
Few-Shot Image Classification via Mutual Distillation



Abstract
:1. Introduction
- (1)
- We use response-based knowledge distillation to regularize metric-based meta-learning methods. As far as we know, we are the pioneering contributors to the integration of mutual distillation within the metric-based meta-learning framework for few-shot learning;
- (2)
- We implement mutual distillation between two distinct and well-established models with varying parameters, such as prototypical networks and relational networks. This mutual learning approach, implemented through distillation, effectively enhances the model’s generalization under few-shot conditions;
- (3)
- Our approach achieves a state-of-the-art performance across two benchmarks in few-shot learning research, underscoring that each metric-based model can obtain an excellent performance when supported by mutual distillation.
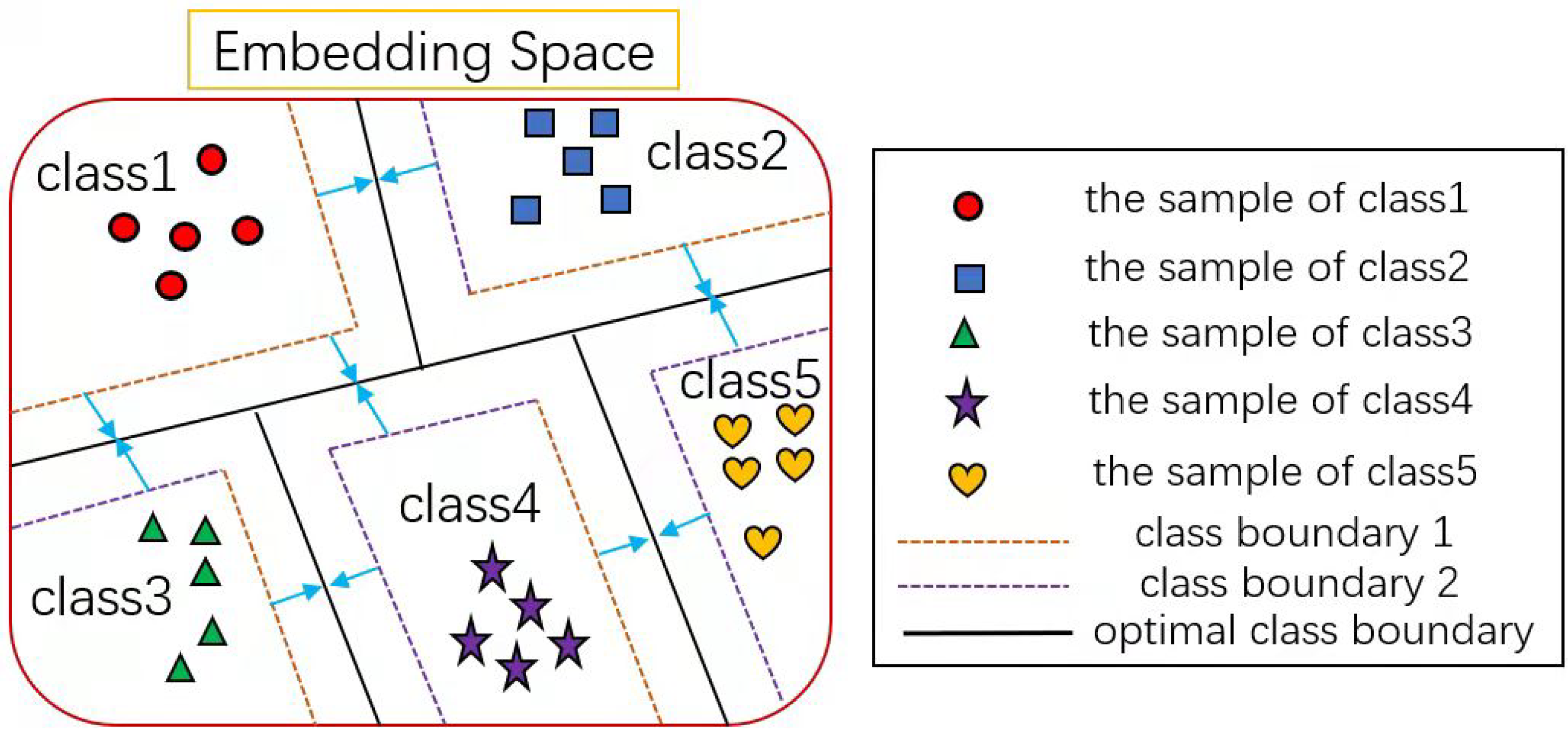
2. Related Work
3. Our Method
3.1. Problem Definition
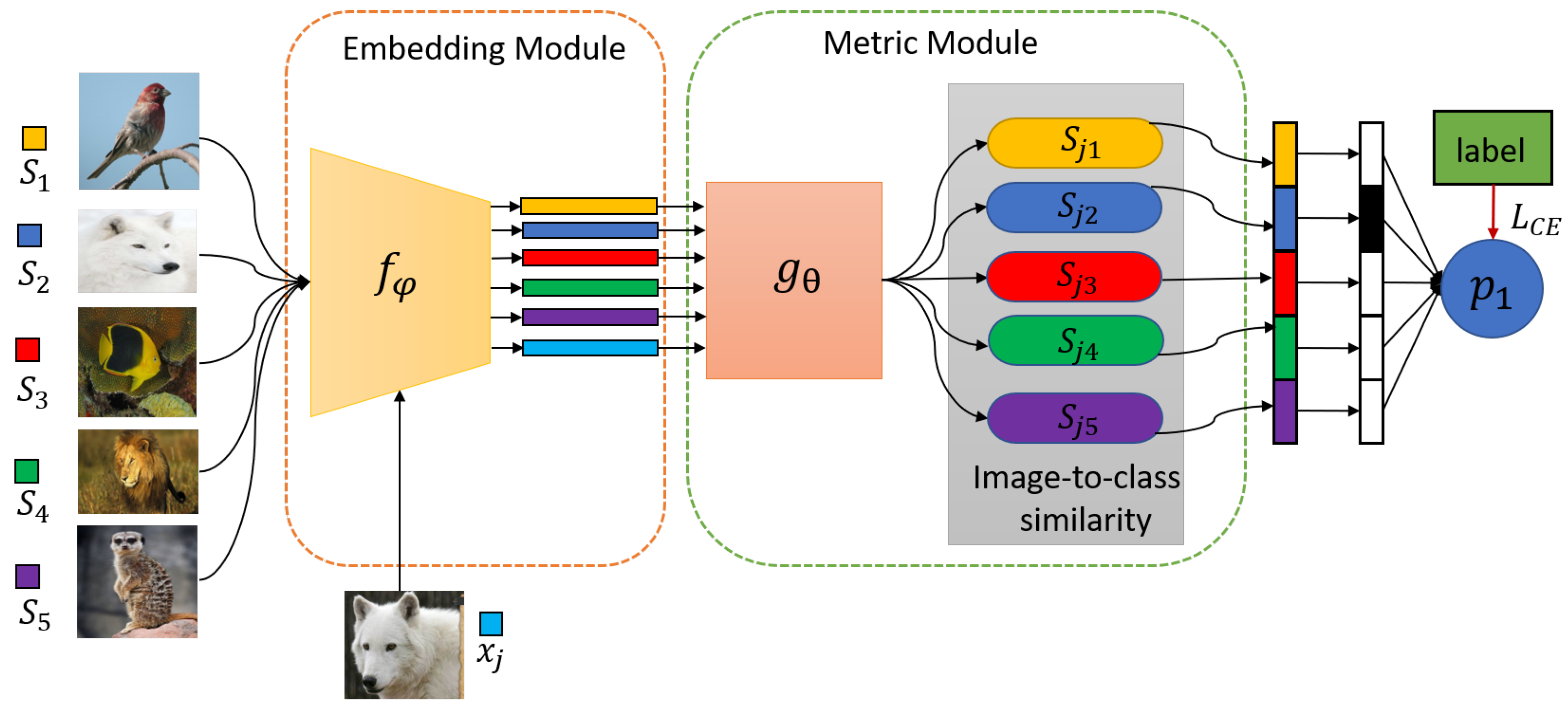
3.2. Preliminary: Metric-Based Meta-Learning
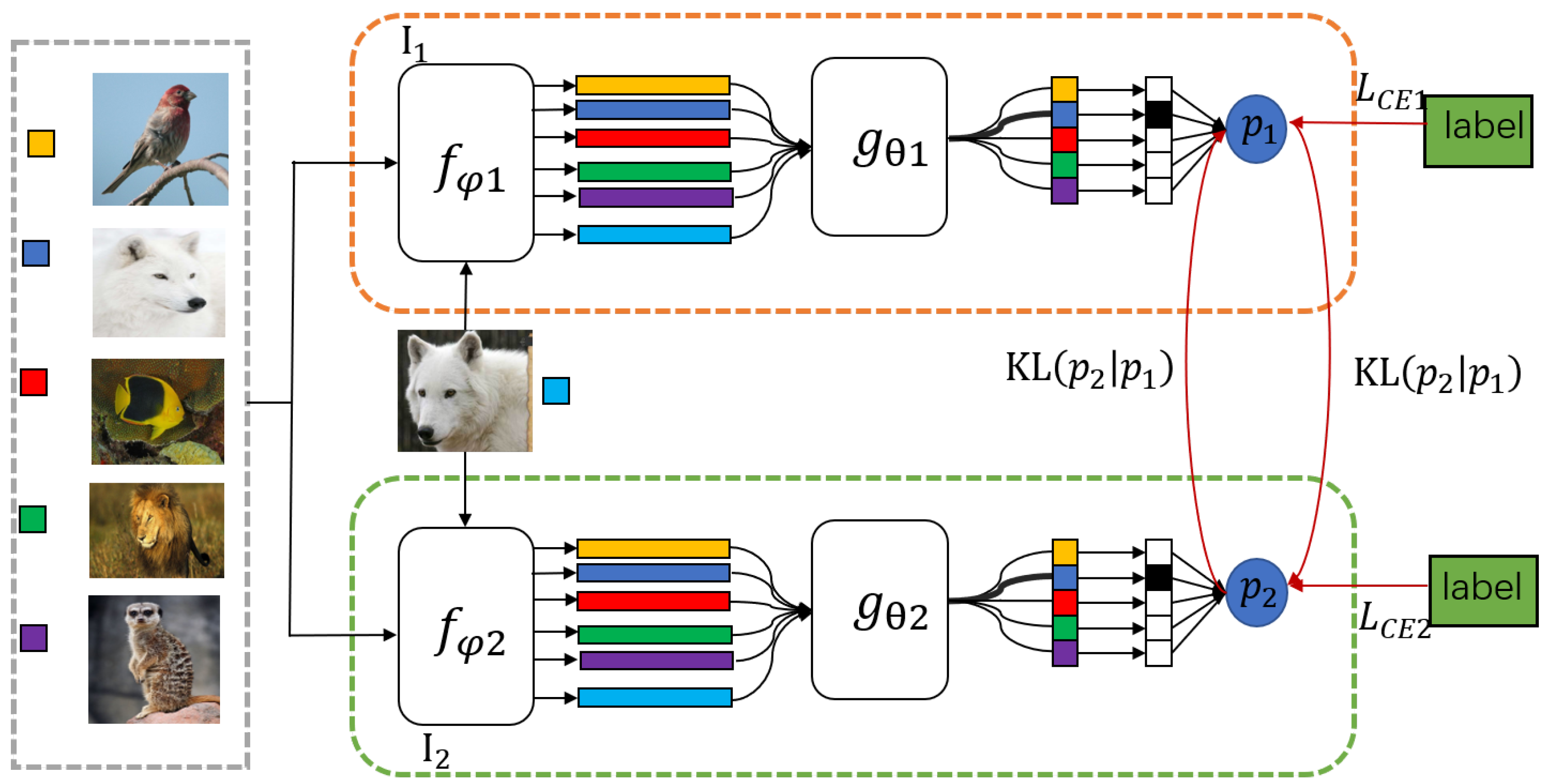
3.3. Mutual Distillation of Metric-Based Meta-Learning
3.4. Few-Shot Evaluation
| Algorithm 1: Mutual Distillation of Metric-based Meta-learning. |
 |
4. Experiements
4.1. Dataset Description
4.2. Implementation Details
4.3. Ablation Study
4.4. T-SNE Visualization of Features
4.5. Comparison with Other Methods
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, X.; Yu, L.; Fu, C.W.; Fang, M.; Heng, P.A. Revisiting metric learning for few-shot image classification. Neurocomputing 2020, 406, 49–58. [Google Scholar] [CrossRef]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. One-shot learning with memory-augmented neural networks. arXiv 2016, arXiv:1605.06065. [Google Scholar]
- Munkhdalai, T.; Yu, H. Meta networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2554–2563. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Wang, Z.; Zhao, Y.; Li, J.; Tian, Y. Cooperative Bi-path Metric for Few-shot Learning. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1524–1532. [Google Scholar]
- Li, A.; Huang, W.; Lan, X.; Feng, J.; Li, Z.; Wang, L. Boosting few-shot learning with adaptive margin loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12576–12584. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding task-relevant features for few-shot learning by category traversal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar]
- Wang, X.; Yu, F.; Wang, R.; Darrell, T.; Gonzalez, J.E. Tafe-net: Task-aware feature embeddings for low shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1831–1840. [Google Scholar]
- Ye, H.J.; Hu, H.; Zhan, D.C.; Sha, F. Learning embedding adaptation for few-shot learning. arXiv 2019, arXiv:1812.03664. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Ding, Q.; Wu, S.; Sun, H.; Guo, J.; Xia, S.T. Adaptive regularization of labels. arXiv 2019, arXiv:1908.05474. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Y.; Guo, L.; Jia, K. PARN: Position-aware relation networks for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6659–6667. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. arXiv 2019, arXiv:1910.07677. [Google Scholar]
- Simon, C.; Koniusz, P.; Nock, R.; Harandi, M. Adaptive subspaces for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4136–4145. [Google Scholar]
- Wu, F.; Smith, J.S.; Lu, W.; Pang, C.; Zhang, B. Attentive prototype few-shot learning with capsule network-based embedding. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 237–253. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 7260–7268. [Google Scholar]
- Bateni, P.; Goyal, R.; Masrani, V.; Wood, F.; Sigal, L. Improved few-shot visual classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14493–14502. [Google Scholar]
- Nguyen, V.N.; Løkse, S.; Wickstrøm, K.; Kampffmeyer, M.; Roverso, D.; Jenssen, R. SEN: A Novel Feature Normalization Dissimilarity Measure for Prototypical Few-Shot Learning Networks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 118–134. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover’s Distance and Structured Classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12203–12213. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A simple neural attentive meta-learner. arXiv 2017, arXiv:1707.03141. [Google Scholar]
- Hilliard, N.; Phillips, L.; Howland, S.; Yankov, A.; Corley, C.D.; Hodas, N.O. Few-shot learning with metric-agnostic conditional embeddings. arXiv 2018, arXiv:1802.04376. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Franceschi, L.; Frasconi, P.; Salzo, S.; Grazzi, R.; Pontil, M. Bilevel programming for hyperparameter optimization and meta-learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1568–1577. [Google Scholar]
- Munkhdalai, T.; Yuan, X.; Mehri, S.; Trischler, A. Rapid adaptation with conditionally shifted neurons. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3664–3673. [Google Scholar]
- Grant, E.; Finn, C.; Levine, S.; Darrell, T.; Griffiths, T. Recasting gradient-based meta-learning as hierarchical bayes. arXiv 2018, arXiv:1801.08930. [Google Scholar]
- Patacchiola, M.; Turner, J.; Crowley, E.J.; O’Boyle, M.; Storkey, A. Bayesian meta-learning for the few-shot setting via deep kernels. Adv. Neural Inf. Process. Syst. 2020, 33, 16108–16118. [Google Scholar]
- Oh, J.; Yoo, H.; Kim, C.; Yun, S.Y. Boil: Towards representation change for few-shot learning. arXiv 2020, arXiv:2008.08882. [Google Scholar]
- Snell, J.; Zemel, R. Bayesian Few-Shot Classification with One-vs-Each Pólya-Gamma Augmented Gaussian Processes. arXiv 2020, arXiv:2007.10417. [Google Scholar]
- Prol, H.; Dumoulin, V.; Herranz, L. Cross-modulation networks for few-shot learning. arXiv 2018, arXiv:1812.00273. [Google Scholar]
- Zhang, H.; Zhang, J.; Koniusz, P. Few-shot learning via saliency-guided hallucination of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 2770–2779. [Google Scholar]
- Hui, B.; Zhu, P.; Hu, Q.; Wang, Q. Self-attention relation network for few-shot learning. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 198–203. [Google Scholar]
- Hao, F.; He, F.; Cheng, J.; Wang, L.; Cao, J.; Tao, D. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8460–8469. [Google Scholar]
- Song, H.; Torres, M.T.; Özcan, E.; Triguero, I. L2AE-D: Learning to aggregate embeddings for few-shot learning with meta-level dropout. Neurocomputing 2021, 442, 200–208. [Google Scholar] [CrossRef]
- Li, W.; Xu, J.; Huo, J.; Wang, L.; Gao, Y.; Luo, J. Distribution consistency based covariance metric networks for few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8642–8649. [Google Scholar]
- Tang, S.; Chen, D.; Bai, L.; Liu, K.; Ge, Y.; Ouyang, W. Mutual CRF-GNN for Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2329–2339. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Fu, Y. Adversarial feature hallucination networks for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13470–13479. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, San Juan, DC, USA, 2–4 May 2016. [Google Scholar]
- Zhang, H.; Torr, P.H.; Koniusz, P. Few-shot Learning with Multi-scale Self-supervision. arXiv 2020, arXiv:2001.01600. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | 5-Way Accuracy (%) | |||
|---|---|---|---|---|---|
| MiniImageNet | CUB | ||||
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | ||
| RN | ResNet12 | 54.68 ± 0.29 | 71.61 ± 0.24 | 72.69 ± 0.49 | 86.98 ± 0.28 |
| PN | ResNet12 | 55.39 ± 0.29 | 75.27 ± 0.2 | 76.41 ± 0.49 | 89.40 ± 0.24 |
| MDMM-RN | ResNet12 | 54.93 ± 0.30 | 73.58 ± 0.23 | 74.19 ± 0.50 | 91.03 ± 0.22 |
| MDMM-PN | ResNet12 | 57.73 ± 0.30 | 75.32 ± 0.22 | 75.36 ± 0.50 | 89.00 ± 0.27 |
| Method | Backbone | 5-Way Accuracy (%) | |||
|---|---|---|---|---|---|
| MiniImageNet | CUB | ||||
| - | - | 1-Shot | 5-Shot | 1-Shot | 5-Shot |
| RN | ResNet12 | 56.68 ± 0.29 | 71.61 ± 0.24 | 72.69 ± 0.49 | 86.98 ± 0.28 |
| PN | ResNet12 | 55.39 ± 0.29 | 75.27 ± 0.23 | 76.41 ± 0.49 | 89.40 ± 0.24 |
| MDMM-RN&RN | ResNet12 | 58.09 ± 0.30 | 72.99 ± 0.23 | 74.64 ± 0.50 | 87.49 ± 0.27 |
| MDMM-PN&PN | ResNet12 | 56.93 ± 0.30 | 77.33 ± 0.22 | 76.50 ± 0.48 | 91.29 ± 0.22 |
| Method | Backbone | Type | Reference | 5-Way Accuracy (%) | |
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | ||||
| Meta network [5] | Conv | Model | ICML’17 | 49.21 ± 0.96 | - |
| SNAIL [30] | ResNet | Model | ICLR’18 | 55.71 ± 0.99 | 68.88 ± 0.92 |
| MAML [6] | Conv4 | Optimization | ICML’17 | 48.70 ± 1.75 | 63.11 ± 0.92 |
| Meta-SGD [32] | Conv4 | Optimization | Arxiv’17 | 50.47 ± 1.87 | 64.03 ± 0.94 |
| Reptile [33] | Conv4 | Optimization | Arxiv’18 | 49.97 ± 0.32 | 65.99 ± 0.58 |
| Bilevel Programming [34] | ResNet12 | Optimization | ICML’18 | 50.54 ± 0.85 | 64.53 ± 0.68 |
| adaResNet [35] | ResNet12 | Optimization | ICML’18 | 56.88 ± 0.62 | 71.94 ± 0.57 |
| LLAMA [36] | Conv4 | Optimization | ICLR’18 | 49.40 ± 1.83 | - |
| DKT [37] | Conv4 | Optimization | NIPS’20 | 49.73 ± 0.07 | - |
| BOIL [38] | Conv4 | Optimization | ICLR’21 | 49.61 ± 0.16 | 66.45 ± 0.37 |
| OVE PG GP + Cosine (ML) [39] | Conv4 | Optimization | ICLR’21 | 50.02 ± 0.35 | 64.58 ± 0.31 |
| Matching Network [10] | Conv4 | Metric | NIPS’16 | 46.6 | 60.0 |
| Prototypical Network [11] † | ResNet12 | Metric | NIPS’17 | 55.39 ± 0.29 | 75.27 ± 0.23 |
| Relation Network [12] † | ResNet12 | Metric | CVPR’18 | 56.68 ± 0.29 | 71.61 ± 0.24 |
| Cross Module [40] | Conv4 | Metric | NIPS’18 | 50.94 ± 0.61 | 66.65 ± 0.67 |
| PARN [20] | Conv4 | Metric | ICCV’19 | 55.22 ± 0.84 | 71.55 ± 0.66 |
| DN4 [24] | Conv4 | Metric | CVPR’19 | 51.24 ± 0.74 | 71.02 ± 0.64 |
| SalNet [41] | Conv4 | Metric | CVPR’19 | 57.45 ± 0.80 | 72.01 ± 0.75 |
| TPN [16] | ResNet8 | Metric | ICLR’19 | 55.51 ± 0.86 | 69.86 ± 0.65 |
| SARN [42] | Conv | Metric | ICMEW’19 | 51.62 ± 0.31 | 66.16 ± 0.51 |
| SAML [43] | Conv | Metric | ICCV’19 | 57.69 ± 0.20 | 73.03 ± 0.16 |
| L2AE-D [44] | Conv4 | Metric | Arxiv’19 | 54.26 ± 0.87 | 70.76 ± 0.67 |
| CovaMNet [45] | Conv4 | Metric | AAAI’19 | 51.19 ± 0.76 | 67.65 ± 0.63 |
| MCGN [46] | 64-96-128-256 | Metric | CVPR’21 | 57.89 ± 0.87 | 73.58 ± 0.87 |
| Our Method | ResNet12 | Metric | - | 58.09 ± 0.30 | 77.33 ± 0.22 |
| Method | Backbone | Type | Reference | 5-Way Accuracy (%) | |
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | ||||
| MAML [6] * | Conv4 | Optimization | ICML’17 | 38.43 | 59.15 |
| Meta-SGD [32] * | Conv4 | Optimization | Arxiv’17 | 66.9 | 77.10 |
| MACO [31] * | Conv4 | Optimization | Arxiv’18 | 60.76 | 74.96 |
| Meta-LSTM [48] * | Conv4 | Optimization | ICLR’17 | 40.43 | 49.65 |
| DKT [37] | Conv4 | Optimization | ICLR’20 | 63.37 ± 0.19 | - |
| OVE PG GP + Cosine (ML) [39] | Conv4 | Optimization | NIPS’20 | 63.98 ± 0.43 | 77.44 ± 0.18 |
| Matching Network [10] * | Conv4 | Metric | NIPS’16 | 49.34 | 59.31 |
| Prototypical Network [11] † | ResNet12 | Metric | NIPS’17 | 76.41 ± 0.4 | 89.40 ± 0.24 |
| Relation Network [12] † | ResNet12 | Metric | CVPR’18 | 72.69 ± 0.49 | 86.98 ± 0.28 |
| DN4 [24] | Conv4 | Metric | CVPR’19 | 53.15 ± 0.84 | 81.90 ± 0.60 |
| DeepEMD [27] | ResNet12 | Metric | CVPR’20 | 75.65 ± 0.83 | 88.69 ± 0.50 |
| SAML [43] | Conv | Metric | ICCV’19 | 69.33 ± 0.22 | 81.56 ± 0.15 |
| CovaMNet [45] | Conv4 | Metric | AAAI’19 | 52.42 ± 0.76 | 63.76 ± 0.64 |
| MsSoSN [49] | Conv4 | Metric | Arxiv’20 | 52.82 | 68.37 |
| K-tuplet [3] | Conv4 | Metric | Neurocomputing’20 | 40.16 ± 0.68 | 56.96 ± 0.65 |
| AFHN [47] | Restnet12 | Metric | CVPR’20 | 70.53 ± 1.01 | 83.95 ± 0.63 |
| Our Method | ResNet12 | Metric | - | 76.50 ± 0.48 | 91.29 ± 0.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Dai, W.; Chen, Z.; Yang, S.; Liu, F.; Zheng, H. Few-Shot Image Classification via Mutual Distillation. Appl. Sci. 2023, 13, 13284. https://doi.org/10.3390/app132413284
Zhang T, Dai W, Chen Z, Yang S, Liu F, Zheng H. Few-Shot Image Classification via Mutual Distillation. Applied Sciences. 2023; 13(24):13284. https://doi.org/10.3390/app132413284
Chicago/Turabian StyleZhang, Tianshu, Wenwen Dai, Zhiyu Chen, Sai Yang, Fan Liu, and Hao Zheng. 2023. "Few-Shot Image Classification via Mutual Distillation" Applied Sciences 13, no. 24: 13284. https://doi.org/10.3390/app132413284
APA StyleZhang, T., Dai, W., Chen, Z., Yang, S., Liu, F., & Zheng, H. (2023). Few-Shot Image Classification via Mutual Distillation. Applied Sciences, 13(24), 13284. https://doi.org/10.3390/app132413284