled the attendance frequency to an interval.
- CNPC (https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/26147, accessed on 28 September 2022)This dataset consists of the Canvas Network Open Course (canvas.net), which hosts open online courses, including Massive Open Online Courses (MOOCs) that are freely available to participants around the world. The dataset used in our experiments is from January 2014 to September 2015, including 224,914 users and 238 courses as well as various attribute information on users’ social relations, forums, users, and courses. The courses include ten disciplines, e.g., mathematics, statistics, and education.
- Yelp (https://www.yelp.com/dataset/documentation/main, accessed on 30 September 2022)This dataset comes from the largest merchant rating website in the United States, yelp.com. The dataset records user ratings of merchants, the users’ social relationship, and attribute information on users and merchants, including 16,239 users, 14,282 merchants, and 198,397 ratings.
- Movielens (http://files.grouplens.org/datasets/movielens/ml-100k-README.txt, accessed on 30 September 2022)The Movielens dataset is a classic movie recommendation dataset from movielens.org. Movielens-100k was selected for this experiment. This dataset has 943 users, 1682 movies, and 100,000 scores, and contains social relationship and attribute information between users and movies.
5.2. Experimental Setup
5.2.1. Baselines
- PMF [30]: This is a recommended algorithm for classical probability matrix factorization models which decomposes the scoring matrix into two low-dimensional matrices.
- SoMF [31]: In this algorithm, social relations have the characteristics of social regularization items, helping to integrate social relations into basic recommendations in the matrix factorization model.
- HERec [6]: This classical recommendation algorithm based on heterogeneous information network embedding adopts the random walk strategy based on the meta-path to generate the embedding, then integrates the embedded fusion into the matrix factorization model for recommendation.
5.2.2. Evaluation Metrics
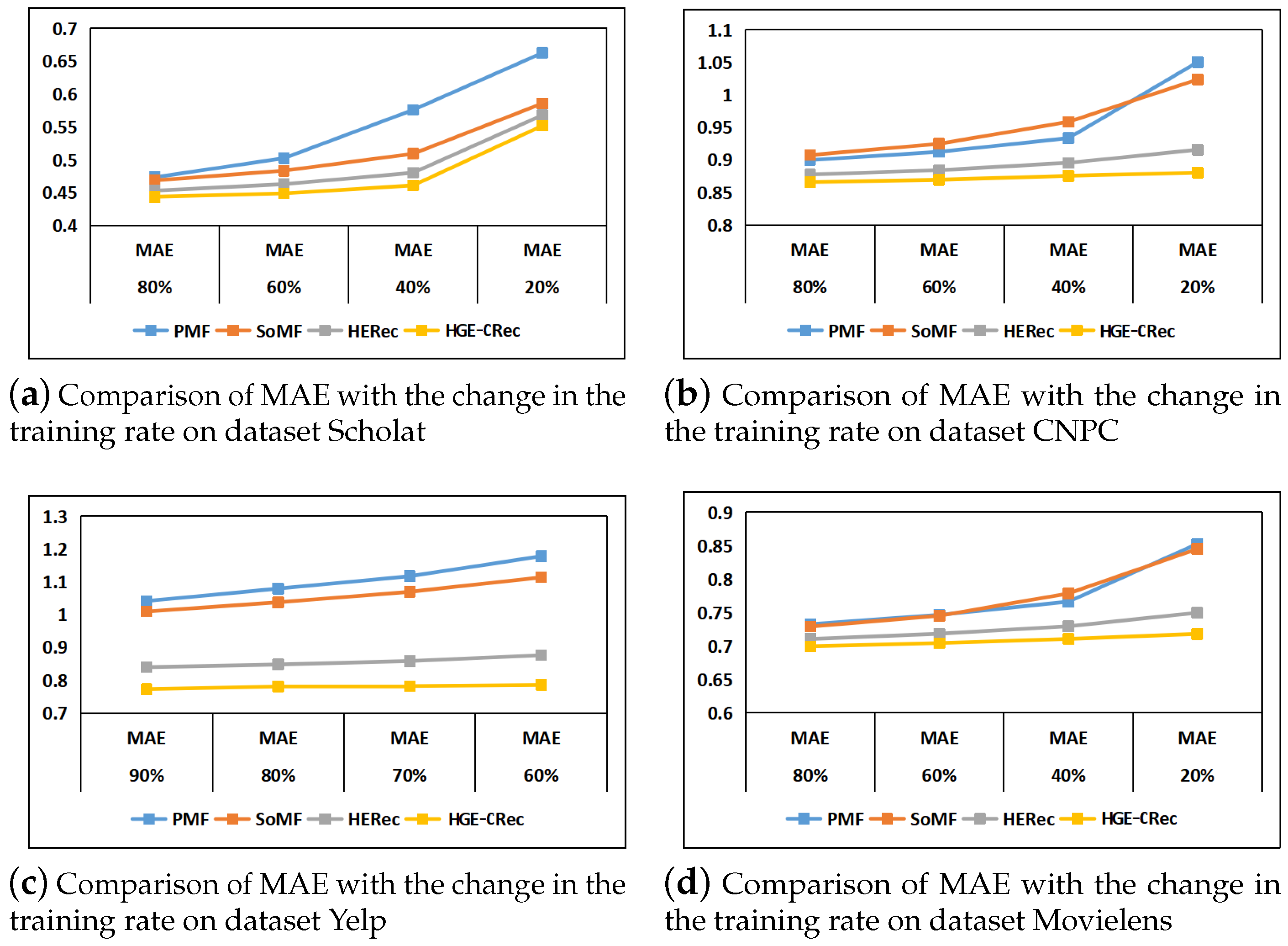
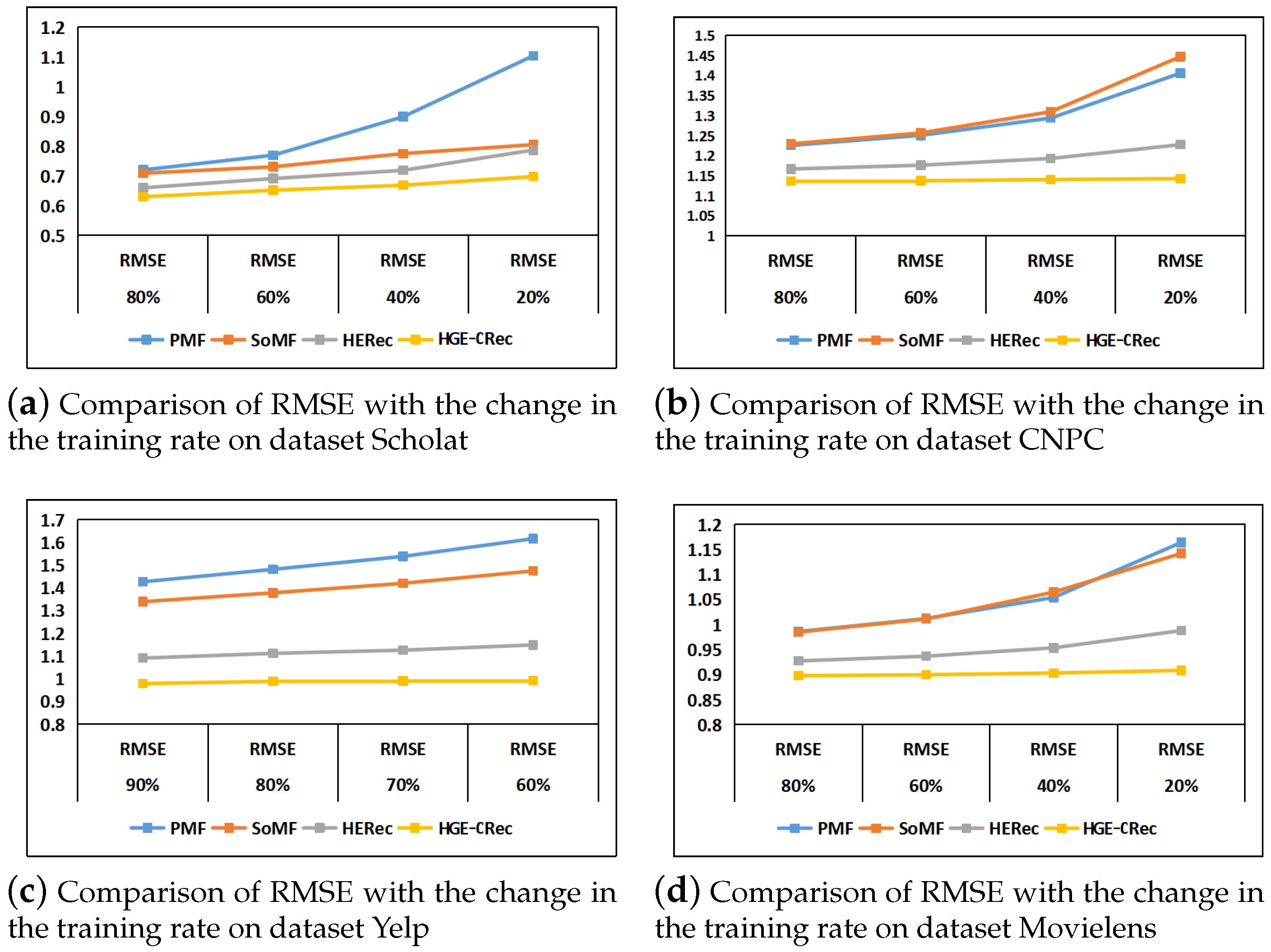
5.3. Results of the Comparative Experiment
5.4. Ablation Study
5.4.1. Component Adjustment
- HGE-CRecOnly the first part of the HGE-CRec model’s meta-path embedding is improved, that is, while GCN is used to generate analog meta-path embedding, GAT is not used to aggregate various kinds of meta-path embedding based on neighbor weight.
- HGE-CRecOnly the second part of the HGE-CRec model’s meta-path embedding is improved, that is, while GAT is used to aggregate the original meta-path embedding based on the neighbor weights, GCN is not used to generate simulated meta-path embeddings.
5.4.2. Meta-Path Embedding Adjustment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Chen, D.; Zhan, Z. Research on personalized recommendation of MOOC resources based on ontology. Interact. Technol. Smart Educ. 2022, 19, 422–440. [Google Scholar] [CrossRef]
- Lin, Y.; Feng, S.; Lin, F.; Zeng, W.; Liu, Y.; Wu, P. Adaptive course recommendation in MOOCs. Knowl. Based Syst. 2021, 224, 107085. [Google Scholar] [CrossRef]
- Tian, X.; Liu, F. Capacity Tracing-Enhanced Course Recommendation in MOOCs. IEEE Trans. Learn. Technol. 2021, 14, 313–321. [Google Scholar] [CrossRef]
- Zhu, Y.; Lu, H.; Qiu, P.; Shi, K.; Chambua, J.; Niu, Z. Heterogeneous teaching evaluation network based offline course recommendation with graph learning and tensor factorization. Neurocomputing 2020, 415, 84–95. [Google Scholar] [CrossRef]
- Wang, C.; Peng, C.; Wang, M.; Yang, R.; Wu, W.; Rui, Q.; Xiong, N.N. CTHGAT: Category-aware and Time-aware Next Point-of-Interest via Heterogeneous Graph Attention Network. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2021, Melbourne, Australia, 17–20 October 2021; pp. 2420–2426. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous Information Network Embedding for Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef]
- Morsomme, R.; Alferez, S.V. Content-based Course Recommender System for Liberal Arts Education. In Proceedings of the 12th International Conference on Educational Data Mining, EDM 2019, Montréal, QC, Canada, 2–5 July 2019. [Google Scholar]
- Chau, H.; Barria-Pineda, J.; Brusilovsky, P. Content Wizard: Concept-Based Recommender System for Instructors of Programming Courses. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, UMAP 2017, Bratislava, Slovakia, 9–12 July 2017; pp. 135–140. [Google Scholar]
- Li, X.; Li, X.; Tang, J.; Wang, T.; Zhang, Y.; Chen, H. Improving Deep Item-Based Collaborative Filtering with Bayesian Personalized Ranking for MOOC Course Recommendation. In Proceedings of the Knowledge Science, Engineering and Management-13th International Conference, KSEM 2020, Hangzhou, China, 28–30 August 2020; Proceedings, Part I. Li, G., Shen, H.T., Yuan, Y., Wang, X., Liu, H., Zhao, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12274, pp. 247–258. [Google Scholar]
- Madani, Y.; Erritali, M.; Bengourram, J.; Sailhan, F. Social Collaborative Filtering Approach for Recommending Courses in an E-learning Platform. In Proceedings of the 10th International Conference on Ambient Systems, Networks and Technologies (ANT 2019)/The 2nd International Conference on Emerging Data and Industry 4.0 (EDI40 2019)/Affiliated Workshops, Leuven, Belgium, 29 April–2 May 2019; Shakshuki, E.M., Yasar, A., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; Volume 151, pp. 1164–1169. [Google Scholar]
- Chang, P.; Lin, C.; Chen, M. A Hybrid Course Recommendation System by Integrating Collaborative Filtering and Artificial Immune Systems. Algorithms 2016, 9, 47. [Google Scholar] [CrossRef]
- Ibrahim, M.E.; Yang, Y.; Ndzi, D.L.; Yang, G.; Al-Maliki, M. Ontology-Based Personalized Course Recommendation Framework. IEEE Access 2019, 7, 5180–5199. [Google Scholar] [CrossRef]
- Huang, C.; Chen, R.; Chen, L. Course-recommendation system based on ontology. In Proceedings of the International Conference on Machine Learning and Cybernetics, ICMLC 2013, Tianjin, China, 14–17 July 2013; pp. 1168–1173. [Google Scholar]
- George, G.; Lal, A.M. Review of ontology-based recommender systems in e-learning. Comput. Educ. 2019, 142, 103642. [Google Scholar] [CrossRef]
- Núñez-Valdéz, E.R.; Lovelle, J.M.C.; Martínez, O.S.; García-Díaz, V.; de Pablos, P.O.; Marín, C.E.M. Implicit feedback techniques on recommender systems applied to electronic books. Comput. Hum. Behav. 2012, 28, 1186–1193. [Google Scholar] [CrossRef]
- Tong, Y.; Zhan, Z. An evaluation model based on procedural behaviors for predicting MOOC learning performance: Students’ online learning behavior analytics and algorithms construction. Interact. Technol. Smart Educ. 2023, 1, 1–22. [Google Scholar] [CrossRef]
- Hew, K.F.; Hu, X.; Qiao, C.; Tang, Y. What predicts student satisfaction with MOOCs: A gradient boosting trees supervised machine learning and sentiment analysis approach. Comput. Educ. 2020, 145, 103724. [Google Scholar] [CrossRef]
- Huang, L.; Wang, C.; Chao, H.; Lai, J.; Yu, P.S. A Score Prediction Approach for Optional Course Recommendation via Cross-User-Domain Collaborative Filtering. IEEE Access 2019, 7, 19550–19563. [Google Scholar] [CrossRef]
- da Silveira Dias, A.; Wives, L.K. Recommender system for learning objects based in the fusion of social signals, interests, and preferences of learner users in ubiquitous e-learning systems. Pers. Ubiquitous Comput. 2019, 23, 249–268. [Google Scholar] [CrossRef]
- Dahdouh, K.; Oughdir, L.; Dakkak, A.; Ibriz, A. Smart Courses Recommender System for Online Learning Platform. In Proceedings of the 5th IEEE International Congress on Information Science and Technology, CiSt 2018, Marrakech, Morocco, 21–27 October 2018; pp. 328–333. [Google Scholar]
- Nabizadeh, A.H.; Gonçalves, D.; Gama, S.; Jorge, J.A.; Rafsanjani, H.N. Adaptive learning path recommender approach using auxiliary learning objects. Comput. Educ. 2020, 147, 103777. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Zhang, Q.; Wu, D.; Lu, J.; Liu, F.; Zhang, G. A cross-domain recommender system with consistent information transfer. Decis. Support Syst. 2017, 104, 49–63. [Google Scholar] [CrossRef]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Yu, P.S. A Survey of Heterogeneous Information Network Analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 17–37. [Google Scholar] [CrossRef]
- Shi, C.; Kong, X.; Huang, Y.; Yu, P.S.; Wu, B. HeteSim: A General Framework for Relevance Measure in Heterogeneous Networks. IEEE Trans. Knowl. Data Eng. 2014, 26, 2479–2492. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Sun, Y.; Sturt, B.; Khandelwal, U.; Gu, Q.; Norick, B.; Han, J. Recommendation in heterogeneous information networks with implicit user feedback. In Proceedings of the 7th ACM International Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 347–350. [Google Scholar]
- Shi, C.; Zhang, Z.; Luo, P.; Yu, P.S.; Yue, Y.; Wu, B. Semantic Path based Personalized Recommendation on Weighted Heterogeneous Information Networks. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, Australia, 19–23 October 2015; pp. 453–462. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar]
- Wang, X.; Wang, Y.; Ling, Y. Attention-Guide Walk Model in Heterogeneous Information Network for Multi-Style Recommendation Explanation. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 6275–6282. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Probabilistic Matrix Factorization. In Proceedings of the 21st Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1257–1264. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R. Recommender systems with social regularization. In Proceedings of the 4th International Conference on Web Search and Web Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Zhan, Z.; Shen, W.; Xu, Z.; Niu, S.; You, G. A bibliometric analysis of the global landscape on STEM education (2004–2021): Towards global distribution, subject integration, and research trends. Asia Pac. J. Innov. Entrep. 2022, 16, 171–203. [Google Scholar] [CrossRef]
- Zhan, Z.; Mei, H.; Liang, T.; Huo, L.; Bonk, C.; Hu, Q. A longitudinal study into the effects of material incentives on knowledge-sharing networks and information lifecycles in an online forum. Interact. Learn. Environ. 2021, 3, 1–14. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The heterogeneous graph | |
| A | The set of the types of node |
| P | A meta-path |
| The set of the meta-path | |
| The type of node t | |
| The number of nodes of type in the neighbor of node v. | |
| An adjacency matrix of HG. | |
| A node embedding on the l meta-path. | |
| The finally embedding of user u and item i. | |
| The rating predicted by user u on item i. | |
| The potential factors for user u and item i |
| Datasets | Relations (A-B) | Number (A) | Number (B) | Number (A-B) |
|---|---|---|---|---|
| Student-Course | 25,293 | 1670 | 53,988 | |
| Student-Unit_of_study | 150,563 | 5753 | 150,563 | |
| Scholat | Student-Research_field | 150,563 | 6458 | 150,563 |
| Course-School | 3168 | 344 | 3168 | |
| Course-Type | 3168 | 13 | 3168 | |
| Course-Teacher | 3168 | 1060 | 7846 | |
| User-Course | 224,914 | 238 | 325,199 | |
| User-Learner_type | 32,719 | 7 | 32,719 | |
| CNPC | User-Age | 224,914 | 4 | 224,914 |
| Course-Discipline | 238 | 10 | 238 | |
| Course-Course_length | 238 | 79 | 238 | |
| User-Business | 16,239 | 14,284 | 198,397 | |
| User-User | 10,580 | 10,580 | 158,590 | |
| Yelp | User-Compliment | 14,411 | 11 | 76,875 |
| Business-City | 14,267 | 47 | 14,267 | |
| Business-Category | 14,180 | 511 | 40,009 | |
| User-Movie | 943 | 1682 | 100,000 | |
| User-User | 943 | 943 | 47,150 | |
| Movielens | User-Occupation | 943 | 21 | 943 |
| User-Age | 943 | 8 | 943 | |
| Movie-Movie | 1682 | 1682 | 82,798 | |
| Movie-Genre | 1682 | 18 | 2891 |
| Scholat | CNPC | Yelp | Movielens |
|---|---|---|---|
| S-C-S, C-S-C, S-C-Te-C-S, C-Te-C, C-Ty-C, S-C-Ty-C-S, S-C-Sc-C-S, C-Sc-C | U-C-U, C-U-C, U-C-D-C-U, C-D-C, U-C-Co-C-U, C-Co-C | U-B-U, B-U-B, U-B-Ci-B-U, B-Ci-B, U-B-Ca-B-U, B-Ca-B | U-M-U, M-U-M, U-M-G-M-U, M-G-M, M-M, U-M-M-U |
| Training Rate | Metrics | PMF | SoMF | HERec | HGE-CRec |
|---|---|---|---|---|---|
| 80% | MAE | 0.4732 | 0.4685 | 0.4529 | |
| RMSE | 0.7199 | 0.7087 | 0.6596 | ||
| 60% | MAE | 0.5023 | 0.4832 | 0.4627 | |
| RMSE | 0.7693 | 0.7303 | 0.6908 | ||
| 40% | MAE | 0.5758 | 0.5090 | 0.4801 | |
| RMSE | 0.8988 | 0.7748 | 0.7185 | ||
| 20% | MAE | 0.8302 | 0.5856 | 0.5677 | |
| RMSE | 1.4199 | 0.8048 | 0.7866 |
| Training Rate | Metrics | PMF | SoMF | HERec | HGE-CRec |
|---|---|---|---|---|---|
| 80% | MAE | 0.8998 | 0.9074 | 0.8775 | |
| RMSE | 1.2254 | 1.2293 | 1.1666 | ||
| 60% | MAE | 0.9124 | 0.9248 | 0.8843 | |
| RMSE | 1.2504 | 1.2563 | 1.1761 | ||
| 40% | MAE | 0.9335 | 0.9585 | 0.8955 | |
| RMSE | 1.2934 | 1.3092 | 1.1928 | ||
| 20% | MAE | 1.0504 | 1.0236 | 0.9156 | |
| RMSE | 1.4053 | 1.4465 | 1.2273 |
| Training Rate | Metrics | PMF | SoMF | HERec | HGE-CRec |
|---|---|---|---|---|---|
| 90% | MAE | 1.0412 | 1.0095 | 0.8395 | |
| RMSE | 1.4268 | 1.3392 | 1.0907 | ||
| 80% | MAE | 1.0791 | 1.0373 | 0.8475 | |
| RMSE | 1.4816 | 1.3782 | 1.1117 | ||
| 70% | MAE | 1.1170 | 1.0694 | 0.8580 | |
| RMSE | 1.5387 | 1.4201 | 1.1256 | ||
| 60% | MAE | 1.1778 | 1.1135 | 0.8759 | |
| RMSE | 1.6167 | 1.4748 | 1.1488 |
| Training Rate | Metrics | PMF | SoMF | HERec | HGE-CRec |
|---|---|---|---|---|---|
| 80% | MAE | 0.7324 | 0.7289 | 0.7103 | |
| RMSE | 0.9862 | 0.9851 | 0.9274 | ||
| 60% | MAE | 0.7463 | 0.7450 | 0.7181 | |
| RMSE | 1.0121 | 1.0112 | 0.9369 | ||
| 40% | MAE | 0.7661 | 0.7784 | 0.7293 | |
| RMSE | 1.0542 | 1.0650 | 0.9536 | ||
| 20% | MAE | 0.8527 | 0.8451 | 0.7495 | |
| RMSE | 1.1641 | 1.1423 | 0.9881 |
| Dataset | Metrics | HGE-CRec | HGE-CRec | HGE-CRec |
|---|---|---|---|---|
| Scholat | MAE | 0.4528 | 0.4435 | 0.4435 |
| RMSE | 0.6598 | 0.6295 | 0.6294 | |
| CNPC | MAE | 0.8775 | 0.8658 | 0.8658 |
| RMSE | 1.1667 | 1.1362 | 1.1361 | |
| Yelp | MAE | 0.8479 | 0.7807 | 0.7804 |
| RMSE | 1.1111 | 0.9880 | 0.9884 | |
| Movielens | MAE | 0.7103 | 0.6992 | 0.6992 |
| RMSE | 0.9272 | 0.8981 | 0.8980 |
| Datasets | Metrics | HGE-CRec | HGE-CRec |
|---|---|---|---|
| Scholat | MAE | 0.4559 | 0.4533 |
| RMSE | 0.6719 | 0.6604 | |
| CNPC | MAE | 0.8808 | 0.8795 |
| RMSE | 1.1784 | 1.1682 | |
| Yelp | MAE | 0.8804 | 0.8529 |
| RMSE | 1.1607 | 1.1283 | |
| Movielens | MAE | 0.7136 | 0.7112 |
| RMSE | 0.9360 | 0.9298 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Liang, Q.; Zhan, Z. Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph. Appl. Sci. 2023, 13, 2404. https://doi.org/10.3390/app13042404
Wu Z, Liang Q, Zhan Z. Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph. Applied Sciences. 2023; 13(4):2404. https://doi.org/10.3390/app13042404
Chicago/Turabian StyleWu, Zhengyang, Qingyu Liang, and Zehui Zhan. 2023. "Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph" Applied Sciences 13, no. 4: 2404. https://doi.org/10.3390/app13042404
APA StyleWu, Z., Liang, Q., & Zhan, Z. (2023). Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph. Applied Sciences, 13(4), 2404. https://doi.org/10.3390/app13042404