
Prompt Language Learner with Trigger Generation for Dialogue Relation Extraction


Abstract
:1. Introduction
2. Related Works
2.1. Dialogue-Based Relation Extraction
2.2. Prompt-Based Learning
2.3. Trigger Generation
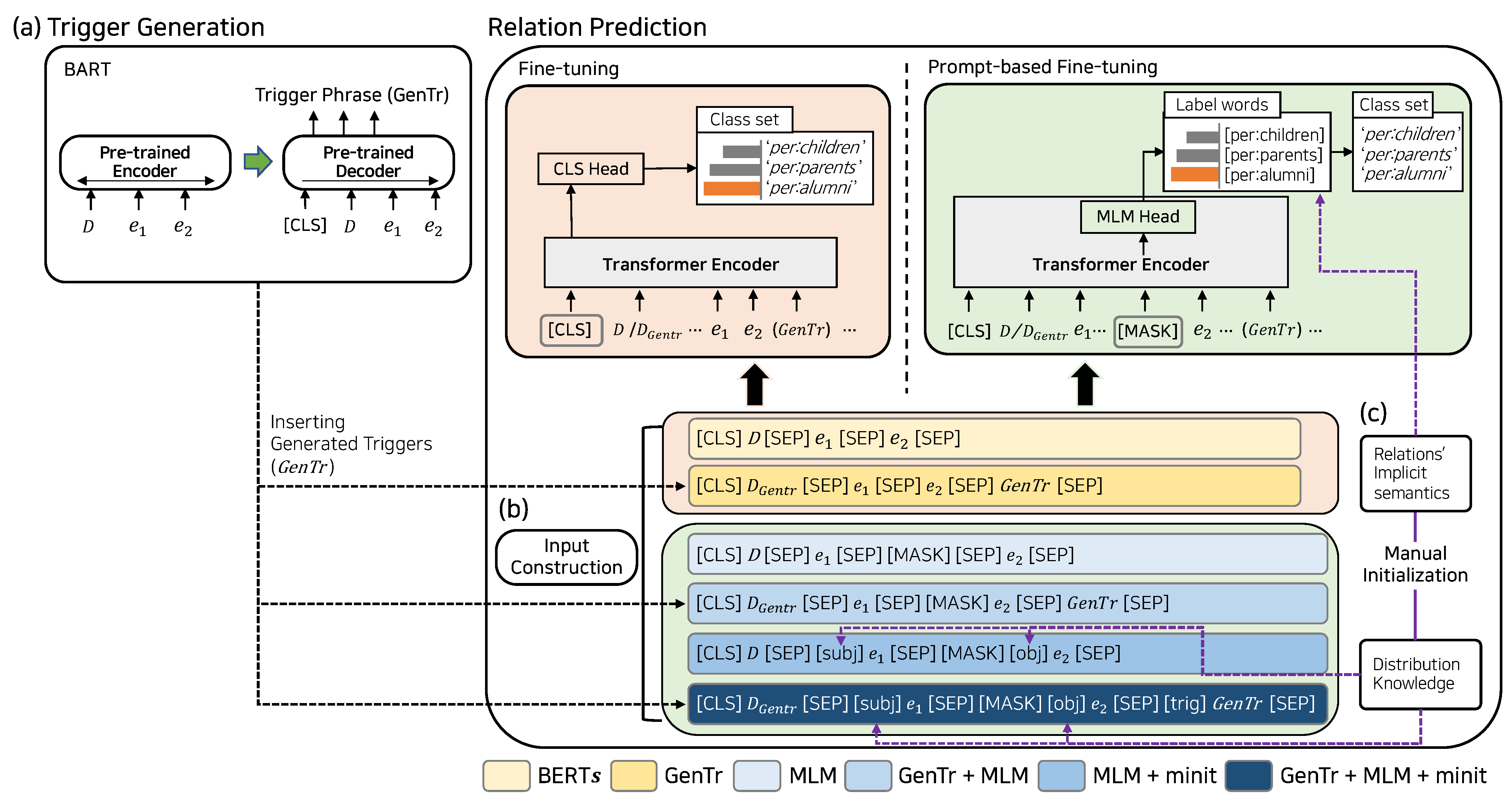
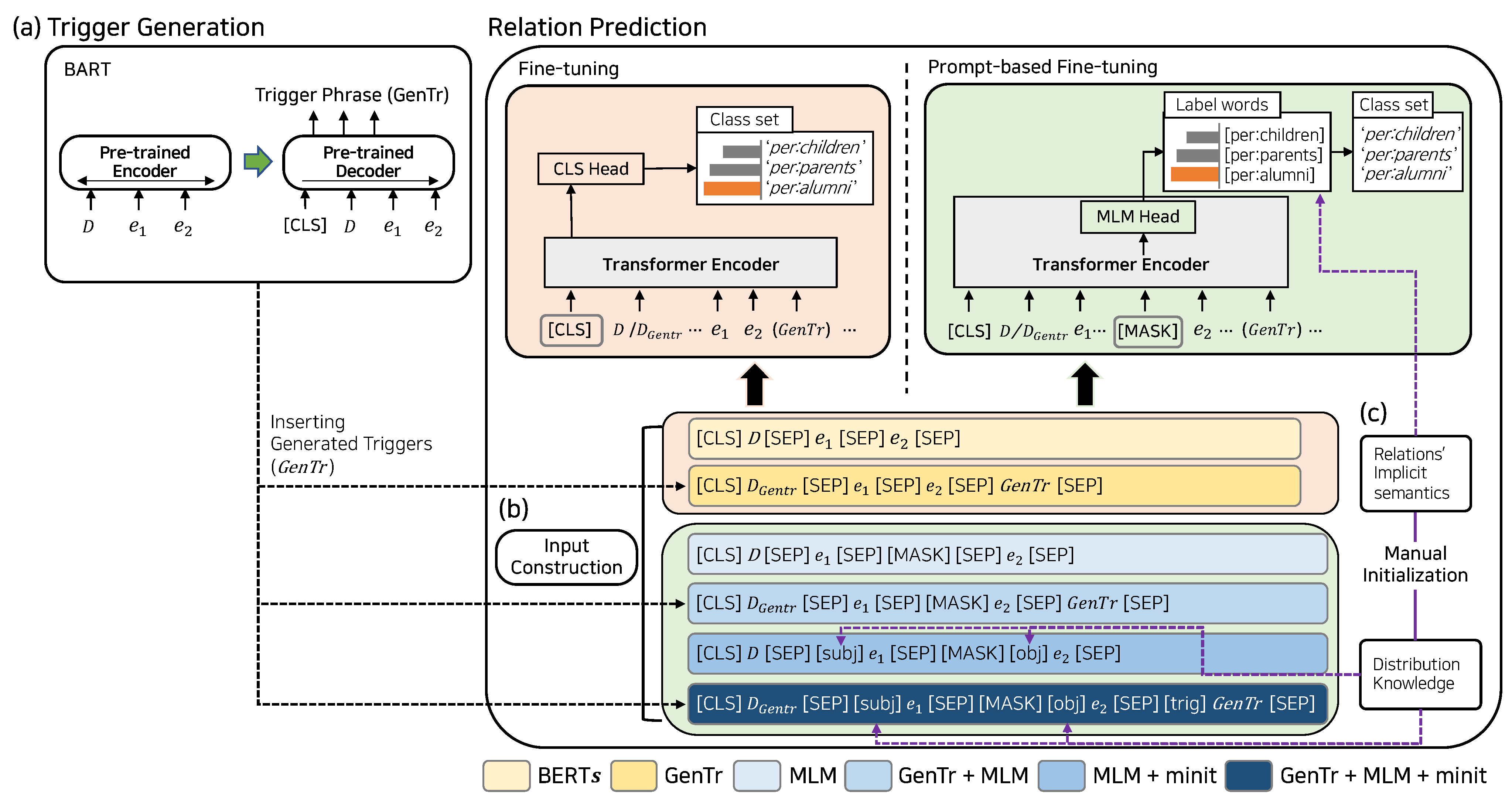
3. Materials and Method
3.1. Prompt Language Learner with Trigger Generation
3.2. Trigger Generation
3.3. Input Construction
3.4. Prompt Manual Initialization
4. Experiments
4.1. Experimental Setup
4.2. Experimental Results
4.2.1. Full-Shot Setting
4.2.2. Few-Shot Setting
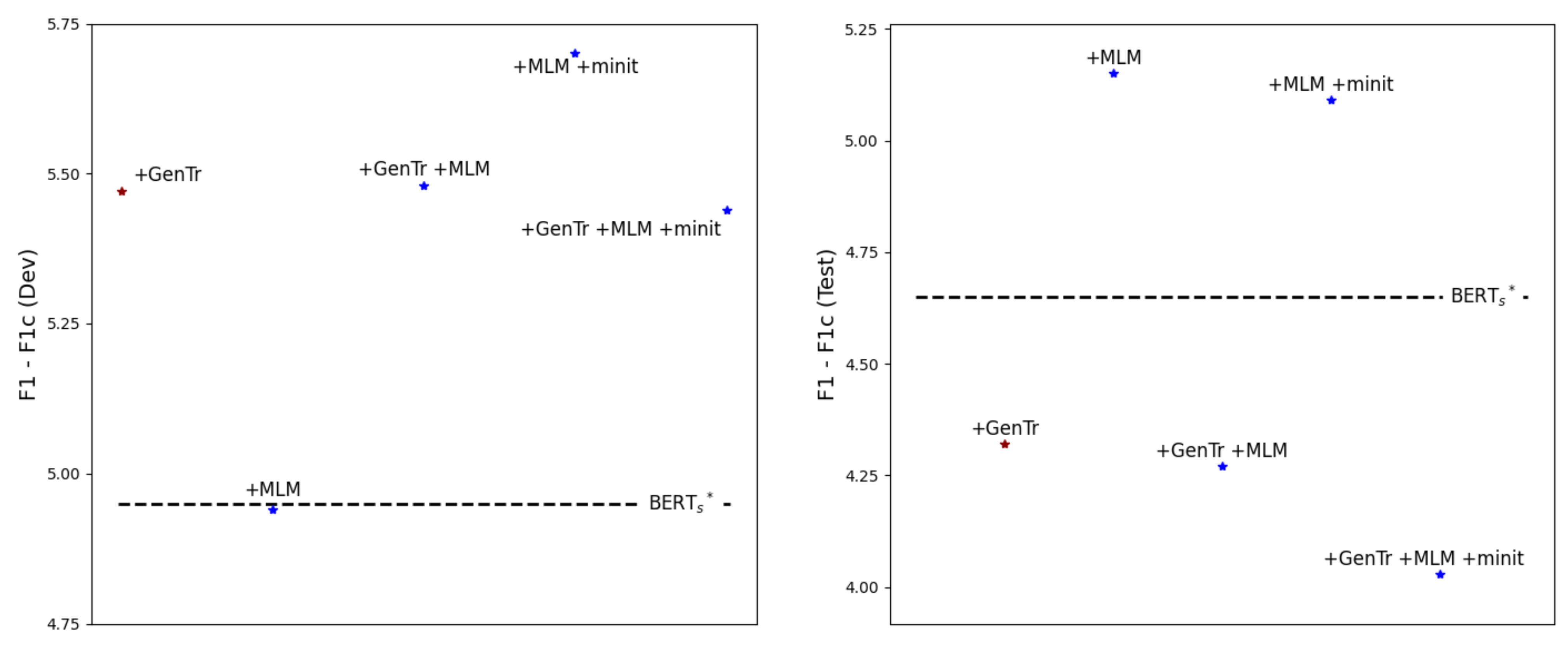
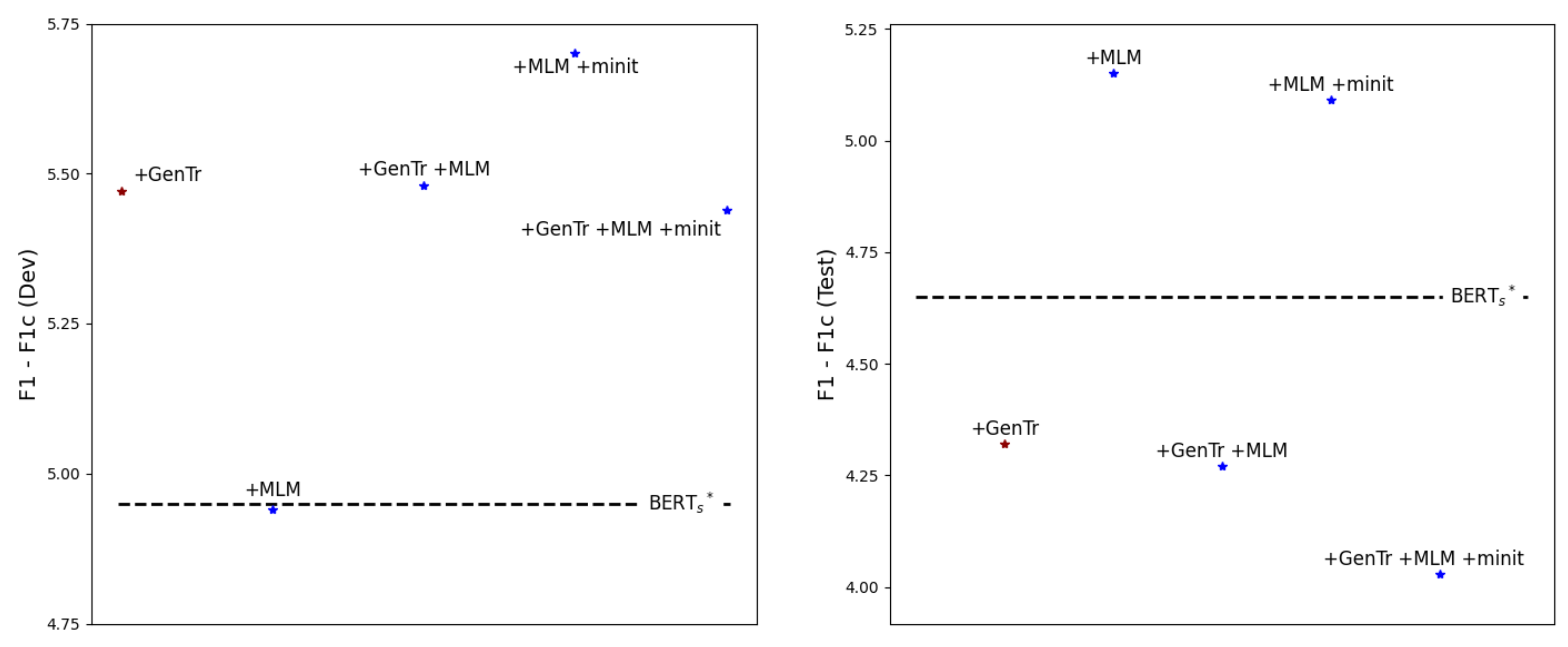
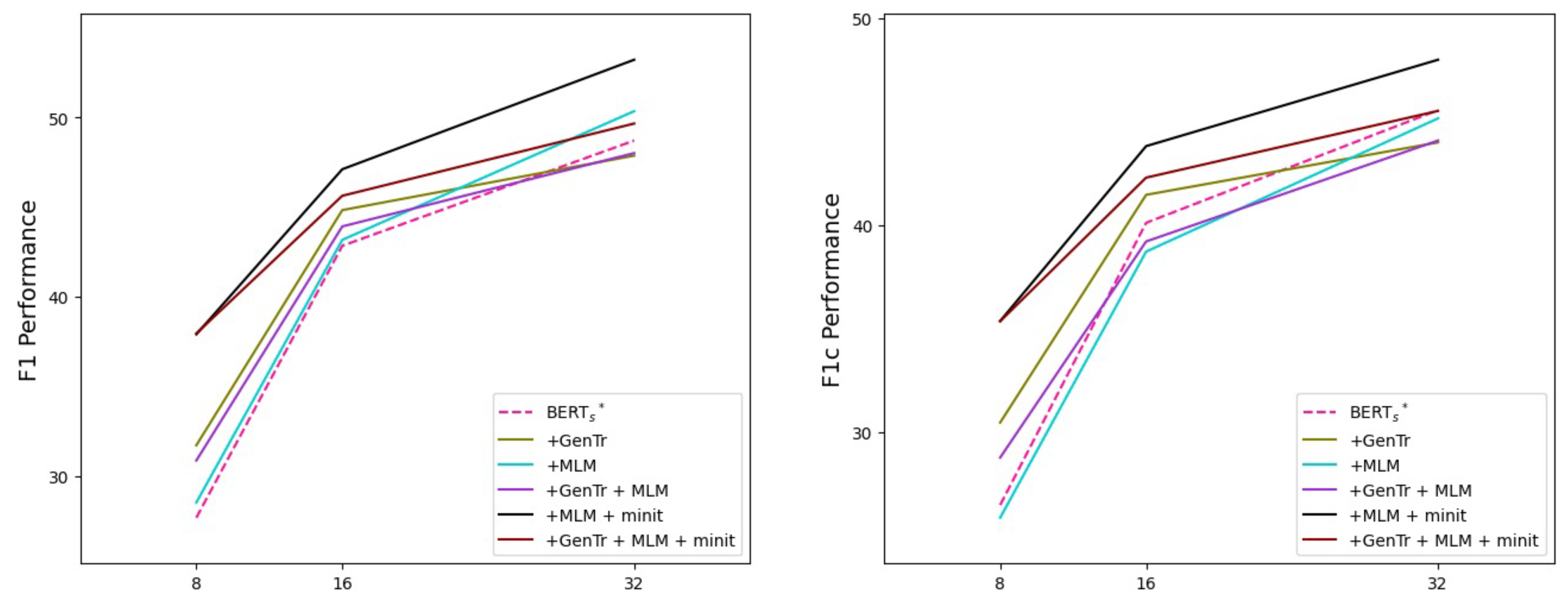
5. Discussion
5.1. Learning Distributional Knowledge with Prompt Manual Initialization Is Advantageous
5.2. Generated Triggers Are Apt to Be Practical When Given a Small Number of Examples
5.3. A Critical Point Is How Appropriate Triggers Are Generated
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ji, H.; Grishman, R.; Dang, H.T.; Griffitt, K.; Ellis, J. Overview of the TAC 2010 knowledge base population track. In Proceedings of the Third Text Analysis Conference (TAC 2010), Gaithersburg, MD, USA, 15–16 November 2010; Volume 3, p. 3. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic Compositionality through Recursive Matrix-Vector Spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Swampillai, K.; Stevenson, M. Inter-sentential relations in information extraction corpora. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Peng, N.; Poon, H.; Quirk, C.; Toutanova, K.; Yih, W.t. Cross-Sentence N-ary Relation Extraction with Graph LSTMs. Trans. Assoc. Comput. Linguist. 2017, 5, 101–115. [Google Scholar] [CrossRef]
- Han, X.; Wang, L. A Novel Document-Level Relation Extraction Method Based on BERT and Entity Information. IEEE Access 2020, 8, 96912–96919. [Google Scholar] [CrossRef]
- Jia, Q.; Huang, H.; Zhu, K.Q. DDRel: A New Dataset for Interpersonal Relation Classification in Dyadic Dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13125–13133. [CrossRef]
- Yu, D.; Sun, K.; Cardie, C.; Yu, D. Dialogue-Based Relation Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4927–4940. [Google Scholar] [CrossRef]
- Han, X.; Zhao, W.; Ding, N.; Liu, Z.; Sun, M. Ptr: Prompt tuning with rules for text classification. AI Open 2022, 3, 182–192. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 3816–3830. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Hur, Y.; Son, S.; Shim, M.; Lim, J.; Lim, H. K-EPIC: Entity-Perceived Context Representation in Korean Relation Extraction. Appl. Sci. 2021, 11, 11472. [Google Scholar] [CrossRef]
- Qin, P.; Xu, W.; Wang, W.Y. Dsgan: Generative adversarial training for distant supervision relation extraction. arXiv 2018, arXiv:1805.09929. [Google Scholar]
- Ji, F.; Qiu, X.; Huang, X.J. Detecting hedge cues and their scopes with average perceptron. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning–Shared Task, Uppsala, Sweden, 15–16 July 2010; pp. 32–39. [Google Scholar]
- Zapirain, B.; Agirre, E.; Marquez, L.; Surdeanu, M. Selectional preferences for semantic role classification. Comput. Linguist. 2013, 39, 631–663. [Google Scholar] [CrossRef]
- Elsahar, H.; Vougiouklis, P.; Remaci, A.; Gravier, C.; Hare, J.; Laforest, F.; Simperl, E. T-rex: A large scale alignment of natural language with knowledge base triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A large-scale document-level relation extraction dataset. arXiv 2019, arXiv:1906.06127. [Google Scholar]
- Mesquita, F.; Cannaviccio, M.; Schmidek, J.; Mirza, P.; Barbosa, D. Knowledgenet: A benchmark dataset for knowledge base population. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 749–758. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Xue, F.; Sun, A.; Zhang, H.; Chng, E.S. Gdpnet: Refining latent multi-view graph for relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 14194–14202. [Google Scholar]
- Long, X.; Niu, S.; Li, Y. Consistent Inference for Dialogue Relation Extraction. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, Canada, 19–27 August 2021; Zhou, Z.H., Ed.; pp. 3885–3891. [Google Scholar] [CrossRef]
- Lee, B.; Choi, Y.S. Graph Based Network with Contextualized Representations of Turns in Dialogue. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 443–455. [Google Scholar] [CrossRef]
- Chen, H.; Hong, P.; Han, W.; Majumder, N.; Poria, S. Dialogue relation extraction with document-level heterogeneous graph attention networks. Cogn. Comput. 2023, 15, 793–802. [Google Scholar] [CrossRef]
- Duan, G.; Dong, Y.; Miao, J.; Huang, T. Position-Aware Attention Mechanism–Based Bi-graph for Dialogue Relation Extraction. Cogn. Comput. 2023, 15, 359–372. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, J.; Zhang, H.; Xue, F.; You, Y. Hierarchical Dialogue Understanding with Special Tokens and Turn-level Attention. arXiv 2023, arXiv:2305.00262. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting cloze questions for few shot text classification and natural language inference. arXiv 2020, arXiv:2001.07676. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 61–68. [Google Scholar]
- Zhang, S.; Khan, S.; Shen, Z.; Naseer, M.; Chen, G.; Khan, F.S. Promptcal: Contrastive affinity learning via auxiliary prompts for generalized novel category discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 8–22 June 2023; pp. 3479–3488. [Google Scholar]
- He, K.; Mao, R.; Huang, Y.; Gong, T.; Li, C.; Cambria, E. Template-Free Prompting for Few-Shot Named Entity Recognition via Semantic-Enhanced Contrastive Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Liu, D.; Lei, W.; Yang, B.; Xue, M.; Chen, B.; Xie, J. Tailor: A soft-prompt-based approach to attribute-based controlled text generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 9–14 July 2023; pp. 410–427. [Google Scholar]
- Kumar, S.; Talukdar, P. NILE: Natural Language Inference with Faithful Natural Language Explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8730–8742. [Google Scholar] [CrossRef]
- Liu, H.; Yin, Q.; Wang, W.Y. Towards Explainable NLP: A Generative Explanation Framework for Text Classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5570–5581. [Google Scholar] [CrossRef]
- Ormandi, R.; Saleh, M.; Winter, E.; Rao, V. Webred: Effective pretraining and finetuning for relation extraction on the web. arXiv 2021, arXiv:2102.09681. [Google Scholar]
- Lin, P.W.; Su, S.Y.; Chen, Y.N. TREND: Trigger-Enhanced Relation-Extraction Network for Dialogues. arXiv 2021, arXiv:2108.13811. [Google Scholar]
- An, H.; Chen, D.; Xu, W.; Zhu, Z.; Zou, Y. TLAG: An Informative Trigger and Label-Aware Knowledge Guided Model for Dialogue-based Relation Extraction. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; IEEE: New York, NY, USA, 2023; pp. 59–64. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Son, J.; Kim, J.; Lim, J.; Lim, H. GRASP: Guiding model with RelAtional Semantics using Prompt. arXiv 2022, arXiv:2208.12494. [Google Scholar]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. KnowPrompt: Knowledge-Aware Prompt-Tuning with Synergistic Optimization for Relation Extraction. In Proceedings of the WWW ’22: ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 2778–2788. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Dialogue | |||
|---|---|---|---|
| |||
| Argument pair | Trigger | Relation Type | |
| R1 | (Speaker 3, Speaker 2) | mom | per:parents |
| R2 | (Speaker 1, Speaker 3) | dad | per:children |
| R3 | (Speaker 1, Speaker 2) | none | per:spouse |
| R4 | (Speaker 1, Jack) | none | per:alternate_names |
| Full-Shot Setting | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Dev | Test | ||||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT * | 61.14 | 62.50 | 61.81 | 63.84 | 51.27 | 56.86 | 59.46 | 60.58 | 59.94 | 63.33 | 49.09 | 55.29 |
| + | 62.91 | 63.24 | 63.07 | 65.00 | 51.72 | 57.60 | 59.00 | 60.68 | 59.80 | 63.20 | 49.45 | 55.48 |
| + | 62.88 | 64.20 | 63.52 | 65.59 | 52.94 | 58.58 | 62.27 | 62.29 | 62.27 | 65.43 | 50.69 | 57.12 |
| + + | 65.09 | 64.76 | 64.92 | 67.07 | 53.38 | 59.44 | 61.13 | 60.95 | 61.03 | 65.42 | 50.13 | 56.76 |
| + +minit | 65.47 | 66.81 | 66.13 | 67.94 | 54.43 | 60.43 | 64.00 | 63.44 | 63.69 | 67.04 | 52.05 | 58.60 |
| + + +minit | 64.92 | 66.35 | 65.62 | 67.98 | 53.99 | 60.18 | 61.18 | 62.67 | 61.90 | 67.19 | 50.86 | 57.87 |
| Few-Shot Setting | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Dev | Test | ||||||||||
| K = 8 | K = 16 | K = 32 | K = 8 | K = 16 | K = 32 | |||||||
| F1 | F1 | F1 | F1 | F1 | F1 | F1 | F1 | F1 | F1 | F1 | F1 | |
| BERT * | 27.56 | 26.30 | 41.49 | 38.61 | 47.87 | 44.17 | 27.67 | 26.49 | 42.84 | 40.11 | 48.71 | 45.55 |
| + | 33.71 | 32.22 | 46.26 | 42.47 | 49.86 | 45.25 | 31.71 | 30.47 | 44.83 | 41.46 | 47.87 | 43.99 |
| + | 28.41 | 25.67 | 39.48 | 35.79 | 48.25 | 43.49 | 28.52 | 25.88 | 43.17 | 38.72 | 50.35 | 45.15 |
| + + MLM | 32.95 | 30.43 | 45.76 | 41.27 | 51.03 | 46.46 | 30.86 | 28.78 | 43.92 | 39.21 | 48.01 | 44.08 |
| + + minit | 39.60 | 37.23 | 48.27 | 44.59 | 53.20 | 48.20 | 37.90 | 35.37 | 47.11 | 43.81 | 53.22 | 47.98 |
| + + + minit | 38.97 | 36.43 | 46.48 | 43.25 | 51.16 | 46.65 | 37.95 | 35.36 | 45.63 | 42.29 | 49.66 | 45.51 |
| Full-Shot Setting | ||||
|---|---|---|---|---|
| Method | Dev | Test | ||
| F1 | F1 | F1 | F1 | |
| BERT * | 61.81 | 56.86 | 59.94 | 55.29 |
| + (T5) | 63.07 (+1.26) | 57.60 (+0.74) | 59.80 (−0.14) | 55.48 (+0.19) |
| + (BART) | 62.58 (+0.77) | 57.07 (+0.21) | 60.16 (+0.22) | 55.83 (+0.54) |
| + (w/rel) | 75.21 (+13.4) | 67.47 (+10.61) | 73.36 (+13.42) | 65.63 (+10.34) |
| Few-Shot Setting | ||||||
|---|---|---|---|---|---|---|
| Method | Shot | |||||
| K = 8 | K = 16 | K = 32 | ||||
| F1 | F1 | F1 | F1 | F1 | F1 | |
| BERT* | 27.67 | 26.49 | 42.84 | 40.11 | 48.71 | 45.55 |
| + (T5) | 31.71 (+4.04) | 30.47 (+3.98) | 44.83 (+1.99) | 41.46 (+1.35) | 47.87 (+0.84) | 43.99 (−1.56) |
| + (BART) | 28.69 (+1.02) | 29.54 (+3.05) | 43.64 (+0.80) | 40.94 (+0.83) | 48.73 (+0.02) | 45.07 (−0.48) |
| Dialogue | ||||||
|---|---|---|---|---|---|---|
| ||||||
| Argument pair | GT Trigger | Generated Triggers | Relation Type | |||
| (T5) | (BART) | (w/rel) | ||||
| R1 | (Speaker 1, Speaker 4) | boyfriend | boyfriend | boyfriend | boyfriend | per:girl/boyfriend |
| R2 | (Speaker 4, Mike) | love | boyfriend | boyfriend | love | per:positive_impression |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Kim, G.; Son, J.; Lim, H. Prompt Language Learner with Trigger Generation for Dialogue Relation Extraction. Appl. Sci. 2023, 13, 12414. https://doi.org/10.3390/app132212414
Kim J, Kim G, Son J, Lim H. Prompt Language Learner with Trigger Generation for Dialogue Relation Extraction. Applied Sciences. 2023; 13(22):12414. https://doi.org/10.3390/app132212414
Chicago/Turabian StyleKim, Jinsung, Gyeongmin Kim, Junyoung Son, and Heuiseok Lim. 2023. "Prompt Language Learner with Trigger Generation for Dialogue Relation Extraction" Applied Sciences 13, no. 22: 12414. https://doi.org/10.3390/app132212414
APA StyleKim, J., Kim, G., Son, J., & Lim, H. (2023). Prompt Language Learner with Trigger Generation for Dialogue Relation Extraction. Applied Sciences, 13(22), 12414. https://doi.org/10.3390/app132212414