

Cause Analysis and Accident Classification of Road Traffic Accidents Based on Complex Networks


Abstract
:1. Introduction
2. Related Work
3. Methodology
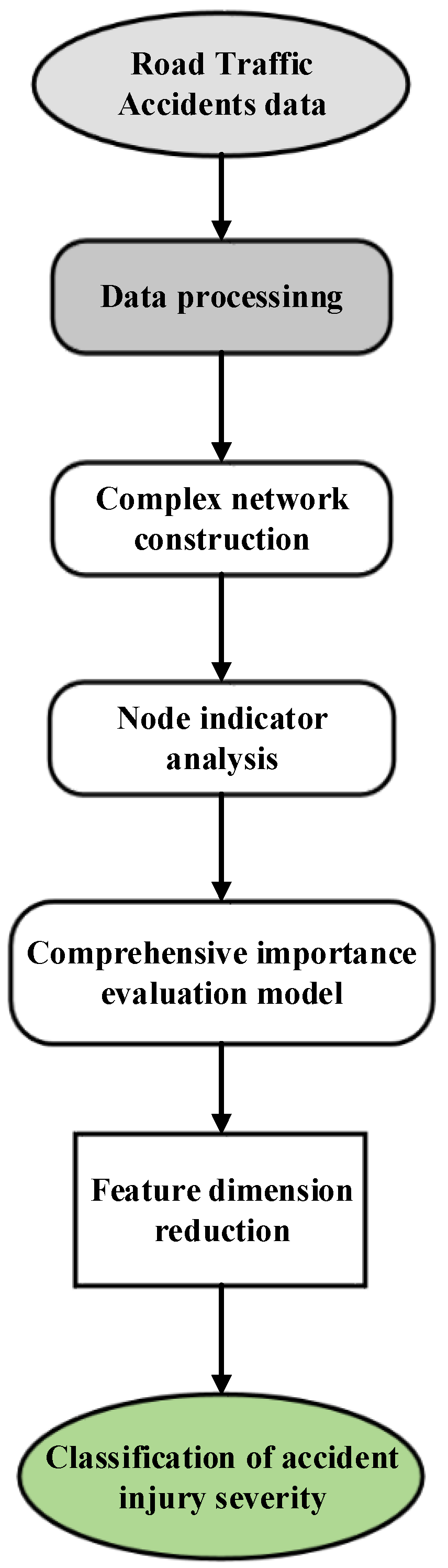
3.1. A Framework for Analyzing the Causes of Road Traffic Accidents and Classifying Accidents Based on Complex Networks
3.2. The Construction of Complex Networks
3.3. Complex Network Evaluation Index
3.4. Construction of a Comprehensive Importance Evaluation Model
3.5. Construction of an Accident Injury Severity Classification Model
4. Case Studies
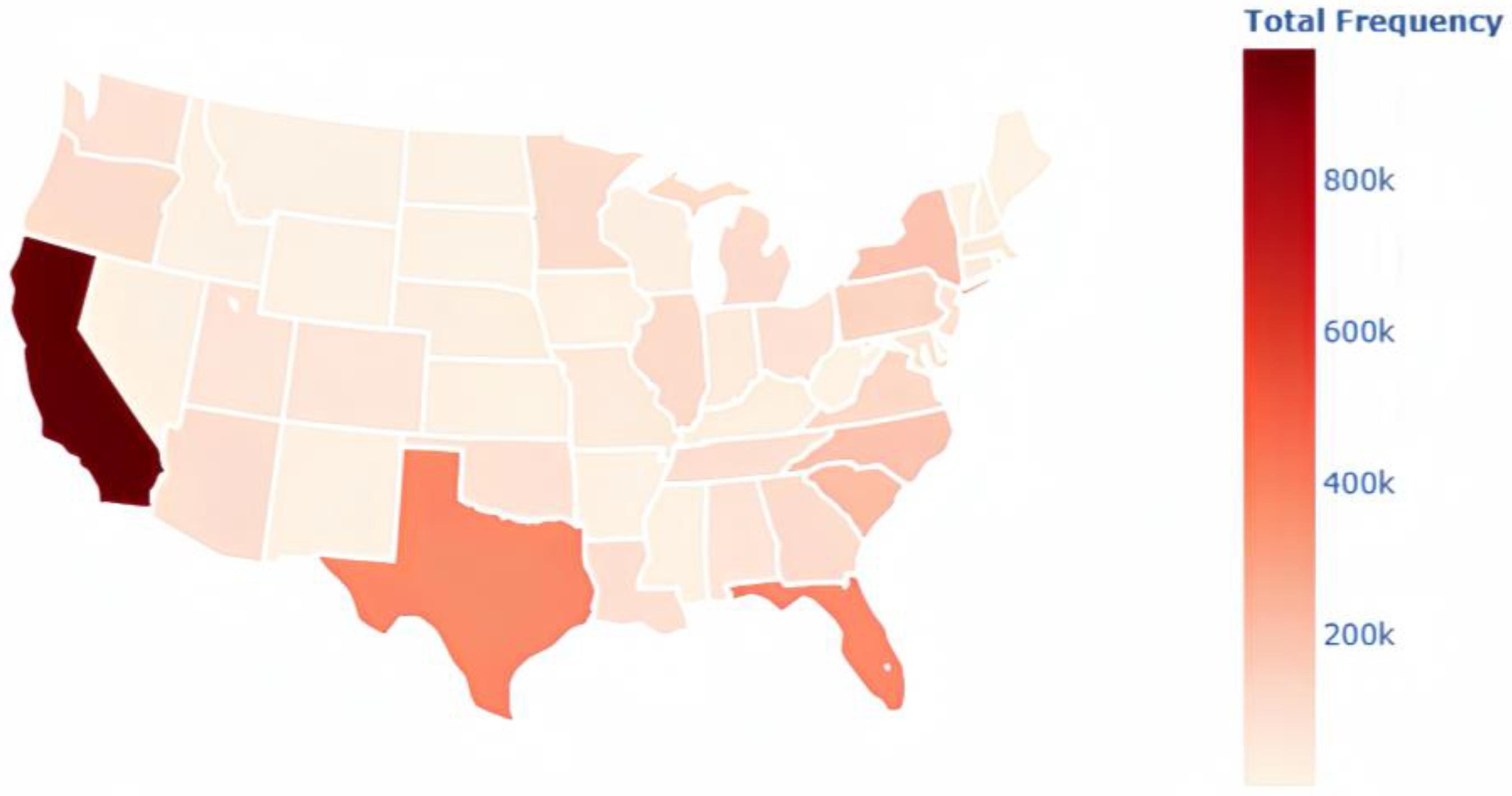
4.1. Data Preparation and Analysis
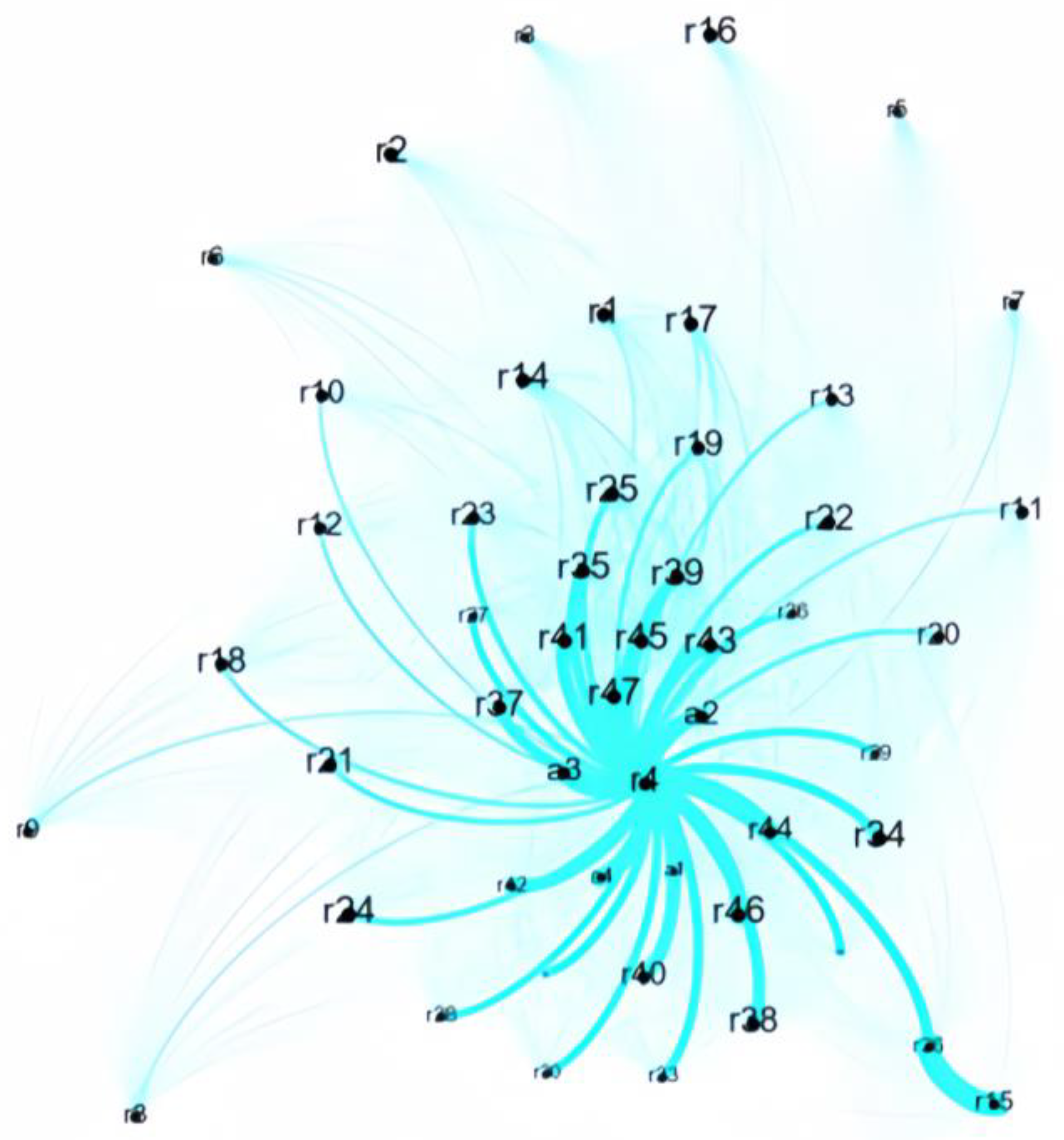
4.2. The Construction of a Road Traffic Accident Cause Analysis Network
4.3. The Evaluation Index of the Road Traffic Accident Cause Analysis Network
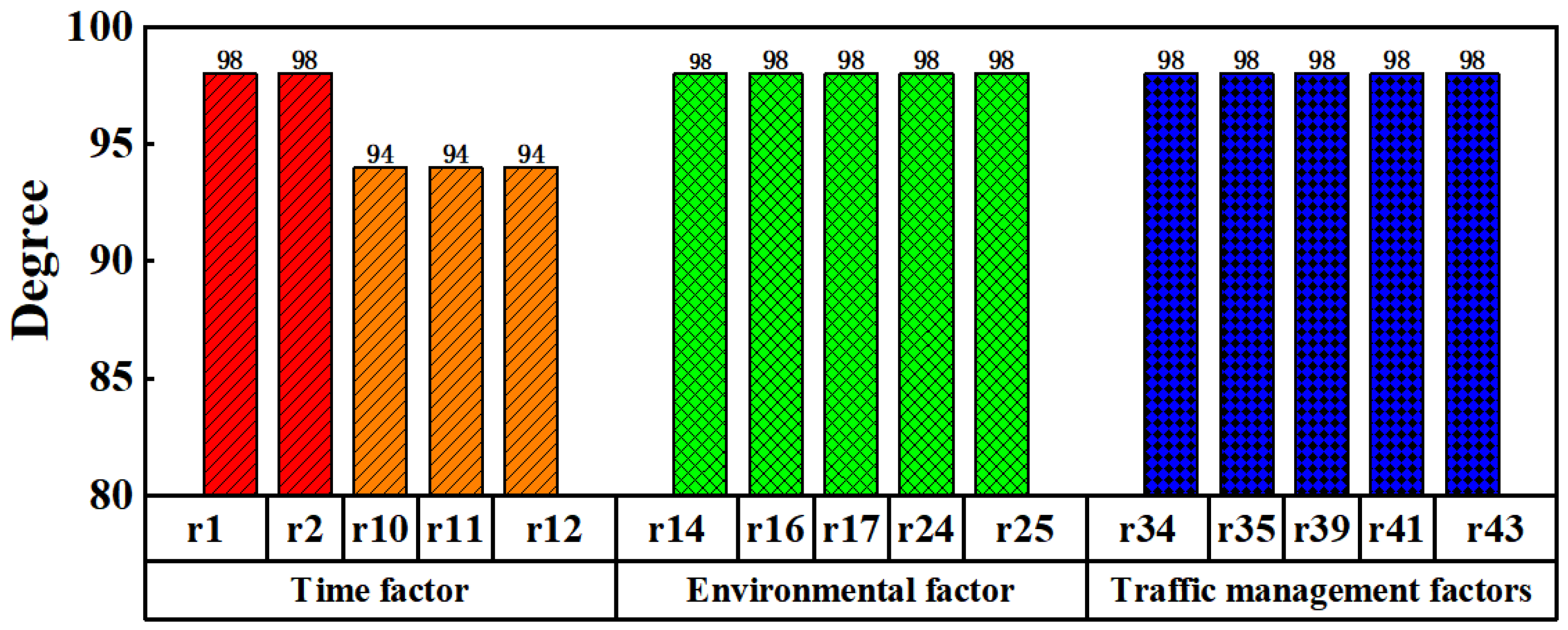
4.3.1. The Degree of Node of Network
4.3.2. Network Diameter and Average Path Length
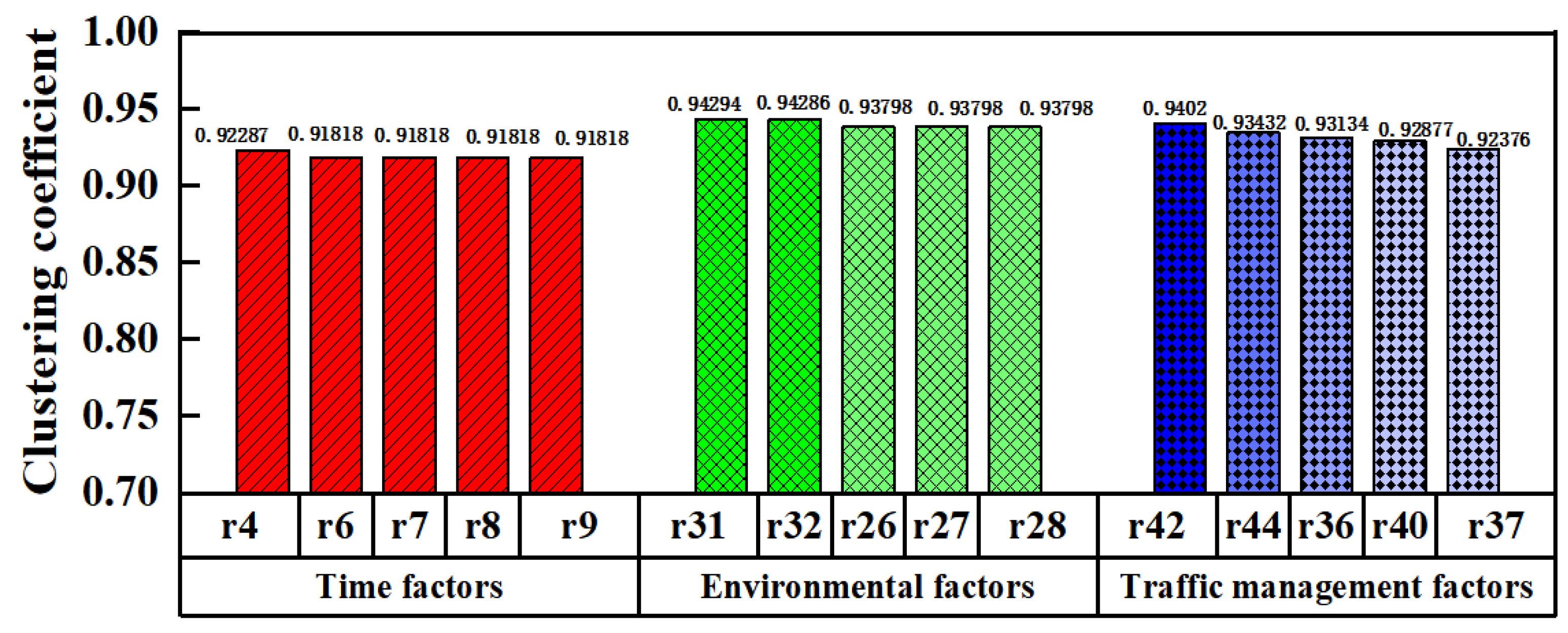
4.3.3. The Clustering Coefficient of the Network
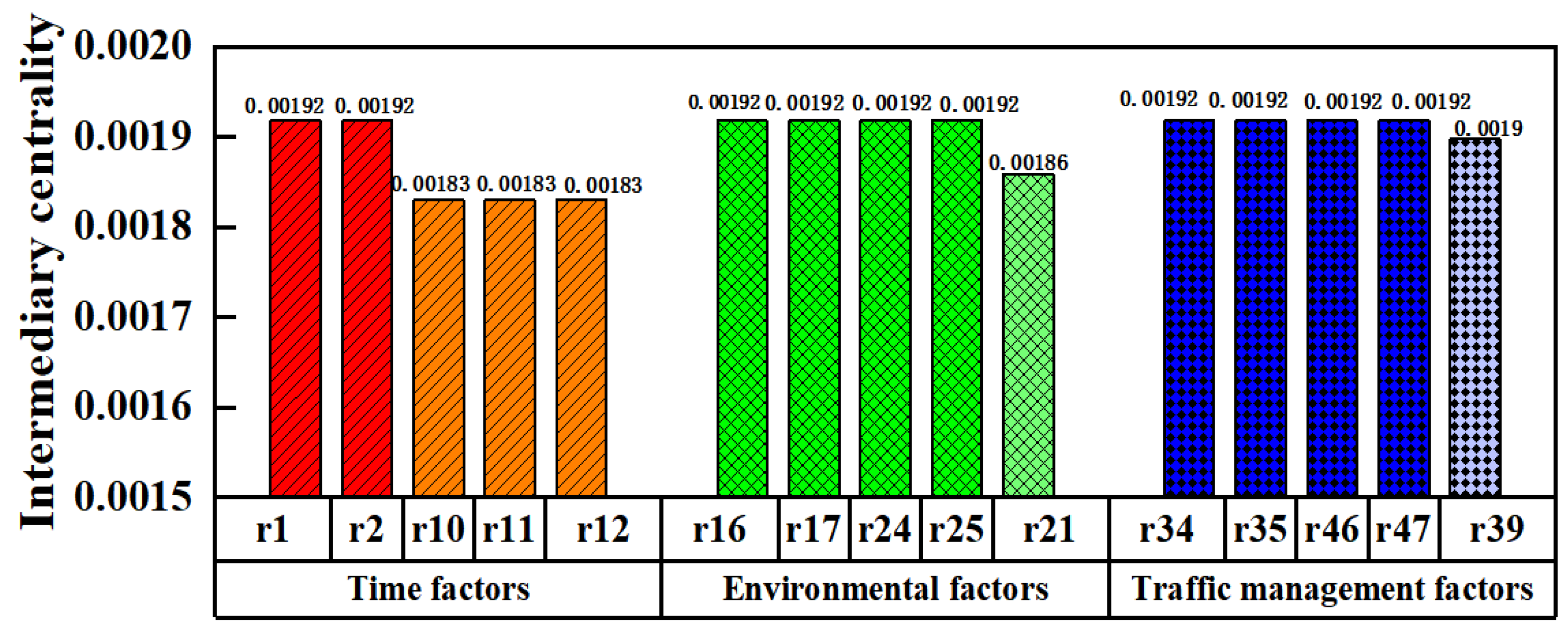
4.3.4. The Intermediary Centrality of the Network
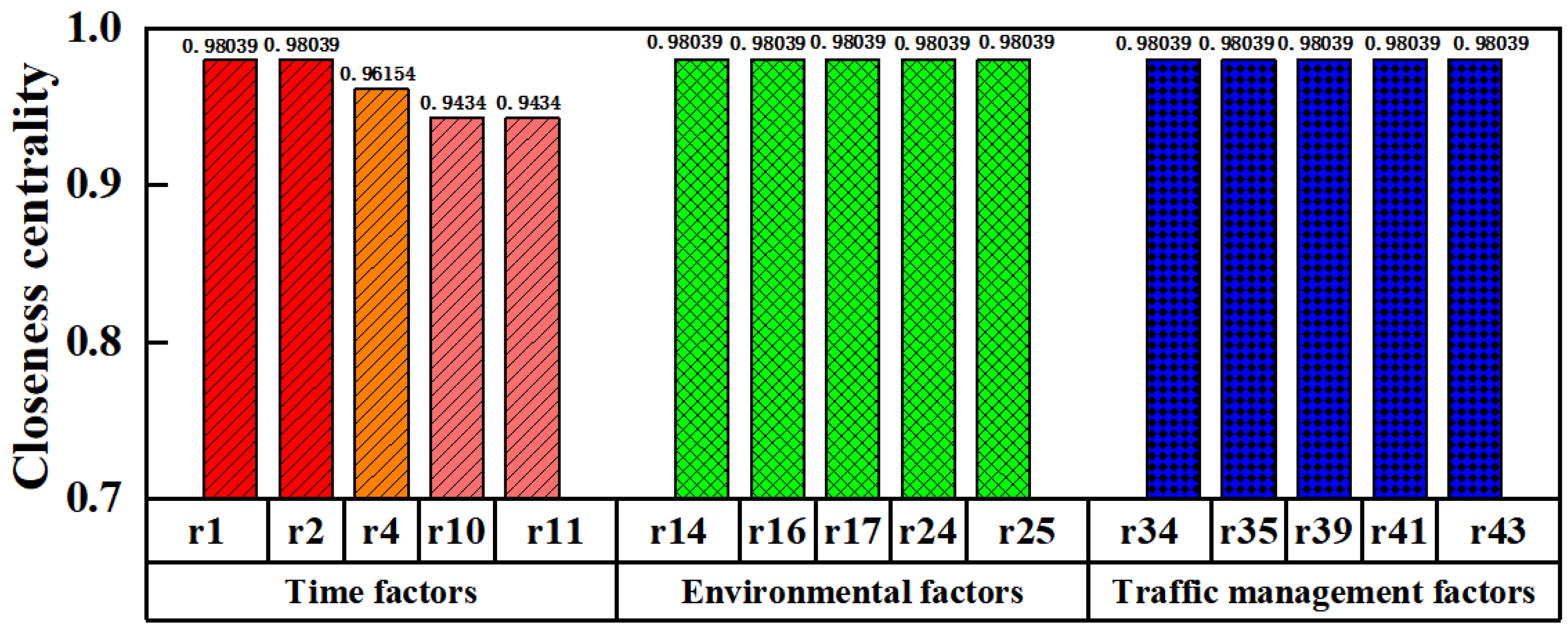
4.3.5. The Closeness Centrality of the Network
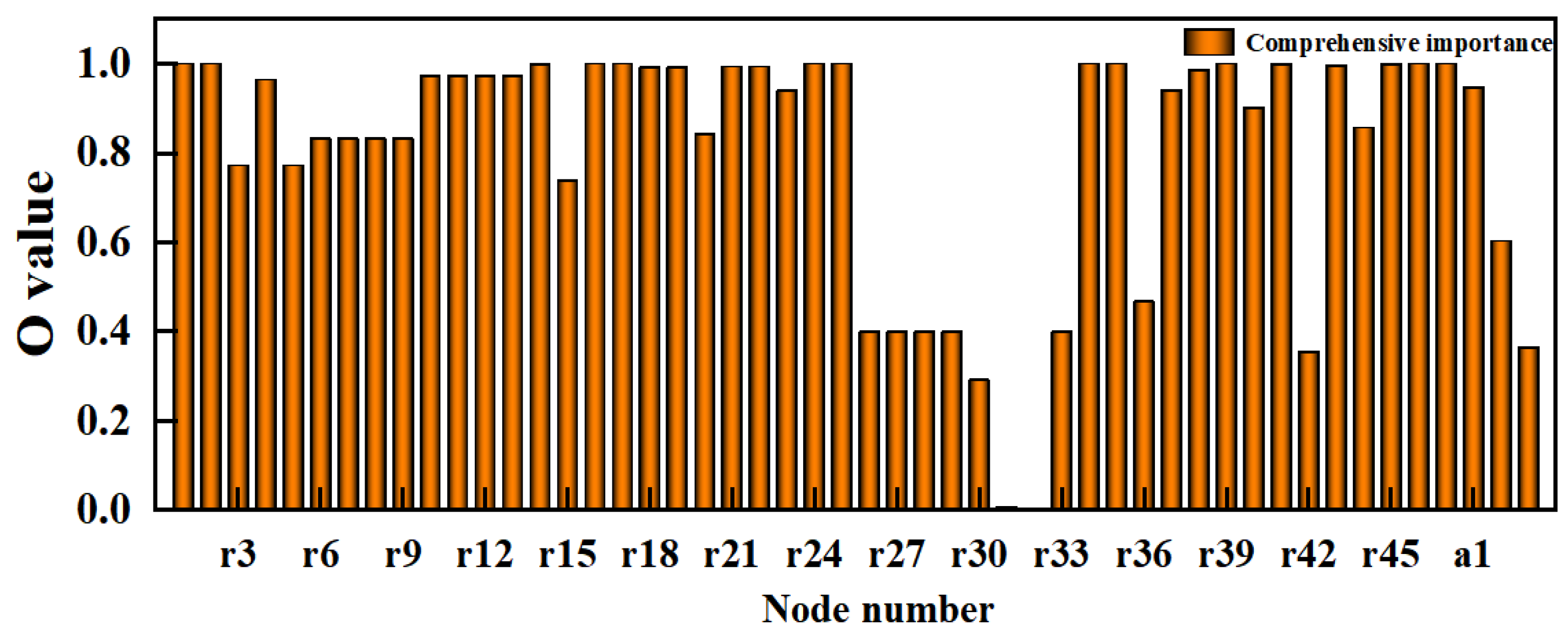
4.4. Comprehensive Importance Analysis of the Road Traffic Accident Cause Analysis Network
4.4.1. Construction of a Comprehensive Important Evaluation Model
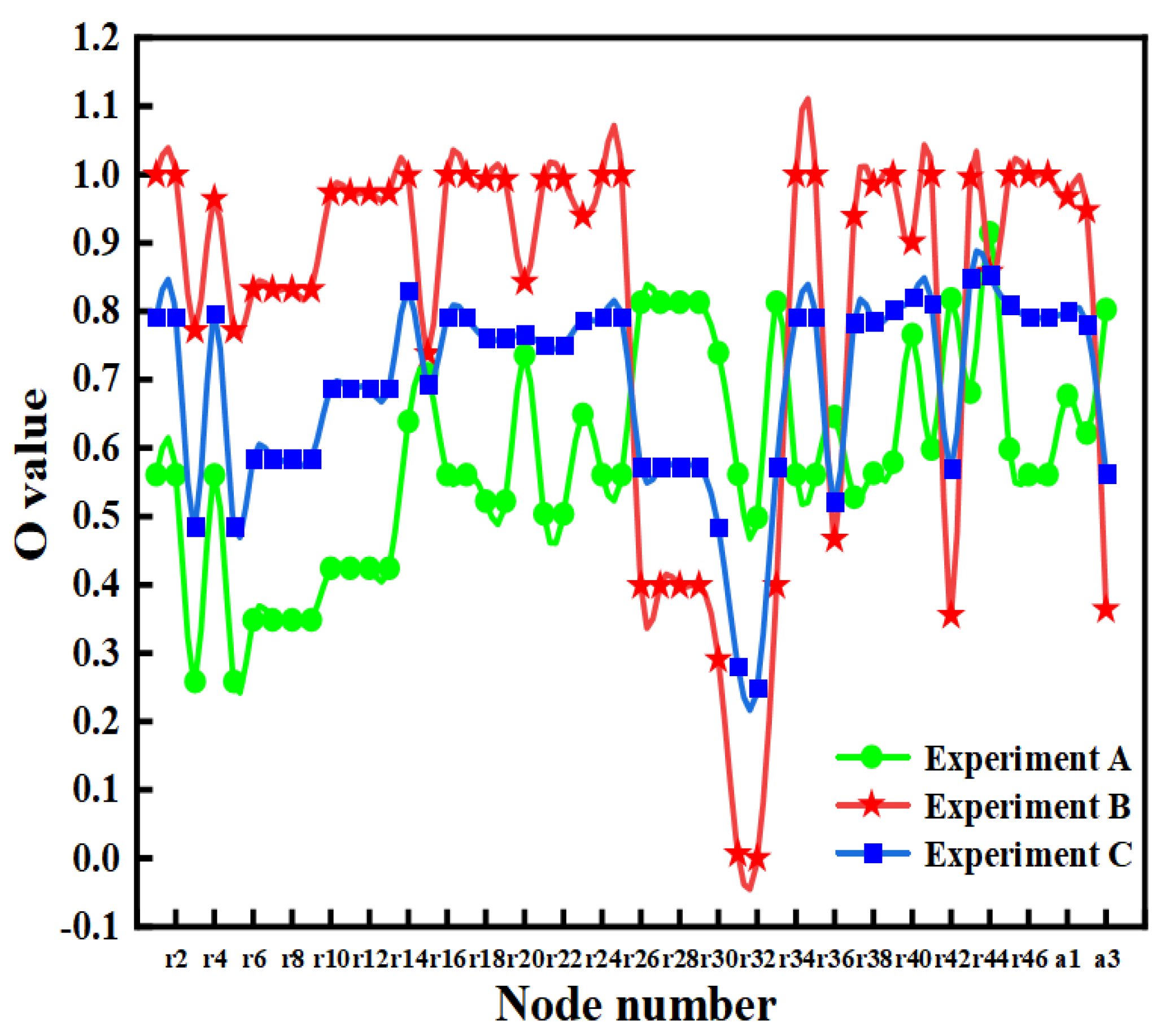
4.4.2. Comparative Experiment of the Comprehensive Importance Evaluation Model
4.5. Construction of an Injury Severity Classification Model for Road Traffic Accidents
4.5.1. Data Normalization Processing
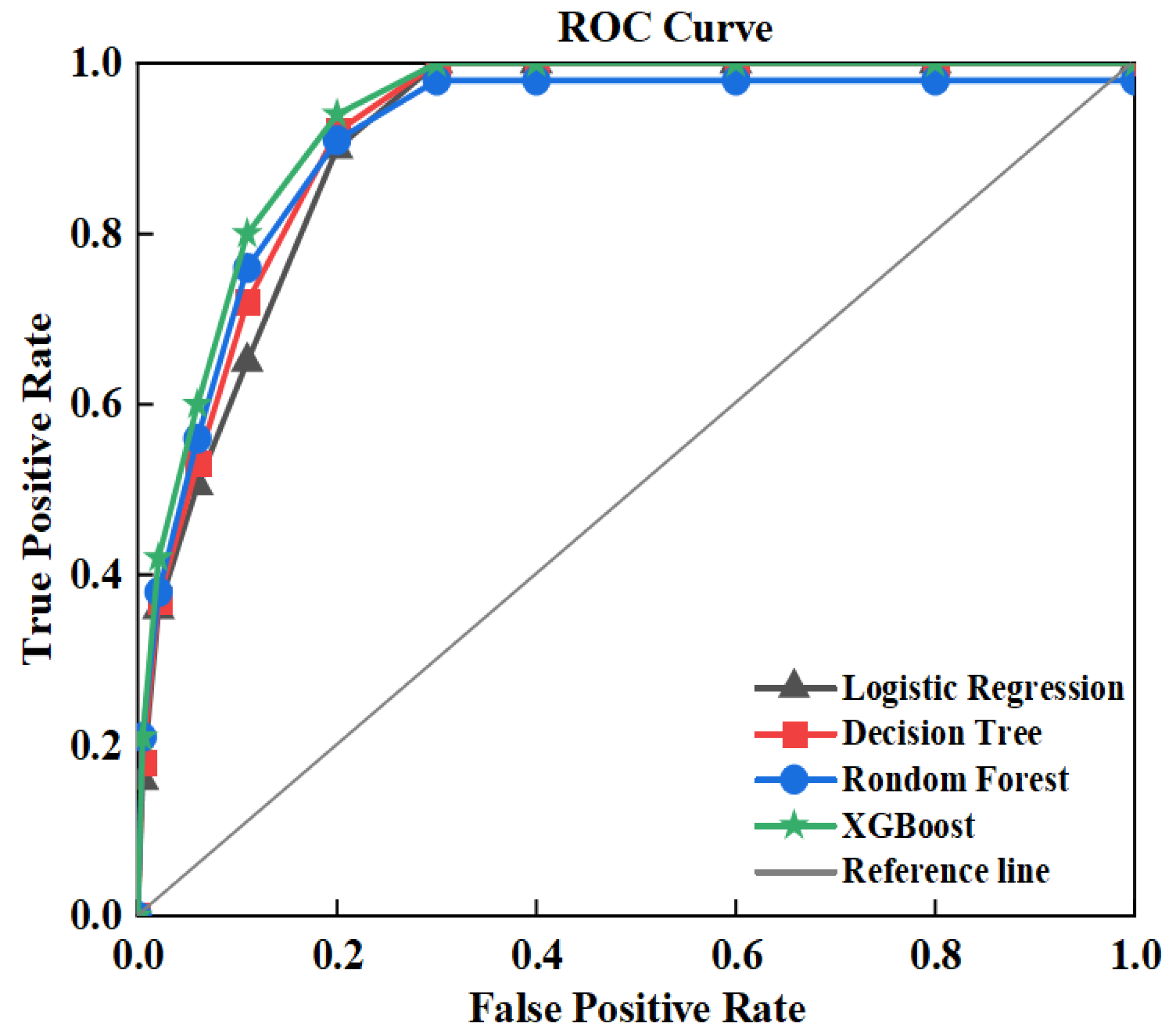
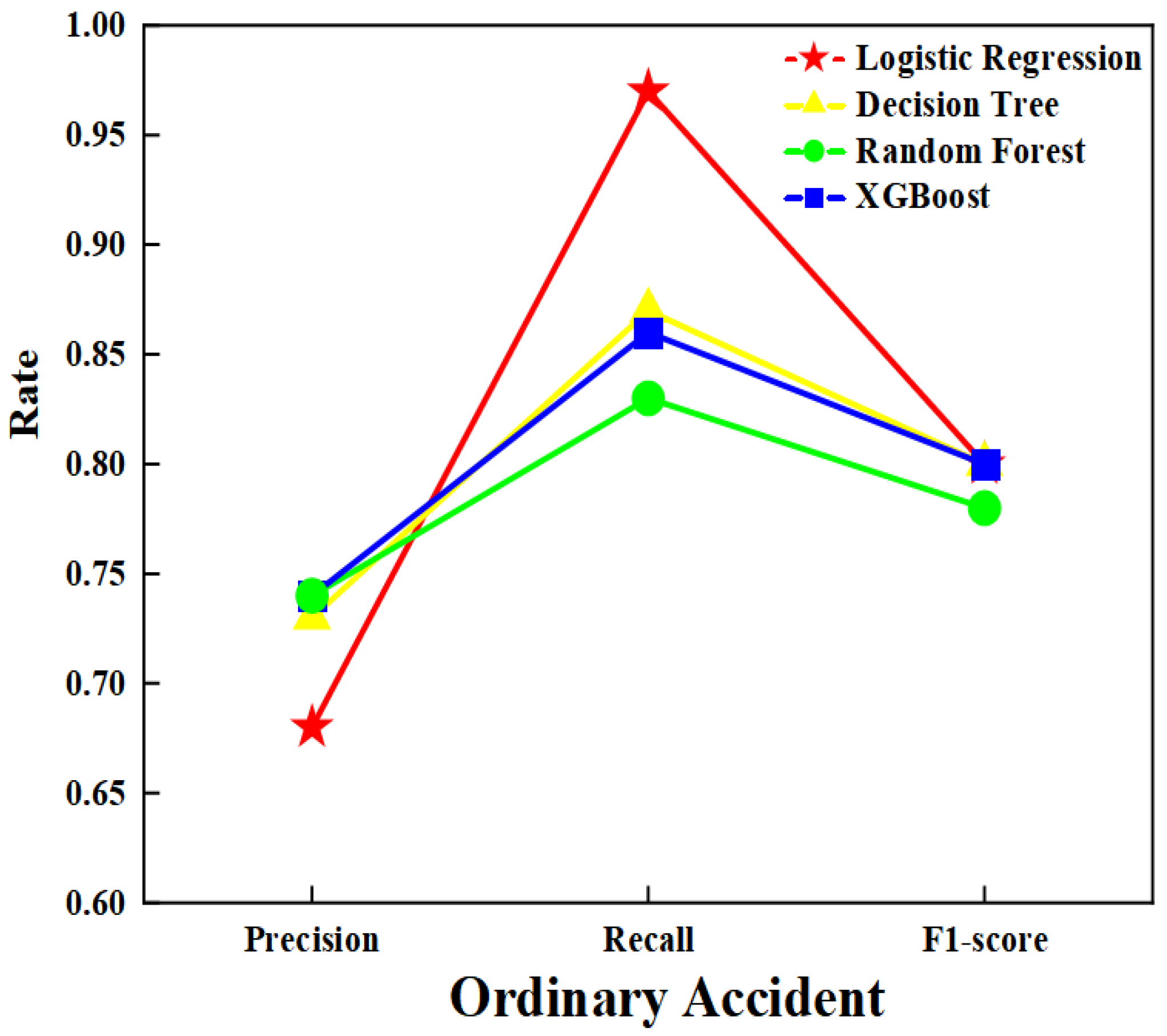
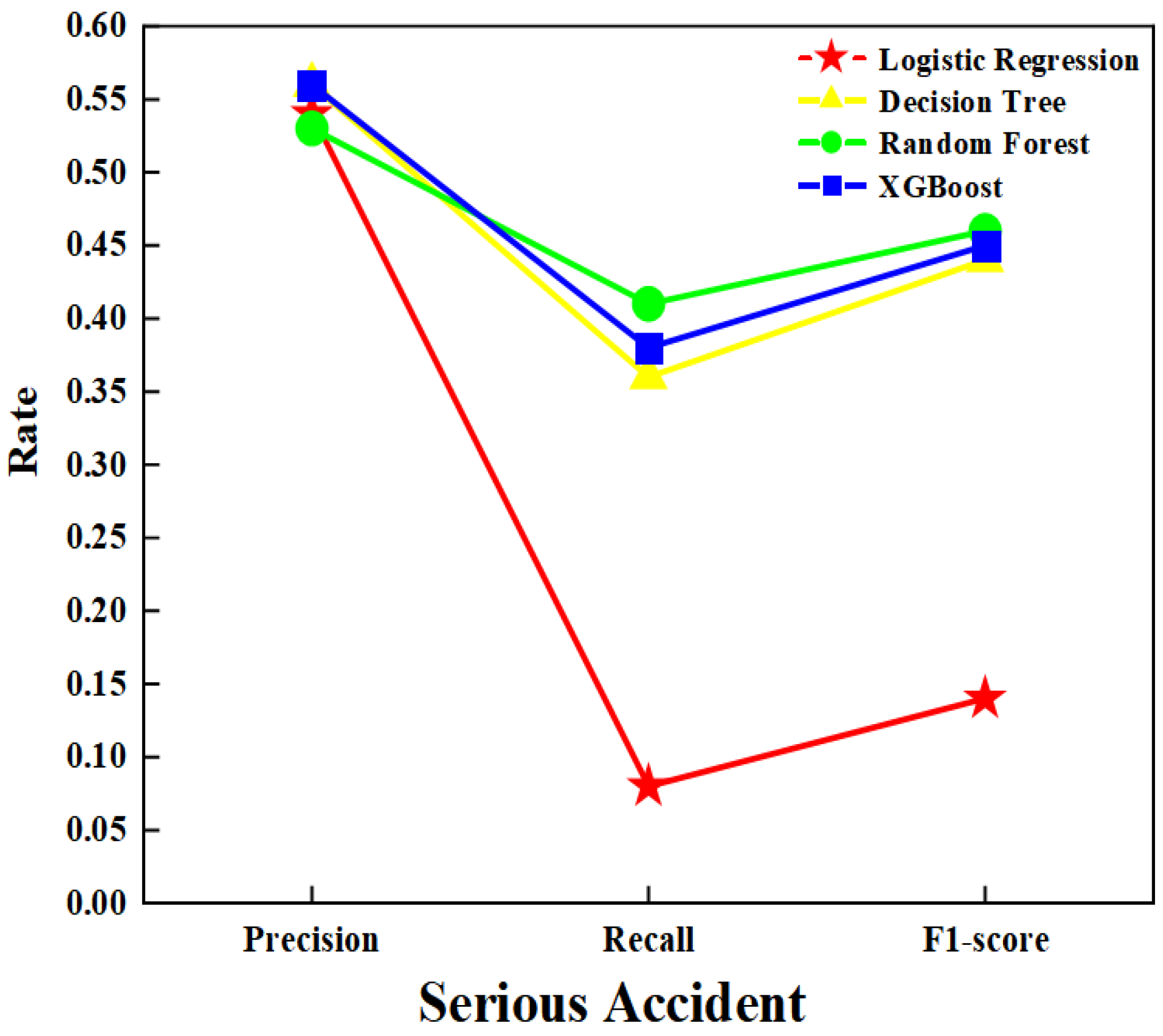
4.5.2. Model Construction and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. World Health Organization Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018.
- Soni, A.; Dharmacharya, D.; Pal, A.; Srivastava, V.K.; Shaw, R.N.; Ghosh, A. Design of a machine learning-based self-driving car. In Machine Learning for Robotics Applications; Springer: Berlin, Germany, 2021; pp. 139–151. [Google Scholar]
- Lee, J.; Huang, H.; Wang, J.; Quddus, M. Road safety under the environment of intelligent connected vehicles. Accid. Anal. Prev. 2022, 170, 106645. [Google Scholar] [CrossRef]
- Zou, X.; Vu, H.L.; Huang, H. Fifty years of accidents analysis & prevention: A bibliometric and scientometric overview. Accid. Anal. Prev. 2020, 144, 105568. [Google Scholar] [PubMed]
- Chen, H.; Zhang, L.; Ran, L. Vulnerability modeling and assessment in urban transit systems considering disaster chains: A weighted complex network approach. Int. J. Disaster Risk Reduct. 2021, 54, 102033. [Google Scholar] [CrossRef]
- Zhang, M.; Huang, T.; Guo, Z.; He, Z. Complex-network-based traffic network analysis and dynamics: A comprehensive review. Phys. A Stat. Mech. Appl. 2022, 607, 128063. [Google Scholar] [CrossRef]
- Zhang, W.; Xue, N.; Zhang, J.; Zhang, X. Identification of critical causal factors and paths of tower-crane accidents in China through system thinking and complex networks. J. Constr. Eng. Manag. 2021, 147, 04021174. [Google Scholar] [CrossRef]
- Qiu, Z.; Liu, Q.; Li, X.; Zhang, J.; Zhang, Y. Construction and analysis of a coal mine accidents causation network based on text mining. Process Saf. Environ. Prot. 2021, 153, 320–328. [Google Scholar] [CrossRef]
- Kopsidas, A.; Kepaptsoglou, K. Identification of critical stations in a Metro System: A substitute complex network analysis. Phys. A Stat. Mech. Appl. 2022, 596, 127123. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Y.; Wang, G.; Li, M.; Jia, L. Identification of the critical accidents causative factors in the urban rail transit system by complex network theory. Phys. A Stat. Mech. Appl. 2023, 610, 128404. [Google Scholar] [CrossRef]
- Sui, Z.; Wen, Y.; Huang, Y.; Zhou, C.; Du, L.; Piera, M.A. Node importance evaluation in marine traffic situation complex network for intelligent maritime supervision. Ocean Eng. 2022, 247, 110742. [Google Scholar] [CrossRef]
- Sheikh, M.S.; Regan, A. A complex network analysis approach for estimation and detection of traffic incidents based on independent component analysis. Phys. A Stat. Mech. Appl. 2022, 586, 126504. [Google Scholar] [CrossRef]
- Li, M.; Liu, R.-R.; Lü, L.; Hu, M.-B.; Xu, S.; Zhang, Y.-C. Percolation on complex networks: Theory and application. Phys. Rep. 2021, 907, 1–68. [Google Scholar] [CrossRef]
- Suo, Q.; Wang, L.; Yao, T.; Wang, Z. Promoting metro operation safety by exploring metro operation accidents network. J. Syst. Sci. Inf. 2021, 9, 455–468. [Google Scholar] [CrossRef]
- Yu, X.; Liu, K.; Montewka, J.; Yu, Q. Causal Analysis of Ship Accidents in China Coastal Waters Based on Complex Network Theory. In Proceedings of the 2021 6th International Conference on Transportation Information and Safety (ICTIS), Wuhan, China, 22–24 October 2021; pp. 1425–1431. [Google Scholar]
- Wu, B.; Lu, M.; Huang, W.; Lan, Y.; Wu, Y.; Huang, Z. A case study on the construction optimization decision scheme of urban subway tunnel based on the TOPSIS method. KSCE J. Civ. Eng. 2020, 24, 3488–3500. [Google Scholar] [CrossRef]
- Santos, K.; Dias, J.P.; Amado, C. A literature review of machine learning algorithms for crash injury severity prediction. J. Saf. Res. 2022, 80, 254–269. [Google Scholar] [CrossRef]
- Ijaz, M.; Zahid, M.; Jamal, A. A comparative study of machine learning classifiers for injury severity prediction of crashes involving three-wheeled motorized rickshaw. Accid. Anal. Prev. 2021, 154, 106094. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Wei, Z.; Ji, S. Analyzing the causation of public accidents caused by urban logistics based on complex network. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 50–55. [Google Scholar]
- Guo, M.; Yuan, Z.; Janson, B.; Peng, Y.; Yang, Y.; Wang, W. Older pedestrian traffic crashes severity analysis based on an emerging machine learning XGBoost. Sustainability 2021, 13, 926. [Google Scholar] [CrossRef]
- Hamim, O.F.; Hasanat-E-Rabbi, S.; Debnath, M.; Hoque, S.; McIlroy, R.C.; Plant, K.L.; Stanton, N.A. Taking a mixed-methods approach to collision investigation: AcciMap, STAMP-CAST and PCM. Appl. Ergon. 2022, 100, 103650. [Google Scholar] [CrossRef]
- Habibzadeh, M.; Ameri, M.; Ziari, H.; Kamboozia, N.; Haghighi, S.M.S. Presentation of Machine Learning Approaches for Predicting the Severity of Accidents to Propose the Safety Solutions on Rural Roads. J. Adv. Transp. 2022, 2022, 4857013. [Google Scholar] [CrossRef]
- Zhang, G.; Feng, W.; Lei, Y. Human factor analysis (HFA) based on a complex network and its application in gas explosion accidents. Int. J. Environ. Res. Public Health 2022, 19, 8400. [Google Scholar] [CrossRef]
- Guo, S.; Zhou, X.; Tang, B.; Gong, P. Exploring the behavioral risk chains of accidents using complex network theory in the construction industry. Phys. A Stat. Mech. Appl. 2020, 560, 125012. [Google Scholar] [CrossRef]
- Chen, Y.; Deng, Y. Traffic accidents risk factor identification based on complex network. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Beijing, China, 2021; Volume 719, p. 032074. [Google Scholar]
- Li, K.; Pan, Y. An effective method for identifying the key factors of railway accidents based on the network model. Int. J. Mod. Phys. B 2020, 34, 2050192. [Google Scholar] [CrossRef]
- Zhen, Z.; Zhang, Y.; Hu, M. Propagation Laws of Reclamation Risk in Tailings Ponds Using Complex Network Theory. Metals 2021, 11, 1789. [Google Scholar] [CrossRef]
- Liu, Y.; Wan, C.; Yu, Q.; Liu, G. Risk Evolution Analysis of Maritime Traffic Accidents in Coastal Areas of China. In Proceedings of the 2023 7th International Conference on Transportation Information and Safety (ICTIS), Xi’an, China, 4–6 August 2023; pp. 665–671. [Google Scholar]
- Zhao, H.; Cheng, H.; Mao, T.; He, C. Research on traffic accidents prediction model based on convolutional neural networks in VANET. In Proceedings of the 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 25–28 May 2019; pp. 79–84. [Google Scholar]
- Hu, S.; Li, Z.; Xi, Y.; Gu, X.; Zhang, X. Path analysis of causal factors influencing marine traffic accidents via structural equation numerical modeling. J. Mar. Sci. Eng. 2019, 7, 96. [Google Scholar] [CrossRef]
- Lin, L.; Wang, Q.; Sadek, A.W. Data mining and complex network algorithms for traffic accidents analysis. Transp. Res. Rec. 2014, 2460, 128–136. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, X.; Yuan, M.; Zhang, Z. Complex Network Analysis of China National Standards for New Energy Vehicles. Sustainability 2023, 15, 1155. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Z.; Peng, F. Causality-network-based critical hazard identification for railway accidents prevention: Complex network-based model development and comparison. Entropy 2021, 23, 864. [Google Scholar] [CrossRef]
- Yang, J.F.; Wang, P.C.; Liu, X.Y.; Bian, M.C.; Chen, L.C.; Lv, S.Y.; Tao, J.F.; Suo, G.Y.; Xuan, S.Q.; Li, R.; et al. Analysis on causes of chemical industry accidents from 2015 to 2020 in Chinese mainland: A complex network theory approach. J. Loss Prev. Process Ind. 2023, 83, 105061. [Google Scholar] [CrossRef]
- Duan, P.; Zhou, J. Cascading vulnerability analysis of unsafe behaviors of construction workers from the perspective of network modeling. Eng. Constr. Archit. Manag. 2023, 30, 1037–1060. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.; Jia, L.; Cui, Y. Risk propagation analysis of urban rail transit based on network model. Alex. Eng. J. 2020, 59, 1319–1331. [Google Scholar] [CrossRef]
- Lu, D.; Yang, S. A survey of the analysis of complex systems based on complex network theory and deep learning. Int. J. Perform. Eng. 2022, 18, 241. [Google Scholar]
- Moosavi, S.; Samavatian, M.H.; Parthasarathy, S.; Ramnath, R. A countrywide traffic accidents dataset. arXiv 2019, arXiv:1906.05409. [Google Scholar]
- Moosavi, S.; Samavatian, M.H.; Parthasarathy, S.; Teodorescu, R.; Ramnath, R. Accidents risk prediction based on heterogeneous sparse data: New dataset and insights. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 33–42. [Google Scholar]
- Wang, J.S. KABCO-to-MAIS Translators-2022 Update; NHTSA: Fort Worth, TX, USA, 2023.
- Liu, Z.; Zhou, J.; Reniers, G. Association analysis of accidents factors in petrochemical storage tank farms. J. Loss Prev. Process Ind. 2023, 84, 105124. [Google Scholar] [CrossRef]
- Mi, X.; Shao, C.; Dong, C.; Zhuge, C.; Zheng, Y. A framework for intersection traffic safety screening with the implementation of complex network theory. J. Adv. Transp. 2020, 2020, 8824447. [Google Scholar] [CrossRef]
- Zhou, C.; Kong, T.; Jiang, S.; Chen, S.; Zhou, Y.; Ding, L. Quantifying the evolution of settlement risk for surrounding environments in underground construction via complex network analysis. Tunn. Undergr. Space Technol. 2020, 103, 103490. [Google Scholar] [CrossRef]
- Feng, J.R.; Zhao, M.; Yu, G.; Zhang, J.; Lu, S. Dynamic risk analysis of accidents chain and system protection strategy based on complex network and node structure importance. Reliab. Eng. Syst. Saf. 2023, 238, 109413. [Google Scholar] [CrossRef]
- Jamal, A.; Zahid, M.; Rahman, M.T.; Al-Ahmadi, H.M.; Almoshaogeh, M.; Farooq, D.; Ahmad, M. Injury severity prediction of traffic crashes with ensemble machine learning techniques: A comparative study. Int. J. Inj. Control. Saf. Promot. 2021, 28, 408–427. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Evaluation Index | Specific Description |
|---|---|
| Degree of node (D) | Indicates the number of edges by which a node connects to other nodes. |
| Network diameter (S) | Represents the maximum distance between any two nodes. |
| Average path length (L) | Represents the average length of the shortest path between all node pairs. |
| Clustering coefficient (C) | Indicates the degree of aggregation of the node in the network |
| Intermediary centrality (B) | Indicates the adjustment ability and transfer function of the node between other nodes. |
| Closeness centrality (M) | Indicates the proximity of the node to other nodes |
| Comprehensive importance evaluation (O) | Indicates the comprehensive importance of nodes from a global perspective |
| Factor Categories | Numbering | Influencing Factors |
|---|---|---|
| Time factor | The accidents happened at daytime | |
| The accidents happened at night | ||
| The accidents happened on Monday | ||
| The accidents happened on Tuesday | ||
| The accidents happened on Wednesday | ||
| The accidents happened on Thursday | ||
| The accidents happened on Friday | ||
| The accidents happened on Saturday | ||
| The accidents happened on Sunday | ||
| The accidents happened in spring | ||
| The accidents happened in summer | ||
| The accidents happened in autumn | ||
| The accidents happened in winter | ||
| Environmental factor | The length of the road affected by the accidents was shorter | |
| The length of the road affected by the accidents was longer | ||
| The accidents occurred on the left side of the road | ||
| The accidents occurred on the right side of the road | ||
| The environmental temperature during the accidents was low temperature | ||
| The environmental temperature during the accidents was moderate temperature | ||
| The environmental temperature during the accidents was high temperature | ||
| The environmental humidity during the accidents was dry | ||
| The environmental humidity during the accidents was humid | ||
| The environmental humidity during the accidents was wetter | ||
| The visibility of the display during the accidents was generally clear | ||
| The visibility of the display during the accidents was relatively clear | ||
| clear sky | ||
| cloudy | ||
| foggy sky | ||
| rainy day | ||
| snowy day | ||
| sandstorm | ||
| hailstone | ||
| Other weather | ||
| Traffic management factors | There was an intersection near the accidents | |
| There was no intersection near the accidents | ||
| There was a reducer belt near the accidents | ||
| There was no reducer belt near the accidents | ||
| There was a deceleration sign near the accidents | ||
| There was no deceleration sign near the accidents | ||
| There was a railway near the accidents | ||
| There was no railway near the accidents | ||
| There was a road safety measure near the accidents | ||
| There was no road safety measure near the accidents | ||
| There was a station near the accidents | ||
| There was no station near the accidents | ||
| There was a stop sign near the accidents. | ||
| There was no stop sign near the accidents |
| Numbering | Severity of Injuries |
|---|---|
| Ordinary accidents | |
| Serious accidents | |
| Major accidents |
| Model | Specific Configuration | Model | Specific Configuration | ||
|---|---|---|---|---|---|
| Logistic Regression (LR) | Regularization type | L2 | Random Forest (RF) | Number of trees | 100 |
| Regularization intensity | 1 | Node splitting rules | Gini | ||
| Maximum number of iterations | 100 | Minimum number of samples for leaf nodes | 1 | ||
| Iteration termination error range | 0.001 | Minimum number of samples contained in internal nodes | 2 | ||
| Optimizer | Ibfgs | ||||
| Decision Tree (DT) | Maximum depth | 8 | Extreme Gradient Boosting (XGBoost) | Evaluating indicator | Mlogloss |
| Minimum number of samples for leaf nodes | 1 | Learning rate | 0.3 | ||
| Minimum number of samples contained in internal nodes | 2 | Maximum depth | 6 | ||
| Node splitting rules | Information entropy | Sampling ratio | 1 | ||
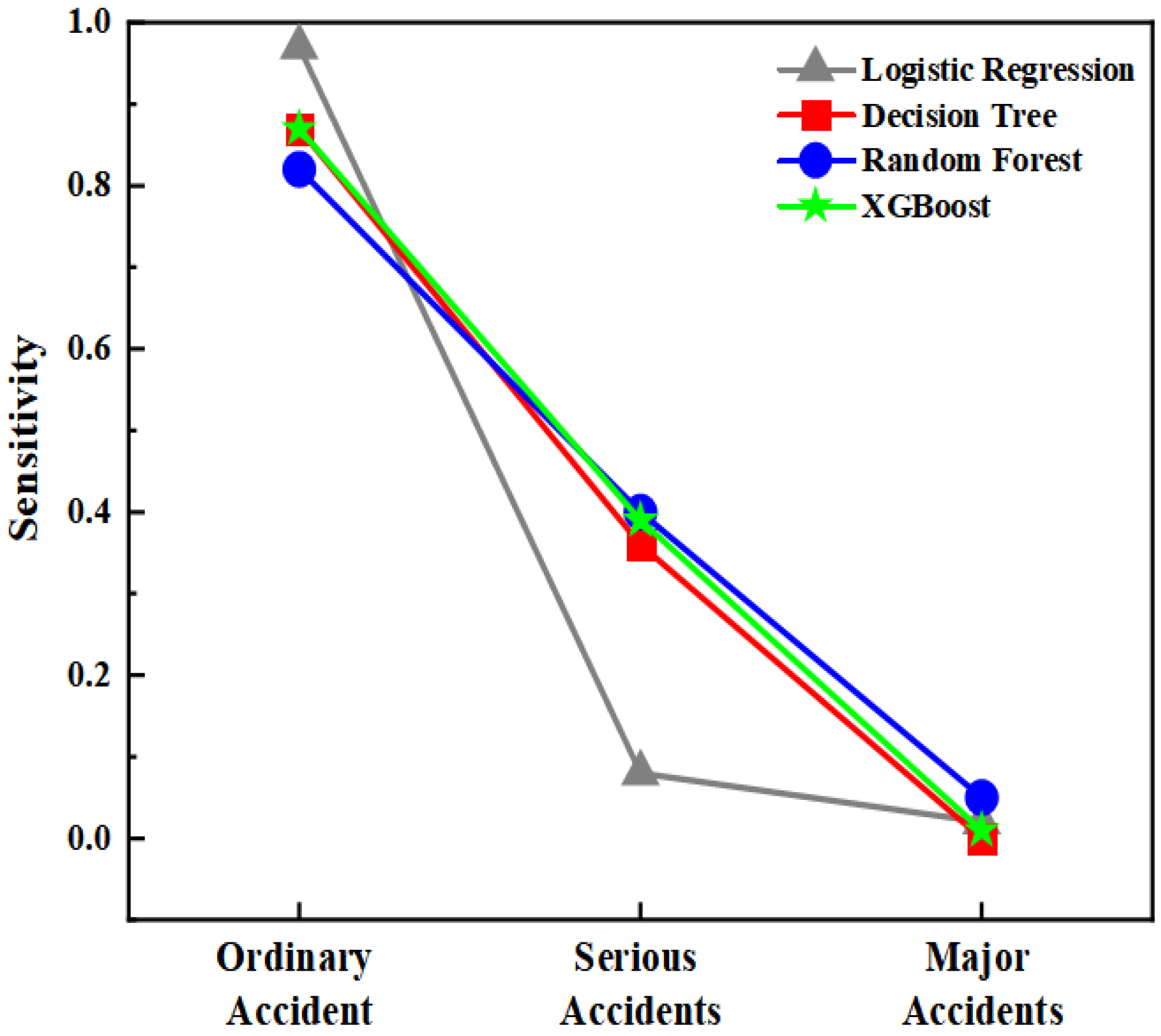
| Method Model | Evaluating Indicator | Ordinary Accidents | Serious Accidents | Major Accidents |
|---|---|---|---|---|
| Logistic Regression (LR) | Precision | 0.68 | 0.54 | 0.13 |
| Recall | 0.97 | 0.08 | 0.02 | |
| F1-score | 0.80 | 0.14 | 0.04 | |
| Decision Tree (DT) | Precision | 0.73 | 0.56 | 0.12 |
| Recall | 0.87 | 0.36 | 0.00 | |
| F1-score | 0.80 | 0.44 | 0.00 | |
| Random Forest (RF) | Precision | 0.74 | 0.53 | 0.19 |
| Recall | 0.83 | 0.41 | 0.05 | |
| F1-score | 0.78 | 0.46 | 0.07 | |
| Extreme Gradient Boosting (XGBoost) | Precision | 0.74 | 0.56 | 0.25 |
| Recall | 0.86 | 0.38 | 0.01 | |
| F1-score | 0.80 | 0.45 | 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhai, H.; Cao, X.; Geng, X. Cause Analysis and Accident Classification of Road Traffic Accidents Based on Complex Networks. Appl. Sci. 2023, 13, 12963. https://doi.org/10.3390/app132312963
Wang Y, Zhai H, Cao X, Geng X. Cause Analysis and Accident Classification of Road Traffic Accidents Based on Complex Networks. Applied Sciences. 2023; 13(23):12963. https://doi.org/10.3390/app132312963
Chicago/Turabian StyleWang, Yongdong, Haonan Zhai, Xianghong Cao, and Xin Geng. 2023. "Cause Analysis and Accident Classification of Road Traffic Accidents Based on Complex Networks" Applied Sciences 13, no. 23: 12963. https://doi.org/10.3390/app132312963
APA StyleWang, Y., Zhai, H., Cao, X., & Geng, X. (2023). Cause Analysis and Accident Classification of Road Traffic Accidents Based on Complex Networks. Applied Sciences, 13(23), 12963. https://doi.org/10.3390/app132312963