


Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network


Abstract
1. Introduction
2. Related Work
2.1. Lexicon-Based Techniques, N-Grams and Natural Language Processing
2.2. Word Embeddings-Based Techniques and Deep Learning Models
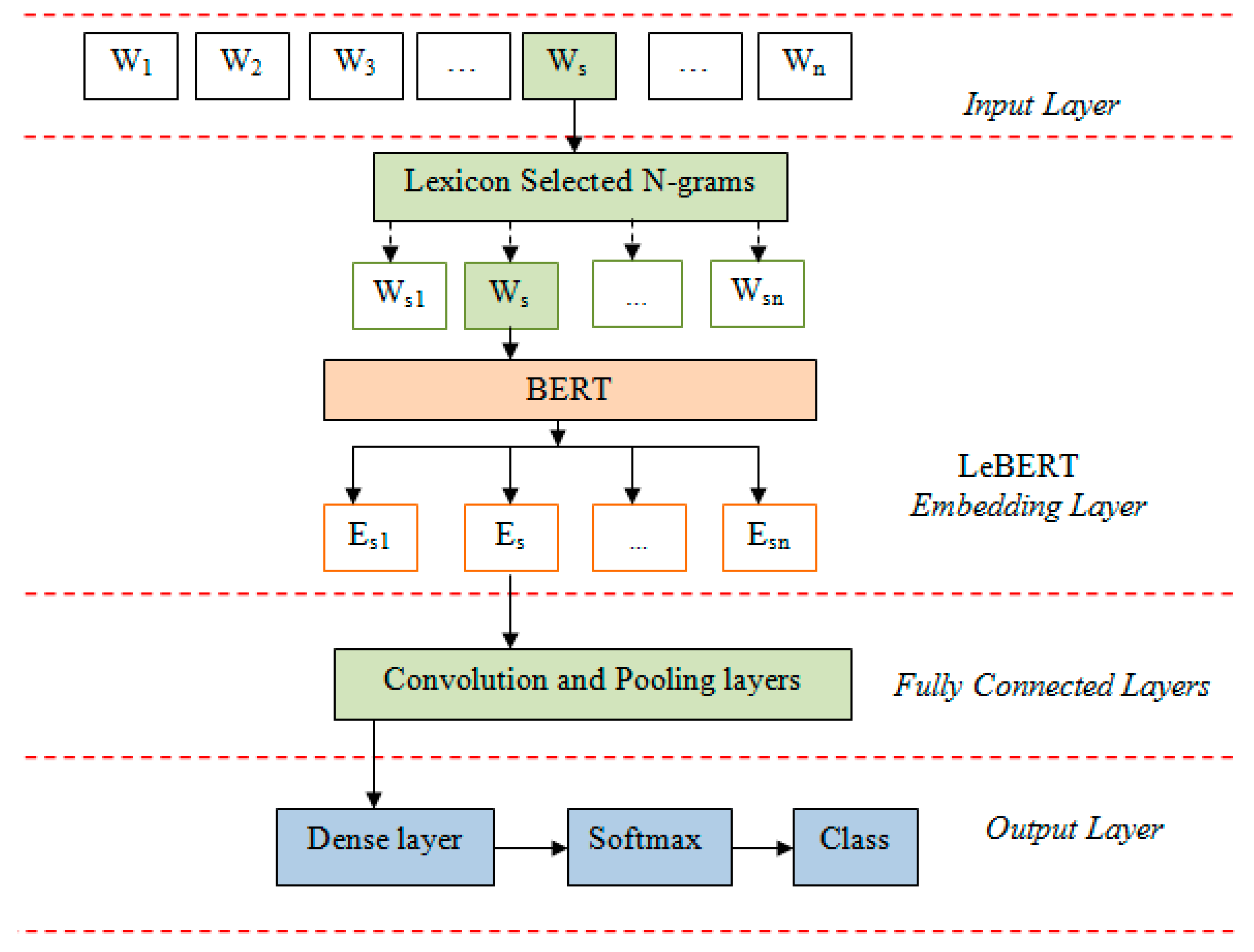
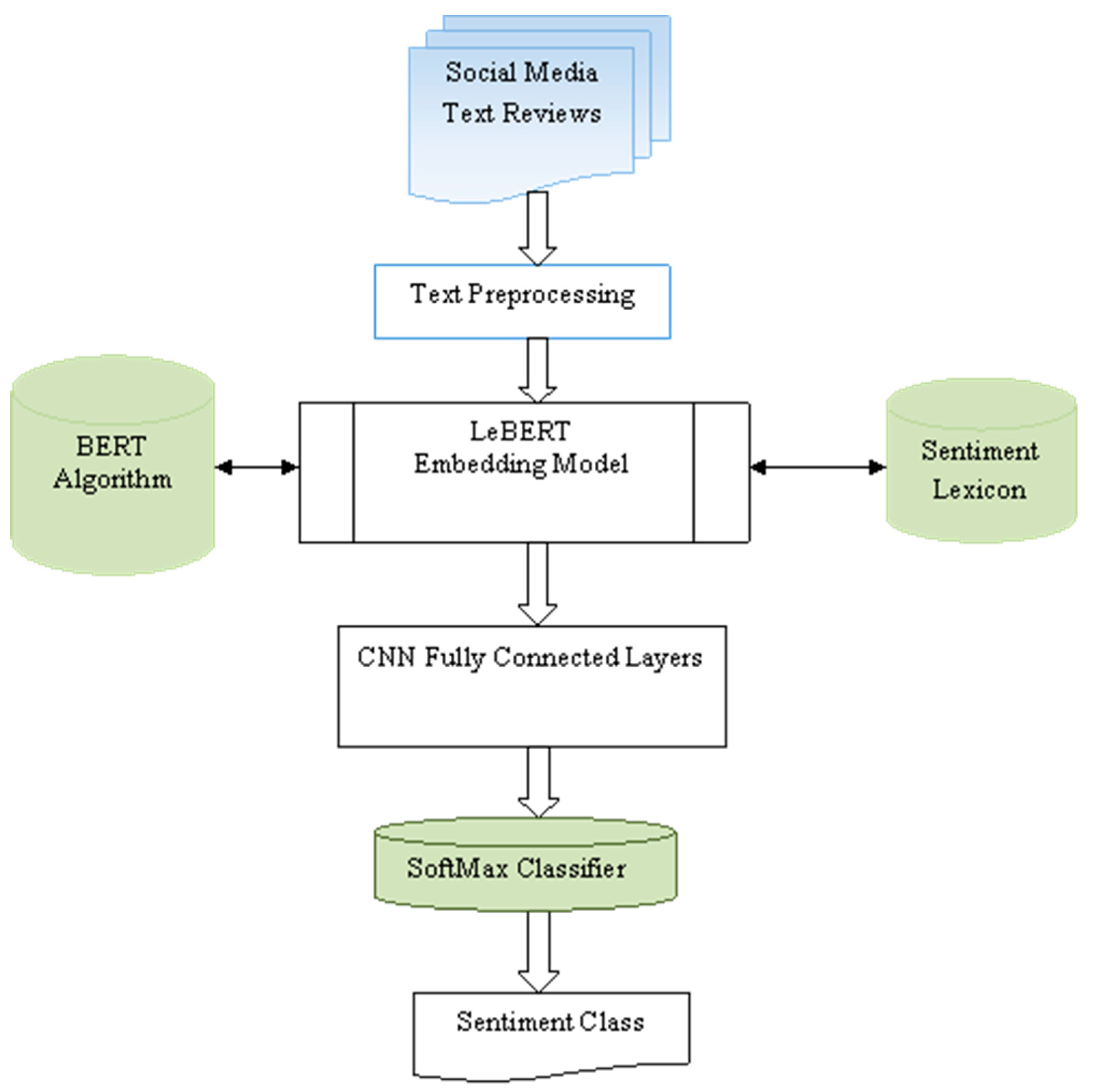
3. The Proposed LeBERT Model
3.1. LeBERT Embedding
3.2. The LeBERT Embedding Algorithm
| Algorithm 1 Contextualized Text Vector Generation |
| Inputs: Ri = {w1, w2, ……, wn), input review containing n words L = sentiment lexicon Be = BERT word-embedding model Output: Contextualized Text Vector (vi), representing the subjective user review |
| START Set the N-gram value to N = 3 FOR each review (RiϵC) with n word tokens PRINT the word trigrams; Call the sentiment lexicon (L) FOR each trigram check for a sentiment word; IF a trigram contains a sentiment word THEN PRINT the trigram words (w1, wt, w2) ELSE delete the trigram ENDIF END Generate section vector(·) FOR Each word (w1, wt, and w2) in the trigram READ (wi) into gag of words (Bwi) Call the pre-trained word-embedding (Be) Calculate the word vector (wvi) END Update vectorVi:‹wv1 and wvt and wv2› END Return VectorVi. |
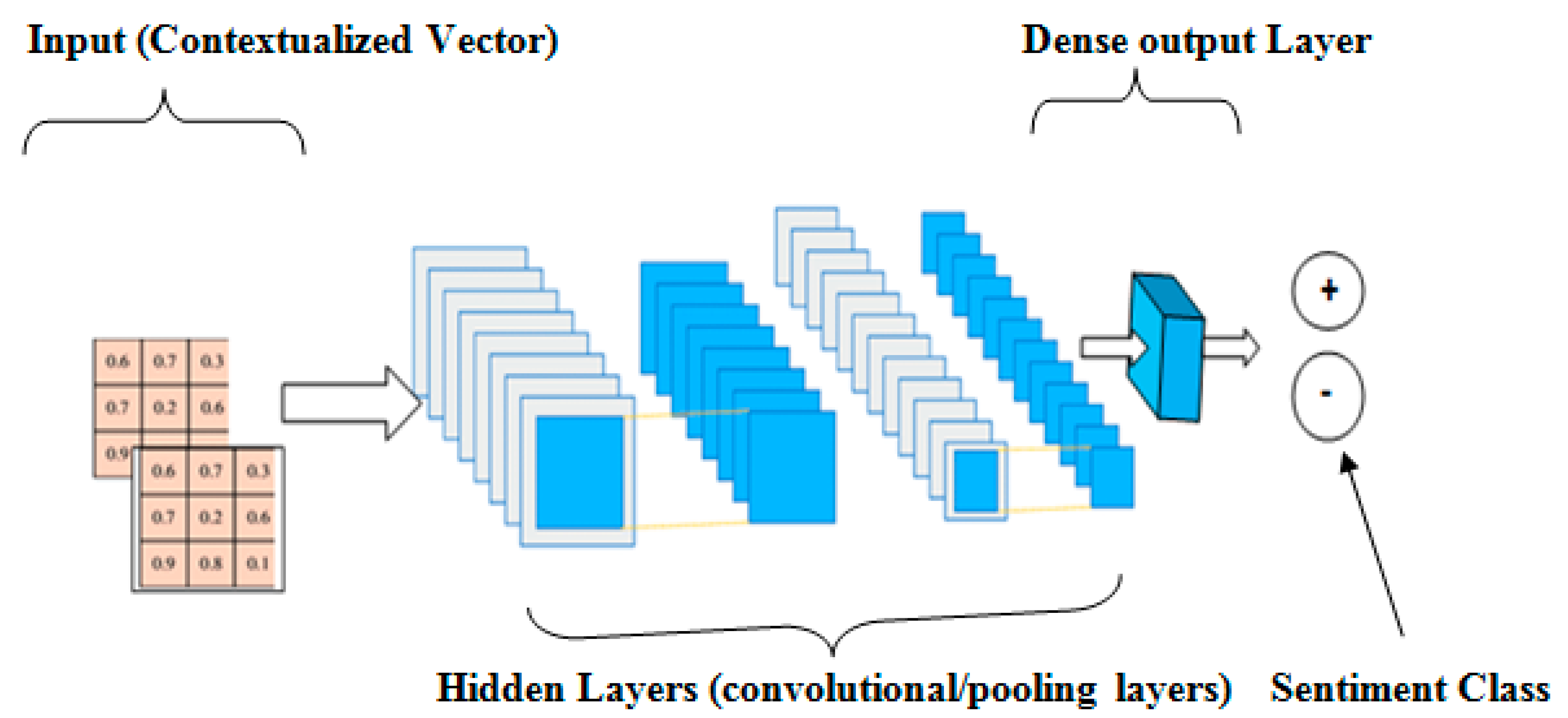
3.3. The CNN Layer
4. Experiments
4.1. Dataset
4.2. Experiment Setup
4.3. Model Parameters BERT, Glove, and Word2Vec Pre-Trained Word Embeddings
4.4. Model Performance Evaluation
5. Results and Discussion
5.1. Ablation Study on Effect of Size of N-Grams on LeBERT Model
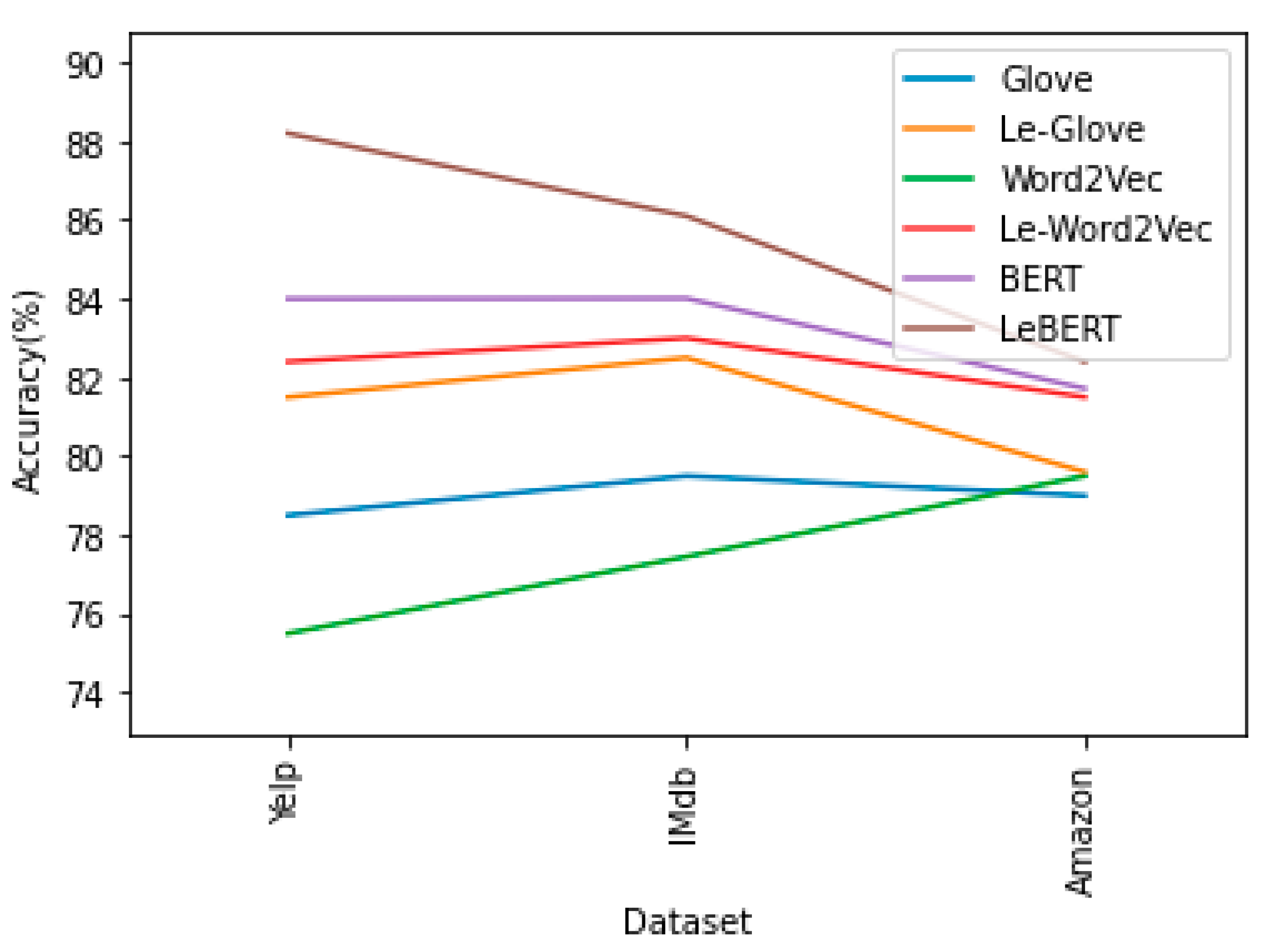
5.2. Comparison of LeBERT Model Performance with Baseline Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, Z.; Gao, B.; He, Y.; Han, Y.; Doyle, P.; Zhu, Q. Text Classification Using Novel Term Weighting Scheme-Based Improved TF-IDF for Internet Media Reports. Math. Probl. Eng. 2021, 2021, 6619088. [Google Scholar] [CrossRef]
- Onan, A.; Üniversitesi, I.K. Ensemble of Classifiers and Term Weighting Schemes for Sentiment Analysis in Turkish. Sci. Res. Commun. 2021. [Google Scholar] [CrossRef]
- Kalarani, P.; Selva, B.S. An overview on research challenges in opinion mining and sentiment analysis. Int. J. Innov. Res. Comput. Commun. Eng. 2015, 3, 1–6. [Google Scholar]
- Yang, J.; Xiu, P.; Sun, L.; Ying, L.; Muthu, B. Social media data analytics for business decision making system to competitive analysis. Inf. Process. Manag. 2021, 59, 102751. [Google Scholar] [CrossRef]
- Rao, L. Sentiment Analysis of English Text with Multilevel Features. Sci. Program. 2022. [Google Scholar] [CrossRef]
- Onan, A.; Korukoğlu, S. A feature selection model based on genetic rank aggregation for text sentiment classification. J. Inf. Sci. 2016, 43, 25–38. [Google Scholar] [CrossRef]
- Bhadane, C.; Dalal, H.; Doshi, H. Sentiment Analysis: Measuring Opinions. Procedia Comput. Sci. 2015, 45, 808–814. [Google Scholar] [CrossRef]
- Mozetič, I.; Grčar, M.; Smailović, J. Multilingual Twitter Sentiment Classification: The Role of Human Annotators. PLoS ONE 2016, 11, e0155036. [Google Scholar] [CrossRef]
- Li, B.; Guoyong, Y. Improvement of TF-IDF Algorithm based on Hadoop Framework. In Proceedings of the 2nd International Conference on Computer Application and System Modeling, Taiyuan, China, 27–29 July 2012; pp. 391–393. [Google Scholar]
- Ankit, N.S. An Ensemble Classification System for Twitter Sentiment Analysis. Procedia Comput. Sci. 2018, 132, 937–946. [Google Scholar] [CrossRef]
- Ahuja, R.; Chug, A.; Kohli, S.; Gupta, S.; Ahuja, P. The Impact of Features Extraction on the Sentiment Analysis. Procedia Comput. Sci. 2019, 152, 341–348. [Google Scholar] [CrossRef]
- Rao, G.; Huang, Z.F.; Cong, Q. LSTM with sentence representations for document level sentiment classification. Neurocomputing 2018, 308, 49–57. [Google Scholar] [CrossRef]
- Mutinda, J.; Mwangi, W.; Okeyo, G. Lexicon-pointed hybrid N-gram Features Extraction Model (LeNFEM) for sentence level sentiment analysis. Eng. Rep. 2021, 3, e12374. [Google Scholar] [CrossRef]
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. 2019, 117, 139–147. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, 26–28 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NaacL-HLT, Minneapolis, Minnesota, 2 June 2019; pp. 4171–4186. [Google Scholar]
- Sharma, A.K.; Chaurasiaa, S.; Srivastavaa, D.K. Sentimental Short Sentences Classification by Using CNN Deep Learning Model with Fine Tuned Word2Vec. Procedia Comput. Sci. 2020, 167, 1139–1147. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Adeel, A.; Larijani, H.; Hussain, A. Sentiment Analysis of Persian Movie Reviews Using Deep Learning. Entropy 2021, 23, 596. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, B.; Shan, L.; Wang, X. Modelling context with neural networks for recommending idioms in essay writing. Neurocomputing 2018, 275, 2287–2293. [Google Scholar] [CrossRef]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Baharudin, B.; Khan, A. Sentiment Classification Using Sentence-level Semantic Orientation of Opinion Terms from Blogs. In Proceedings of the 2011 National Postgraduate Conference, Perak, Malaysia, 19–20 September 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Mudinas, A.; Zhang, D.; Levene, M. Combining lexicon and learning based approaches for concept-level sentiment analysis. In Proceedings of the First International Workshop on Issues of Sentiment Discovery and Opinion Mining, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar]
- Huang, L.; Dou, Z.; Hu, Y.; Huang, R. Textual Analysis for Online Reviews: A Polymerization Topic Sentiment Model. IEEE Access 2019, 7, 91940–91945. [Google Scholar] [CrossRef]
- Fotis, A.; Dimitrios, T.; John, V.; Theodora, V. Using N-Gram Graphs for Sentiment Analysis: An Extended Study on Twitter. In Proceedings of the 2016 IEEE Second International Conference on Big Data Computing Service and Applications (BigDataService), Oxford, UK, 29 March–1 April 2016; pp. 44–51. [Google Scholar]
- Jain, D.K.; Boyapati, P.; Venkatesh, J.; Prakash, M. An Intelligent Cognitive-Inspired Computing with Big Data Analytics Framework for Sentiment Analysis and Classification. Inf. Process. Manag. 2022, 59, 102758. [Google Scholar] [CrossRef]
- Araque, O.; Corcuera-Platas, I.; Sánchez-Rada, J.; Iglesias, C. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Chandrasekaran, G.; Nguyen, T.N.; Hemanth, J.H. Multimodal sentimental analysis for social media applications: A comprehensive review. WIREs Data Min. Knowl. Discov. 2021, 11, e1415. [Google Scholar]
- Prottasha, N.J.; Sami, A.A.; Kowsher; Murad, S.A.; Bairagi, A.K.; Masud, M.; Baz, M. Transfer Learning for Sentiment Analysis Using BERT Based Supervised Fine-Tuning. Sensors 2022, 22, 4157. [Google Scholar] [CrossRef] [PubMed]
- Jain, P.K.; Quamer, W.; Saravanan, V.; Pamula, R. Employing BERT-DCNN with sentic knowledge base for social media sentiment analysis. J. Ambient. Intell. Humaniz. Comput. 2022, 1–13. [Google Scholar] [CrossRef]
- Garg, S.B.; Subrahmanyam, V.V. Sentiment Analysis: Choosing the Right Word Embedding for Deep Learning Model. In Advanced Computing and Intelligent Technologies; Lecture Notes in Networks and Systems; Bianchini, M., Piuri, V., Das, S., Shaw, R.N., Eds.; Springer: Singapore, 2022; Volume 218. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Liu, J.; Zheng, S.; Xu, G.; Lin, M. Cross-domain sentiment aware word embeddings for review sentiment analysis. Int. J. Mach. Learn. Cybern. 2021, 12, 343–354. [Google Scholar] [CrossRef]
- D’Silva, J.; Sharma, U. Automatic text summarization of konkani texts using pre-trained word embeddings and deep learning. Int. J. Electr. Comput. Eng. (IJECE) 2022, 12, 1990–2000. [Google Scholar] [CrossRef]
- Hu, Y.; Ding, J.; Dou, Z.; Chang, H. Short-Text Classification Detector: A Bert-Based Mental Approach. Comput. Intell. Neurosci. 2022. [Google Scholar] [CrossRef]
- Yang, H. Network Public Opinion Risk Prediction and Judgment Based on Deep Learning: A Model of Text Sentiment Analysis. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef]
- Kotzias, D.; Denil, M.; de Freitas, N.; Smyth, P. From Group to Individual Labels Using Deep Features. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 15 August 2015; Association for Computing Machinery: New York, NY, USA; pp. 597–606. [Google Scholar] [CrossRef]
- Singh, K.N.; Devi, S.D.; Devi, H.M.; Mahanta, A.K. A novel approach for dimension reduction using word embedding: An enhanced text classification approach. Int. J. Inf. Manag. Data Insights 2022, 2, 100061. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| Keras Layer | (None, 128) | 4,385,921 |
| Dense Hidden layers | (None, 16) | 2064 |
| Dense Output Layer | (None, 1) | 17 |
| Total Parameters 4,388,002 Trainable Parameters: 4,388,001 Non-trainable Parameters: 1 |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| Keras Layer | (None, 50) | 48,190,600 |
| Dense Hidden layers | (None, 16) | 816 |
| Dense Output Layer | (None, 1) | 17 |
| Total Parameters 48,191,433 Trainable Parameters: 48,191,433 Non-trainable Parameters: 0 |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| Keras Layer | (None, 250) | 252,343,750 |
| Dense Hidden layers | (None, 16) | 4016 |
| Dense Output Layer | (None, 1) | 17 |
| Total Parameters 48,191,433 Trainable Parameters: 48,191,433 Non-trainable Parameters: 0 |
| Classified as Positive | Classified as Negative | |
|---|---|---|
| Actual Positive | TP | FN |
| Actual Negative | FP | TN |
| Text Data Item | Before Using the Sentiment Lexicon | After Using the Sentiment Lexicon |
|---|---|---|
| Characters(no spaces) | 46,744 | 14,182 |
| Characters(with spaces) | 56,616 | 19,212 |
| Number of words | 10,863 | 2989 |
| Number of paragraphs | 996 | 996 |
| Average Number of words per Post/paragraph | 11 | 3 |
| N-Grams | LeBERT-CNN | |||
|---|---|---|---|---|
| Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) | |
| N = 1 | 65.02 | 65.02 | 65.15 | 65.08 |
| N = 2 | 79.45 | 79.50 | 80.04 | 79.77 |
| N = 3 | 88.20 | 88.45 | 89.01 | 88.73 |
| N = 4 | 87.65 | 87.65 | 87.80 | 87.72 |
| All words | 84.00 | 84.00 | 84.20 | 84.10 |
| Embedding Model | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) |
|---|---|---|---|---|
| Glove | 78.50 | 78.56 | 78.70 | 78.63 |
| Le-Glove | 81.50 | 82.00 | 83.01 | 82.50 |
| Word2Vec | 75.50 | 75.50 | 75.80 | 75.65 |
| Le-Word2Vec | 82.40 | 82.45 | 83.15 | 82.80 |
| BERT | 84.00 | 84.00 | 84.20 | 84.10 |
| LeBERT(our Model) | 88.20 | 88.45 | 89.01 | 88.73 |
| Embedding Model | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) |
|---|---|---|---|---|
| Glove | 79.50 | 79.50 | 80.10 | 79.80 |
| Le-Glove | 82.50 | 82.70 | 83.25 | 82.97 |
| Word2Vec | 77.45 | 77.46 | 78.01 | 77.73 |
| LeWord2Vec | 83.00 | 83.02 | 83.42 | 83.22 |
| BERT | 84.01 | 84.08 | 84.63 | 84.35 |
| LeBERT (our Model) | 86.10 | 86.71 | 87.00 | 86.85 |
| Embedding Model | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) |
|---|---|---|---|---|
| Glove | 79.00 | 79.00 | 79.65 | 79.32 |
| Le-Glove | 79.60 | 80.00 | 80.45 | 80.22 |
| Word2Vec | 79.50 | 79.50 | 80.25 | 79.87 |
| Le-Word2Vec | 81.50 | 81.50 | 82.05 | 81.77 |
| BERT | 81.72 | 81.75 | 82.04 | 81.89 |
| LeBERT | 82.40 | 82.40 | 82.64 | 82.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mutinda, J.; Mwangi, W.; Okeyo, G. Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network. Appl. Sci. 2023, 13, 1445. https://doi.org/10.3390/app13031445
Mutinda J, Mwangi W, Okeyo G. Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network. Applied Sciences. 2023; 13(3):1445. https://doi.org/10.3390/app13031445
Chicago/Turabian StyleMutinda, James, Waweru Mwangi, and George Okeyo. 2023. "Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network" Applied Sciences 13, no. 3: 1445. https://doi.org/10.3390/app13031445
APA StyleMutinda, J., Mwangi, W., & Okeyo, G. (2023). Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network. Applied Sciences, 13(3), 1445. https://doi.org/10.3390/app13031445