1. Introduction
Due to the rapid proliferation of electronic medical records and the varied data formats they encompass, individuals are encountering growing difficulties in the pursuit of clinical knowledge. Typically, electronic medical records encompass a wide range of data types, including hospitalization records, medical procedure records, and more, collectively chronicling a patient’s entire treatment history. It holds a crucial position in medical decision-making and research. Against this background, creating an intelligent named entity recognition (NER) system to identify medical entities with crucial information provides a solid foundation for constructing electronic medical record clinical knowledge bases and promoting knowledge discovery [
1].
NER constitutes the initial critical stage in the realm of natural language processing for information extraction [
2]. Compared to general-domain texts, electronic medical record texts contain more domain-specific terminologies. For the electronic medical record NER task, the entity categories to be identified include anatomical location, disease diagnosis, symptom description, etc. Our purpose is to recognize these types of entities from clinical sentences. The formalization process of NER can be defined as follows: given an annotated sequence
, we can obtain a list of triples after the recognition, where each triple contains the information of an entity [
3]. For example, in the triple
,
and
respectively refer to the start index and the end index of an entity, and
is one of the predefined entity types.
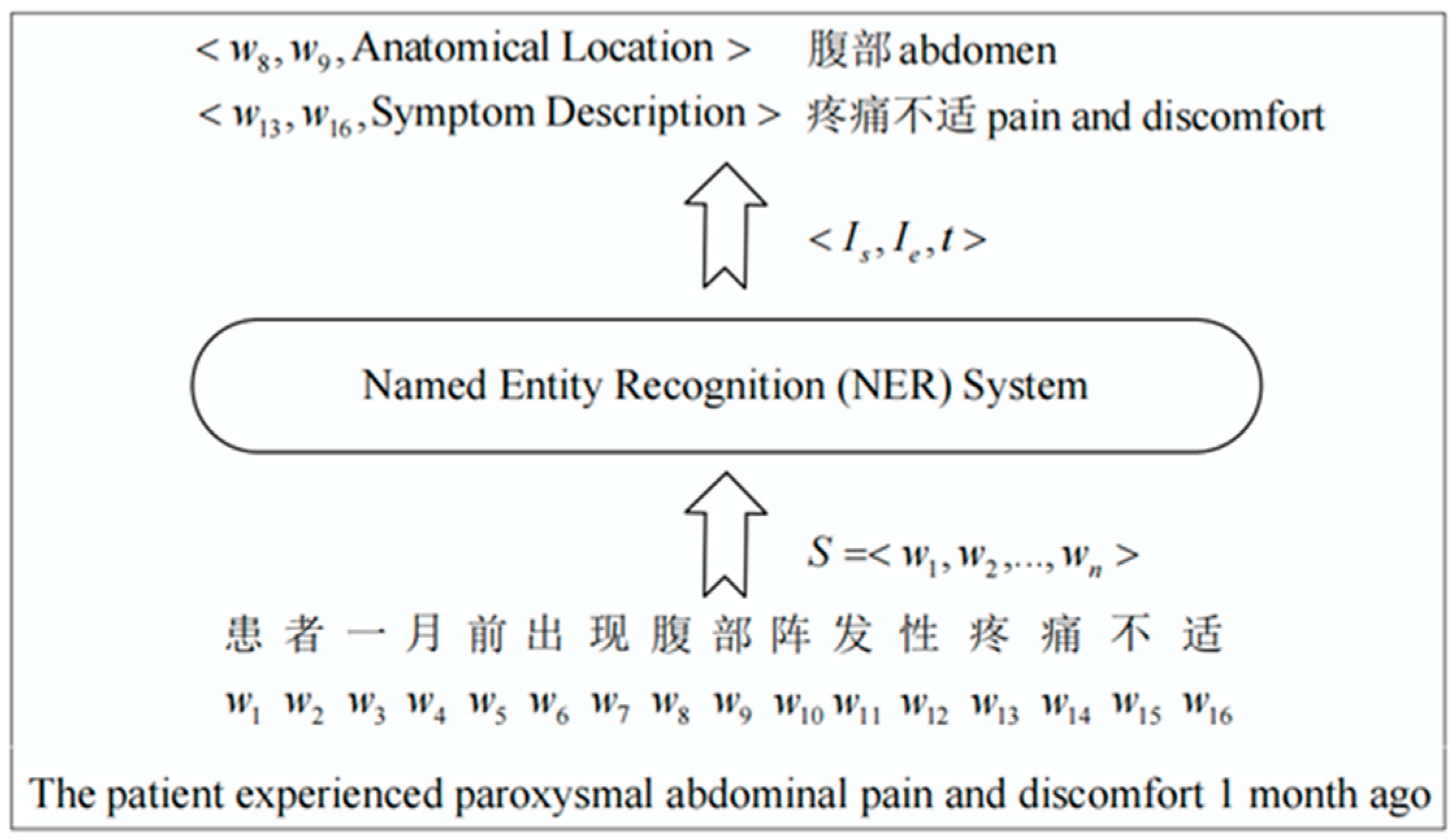
Figure 1 shows an example of the NER process. The input is a Chinese electronic medical record, “患者一月前出现腹部阵发性疼痛不适 The patient experienced paroxysmal abdominal pain and discomfort 1 month ago”, and two triples have been obtained after the NER system. The resulting triples indicate that “腹部 abdomen” is the entity of anatomical location, and “疼痛不适 pain and discomfort” is the entity of symptom description. In the NER system, people frequently overlook the fact that every component of the model is purposefully driven to generate the desired results. The automatic identification of these entities in electronic medical records plays a pivotal role in the development of medical informatics.
Most of the previous NER systems have adhered to the traditional Data–Information–Knowledge–Wisdom (DIKW) architecture [
4,
5]. Over the past few years, deep learning-based techniques for electronic medical record NER have gained immense popularity as one of the leading approaches. Researchers have endeavored to integrate the DIKW with a knowledge graph [
6,
7,
8,
9]. Meanwhile, thanks to the abundance of English-language corpora and the relatively straightforward processing, research in English NER has seen significant advancements. In the case of Chinese NER, a straightforward method involves initially conducting word segmentation and subsequently applying word-level sequence labeling models to the segmented sentences [
10]. However, the unavoidable occurrence of incorrect word segmentation can result in NER errors, which can then lead to the propagation of these errors. Numerous studies also proposed that character-based Chinese NER techniques tend to outperform their word-based counterparts [
11,
12,
13]. Nevertheless, character-based methods have their limitations as well, as they do not leverage the semantic information of words. To address this issue, Zhang et al. [
14] first proposed the Lattice-LSTM model for mixed characters and lexicon words. In contrast to conventional character-based and word-based models, this approach can attain superior performance by harnessing explicit word information instead of relying on character sequence tags. Ma et al. [
15] improved the Lattice-LSTM model and proposed a SoftLexicon method by considering more lexical information, achieving the best performance so far. Nonetheless, these methods may not prioritize the significance of the intended purpose and might not make the most of entities within Chinese electronic medical records, potentially leading to the exclusion of crucial lexical information. To address these gaps, this paper adopts the novel purpose-driven DIKW [
16], which connects the diverse models of DIKW through purpose and unifies them as a whole.
Specifically, this paper proposes a novel purpose-driven SoftLexicon-RoBERTa-BiLSTM-CRF (SLRBC) NER model for electronic medical records. SLRBC initially acquires a word-level representation with the fusion of SoftLexicon and RoBERTa, subsequently improving the recognition of long-distance entities using Bidirectional Long Short-Term Memory (BiLSTM). Finally, a Conditional Random Field (CRF) is employed for decoding. The main contributions of this paper can be summarized as follows:
We designed an SLRBC NER model for Chinese electronic medical records, fusing SoftLexicon and RoBERTa at the representation layer and adopting the classical BiLSTM-CRF framework to improve the model’s performance;
SLRBC employs a novel purpose-driven DIKW architecture. Within the SoftLexcion representation, we established four sets for each character to incorporate word lexicon information from electronic medical records into character representations and assigned weights to achieve a more comprehensive purpose representation;
We conducted extensive experiments on the CCKS2018 and CCKS2019 public datasets to verify the effectiveness of SLRBC, and the results demonstrate its superiority in Chinese electronic medical record NER. The code can be accessed at
https://github.com/QuXiaolong0812/SLRBC (accessed on 8 December 2023).
The rest of this paper is organized as follows. In
Section 2, we present an overview of the literature covering character-based, word-based, and hybrid methods.
Section 3 details our proposed approach, encompassing the representation layer, the encoding layer, and the label decoding layer.
Section 4 includes our experimental procedures and a discussion of the results.
Section 5 discusses strengths and weaknesses of the proposed approach. Finally, in
Section 6, we summarize our findings and provide insights into potential avenues for future research.
3. Proposed Method
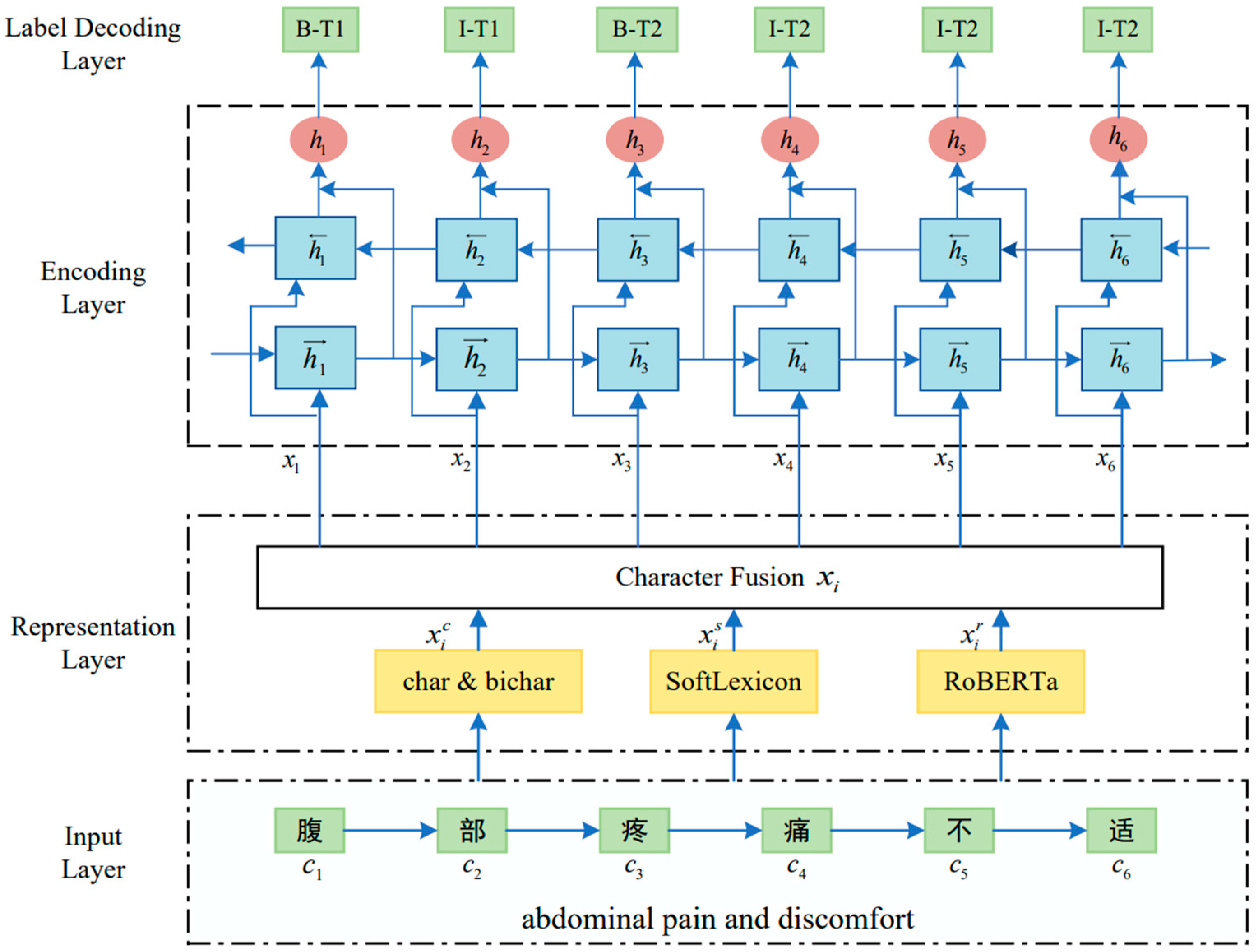
The framework of the proposed SLRBC is shown in
Figure 2, which consists of three main modules: (1) The representation layer incorporates the basic character representation, Softexicon representation, and RoBERTa representation to obtain a more comprehensive representation; (2) The encoding layer adopts the classical BiLSTM to capture contextual information and long-distance dependencies within sequences; (3) The label decoding layer uses the CRF mechanism to recognize entities. Taking the input sentence “腹部疼痛不适 abdominal pain and discomfort” as an example, character “腹 location” will be assigned the label “B-T1”, indicating that it is the beginning position (B) of the anatomical location (T1) entity. At the same time, the character “部” will be assigned the label “I-T1”, indicating that it is the inside position (I) of the anatomical location (T1) entity. As a result, the whole entity “腹部 abdomen” can be recognized. The details of each module are described below.
3.1. Representation Layer
In addition to the basic character representation, both SoftLexicon and RoBERTa to obtain a more comprehensive representation are introduced in the representation layer. SoftLexicon effectively leverages a built word frequency dictionary to integrate word lexicon information into character representations, while RoBERTa excels at capturing more comprehensive semantic information.
In this paper, each sentence is treated as , where represents the set of all characters, and represents the length of the sentence.
3.1.1. Basic Character Representation
The Lattice-LSTM model proposed by Zhang et al. [
14] has proved the effectiveness of character embedding using both character embedding (char) and double character embedding (bichar). Therefore, we adopt both char and bichar in this step, which can be calculated as Equation (1):
where
denotes the character embedding lookup table, and
denotes the double-character embedding lookup table.
3.1.2. SoftLexicon Representation
Relying solely on the basic character representation described earlier is inadequate for fully integrating entity information into the model. Because traditional character-based methods face challenges in integrating medical word lexicon information into the model without the aid of word segmentation. On the other hand, word-based models heavily rely on the precision of word segmentation outcomes and have encountered difficulties in achieving desirable performance levels. Inspired by Ma et al. [
15], we adopt the SoftLexicon approach to embed known medical entities into the model.
Individuals may perceive the same thing differently, and varying purposes can yield distinct outcomes. Similarly, as for the character
, we use the word frequency dictionary constructed in the data pre-processing stage to obtain the relevant words, and thus, construct four sets,
,
,
, and
, where
is the set including all words starting with
;
is the set including all words with
as the middle part;
is the set including all words ending with
, and
is the set of a single character
. These four sets signify four distinct purposes and encompass semantic details pertaining to various facets of entities. As shown in
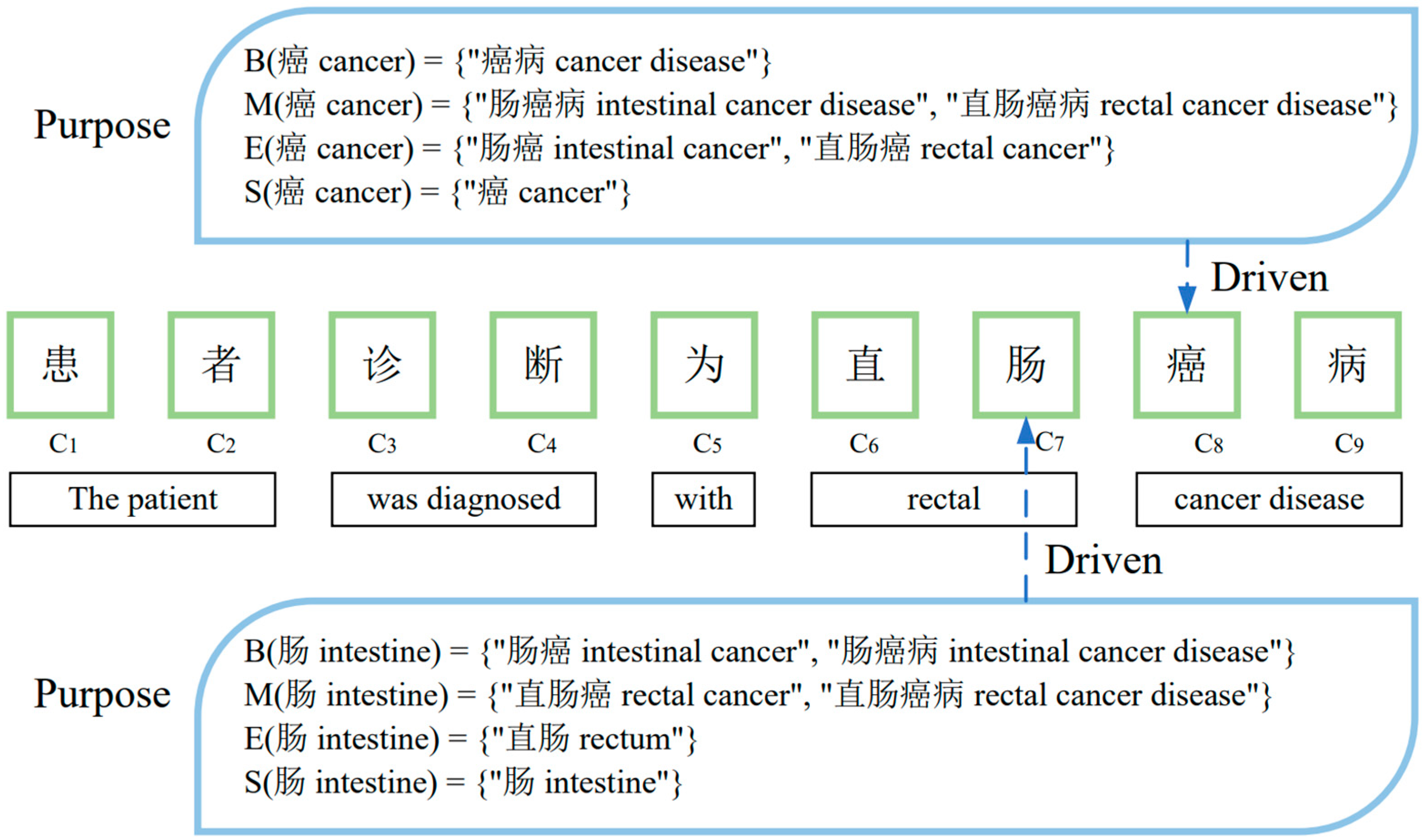
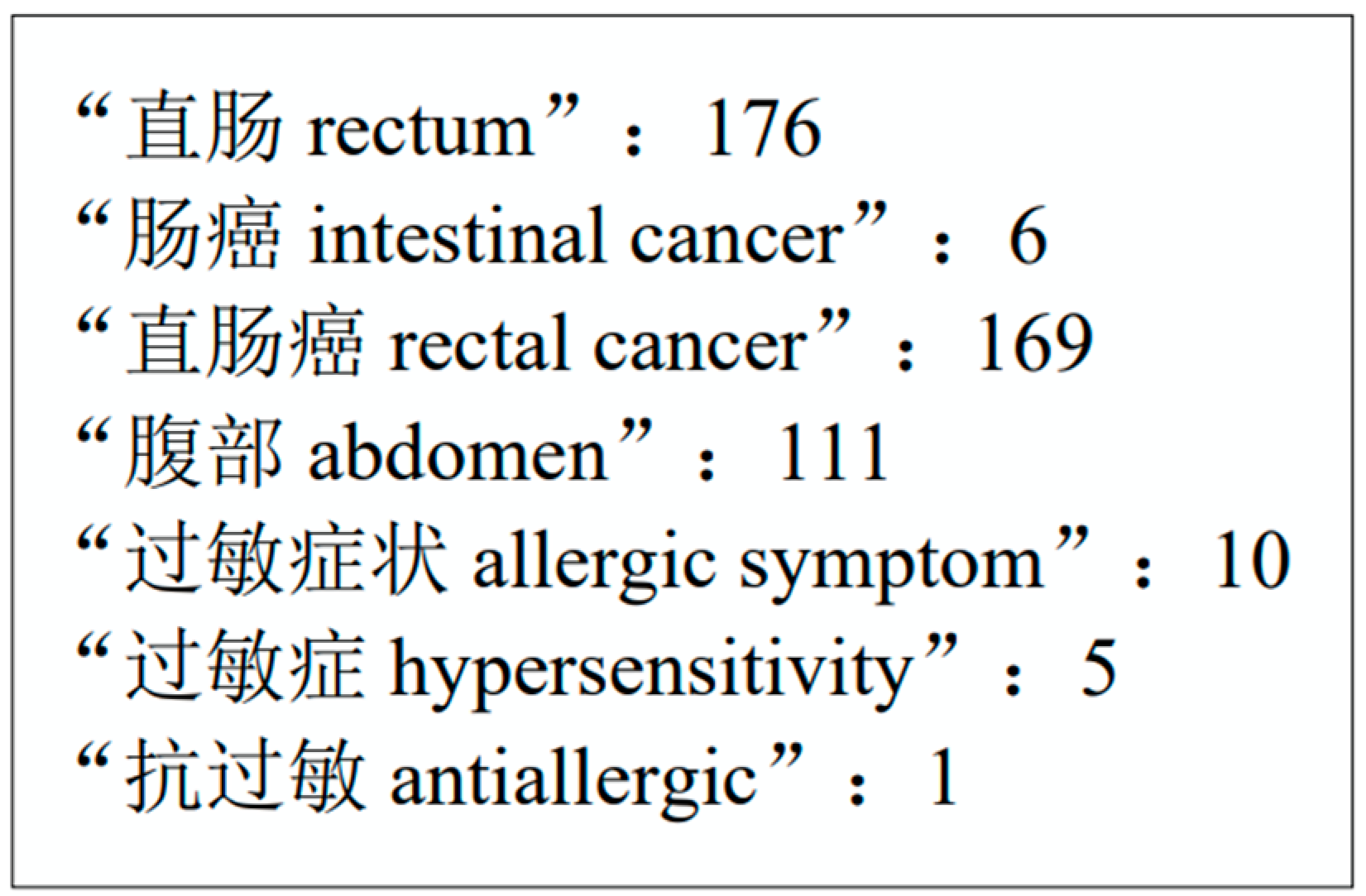
Figure 3, in the sequence of “患者诊断为直肠癌病 The patient was diagnosed with rectal cancer disease”, these four sets corresponding to the character “肠 intestine” are as follows:
= {“肠癌 intestinal cancer”, “肠癌病 intestinal cancer disease”};
= {“直肠癌 rectal cancer”, “直肠癌病 rectal cancer disease”};
= {“直肠 rectum”}; and
= {“肠 intestine”}. It is obvious that the same lexical set may contain more than one word, such as
, which indicates that there are two words beginning with “肠 intestine”. To achieve a more harmonious balance among these four purposes and facilitate their fusion, it is essential to assign weights to them based on word frequency.
As for the input sequence
, assuming that there is a vocabulary set
, the weighted average is expressed as
, which can be calculated as Equations (2) and (3):
where
is the word to be embedded;
is the word embedding lookup table;
is the frequency of
counted in the word frequency dictionary.
To retain a greater amount of information, the representations of these four lexical sets are combined through concatenation. Finally, the embedding representation of
transformed by the SoftLexicon can be calculated as Equation (4):
3.1.3. RoBERTa Representation
In order to obtain better word-level semantic representation, we also introduce RoBERTa-wwm [
35], a robust Chinese PLM. RoBERTa-wwm thoroughly addresses the necessity of word segmentation in the Chinese language and covers not only individual characters but entire words when applying masking.
Table 1 shows an example of the whole word masking mechanism of RoBERTa-wwm. In contrast to BERT, three characters, “直肠癌 rectal cancer”, in RoBERTa-wwm, are considered as a single unit, and these characters are masked together. Following the pre-training phase, the acquired semantic representation operates at the lexical level, significantly enhancing the overall representational capacity of the model beyond the character level.
With the text sequence
as input, the embedding representation with RoBERTa-wwm can be calculated as Equation (5):
where
is the vector lookup table of RoBERTa-wwm.
3.1.4. Representation Fusion
There are two prevalent methods for fusing the aforementioned embedding vectors. One approach involves performing a weighted summation operation on the vectors, while the other entails concatenating these vectors. To simplify the computation, we opt for the latter. This approach offers a degree of flexibility since it does not need to be concerned about the dimensions of each embedding vector in the representation layer. The final embedding representation of
can be calculated as Equation (6):
3.2. Encoding Layer
In the encoding layer, we utilize the conventional BiLSTM to understand the fused representation obtained from the representation layer. BiLSTM stands out as an effective variant of RNN, capable of retaining information from both preceding and subsequent neural nodes, allowing for it to capture contextual information and long-distance dependencies within sequences [
20].
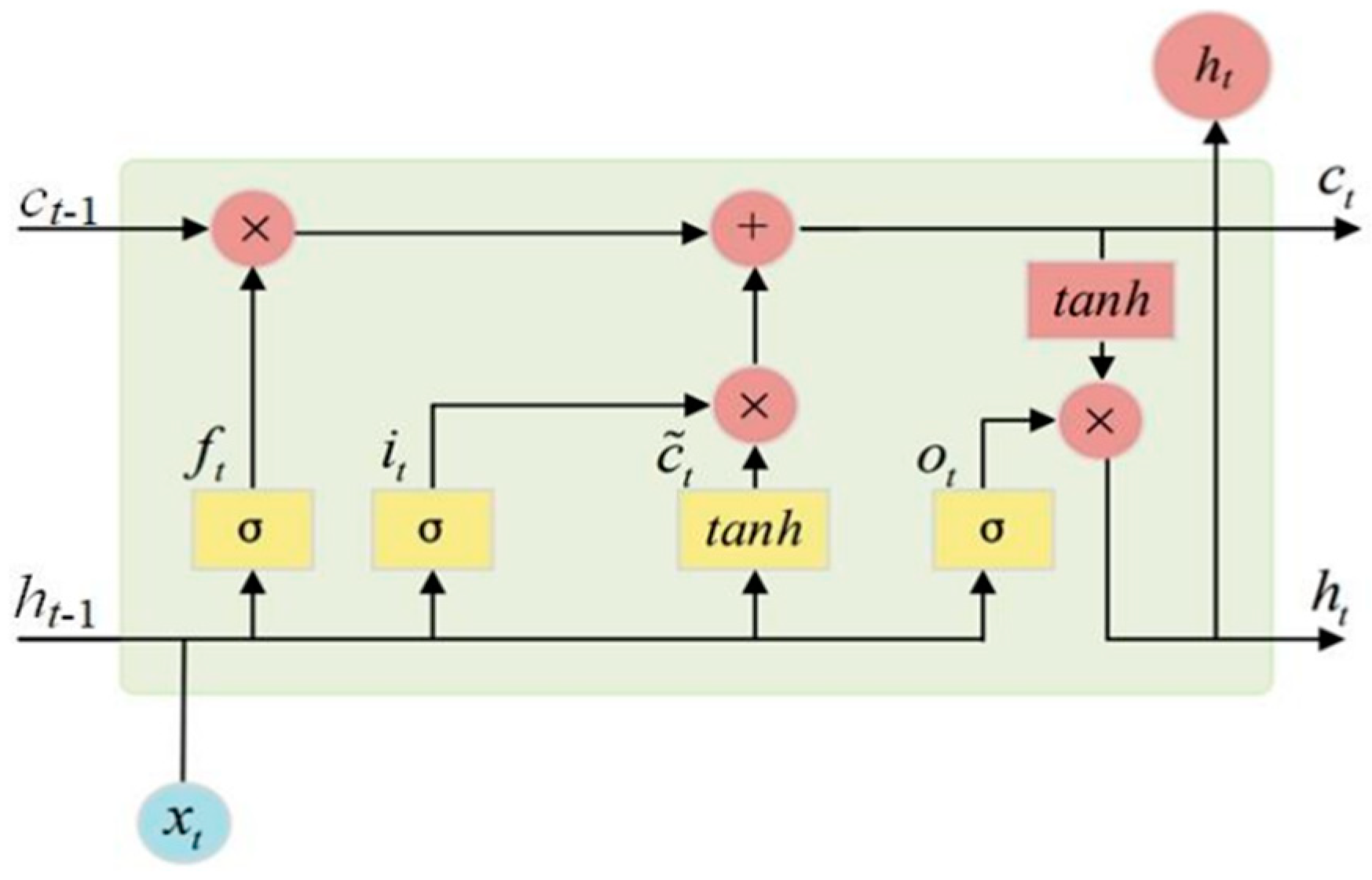
The internal structure of the LSTM cell is shown in
Figure 4. Each neural node of LSTM consists of an input gate, a forgetting gate, and an output gate. Utilizing these gate control units makes it feasible to determine whether to preserve or discard node-related information at each stage, thereby enabling the detection of long-distance dependencies. Specifically, the input gate is responsible for determining whether to retain the current node’s input information, while the forgetting gate determines whether to retain information from the previous neural node’s hidden layer. Lastly, the output gate decides whether to pass on the current node’s output to the subsequent node.
Assuming that the output of the hidden layer of the last node is
, and the input of the current node is
, the forgetting gate
, the input gate
, and the output gate
can be calculated as Equations (7)–(9):
where
is the sigmoid activation function;
,
,
,
,
, and
are trainable weights, and
,
, and
are biases.
With these calculated gates, the memory cell corresponding to the current node can be calculated as Equation (10):
where
is the activation function;
and
are trainable weights, and
is a bias.
Then, we can obtain the output of the hidden layer of the current node with the output gate
, which can be calculated as Equation (11):
The described process outlines the computation of LSTM. BiLSTM comprises both a forward LSTM and a backward LSTM, allowing for the simultaneous capture of information from both the preceding and following moments. It can be calculated as Equations (12)–(14):
where
and
denote the outputs in both directions.
3.3. Label-Decoding Layer
The NER task can be viewed as a label prediction task, and these predicted labels have associations with neighboring labels. For instance, when the current predicted label is “I-Type1”, the preceding label can only be “I-Type1” or “B-Type1”. Within the encoding layer, we solely focus on the contextual information present in the electronic medical record text and do not account for label dependencies. As a result, we introduce a CRF layer after the neural network layer to determine the globally optimal sequence of labels, thus identifying possible entities.
Assuming that there is an input sequence
and the corresponding predicted label sequence is
, the score of the predicted label sequence y corresponding to the input sequence
can be calculated by Equation (15):
where
is the transfer score matrix;
is the score of the label
transfer to the label
;
is the character label score matrix obtained from the output of the BiLSTM layer, and
is the score of the i-th character predicted as
by the BiLSTM layer.
Then, the probability distribution of the label sequence y is obtained by normalizing
with the softmax function, which can be calculated as Equation (16):
where
denotes the true label sequence, and
denotes all the predicted label sequences.
To improve loss calculation, this paper opts for maximum likelihood estimation, aiming to maximize the probability of the actual label sequences, which can be calculated as Equation (17):
Ultimately, we employ the Viterbi algorithm to identify the label sequence with the highest score, which can be calculated as Equation (18):
4. Experiments
4.1. Datasets
We assess the performance of SLRBC using the publicly available electronic medical record datasets from CCKS2018 (
https://www.sigkg.cn/ccks2018/?page_id=16 (accessed on 10 November 2023)) and CCKS2019 (
https://www.sigkg.cn/ccks2019/?page_id=62 (accessed on 10 November 2023)). The entity distribution statistics of the datasets are shown in
Table 2 and
Table 3. CCKS2018 consists of 5 entity types and comprises 3251 sentences for training, 358 for validating, and 432 for testing. CCKS2019, on the other hand, defines 6 entity types and includes 5708 sentences for training, 755 for validation, and 743 for testing.
The datasets are labeled with the BIO annotation method, in which the first character constituting the entity is labeled as “B-Type”; the rest characters constituting the entity are labeled as “I-Type”, and the other non-entity characters are labeled as “O”. As a result, there are 11 different labels in CCKS2018 and 13 in CCKS2019.
Since the word frequency dictionary needs to be constructed in the representation layer of SLRBC, we extract words from the datasets and count the frequency of each word. In this regard, the CCKS2018 word frequency dictionary encompasses 7619 words, while the CCKS2019 word frequency dictionary comprises 10,566 words. Exemplary words and their respective frequencies from the word frequency dictionary are depicted in
Figure 5.
4.2. Experimental Setup
SLRBC is implemented on a single RTX 2080 Ti GPU with PyTorch version 1.10.0. We carry out an extensive array of experiments and record the parameter values at which the model achieves its optimal performance. The network weights are optimized by the Adam algorithm, and other details of the parameters are specified in
Table 4.
In our experiments, we use standard Precision (P), Recall (R), and F1-score (F1) to evaluate the model performance:
where TP represents the number of entities correctly identified by the model; FP represents the number of entities identified by the model as unrelated, and FN represents the number of correct entities not identified by the model.
4.3. Baselines
To verify the effectiveness of SLRBC, we conduct comparison experiments on the electronic medical record datasets of CCKS2018 and CCKS2019 with the following models: the first three are character-based methods, while the remaining two are hybrid methods. Note that there are few existing Chinese word-based methods, and they do not perform as well as the other two types of methods, so we do not consider this type of method.
CNN-CRF [
19] uses a CNN-based character embedding layer and employs CRF to decode;
BiLSTM-CRF [
20] uses a BiLSTM-based character embedding layer and employs CRF to decode;
BERT-BiLSTM-CRF [
22] is an improvement in the BiLSTM-CRF model, which introduces BERT on the top of the encoder;
SoftLexicon-BiLSTM-CRF [
15] combines character-level and word-level representations and adopts the classical BiLSTM-CRF framework;
SoftLexicon-BERT [
15] combines SoftLexicon and BERT to achieve better representations.
4.4. Main Results
In this section, we compare and analyze the performance of SLRBC with other baseline models. The experimental results are shown in
Table 5. It is noticeable that when compared to these baseline models, SLRBC has enhanced the F1 score on the CCKS2018 dataset by 7.81%, 9.71%, 0.8%, 1.62%, and 0.78%, respectively, and on the CCKS2019 dataset by 16.93%, 2%, 1.43%, 2.36%, and 1.32%, respectively.
Through horizontal comparison, we observe that the performance of all models is superior on CCKS2018 compared to CCKS2019. This discrepancy is evidently due to variations in the granularity of entity annotation between the two datasets. The clearer the annotation of training data, the better the performance of the model. Among these models, the CNN-CRF model displays the most prominent performance variation between the two datasets. Its performance on CCKS2019 notably lags behind that of the other models. This discrepancy arises from the fact that the named entities in CCKS2019 are longer, and the CNN model struggles to capture long-distance dependencies effectively. It is evident that our SLRBC can effectively address this issue.
Through vertical comparison, we observe a significant improvement in model performance after incorporating SoftLexicon compared to the traditional CNN and BiLSTM model structures. This result further validates the positive impact of the purpose-driven approach on enhancing NER accuracy. Simultaneously, it is evident that the F1 scores for BERT-BiLSTM-CRF and SoftLexicon-BERT with PLM, as well as our SLRBC, are notably superior to those without PLM. It proves the effectiveness of introducing large PLMs. The remarkable performance of SLRBC underscores the effectiveness of the model structure we proposed, which integrates SoftLexicon and RoBERTa in the realm of Chinese electronic medical record NER.
In addition, we conduct a comparison of the training speed and testing speed of each model, as shown in
Table 6. It can be found that the model without BERT or RoBERTa, including CNN-CRF, BiLSTM-CRF, and SoftLexicon-BiLSTM-CRF, has faster processing speed, primarily due to the simpler model structures and fewer parameters. However, SLRBC operates at a slower pace, indicating that RoBERTa, with its increased parameter count, contributes to the slower processing speed compared to BERT. Meanwhile, the output vector dimension of BERT is 768, while the output vector dimension of RoBERTa is 1024, which further increases the overall computational load of the model.
4.5. Ablation Study
4.5.1. Analysis of Different Representation Layers
To further investigate the impact of four modules in representation layers on model performance, we conduct ablation experiments. Acknowledging character embedding (char) as the most basic representation, we make the deliberate decision to retain it consistently in each experiment. Subsequently, we progressively eliminate either one or both bichars, SoftLexicon, and RoBERTa.
Table 7 shows the specific experimental results.
In the representation layer of our SLRBC, char, bichar, SoftLexicon, and RoBERT are used simultaneously to achieve the best results on both datasets, once again verifying the validity of SLRBC. The removal of SoftLexicon or RoBERTa results in a significant decrease in F1 compared to SLRBC. F1 reaches its lowest point when both are removed simultaneously, providing conclusive evidence that these two modules play a crucial role in the representation layer of SLRBC. However, when bichar is removed, F1 does not decrease significantly compared with SLRBC. This is due to the fact that bichar, serving as an adjunct to char, makes a relatively smaller contribution to the representation. Experiments conducted on the two datasets reveal that the F1 for CCKS2018 exhibited less fluctuation compared to that of CCKS2019. This result indicates that when the entity annotation of training data is clearer, the change in the representation layer has less influence on the final recognition performance.
4.5.2. Analysis of Different Neural Networks
In the SLRBC proposed in this paper, BiLSTM is selected as the encoding layer. In order to explore the influence of different neural networks on the overall model and subsequently optimize the neural network layer, we replace the BiLSTM with CNN and Transformer in ablation experiments. The experimental results are shown in
Table 8, which indicates that the model performs best when using BiLSTM in the encoding layer. When employing CNN and Transformer, there is a discernible disparity in F1 on both datasets compared to BiLSTM. It can be inferred that the constrained receptive field of CNN hinders its ability to capture long-distance dependencies, and the ability of Transformer to capture such dependencies is also marginally inferior to that of BiLSTM. Therefore, we choose to use BiLSTM in the encoding layer, resulting in the best overall model performance.
4.5.3. Analysis of Different Hidden Layer Dimensions
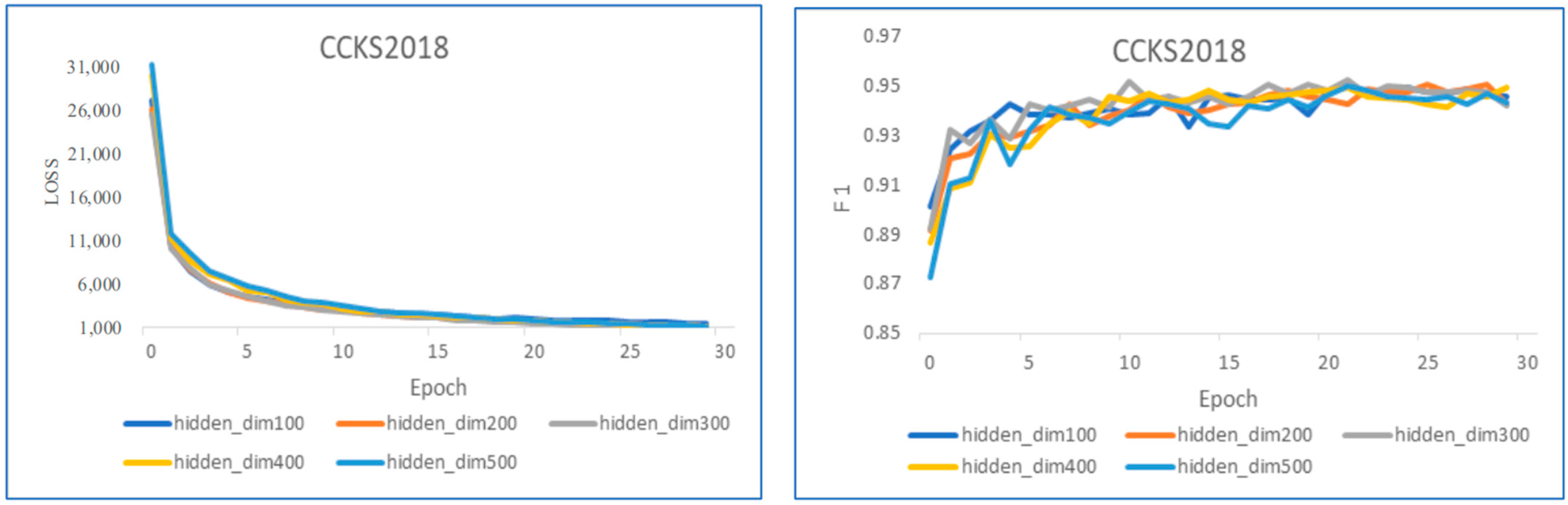
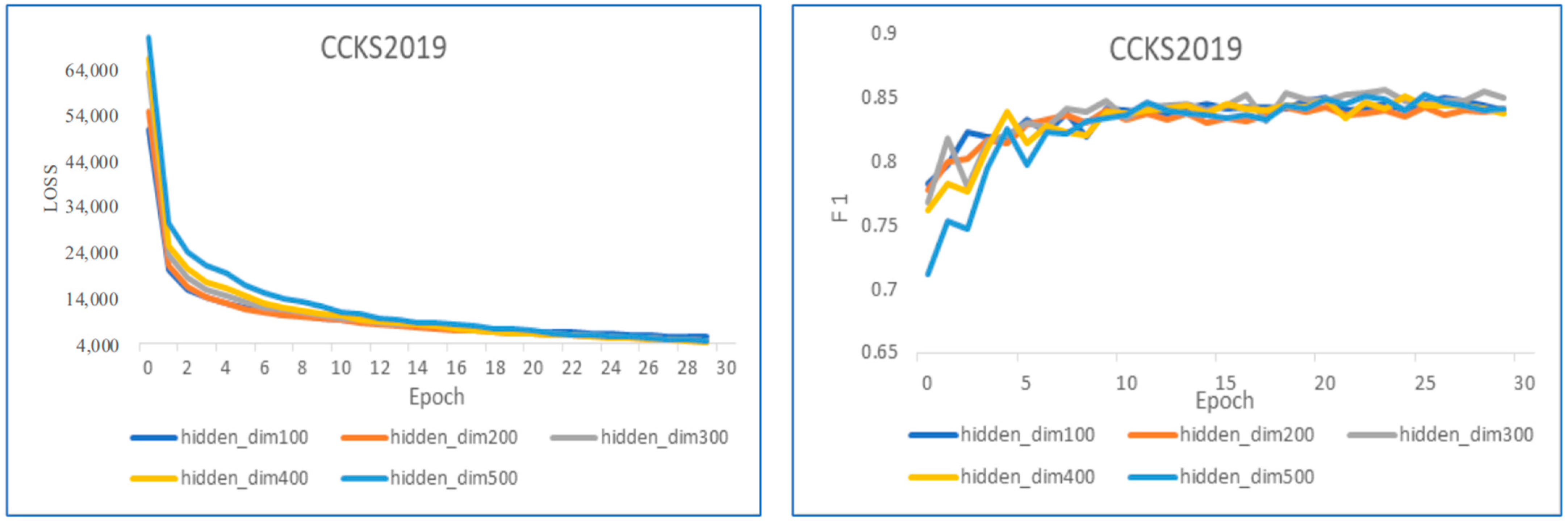
We set the hidden layer dimensions as 100, 200, 300, 400, and 500 to investigate its impact on model performance. At the same time, we compare the total loss and F1 of the model under different hidden layer dimensions on CCKS2018 and CCKS2019, which can be seen in
Figure 6 and
Figure 7. With a training epoch count below 10, the total loss experiences the most rapid decline, and F1 shows the most noticeable increase. Beyond 20 training epochs, both the total loss and F1 begin to gradually stabilize. Consequently, we opt to set the epoch to 30. In general, the dimension of the hidden layer exhibits no discernible impact on F1. Setting the hidden layer dimension to 100 results in the fastest convergence, and the speed diminishes with an increase in the hidden layer dimension. When the hidden layer dimension is set to 300, SLRBC demonstrates relatively excellent overall performance, reaching the peak of F1. Therefore, we set the dimension of the hidden layer to 300 in this paper.
5. Discussion
Our experimental results demonstrate that the proposed SLRBC can provide more accurate recognition performance by using a purpose-driven approach with the fusion of SoftLexicon and RoBERTa. We compare SLRBC with five baseline models: CNN-CRF [
19]; BiLSTM-CRF [
20]; BERT-BiLSTM-CRF [
22]; SoftLexicon-BiLSTM-CRF [
15]; and SoftLexicon-BERT [
15]. By comparing CNN-CRF, BiLSTM-CRF, and BERT-BiLSTM-CRF, we prove the importance of lexical information in Chinese electronic medical record NER. Then, we compare SLRBC with SoftLexicon-BiLSTM-CRF and SoftLexicon-BERT, which belong to hybrid methods. The latter two only consider one or both representations, while our SLRBC considers basic character representation, SoftLexicon representation, and RoBERTa representation at the same time, thus achieving a more comprehensive representation. Moreover, the classical BiLSTM-CRF framework is adopted in our SLRBC, which helps to capture contextual information of entities more effectively.
However, we also notice that SLRBC operates at a slower pace compared with other baseline models. This may be attributed to the fusion method adopted by the representation layer. In SLRBC, we use the simple concatenate method to fuse different representations. This approach preserves as much of the original information as possible but increases the dimensions of representation features. Although it is helpful to improve the performance of entity recognition, it also significantly increases the time and space cost. Therefore, different fusion methods can be explored to further improve SLRBC.
6. Conclusions
In this paper, we propose a novel purpose-driven model called SLRBC for the Chinese electronic medical record NER model, namely, SLRBC, which uses the fusion of SoftLexicon and RoBERTa within the representation layer. Compared to existing character-based, word-based, and hybrid methods, SLRBC fuses SoftLexicon and RoBERTa, constructing four sets with different purposes to achieve a more comprehensive purpose representation. Such a purpose-driven approach helps to incorporate the word lexicon information from electronic medical records into the character representations, thereby endowing the model with more extensive semantic embedding representations. Simultaneously, SLRBC introduces the classical BiLSTM-CRF framework to enhance the model’s ability in medical entity recognition. We conducted several comparative experiments on two public NER datasets. The experimental results show that each module plays an indispensable role in our proposed SLRBC. Specifically, the F1 of SLRBC increases by 0.78% to 9.71% on CCKS2018 and 1.32% to 16.93% on CCKS2019, which validates the effectiveness of the model and lays the foundation for clinical knowledge discovery in electronic medical records.
Although SLRBC has achieved advanced performance in experiments, there are still challenges and space for improvement. In the future, faced with increasingly complex medical knowledge, we will delve deeper into integrating more domain knowledge and merging the latest prompt learning paradigm to further elevate the model’s performance and its practical value in clinical applications.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}