
Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning

Abstract
:1. Introduction
- To the extent of our knowledge, we present the first approach that combines regularization constraints with pseudo-label construction in solving a federated learning for medical information classification tasks.
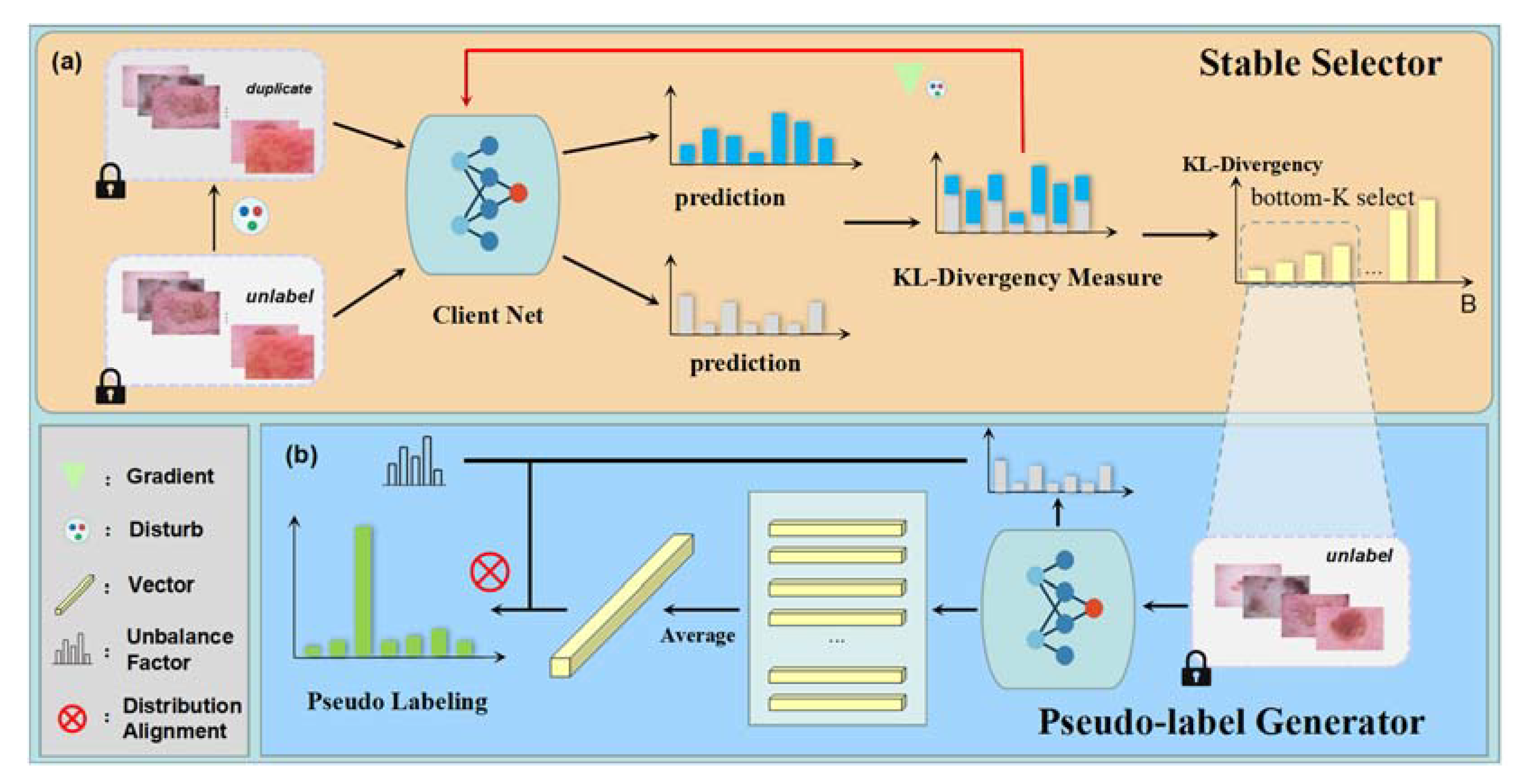
- We propose a stable selector to filter unlabeled data to improve the robustness of the model and the pseudo-labeling information.
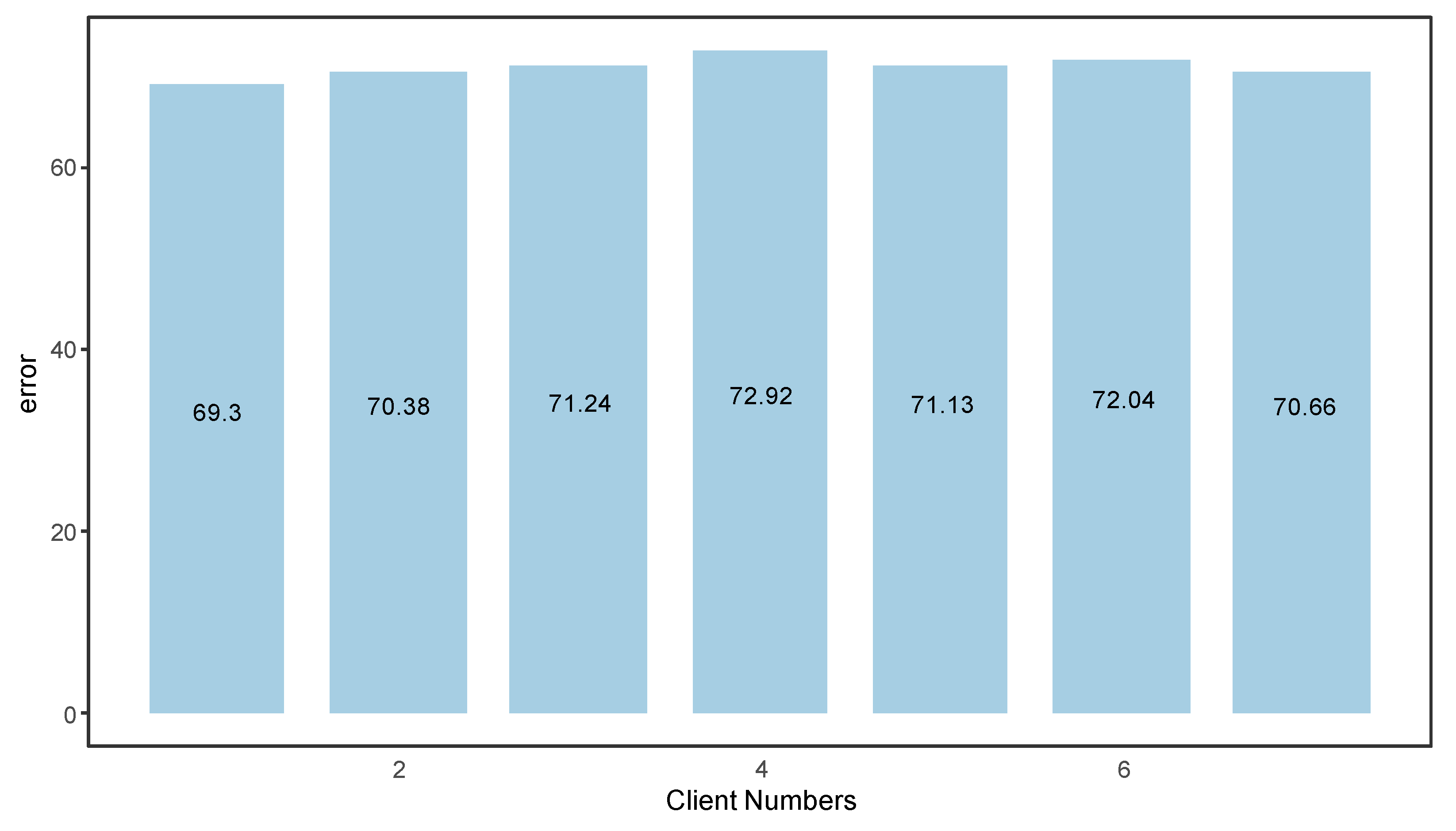
- We construct controllable data samplers that can divide labeled and unlabeled data in arbitrary proportions to explore the impact of different numbers of clients on the model.
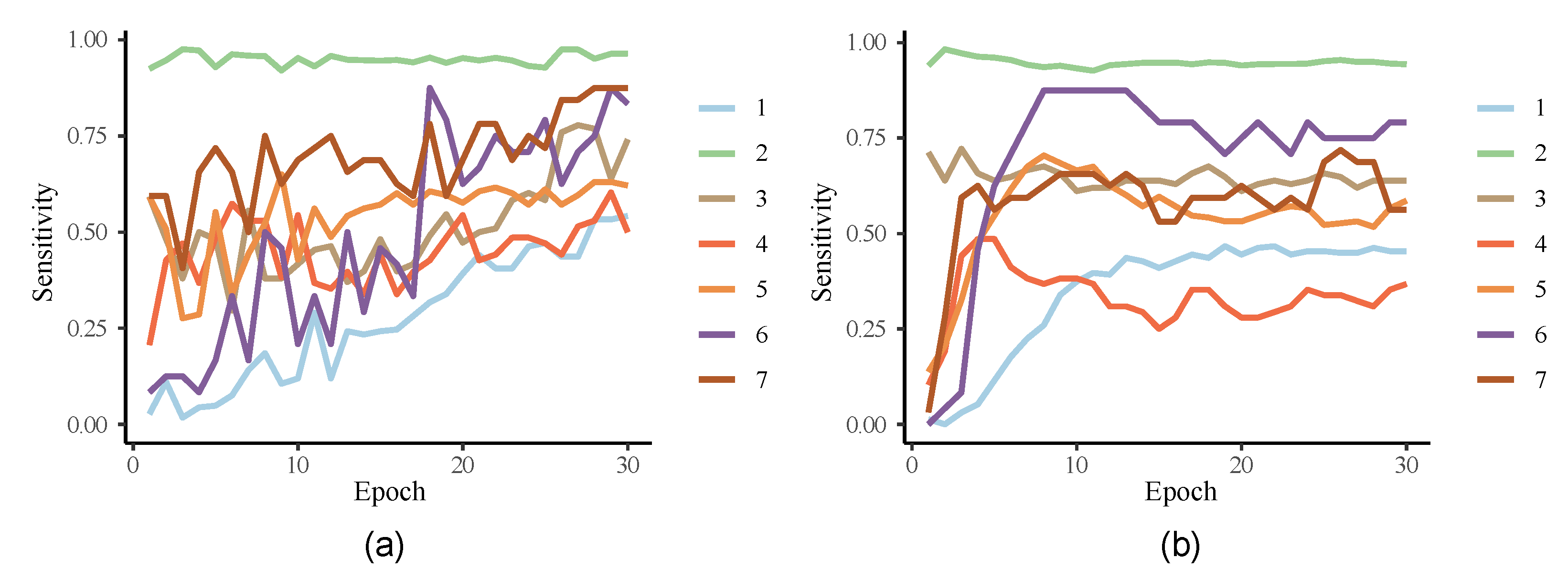
- We suggest a measure of model robustness that measures the sensitivity of the model to the class of data.
2. Materials and Methods
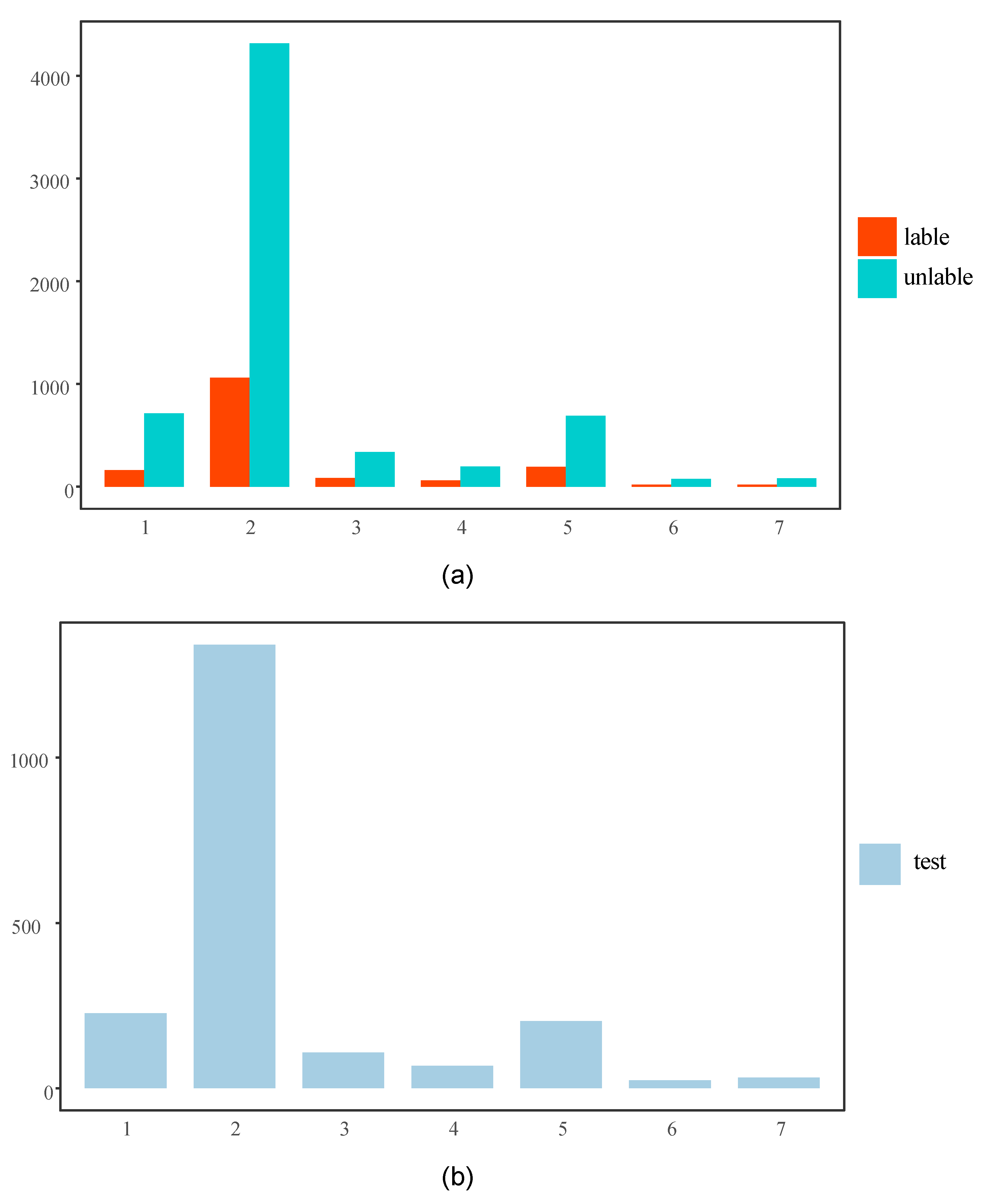
2.1. Data Set and Task Setup
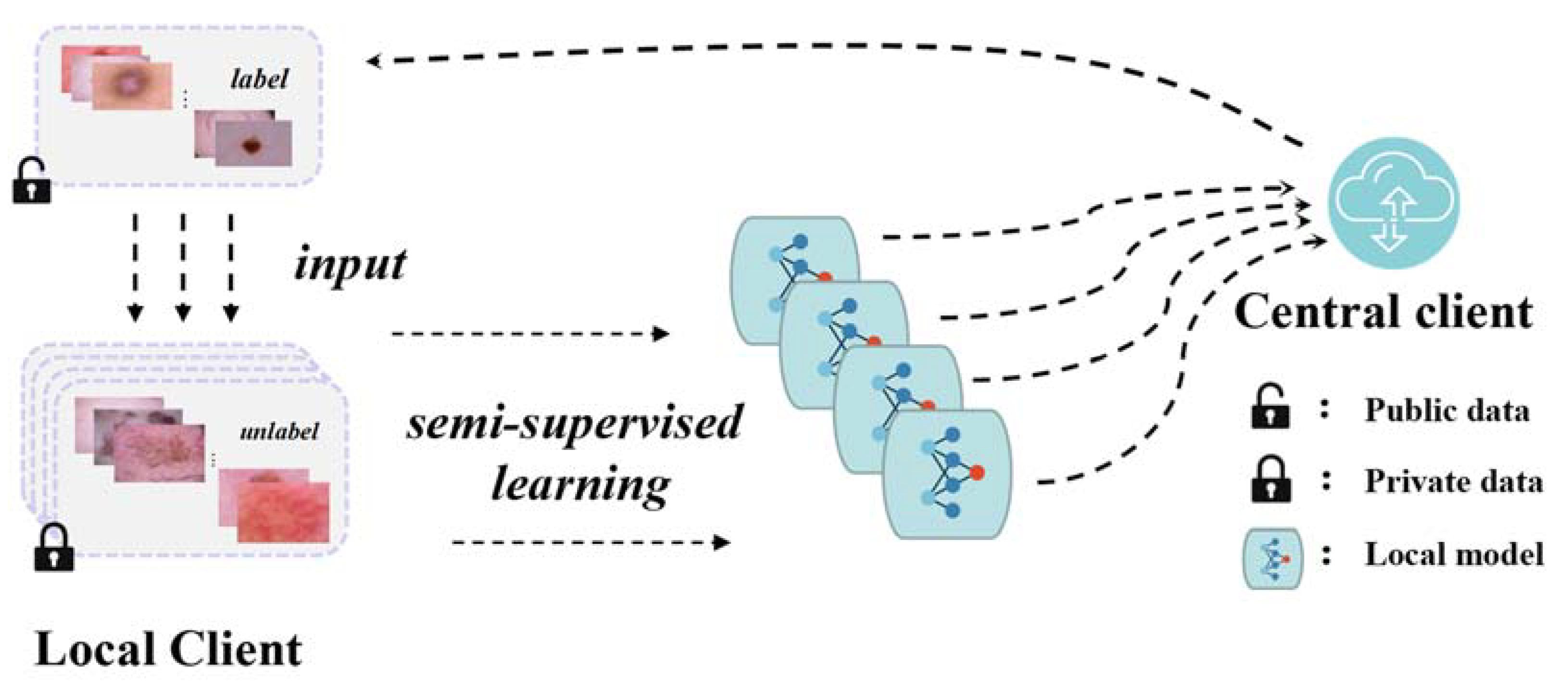
2.2. Federated Learning Method
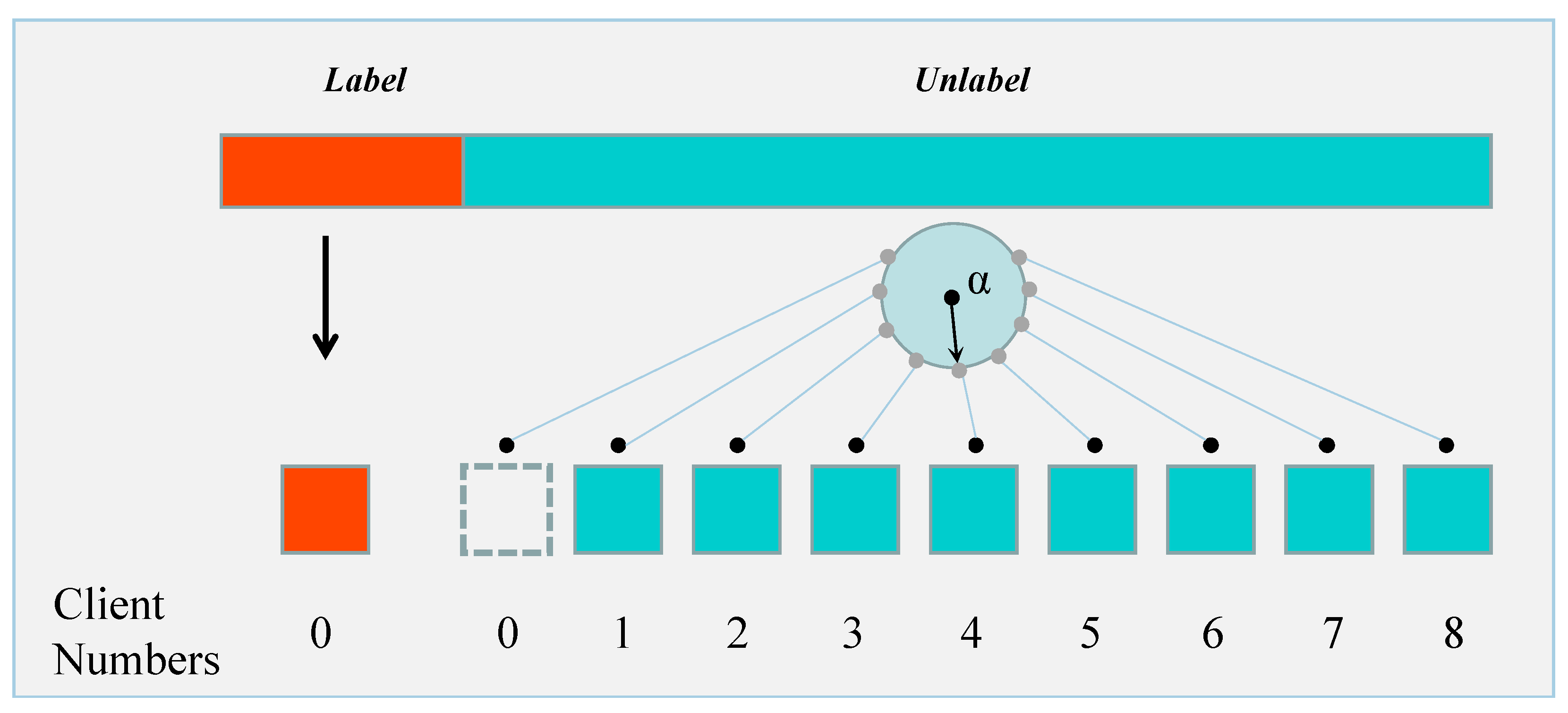
2.3. Data Distribution
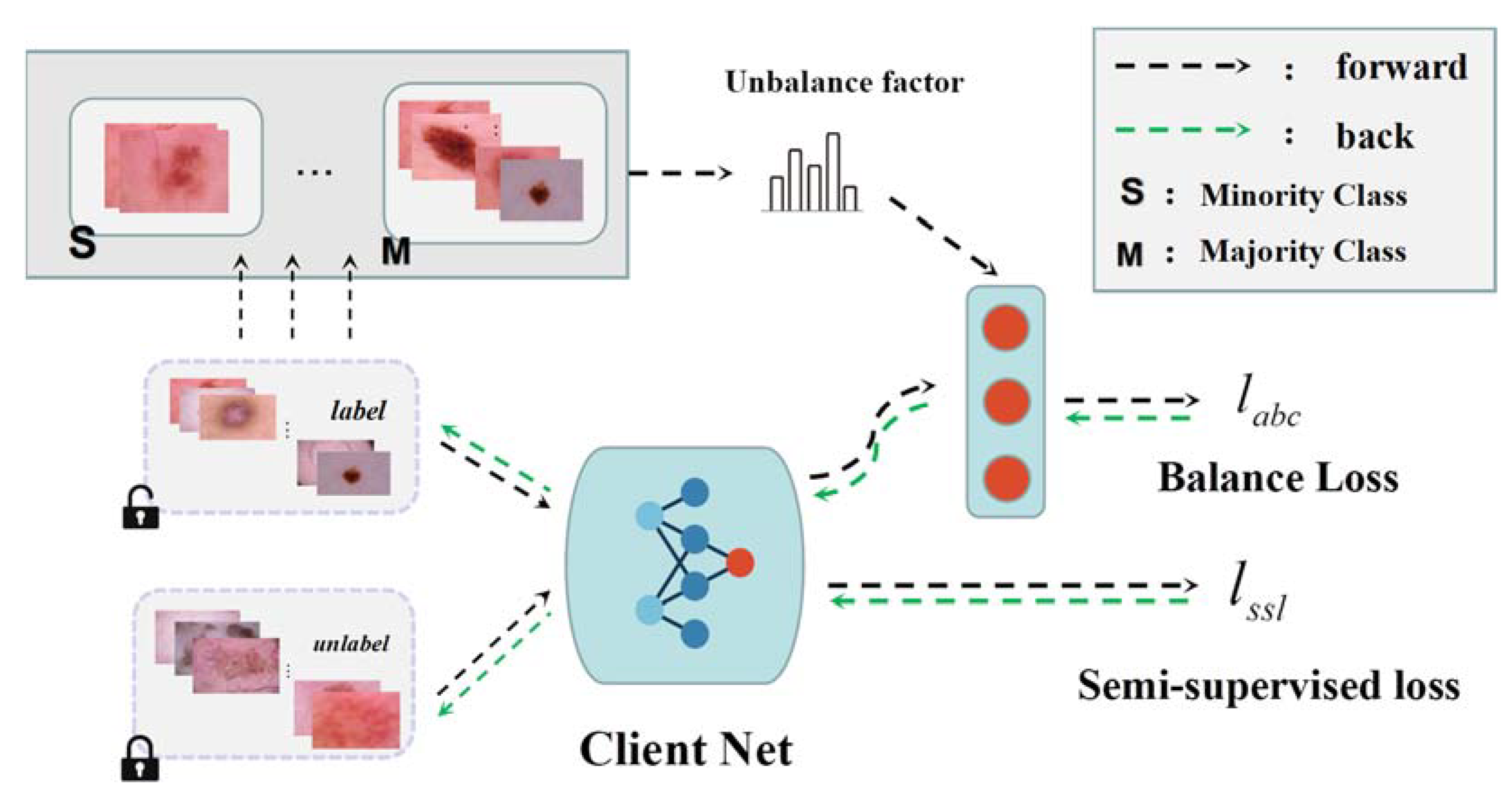
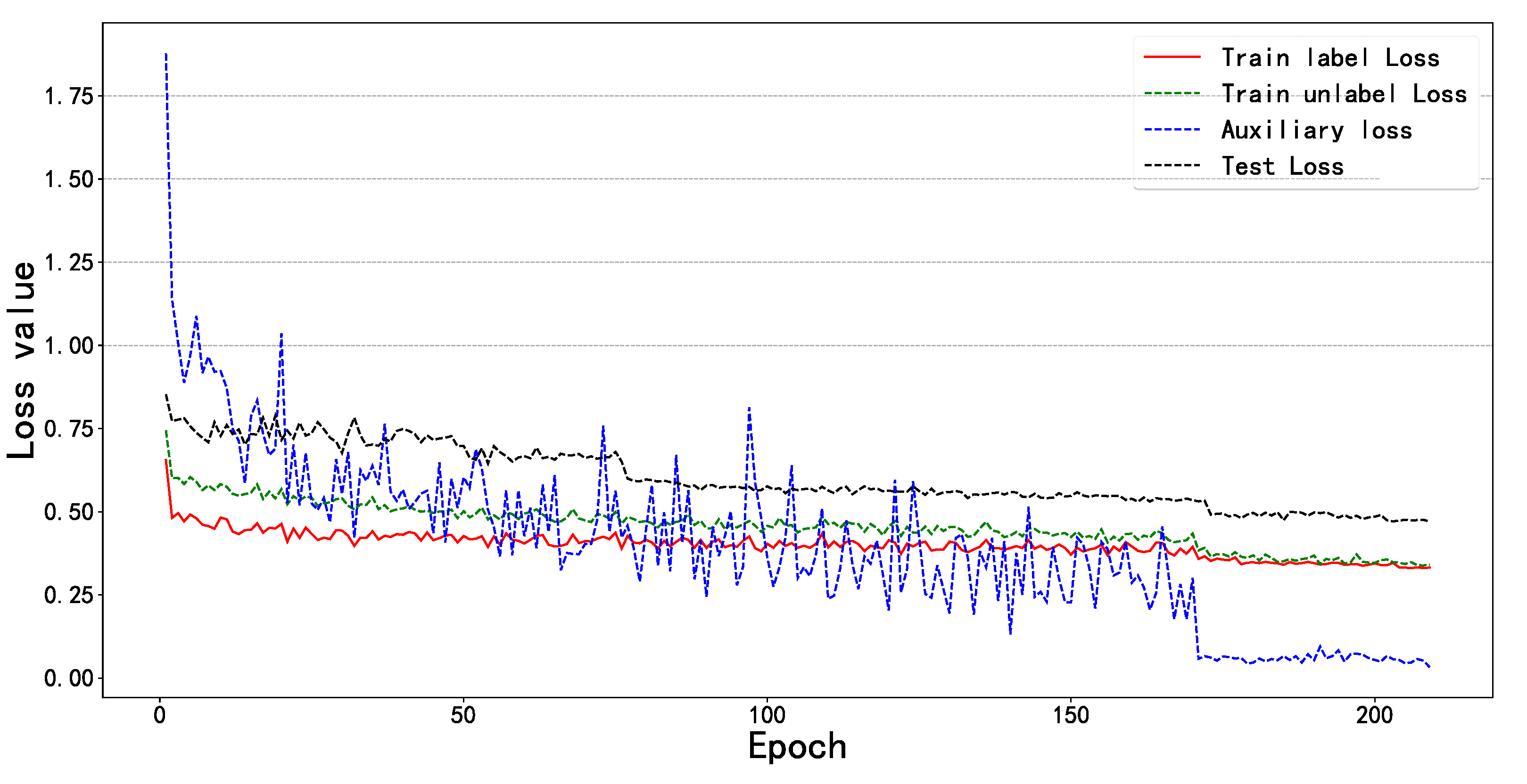
2.4. Class Balance Auxiliary
2.5. Pseudo-Label Construction
2.6. Model Stability Validation
3. Results
3.1. Experimental Setup and Details
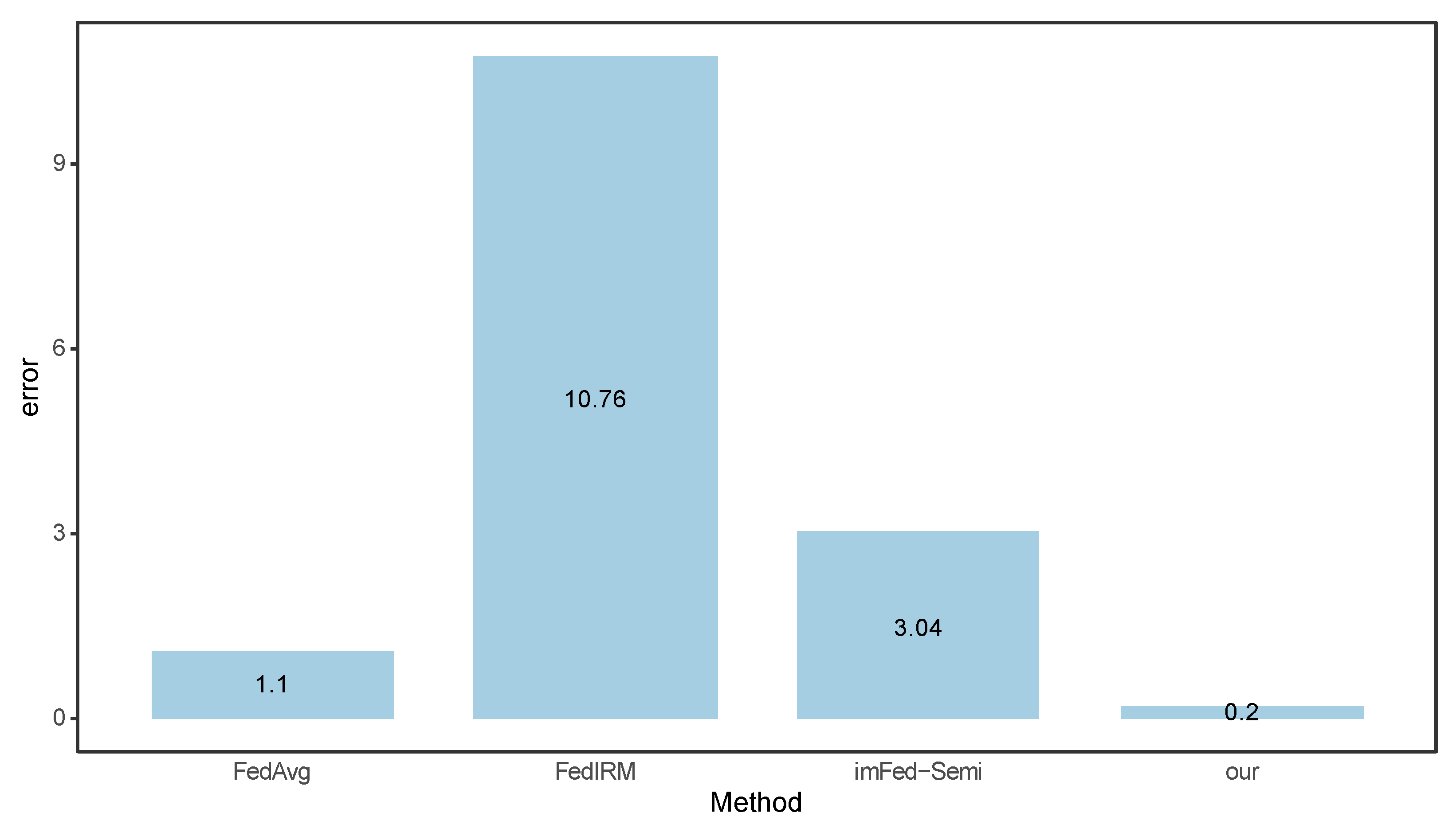
3.2. Comparison with Advanced Methods
3.3. Internal Comparative Analysis of Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dhruva, S.S.; Ross, J.S.; Akar, J.G.; Caldwell, B.; Childers, K.; Chow, W.; Ciaccio, L.; Coplan, P.; Dong, J.; Dykhoff, H.J.; et al. Aggregating multiple real-world data sources using a patient-centered health-data-sharing platform. npj Digit. Med. 2020, 3, 60. [Google Scholar] [CrossRef] [PubMed]
- Silva, S.; Gutman, B.A.; Romero, E.; Thompson, P.M.; Altmann, A.; Lorenzi, M. Federated Learning in Distributed Medical Databases: Meta-Analysis of Large-Scale Subcortical Brain Data. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019. [Google Scholar]
- Razzak, M.I.; Naz, S.; Zaib, A. Deep Learning for Medical Image Processing: Overview, Challenges and Future. In Classification in BioApps: Automation of Decision Making; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Dong, N.; Voiculescu, I. Federated Contrastive Learning for Decentralized Unlabeled Medical Images; Springer: Berlin/Heidelberg, Germany, 2021; p. 12903. [Google Scholar] [CrossRef]
- Dou, Q.; So, T.Y.; Jiang, M.; Liu, Q.; Vardhanabhuti, V.; Kaissis, G.; Li, Z.; Si, W.; Lee, H.H.C.; Yu, K.; et al. Author Correction: Federated deep learning for detecting COVID-19 lung abnormalities in CT: A privacy-preserving multinational validation study. npj Digit. Med. 2022, 5, 56. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. FedBN: Federated Learning on Non-IID Features via Local Batch Normalization. arXiv 2021, arXiv:2102.07623. [Google Scholar] [CrossRef]
- Roth, H.R.; Chang, K.; Singh, P.; Neumark, N.; Li, W.; Gupta, V.; Gupta, S.; Qu, L.; Ihsani, A.; Bizzo, B.C.; et al. Federated Learning for Breast Density Classification: A Real-World Implementation; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12444, pp. 181–191. [Google Scholar]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Colen, R.R.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 12598. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Zeng, D.; Wang, Z.; Shi, Y.; Hu, J. Federated Contrastive Learning for Volumetric Medical Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12903, pp. 367–377. [Google Scholar]
- Chang, Q.; Qu, H.; Zhang, Y.; Sabuncu, M.; Chen, C.; Zhang, T.; Metaxas, D.N. Synthetic Learning: Learn From Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, D.; Kar, A.; Ravikumar, N.; Frangi, A.F.; Fidler, S. Federated Simulation for Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2022; Volume 12261, pp. 159–168. [Google Scholar]
- Liu, Q.; Yang, H.; Dou, Q.; Heng, P.-A. Federated Semi-Supervised Medical Image Classification via Inter-Client Relation Matching; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12903, pp. 325–335. [Google Scholar]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. npj Digit. Med. 2022, 3, 119. [Google Scholar] [CrossRef] [PubMed]
- Gyawali, P.K.; Ghimire, S.; Bajracharya, P.; Li, Z.; Wang, L. Semi-Supervised Medical Image Classification with Global Latent Mixing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12261, pp. 604–613. [Google Scholar]
- Shi, X.; Su, H.; Xing, F.; Liang, Y.; Qu, G.; Yang, L. Graph temporal ensembling based semi-supervised convolutional neural network with noisy labels for histopathology image analysis. Med. Image Anal. 2020, 60, 101624. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Yu, L.; Luo, L.; Dou, Q.; Heng, P.A. Semi-supervised Medical Image Classification with Relation-driven Self-ensembling Model. IEEE Trans. Med. Imaging 2020, 39, 3429–3440. [Google Scholar] [CrossRef] [PubMed]
- Amyar, A.; Modzelewski, R.; Vera, P.; Morard, V.; Ruan, S. Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction. J. Imaging 2020, 8, 130. [Google Scholar] [CrossRef]
- Jiang, M.; Yang, H.; Li, X.; Liu, Q.; Heng, P.-A.; Dou, Q. Dynamic Bank Learning for Semi-Supervised Federated Image Diagnosis with Class Imbalance; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13433, pp. 196–206. [Google Scholar]
- Bai, W.; Oktay, O.; Sinclair, M.; Suzuki, H.; Rajchl, M.; Tarroni, G.; Glocker, B.; King, A.; Matthews, P.M.; Rueckert, D. Semi-Supervised Learning for Network-Based Cardiac MR Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10434, pp. 253–260. [Google Scholar]
- Lee, H.; Shin, S.; Kim, H. ABC: Auxiliary Balanced Classifier for Class-imbalanced Semi-supervised Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 7082–7094. [Google Scholar]
- Bdair, T.; Navab, N.; Albarqouni, S. Semi-Supervised Federated Pe-er Learning for Skin Lesion Classification. arXiv 2021, arXiv:2103.03703. Available online: https://arxiv.org/pdf/2103.03703.pdf (accessed on 17 December 2022).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Oerton, E.; Roberts, I.; Lewis, P.S.; Guilliams, T.; Bender, A. Understanding and predicting disease relationships through similarity fusion. Bioinformatics 2018, 35, 1213–1220. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, C.K.; Marchetti, M.; et al. Skin Lesion Analysis Toward Melanoma Detection 2018: A ChallengeHosted by the International Skin Imaging Collaboration (ISIC). arXiv 2019, arXiv:1902.03368. [Google Scholar] [CrossRef]
- Cao, X.; Chen, B.C.; Lim, S.N. Unsupervised Deep Metric Learning via Auxiliary Rotation Loss. arXiv 2019, arXiv:1911.07072. [Google Scholar] [CrossRef]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4L: Self-Supervised Semi-Supervised Learning. arXiv 2019, arXiv:1905.03670. [Google Scholar] [CrossRef]
- Wang, L.; Lin, Z.Q.; Wong, A. COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef]
- Yuan, Z.; Yan, Y.; Sonka, M.; Yang, T. Large-Scale Robust Deep AUC Maximization: A New Surrogate Loss and Empirical Studies on Medical Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 17 October 2021. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Amyar, A.; Modzelewski, R.; Vera, P.; Morard, V.; Ruan, S. Multi-Task Multi-Scale Learning For Outcome Prediction in 3D PET Images. Comput. Biol. Med. 2022, 151, 106208. Available online: https://arxiv.org/pdf/2203.00641.pdf (accessed on 17 December 2022). [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Client Num | Metrics | ||||||
|---|---|---|---|---|---|---|---|---|
| Label | Unlabel | AUC | Accuracy | Sensitivity | Specificity | Precision | F1 | |
| FedAvg [22] | 2 | 0 | 88.27 | 92.34 | 61.43 | 92.28 | 66.50 | 62.53 |
| FedIRM(10) [12] | 2 | 8 | 88.17 | 89.87 | 40.76 | 91.66 | 34.38 | 37.02 |
| FedIRM(best) [12] | 2 | 8 | 90.38 | 90.30 | 67.86 | 92.87 | 61.20 | 62.02 |
| imFed-Semi(10) [18] | 2 | 8 | 92.40 | 93.30 | 58.29 | 92.10 | 76.87 | 63.10 |
| imFed-Semi(best) [18] | 2 | 8 | 88.40 | 94.75 | 67.75 | 94.04 | 79.12 | 71.77 |
| our | 2 | 8 | 95.75 | 95.58 | 72.92 | 95.47 | 73.88 | 72.90 |
| Method | Category | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | Average | |
| FedAvg | 44.40 | 92.99 | 69.63 | 42.05 | 57.83 | 60.83 | 70.00 | 62.53 |
| FedIRM(10) | 61.23 | 88.73 | 0 | 0 | 60.59 | 0 | 0 | 30.07 |
| FedIRM(best) | 58.15 | 80.76 | 87.96 | 45.59 | 66.01 | 33.33 | 11.75 | 54.79 |
| imFed-Semi(10) | 29.07 | 99.40 | 74.07 | 50.00 | 39.40 | 16.66 | 78.12 | 55.24 |
| imFed-Semi(best) | 52.86 | 99.11 | 77.78 | 57.35 | 49.75 | 87.50 | 78.13 | 71.78 |
| our | 53.30 | 96.34 | 63.88 | 60.29 | 63.05 | 87.50 | 87.50 | 73.12 |
| 1 | 0.98 | 0.95 | 0.9 | 0.85 | 0.8 | 0.75 | 0.7 | |
| Sensitivity | 71.09 | 71.63 | 72.92 | 71.53 | 72.16 | 71.5 | 69.89 | 69.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Mo, J.; Zhong, F. Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning. Appl. Sci. 2023, 13, 2109. https://doi.org/10.3390/app13042109
Liu W, Mo J, Zhong F. Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning. Applied Sciences. 2023; 13(4):2109. https://doi.org/10.3390/app13042109
Chicago/Turabian StyleLiu, Wei, Jiaqing Mo, and Furu Zhong. 2023. "Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning" Applied Sciences 13, no. 4: 2109. https://doi.org/10.3390/app13042109
APA StyleLiu, W., Mo, J., & Zhong, F. (2023). Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning. Applied Sciences, 13(4), 2109. https://doi.org/10.3390/app13042109