
FiMa-Reader: A Cost-Effective Fiducial Marker Reader System for Autonomous Mobile Robot Docking in Manufacturing Environments



Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- The proposed DAH pattern combines the ArUco and Data Matrix to increase information encoding capacity while maintaining simple features. The redundancy in the DAH pattern design allows it to function even in the presence of occlusion. Additionally, the composite design minimizes deployment costs as only one marker needs to be installed;
- (2)
- The proposed multithread acceleration framework distributes the detection tasks across multiple cores, resulting in a higher frame rate per second. This optimization maximizes the utilization of onboard resources and enables robots to dock with higher precision;
- (3)
- The FiMa-Reader system utilizes a near-infrared camera for detection, ensuring that ambient light does not affect the image quality. This ensures stable detection results under different indoor lighting conditions.
2. Related Work
3. Proposed System
3.1. Software Module
3.1.1. Definition of DataMatrix-ArUco-Hybrid Pattern
3.1.2. Detection Framework of DataMatrix-ArUco-Hybrid Pattern
- (a)
- The contents of the two DM regions are identical except for the first symbol;
- (b)
- The distance between the two DM region centroids is within x times the side length of the current new DM region, and the x chosen here is between 1.5 and 2.0, we mark the two DM regions that satisfy the above two conditions as a “friend DM region” of the other. This is useful in the DAH pattern combination module.
- (a)
- The ArUco ID and the content of the current DM region satisfy the mapping relationship introduced in Section 3.1.1;
- (b)
- The distance between the ArUco centroid and the DM centroid is within x times the side length of the DM region, and the x chosen here is between 0.7 and 1.5.
3.1.3. Multithread Processing Framework for Acceleration
| Algorithm 1: Integrate region to DAH pattern. |
 |
3.2. Hardware Modules
4. Experiments and Analysis
4.1. Experiment 1: DAH Pattern Performance
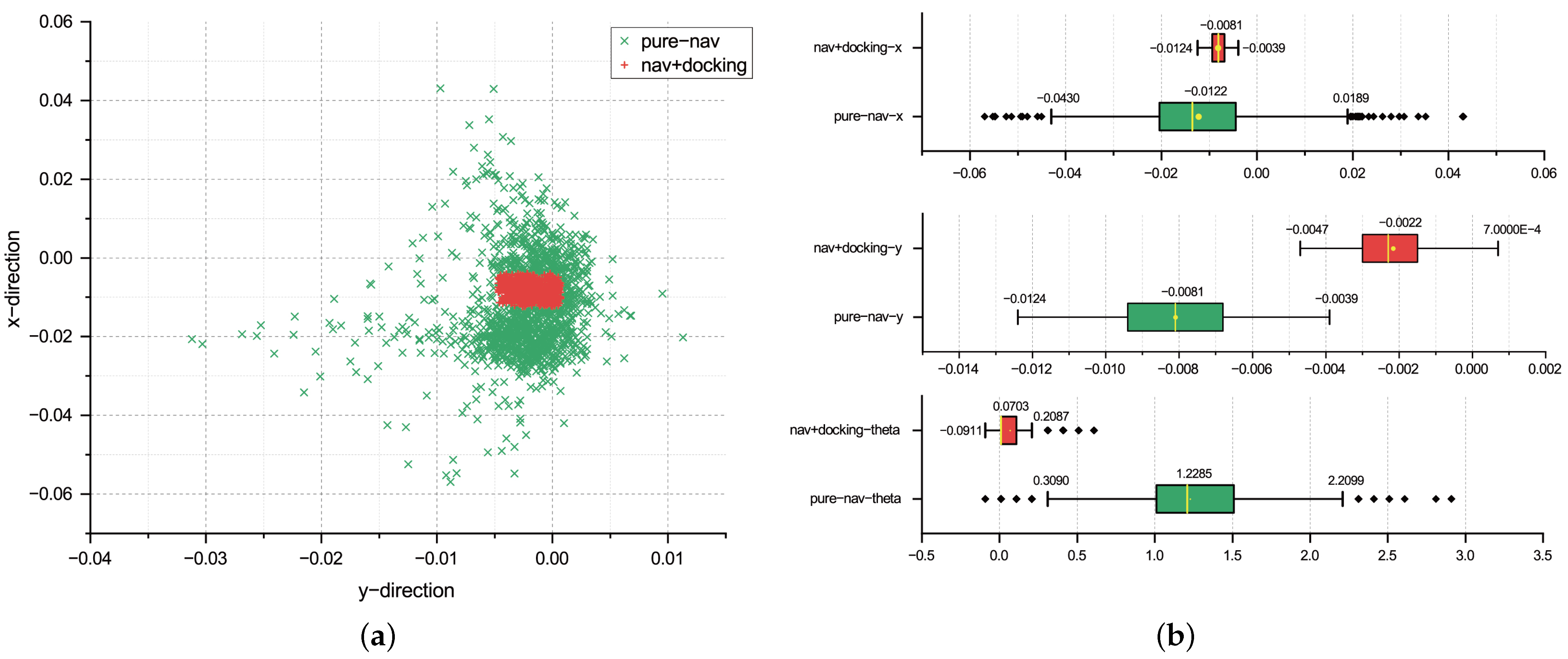
4.2. Experiment 2: FiMa-Reader System Positioning Accuracy
4.3. Experiment 3: Positioning Accuracy of Different FiMa-Reader System Output Rates
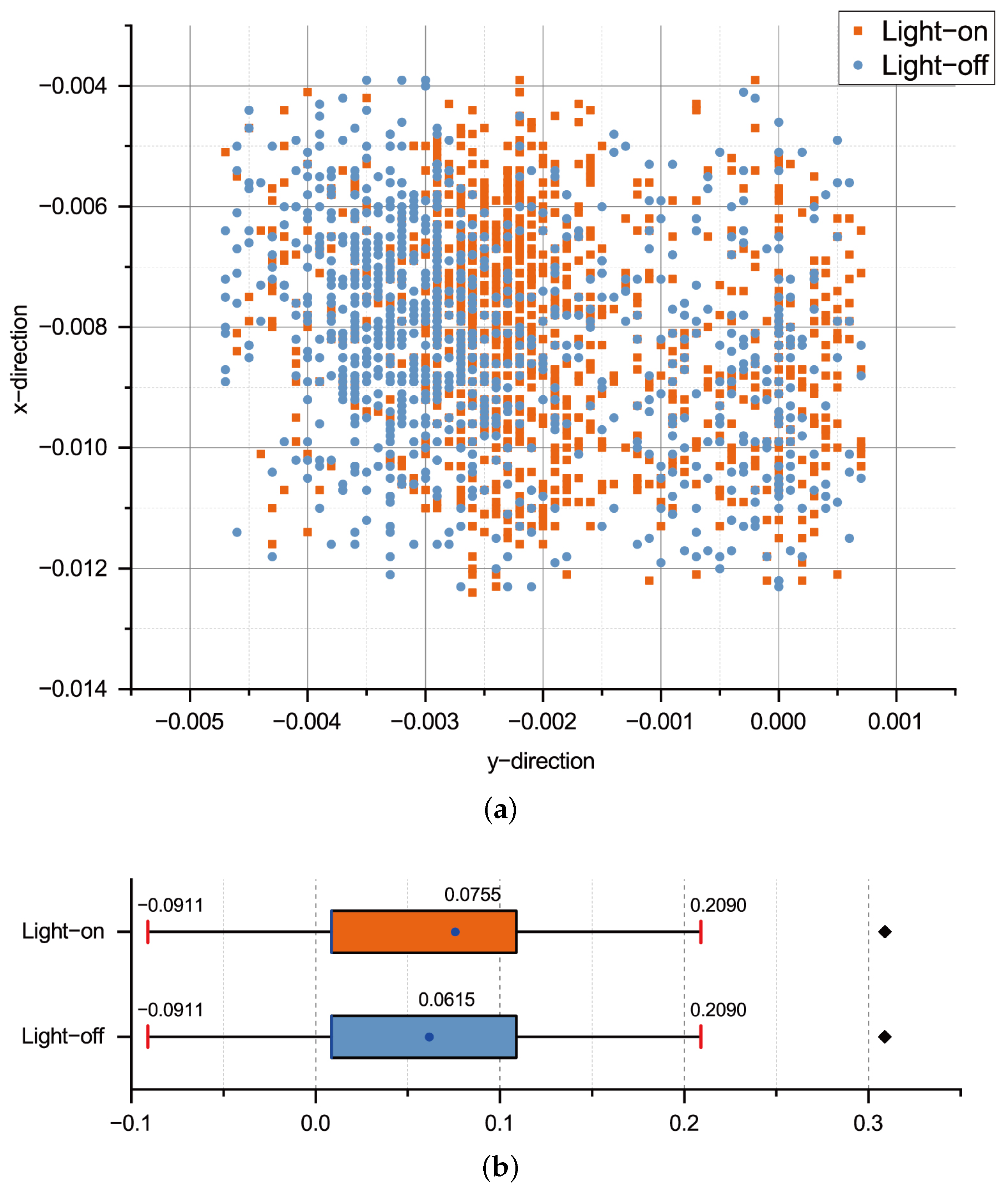
4.4. Experiment 4: Positioning Accuracy of the Light-On and Light-Off Scenarios
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fasuludeen Kunju, F.K.; Naveed, N.; Anwar, M.N.; Ul Haq, M.I. Production and maintenance in industries: Impact of industry 4.0. Ind. Robot. Int. J. Robot. Res. Appl. 2022, 49, 461–475. [Google Scholar] [CrossRef]
- Brecher, C.; Müller, A.; Dassen, Y.; Storms, S. Automation technology as a key component of the Industry 4.0 production development path. Int. J. Adv. Manuf. Technol. 2021, 117, 2287–2295. [Google Scholar] [CrossRef]
- Fragapane, G.; Ivanov, D.; Peron, M.; Sgarbossa, F.; Strandhagen, J.O. Increasing flexibility and productivity in Industry 4.0 production networks with autonomous mobile robots and smart intralogistics. Ann. Oper. Res. 2022, 308, 125–143. [Google Scholar] [CrossRef]
- Chang, C.Y.; Wu, C.L.; Cheng, J.M.; Jian, S.J. Autonomous mobile robots for recycling metal shaving at CNC factories. Int. J. Adv. Manuf. Technol. 2023, 126, 2205–2218. [Google Scholar] [CrossRef]
- Savci, I.H.; Yilmaz, A.; Karaman, S.; Ocakli, H.; Temeltas, H. Improving navigation stack of a ros-enabled industrial autonomous mobile robot (amr) to be incorporated in a large-scale automotive production. Int. J. Adv. Manuf. Technol. 2022, 120, 3647–3668. [Google Scholar] [CrossRef]
- Grau, A.; Indri, M.; Bello, L.L.; Sauter, T. Robots in industry: The past, present, and future of a growing collaboration with humans. IEEE Ind. Electron. Mag. 2020, 15, 50–61. [Google Scholar] [CrossRef]
- Nejat, G.; Benhabib, B. Modelless guidance for the docking of autonomous vehicles. IEEE Trans. Robot. 2007, 23, 753–762. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Bostelman, R.; Bostelman, R.; Hong, T. Review of Research for Docking Automatic Guided Vehicles and Mobile Robots; US Department of Commerce—National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016. [Google Scholar]
- Vukolov, A.; Kourousias, G.; Pugliese, R. Flexible vision-based auto-docking control system for unmanned ground vehicles equipped with differential chassis. In Proceedings of the International Conference on Robotics in Alpe-Adria Danube Region, Klagenfurt am Wörthersee, Austria, 8–10 June 2022; pp. 403–411. [Google Scholar]
- Wang, Y.; Shan, M.; Yue, Y.; Wang, D. Autonomous target docking of nonholonomic mobile robots using relative pose measurements. IEEE Trans. Ind. Electron. 2020, 68, 7233–7243. [Google Scholar] [CrossRef]
- Bolanakis, G.; Nanos, K.; Papadopoulos, E. A QR Code-based High-Precision Docking System for Mobile Robots Exhibiting Submillimeter Accuracy. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Delft, The Netherlands, 12–16 July 2021; pp. 830–835. [Google Scholar]
- Tsiogas, E.; Kleitsiotis, I.; Kostavelis, I.; Kargakos, A.; Giakoumis, D.; Bosch-Jorge, M.; Ros, R.J.; Tarazón, R.L.; Likothanassis, S.; Tzovaras, D. Pallet detection and docking strategy for autonomous pallet truck agv operation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3444–3451. [Google Scholar]
- Liu, Y. A laser intensity based autonomous docking approach for mobile robot recharging in unstructured environments. IEEE Access 2022, 10, 71165–71176. [Google Scholar] [CrossRef]
- Hercik, R.; Byrtus, R.; Jaros, R.; Koziorek, J. Implementation of autonomous mobile robot in smartfactory. Appl. Sci. 2022, 12, 8912. [Google Scholar] [CrossRef]
- Yilmaz, A.; Sumer, E.; Temeltas, H. A precise scan matching based localization method for an autonomously guided vehicle in smart factories. Robot. Comput. Integr. Manuf. 2022, 75, 102302. [Google Scholar] [CrossRef]
- Wu, X.; Lou, P.; Shen, K.; Peng, G.; Tang, D. Precise transhippment control of an automated magnetic-guided vehicle using optics positioning. Int. J. Smart Sens. Intell. Syst. 2014, 7, 48–71. [Google Scholar] [CrossRef]
- Su, S.; Zeng, X.; Song, S.; Lin, M.; Dai, H.; Yang, W.; Hu, C. Positioning accuracy improvement of automated guided vehicles based on a novel magnetic tracking approach. IEEE Intell. Transp. Syst. Mag. 2018, 12, 138–148. [Google Scholar] [CrossRef]
- Falkowski, P.; Smater, M.; Koper, J.; Myśliwiec, A.; Mackiewicz, T. An Approach towards high-precision docking of the mobile robots for industrial purposes. In Proceedings of the Conference on Automation, Paris, France, 31 May–31 August 2020; pp. 239–247. [Google Scholar]
- Liu, H.; Zhu, W.; Ke, Y. Pose alignment of aircraft structures with distance sensors and CCD cameras. Robot. Comput. Integr. Manuf. 2017, 48, 30–38. [Google Scholar] [CrossRef]
- Vasiljević, G.; Miklić, D.; Draganjac, I.; Kovačić, Z.; Lista, P. High-accuracy vehicle localization for autonomous warehousing. Robot. Comput. Integr. Manuf. 2016, 42, 1–16. [Google Scholar] [CrossRef]
- Romero-Ramirez, F.J.; Muñoz-Salinas, R.; Medina-Carnicer, R. Speeded up detection of squared fiducial markers. Image Vis. Comput. 2018, 76, 38–47. [Google Scholar] [CrossRef]
- Wang, J.; Olson, E. AprilTag 2: Efficient and robust fiducial detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4193–4198. [Google Scholar]
- Zhang, H.; Zhang, C.; Yang, W.; Chen, C.Y. Localization and navigation using QR code for mobile robot in indoor environment. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; pp. 2501–2506. [Google Scholar]
- Tian, W.; Chen, D.; Yang, Z.; Yin, H. The application of navigation technology for the medical assistive devices based on Aruco recognition technology. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 2894–2899. [Google Scholar]
- Wang, C.; Yin, L.; Zhao, Q.; Wang, W.; Li, C.; Luo, B. An intelligent robot for indoor substation inspection. Ind. Robot. Int. J. Robot. Res. Appl. 2020, 47, 705–712. [Google Scholar] [CrossRef]
- Dong, H.; Wu, Z.; Wang, J.; Chen, D.; Tan, M.; Yu, J. Implementation of autonomous docking and charging for a supporting robotic fish. IEEE Trans. Ind. Electron. 2022, 70, 7023–7031. [Google Scholar] [CrossRef]
- Xu, Z.; Haroutunian, M.; Murphy, A.J.; Neasham, J.; Norman, R. An underwater visual navigation method based on multiple ArUco markers. J. Mar. Sci. Eng. 2021, 9, 1432. [Google Scholar] [CrossRef]
- Jin, S.; Zhang, J.; Shen, L.; Li, T. On-board vision autonomous landing techniques for quadrotor: A survey. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 10284–10289. [Google Scholar]
- Magdalena Nowara, E.; Marks, T.K.; Mansour, H.; Veeraraghavan, A. SparsePPG: Towards driver monitoring using camera-based vital signs estimation in near-infrared. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1272–1281. [Google Scholar]
- Ghadiok, V.; Goldin, J.; Ren, W. On the design and development of attitude stabilization, vision-based navigation, and aerial gripping for a low-cost quadrotor. Auton. Robot. 2012, 33, 41–68. [Google Scholar] [CrossRef]
- Hijikata, S.; Terabayashi, K.; Umeda, K. A simple indoor self-localization system using infrared LEDs. In Proceedings of the 2009 Sixth International Conference on Networked Sensing Systems (INSS), Pittsburgh, PA, USA, 17–19 June 2009; pp. 1–7. [Google Scholar]
- Michail, K.; Cain, B.; Carroll, S.; Anand, A.; Camden, W.; Nikolaos, V. Fiducial Markers for Pose Estimation. J. Intell. Robot. Syst. 2021, 101, 71. [Google Scholar]
- Collins, T.; Bartoli, A. Infinitesimal plane-based pose estimation. Int. J. Comput. Vis. 2014, 109, 252–286. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fiducial Marker | Data Capacity | Origin (100 per Group) | Occlusion (1000 per Group) | ||
|---|---|---|---|---|---|
| Detection Rate | Average (Success) Detection Time (ms) | Detection Rate | Average (Success) Detection Time (ms) | ||
| DAH pattern | maximum 1556 bytes (ECC200) | 97% | 11.06 | 67.3% | 23.56 |
| ArUco | origin dictionary size: 1000 ids | 70% | 24.58 | 4.5% | 27.61 |
| Data Matrix | maximum 1556 bytes (ECC200) | 19% | 14.01 | 0.2% | 44.56 |
| Data Matrix with Box | maximum 1556 bytes (ECC200) | 84% | 12.05 | 7.2% | 20.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bian, X.; Chen, W.; Ran, D.; Liang, Z.; Mei, X. FiMa-Reader: A Cost-Effective Fiducial Marker Reader System for Autonomous Mobile Robot Docking in Manufacturing Environments. Appl. Sci. 2023, 13, 13079. https://doi.org/10.3390/app132413079
Bian X, Chen W, Ran D, Liang Z, Mei X. FiMa-Reader: A Cost-Effective Fiducial Marker Reader System for Autonomous Mobile Robot Docking in Manufacturing Environments. Applied Sciences. 2023; 13(24):13079. https://doi.org/10.3390/app132413079
Chicago/Turabian StyleBian, Xu, Wenzhao Chen, Donglai Ran, Zhimou Liang, and Xuesong Mei. 2023. "FiMa-Reader: A Cost-Effective Fiducial Marker Reader System for Autonomous Mobile Robot Docking in Manufacturing Environments" Applied Sciences 13, no. 24: 13079. https://doi.org/10.3390/app132413079
APA StyleBian, X., Chen, W., Ran, D., Liang, Z., & Mei, X. (2023). FiMa-Reader: A Cost-Effective Fiducial Marker Reader System for Autonomous Mobile Robot Docking in Manufacturing Environments. Applied Sciences, 13(24), 13079. https://doi.org/10.3390/app132413079