
Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis


Abstract
1. Introduction
- Provision of a novel model for processing text voice bimodal data that can solve the dynamic change problem of cross-modal data in the time dimension and update the cross-modal weight value by iteration;
- Solving the problem of long-term dependencies in intermodality and intramodality, focusing on solving the “vector offset” problem caused by audio modal data to the vector representation of textual words.
2. Related Work
2.1. Unimodal Sentiment Analysis
2.1.1. Textual Sentiment Analysis (TSA)
2.1.2. Audio Sentiment Analysis (ASA)
2.2. Text–Audio Bimodal Sentiment Analysis
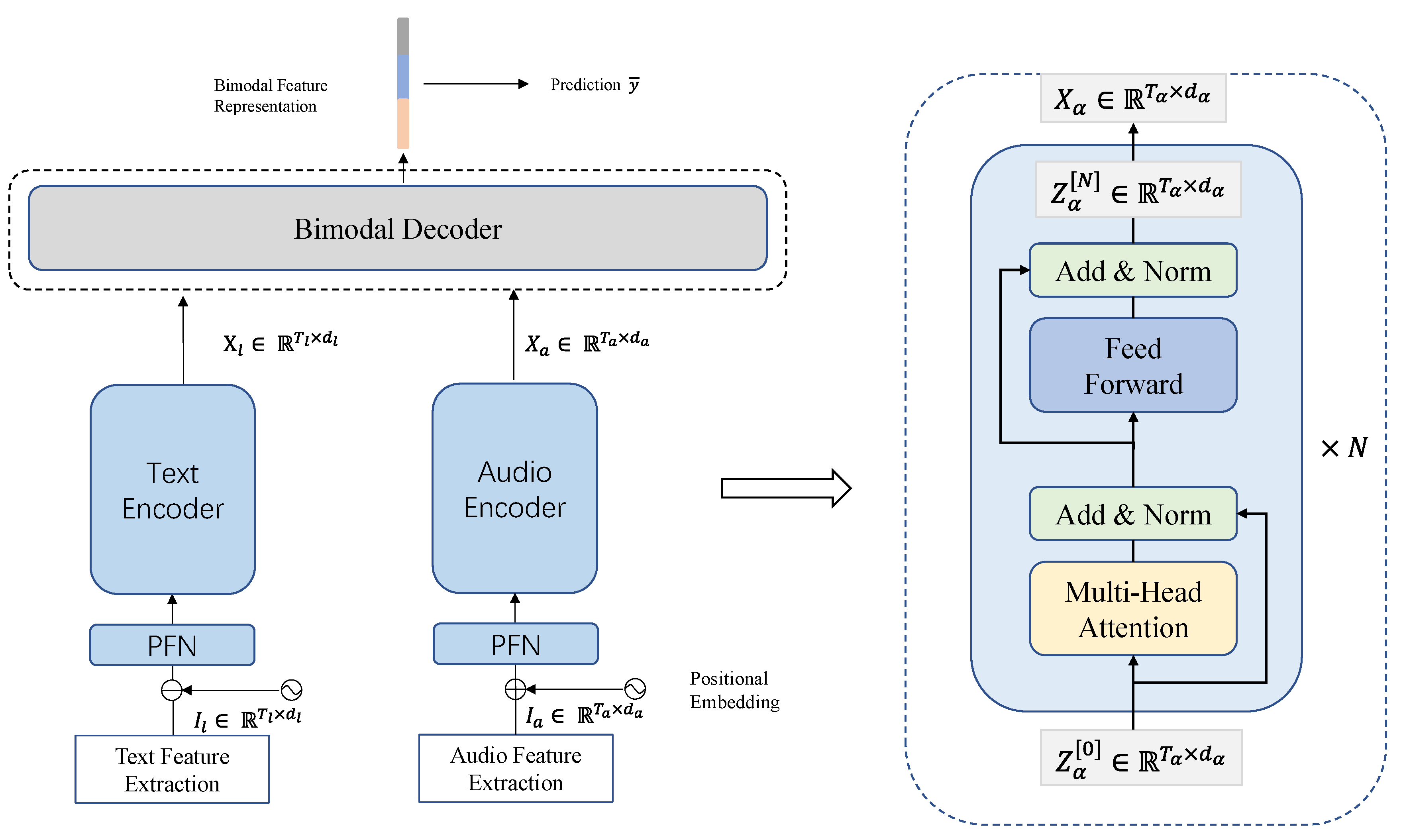
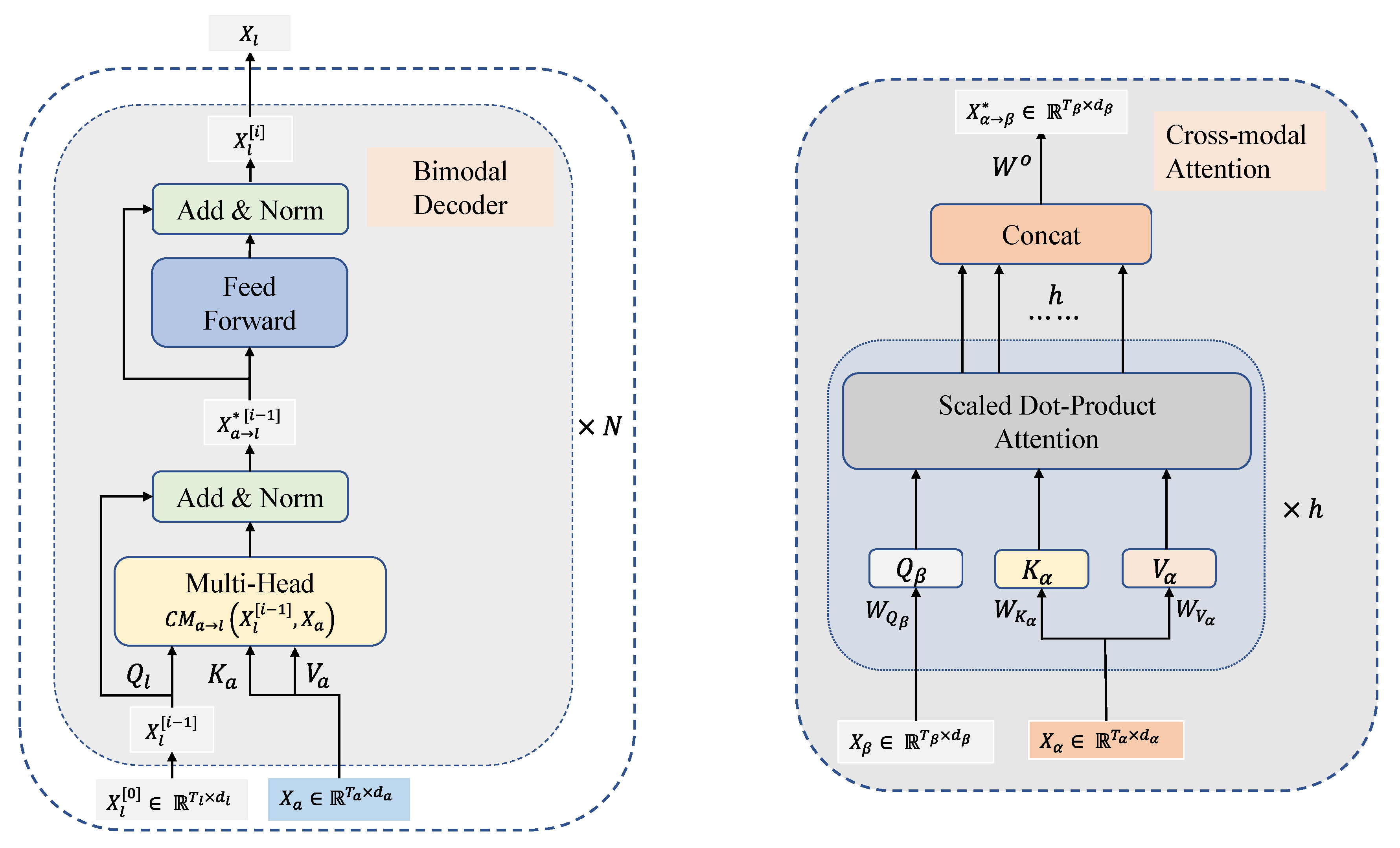
3. Proposed Approach
3.1. Unimodal Encoders
3.2. Bimodal Decoder
4. Experiments
4.1. Dataset
4.2. Baselines
4.3. Setup
4.4. Multimodal Sentiment Analysis Results
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Truong, Q.-T.; Lauw, H.W. VistaNet: Visual Aspect Attention Network for Multimodal Sentiment Analysis. Proc. AAAI Conf. Artif. Intell. 2019, 33, 305–312. [Google Scholar] [CrossRef]
- Yang, K.; Xu, H.; Gao, K. CM-BERT: Cross-Modal BERT for Text-Audio Sentiment Analysis. In Proceedings of the 28th ACM International Conference on Multimedia (MM ‘20), Seattle, WA, USA, 12–16 October 2020; pp. 521–528. [Google Scholar]
- Tu, G.; Wen, J.; Liu, C.; Jiang, D.; Cambria, E. Context- and Sentiment-Aware Networks for Emotion Recognition in Conversation. IEEE Trans. Artif. Intell. 2022, 3, 699–708. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2007, 37, 98–125. [Google Scholar] [CrossRef]
- Zhou, M.; Liu, D.; Zheng, Y.; Zhu, Q.; Guo, P. A text sentiment classification model using double word embedding methods. Multimed. Tools Appl. 2022, 81, 18993–19012. [Google Scholar] [CrossRef]
- Xiao, L.; Wu, X.; Wu, W.; Yang, J.; He, L. Multi-Channel Attentive Graph Convolutional Network with Sentiment Fusion for Multimodal Sentiment Analysis. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4578–4582. [Google Scholar]
- Mai, S.; Hu, H.; Xu, J.; Xing, S. Multi-Fusion Residual Memory Network for Multimodal Human Sentiment Comprehension. IEEE Trans. Affect. Comput. 2022, 13, 320–334. [Google Scholar] [CrossRef]
- Huang, Z.; Liu, F.; Wu, X.; Ge, S.; Wang, H.; Fan, W.; Zou, Y. Audio-Oriented Multimodal Machine Comprehension via Dynamic Inter- and Intra-modality Attention. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13098–13106. [Google Scholar] [CrossRef]
- Tsai, Y.-H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.-P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6558–6569. [Google Scholar]
- Bagher Zadeh, A.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.-P. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 2236–2246. [Google Scholar]
- Gu, Y.; Yang, K.; Fu, S.; Chen, S.; Li, X.; Marsic, I. Multimodal Affective Analysis Using Hierarchical Attention Strategy with Word-Level Alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 2225–2235. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.-P. Memory Fusion Network for Multi-view Sequential Learning. arXiv 2018, arXiv:1802.00927. [Google Scholar] [CrossRef]
- Tsai, Y.-H.H.; Liang, P.P.; Zadeh, A.; Morency, L.-P.; Salakhutdinov, R. Learning Factorized Multimodal Representations. In Proceedings of the International Conference on Representation Learning, Addis Ababa, Ethiopia, 25–29 April 2019. [Google Scholar]
- Lee, Y.; Yoon, S.; Jung, K. Multimodal Speech Emotion Recognition using Cross Attention with Aligned Audio and Text. Interspeech 2020, 2717–2721. [Google Scholar]
- Xu, H.; Zhang, H.; Han, K.; Wang, Y.; Peng, Y.; Li, X. Learning Alignment for Multimodal Emotion Recognition from Speech. arXiv 2020, arXiv:1909.05645. [Google Scholar]
- Yoon, S.; Byun, S.; Dey, S.; Jung, K. Speech Emotion Recognition Using Multi-hop Attention Mechanism. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2822–2826. [Google Scholar]
- Blekanov, I.; Kukarkin, M.; Maksimov, A.; Bodrunova, S. Sentiment Analysis for Ad Hoc Discussions Using Multilingual Knowledge-Based Approach. In Proceedings of the 3rd International Conference on Applications in Information Technology, Wakamatsu, Japan, 1–3 November 2018; pp. 117–121. [Google Scholar]
- Pak, A.; Paroubek, P. Text Representation Using Dependency Tree Subgraphs for Sentiment Analysis. Database Syst. Adanced Appl. 2011, 6637, 323–332. [Google Scholar]
- Le, T. A Hybrid Method for Text-Based Sentiment Analysis. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 1392–1397. [Google Scholar]
- Liu, F.; Zheng, L.; Zheng, J. HieNN-DWE: A hierarchical neural network with dynamic word embeddings for document level sentiment classification. Neurocomputing 2020, 403, 21–32. [Google Scholar] [CrossRef]
- Yin, R.; Li, P.; Wang, B. Sentiment Lexical-Augmented Convolutional Neural Networks for Sentiment Analysis. In Proceedings of the 2017 IEEE Second International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 26–29 June 2017; pp. 630–635. [Google Scholar]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl. Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Bitouk, D.; Verma, R.; Nenkova, A. Class-level spectral features for emotion recognition. Speech Commun. 2010, 52, 613–625. [Google Scholar] [CrossRef] [PubMed]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning Salient Features for Speech Emotion Recognition Using Convolutional Neural Networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Akagi, M. Speech Emotion Recognition Based on Speech Segment Using LSTM with Attention Model. In Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 40–44. [Google Scholar]
- Sebastian, J.; Pierucci, P. Fusion Techniques for Utterance-Level Emotion Recognition Combining Speech and Transcripts. Proc. Interspeech 2019, 51–55. [Google Scholar]
- Cai, L.; Hu, Y.; Dong, J.; Zhou, S. Audio-Textual Emotion Recognition Based on Improved Neural Networks. Math. Probl. Eng. 2019, 2019, 2593036. [Google Scholar] [CrossRef]
- Pepino, L.; Riera, P.; Ferrer, L.; Gravano, A. Fusion Approaches for Emotion Recognition from Speech Using Acoustic and Text-Based Features. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6484–6488. [Google Scholar]
- Wu, Y.; Lin, Z.; Zhao, Y.; Qin, B.; Zhu, L. A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP, Online, 3 August 2021; pp. 4730–4738. [Google Scholar]
- Sun, Z.; Sarma, P.K.; Sethares, W.A.; Liang, Y. Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8992–8999. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Williams, J.; Kleinegesse, S.; Comanescu, R.; Radu, O. Recognizing Emotions in Video Using Multimodal DNN Feature Fusion. In Proceedings of the grand Challenge and Workshop on Human Multimodal Language (Challenge-HML), Melbourne, Australia, 10 July 2018; pp. 11–19. [Google Scholar]
- Han, W.; Chen, H.; Gelbukh, A.F.; Zadeh, A.; Morency, L.; Poria, S. Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis. In Proceedings of the 2021 International Conference on Multimodal Interaction, Montréal, QC, Canada, 18–22 October 2021; pp. 6–15. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7216–7223. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Model | Acc-7 | Acc-2 | F1-Score | MAE | Corr | Data Setting |
|---|---|---|---|---|---|---|
| Transformer-T | 46.5 | --/77.4 | --/78.2 | 0.653 | 0.631 | Unaligned |
| Transformer-A | 41.4 | --/65.6 | --/68.8 | 0.764 | 0.31 | Unaligned |
| Transformer-V | 43.5 | --/66.4 | --/69.3 | 0.759 | 0.343 | Unaligned |
| CTC+EF-LSTM | 41.7 | 65.3/-- | 76.0/-- | 0.799 | 0.265 | Unaligned |
| CTC+RAVEN | 45.5 | --/75.4 | --/75.7 | 0.664 | 0.599 | Unaligned |
| BMAN | 48.12 | 79.29/78.95 | 78.06/77.84 | 0.6471 | 0.640 | Unaligned |
| Graph-MFN | 45.0 | 76.9/-- | 77.0/-- | 0.71 | 0.54 | Aligned |
| EF-LSTM | 46.7 | 79.1/72.02 | 79.89/61.89 | 0.674 | 0.704 | Aligned |
| BBFN(VA) | 41.1 | --/71.1 | --/64.5 | 0.816 | 0.261 | Aligned |
| BMAN | 46.84 | 75.55/78.5 | 76.11/78.32 | 0.656 | 0.624 | Aligned |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Xue, C.; Qi, Q.; Lin, L.; Zhang, J.; Zhang, L. Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis. Appl. Sci. 2023, 13, 1915. https://doi.org/10.3390/app13031915
Zhang R, Xue C, Qi Q, Lin L, Zhang J, Zhang L. Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis. Applied Sciences. 2023; 13(3):1915. https://doi.org/10.3390/app13031915
Chicago/Turabian StyleZhang, Rui, Chengrong Xue, Qingfu Qi, Liyuan Lin, Jing Zhang, and Lun Zhang. 2023. "Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis" Applied Sciences 13, no. 3: 1915. https://doi.org/10.3390/app13031915
APA StyleZhang, R., Xue, C., Qi, Q., Lin, L., Zhang, J., & Zhang, L. (2023). Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis. Applied Sciences, 13(3), 1915. https://doi.org/10.3390/app13031915