


Weed Detection Method Based on Lightweight and Contextual Information Fusion


Abstract
:1. Introduction
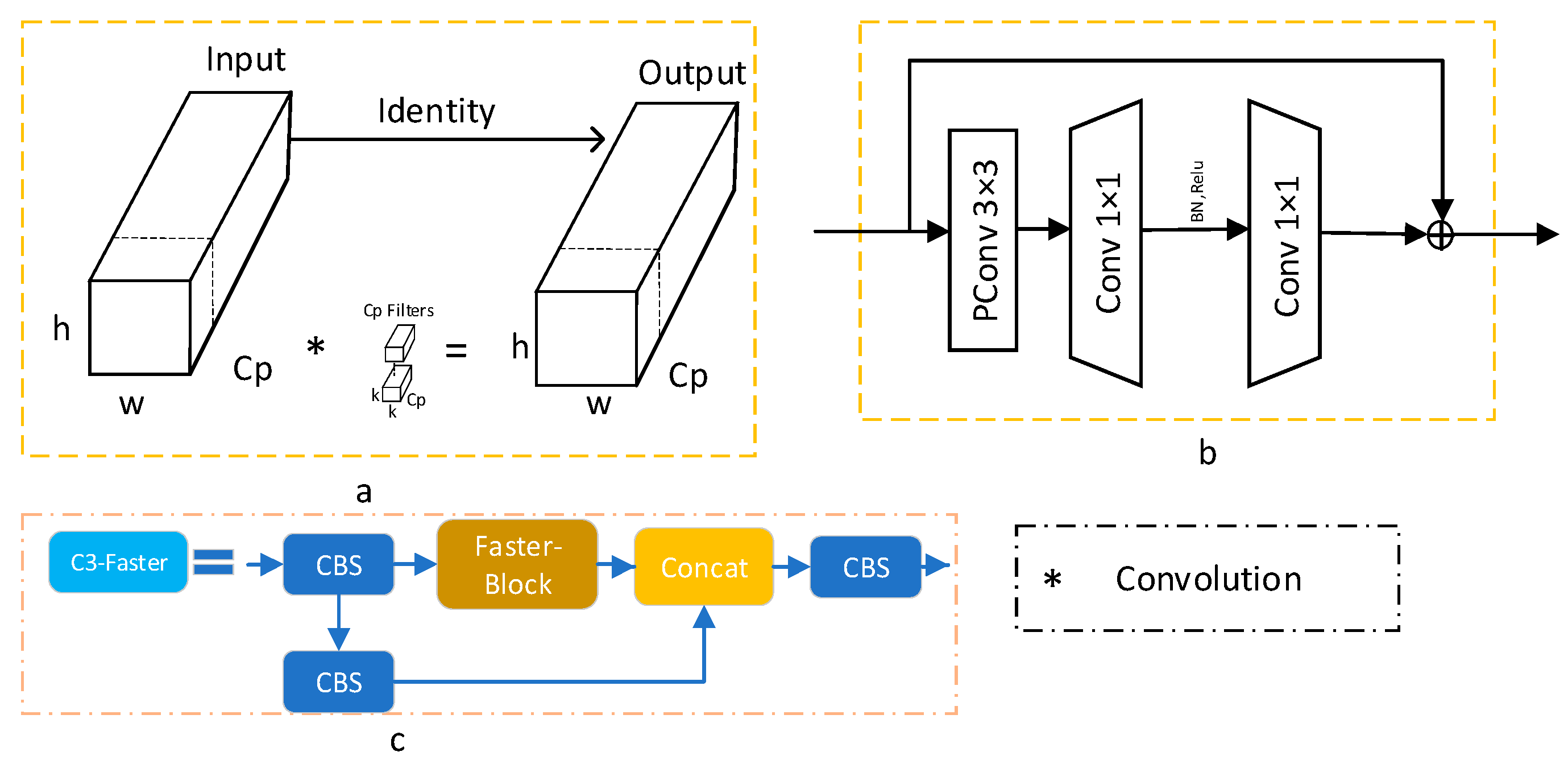
- Improved the neck network by utilizing the lightweight FasterNet [27] architecture to create the new C3_faster module, which replaced the first three C3 modules in the neck. The objective was to reduce the model’s parameter count, making it more lightweight.
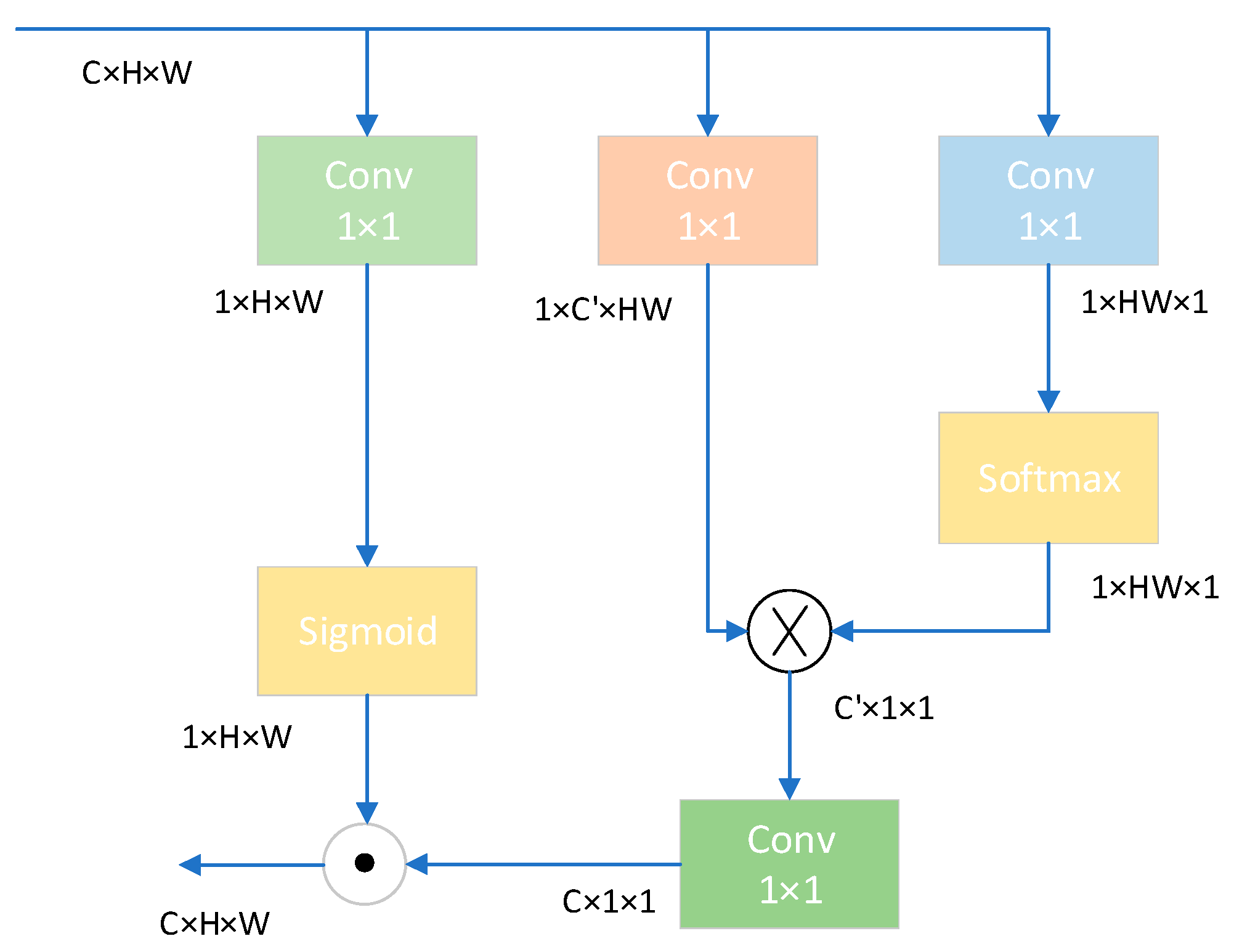
- Replaced the 1 × 1 convolution in the head with Contest Aggregation [28], adaptively fusing context information of different scales, improving the model’s performance in detecting weeds in complex backgrounds.
- Replaced the conventional upsampling modules in the neck network with the CARAFE [29] module, enhancing the fusion of contextual information and improving the model’s performance in detecting small targets.
- Proposed using EIoU [30] to replace the original CIoU in YOLOv5, enhancing regression accuracy. Additionally, we introduce Soft-NMS [31] to optimize overlapping bounding boxes in the regression task, reducing redundant boxes, and retaining potential target boxes, thus enhancing the model’s robustness.
- Conducted tests to evaluate performance under different IoU thresholds and using combinations of IoU and Soft-NMS. We also perform ablation experiments on different optimization modules. Lastly, we compare our model with classical object detection networks to validate its effectiveness.
- To validate the robustness of the model, the performance of YOLOv5 was compared with the improved algorithm on the sesame weed dataset.
2. Materials and Methods
2.1. Dataset
2.2. Enhanced YOLOv5 Model
2.2.1. YOLOV5
2.2.2. C3-Faster
2.2.3. Context Aggregation
2.2.4. Lightweight CARAFE Upsampling Operator
2.2.5. Soft-NMS-EIoU
2.2.6. The Structure of CCCS-YOLO

3. Experimental Validation and Results Analysis
3.1. Model Evaluation Metrics
3.2. Comparative Experiments with Different IoU and Soft-NMS-X
3.3. Comparative Experiments
3.4. Ablation Experiments
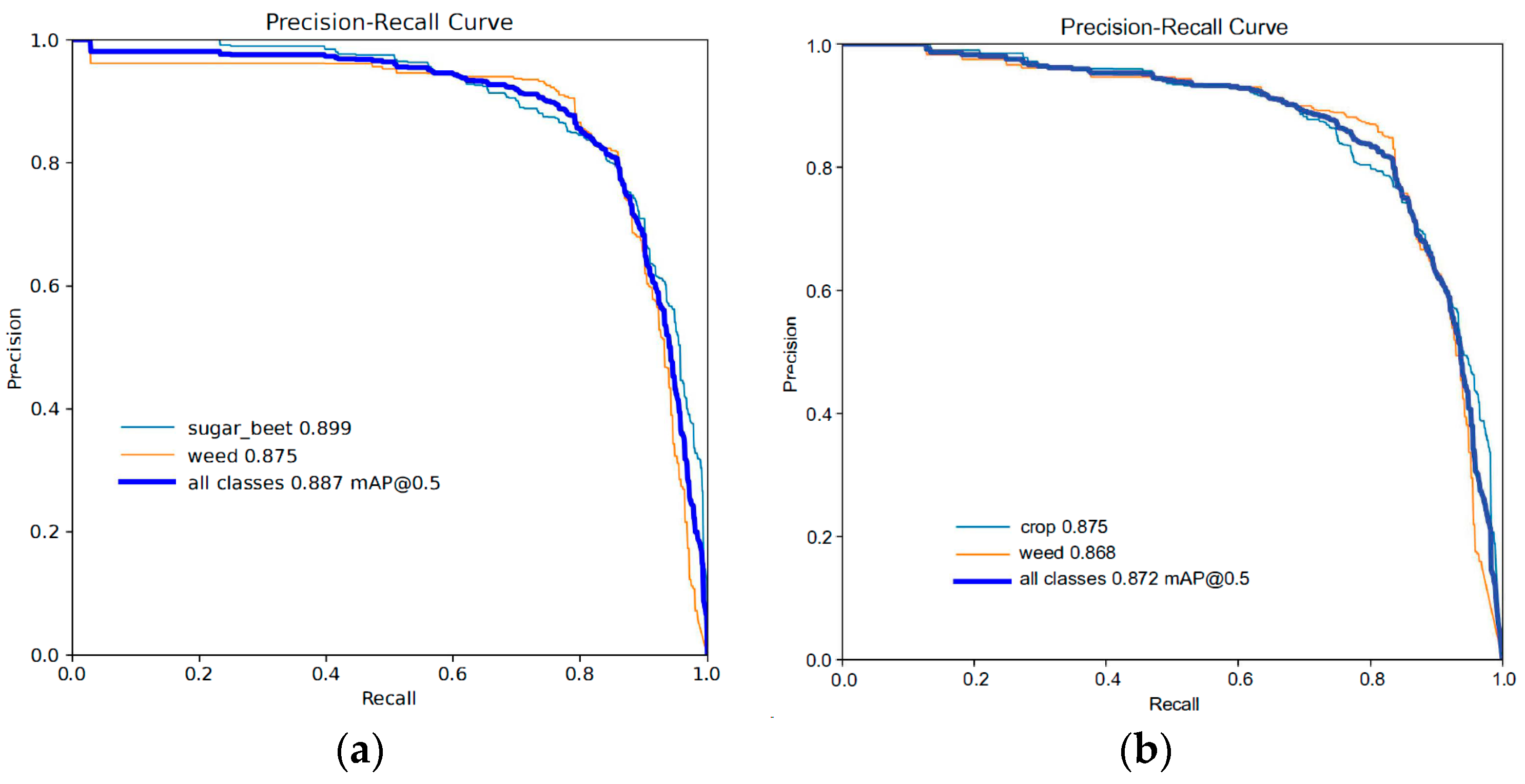
3.5. Results Visualization
3.6. Robustness Evaluation of the Improved Algorithm
3.6.1. Sesame Weed Dataset
3.6.2. Comparative Analysis before and after Improvement
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Llewellyn, R.; Ronning, D.; Clarke, M.; Mayfield, A.; Walker, S.; Ouzman, J. Impact of Weeds in Australian Grain Production; Grains Research and Development Corporation: Canberra, ACT, Australia, 2016. [Google Scholar]
- Gao, J.; Liao, W.; Nuyttens, D.; Lootens, P.; Vangeyte, J.; Pižurica, A.; He, Y.; Pieters, J.G. Fusion of pixel and object-based features for weed mapping using unmanned aerial vehicle imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 67, 43–53. [Google Scholar] [CrossRef]
- Utstumo, T.; Urdal, F.; Brevik, A.; Dørum, J.; Netland, J.; Overskeid, Ø.; Berge, T.W.; Gravdahl, J.T. Robotic in-row weed control in vegetables. Comput. Electron. Agric. 2018, 154, 36–45. [Google Scholar] [CrossRef]
- Søgaard, H.T.; Lund, I. Application accuracy of a machine vision-controlled robotic micro-dosing system. Biosyst. Eng. 2007, 96, 315–322. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, Y.; Mu, D.; Bai, L.; Zhuang, H.; Li, H. YOLOX-based blue laser weeding robot in corn field. Front. Plant Sci. 2022, 13, 1017803. [Google Scholar] [CrossRef] [PubMed]
- Gu, B.; Liu, Q.; Tian, G.; Wang, H.; Li, H.; Xie, S. Recognizing and locating the trunk of a fruit tree using improved YOLOv3. Trans. Chin. Soc. Agric. Eng. 2022, 38, 122–129. [Google Scholar]
- González-Cabrera, M.; Wieland, K.; Eitenberger, E.; Bleier, A.; Brunnbauer, L.; Limbeck, A.; Hutter, H.; Haisch, C.; Lendl, B.; Domínguez-Vidal, A.; et al. Multisensor hyperspectral imaging approach for the microchemical analysis of ultramarine blue pigments. Sci. Rep. 2022, 12, 707. [Google Scholar] [CrossRef] [PubMed]
- Ge, H.; Lv, M.; Lu, X.; Jiang, Y.; Wu, G.; Li, G.; Li, L.; Li, Z.; Zhang, Y. Applications of THz Spectral Imaging in the Detection of Agricultural Products. Photonics 2021, 8, 518. [Google Scholar] [CrossRef]
- Cecconi, V.; Kumar, V.; Pasquazi, A.; Gongora, J.S.T.; Peccianti, M. Nonlinear field-control of terahertz waves in random media for spatiotemporal focusing [version 3; peer review: 2 approved]. Open Res. Europe 2023, 2, 32. [Google Scholar] [CrossRef]
- Luana, O.; Peters, L.; Cecconi, V.; Cutrona, A.; Rowley, M.; Totero Gongora, J.S.; Alessia Pasquazi, A.; Peccianti, M. Terahertz Nonlinear Ghost Imaging via Plane Decomposition: Toward Near-Field Micro-Volumetry. ACS Photonics 2023, 10, 1726–1734. [Google Scholar] [CrossRef]
- Abro, G.M.; Kundan, K. Implementation of fruit grading & sorting station using digital image processing techniques. Sir Syed Univ. Res. J. Eng. Technol. 2017, 7, 6. [Google Scholar]
- Tunio, N.; Abdul, L.M.; Faheem, Y.K.; Ghulam, M.A. Detection of infected leaves and botanical diseases using curvelet transform. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 1. [Google Scholar] [CrossRef]
- Mahmudul Hasan, A.S.M.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M.G. A survey of deep learning techniques for weed detection from images. Comput. Electron. Agric. 2021, 184, 106067. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y.; Zhao, B.; Kang, X.; Ding, Y. Review of Weed Detection Methods Based on Computer Vision. Sensors 2021, 21, 3647. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Zhang, W.; Wei, X. A review on weed detection using ground-based machine vision and image processing techniques. Comput. Electron. Agric. 2019, 158, 226–240. [Google Scholar] [CrossRef]
- Longzhe, Q.; Wei, J.; Li, J.; Li, H.; Wang, Q.; Chen, L. Intelligent intra-row robotic weeding system combining deep learning technology with a targeted weeding mode. Biosyst. Eng. 2022, 216, 13–31. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Mu, Y.; Feng, R.; Ni, R.; Li, J.; Luo, T.; Liu, T.; Li, X.; Gong, h.; Guo, Y.; Sun, Y.; et al. A Faster R-CNN-Based Model for the Identification of Weed Seedling. Agronomy 2022, 12, 2867. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ying, B.; Xu, Y.; Zhang, S.; Shi, Y.; Liu, L. Weed Detection in Images of Carrot Fields Based on Improved YOLO v4. Trait. Signal 2021, 38, 341–348. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Zhang, H.; Luo, T.; Wei, D.; Long, T.; Wang, Z. Weed detection in sesame fields using a YOLO model with an enhanced attention mechanism and feature fusion. Comput. Electron. Agric. 2022, 202, 107412. [Google Scholar] [CrossRef]
- Hong, W.; Ma, W.; Ye, B.; Yu, G.; Tang, T.; Zheng, M. Detection of Green Asparagus in Complex Environments Based on the Improved YOLOv5 Algorithm. Sensors 2023, 23, 1562. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liang, J.; Wang, J.; Hu, P.; Wan, L.; Zheng, Q. An improved YOLOv5-based approach to soybean phenotype information perception. Comput. Electr. Eng. 2023, 106, 108582. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]
- Liu, Y.; Li, H.; Hu, C.; Luo, S.; Luo, Y.; Chen, C.W. Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images. arXiv 2021, arXiv:2111.11057. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2009; pp. 3007–3016. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving object detection with one line of code. arXiv 2017, arXiv:1704.04503. [Google Scholar]
- Salazar-Gomez, A.; Darbyshire, M.; Gao, J.; Sklar, E.I.; Parsons, S. Towards practical object detection for weed spraying in precision agriculture. arXiv 2021, arXiv:2109.11048. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. arXiv 2018, arXiv:1707.01083. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. arXiv 2020, arXiv:1911.11907. [Google Scholar]
- Neubeck, A.; Gool, L.J.V. Efficient Non-Maximum Suppression. In Proceedings of the International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; IEEE Computer Society: Hong Kong, China, 2006. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Siliang, M.; Yong, X. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2023, arXiv:2207.02696. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, A.; Peng, T.; Cao, H.; Xu, Y.; Wei, X.; Cui, B. TIA-YOLOv5: An improved YOLOv5 network for real-time detection of crop and ed in the field. Front. Plant Sci. 2022, 13, 1091655. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| Optical Detection | High accuracy, fast speed | High cost, not suitable for multi-target detection |
| Digital Image Processing | Fast speed, low cost | Limited applicability, high environmental requirements |
| Curvelet Transform Detection | Fast speed | Limited applicability, high detection environmental requirements |
| Computer Vision | High accuracy, fast speed | Requires a large amount of dataset and computational resources |
| Methods | Params (M) | FLOPs@640 (B) | mAP@0.5 (%) | mAP@0.5:0.95(%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| yolov5s | 7.1 | 15.8 | 76.3 | 53.5 | 76.9 | 71.5 |
| yolov5s + G | 7.1 | 15.8 | 77.7 | 53.7 | 76.3 | 72.5 |
| yolov5s + D | 7.1 | 15.8 | 77.3 | 53.7 | 76.9 | 72.4 |
| yolov5s + E | 7.1 | 15.8 | 77.8 | 54.2 | 76.9 | 73.0 |
| yolov5s + S | 7.1 | 15.8 | 77.9 | 54.0 | 76.5 | 72.7 |
| yolov5s + W | 7.1 | 15.8 | 75.8 | 52.8 | 76.2 | 71.6 |
| yolov5s + M | 7.1 | 15.8 | 75.8 | 53.0 | 76.6 | 71.2 |
| yolov5s + SN | 7.1 | 15.8 | 77.3 | 57.5 | 76.4 | 71.3 |
| yolov5s + SN + D | 7.1 | 15.8 | 77.6 | 57.5 | 76.7 | 72.4 |
| yolov5s + SN + E | 7.1 | 15.8 | 77.6 | 57.9 | 76.8 | 73.0 |
| yolov5s + SN + G | 7.1 | 15.8 | 77.7 | 57.4 | 76.2 | 72.6 |
| yolov5s + SN + S | 7.1 | 15.8 | 76.7 | 57.2 | 77.3 | 70.6 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Recall (%) | F1 | Precision (%) | Weight (MB) | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| YOLOv4-tiny | 50.68 | 30.69 | 46.2 | 54.8 | 67.87 | 22.4 | 6.0 | 16.3 |
| Faster-RCNN | 53.46 | 36.1 | 60.1 | 52.8 | 47.1 | 108 | 41.13 | 78.1 |
| SSD | 46.48 | 31.2 | 56.9 | 65.0 | 75.8 | 91.1 | 50.4 | 114.2 |
| YOLOx | 74.84 | 53.7 | 71.4 | 74.4 | 77.69 | 34.3 | 8.94 | 26.64 |
| YOLOv5s | 76.3 | 53.5 | 71.5 | 74.1 | 76.9 | 13.7 | 7.1 | 15.8 |
| TIA-YOLOv5 | 75.63 | 52.4 | 72.4 | 74.8 | 77.5 | 16.8 | 9.4 | 17.6 |
| YOLOv7-tiny | 76.9 | 51.3 | 71.3 | 74.7 | 78.6 | 11.7 | 6.1 | 13.0 |
| YOLOv8s | 77.1 | 54.0 | 72.4 | 76.9 | 82.1 | 21.5 | 11.2 | 28.6 |
| CCCS-YOLO | 79.5 | 58.6 | 74.8 | 77.9 | 81.3 | 14.9 | 7.65 | 16.1 |
| Methods | Params (M) | GFLOPs | mAP@0.5 (%) | mAP@0.5:0.95 (%) | P (%) | R (%) |
|---|---|---|---|---|---|---|
| YOLOv5s | 7.1 | 15.8 | 76.3 | 53.5 | 76.9 | 71.5 |
| YOLOv5s + C3F | 6.8 | 14.9 | 77.7 | 53.4 | 77.9 | 72.8 |
| YOLOv5s + CA | 7.7 | 16.7 | 77.9 | 53.9 | 77.8 | 71.8 |
| YOLOv5s + CAR | 7.16 | 16.0 | 77.5 | 53.7 | 79.8 | 72.7 |
| YOLOv5s + SNE | 7.1 | 15.8 | 77.6 | 57.9 | 76.8 | 73.0 |
| YOLOv5s + C3F + CA | 7.5 | 15.8 | 78.1 | 53.8 | 78.4 | 73.6 |
| YOLOv5s + C3F + CA + SNE | 7.5 | 15.8 | 78.9 | 58.2 | 78.7 | 73.6 |
| YOLOv5s + C3F + CA + SNE + CAR | 7.65 | 16.1 | 79.5 | 58.6 | 81.3 | 74.8 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Recall (%) | Precision (%) |
|---|---|---|---|---|
| YOLOv5s | 87.2% | 57.3% | 82.5% | 81.2% |
| CCCS-YOLO | 88.7% | 58.9% | 83.1% | 83.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Liu, J.; Li, H.; Chen, H.; Xu, Z.; Ou, Z. Weed Detection Method Based on Lightweight and Contextual Information Fusion. Appl. Sci. 2023, 13, 13074. https://doi.org/10.3390/app132413074
Zhang C, Liu J, Li H, Chen H, Xu Z, Ou Z. Weed Detection Method Based on Lightweight and Contextual Information Fusion. Applied Sciences. 2023; 13(24):13074. https://doi.org/10.3390/app132413074
Chicago/Turabian StyleZhang, Chi, Jincan Liu, Hongjun Li, Haodong Chen, Zhangxun Xu, and Zhen Ou. 2023. "Weed Detection Method Based on Lightweight and Contextual Information Fusion" Applied Sciences 13, no. 24: 13074. https://doi.org/10.3390/app132413074
APA StyleZhang, C., Liu, J., Li, H., Chen, H., Xu, Z., & Ou, Z. (2023). Weed Detection Method Based on Lightweight and Contextual Information Fusion. Applied Sciences, 13(24), 13074. https://doi.org/10.3390/app132413074