1. Introduction
In recent years, automatic text summarization has made strides mainly due to two factors: the success of Deep Learning models and the use of a large amount of information available on the web for building large corpora in order to train the Deep Learning models. The automatic text summarization problem has been addressed in the literature using abstractive, extractive, or mixed approaches. Extractive approaches compose summaries by selecting sentences or words directly from the documents, whereas abstractive approaches build the summaries by paraphrasing/rewriting the sentences of the documents. Furthermore, there are also mixed strategies that combine extractive and abstractive techniques, performed in a decoupled way or simultaneously during the training of the models. Recently, an important effort has been made to develop abstractive methods. However, extractive approaches are still important in summarization, since they maintain the coherence, the factuality, and do not hallucinate like abstractive approaches do. Additionally, selecting sentences is also important for other tasks such as Text Classification, Question Answering and Information Extraction.
Some successful approaches to extractive summarization are based on graph representations of the documents. This is the case with LexRank [
1] and TextRank [
2,
3,
4,
5], among others. Other approaches are based on Neural Networks. Typically, these neural network-based approaches have been addressed as a sequential binary sentence classification problem [
6,
7,
8,
9,
10,
11,
12,
13,
14]. However, the available corpora do not directly provide this kind of labeling for training purposes since, in general, corpora only consist of (document, summary) pairs. In order to label the document sentences, prior to the training of the model, the most common strategy consists of using suboptimal extractive oracles [
6,
7,
8,
9]. Additionally, several unsupervised approaches for extractive summarization have been proposed by Joshi et al. [
15], and Mohd et al. [
16]. Recently, Reinforcement Learning strategies have been extensively applied [
10,
11,
12,
13] in order to dispense with the sentence labeling and optimizing directly the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metric [
17].
The research objective of this work is to present in detail the general theoretical framework for extractive summarization called Attentional Extractive Summarization. Our proposal dispenses with the sentence labeling, avoiding the large computational cost required to compute near-optimal solutions, and allowing us to address the summarization problem in a simpler way than Reinforcement Learning techniques. Specifically, our proposal is based on the interpretation of the attention mechanisms of neural models that are trained to distinguish correct summaries for documents. It should be noted that it is only required a binary signal in order to train the model instead of sentence labeling. This training allows our system to learn relationships among document and summary sentences, and to replace the binary sequential sentence classification with a binary classification among documents and summaries. After the training of the model, it is possible to select the most attended sentences by focusing on the document sentence attentions computed by the model.
The
Attentional Extractive Summarization framework was proposed with the aim of generalizing our previous proposals in extractive summarization and boosting future works and improvements under this framework. Gonzalez et al. [
18] proposed a Siamese neural model based on Hierarchical Attention Networks [
19]. Later, in [
20], an extension to other types of attention mechanisms, in particular, to multi-head self-attention mechanisms of the Transformer Encoders [
21], was proposed by Gonzalez et al. In this work, these two systems are also instantiated under the proposed framework, replacing each theoretical component by concrete neural network-based approaches such as Hierarchical Attention Networks or Hierarchical Transformer Encoders to compute sentence and document representations, and attention mechanisms to compute sentence scores. Therefore, the proposed framework also allows the development of novel summarization systems, in addition to those presented in this work. For example, a system based on Hierarchical Convolutional Neural Networks, trained to distinguish correct summaries for documents and that relies on statistics such as the norm of the activations in order to compute sentence scores, would also fall under the umbrella of our framework. The performances of our systems were evaluated and studied on the CNN/DailyMail [
22] and NewsRoom [
23] corpora, comparing them with more recent systems based on diverse strategies (extractive and mixed summarization systems based on oracles or reinforcement learning). A preliminary version of this work has been presented in Gonzalez et al. [
24].
In this paper, the theoretical framework is presented in detail: two systems ([
18,
20]) previously proposed by Gonzalez et al. were instantiated under the
Attentional Extractive Summarization framework, an extensive evaluation of the systems on CNN/DailyMail and NewsRoom corpora was performed, showing that our systems are competitive with other extractive and mixed state-of-the-art systems. A detailed analysis of the results was performed, including the convergence of our models and the word-length distribution of system generated summaries and, finally, several examples are provided to illustrate the generated summaries and the attention weights used to score the sentences.
This paper is organized as follows. In
Section 2, the state-of-the-art systems for extractive and mixed summarization, which were compared to our proposal for the CNN/DailyMail and NewsRoom corpora, are described. In
Section 3, the main characteristics of our
Attentional Extractive Summarization framework are introduced, to be formalized in
Section 4. In
Section 5, two systems that fall under the umbrella of our framework are defined. In
Section 6 and
Section 7, the corpora and the hyper-parameters of the systems are presented, respectively. In
Section 8, our systems were compared to other state-of-the-art systems for the CNN/DailyMail and NewsRoom corpora. In
Section 9, several analyses of the behavior of the proposed systems were performed. Finally, in
Section 10, some conclusions and future works are presented.
2. Related Work
In this section, different approaches to extractive and mixed summarization are described, in particular those state-of-the-art systems used in the experimental comparison of this work. Recently, the construction of large corpora [
22,
23,
25,
26] has allowed the training of Deep Learning systems for the automatic summarization problem.
A very robust baseline used commonly in newspaper summarization is the Lead system. It is based on extracting the first k sentences of the documents to compose a summary. Although it seems naive, it is especially robust when it is applied to articles in newspapers, since in this domain, generally, the first sentences are dedicated to condensing the information of the whole document and they are used to attract the reader’s attention.
Extractive approaches can be divided into two different categories: those which use an oracle algorithm to label the sentences of the documents before training the models, and those which directly optimize the ROUGE evaluation metric by means of Reinforcement Learning strategies.
Regarding the extractive systems based on oracles, the first approaches were proposed by Cheng et al. [
6] and Nallapati et al. [
7]. In [
6], an encoder-decoder approach for extractive single-document summarization was proposed. In [
7] (SummaRunner), Nallapati et al. presented two versions of Hierarchical Attention Networks to select sentences from the documents as a binary sequence classification problem. One of these versions is trained using the samples provided by the corpus without a previous sentence labeling. The other version requires a greedy algorithm as an oracle for labeling the corpus at sentence level, selecting as a reference summary the set of sentences from the document that maximize the similarity with respect to the reference summary. Recently, the great impact of the Transformer architecture [
21] in Natural Language Processing tasks, and particularly in language modeling [
27], has boosted the results in automatic summarization by fine-tuning powerful pre-trained language models. The most relevant example is the BertSumEXT system [
8], which is based on the fine-tuning of pre-trained Bidirectional Encoder Representations from Transformers (BERT) models [
27]. Liu et al. [
8] also proposed abstractive and mixed strategies for generating summaries starting from the pre-trained BERT.
Reinforcement Learning strategies for automatic summarization have received great interest from the research community. Despite the first works on Reinforcement Learning being intended to perform abstractive summarization by Paulus et al. [
28], recently these strategies have been widely used for extractive text summarization, directly optimizing the ROUGE evaluation measure [
10,
11,
12,
13,
14]. Narayan et al. [
10] argued about the application of cross-entropy with ground-truth sentence labels to optimize neural summarization models, and they proposed the application of the REINFORCE algorithm [
29] for extractive summarization in order to train a hierarchical encoder-decoder. Zhang et al. [
11] also discussed the suboptimal nature of the labels obtained using oracles. They presented a latent variable extractive model, which can also be viewed as a Reinforcement Learning approach, where the reward is defined as a weighted sum of two measures related to the precision and the recall. These measures were computed from the likelihood of a summary sentence and a document sentence, estimated using an attention-based sequence-to-sequence sentence compression model. This system can be trained in an extractive (Latent) or in a compressive way (Latent-Comp). A theoretically grounded method (BanditSum) was proposed by Dong et al. [
12] to model the extractive summarization problem by means of a bandit formalism. They proposed a novel structure for computing the conditional probability of a subset of document sentences given the document, which avoids privileging early sentences over later ones. An approach based on Deep Q Learning (DQN) was proposed by Yaok et al. [
13]. This approach is based on an iterative decision problem, where a sentence is selected at each step. After each sentence selection, the state of the model is updated and the selected sentence is added to the summary state.
Recently, the interest in mixed strategies has increased. These approaches are typically based on first extracting a set of sentences and later adapting them to the reference summaries, e.g., Mendes et al. proposed compressing [
30] and Chen et al. proposed paraphrasing [
14]. In [
30], they proposed a compressive approach that removes unnecessary words while keeping the summaries informative, concise, and grammatically correct. The model can be trained in an extractive way (ExConSumm-Ext) and in a compressive way (ExConSumm-Comp). In [
14], they proposed a sentence-level policy gradient method to first select salient sentences and then to paraphrase them (Fast-RL). Other types of mixed strategies are those based on selecting or generating a new word at each step as in See et al. [
31], or Ive et al. [
32]. The most relevant example is [
31], where an approach based on Pointer Networks and encoder-decoder models with attention mechanisms is proposed. Moreover, in order to address the word repetition problem, the authors enrich their system by using a coverage mechanism based on the encoder attentions of previous steps, for each decoder step (PointerGen+Cov). This system has been modified by the authors of [
32], replacing Long Short Term Memories [
33] with Transformers [
21].
In this work, a theoretical framework for extractive summarization is proposed. It is based on the interpretability of the attention mechanisms proposed by Vaswani et al. [
34] of Siamese hierarchical networks trained for distinguishing correct summaries for documents. Differently from the extractive approaches discussed before in this section, our approach is able to learn directly relationships among document and summary sentences, dispensing with extractive oracles and with the sequential sentence labeling. (A similar paradigm that addresses extractive summarization as a semantic matching problem has been explored recently in the literature [
9]). Two systems that fall under the umbrella of the
Attentional Extractive Summarization framework, were previously proposed by Gonzalez et al.: Siamese Hierarchical Attention Neural Networks [
18] (SHA-NN) and Siamese Hierarchical Transformer Encoders [
20] (SHTE). They are discussed in more detail in
Section 5.
3. Attentional Extractive Summarization Framework
As pointed out before, approaches that do not rely on Reinforcement Learning strategies to directly optimize the ROUGE evaluation metric, are mainly based on the use of suboptimal oracle algorithms since they require a binary sentence labeling in order to be trained. These approaches typically consist of using oracle systems to label the sentences by following some evaluation measures such as ROUGE. In the paper of Narayan et al. [
10], two types of oracles are distinguished: individual oracles, that label each sentence independently (e.g., semantic similarity above a threshold) and collective oracles that consider dependencies among sentences (e.g., greedy algorithms to search combinations of document sentences that maximize the ROUGE with respect to the reference summary). As stated in [
10], the problem of the first type of oracles is that they often generate too many positive labels, causing the model to overfit the data. In the other case, the main problem is related to the underfitting, since the models trained with cross-entropy loss on collective labels will only maximize probabilities for the sentences in the selected sets. Collective oracles are common in the literature [
7,
8,
30,
35,
36].
To require a sentence labeling for training the systems has several drawbacks. First, the labeling is suboptimal and it can fall in local optimum, leading the model to be trained with non-relevant sentences or missing relevant ones as it is shown in Zhang et al. [
11]. Second, this problem becomes more complex for large corpora, where obtaining oracles can be computationally intensive if near-optimal solutions are preferred. Furthermore, the sequential classification, where each sentence is classified taking into account its dependencies with all the other sentences in the document, is a complex problem that can be simplified.
Our proposal allows the systems to learn by themselves relationships among the sentences of documents and reference summaries. These relationships are learned by attention mechanisms, that are interpreted to extract the most relevant document sentences. In order to learn these relationships and to avoid training with a sequential classification problem on sequences of labeled sentences, we propose to address the summarization task as a binary classification problem where correct summaries are distinguished from incorrect summaries for documents. (We consider as incorrect summaries, for a given document, the reference summaries of other documents in the corpora.) This way, it is only required a binary signal in order to train the models, instead of sentence labeling. We call this proposal Attentional Extractive Summarization framework.
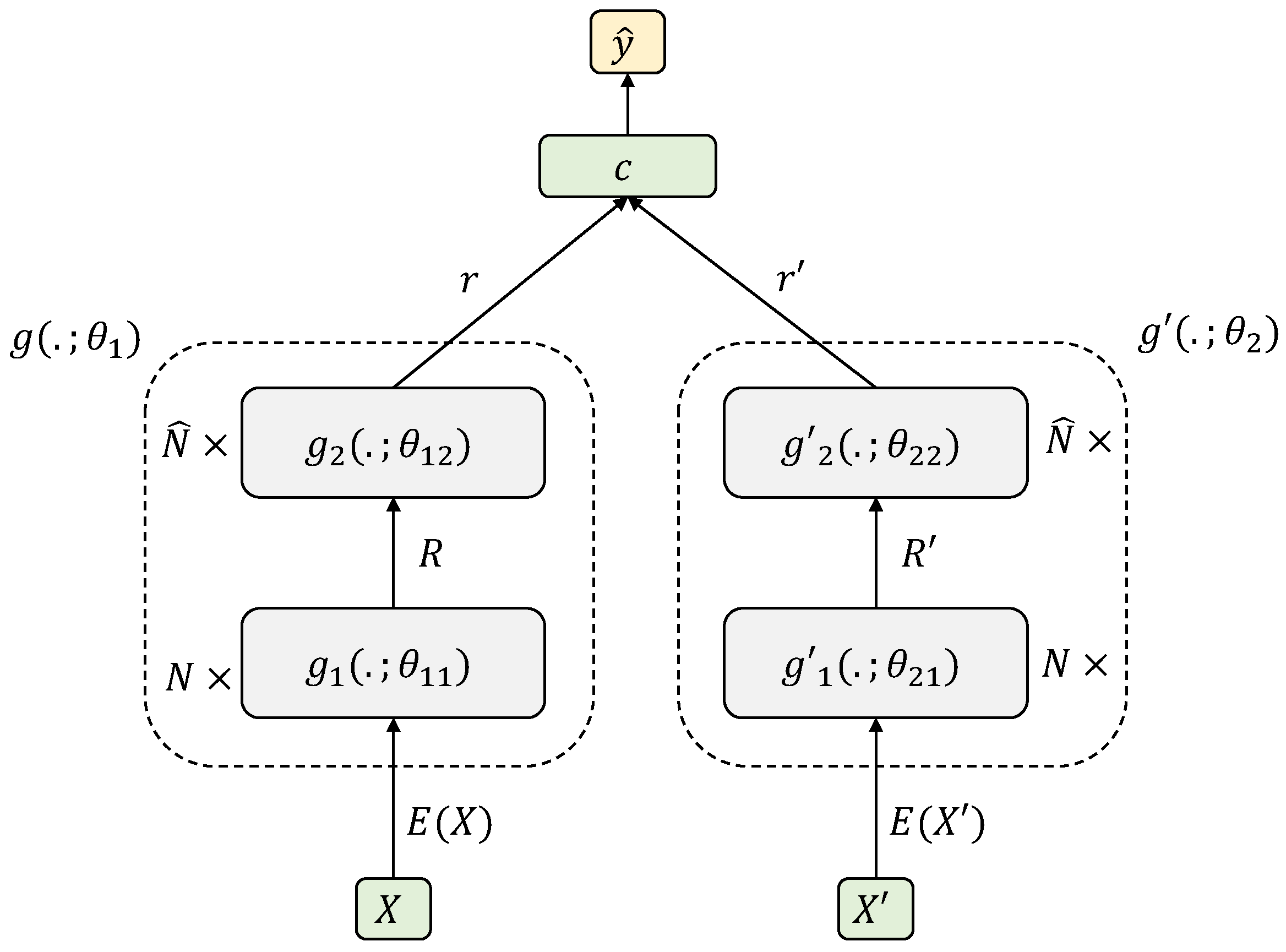
It is possible to identify the required mechanisms for designing systems based on the proposed framework. First, it is required to learn representations for documents and summaries that can be used to distinguish if a summary is correct for a given document. Regarding this point, we used hierarchical models in order to compute document-level representations from the sentence-level representations, which were built from the word-level representations. Second, a mechanism to distinguish correct summaries for documents, from the document-level representations, has to be designed. In our framework, this mechanism is based on Siamese networks, which use the document-level representations to address the summarization task as a binary classification problem, where a probability distribution of the summary correctness is computed. Finally, an interpretable mechanism to compute relationships among document and summary sentences is required. In our proposal, we focused on the attention mechanisms of the hierarchical models at document level in order to compute the relevance of the document sentences. In this way, it is possible to assign a score to each sentence (based on its relevance when distinguishing correct and incorrect summaries) and rank these scores to extract the k most relevant sentences.
4. Framework Definition
A scheme of our framework can be seen in
Figure 1. Let
be a corpus of
M (document, summary) pairs, where all documents and summaries are defined according to a vocabulary
, let
be a document composed by
T sentences of
W words,
, let
be a summary composed by
Q sentences of
V words, (Although documents and summaries of the dataset can have arbitrary lengths, the models based on neural networks digest fixed-length representations achieved by means of truncating or padding. So, we used a maximum number of sentences (T and Q) and a maximum number of words per sentence (W and V) to better reflect it. Regarding the notation,
is intended to represent the set of
A lists with
B words each one, each word belonging to
).
and let
be a model whose input is a (document, summary) pair and whose output is a probability distribution of the summary correctness over
, where 0 is for incorrect summaries and 1 is for correct summaries.
The objective is that the model has to be able to determine if a pair is correct or incorrect. This way, the class computed from the output of the model for the pair will be 1, as is the reference summary for the document X, while for the pair, the class computed will be 0, as is the reference summary for another document from the corpus , different from X. In order to do that, the model must represent documents and summaries in a proper way to distinguish each case. Thus, relies on a document encoder and in a summary encoder . These encoders have to be able to model the hierarchical structure of documents and summaries, so that and are decomposed in two different levels.
First, and that are applied independently on each sentence (of documents and summaries respectively) to obtain sentence-level representations from the word-level representations. The encoders can be composed of N hidden layers. In practice, the words are represented by means of a -dimensional embedding model , typically pretrained and applied to arbitrary-length (P) word sequences, i.e., . Therefore, and . Second, in order to represent documents and summaries from the representation of their sentences, and are defined. These encoders can have hidden layers. Basically, the sentence encoders can be any function that digests a three-dimensional tensor of word embeddings representing the words inside the sentences of a text, and generates a vector representation for each sentence of the text. Similarly, the document encoders, can be any function that digests a matrix of sentence representations to generate a vector representation of the whole text.
Therefore, the encoders and are defined as a composition of two levels, and , where and . Because both documents and summaries come from the same domain, they could be represented in the same way through the use of the same set of parameters in both cases, i.e., and , leading to Siamese architectures. Although this is possible, the parameters are not constrained to be always shared, so, for the sake of simplicity, we also refer to these architectures as Siamese networks. The parameters of the documents and summaries encoders are defined as and .
As stated before, the document encoder
must be interpretable so that it must assign relevance scores both to words, in order to compute sentence representations, and to sentences, in order to compute document representations. Our approach consists in designing these encoders by means of attention mechanisms that assign scores to words and sentences. Then, document representations are computed as an average of their sentence representations, using the document level attention mechanism. At the same time, the sentence representations are computed as an average of their words, using the sentence level attention mechanism. The application of these mechanisms is diverse and they can be applied as auxiliary functions on top of the encoders [
37,
38] as in [
18] or as main mechanisms to compute representations [
21] as in [
20].
Let and be the representations of document and summary respectively, the system must be able to determine if the summary is correct for the document, by using r and . In order to do this, a classifier whose output is a probability distribution over , , is applied. Therefore, the model can be seen as a classifier applied on top of the encoder outputs, both for document, r, and summary, , i.e., . The parameters of the model are determined by the parameters of each subpart: encoders for documents and summaries and the classifier, .
The objective is that the model
must be able to classify correctly the largest number of pairs, both the positives (extracted directly from the corpora) and the negatives (for a given document, reference summaries from all the other documents in the corpora, sampled by following a distribution
p). Therefore, the objective is determined by the minimization of Equation (
1).
where L is a loss function, and
denotes expectation with respect to a Bernoulli distribution with parameter
p.
It is interesting to highlight that, once the system is trained for minimizing the training objective, the encoders and must compute proper representations of documents and summaries, respectively. In this way, the document representations, computed from their sentences by using the attention mechanism of , are useful to distinguish correct and incorrect (document, summary) pairs. Moreover, this attention mechanism is able to assign a relevance score to each document sentence. Thus, it is possible to determine, focusing on the attentions, which document sentences have a greater impact on the document representation, being these sentences the most related with the reference summary.
Finally, it is also interesting to highlight that the attention mechanism of can be used to extract keywords from the documents, being the most attended words inside a sentence those mostly related with respect to the reference summary. We have not experimented in this work with these attentions, but it opens the door for future improvements by considering the words along with the sentences during the summarization process.
5. Proposed Systems
From the definition of the general framework, presented in the previous section, it is possible to design systems based on it for extractive summarization. To do this, it is necessary to define the encoders both for documents and summaries and both at sentence (
and
) and document level (
and
). Furthermore, it is also required to define a strategy for sentence scoring based on the attention mechanisms of document encoder
. In the following subsections, a formalization of two systems proposed inside the
Attentional Extractive Summarization framework is defined [
18,
20].
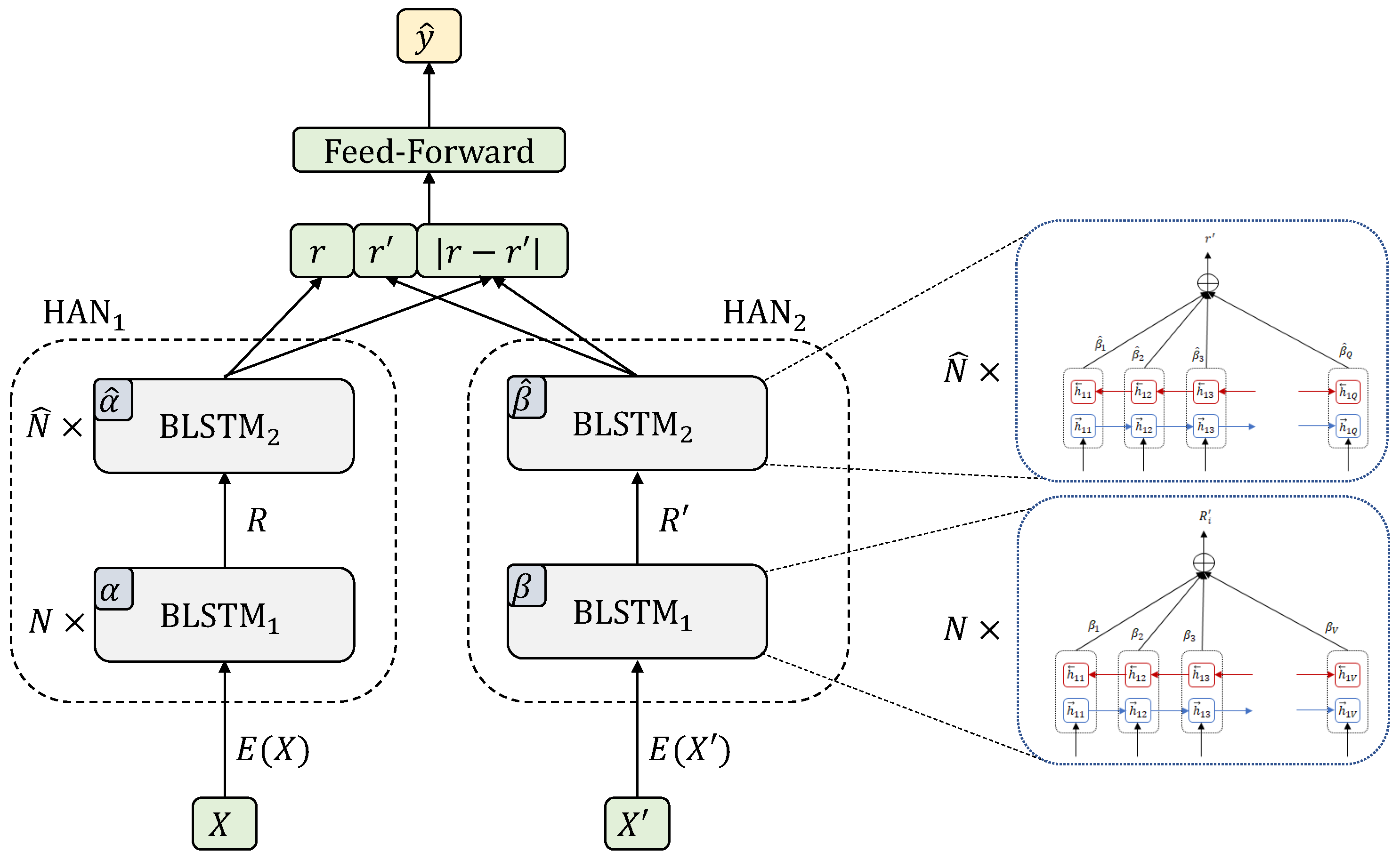
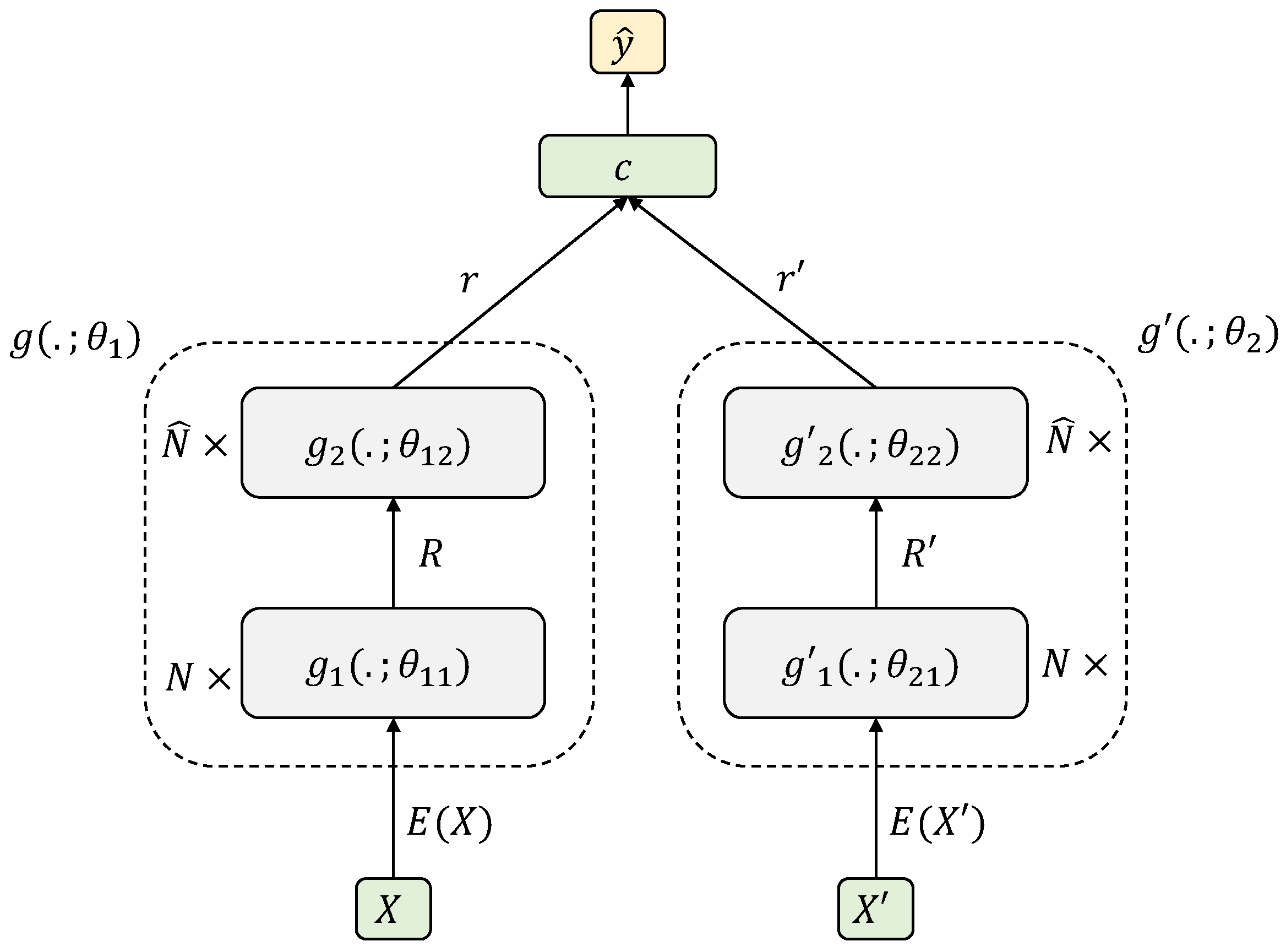
5.1. Siamese Hierarchical Attention Networks
The Siamese Hierarchical Attention Neural Network (SHA-NN) [
18] is an instance of the general attentional framework when the encoders are Hierarchical Attention Networks [
19] based on Bidirectional Long Short Term Memory (BLSTM) [
33,
39] with attention mechanisms, i.e.,
,
,
and
. The BLSTM layers are shared for documents and summaries, both at sentence level (
with dimensionality
) and at document level (
with dimensionality
). However, the attention mechanisms for both branches of the Siamese model are not shared. Regarding classifier
c, it is a feed-forward network. The architecture can be seen in
Figure 2.
For this approach,
and
are computed, following Equations (
2) and (
4), as proposed in [
37]. They are the output from the sentence level
-dimensional
with attention, where each row
i is computed as the average of the hidden vectors of the sentence
i attended by
(Equation (
3)) and
(Equation (
5)) for document and summary respectively. This process is applied independently to each word embedding matrix that represents each sentence both for document and summary (
and
). The following equations show a sentence encoder composed by
network.
where
,
, are the weights of the attention mechanism for document and summary at word level.
From
R and
,
and
can be obtained, following Equations (
6) and (
8), similarly to the sentence level but using
and the attentions
and
for document and summary respectively. The following equations show a document encoder composed by the
network.
where
,
, are the weights of the attention mechanism for document and summary at document level.
These vector representations,
r and
, capture bidirectional relationships among the sentence representations, which are obtained from the representations of their words. Then, they can be used to distinguish correct summaries for documents by forcing the attention mechanisms of the document branch to focus on the most relevant sentences. In order to do this, the vector representations of the document
r, the summary
, and the difference between them
are concatenated and used as input to a feed-forward network with one softmax fully-connected layer, as defined in Equation (
10), to compute a probability distribution over
.
where
is the output of the classifier,
is the weight matrix of the fully connected layer and
is the bias.
Once the network has been trained to distinguish correct summaries for documents, to carry out document summarization with SHA-NN, the attention mechanisms at document level can be directly used to rank sentences and then, to select the most relevant of them based on this rank. Specifically, for the summarization process, given a document
X, a forward pass is performed on the document branch (left branch) of the Siamese network (
in
Figure 2) to obtain the attention score
of each document sentence. From the ranking of the document sentences based on those scores, the top-
k sentences with higher attention score are selected to build the summary.
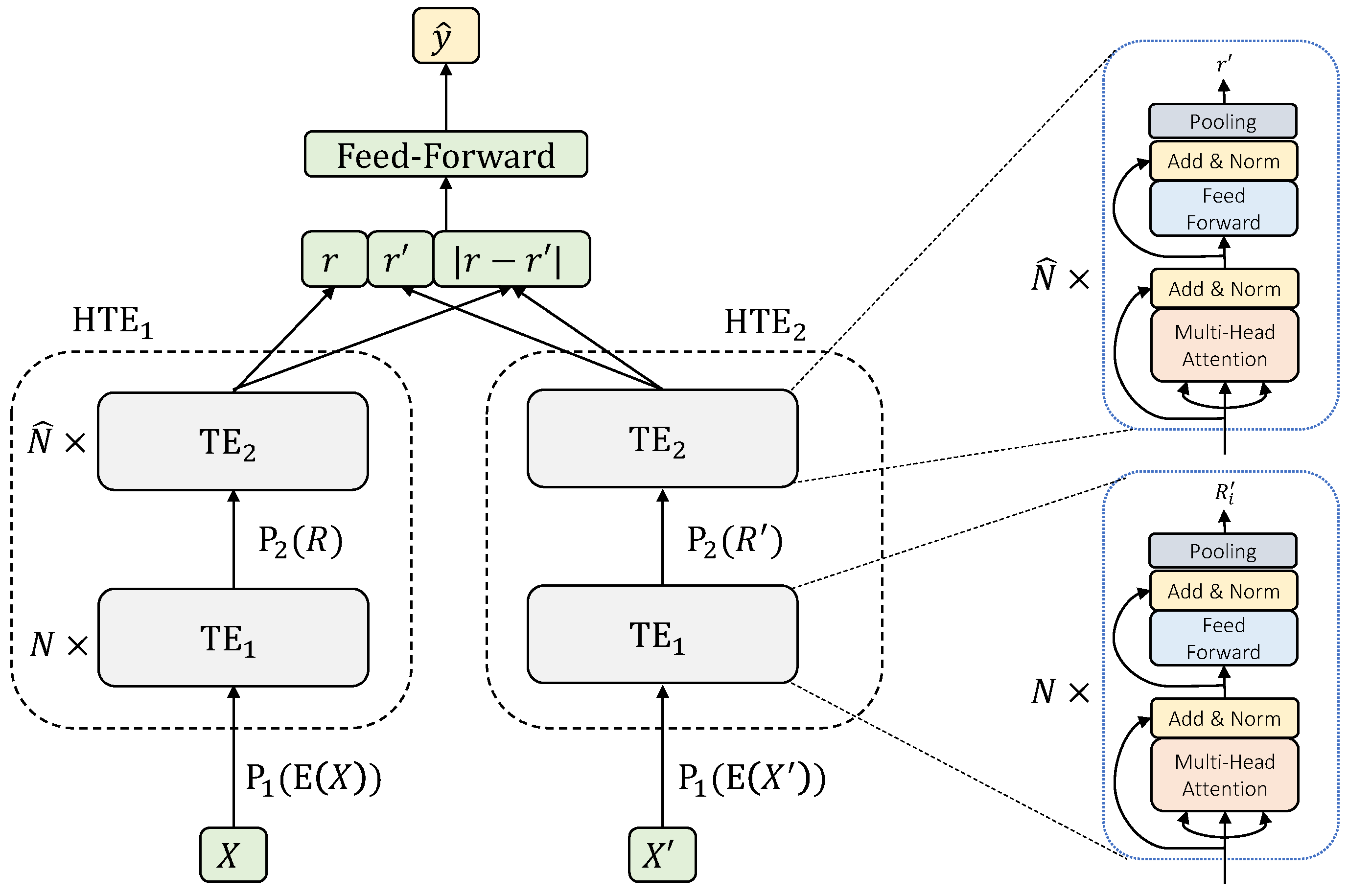
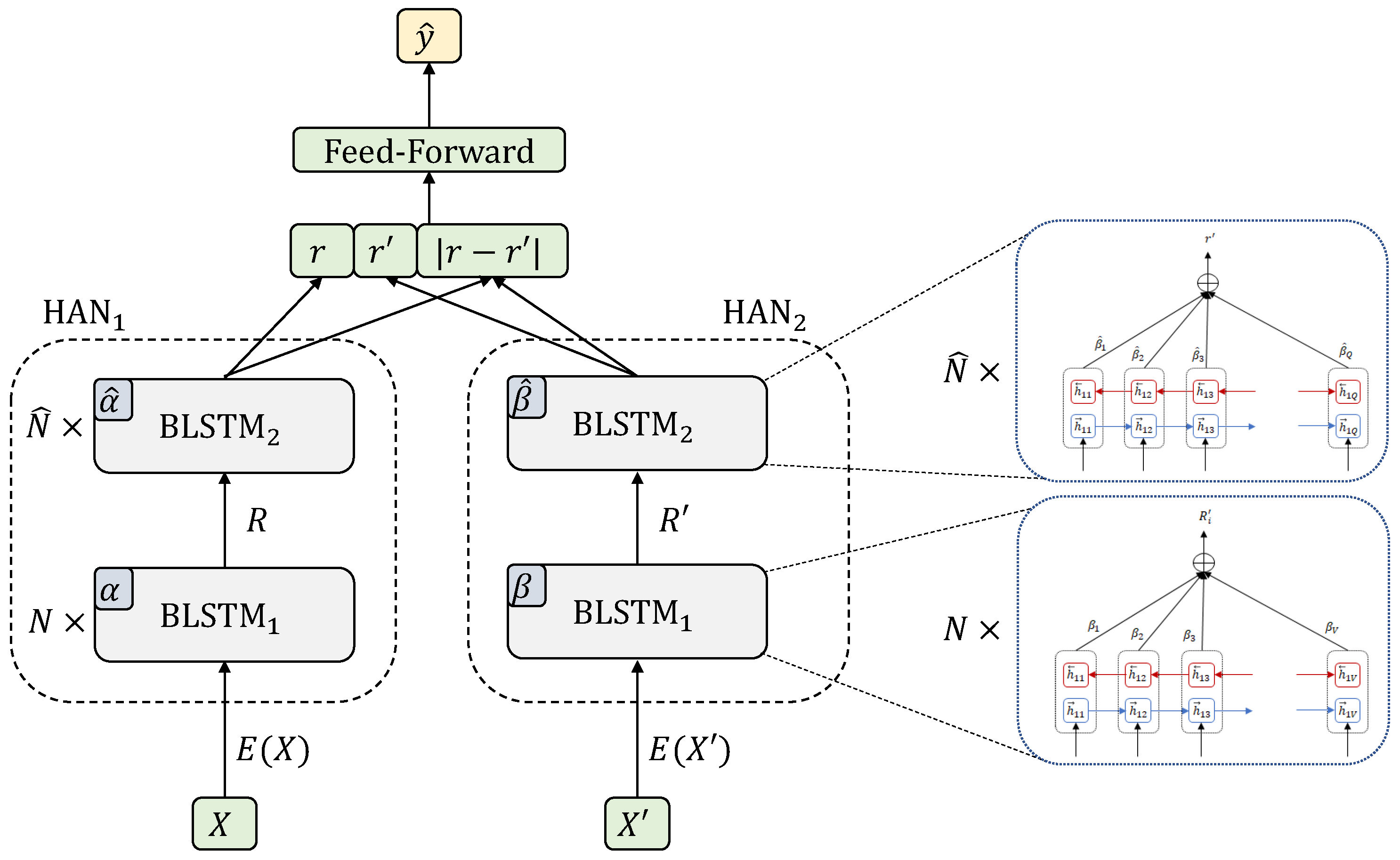
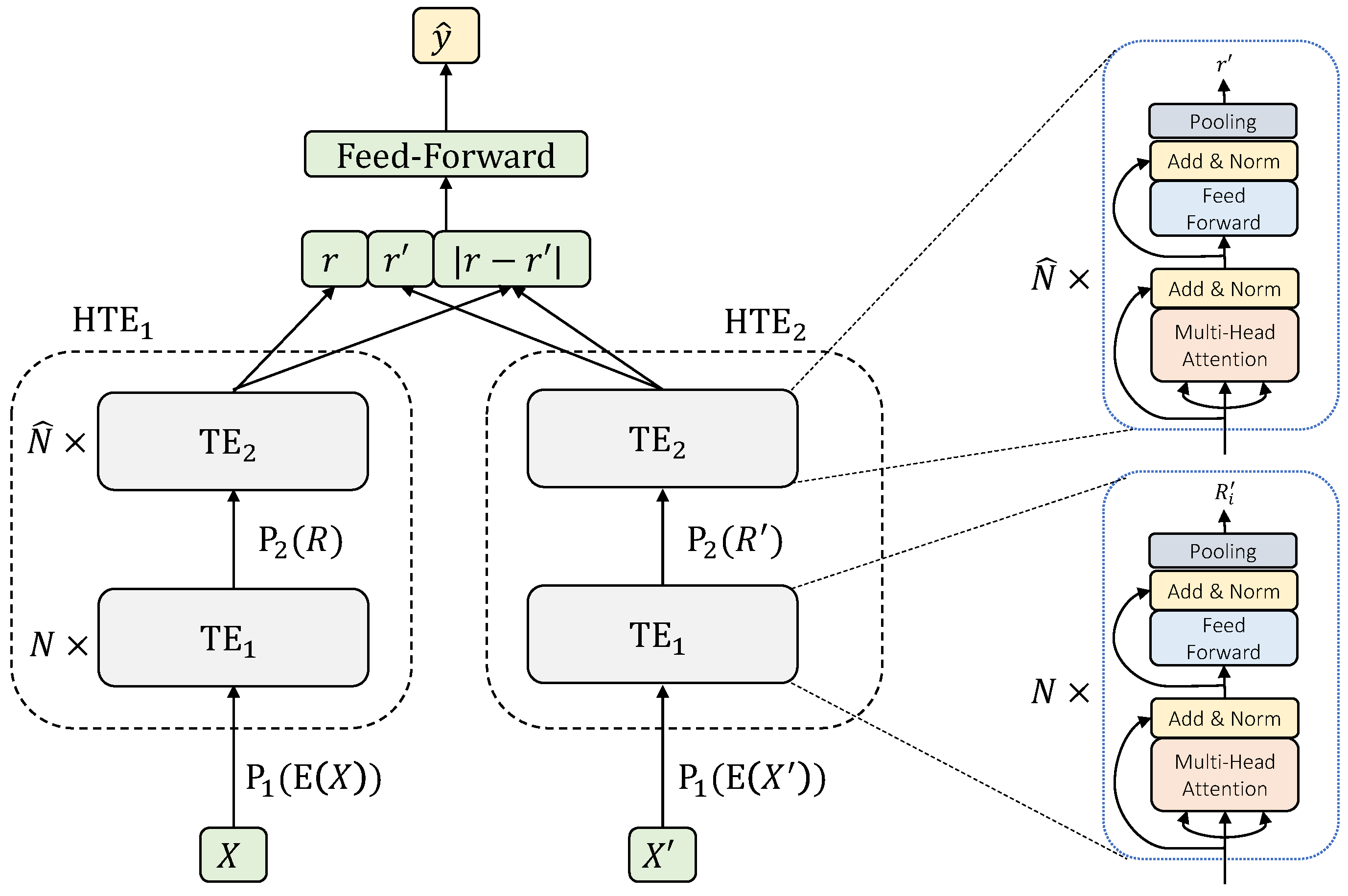
5.2. Siamese Hierarchical Transformer Encoders
Siamese Hierarchical Transformer Encoders (SHTE) [
20] is the instance of the general attentional framework when the encoders, both for sentence and document levels, are Transformer Encoders (TE) [
21] shaped in a hierarchical way, i.e.,
,
,
y
. Additionally, in this case, all the weights are shared between the sentence and document levels of the two branches and classifier
c is a feed-forward network. The scheme of this architecture can be seen in
Figure 3.
The multi-head self-attention mechanism used in the Transformer Encoders is defined in Equations from (
11) to (
13).
where
A,
B and
C are the inputs of the multi-head attention,
h is the number of attention heads,
,
,
and
are the projection matrices for Query (
Q), Key (
K), Value (
V) of the head
i, and output (
O) of the multi-head attention respectively. This mechanism is used both at sentence and document levels. Additionally, it is important to highlight that it does not consider the word order and, due to this fact, it is necessary to incorporate positional information into the system.
First, we define a function
that is applied independently to each word to identify its position in the input of the sentence encoder. Thus, from
X and
,
for article and
for summary are computed by using Transformer Encoders as sentence encoders, following Equations (
14) and (
15).
where the
layered Transformer Encoder
is defined in Equation (
16). Note that, if
Transformer Encoder layers are used, the output of
in layer
i is used as input for
in layer
.
where the weight matrices of the multi-head attention mechanism (Equations (
11) and (
12)) are defined for the sentence level as
,
,
and
and, additionally, are shared among the two branches;
,
,
and
are the weights and the bias respectively of the position-wise feed-forward network; and
refers to Layer Normalization [
40]. This process is independently applied to each word embedding matrix that represents each sentence both for document and summary (
and
).
From
R and
,
and
can be obtained, following Equations (
19) and (
20), similarly to the sentence level but using
for document and summary respectively. Note that, due to Transformer Encoders are applied on top of the sentence representations, it is possible to include positional information also to take into account the position of the sentences both in documents and summaries. To do this, a function
is defined, that is applied to each sentence independently to incorporate sentence positional information in the input of the encoder at document level.
where
, composed by
layer is defined in the same way that
, following Equation (
21). If
, the output of
in layer
i is used as input for the next layer
.
where the weight matrices of the multi-head attention mechanism (Equations (
11) and (
12)) are defined for the document level as
,
,
and
, and additionally, are shared among the two branches;
,
,
and
.
From the vectors
r and
, the interaction between them is computed as their concatenation with their absolute difference. This interaction is used as input for a feed-forward network whose output is a probability distribution over
, as defined in Equation (
10).
It is interesting to note the main difference of SHTE concerning SHA-NN. In SHA-NN, BLSTM are used to compute the representations, combined with attention mechanisms to average them. Due to the attention mechanism computes directly the impact of each sentence in the final representation, this score can be used directly to rank the sentences. However, in SHTE, the same attention mechanism computes both the representations and the relevance scores. Due to this fact, the relevance of each sentence is implicitly captured by the multi-head self-attention mechanism. This system considers that a document sentence is more relevant the more attended it is by all the sentences of the document. With the aim of building a ranking over the document sentences, we use the attention matrices of the last Transformer Encoder at document level, obtained after a forward pass on the left branch of the network from an input document, following Equations from (
24) to (
26).
where
are the Queries and Keys in head
i,
is the attention matrix of head
i,
is the averaged attention of all the heads, and
is the vector that contains the final score assigned to each sentence
j.
The system is composed of
h different attentions that explain different relationships among the sentences. As shown in Equation (
25), we consider that all the relationships captured by the self-attention mechanism have the same relevance to obtain a score. For this reason, the most attended sentences, on average among the different relationships (attentions), are considered as the most relevant, as it was stated in [
20].
After computing the average attention of all the heads,
H, the component
represents the average attention that the model assigns to the sentence
j when it is processing the sentence
i. Then, it could be used to compute the relevance of a sentence
j in the document based on the average attention that
j receives of all the sentences of the document, following Equation (
26). This process is used to compute the scores for all the sentences, and the scores are used to rank them for selecting the top-
k most relevant document sentences in order to compose the summary.
6. Corpora
We carried out the experimentation by using two different corpora for newspaper summarization. On the one hand, the CNN/DailyMail (
https://cs.nyu.edu/~kcho/DMQA/ (accessed on 16 January 2023)) corpus was used in this work. This corpus, which is a set of articles from the CNN and DailyMail news websites, was originally constructed for Question Answering [
22] and was modified for abstractive and extractive summarization [
6,
41]. The CNN/DailyMail corpus was partitioned into 287,227 training (article, summary) pairs, 13,368 validation (article, summary) pairs and 11,490 test (article, summary) pairs. In order to compare our systems with most of the works on this corpus, we used the non-anonymized version. It should be noted that the ground truth summaries provided by this corpus are abstractive, and they were constructed by concatenation of the highlights associated with the documents.
On the other hand, the NewsRoom (
https://lil.nlp.cornell.edu/newsroom/ (accessed on 16 January 2023)) corpus, proposed in [
23] for the summarization task, was also used. It consists of 1.3 million articles and summaries that have been written by the authors and the editors of 38 different major news publications. The corpus was created through a web-scale crawling of over 100 million pages from a set of online publishers by gathering the news and using the summaries provided in the HTML metadata. The summaries contained in this corpus combine both extractive and abstractive strategies to describe the content of the articles. The NewsRoom corpus was partitioned into 995,041 training (article, summary) pairs, 108,837 validation (article, summary) pairs, and 108,862 test (article, summary) pairs.
Some characteristics of both corpora are presented in
Table 1. It is important to note that the NewsRoom corpus is much bigger than the CNN/DailyMail corpus as stated before. Regarding the number of article sentences and words in all the sample sets, both corpora are very similar. However, reference summaries (Summ columns) are twice as long in CNN/DailyMail than in NewsRoom.
7. Experimental Setup
To carry out the experimentation, we maintained most of the hyper-parameters published both for SHA-NN [
18] and SHTE [
20] systems. All the experiments were performed in a single GPU NVIDIA GeForce RTX 2080.
On the one hand, for the SHA-NN system, we used pre-trained word embeddings, obtained by means of a
-dimensional skip-gram architecture, trained from the articles of the corpora. These embeddings were frozen during the training of the models. We used
sentence encoders and
document encoders with
. Adam [
42] was used as update rule with
and
to optimize the cross-entropy. In order to train the model with both corpora, we used batches of 64 (article, summary) pairs (32 positive and 32 negative randomly sampled following a uniform distribution). To generate the summaries, the top-
k most relevant sentences were selected by following directly the attention score of the document encoder.
On the other hand, for the SHTE system, we used randomly initialized word embeddings with
which were trained simultaneously with the model. Most of the hyper-parameters were also fixed, such as
word encoders and
sentences encoders,
heads,
,
,
is the identity function (we do not add positional information to the words inside each sentence) and
is the sine-cosine function defined in [
21]. We only used positional information on the sentences due to the empirical results obtained in [
20], where positional information in sentences seems to work better than positional information in words. Adam [
42] was used as update rule with
and
to optimize the cross-entropy, and Noam [
21] was used as learning rate schedule with
= 4000. To train the model with CNN/DailyMail we used batches of 64 (article, summary) pairs (32 positive and 32 negative randomly sampled following an uniform distribution). For training with NewsRoom, we used batches of 128 (article, summary) pairs. In order to generate the summaries, the top-
k most relevant sentences were selected by following the scoring mechanism presented in
Section 5.2.
For both systems, we used early stopping with 20 epochs of patience during the training phase. For the summarization phase, both models extracted the most relevant sentences for the CNN/DailyMail corpus and for the NewsRoom corpus.
8. Evaluation
In this section, we show and discuss the results obtained by the systems of the
Attentional Extractive Summarization framework (SHA-NN and SHTE) on the CNN/DailyMail and NewsRoom corpora. We also performed comparisons with other extractive and mixed systems. (We considered as mixed systems those that combine extractive and abstractive strategies, either end-to-end or decoupled.)In order to reflect the categorization of the models, we show in the tables the category to which each model belongs. Specifically, these categories are five:
Heuristic (simple rules to generate summaries),
Attentional (models that fall under our framework for extractive summarization),
Oracle (models that require a sentence labeling previously to the training phase),
Reinforcement (models that use Reinforcement Learning to optimize ROUGE metrics during training) and
Text generation (models that do not use oracles nor reinforcement learning, and are trained for text generation by maximizing the likelihood of each word in the reference summary, given the document and all the previous words in that reference summary). The evaluation of the systems’ performance has been carried out by using three variants of the ROUGE measure [
17]. Concretely, Rouge-N with unigrams and bigrams (R-1 and R-2) and Rouge-L (R-L) were used. It should be noted that the ROUGE measure is based on ngrams overlapping. Therefore it is adequate when reference and generated summaries are extractive; however, it is no longer as suitable when the reference or the generated summaries are abstractive.
In
Table 2, the results of our systems and other state-of-the-art systems for the CNN/DailyMail corpus are shown (ECS and PGen are the acronyms for ExConSumm and Pointer-Generator respectively). Our systems obtain similar results to those of Pointer-Gen+Cov [
31], CopyCat [
32], and SummaRunner [
7]. The obtained results are worse in comparison, despite our systems sharing with it the same backbone architecture (Transformer Encoders). This is possibly due to BertSumEXT starts from a very powerful contextualized pre-trained language model [
27]. Additionally, it is interesting to observe that the results obtained by our systems are better than those obtained by some Reinforcement Learning based systems such as DQN [
13] and similar to Refresh [
10]. Therefore, our extractive summarization framework could be used as an alternative to Reinforcement Learning approaches and oracle-based systems.
Table 3 and
Table 4 show the results, in terms of ROUGE, on the NewsRoom corpus. Specifically,
Table 3 shows the results on the full test set and
Table 4 shows the results on each one of the three test subsets defined by Grusky et al. [
23].
Each subset makes reference to the extractiveness degree of their summaries, measured in terms of the density metric proposed in [
23]. There are 3 different subsets: NR-Ext (subset whose reference summaries have a high density of words that appear in the articles), NR-Mix (subset with a medium density), and NR-Abs (subset whose reference summaries have a low density and, then, it can be considered as abstractive).
It is possible to observe how extracting a number of sentences similar to the reference summary length (1.4 as shown in
Table 1) improves notably the performance of the systems (
instead of
). This behavior is observed especially in the NR-Ext and NR-Mix subsets, in comparison to the NR-Abs subset. This suggests that, when the reference summaries are extractive, in addition to determine the relevance of each sentence, it is also important to adjust correctly the length of the summaries. However, when the reference summaries are abstractive, the results by using
and
are very similar and clearly lower for all the systems. These bad results are due to the abstractiveness nature of this set of reference summaries, taking into account that the systems are extractive and mixed. Additionally, it is interesting to highlight that, although Lead is a robust baseline in the NR-Ext and NR-Mix subsets, it is not so good in the NR-Abs subset, where our systems obtain almost the same results.
In both cases, the results obtained by our systems are better than those obtained by widely used approaches such as Pointer-Gen+Cov [
31] or by Reinforcement Learning systems such as FastRL [
14,
43]. Additionally, they obtain better results than TLM [
44] in terms of ROUGE-2 and ROUGE-L on the full dataset, in spite of this system stands out in the abstractive subset NR-Abs. The only systems that consistently outperform the Lead systems are those based on ExConSumm [
30] (both in the extractive and mixed variants), mainly due to they largely outperform the results on NR-Ext and NR-Mix subsets. Differently from our systems, these systems are able to generate variable-length summaries depending on the input text.
In
Table 5, several details about the convergence of our systems are shown. Specifically, it shows the number of samples that each system has seen until convergence, the accuracy on the development set (for each sample in the development set, two samples are built, one positive and one negative randomly sampled), and the time until the convergence. It is possible to see how the SHTE model visited a large number of samples during the training until convergence, at the same time that obtains significantly worse results in terms of accuracy. However, the time required to train these models is significantly lower, requiring up to a four times shorter duration than SHA-NN for the NewsRoom corpus. Furthermore, as
Table 2 and
Table 3 show, the results in terms of ROUGE on both corpora are very similar for both systems. Thus, SHTE constitutes an efficient alternative to SHA-NN since, with a lower training time, obtains very similar results in terms of ROUGE. In comparison to other systems such as BanditSum [
12] (76 h in a single NVIDIA Geforce Titan Xp), DQN [
13] (10 days on a single NVIDIA GeForce GTX 1080) or Refresh [
10] (12 h “on a single GPU”), both systems require a significantly lower training time for the CNN/DailyMail corpus. Furthermore, they dispense with the computation of sentence oracles previously to the training step.
It is interesting to observe in
Table 5 that, in spite of the significant differences in terms of accuracy during the evaluation with the development set, the results in terms of ROUGE in the evaluation of the test summaries are very similar. This clearly illustrates the mismatch discussed by Narayan et al. in [
10], derived from the disconnection between the task definition and the training objective. This is the main drawback of the summarization systems based on optimizing the cross-entropy instead of the ROUGE measure. Due to this reason, it is interesting to search alternatives to Reinforcement Learning in order to optimize directly the evaluation measure.
Finally, despite of the systems based on the attentional framework obtained similar results to Lead in both corpora (mainly due to the bias to the first article sentences in almost all the extractive samples), those systems are capable of generalizing on unseen documents where the sentences are more scattered, as shown in Gonzalez et al. [
45].
9. Analysis
Following the experimentation carried out by Mendes et al. in [
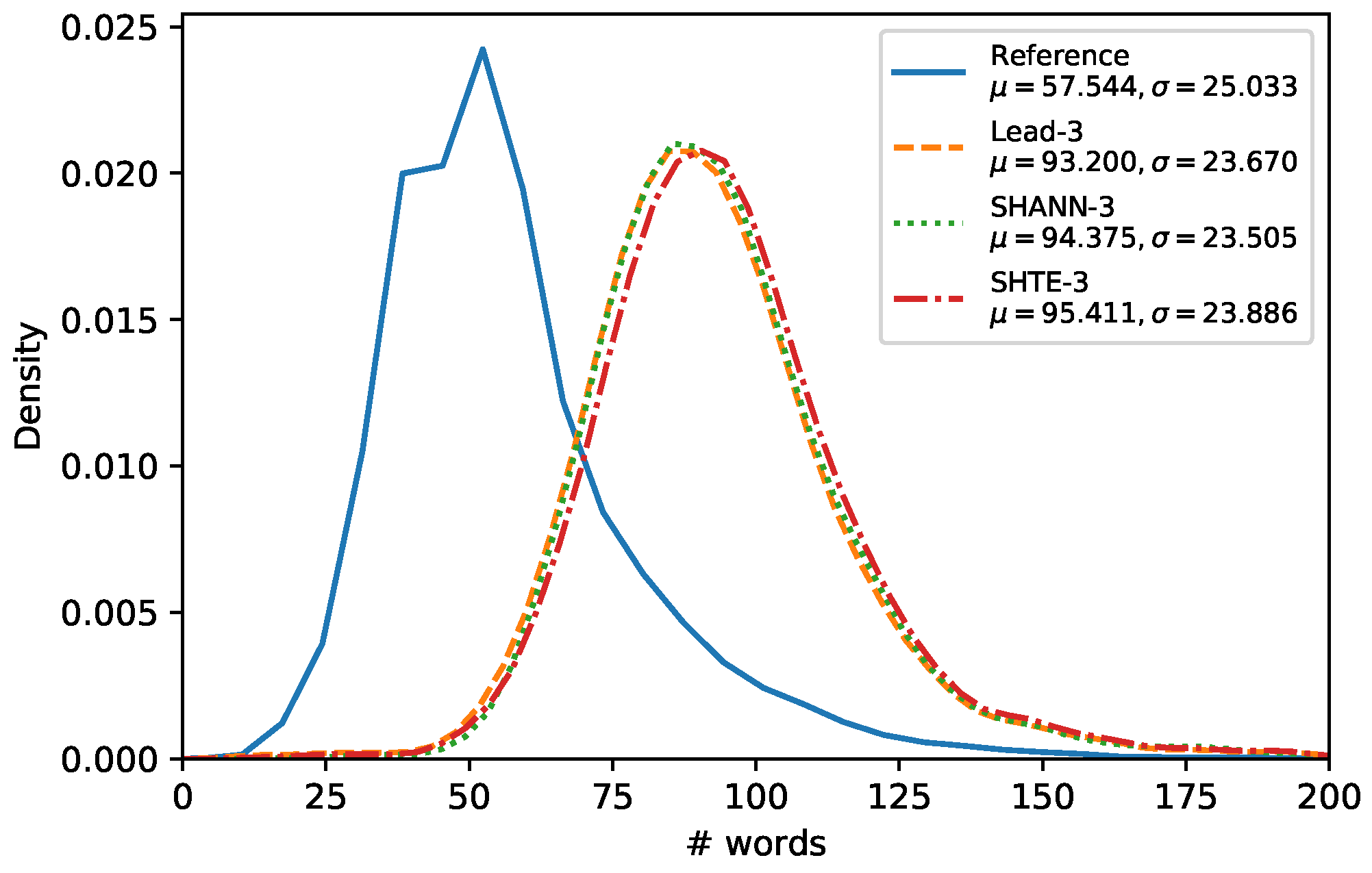
30], we analyzed the lengths of the summaries generated by our proposals.
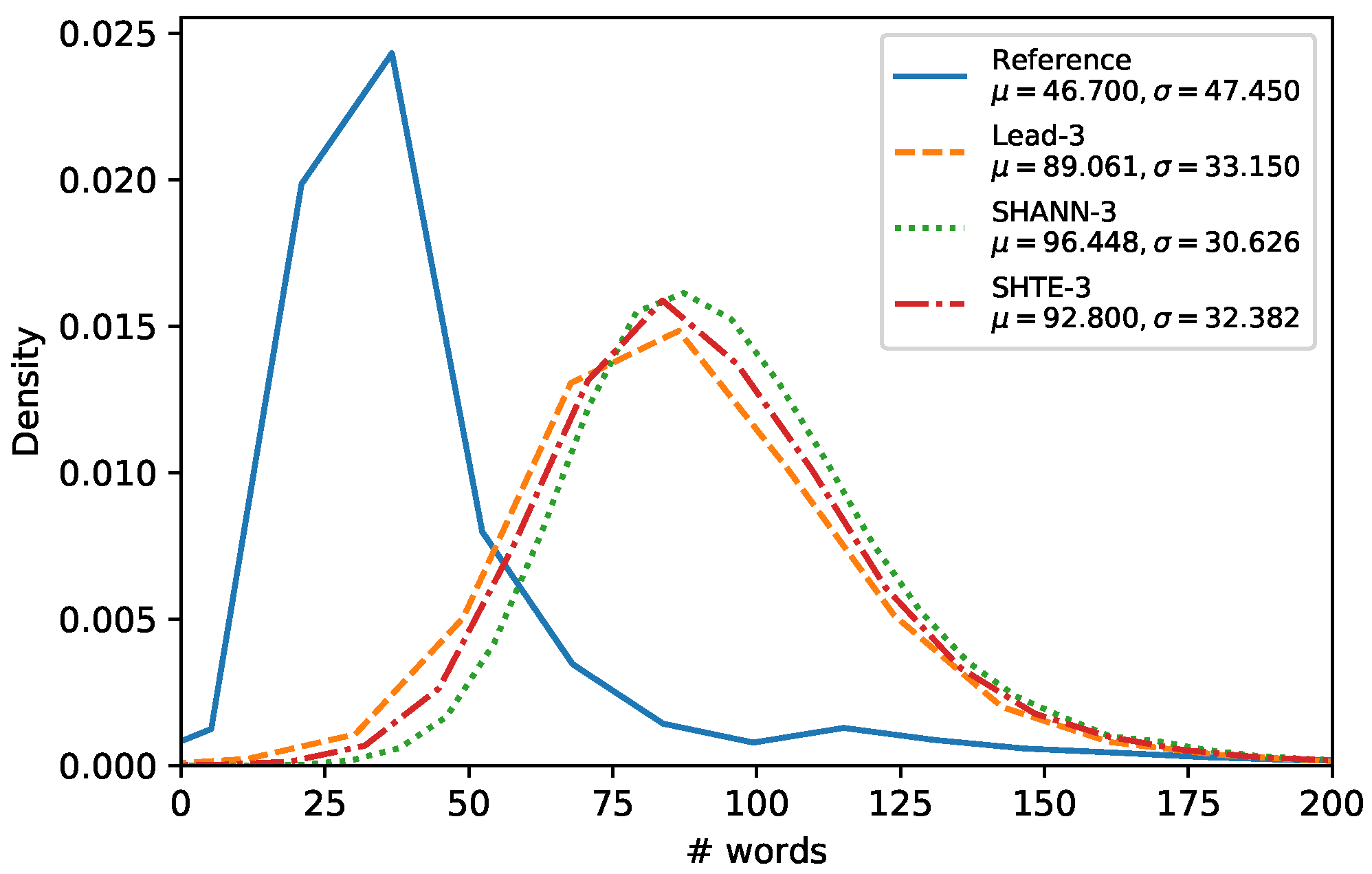
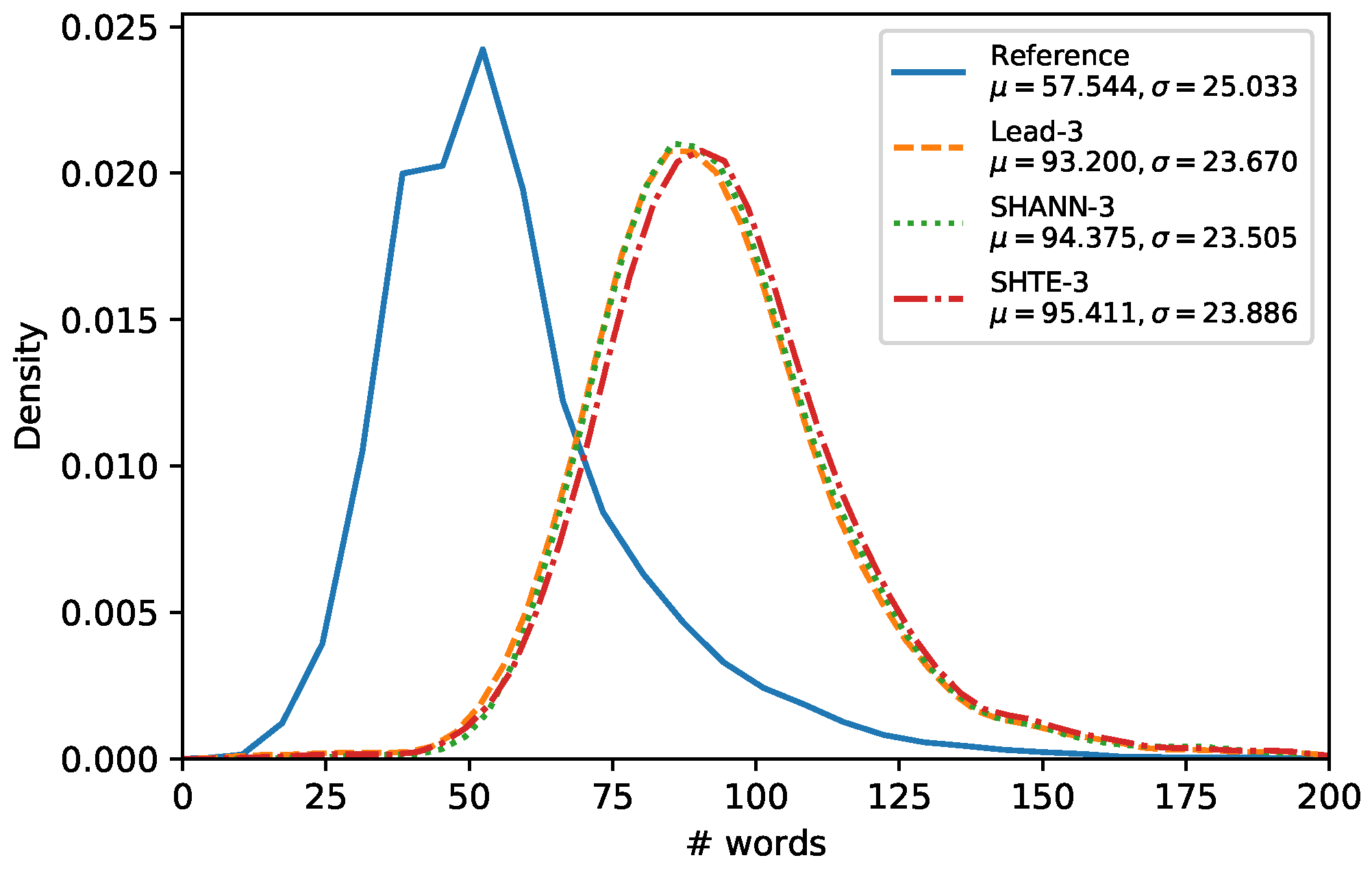
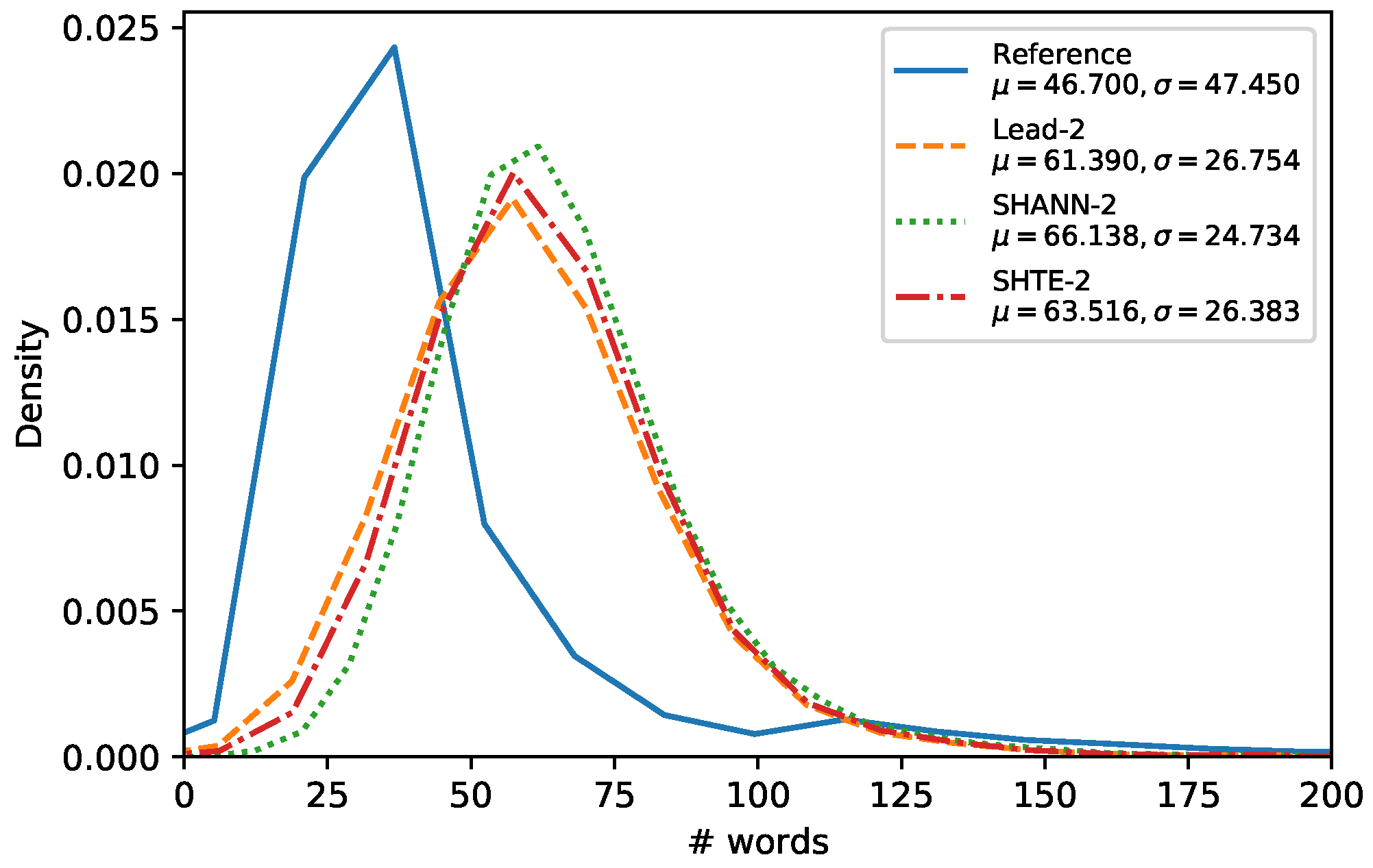
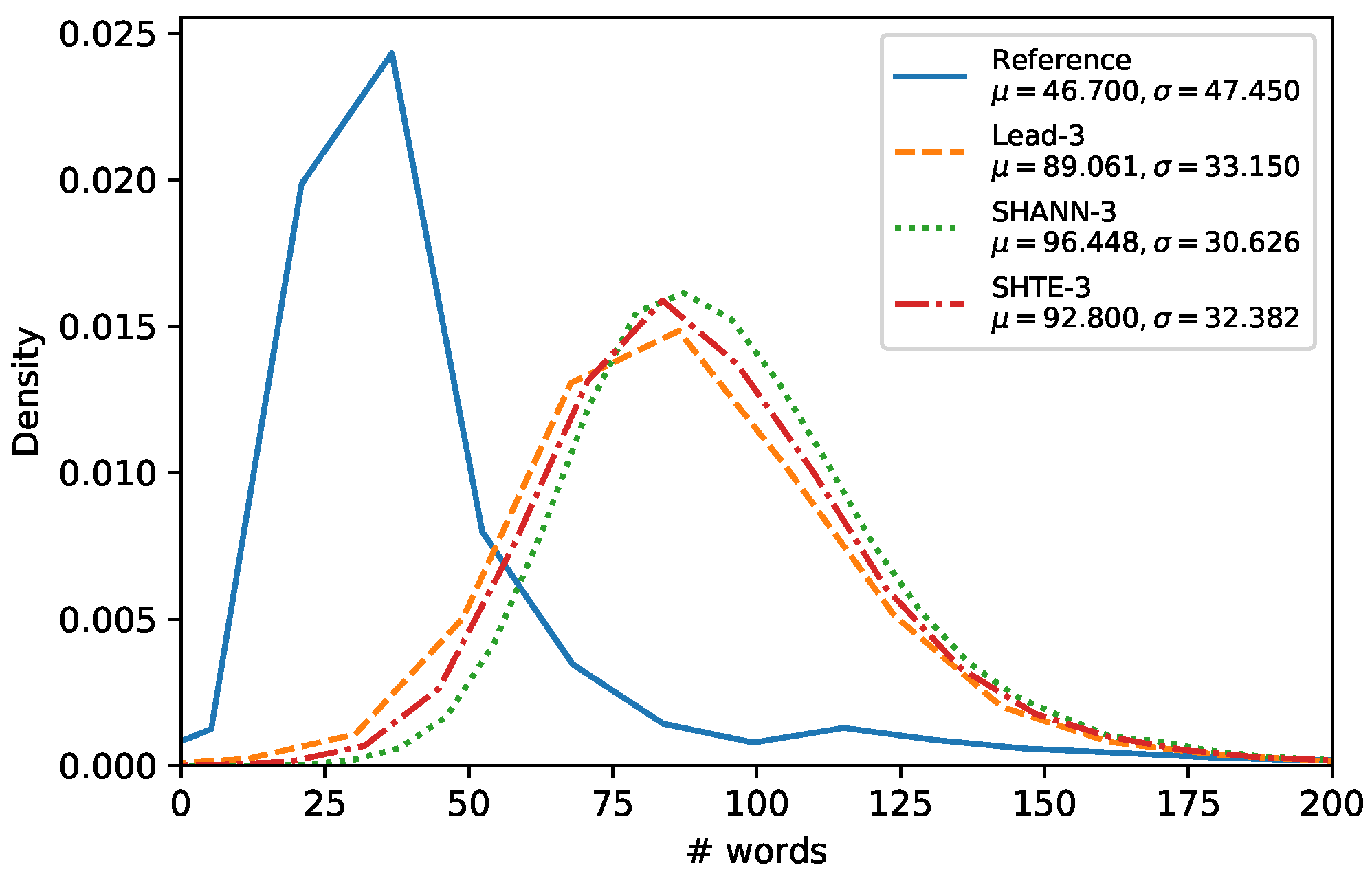
Figure 4,
Figure 5 and
Figure 6 show the word-length distributions of the summaries for Lead, SHA-NN, and SHTE systems (with
) applied on CNN/DailyMail corpus and NR-Ext subset of NewsRoom. We included also the word distribution of the human reference summaries for both corpora.
It can be seen that the word-length distributions of the summaries extracted by our proposals are almost identical to the distribution of the Lead system. This similarity can be observed also in other systems, based on Reinforcement Learning which dispenses of oracles, such as Latent [
11] and Refresh [
10], as shown in [
30]. These results suggest that the extractive systems that do not use oracles are biased towards selecting the first sentences to a higher extent than oracle based systems. For both corpora, all the system distributions are shifted considerably to the right in comparison to the distribution of the human reference summaries. Thus, our systems seem not to be able to generate summaries in lower length ranges (12–50 for CNN/DailyMail, 5–25 for NR-Ext with
, and 20–50 for NR-Ext with
). This is mainly due to they are not able to build variable-length summaries and they are limited to select all the words of a fixed number of sentences without making word-level operations e.g., compression [
30] or selection [
31].
In
Figure 7 and
Figure 8, we show two examples of summaries generated by the SHTE and SHA-NN systems both for NewsRoom and CNN/DailyMail respectively. In the NewsRoom example, the SHTE model generates a shorter summary than SHA-NN, extracting the first sentence of the document as a short and direct lead. Additionally, it is the only model that makes explicit the name of the analyst (
technical analyst andrew keene, in the 5th sentence), like in the reference summary. Differently, SHA-NN prefers the sentence that contains the introduction to the analyst’s statements (4th sentence), but does not contain its name. Only SHA-NN mentions the
copper (
red metal), the
mining (
mining giant), and the
end of the stock (
rally could be over). It should be noted that, in this example, SHA-NN prefers the longest sentences that appear before in the document (3rd and 4th), differently from SHTE (1st and 5th). For the CNN/DailyMail example, both systems extract the first article sentence. Along with it, SHTE extracts a sentence related to the reference summary and one irrelevant sentence. In the same way, this behavior is also observed in SHA-NN where the related sentence extracted is different from the one extracted by SHTE. If the 3rd sentence extracted by SHTE and the 2nd extracted by SHA-NN were selected, almost all the semantic of the reference summary would be covered. It is also interesting to note that the generated summaries are much longer than the reference summaries, due to our systems being restricted to selecting full article sentences; however, the reference summaries could be composed of simplified sentences.
For the previous examples, in
Figure 9 we show the attentions that each system assign to each sentence (the lighter the more relevant is a sentence). In this figure, the first column refers to the systems SHTE and SHA-NN when they are applied on the NewsRoom example, whereas the second column refers to their application on the CNN/DailyMail example.
is the averaged matrix shown in Equation (
25) for the SHTE system,
are the relevance scores assigned to each sentence by the SHTE system following Equation (
26), and
are the relevance scores assigned to each sentence by the SHA-NN system.
A bias towards the first sentences can be seen. However, in spite of this bias, both systems are able to also assign high scores to late sentences of the documents. The matrix H of the SHTE system, in the NewsRoom example, is almost a lower triangular matrix, suggesting that the dependencies among the sentences are given only backward. This does not happen in the example of CNN/DailyMail where the attentions seem to compose patterns repeated at regular intervals within the same column.
10. Conclusions and Future Works
In this work, we presented a formalization of a general framework for extractive summarization that does not fall under the umbrella of the traditional extractive systems (based on suboptimal oracles or Reinforcement Learning to optimize the ROUGE). The main objective of this work is to favor the development of new models and techniques within our proposed framework. A future instantiation of this framework could be based on hierarchical BERT-like models, whose attentions could be interpreted to extract the most relevant sentences for the summary.
Under the proposed framework, the summarization systems are based on Siamese architectures to learn directly relationships among articles and summaries. Additionally, they are based on the interpretability of the attention mechanisms, to select the most relevant article sentences. For this reason, we referred to our extractive summarization framework as Attentional Extractive Summarization.
We have performed an extensive evaluation and several analyses of the systems in comparison to other Deep Learning extractive and mixed systems, both for the CNN/DailyMail and for the NewsRoom corpora. The obtained results are very promising and they suggest that there is still room for improvement in our attentional framework. This encourages us to continue with the research of this kind of systems.
As future work, several lines of research are open: the extraction of variable-length summaries, the use of the word attentions in order to perform post-process on the extracted sentences, and the inclusion of some abstractive mechanisms on top of the proposed extractive systems. Due to the similarity between the classification and summarization objectives, in the sense that they look for relevant segments of a text, it could be very interesting to study a strategy to approach a text classification system based on the output of a summarization system that provides the selected sentences.




 ,
, 



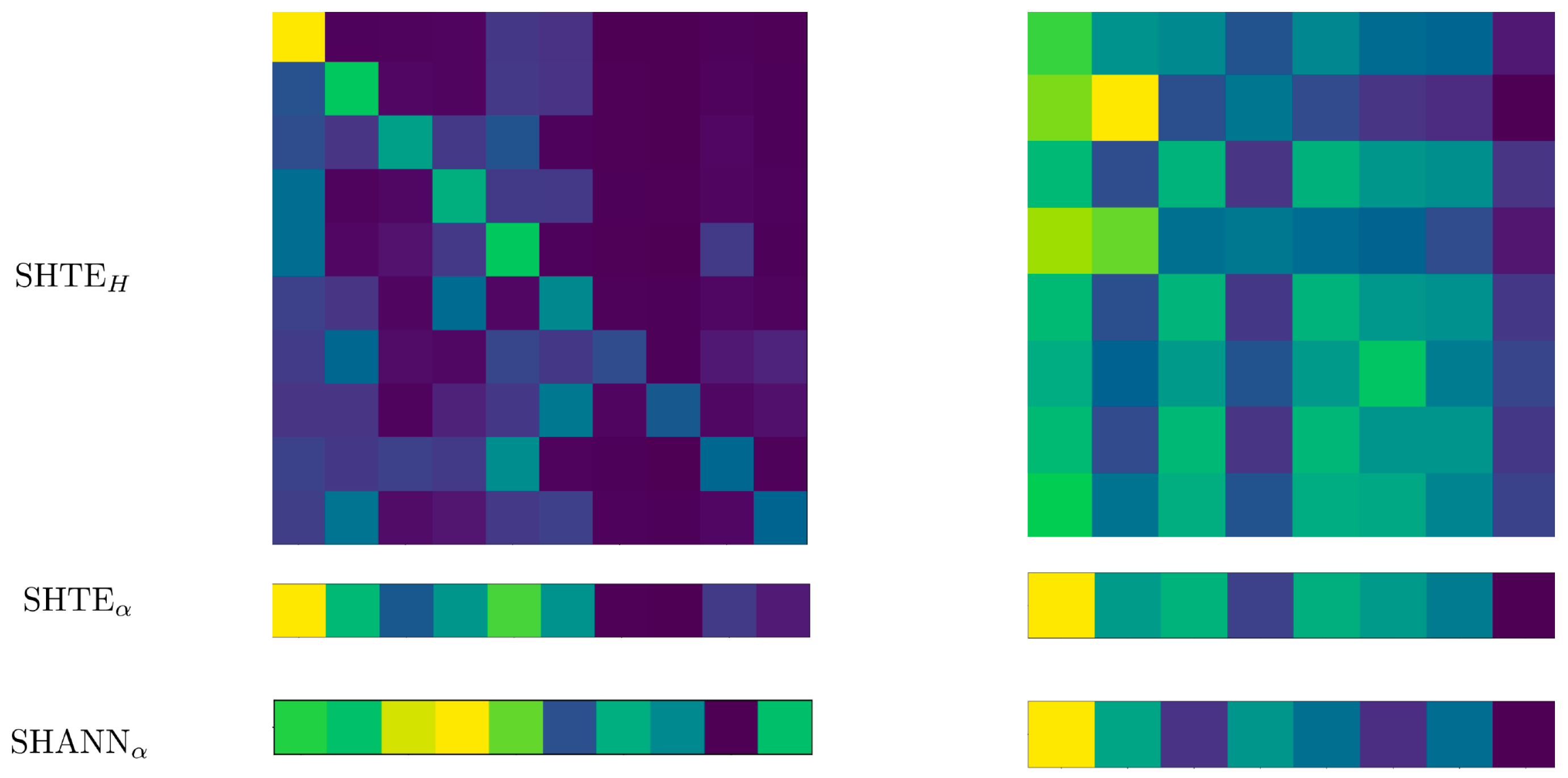

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
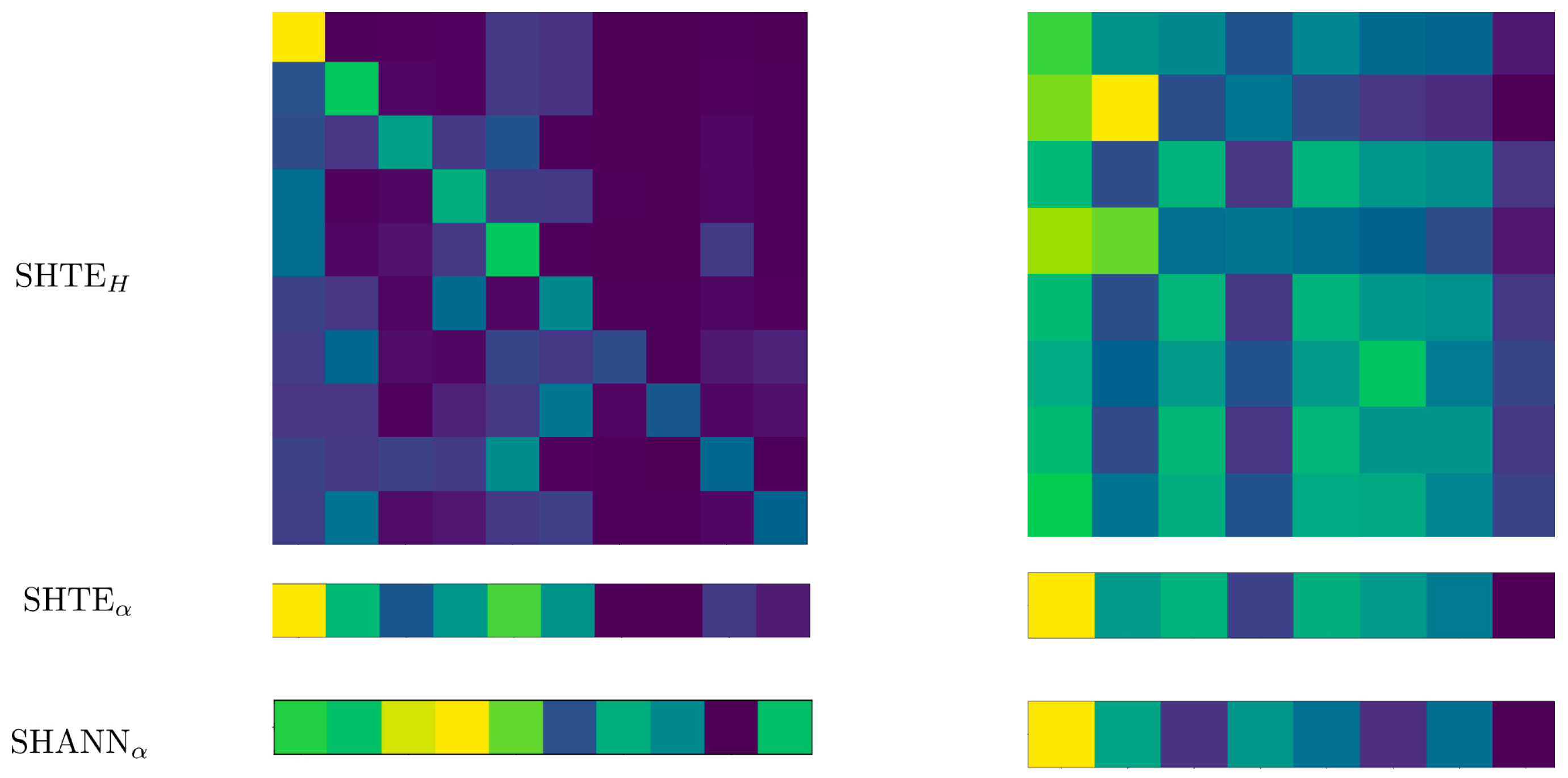{kind=link}