


Blockchain-Based Decentralized Federated Learning Method in Edge Computing Environment

Abstract
1. Introduction
- We propose the BD-FL by combining blockchain with federated learning in the edge computing environment. BD-FL uses the distributed characteristics of blockchain and edge computing to solve the problem of a centralized server in that the local device trains the local model and the edge server aggregates the global model. BD-FT also introduces an incentive mechanism to encourage local devices to actively participate in model training, increasing the number of samples and improving the model accuracy.
- We propose a preference-based stable matching algorithm in BD-FT, which binds local devices to appropriate edge servers, improving the utilization of edge server resources and reducing the delay of data transmission. We propose the R-PBFT algorithm, which optimizes the network topology and the consistency protocol and designs a dynamic reputation mechanism, reducing the communication overhead of the blockchain consensus process and improving the model training efficiency.
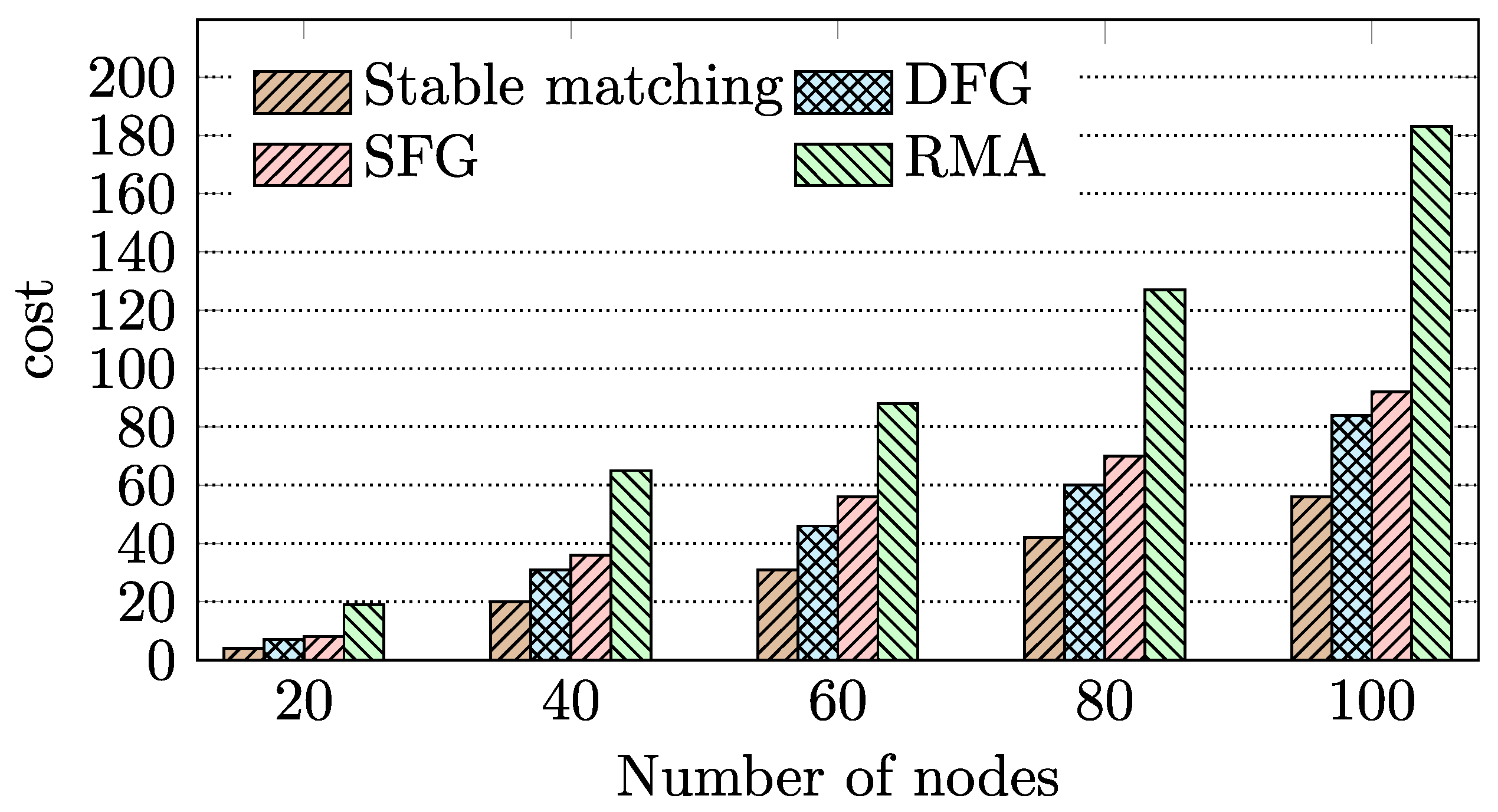
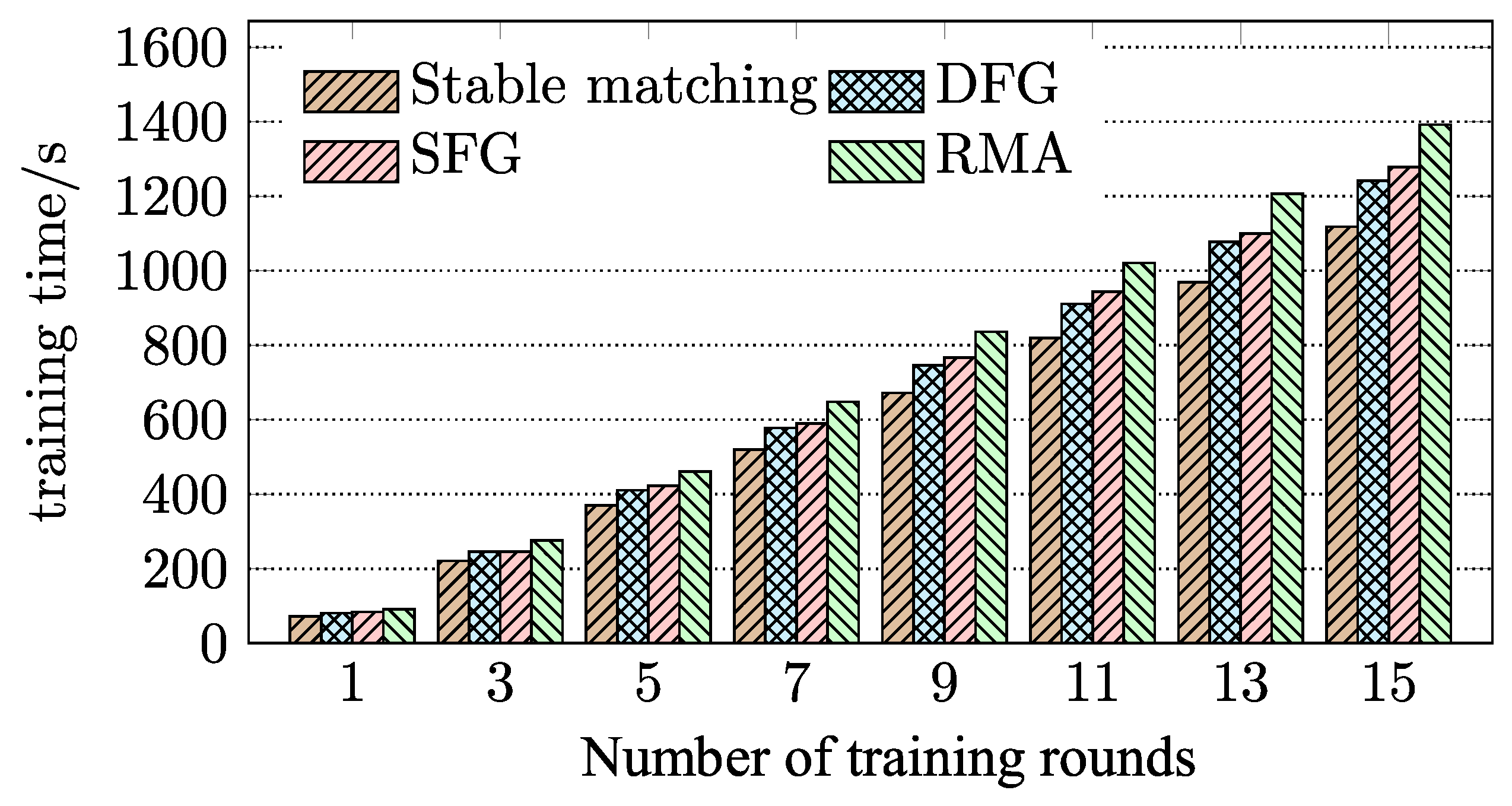
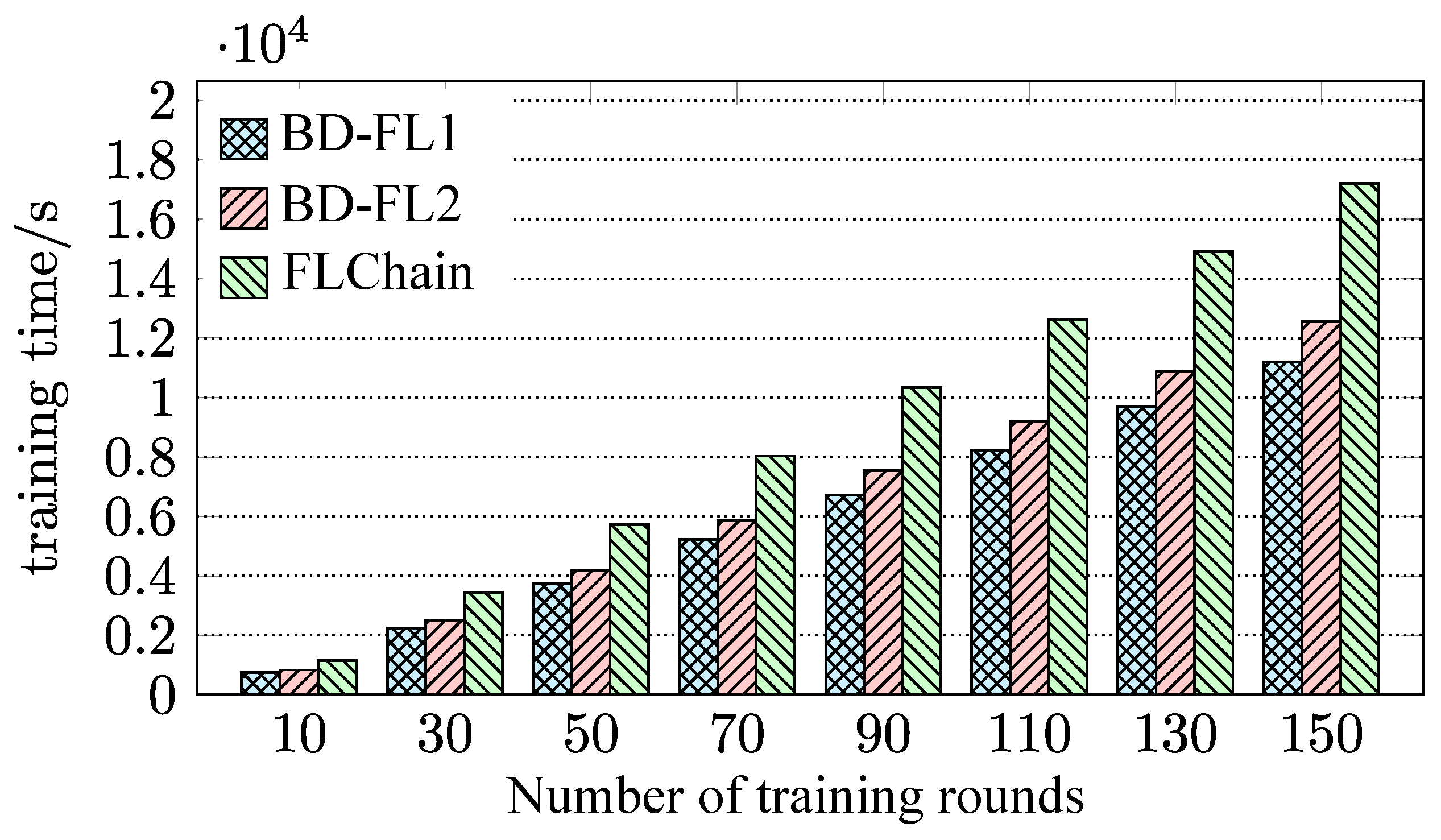
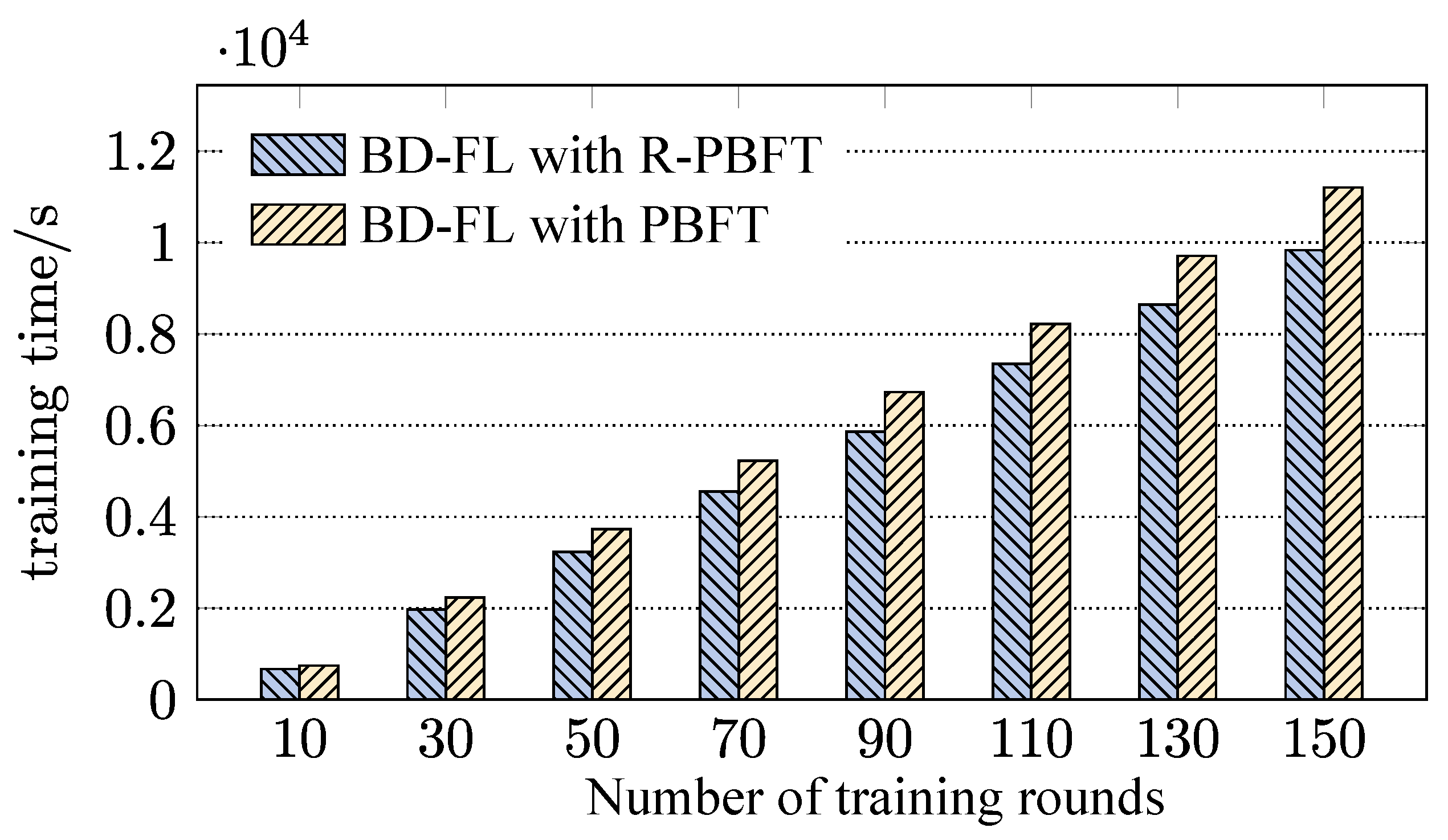
- We performed extensive simulation experiments to evaluate the proposed BD-FL. Experimental results show that BD-FL effectively reduces the model training time by up to 19.7% and 34.9%, respectively, compared with several federated learning methods with different matching algorithms and a state-of-the-art blockchain-based federated learning method. The R-PBFT algorithm can reduce the communication overhead of the consensus process and improve the training efficiency of BD-FL by 12.2%.
2. Related Work
3. Methodology
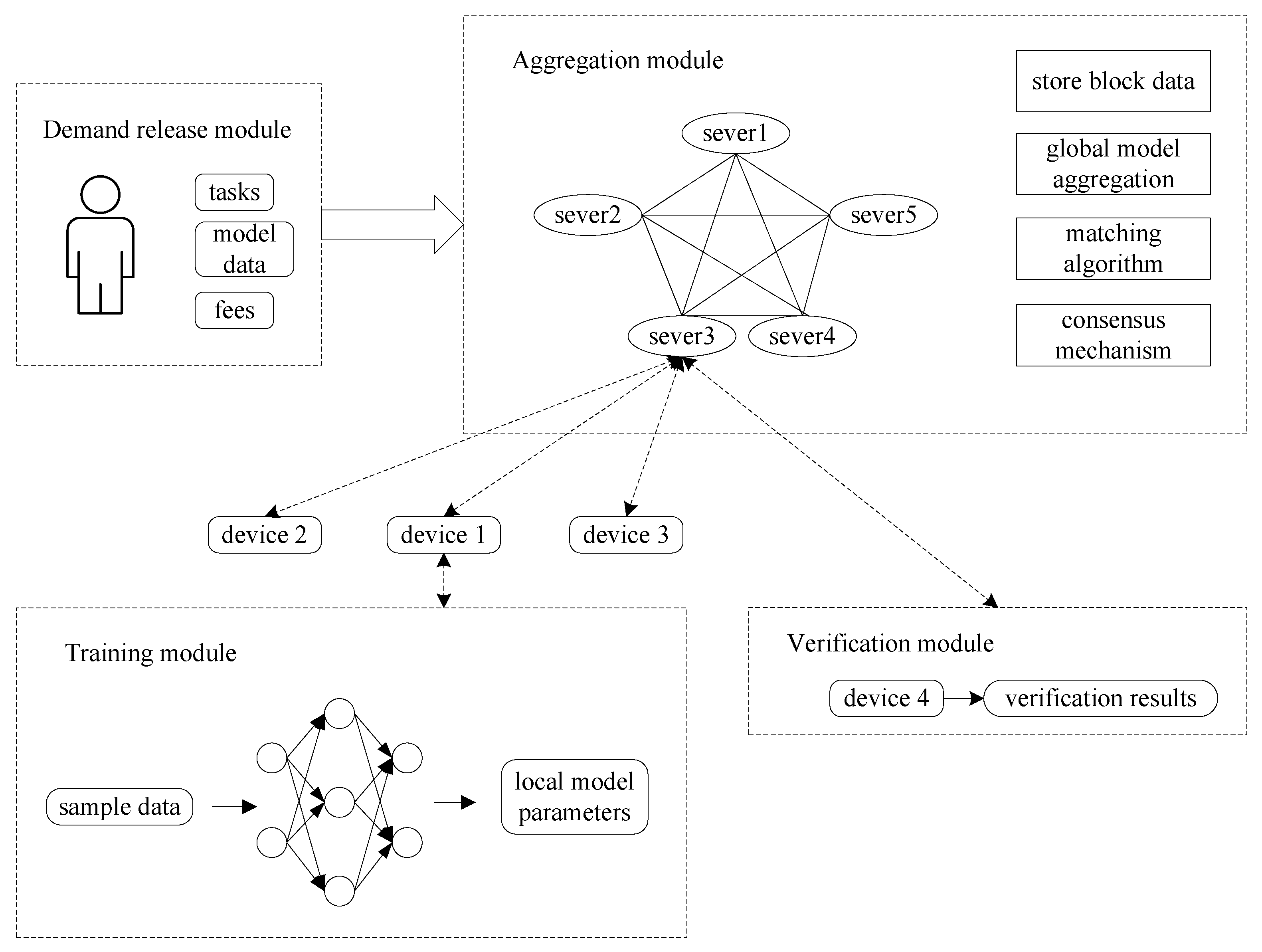
3.1. System Architecture
3.2. Incentive Mechanism
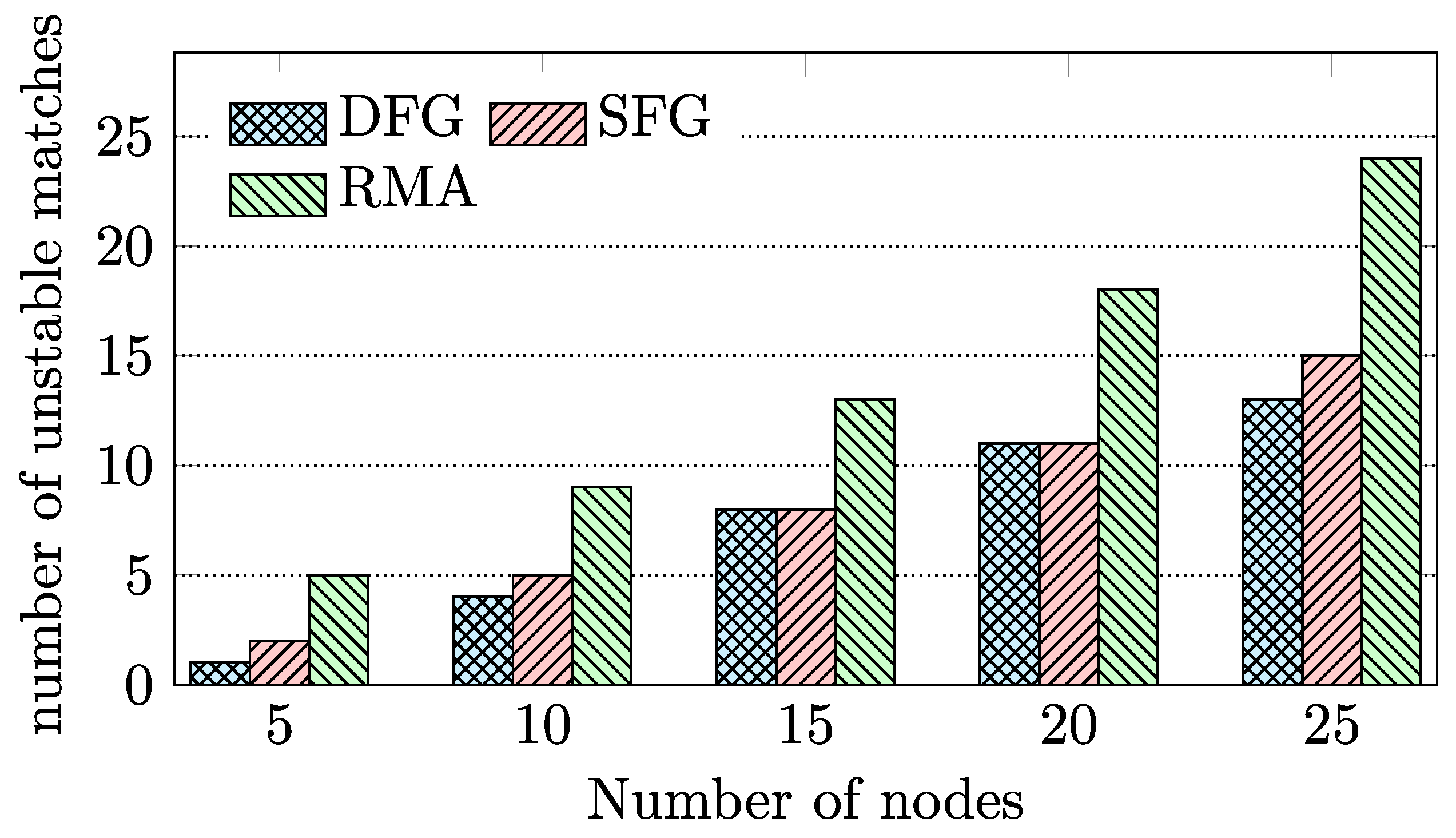
3.3. Preference-Based Stable Matching Algorithm
| Algorithm 1 Preference-based stable matching algorithm. |
|
3.4. R-PBFT Consensus Algorithm
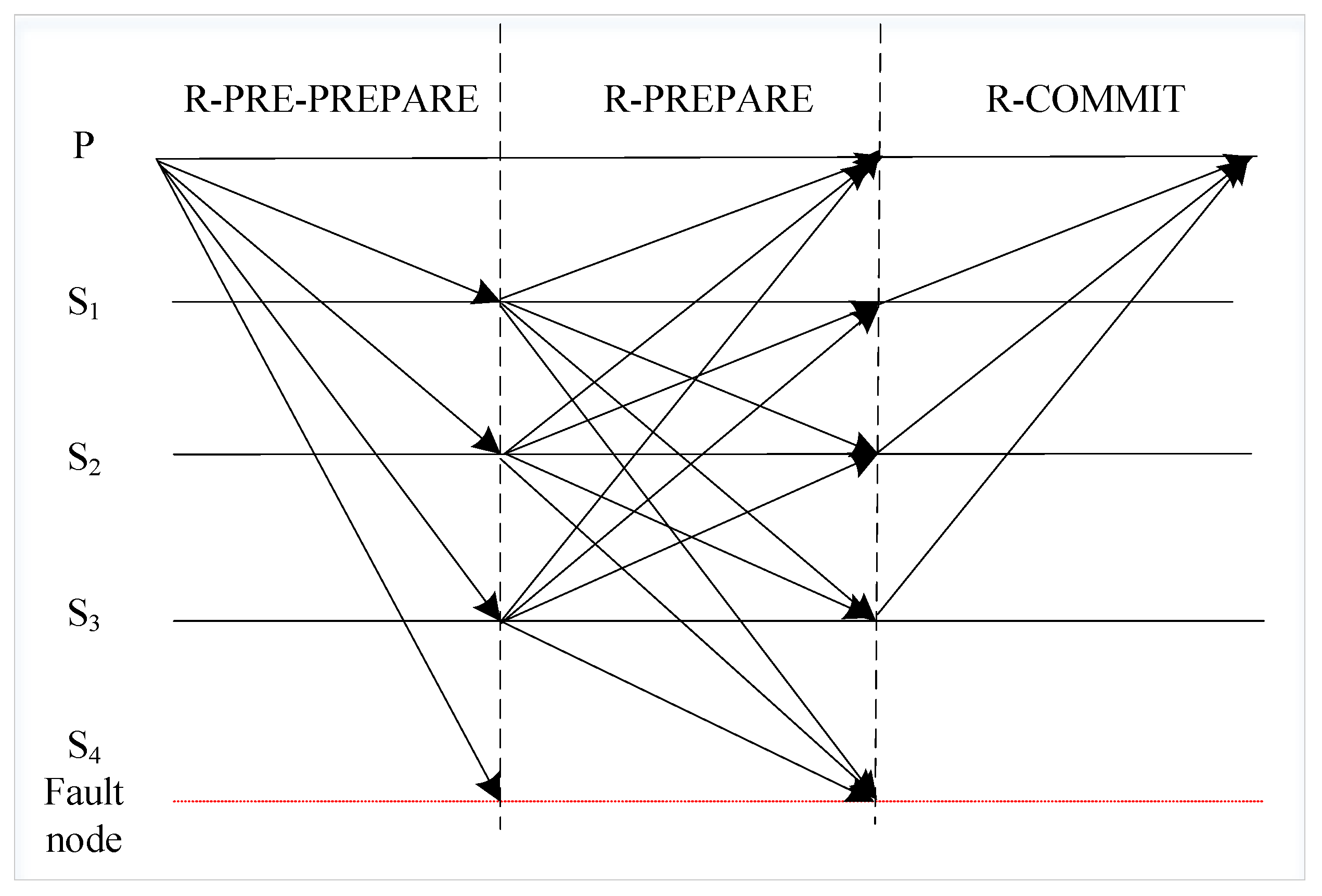
- Remove the client node. In the traditional PBFT algorithm, the request phase and the reply phase occur between the client and the master nodes. However, in the blockchain structure, information is broadcast between nodes in the form of P2P, without the participation of the client. Therefore, we remove the request and reply phases of the client node in the consistency protocol, modify the C/S structure of PBFT to a distributed topology, and divide all nodes into master and slave nodes.
- Optimize the consistency protocol. The five phases of consensus in PBFT are changed to three phases, including the pre-preparation phase, preparation phase, and confirmation phase. In the pre-preparation phase, the master node broadcasts blocks to other slave nodes. In the preparation phase, the slave node broadcasts the block verification results to other slave nodes and master nodes. In the confirmation phase, traditional PBFT requires mutual interaction between nodes. We simplify it as all slave nodes send verification results to the master node, and the master node makes a decision on the consensus results, thus reducing the communication overhead of consensus.
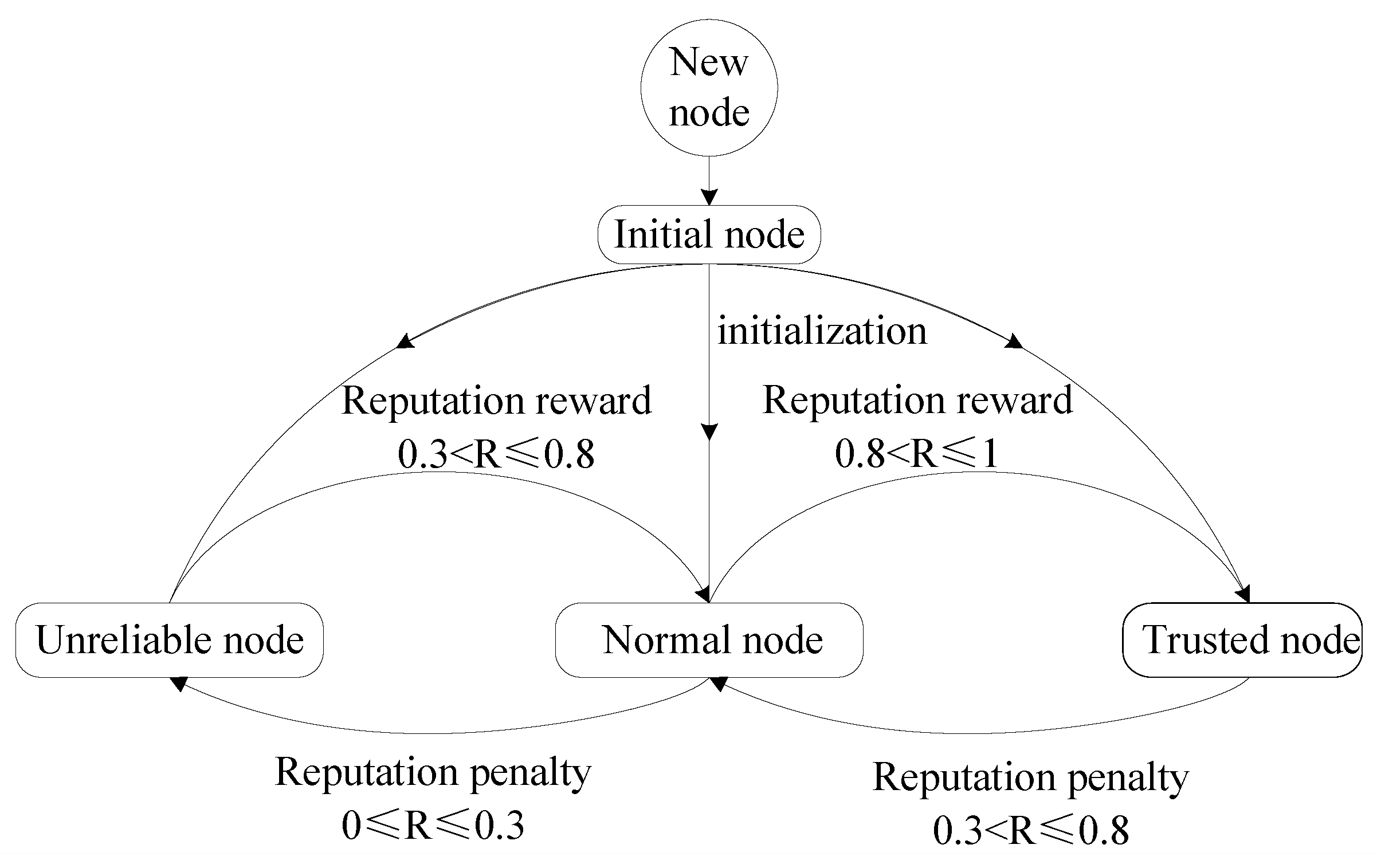
- Introduce reputation mechanism. The main purpose of the reputation mechanism is to make the nodes with high reliability easier to be elected as the master node. Each node will be divided into different reputation levels according to the reputation value, and then each node will be rewarded or punished based on its performance in each round of consensus. According to a preset reputation threshold, nodes can be dynamically transformed in different reputation levels.
3.5. Training of BD-FL
| Algorithm 2 BD-FL training. |
|
4. Experiments and Results
4.1. Experiment Setting
4.2. Evaluation of BD-FL
4.3. Evaluation of R-PBFT
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vinod, D.; Bharathiraja, N.; Anand, M.; Antonidoss, A. An improved security assurance model for collaborating small material business processes. Mater. Today Proc. 2021, 46, 4077–4081. [Google Scholar] [CrossRef]
- Zhang, Q.; Ding, Q.; Zhu, J.; Li, D. Blockchain empowered reliable federated learning by worker selection: A trustworthy reputation evaluation method. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Tomovic, S.; Yoshigoe, K.; Maljevic, I.; Radusinovic, I. Software-defined fog network architecture for IoT. Wirel. Pers. Commun. 2017, 92, 181–196. [Google Scholar] [CrossRef]
- Hu, Y.; Niu, D.; Yang, J.; Zhou, S. FDML: A collaborative machine learning framework for distributed features. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2232–2240. [Google Scholar]
- Nakamoto, S.; Bitcoin, A. A peer-to-peer electronic cash system. Bitcoin 2008, 4, 2. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 1 January 2023).
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Gao, P.; Hua, X.; Zhang, D.; Jiang, T. Multi-UAV network assisted intelligent edge computing: Challenges and opportunities. China Commun. 2022, 19, 258–278. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, W.; Yang, S.; Wang, X. Falcon: A blockchain-based edge service migration framework in MEC. Mobile Inf. Syst. 2020, 2020, 8820507. [Google Scholar] [CrossRef]
- Guo, F.; Yu, F.R.; Zhang, H.; Ji, H.; Liu, M.; Leung, V.C. Adaptive resource allocation in future wireless networks with blockchain and mobile edge computing. IEEE Trans. Wirel. Commun. 2019, 19, 1689–1703. [Google Scholar] [CrossRef]
- Shahryari, O.K.; Pedram, H.; Khajehvand, V.; TakhtFooladi, M.D. Energy and task completion time trade-off for task offloading in fog-enabled IoT networks. Pervasive Mob. Comput. 2021, 74, 101395. [Google Scholar] [CrossRef]
- Yang, S.; Han, K.; Zheng, Z.; Tang, S.; Wu, F. Towards personalized task matching in mobile crowdsensing via fine-grained user profiling. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 2411–2419. [Google Scholar]
- Bharathiraja, N.; Padmaja, P.; Rajeshwari, S.; Kallimani, J.S.; Buttar, A.M.; Lingaiah, T.B. Elite Oppositional Farmland Fertility Optimization Based Node Localization Technique for Wireless Networks. In Proceedings of the Wireless Communications and Mobile Computing, Dubrovnik, Croatia, 30 May–3 June 2022; Volume 2022. [Google Scholar]
- Vasin, P. Blackcoin’s Proof-of-Stake Protocol v2. 2014. Volume 71. Available online: https://blackcoin.co/blackcoin-pos-protocol-v2-whitepaper.pdf (accessed on 1 January 2023).
- Liu, D.; Camp, L.J. Proof of Work can Work. In Proceedings of the 5th Annual Workshop on the Economics of Information Security, Robinson College, University of Cambridge, England, UK, 26–28 June 2006; Available online: https://econinfosec.org/archive/weis2006/docs/50.pdf (accessed on 1 January 2023).
- Yang, F.; Zhou, W.; Wu, Q.; Long, R.; Xiong, N.N.; Zhou, M. Delegated proof of stake with downgrade: A secure and efficient blockchain consensus algorithm with downgrade mechanism. IEEE Access 2019, 7, 118541–118555. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical Byzantine Fault Tolerance. ACM Trans. Comput. Syst. (TOCS) 2002, 20, 398–461. [Google Scholar] [CrossRef]
- Bao, X.; Su, C.; Xiong, Y.; Huang, W.; Hu, Y. FLChain: A blockchain for auditable federated learning with trust and incentive. In Proceedings of the 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), Qingdao, China, 9–11 August 2019; pp. 151–159. [Google Scholar]
- Nofer, M.; Gomber, P.; Hinz, O.; Schiereck, D. Blockchain. Bus. Inf. Syst. Eng. 2017, 59, 183–187. [Google Scholar] [CrossRef]
- Zheng, Z.; Xie, S.; Dai, H.N.; Chen, X.; Wang, H. Blockchain challenges and opportunities: A survey. Int. J. Web Grid Serv. 2018, 14, 352–375. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2438–2455. [Google Scholar] [CrossRef]
- Jia, R.; Dao, D.; Wang, B.; Hubis, F.A.; Hynes, N.; Gürel, N.M.; Li, B.; Zhang, C.; Song, D.; Spanos, C.J. Towards efficient data valuation based on the shapley value. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, PMLR, Naha, Okinawa, Japan, 16–18 April 2019; pp. 1167–1176. [Google Scholar]
- Hu, G.; Jia, Y.; Chen, Z. Multi-user computation offloading with d2d for mobile edge computing. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Wu, D. Research on multi-task multi-device matching algorithm based on machine learning. Master’s Thesis, Zhe Jiang University, Hangzhou, China, 2019. [Google Scholar]
- Lu, X.; Liao, Y.; Lio, P.; Hui, P. Privacy-preserving asynchronous federated learning mechanism for edge network computing. IEEE Access 2020, 8, 48970–48981. [Google Scholar] [CrossRef]
- Zheng, H.; Guo, W.; Xiong, N. A kernel-based compressive sensing approach for mobile data gathering in wireless sensor network systems. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 2315–2327. [Google Scholar] [CrossRef]
- Ma, S.; Cao, Y.; Xiong, L. Transparent contribution evaluation for secure federated learning on blockchain. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering Workshops (ICDEW), Chania, Greece, 19–22 April 2021; pp. 88–91. [Google Scholar]
- Gao, S.; Yu, T.; Zhu, J.; Cai, W. T-PBFT: An EigenTrust-based practical Byzantine fault tolerance consensus algorithm. China Commun. 2019, 16, 111–123. [Google Scholar] [CrossRef]
- Liu, J.; Li, W.; Karame, G.O.; Asokan, N. Scalable byzantine consensus via hardware-assisted secret sharing. IEEE Trans. Comput. 2018, 68, 139–151. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Z.; Cheng, T. Improvement research of PBFT consensus algorithm based on credit. In International Conference on Blockchain and Trustworthy Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 47–59. [Google Scholar]
- Yu, G.; Wu, B.; Niu, X. Improved blockchain consensus mechanism based on PBFT algorithm. In Proceedings of the 2020 2nd International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 10–12 July 2020; pp. 14–21. [Google Scholar]
- Nithya, G.; Engels, R.; Das, H.R.; Jayapratha, G. A Novel-Based Multi-agent Brokering Approach for Job Scheduling in a Cloud Environment. In Informatics and Communication Technologies for Societal Development; Springer: Berlin/Heidelberg, Germany, 2015; pp. 71–84. [Google Scholar]
- Hochman, H.M.; Rodgers, J.D. Pareto optimal redistribution. Am. Econ. Rev. 1969, 59, 542–557. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Parameters | Value |
|---|---|
| Network Bandwidth | 20 MHz |
| Shooting Power | 200 mW |
| Power Spectral Density | −95 dbm/Hz |
| Uplink Data Size | [3000, 4000] kb |
| 0.5,0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Wang, X.; Hui, L.; Wu, W. Blockchain-Based Decentralized Federated Learning Method in Edge Computing Environment. Appl. Sci. 2023, 13, 1677. https://doi.org/10.3390/app13031677
Liu S, Wang X, Hui L, Wu W. Blockchain-Based Decentralized Federated Learning Method in Edge Computing Environment. Applied Sciences. 2023; 13(3):1677. https://doi.org/10.3390/app13031677
Chicago/Turabian StyleLiu, Song, Xiong Wang, Longshuo Hui, and Weiguo Wu. 2023. "Blockchain-Based Decentralized Federated Learning Method in Edge Computing Environment" Applied Sciences 13, no. 3: 1677. https://doi.org/10.3390/app13031677
APA StyleLiu, S., Wang, X., Hui, L., & Wu, W. (2023). Blockchain-Based Decentralized Federated Learning Method in Edge Computing Environment. Applied Sciences, 13(3), 1677. https://doi.org/10.3390/app13031677