
Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction

 , , ,
, , ,
Abstract
:1. Introduction
- An FL-based framework is proposed in this paper to overcome the problem of data privacy for HSP systems.
- We utilize the modified version of a federated matched averaging (FedMA) algorithm to preserve the privacy of heart disease data and to address the issues of the HSP’s central model updation and communication efficiency.
- A hybrid technique comprised of a modified artificial bee colony and support vector machine (MABC-SVM) is proposed for the prediction of CVD with improved prediction accuracy. This hybrid algorithm is introduced at the client end of HSP.
- Our hybrid method’s performance in terms of communication efficiency, classification error, and prediction accuracy is assessed and compared to current FL approaches.
2. Background
2.1. Basics of Federated Learning
2.2. M-ABC-Based Optimization Algorithm
2.3. SVM Classification Technique
3. Related Work
4. Proposed Hybrid FL-Based Framework
4.1. M-ABC-Based Feature Selection
4.1.1. Phase-I
4.1.2. Phase-II (Searching of Candidate Solution by Employed Bee)
4.1.3. Phase-III (Onlooker Bee’s Candidate Solution)
4.1.4. Phase-IV (Scout Bee with Firefly)
4.2. Classification Based on SVM
4.3. Discussion on Proposed Framework
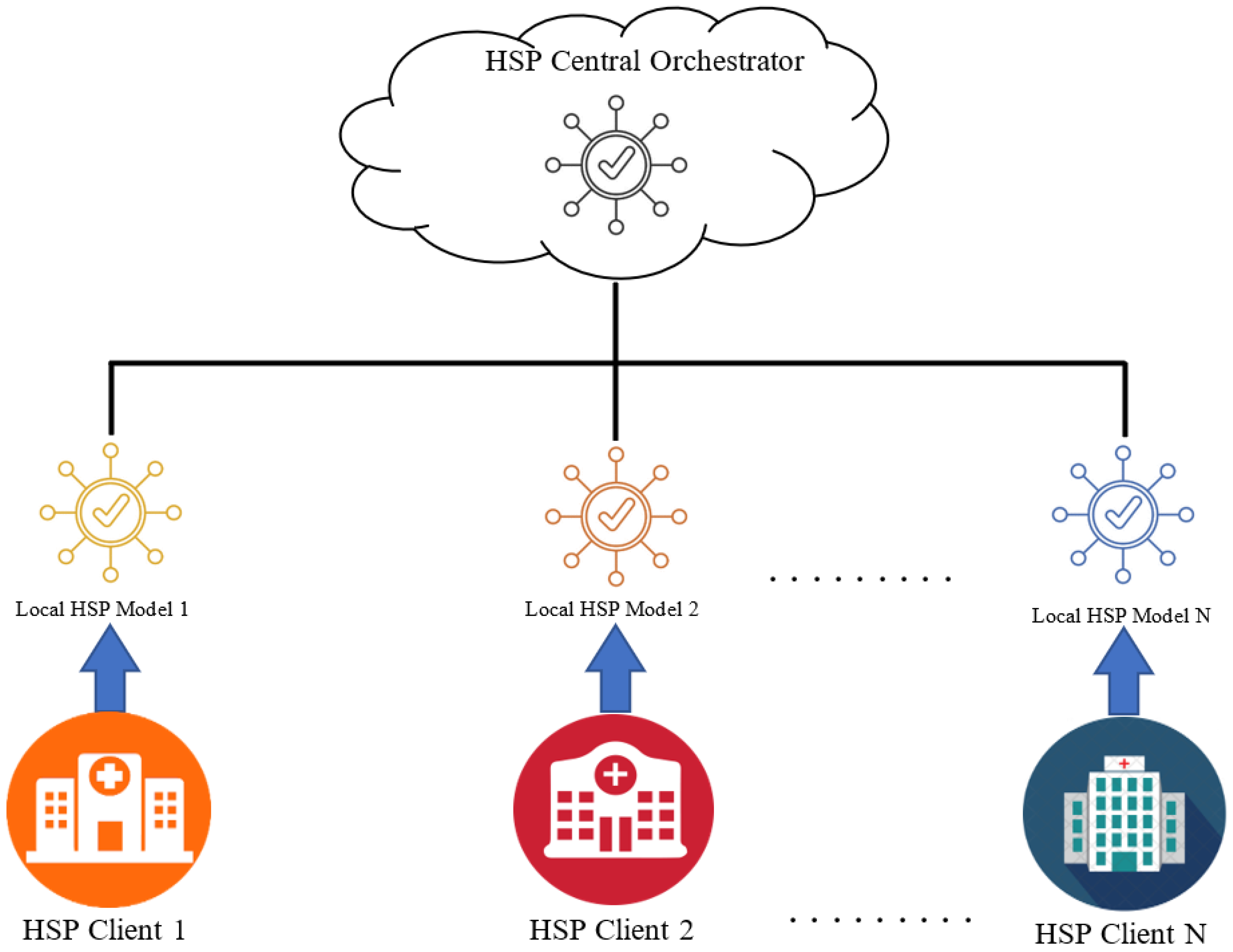
- Stage-I (initial): An initial global model o is disseminated to every HSP client user HCN. After obtaining this initial model, the HSP client is initiated for initial feature selection using Xi0.
- Stage-II (HSP clients): The client nodes will perform feature selection and classification of each fragmented local data of size β using a hybrid MABC with the RB-SVM technique. The updated weights of the local solution are returned to the HSP global orchestrator from every HSP client.
- Stage-III (HSP global orchestrator): Upon reception of the weights from every HSP client, it performs the matched averaging and obtains an updated weight N for the current round of communication.
- Stage-IV (finalization at HSP global orchestrator): The updated weights N are computed until there is no evolution in the HSP client models.
| Algorithm 1: Proposed hybrid FL-based framework for heart disease prediction |
| Input: CVD Data from HSP clients {HC1, HC2, - - -, HCN} Output: Privacy aware model for heart disease at HSP client user N // Computation at the HSP global orchestrator:
|
5. Experimental Evaluation and Validation
5.1. Simulation Setup
5.2. Dataset Description
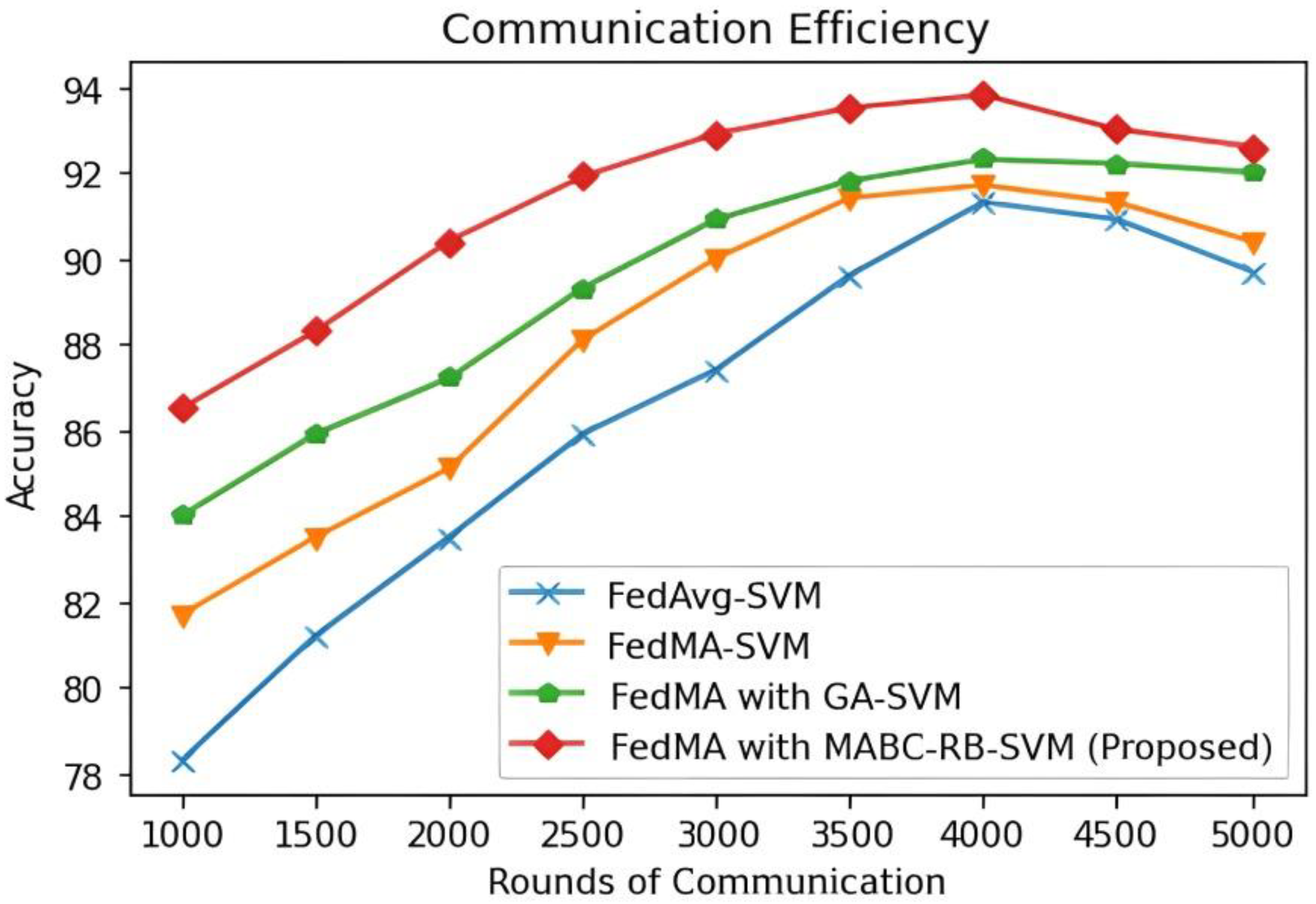
5.3. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turjman, F.A.; Nawaz, M.H.; Uluser, U.D. Intelligence in the Internet of Medical Things era: A systematic review of current and future trends. Comput. Commun. 2020, 150, 644–660. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Watkins, D.A.; Beaton, A.Z.; Carapetis, J.R.; Karthikeyan, G.; Mayosi, B.M.; Wyber, R.; Yacoub, M.H.; Zühlke, L.J. Rheumatic heart disease worldwide: JACC scientific expert panel. J. Am. Coll. Cardiol. 2018, 72, 1397–1416. [Google Scholar] [CrossRef] [PubMed]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Li, J.P.; Haq, A.U.; Din, S.U.; Khan, J.; Khan, A.; Saboor, A. Heart Disease Identification Method Using Machine Learning Classification in E-Healthcare. IEEE Access 2020, 8, 107562–107582. [Google Scholar] [CrossRef]
- Voigt, P.; dem Bussche, A.V. Scope of application of the GDPR. In The EU General Data Protection Regulation; Springer: Cham, Switzerland, 2017; pp. 9–30. [Google Scholar]
- Wagner, J. China’s Cybersecurity Law: What You Need to Know. The Diplomat. 2017. Available online: https://thediplomat.com/2017/06/chinas-cybersecurity-law-what-you-need-to-know/ (accessed on 10 October 2022).
- de la Torre, L. A Guide to the California Consumer Privacy Act of 2018. 2018. Available online: http://dx.doi.org/10.2139/ssrn.3275571 (accessed on 10 October 2022).
- McMahan, B.; Ramage, D. Federated Learning: Collaborative Machine Learning without Centralized Training Data. Google AI Blog 2017. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 11 October 2022).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Areas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yaqoob, M.M.; Nazir, M.; Yousafzai, A.; Khan, M.A.; Shaikh, A.A.; Algarni, A.D.; Elmannai, H. Modified Artificial Bee Colony Based Feature Optimized Federated Learning for Heart Disease Diagnosis in Healthcare. Appl. Sci. 2022, 12, 12080. [Google Scholar] [CrossRef]
- Xu, X.; Liu, W.; Zhang, Y.; Zhang, X.; Dou, W.; Qi, L.; Bhuiyan, M.Z.A. Psdf: Privacy-aware iov service deployment with federated learning in cloud-edge computing. ACM Trans. Intell. Syst. Technol. (TIST) 2022, 13, 70. [Google Scholar] [CrossRef]
- Zhang, X.; Hu, M.; Xia, J.; Wei, T.; Chen, M.; Hu, S. Efficient Federated Learning for Cloud-Based AIoT Applications. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 2211–2223. [Google Scholar] [CrossRef]
- Yang, J.; Zheng, J.; Zhang, Z.; Chen, Q.; Wong, D.S.; Li, Y. Security of federated learning for cloud-edge intelligence collaborative computing. Int. J. Intell. Syst. 2022, 37, 9290–9308. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Xiong, S.; Jayasena, K.P.N.; Li, L. Task scheduling in cloud computing based on hybrid moth search algorithm and differential evolution. Knowl.-Based Syst. 2019, 169, 39–52. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, H.; Heidari, A.A.; Gandomi, A.H. Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Syst. Appl. 2021, 177, 114864. [Google Scholar] [CrossRef]
- Panniem, A.; Puphasuk, P. A Modified Artificial Bee Colony Algorithm with Firefly Algorithm Strategy for Continuous Optimization Problems. J. Appl. Math. 2018, 2018, 1237823. [Google Scholar] [CrossRef]
- Chen, H.L.; Yang, B.; Liu, J.; Liu, D.-Y. A support vector machine classifier with rough set-based feature selection for breast cancer diagnosis. Expert Syst. Appl. 2011, 38, 9014–9022. [Google Scholar] [CrossRef]
- Yadav, D.P.; Saini, P.; Mittal, P. Feature Optimization Based Heart Disease Prediction using Machine Learning. In Proceedings of the 2021 5th IEEE International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 22–23 October 2021; pp. 1–5. [Google Scholar]
- Abdulrahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond. IEEE Internet Things J. 2021, 8, 5476–5497. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning (DIDL), Rennes France, 10–11 December 2018; ACM: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Aledhari, M.; Razzak, R.; Parizi, R.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Ma, Z.; Mengying, Z.; Cai, X.; Jia, Z. Fast-convergent federated learning with class-weighted aggregation. J. Syst. Archit. 2021, 117, 102125. [Google Scholar] [CrossRef]
- Salam, M.A.; Taha, S.; Ramadan, M. COVID-19 detection using federated machine learning. PLoS ONE 2021, 16, e0252573. [Google Scholar]
- Cheng, W.; Ou, W.; Yin, X.; Yan, W.; Liu, D.; Liu, C. A Privacy-Protection Model for Patients. Secur. Commun. Netw. 2020, 2020, 6647562. [Google Scholar] [CrossRef]
- Fang, L.; Liu, X.; Su, X.; Ye, J.; Dobson, S.; Hui, P.; Tarkoma, S. Bayesian Inference Federated Learning for Heart Rate Prediction. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare, Virtual Event, 19 November 2020; Springer: Cham, Switzerland, 2020; pp. 116–130. [Google Scholar]
- Babar, M.; Khan, M.; Din, A.; Ali, F.; Habib, U.; Kwak, K.S. Intelligent Computation Offloading for IoT Applications in Scalable Edge Computing Using Artificial Bee Colony Optimization. Complexity 2021, 2021, 5563531. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Sehwag, V.; Hosseinalipour, S.; Brinton, C.; Chiang, M.; Poor, H.V. Fast-Convergent Federated Learning. IEEE J. Sel. Areas Commun. 2021, 39, 201–218. [Google Scholar] [CrossRef]
- Manimurugan, S.; Almutairi, S.; Aborokbah, M.; Narmatha, C.; Ganesan, S.; Chilamkurti, N.; Alzaheb, R.A.; Almoamari, H. Two-Stage Classification Model for the Prediction of Heart Disease Using IoMT and Artificial Intelligence. Sensors 2022, 22, 476. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Chen, J.; Zhang, K.; Wu, Y.; Yang, T. A Stable AI-Based Binary and Multiple Class Heart Disease Prediction Model for IoMT. IEEE Trans. Ind. Inform. 2022, 18, 2032–2040. [Google Scholar] [CrossRef]
- Khan, M.A.; Algarni, F. A Healthcare Monitoring System for the Diagnosis of Heart Disease in the IoMT Cloud Environment Using MSSO-ANFIS. IEEE Access 2020, 8, 122259–122269. [Google Scholar] [CrossRef]
- Chhabra, A.; Singh, G.; Kahlon, K.S. Multi-criteria HPC task scheduling on IaaS cloud infrastructures using meta-heuristics. Clust. Comput. 2021, 24, 885–918. [Google Scholar] [CrossRef]
- Li, C.; Hu, X.; Zhang, L. The IoT-based heart disease monitoring system for pervasive healthcare service. Procedia Comput. Sci. 2017, 112, 2328–2334. [Google Scholar] [CrossRef]
- Khan, M.A. An IoT Framework for Heart Disease Prediction Based on MDCNN Classifier. IEEE Access 2020, 8, 34717–34727. [Google Scholar] [CrossRef]
- Sarmah, S.S. An Efficient IoT-Based Patient Monitoring and Heart Disease Prediction System Using Deep Learning Modified Neural Network. IEEE Access 2020, 8, 135784–135797. [Google Scholar] [CrossRef]
- Makhadmeh, Z.A.; Tolba, A. Utilizing IoT wearable medical device for heart disease prediction using higher order Boltzmann model: A classification approach. Measurement 2019, 147, 106815. [Google Scholar] [CrossRef]
- Ganesan, M.; Sivakumar, N. IoT based heart disease prediction and diagnosis model for healthcare using machine learning models. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–5. [Google Scholar]
- Albahri, A.S.; Zaidan, A.A.; Albahri, O.S.; Zaidan, B.B.; Alamoodi, A.H.; Shareef, A.H.; Alwan, J.K.; Hamid, R.A.; Aljbory, M.T.; Jasim, A.N.; et al. Development of IoT-based mhealth framework for various cases of heart disease patients. Health Technol. 2021, 11, 1013–1033. [Google Scholar] [CrossRef]
- Gupta, A.; Yadav, S.; Shahid, S.; Venkanna, U. HeartCare: IoT Based Heart Disease Prediction System. In Proceedings of the 2019 International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 88–93. [Google Scholar]
- Jabeen, F.; Maqsood, M.; Ghanzafar, M.A.; Adil, F.; Khan, S.; Khan, M.F.; Mehmood, I. An IoT based efficient hybrid recommender system for cardiovascular disease. Peer-to-Peer Netw. Appl. 2019, 12, 1263–1276. [Google Scholar] [CrossRef]
- Fedesoriano. Heart Failure Prediction Dataset. Available online: https://www.kaggle.com/fedesoriano/heart-failure-prediction (accessed on 28 November 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Brief Description |
|---|---|
| Xio | Initial vector for MABC at client sites |
| Xri | Local solution chosen randomly |
| Cen | Employed bee’s candidate solution |
| Con | Candidate solution from onlooker bee |
| Csn | Candidate solution obtained by scout bee |
| Fit[n] | Fitness function |
| N | Number of HSP clients |
| Β | Local minibatch at every HSP client |
| o | Initial model by HSP global orchestrator |
| c (wjl, θi) | Similarity function |
| θi | Gaussian mean |
| wjl | Weight of lth neuron on dataset j in MABC |
| E | Local epochs |
| η | Learning rate |
| N | Model of Nth HSP client |
| d | Input dataset to RB-SVM |
| KF | Kernel function |
| DF (d) | Decision function on dataset d in RB-SVM |
| mr | Margin function |
| RBF | Radial basis function |
| S# | Feature | Explanation | Unit | Coded Values |
|---|---|---|---|---|
| 1 | Resting blood pressure (Rt_Bp) | In mmHg | Integer | Low Level = Below 120 = −1 Normal Level = 120–139 = 0 High Level = Above 139 = 1 |
| 2 | Cholesterol serum (Cl_S) | In mg/dL | Integer | <200 mg/dL = Low = −1 200–239 mg/dL = Normal = 0 >240 mg/dL = High = 1 |
| 3 | Chest pain (C_P) | Type of chest pain | String | Angina Typical (AT) = 2 Asymptomatic (AS) = 1 Angina Atypical (ATA) = 0 Non-Angina (NA) = −1 |
| 4 | Max heart rate (MHR) | Maximum achieved heart rate in bpm | Integer | <69 bpm = Low = −1 70–90 bpm = Normal = 0 >91 bpm = High = 1 |
| 5 | Depression level (Dp_L) | Old peak in ST (numeric value measured for depression level) | Float | <0.5 mm = Normal = 0 >0.5 mm = High = 1 |
| 6 | Resting electrocardiogram (Rt_ECG) | Normal, ST T, or LVH | String | LVH = 2 ST T = 1 Normal = 0 |
| 7 | Angina induced by exercise (AI_bE) | Yes or No | String | Yes = 1 No = 0 |
| 8 | Fasting blood sugar (F_BS) | >120 mg/dL | Integer | True = 1 False = 0 |
| 9 | ST slope (ST_S) | Peak exercise slope | String | Up = 2 Flat = 1 Down = 0 |
| 10 | Age (A) | Age in years | Integer | >77 = 2, 64–77 = 1, 47–63 = 0, 35–46 = −1, <35 = −2 |
| 11 | Sex (S) | Female and Male | String | Female = 0, Male = 1 |
| 12 | Target (heart disease) | Yes or No | Integer | Yes = 1, No = 0 |
| Techniques | Max. Accuracy Achieved | # Of Rounds to Reach 91% | Difference |
|---|---|---|---|
| FedAvg-SVM | 91.3 | 3810 | -- |
| FedMA-SVM | 91.7 | 3425 | 10.1% |
| FedMA with GA-SVM | 92.3 | 3046 | 20.1% |
| FedMA with MABC-RB-SVM (Proposed) | 93.8 | 2408 | 37.8% |
| Techniques | Accuracy | F-Measure | Precision | Classification Error | Sensitivity | Specificity |
|---|---|---|---|---|---|---|
| FedAvg-SVM | 91.3 | 87.3 | 92.3 | 20.4 | 85.3 | 59.5 |
| FedMA-SVM | 91.7 | 88.4 | 90.1 | 18.6 | 89.5 | 72.5 |
| FedMA with GA-SVM | 92.3 | 89.6 | 93.7 | 13.3 | 91.9 | 78.8 |
| FedMA with MABC-RB-SVM (Proposed) | 93.8 | 90.1 | 94.2 | 11.9 | 96.6 | 81.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaqoob, M.M.; Nazir, M.; Khan, M.A.; Qureshi, S.; Al-Rasheed, A. Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction. Appl. Sci. 2023, 13, 1911. https://doi.org/10.3390/app13031911
Yaqoob MM, Nazir M, Khan MA, Qureshi S, Al-Rasheed A. Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction. Applied Sciences. 2023; 13(3):1911. https://doi.org/10.3390/app13031911
Chicago/Turabian StyleYaqoob, Muhammad Mateen, Muhammad Nazir, Muhammad Amir Khan, Sajida Qureshi, and Amal Al-Rasheed. 2023. "Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction" Applied Sciences 13, no. 3: 1911. https://doi.org/10.3390/app13031911
APA StyleYaqoob, M. M., Nazir, M., Khan, M. A., Qureshi, S., & Al-Rasheed, A. (2023). Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction. Applied Sciences, 13(3), 1911. https://doi.org/10.3390/app13031911