Abstract
Surround sound systems that play back multi-channel audio signals through multiple loudspeakers can improve augmented reality, which has been widely used in many multimedia communication systems. It is common that a hand-free speech communication system suffers from the acoustic echo problem, and the echo needs to be canceled or suppressed completely. This paper proposes a deep learning-based acoustic echo cancellation (AEC) method to recover the desired near-end speech from the microphone signals in surround sound systems. The ambisonics technique was adopted to record the surround sound for reproduction. To achieve a better generalization capability against different loudspeaker layouts, the compressed complex spectra of the first-order ambisonic signals (B-format) were sent to the neural network as the input features directly instead of using the ambisonic decoded signals (D-format). Experimental results on both simulated and real acoustic environments showed the effectiveness of the proposed algorithm in surround AEC, and outperformed other competing methods in terms of the speech quality and the amount of echo reduction.
1. Introduction
Surround sound systems offer the potential for immersive sound field reproduction [1], enhancing realism in virtual reality and multimedia communication systems [2], such as immersive teleconference and acoustic human–machine interfaces. In a closed-loop teleconference system, the echo signal caused by the acoustic coupling between microphones and loudspeakers has a significant negative impact on hands-free speech communication systems. Conventional AEC methods often use adaptive filters to identify the acoustic echo paths, and the echo signal in each microphone is then estimated and subtracted from each microphone signal [3,4]. However, the adaptive filtering-based algorithms may suffer from the well-known non-unique solution problem [5] due to high cross-correlation between the loudspeaker signals, when there are two or more reproduction channels. Although many algorithms [6,7,8,9] have been proposed to decorrelate the loudspeaker signals so as to solve the non-unique solution problem, the reproduction quality and immersion of the far-end may be affected. Besides, as the number of channels increases, the computational complexity and convergence time will increase, and the control of the step size becomes much more sophisticated [10].
In recent years, deep learning-based methods have been employed in AEC and have achieved significant success. Compared with conventional AEC algorithms, deep learning-based AEC methods have the ability to recover the near-end signals from the microphone signals directly, and they do not need to identify the acoustic echo paths explicitly and also do not suffer from the non-unique solution problem. Lee et al. [11] proposed a deep neural network (DNN)-based residual echo suppression gain estimation, which was then used to remove the nonlinear components after a linear acoustic echo canceller. Zhang et al. [12] formulated AEC as a supervised speech separation problem and proposed a recurrent neural network with bidirectional long short-term memory (BLSTM) to separate and suppress the far-end signal, hence removing the echo. However, due to the non-causality of BLSTM, the usage of this method may be restricted, especially in real-time applications. Cheng et al. [13] proposed a convolutional recurrent network (CRN) model to estimate the non-linear gain from the magnitude spectra of both the microphone and far-end signals for the stereo AEC, which was then multiplied by the spectrum of the microphone signal to estimate near-end speech. Besides, Peng et al. [14] described a three-stage AEC and suppression framework for the ICASSP 2021 AEC Challenge, where the partitioned block frequency domain least mean square (PBFDLMS) with a time alignment was firstly implemented to cancel the linear echo components, and two deep learning networks were then proposed to suppress the residual echo and the non-speech residual noise simultaneously. In addition, Zhang et al. [15] proposed a neural cascade architecture, including a CRN module and an LSTM module, which is used for joint acoustic echo and noise suppression to address both single-channel and multi-channel AEC problems. More recently, Cheng et al. [16] proposed a deep complex multi-frame filtering network for stereophonic AEC, where two deep learning-based modules were separately used for suppression of the linear and residual echo components.
Nowadays, with the widespread adoption of virtual reality and immersive teleconference, the surround sound-based real-time communication system will be popularized in the future trend. It is well known that the Ambisonic technique [17,18,19] is one basic and common surround sound recording and reproduction approach, where the Ambisonics encoder decomposes a sound field signal into spherical harmonics, i.e., B-format, and the Ambisonic decoder transforms the B-format signal into a multi-channel sound field signal, i.e., D-format, and they are then played back by multiple loudspeakers with a special layout, for example, the 5.1 channel surround sound layout. To the best of our knowledge, Ambisonics-based surround AEC methods have not been well studied yet. This paper proposes a gated convolutional recurrent network (GCRN) model to suppress the echo signal for the surround sound reproduction system. The input features of the GCRN model are the compressed complex spectra of the microphone signal and the B-format signals of the far-end instead of the D-format signals. This setting is mainly under the consideration that the actual loudspeakers layout in the near-end room may be different from the desired layout due to the obstacles or artificial errors, leading to the mismatch of the Ambisonic decoding matrix. The output of the GCRN model was the compressed complex spectrum of the near-end speech and the cost function was calculated between the estimated and real near-end speech signals with regard to their real and imaginary parts of the compressed complex spectra, respectively. The proposed algorithm was evaluated using the perceptual evaluation of speech quality (PESQ) [20] in double-talk scenarios and echo return loss enhancement (ERLE) in single-talk scenarios. The GCRN-based algorithm showed its effectiveness in both the simulated and real acoustic environments. In summary, this paper has two main contributions. On the one hand, the surround AEC is taken into consideration and the Ambisonics technique is adopted to record the surround sound for reproduction. On the other hand, the B-format signals instead of the D-format signals are used as the references to achieve better generalization against different non-standard loudspeaker layouts.
The rest of this paper is organized as follows. A brief introduction to the fundamentals of Ambisonics is described in Section 2. The surround AEC problem and symbols definition are formulated in Section 3. Section 4 presents the used network architecture and the compressed complex spectrum. Experimental settings and results as well as analysis are given in Section 5. In Section 6, we give our conclusions.
2. First-Order Ambisonics (B-Format)
Ambisonics is unique in being a total systems approach to reproducing or simulating the spatial sound in all its dimensions [17] and the Ambisonic encoder decomposes the sound field at a particular point of space on the orthogonal basis of spherical harmonics functions [21]. The B-Format is the first-order Ambisonics, which encodes the directional information of a given three-dimensional sound field into four channels called W, X, Y, Z, where W is the omini-directionial channel, X, Y and Z are the three figure-of-eight directional channels [22]. For a point sound source assimilated to a plane-wave coming from azimuth and elevation , where n denotes the time index, the decomposition of the sound field on these four channels can be formulated as follows [22,23]:
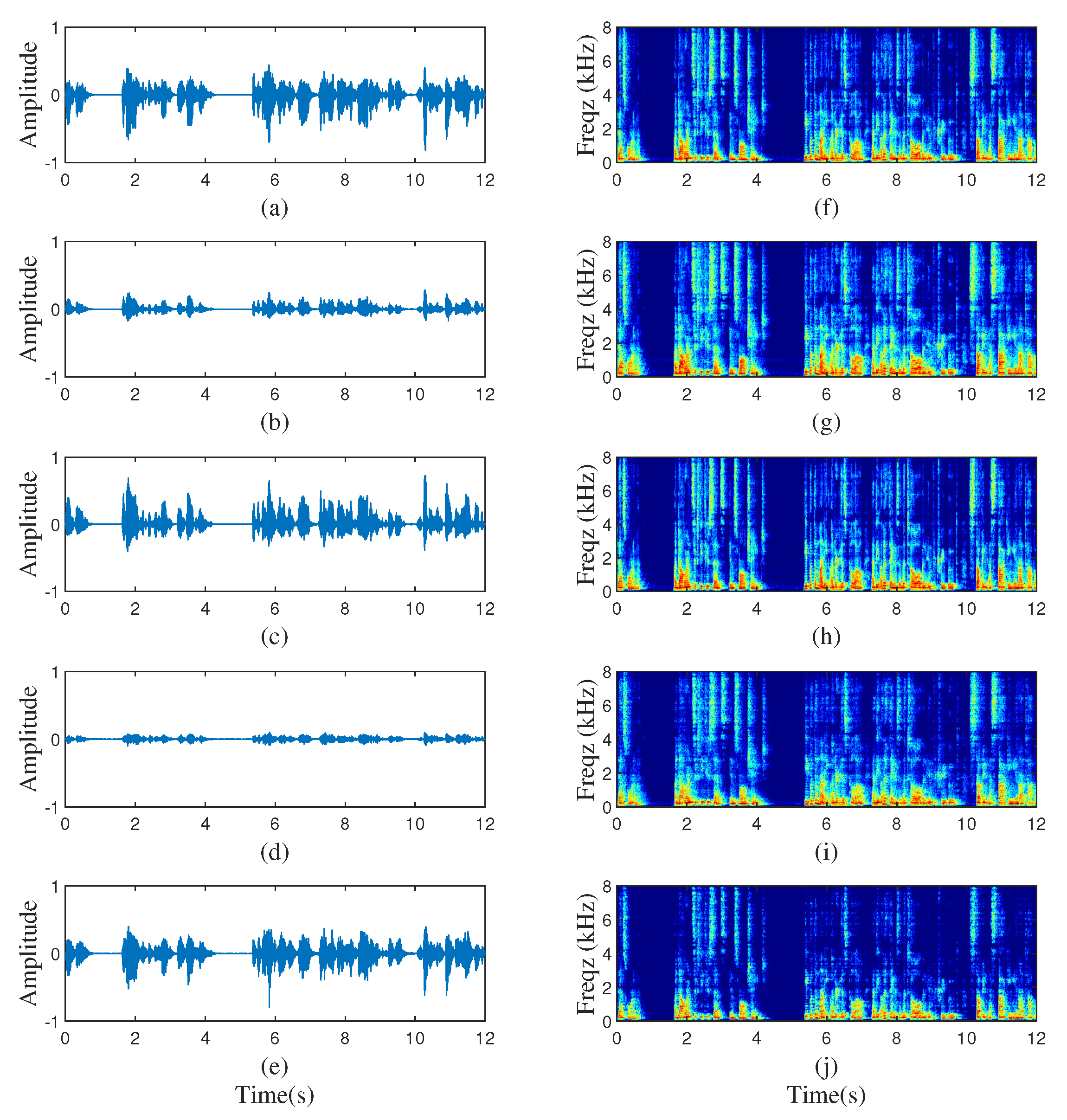
Ambisonic-encoded signals carry the spatial information of the entire sound field. To drive the loudspeaker signals with a particular layout, an Ambisonic decoder is needed to transform the B-format signals into D-format (loudspeaker signals). The decoding matrix used in this paper can be found in [24]. To show the characteristics of the B-format signals and their corresponding echo components received by a microphone intuitively, the waveforms and spectrograms of a randomly chosen sample are shown in Figure 1. In the left panel of Figure 1, from top to bottom, Figure 1a–d plots the time-domain W-, X-, Y- and Z-channel signals of B-format recording, respectively, and Figure 1e plots the echo signal. In the right panel of Figure 1, Figure 1f–j plot spectrograms of Figure 1a–e.

Figure 1.
Waveforms and Spectrograms of B-format and echo signals. (a,f) B-format W-channel signal, (b,g) B-format X-channel signal, (c,h) B-format Y-channel signal, (d,i) B-format Z-channel signal, (e,j) echo signal.
3. Signal Model
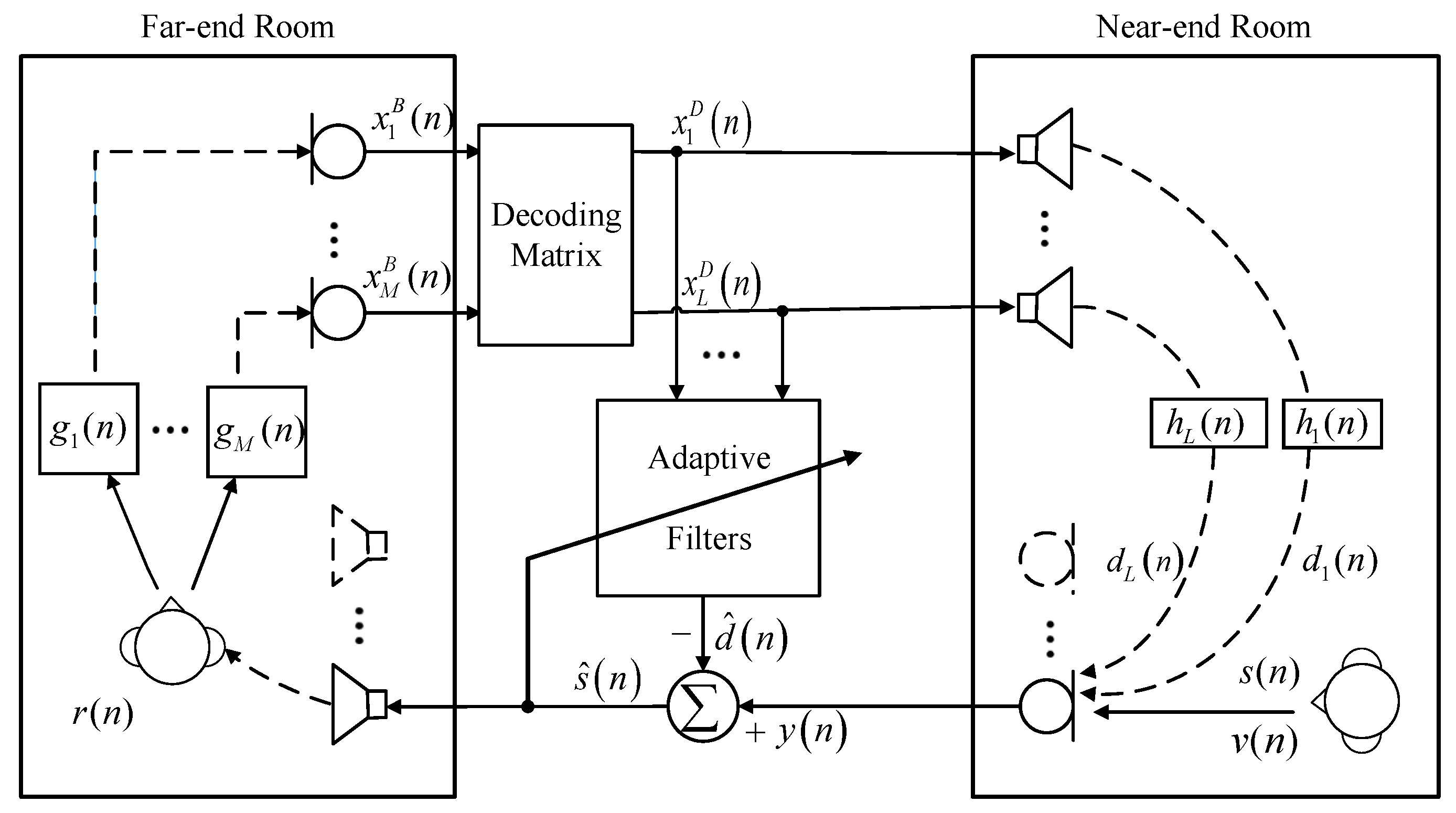
Assuming there are L loudspeakers and one microphone in the near-end room, and there is an Ambisonics recording device in the far-end room, then the typical diagram of the AEC method is shown in Figure 2, and the microphone signal in the near-end room can be formulated as:
where denotes the signals played back by the loudspeakers with l denoting the index of loudspeakers, which can be regarded as the D-format signals in the surround sound system. denotes the room impulse responses (RIRs) from the loudspeakers to the microphone in the near-end room and ∗ denotes the linear convolution operation. The near-end speech signal is denoted as , and represents the additive noise signal. The echo signals transmitted from the loudspeakers to the microphone are denoted as . In the far-end room, as shown in Figure 2, the Ambisonics recordings are denoted as , with m denoting the index of Ambisonics input channels, which are generated by the source signal via the acoustic paths characterized by the impulse responses . can be decoded to the loudspeaker signals via a decoding matrix. The adaptive filtering-based AEC methods attempt to cancel out the echo signal from by subtracting the estimated echo signal via the adaptive filters. However, it is difficult for a conventional AEC method to entirely reduce the echo signals and the residual echo signal inevitably exists in the estimated near-end signal . Besides, in the surround sound condition, the conventional AEC methods may suffer from the non-unique solution problem due to the high cross-correlation between the loudspeaker signals.
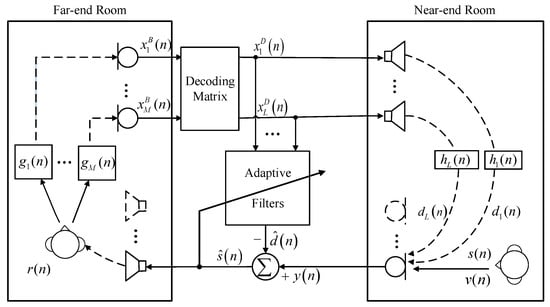
Figure 2.
Diagram of a surround sound acoustic echo system.
4. Proposed GCRN-Based Surround AEC
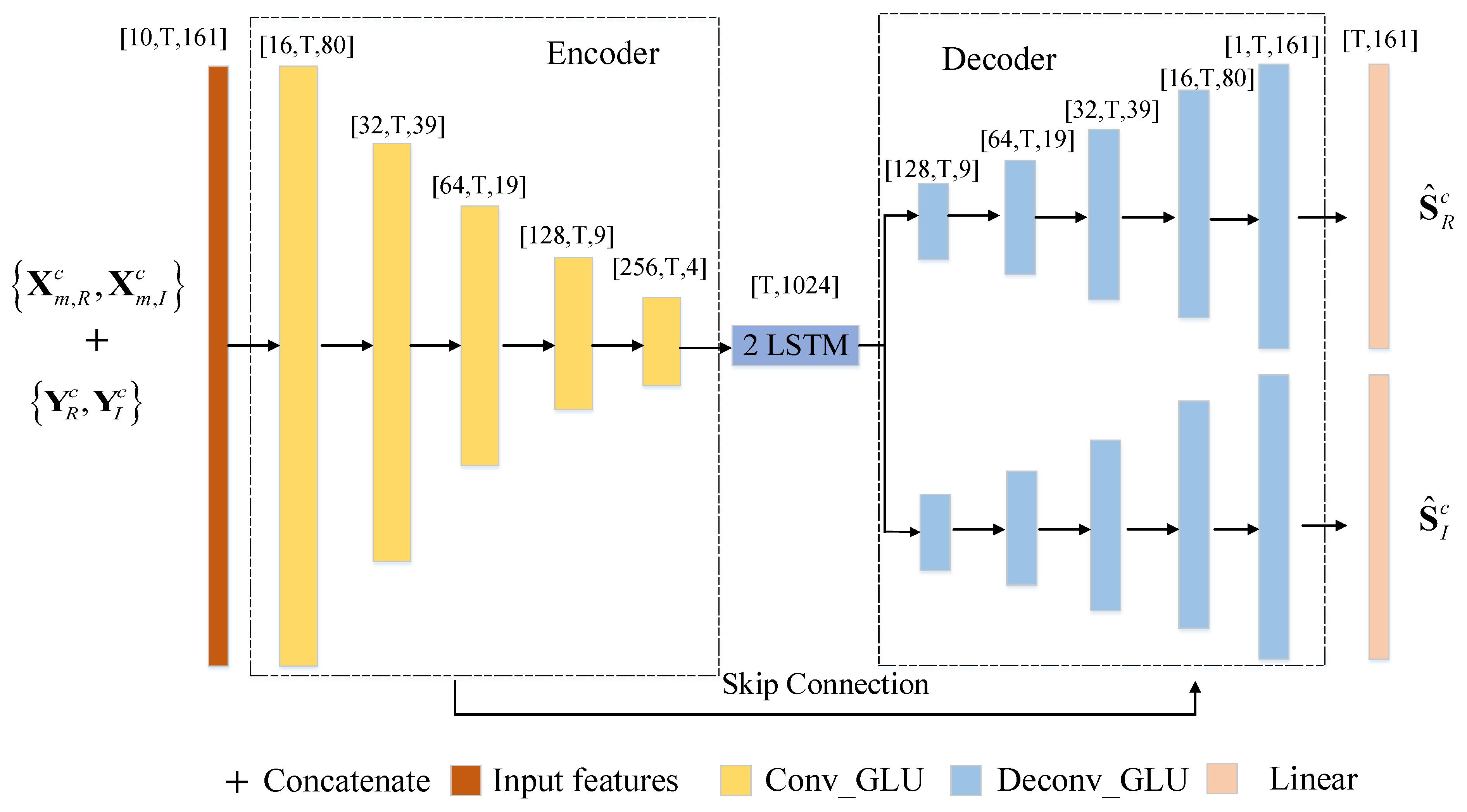
To recover the near-end signal from microphone recordings directly without decorrelating the far-end signals, a GCRN model-based algorithm was proposed as shown in Figure 3. Note that we chose the B-format signals together with the microphone signals as the inputs of the neural network. In Figure 3, and represent the real and imaginary part of the compressed complex spectrum of B-format signal , respectively. They can be defined as follows:
where denotes the complex spectra of , , and represents the magnitude and phase information of , respectively. The value of the power compressed coefficient was set as in this work [25,26]. Accordingly, and denote the real and imaginary part of the spectra of the microphone and estimated near-end speech signal correspondingly.
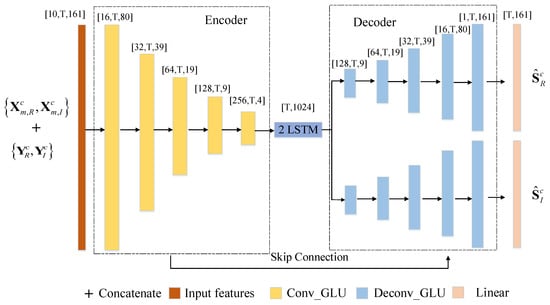
Figure 3.
The architecture illustration of the GCRN model for surround AEC.
4.1. Feature Extraction and Signal Reconstruction
In the GCRN model, the compressed complex spectra of the microphone signal and the four-channel B-format signals were used as the input features. All signals were sampled at 16 kHz. A 20 ms Hanning window with 50% overlap between adjacent frames was used to produce a set of time frames in this work, and a 320-point STFT (short-time Fourier transform) was adopted to generate input features, leading to a 161-dimensional spectral feature in each frame. The compressed complex spectra of the microphone signal and the four-channel B-format signals were concatenated as input feature maps, which have a shape of , where T represents the total frames. They were taken as the input features to train the GCRN model. As for the output, the real and imaginary parts of the compressed complex spectrum of near-end speech were used. The loss function can be formulated as follows:
In the enhancement stage, the estimated real and imaginary parts were used to recover the spectrum near-end signal, which was then used to reconstruct the estimated near-end signal in the time domain by the inverse STFT and the overlap-add method. The estimated magnitude and phase information is given by
finally, the spectrum can be written as:
where and are the estimated magnitude and phase information of the near-end speech , respectively.
4.2. Model Architecture
In this paper, the GCRN model was used to recover the near-end speech, which is mainly comprised of three components, namely one convolutional encoder, LSTM modules, and two decoders for both real and imaginary part reconstruction. The encoder consists of five convolutional-gated linear units (Conv-GLUs) layers [27], which extract the high-level dimension feature patterns from the inputs, while the decoder serves as the mirror version of the encoder to gradually recover the original size [28]. Each decoder has five deconvolutional-gated linear units (Deconv-GLUs). Each convolution or deconvolution layer is successively followed by a batch normalization (BN) [29] and an exponential linear unit (ELU) [30] activation function. Between the encoder and the decoder, two LSTMs are stacked to effectively establish the sequential correlation between adjacent frames. Additionally, the skip connection [31] was also adopted to concatenate the output of each encoder layer to the input of the corresponding decoder layer, which effectively mitigates the information loss. One linear layer is stacked in the end of each decoder to obtain the real or imaginary estimation.
The detailed parameter setup of the GCRN architecture is presented in Table 1. The format was used to specify the input size and output size of each layer. The (kernelSize, strides, outChannels) format was adopted to represent the hyperparameters of each layer. The number of input feature maps in each decoder layer is doubled because of the skip connections.

Table 1.
Detailed parameter setup for GCRN.
5. Experimental Results and Discussions
5.1. Experiment Settings
The English reading speech of the DNS-challenge dataset [32] was used as the near-end and the far-end reference signals to perform experiments in the surround AEC situation, which was derived from Librivox, consisting of 65,348 clean clips from 1948 speakers. Each speaker was taken from about 33 utterances with about 30 s for each. Eighty percentages of speakers were used for training and the remaining twenty percentages for testing. For each training sample, two speakers were randomly selected, and one was used as the far-end speaker and the other was used as the near-end speaker. We randomly cut 12 s long segments from each utterance of the far-end speaker, and the segment was used as the far-end speech. For the near-end speech, we randomly cut 3 s long segments from each utterance of the near-end speaker, and this segment was zero-padded on both sides to ensure that each near-end speech had the same duration as the far-end speech. The zero-padding operation was used to simulate the single-talk scene in real-world scenarios.
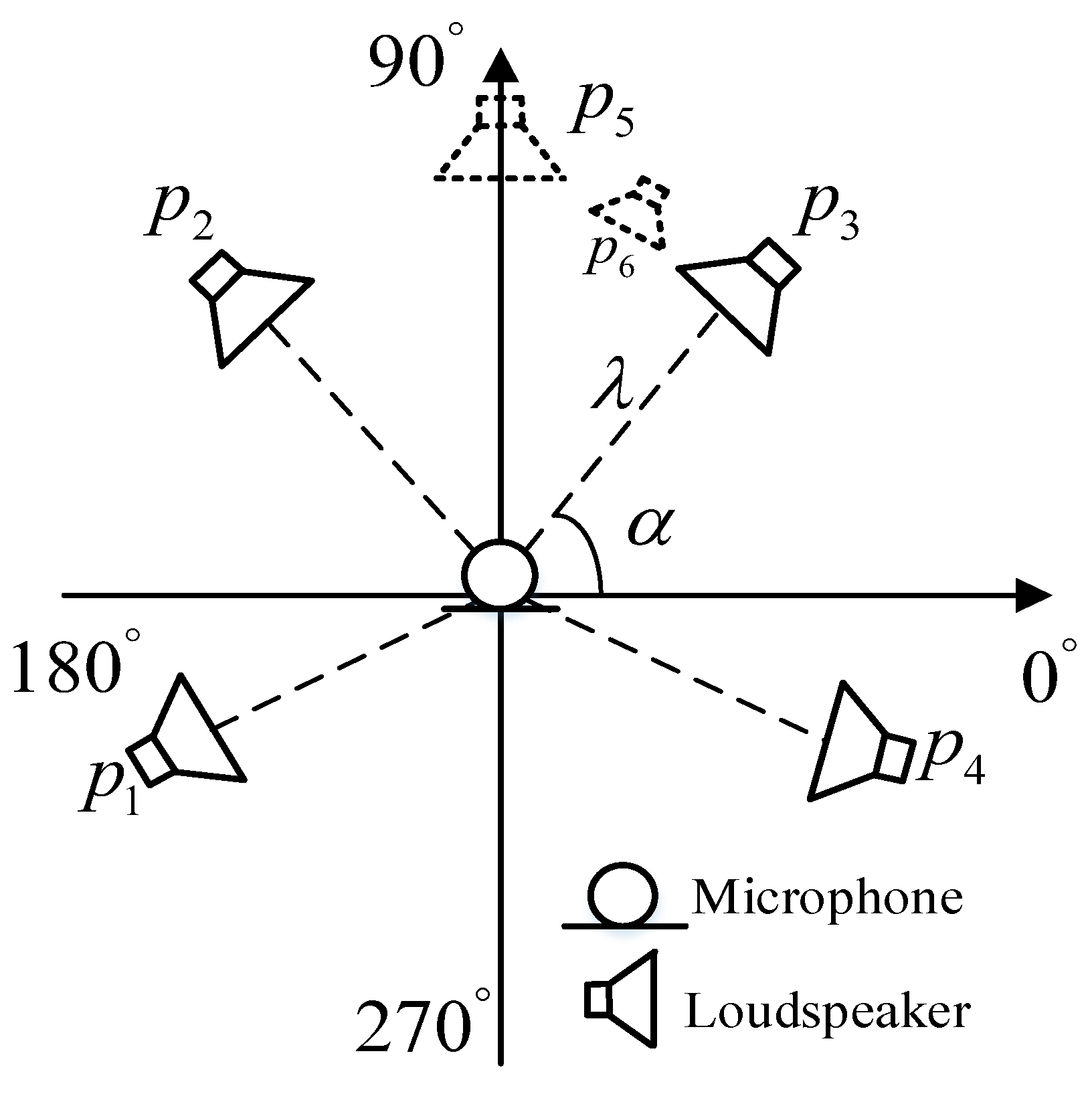
The RIRs were generated using the image method [33]. In the far-end room, four microphones with different directivities were used to simulate an Ambisonics recording device located in the center of the room, including an omni-directional microphone, dubbed W, and three figure-of-eight directional microphones, dubbed X, Y and Z, respectively. Signals recorded by these four microphones constitute the B-format signal. Thus, for each sound source and Ambisonics microphone pair, we can get four RIRs, which were then defined as an Ambisonic RIRs group. In the near-end room, the RIRs were generated according to the position of the microphone, its directivity, and loudspeakers. To improve the generalization capacity of the DNN, the length and width of the simulated rooms were randomly sampled from with 1 m interval and the height was sampled form . In each simulated room, the reverberation time value was randomly sampled from . The locations of the microphones and loudspeakers in the simulated room are shown in Figure 4, where the 5.1 surround sound system without the center and subwoofer channels was taken into consideration and the microphones were fixed in the center of each simulated room. As illustrated in Figure 4, four surround loudspeakers were used and represents the angle between loudspeakers and the horizontal axis. represents the distance between the loudspeakers and microphones. For standard (ITU-R BS 77) 5.1 surround set-up [34], the angles for were set to . The nonstandard 5.1 surround set-up was also considered. In the nonstandard conditions, the angle for loudspeaker was randomly sampled from with interval, and similarly, the ranges for were set to be , and with interval, respectively. was sampled from . In the far-end room, the angle between the speaker and horizontal axis was randomly sampled from with interval, and the distance between the speakers and microphones was sampled from . Besides, the height of the microphones, loudspeakers and sound sources were all set to 1.2 m.
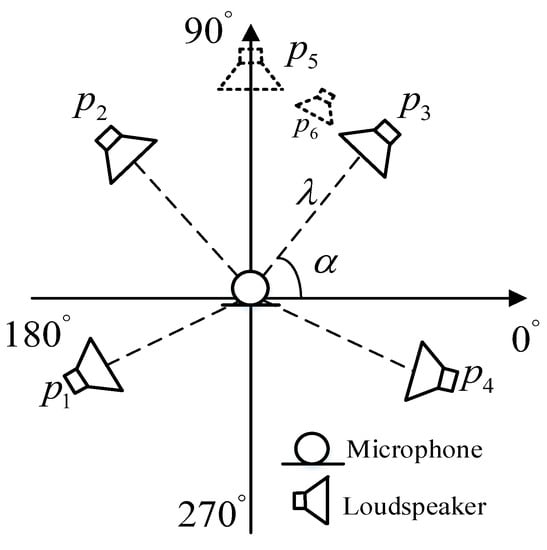
Figure 4.
Location of microphones and loudspeakers.
The far-end speech was convolved with four RIRs, which are from the same Ambisonic RIRs group as mentioned above, resulting in the four-channel Ambisonic B-format signals. The B-format signals were then decoded to the D-format signals by using the decoding rules as described in [21,24]. The echo signals were generated by convolving the D-format signals with randomly selected RIRs. Finally, the near-end speech was mixed with the echo signals under a signal-to-echo ratio (SER) value randomly selected from dB to get the near-end microphone signals. The SER is evaluated on double-talk scenarios, which is defined as:
As described in [13], white Gaussian noise was also taken into consideration as the microphone internal noise and the signal-to-noise ratio (SNR) was set as 30 dB, which is defined as:
The mean squared error (MSE) between the estimated and true compressed complex spectra of the near-end signal was used as a loss function, and optimized by the Adam algorithm [35]. The learning rate was set to . The mini-batch size was set to 16 at the utterance level and each batch took about 1.20 s in the training stage. The GCRN network was trained for 50 epochs. All training samples were padded with zeros to have the same number of time frames as the longest sample within a mini-batch and cross-validation was used to select the best model and prevent overfitting.
In single-talk scenarios, the AEC performance is evaluated in terms of ERLE and it is defined as:
In double-talk scenarios, PESQ is used to evaluate the AEC performances of different algorithms. PESQ is a widely used speech quality metric which ranges from to , and highly correlates with subjective scores [20]. For both the ERLE and PESQ metrics, a higher score indicates better performance.
The least mean square (LMS) algorithm is one of the most widely used adaptation methods in the echo path identification. Among LMS algorithms, the partitioned block frequency domain LMS (PBFDLMS) algorithm is popular for its lower computational complexity than the time-domain LMS algorithms and its lower latency than frequency-domain LMS algorithms, especially when the acoustic echo path is relatively long [14]. To validate the proposed algorithm, the PBFDLMS algorithm with Wiener post-filtering was chosen as the baseline. The PBFDLMS algorithm should be combined with the double-tale detector (DTD) algorithm [36,37]. In order to reduce the performance degradation caused by the DTD method, an ideal DTD was assumed for the PBFDLMS algorithm. The test mixtures were generated in the same way, which were not used in the training procedure.
5.2. Performance and Analysis
The performance of the proposed GCRN-based AEC algorithm trained with B-format data (denoted as B-format Model) was firstly analyzed through comparison with the traditional PBFDLMS with the Wiener post-filtering method. Besides, we also trained a model using the D-format signals as the reference signal (denoted as D-format Model). For this model, the standard 5.1 surround sound set-up, as mentioned in Section 5.1, was used, and the decoding rules for this model were fixed. As for the B-format model, the decoding rules are in accordance with the loudspeaker layouts. Moreover, a model using only one channel B-format data and the microphone signal (denoted as Singlechn Model) as inputs was also performed to compare with the B-format model.
The performance of the B-format and D-format model was firstly tested in standard 5.1 surround sound set-up condition without the center and the subwoofer channels. One test set generated with standard loudspeaker layouts was used, where the sets were the same as the ones used to train the D-format model. The PESQ and ERLE results in this situation are shown in Table 2. The value was set to s in the far-end room. From Table 2, one can see that in the standard loudspeaker assignment condition, the D-format model outperformed the B-format model in all conditions in terms of the ERLE criterion, because the tested surround sound set-up matched the training dataset of the D-format model completely. Both models had similar performances in terms of the PESQ criterion.
Table 2.
Performance comparisons among different algorithms in different SERs and the standard surround set-up conditions.
To further evaluate the generalization capability of GCRN-based AEC algorithm to unseen RIRs and loudspeaker layouts, different settings were used to generate the RIRs in the near-end room. As shown in Figure 4, the angle for loudspeaker was randomly sampled from with interval, and similarly, the ranges for were set to be , and with interval, respectively. The room dimensions were the same as the ones used in the training set. Note that the settings were different from that in the training sets, thus no RIRs were overlapped between the training and test sets. In this experiment, the value was set to s in the far-end room, and we tested the performance of each algorithm in different values (0.3 s, 0.6 s, 0.9 s) of the near-end room. The PESQ and the ERLE results for different SER conditions are shown in Table 3. One can find that the GCRN-based surround AEC method performed much better than the other algorithms in every test condition. For the D-format model, the decoding rules mismatched with ones used in the training procedure, which is the main reason for its performance degradation. As for the one-channel model, it seemed that one-channel information was insufficient for the model to achieve the best performance. Besides, compared with Table 2 and Table 3, one can find that the D-format model performed much worse in the nonstandard surround set-up, while the B-format model had similar performance in each test condition.
Table 3.
As in Table 2 but for the nonstandard surround set-up conditions.
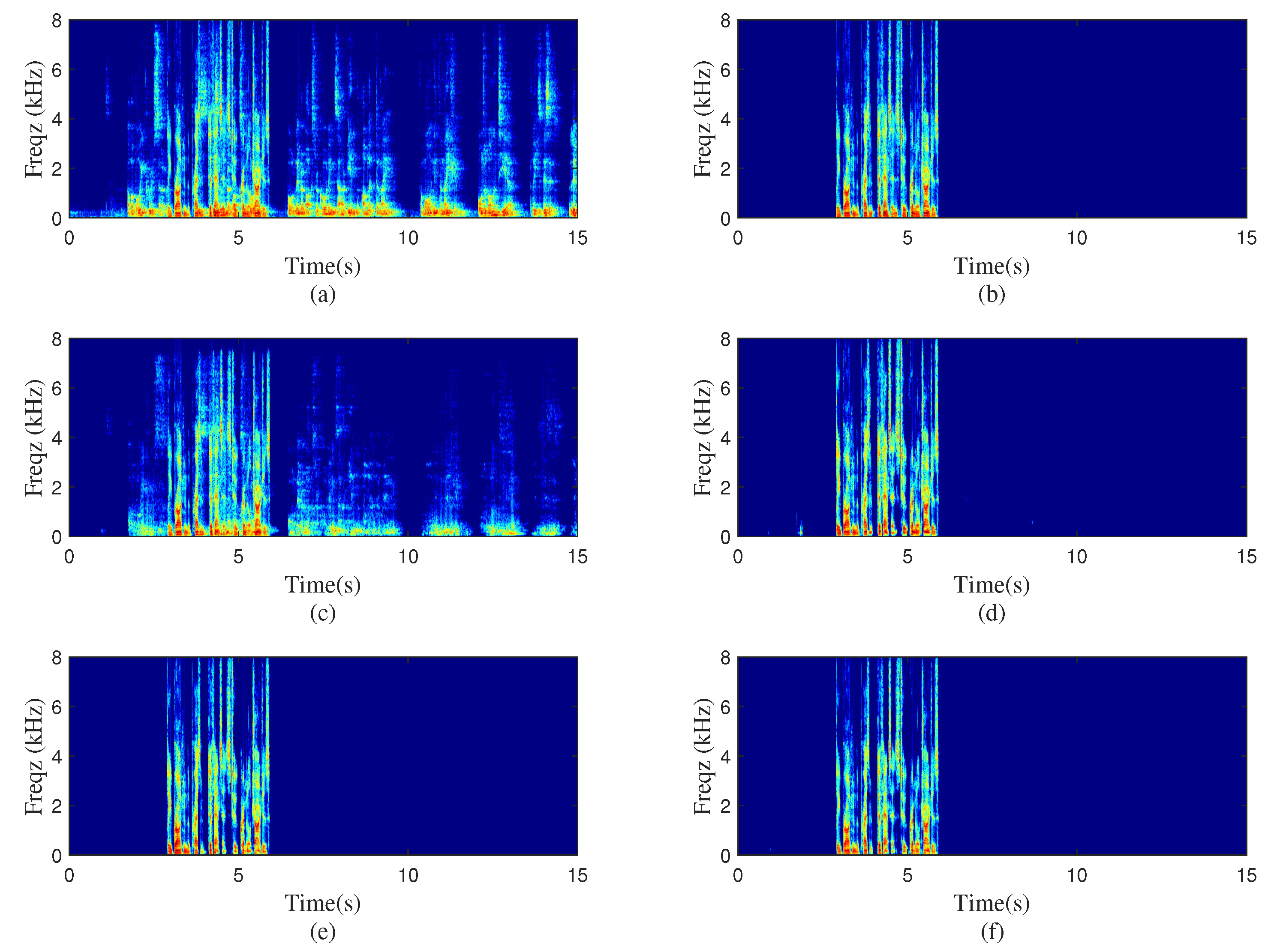
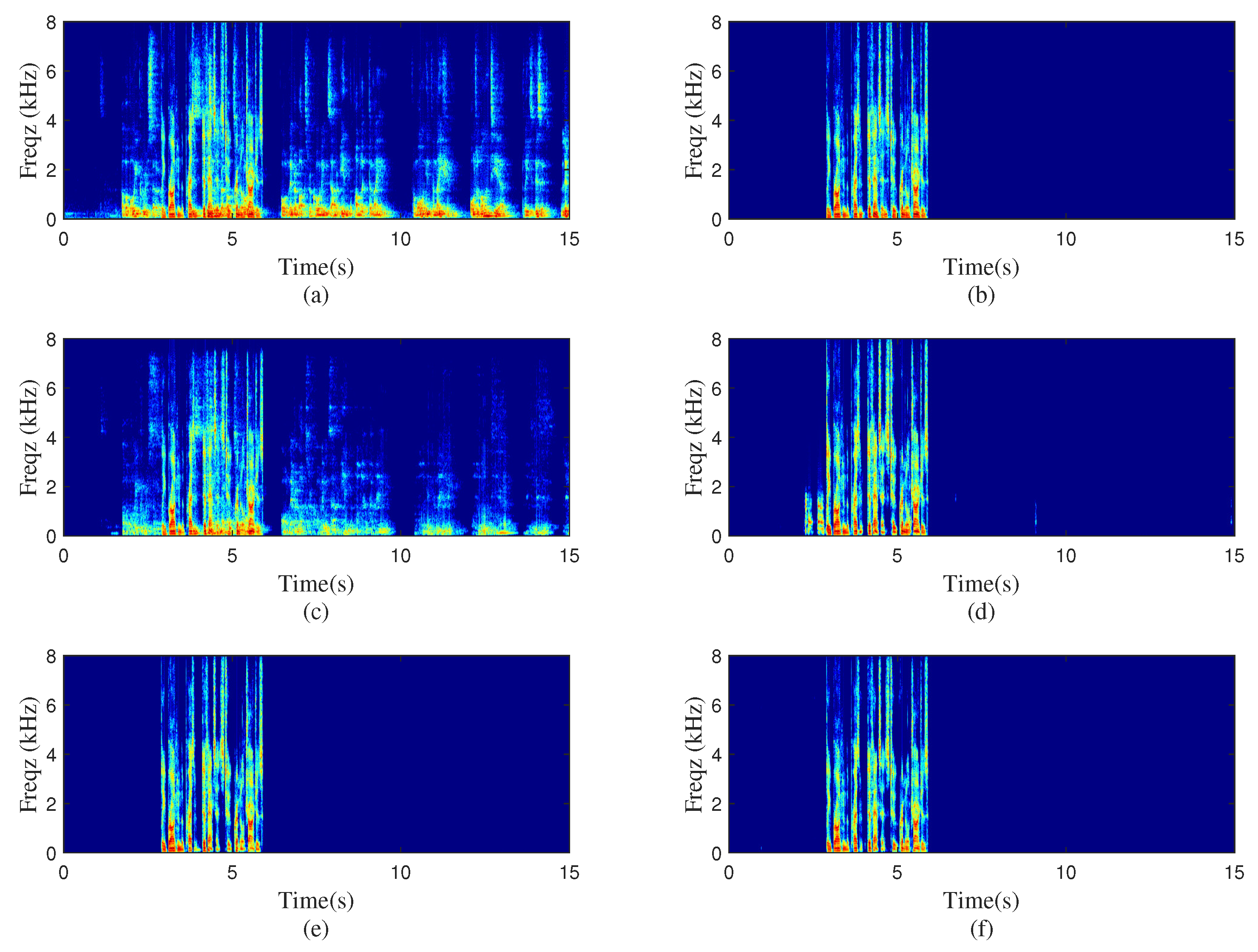
To test the performance of the proposed method in the real acoustic environment, real-world experiments were conducted in one meeting room. The values of the far-end room and near-end room were about s and s, respectively. The sizes of the two meeting rooms were about and , separately. In the far-end room, the distance between the speaker and Ambisonics microphone was about m. The recorded B-format signal in the far-end room was then decoded and played by the loudspeakers in the near-end room. Meanwhile, the echo signal was picked up by a microphone. Here, two different settings, as illustrated in Figure 4, were used to represent the standard and nonstandard loudspeakers assignment situations and the two sets for loudspeakers are and , separately. As the reverberation of near-end speech was not taken into consideration, the near-end signal was directly mixed with the recorded echo signal at dB to generate the near-end microphone signal. The spectrogram of the real recordings with standard or nonstandard loudspeaker layouts processed by different algorithms are plotted in Figure 5 and Figure 6. Figure 5 represents the standard loudspeakers assignment situation; the nonstandard scene is shown in Figure 6. The ERLE and PESQ scores of two models were also presented in the two figures. As shown in these two figures, both the D-format and B-format models performed well in the standard situation. Note that in the real experiment, the deviation of angle and distance between the loudspeakers and microphone inevitably existed. Although the decoding rules were the same as the training stage, the contribution of each loudspeaker signal for the echo signal was different from the standard condition due to the existence of the deviation. This can be the main reason for the performance degradation of the D-format model. Besides, the characteristics of each loudspeaker can also affect the produced echo. In the unknown decoding rule scene, the performance of the B-format model was much superior than the D-format model, indicating the greater robustness of the B-format model for practical applications.
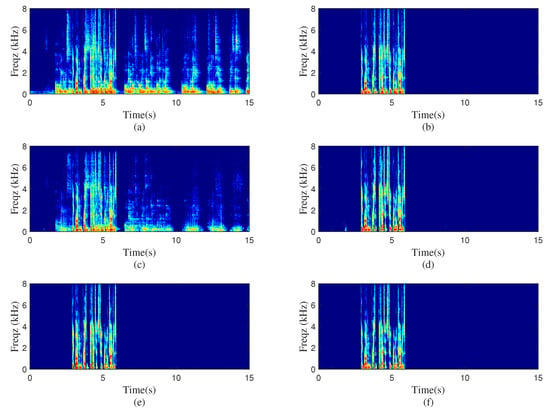
Figure 5.
Spectrograms processed by different methods with standard loudspeakers layout. (a) Microphone signal, , (b) clean near-end speech, (c) PBFDLMS algorithm, dB, , (d) D-format model-based algorithm, dB, , (e) Singlechn model-based algorithm, dB, , (f) B-format model-based algorithm, dB, .
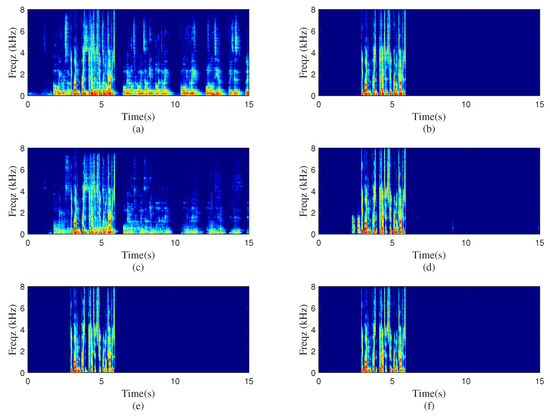
Figure 6.
Spectrograms processed by different methods with nonstandard loudspeakers layout. (a) Microphone signal, , (b) clean near-end speech, (c) PBFDLMS algorithm, dB, , (d) D-format model-based algorithm, dB, , (e) Singlechn model-based algorithm, 52.56 dB, , (f) B-format model-based algorithm, dB, .
6. Conclusions
This paper proposed a compressed complex spectrum mapping approach for surround AEC, and the method does not need to identify the acoustic echo paths explicitly, and thus does not suffer from the non-unique solution problem. The proposed method used the B-format signals instead of the far-end D-format loudspeaker signals as the reference signals of the AEC algorithm. Experimental studies showed that the model trained with the B-format signals was more robust than that trained with D-format signals against various loudspeaker layouts, including the standard and nonstandard 5.1 surround set-ups. The proposed algorithm outperformed the traditional PBFDLMS in both the single-talk and double-talk scenarios. Experimental results in real acoustic scenarios further confirmed the effectiveness of this method. In the near future, we will explore more effective network structures, such as Transformer-based networks [38], and compare them with this work.
Author Contributions
Conceptualization, G.L. and C.Z.; methodology, G.L. and Y.K.; software and validation, G.L. and Y.K.; writing—original draft preparation, G.L.; writing—review and editing, Y.K. and C.Z.; supervision, X.L.; funding acquisition, Y.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant 62101550.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this paper:
| AEC | Acoustic echo cancellation |
| DNN | Deep neural network |
| BLSTM | Bidirectional long short-term memory |
| CRN | Convolutional recurrent network |
| PBFDLMS | Partitioned block frequency domain least mean square |
| GCRN | Gated convolutional recurrent network |
| PESQ | Perceptual evaluation of speech quality |
| ERLE | Echo return loss enhancement |
| STFT | Short-time Fourier transform |
| Conv-GLUs | Convolutional gated linear units |
| Deconv-GLUs | Deconvolutional gated linear units |
| BN | Batch normalization |
| ELU | Exponential linear unit |
| SER | Signal-to-echo ratio |
| SNR | Signal-to-noise ratio |
| MSE | Mean squared error |
| RIRs | Room impulse responses |
References
- Poletti, M.A. Three-dimensional surround sound systems based on spherical harmonics. J. Audio Eng. Soc. 2005, 53, 1004–1024. [Google Scholar]
- Buchner, H.; Spors, S. A general derivation of wave-domain adaptive filtering and application to acoustic echo cancellation. In Proceedings of the 2008 42nd Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 26–29 October 2008; pp. 816–823. [Google Scholar]
- Schneider, M.; Kellermann, W. The generalized frequency-domain adaptive filtering algorithm as an approximation of the block recursive least-squares algorithm. Eurasip. J. Adv. Sign. Process. 2016, 1, 1–15. [Google Scholar]
- Hänsler, E. The hands-free telephone problem-An annotated bibliography. Signal Process 1992, 27, 259–271. [Google Scholar] [CrossRef]
- Sondhi, M.M.; Morgan, D.R.; Hall, J.L. Stereophonic acoustic echo cancellation-an overview of the fundamental problem. IEEE Signal Process Lett. 1995, 2, 148–151. [Google Scholar] [CrossRef] [PubMed]
- Romoli, L.; Cecchi, S.; Piazza, F. A combined approach for channel decorrelation in stereo acoustic echo cancellation exploiting time-varying frequency shifting. IEEE Signal Process Lett. 2013, 20, 717–720. [Google Scholar] [CrossRef]
- Gansler, T.; Eneroth, P. Influence of audio coding on stereophonic acoustic echo cancellation. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 12–15 May 1998; pp. 3649–3652. [Google Scholar]
- Ali, M. Stereophonic acoustic echo cancellation system using time-varying all-pass filtering for signal decorrelation. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 12–15 May 1998; pp. 3689–3692. [Google Scholar]
- Herre, J.; Buchner, H.; Kellermann, W. Acoustic echo cancellation for surround sound using perceptually motivated convergence enhancement. In Proceedings of the 2007 IEEE International Conference on Acoustics, Honolulu, HI, USA, 15–20 April 2007; pp. 17–120. [Google Scholar]
- Emura, S.; Haneda, Y. A method of coherence-based step-size control for robust stereo echo cancellation. In Proceedings of the 2003 IEEE International Conference on Accoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; pp. 592–595. [Google Scholar]
- Lee, C.M.; Shin, J.W.; Kim, N.S. DNN-based residual echo suppression. In Proceedings of the 16th Annual Conference of the International Speech Communication, Dresden, Germany, 6–10 September 2015; pp. 1775–1779. [Google Scholar]
- Zhang, H.; Wang, D. Deep learning for acoustic echo cancellation in noisy and double-talk scenarios. In Proceedings of the 19th Annual Conference of the International Speech Communication, Hyderabad, India, 2–6 September 2018; pp. 3239–3243. [Google Scholar]
- Cheng, L.; Peng, R.; Li, A.; Zheng, C.; Li, X. Deep learning-based stereophonic acoustic echo suppression without decorrelation. J. Acoust. Soc. Am. 2021, 150, 816–829. [Google Scholar] [CrossRef] [PubMed]
- Peng, R.; Cheng, L.; Zheng, C.; Li, X. ICASSP 2021 acoustic echo cancellation challenge: Integrated adaptive echo cancellation with time alignment and deep learning-based residual echo plus noise suppression. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 146–150. [Google Scholar]
- Zhang, H.; Wang, D. Neural Cascade Architecture for Multi-Channel Acoustic Echo Suppression. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2326–2336. [Google Scholar] [CrossRef]
- Cheng, L.; Zheng, C.; Li, A.; Peng, R.; Li, X. A deep complex network with multi-frame filtering for stereophonic acoustic echo cancellation. In Proceedings of the 23rd INTERSPEECH Conference, Songdo Convension, Incheon, Korea, 18–22 September 2022; pp. 2508–2512. [Google Scholar]
- Gerzon, M.A. Ambisonics in multichannel broadcasting and video. J. Audio Eng. Soc. 1985, 33, 859–871. [Google Scholar]
- Malham, D.G.; Myatt, A. 3-D sound spatialization using ambisonic techniques. Comput. Music J. 1995, 19, 58–70. [Google Scholar] [CrossRef] [Green Version]
- Noisternig, M.; Musil, T.; Sontacchi, A.; Holdrich, R. 3D binaural sound reproduction using a virtual ambisonic approach. In Proceedings of the 2003 International Symposium on Virtual Environments, Human-Computer Interfaces and Measurement Systems, VECIMS 2003, Lugano, Switzerland, 27–29 July 2003; pp. 174–178. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Politis, A. Microphone Array Processing for Parametric Spatial Audio Techniques. Ph.D. Thesis, Department of Signal Processing and Acoustics, Aalto University, Espoo, Finland, 2016. [Google Scholar]
- Daniel, J.; Rault, J.B.; Polack, J.D. Ambisonics encoding of other audio formats for multiple listening conditions. In Proceedings of the 105th Convention of the Audio Engineering Society, San Francisco, CA, USA, 26–29 September 1998. [Google Scholar]
- Arteaga, D. Introduction to Ambisonics; Escola Superior Politècnica Universitat Pompeu Fabra: Barcelona, Spain, 2015; pp. 6–8. [Google Scholar]
- Zotter, F.; Pomberger, H.; Noisternig, M. Energy-preserving ambisonic decoding. Acta Acust. United Acust. 2012, 98, 37–47. [Google Scholar] [CrossRef]
- Li, A.; Zheng, C.; Peng, R.; Li, X. On the importance of power compression and phase estimation in monaural speech dereverberation. JASA Exp. Lett. 2021, 1, 014802. [Google Scholar] [CrossRef] [PubMed]
- Li, A.; Peng, R.; Zheng, C.; Li, X. A supervised speech enhancement approach with residual noise control for voice communication. Appl. Sci. 2020, 10, 2894. [Google Scholar] [CrossRef] [Green Version]
- Tan, K.; Wang, D. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 380–390. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lile, France, 6–11 July 2015; pp. 448–456.
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Reddy, C.K.; Dubey, H.; Koishida, K.; Nair, A.; Gopal, V.; Cutler, R.; Srinivasan, S. Interspeech 2021 deep noise suppression challenge. arXiv 2021, arXiv:2101.01902. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Neukom, M. Decoding second order ambisonics to 5.1 surround systems. In Proceedings of the 121st Convention Papers 2006, San Francisco, CA, USA, 5–8 October 2006; pp. 1399–1406. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Gänsler, T.; Benesty, J. The fast normalized cross-correlation double-talk detector. Signal Process 2006, 86, 1124–1139. [Google Scholar] [CrossRef]
- Buchner, H.; Benesty, J.; Gansler, T.; Kellermann, W. Robust extended multidelay filter and double-talk detector for acoustic echo cancellation. IEEE/ACM Trans. Audio Speech Lang. Process. 2006, 14, 1633–1644. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5999–6009. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).