
Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review


Abstract
:1. Introduction
2. Background
2.1. Natural Language Processing
2.2. Natural Language Processing in Governments
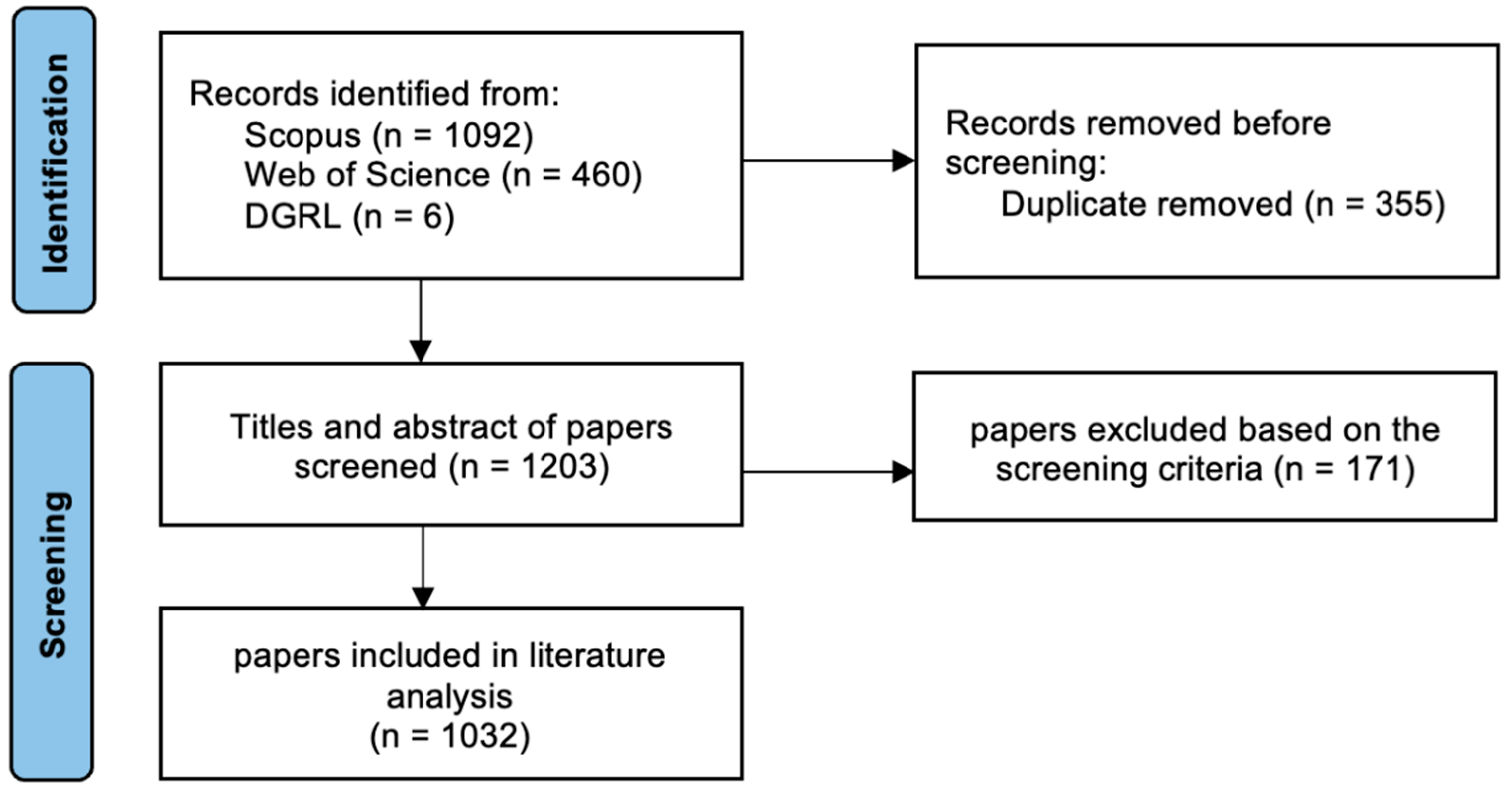
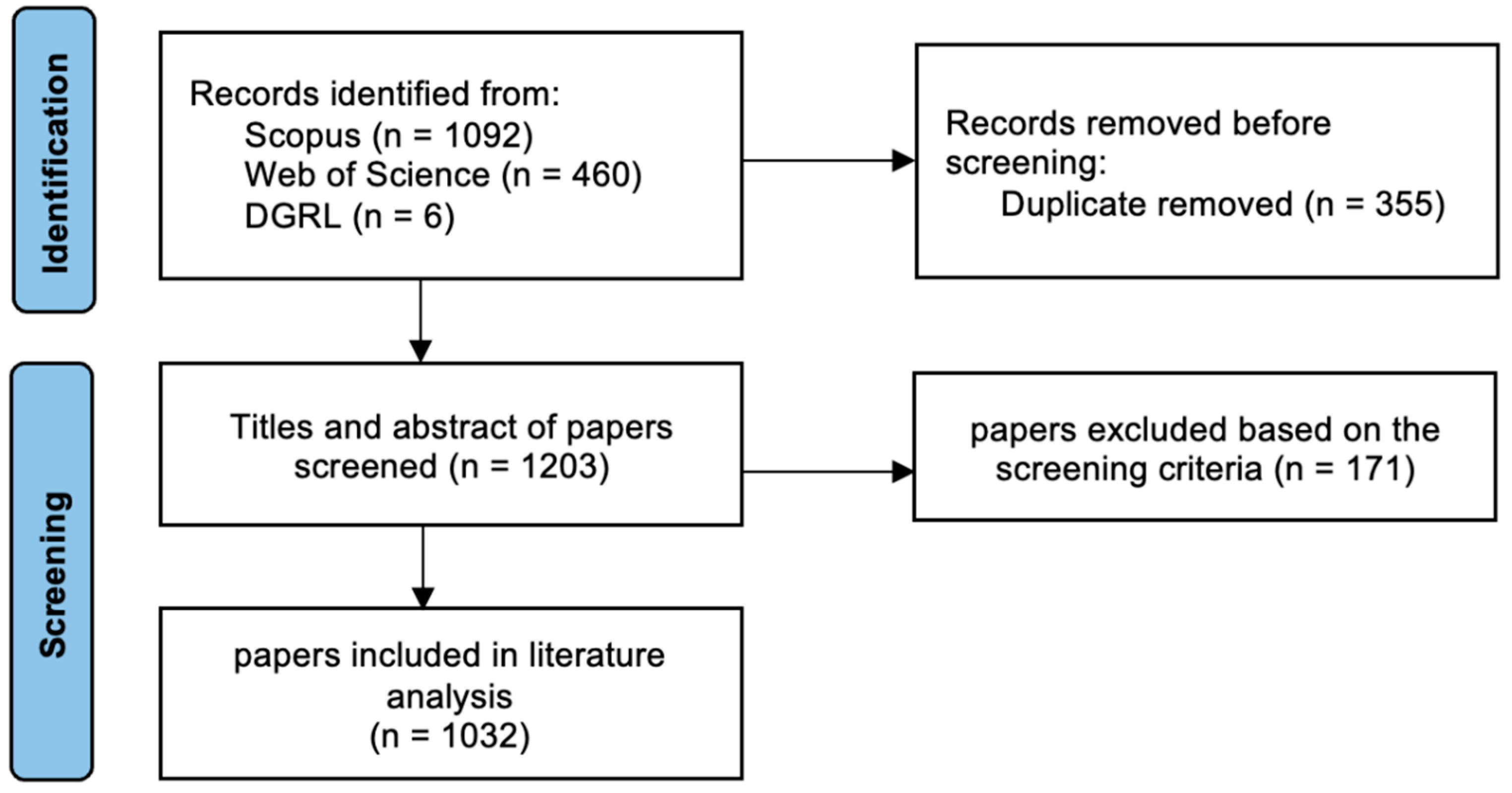
3. Material and Methods
3.1. Search Strategy
3.2. Screening Strategy
- The use of NLP should play a significant or major part in the study (its research objective, questions, etc.). Studies with an unrelated or secondary focus on the usage of NLP were excluded from this phase. For example, those articles may use other methods in AI but merely mention NLP technologies and do not use them in their research.
- NLP use in government (or the public sector) should be the main focus of the study, and the study’s objective should directly serve or benefit governments. For example, if NLP was not applied in the context of a government, or the authors only used the open data source from the government to conduct research in other fields, these articles were excluded.
3.3. Data Analysis
4. Results
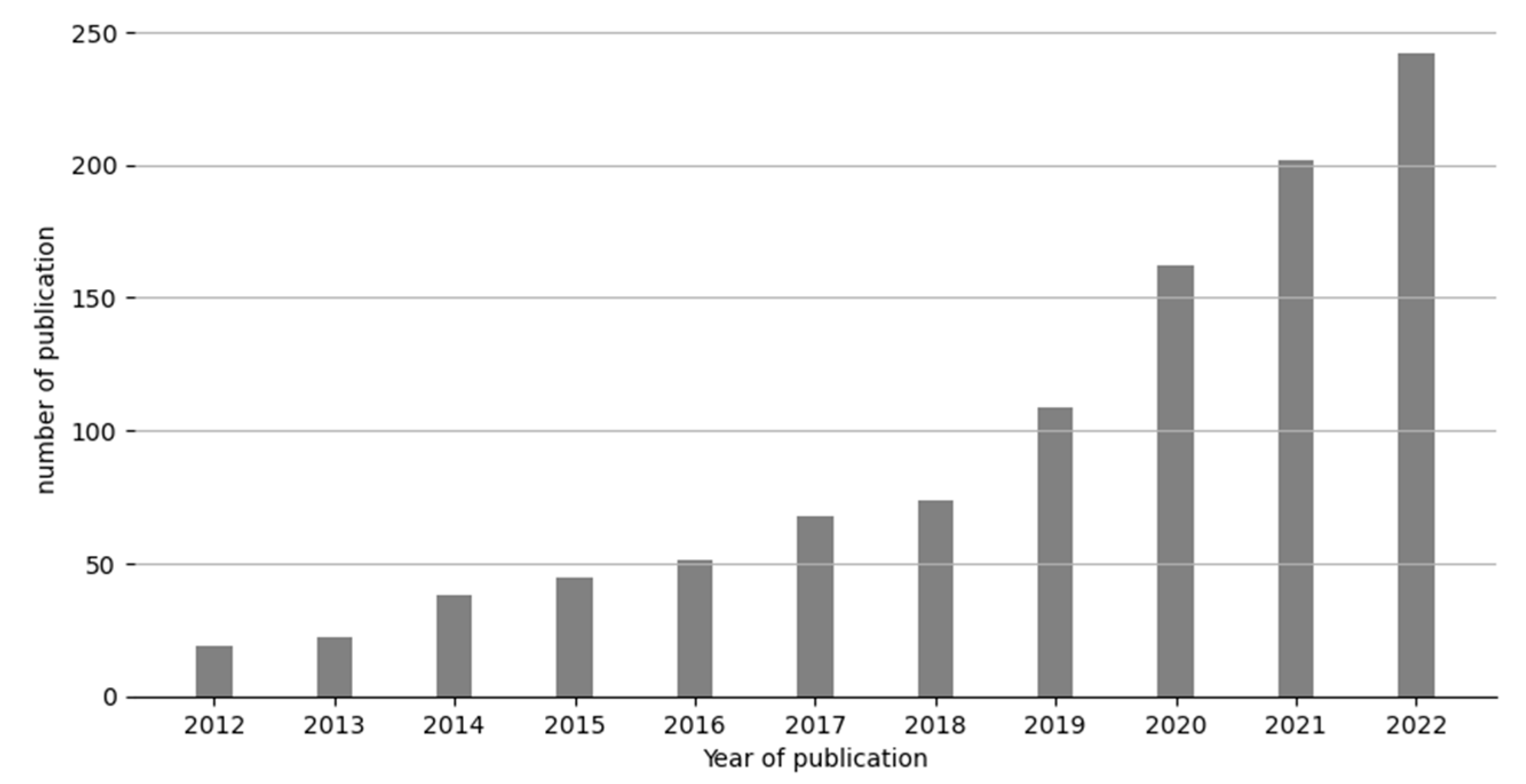
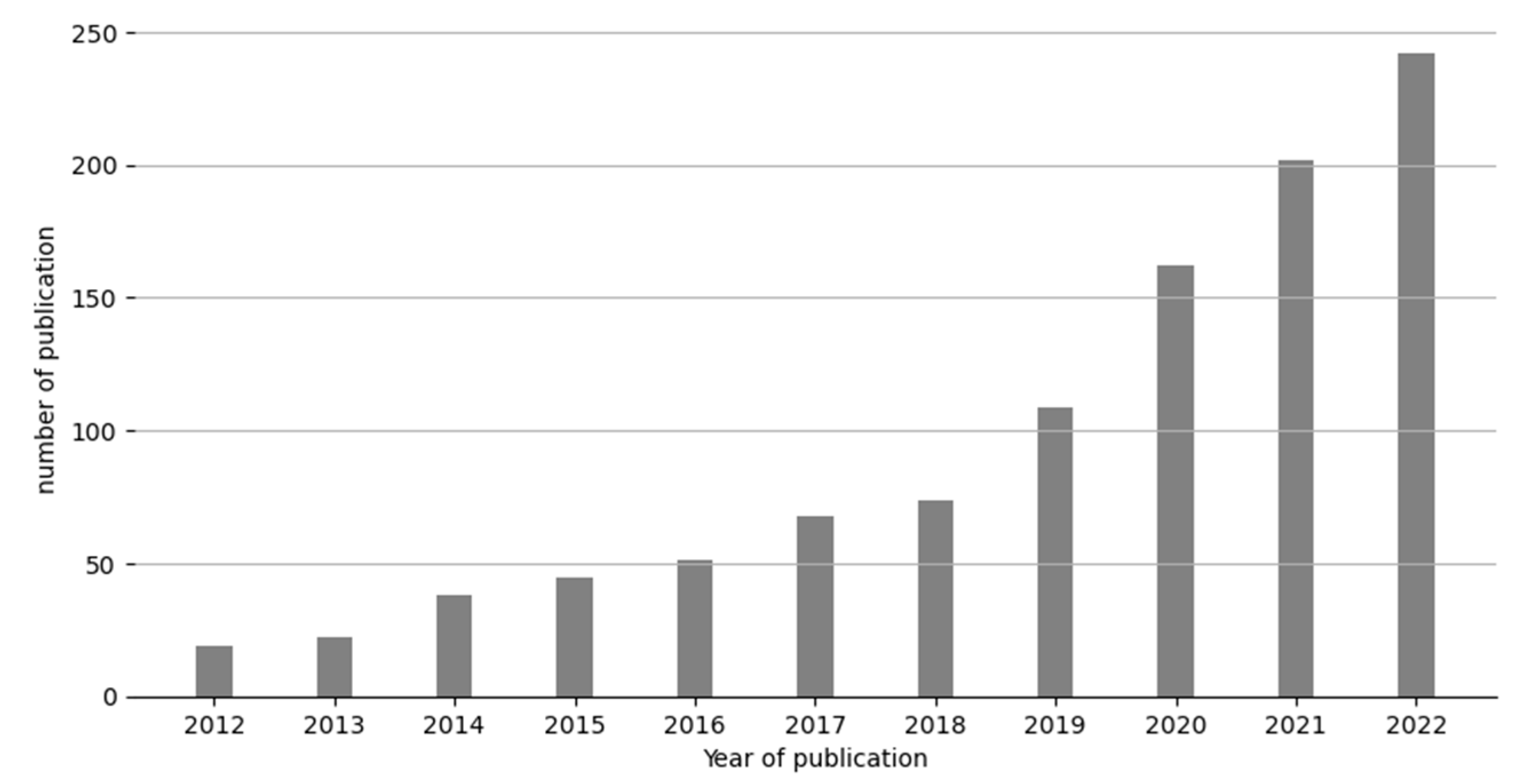
4.1. Descriptive Results
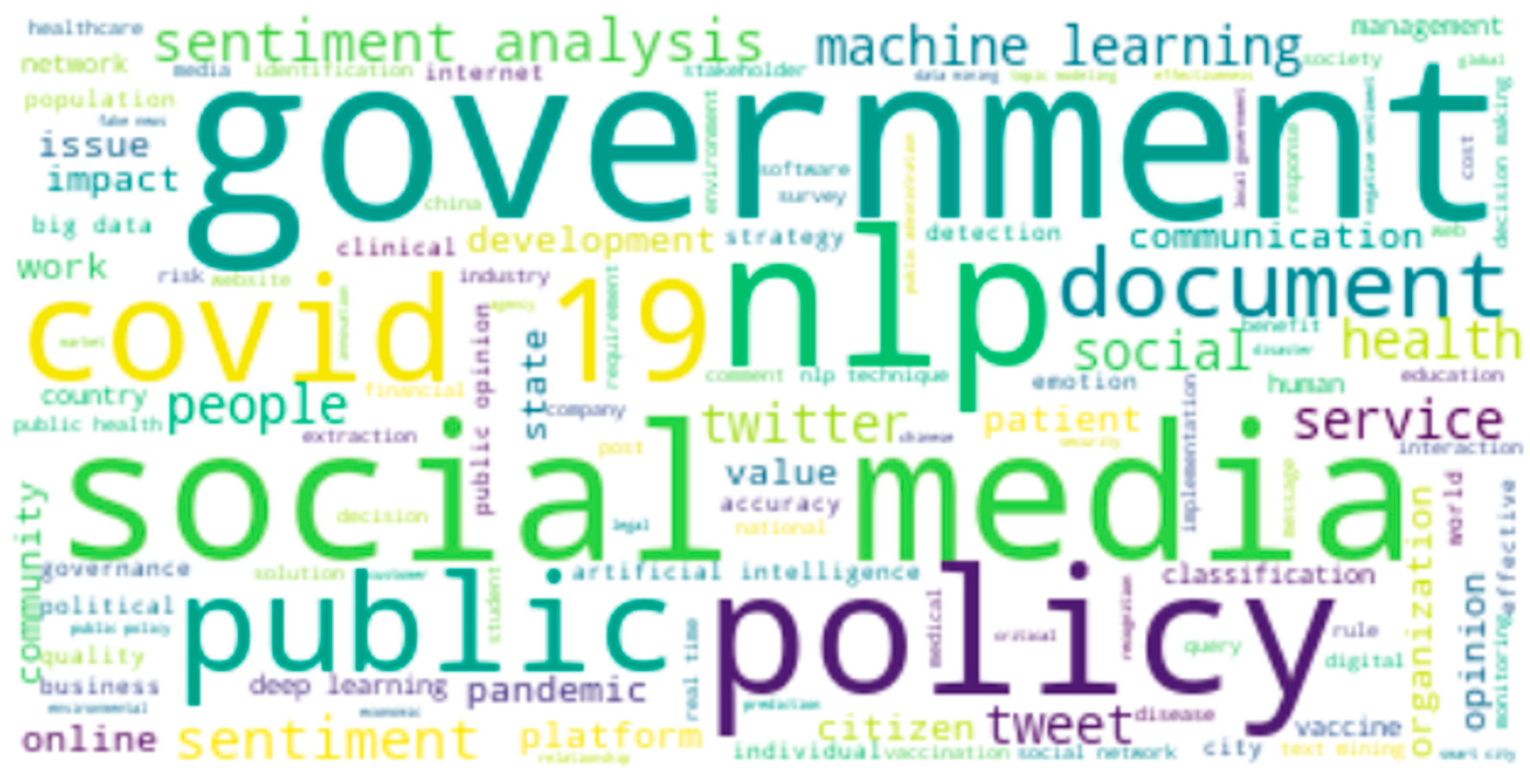
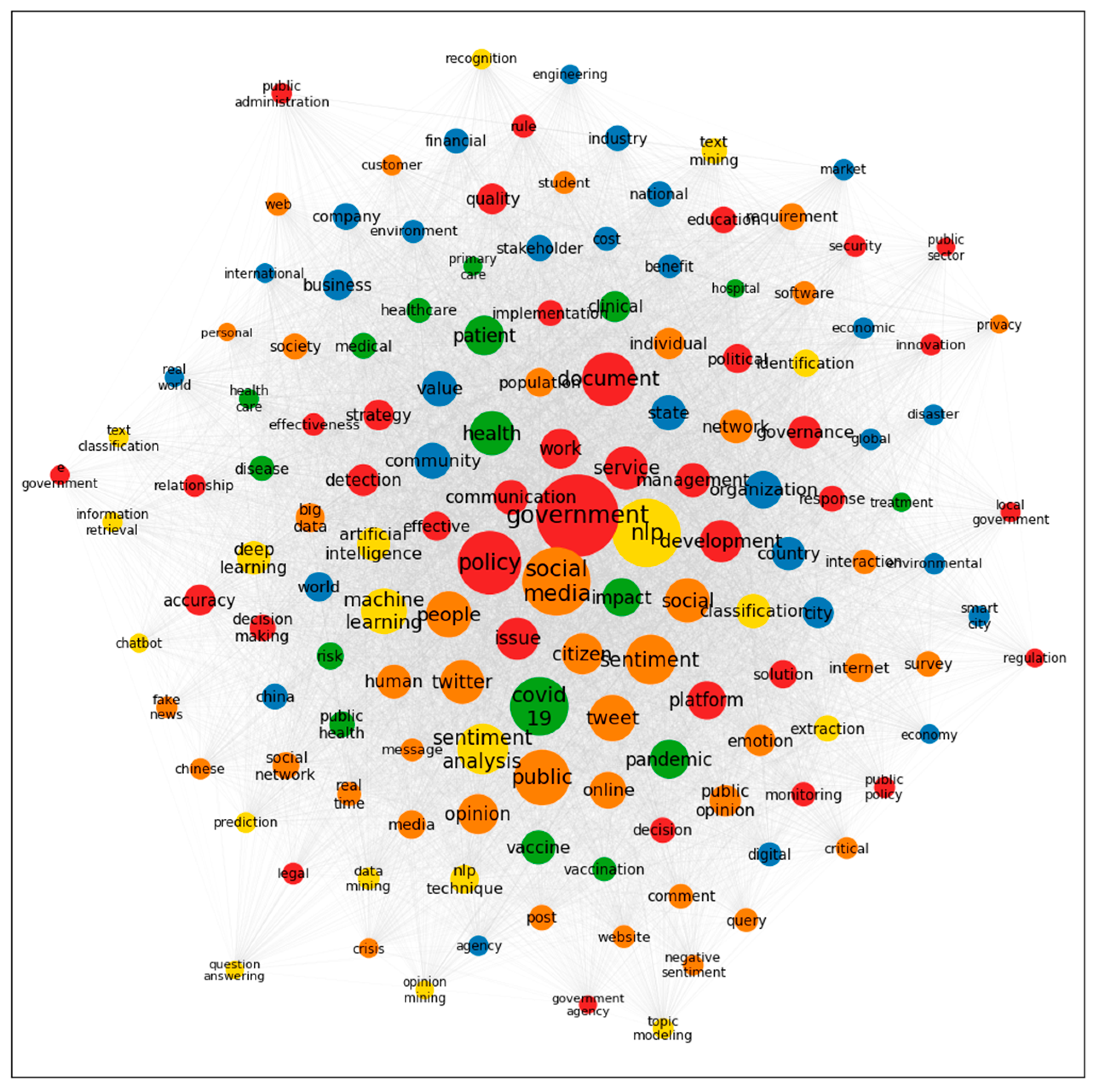
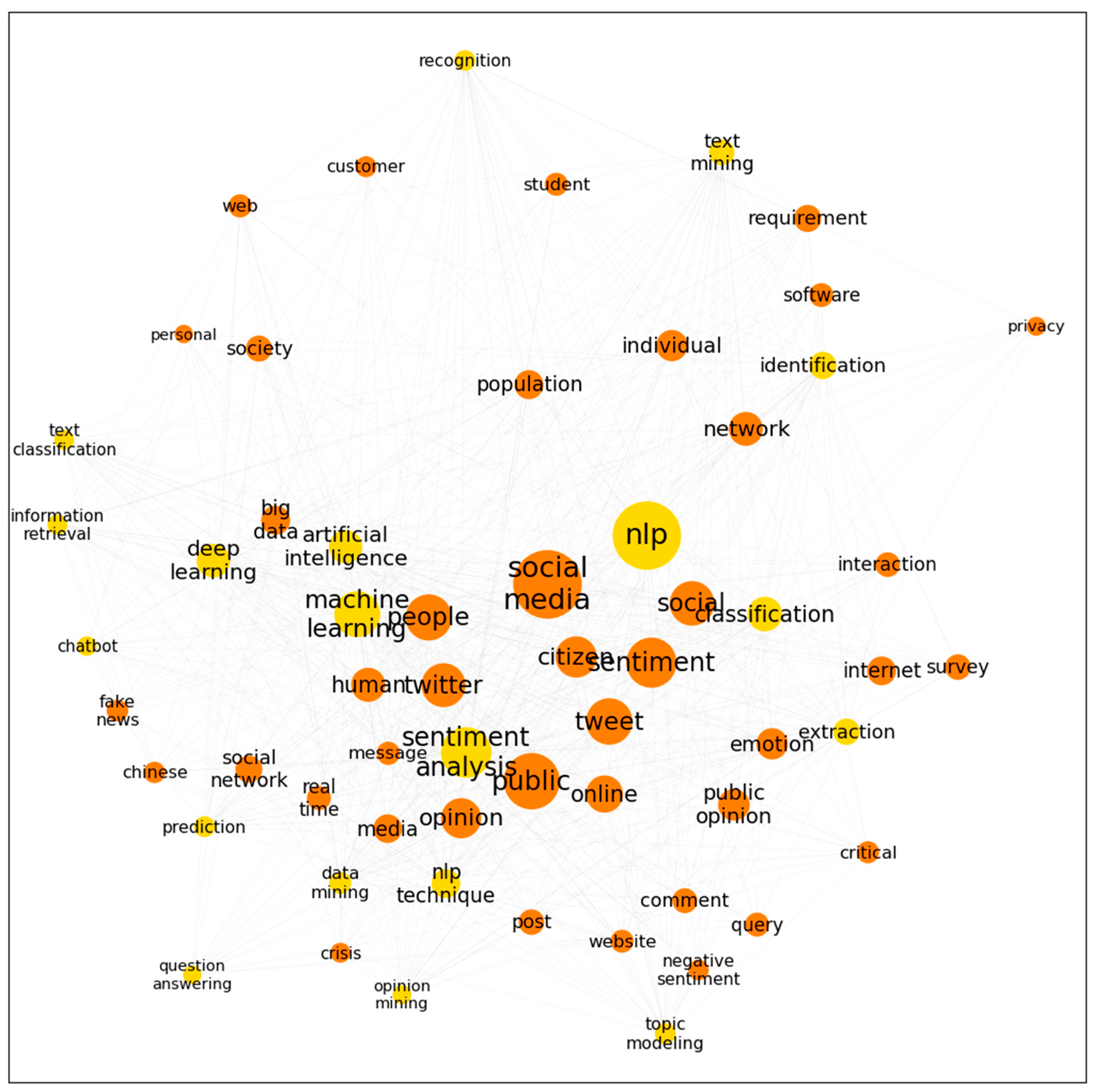
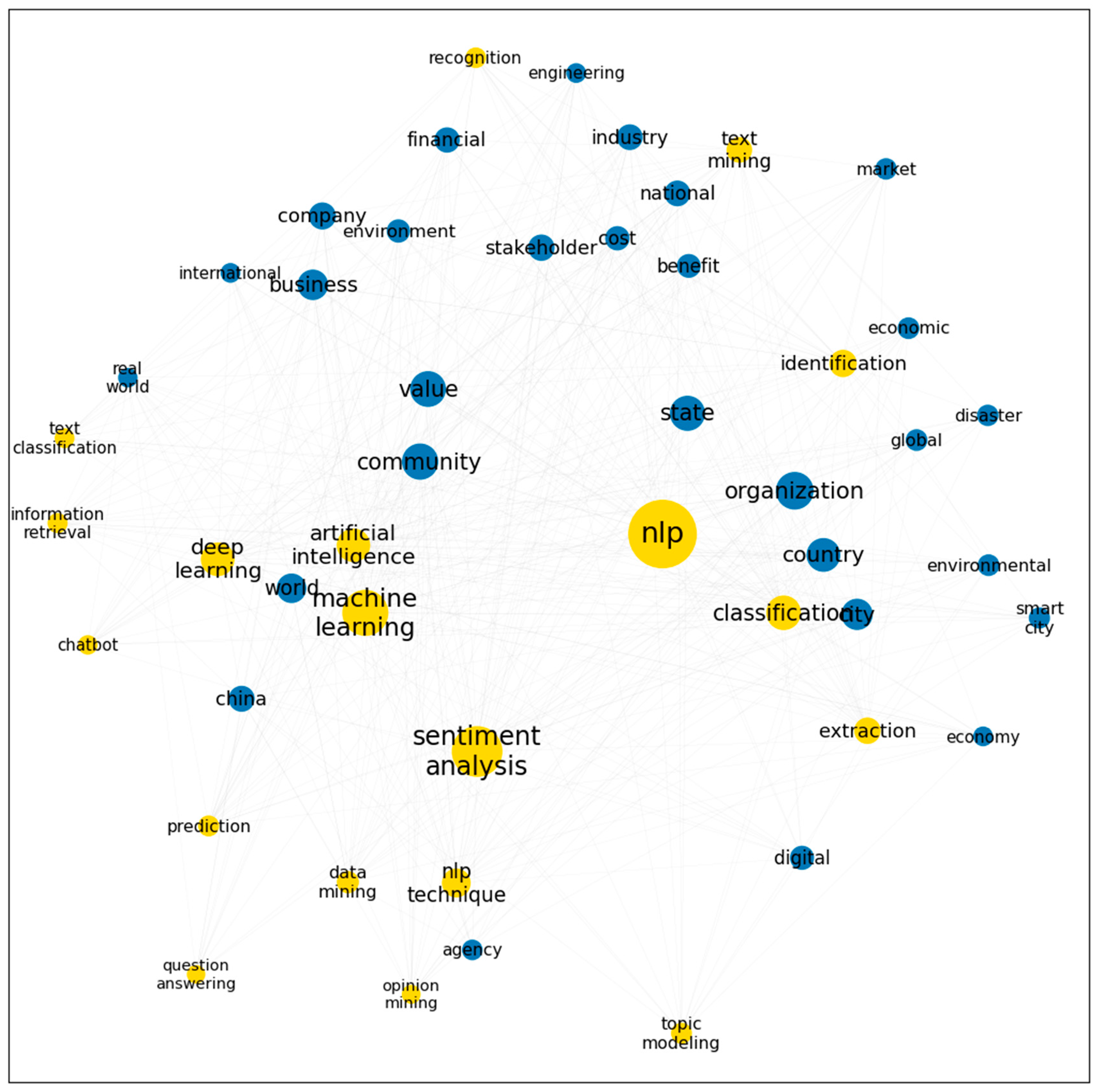
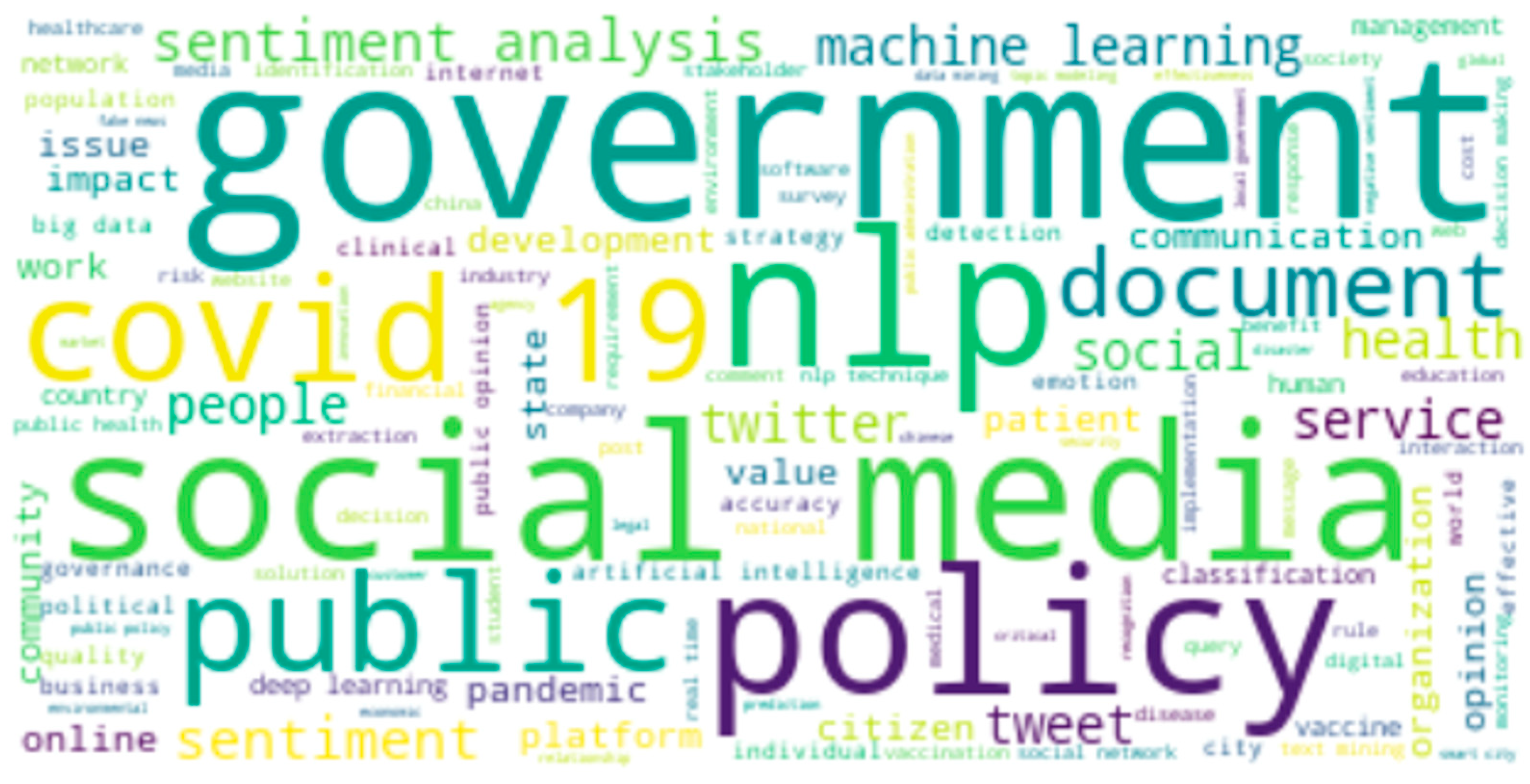
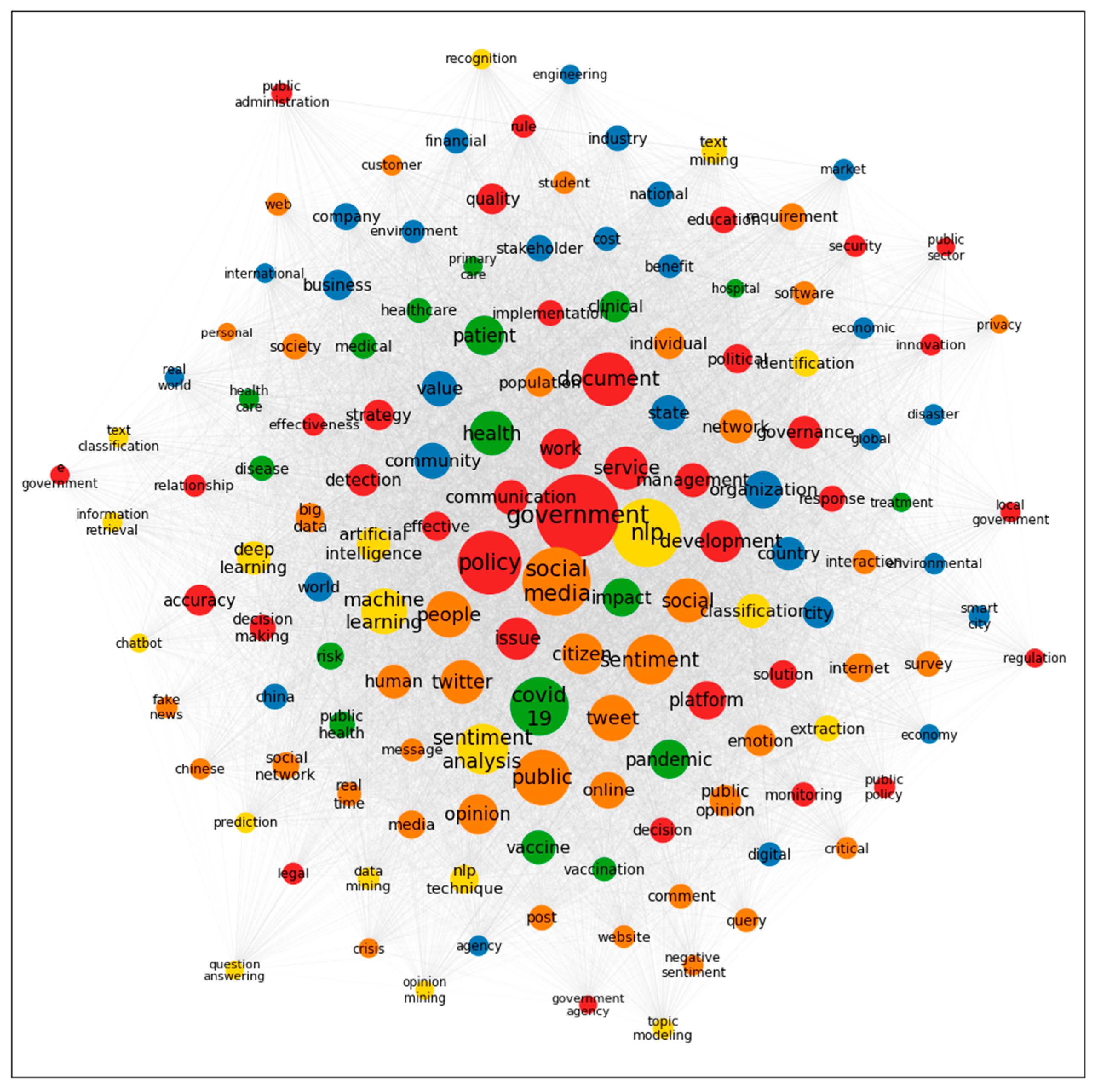
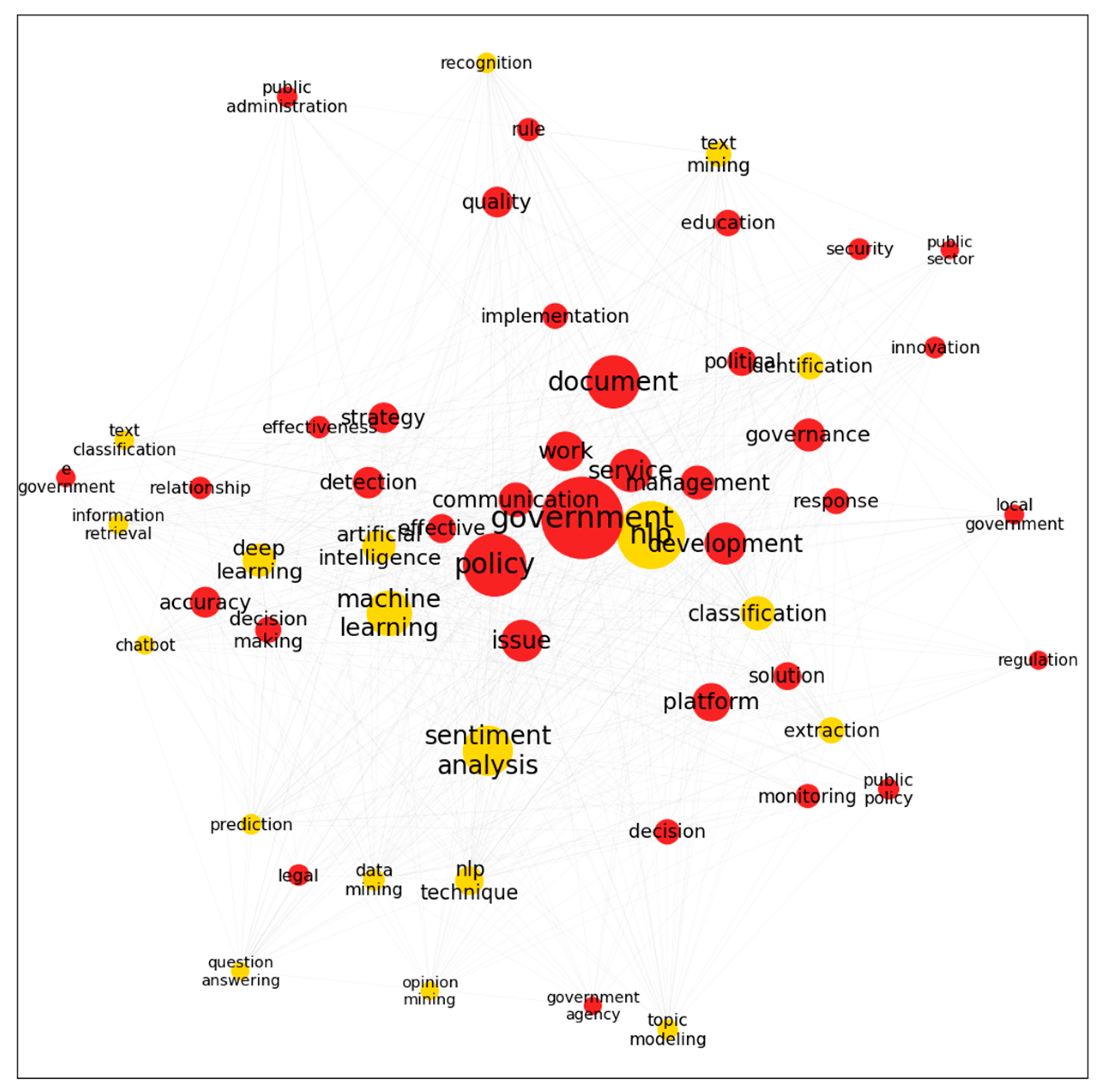
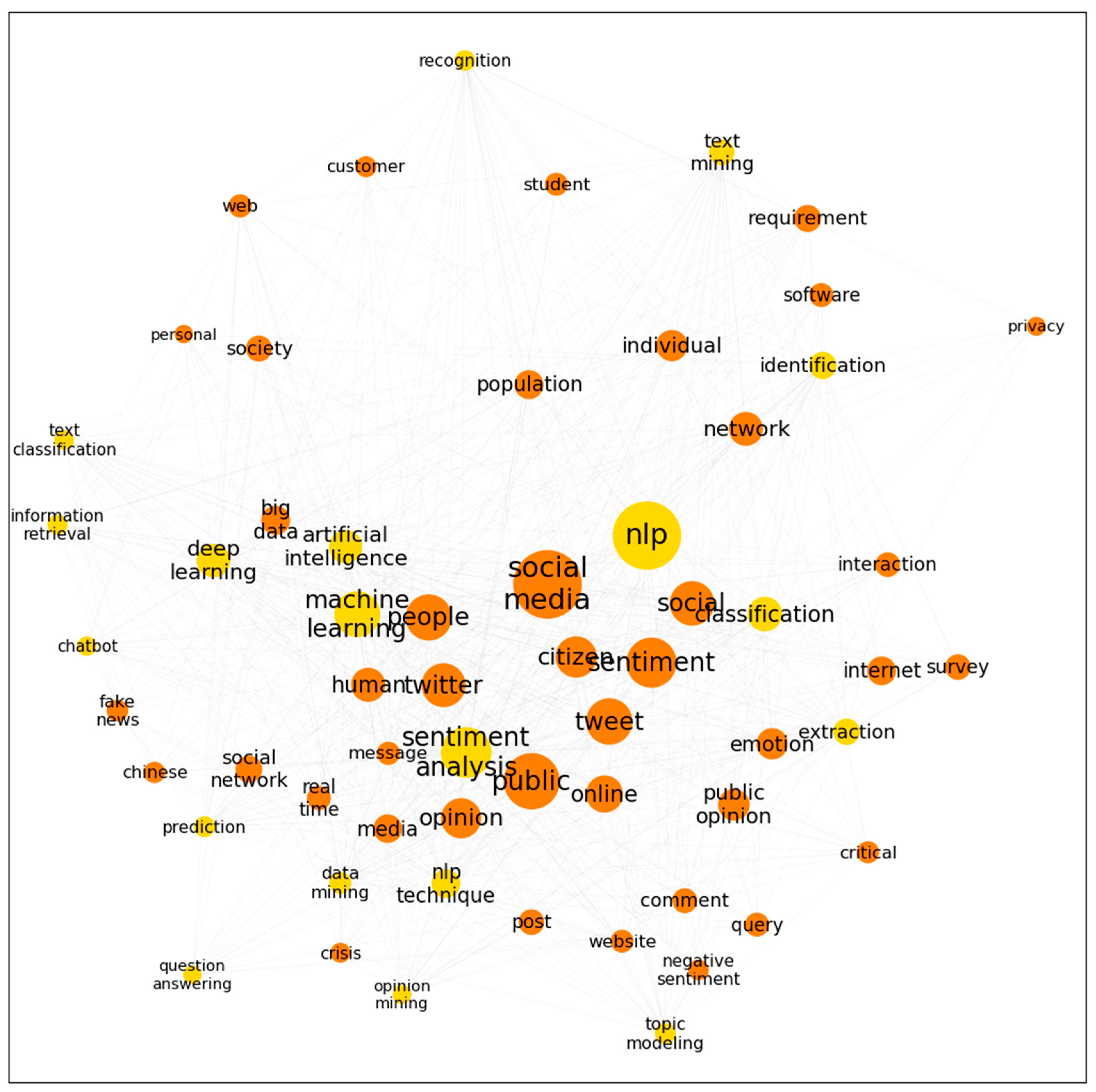
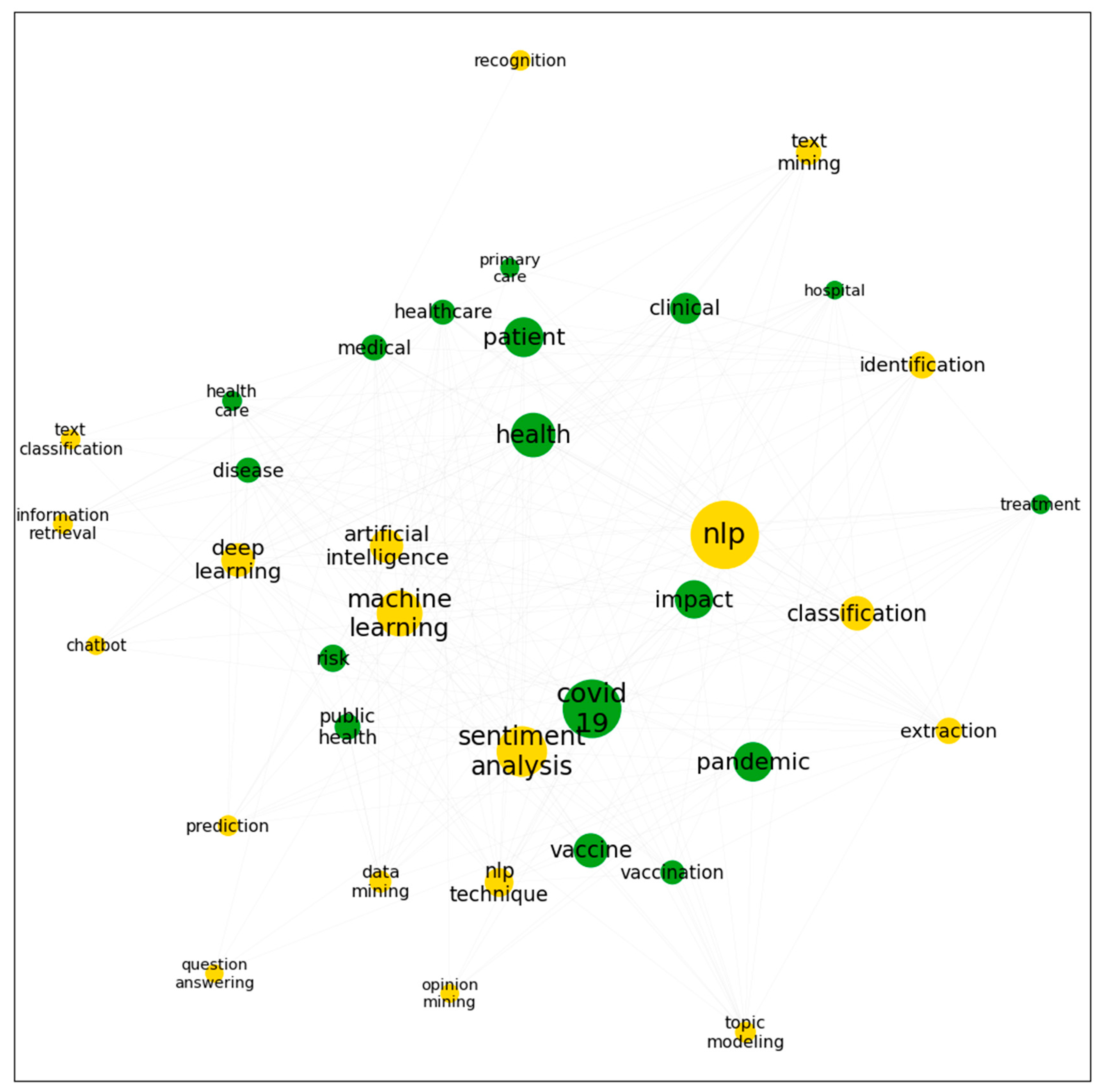
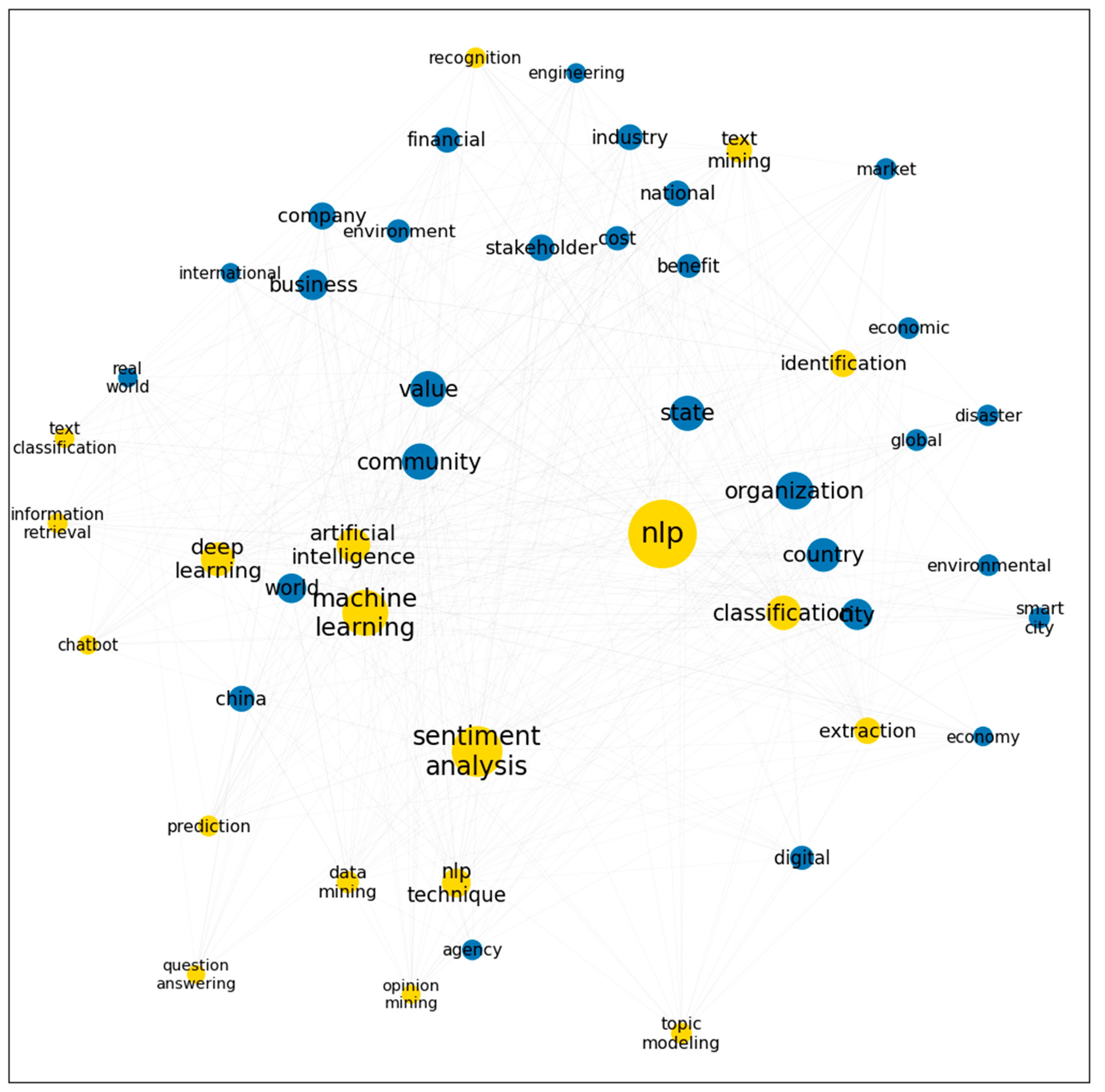
4.2. Co-Word and Network Analysis
5. Discussion
- (1)
- Automation: NLP technologies are leveraged for automating processes and activities under this classification. Exemplar literature includes a discussion of an automatic system to offer COVID-19 information to German citizens [67];
- (2)
- Extension—NLP technologies are being utilised to support novel forms of governance that enhance rather than replace current procedures or activities, such as to enhance the algorithms for fake news identification [68];
- (3)
- Transformation—This category refers to the innovative forms of governance made possible by NLP technologies with the potential to replace or alternate the established ones. For example, chatting robots as a new form of citizen-to-government communication [69].
5.1. NLP for Governance and Policy
5.2. NLP for Understanding Citizen and Public Opinion
5.3. NLP for Medical and Healthcare
5.4. NLP for Economy and Environment
5.5. Implications for Future Research
- (1)
- The Potential of Chatbots: The literature analysis reveals a lack of interest in chatbots, though government agencies have gradually shown their interest in chatbots recently, such as [65,95]. Chatbot research is an active NLP research subfield, but the same may not be true in governmental research, given that “the development of chatbots for public administration services has received very little attention” [96]. In fact, chatbots are being used to perform a wide variety of tasks, for instance, placing orders for meals, making product recommendations, providing customer support, setting up meetings, etc. During the pandemic, chatbots’ ability to “chat” with people caught the focus of governments, and they are used as a solution for maintaining conversational engagements under social distancing policies [97]. However, there are few chatbot applications developed for local administrative services [96]. With the introduction of ChatGPT, the conversational capabilities of AI-driven tools have reached the eyesight of the public. It can carry on a conversation by picking up and comprehending human languages and engaging in dialogues in accordance with the chat’s context. One of ChatGPT’s first models can successfully talk with its users in English and other languages on a variety of topics, which has generated both excitement and controversy [98]. This relaxed conversation mode is friendly to the elderly and those who do not know how to use electronic devices well. If governments and researchers plan to use chatbots, the emergence of large language models like ChatGPT will bring benefits since they are suitable for answering questions and providing solutions for citizens, which can enable citizens to easily access government services.
- (2)
- NLP Applications in the Post-Pandemic Era: Another finding of ours is that COVID-19 became a topic of concern studied by many governments. Governments around the world have organised much of their work around the pandemic, and NLP can gauge the effectiveness of government policies [87]. As the illness appears less severe and has turned into a type of respiratory infection, the post-pandemic era has begun, and the emphases of governments’ work have also transformed. The disease has warned and reminded people of the importance of health and lifestyle, and therefore governments need to strengthen the management and the response to public health in the near future. Set against this background, what would be the public health issues that are worth following up on? This is a noteworthy question in the post-pandemic era. NLP approaches such as sentiment analysis and keyword summarisation can be used by governments for monitoring potential reports of infections. In addition, NLP techniques have been found to be useful in the reform of public health systems to collect citizens’ feedback and their sentiments towards the changes [99]. This can serve as a potential future research direction as healthcare systems continue to evolve after the pandemic.
- (3)
- NLP Empirical Research for Government Work: Governance and policy formulation can be viewed as the main functions of governments, and researchers have conducted different NLP studies to tackle the issues in these areas, for instance, creating a contemporary government early warning system and public policy monitoring system to assess government credit in real-time [100]. Other governance-related research includes an NLP-based e-governance platform [101,102] and decision-making systems [82,103]. Our work has identified that some government departments such as health and finance have started using NLP, and it has the potential to bring convenience to other departments, too. To this end, researchers can investigate how to discover novel approaches to improve the effectiveness or accuracy of NLP models to better assist government work, with the aim of eliminating heavy workloads and manual work in the future. To bring NLP into practice, governments must develop novel strategies and guidelines to evaluate the genuine qualitative advantages of various NLP models.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zuiderwijk, A.; Chen, Y.-C.; Salem, F. Implications of the Use of Artificial Intelligence in Public Governance: A Systematic Literature Review and a Research Agenda. Gov. Inf. Q. 2021, 38, 101577. [Google Scholar] [CrossRef]
- Schwarzer, M.; Düver, J.; Ploch, D.; Lommatzsch, A. An Interactive E-Government Question Answering System. In Proceedings of the Lernen, Wissen, Daten, Analysen 2016, Potsdam, Germany, 12–14 September 2016; Volume 1670, pp. 74–82. [Google Scholar]
- Nasseef, O.A.; Baabdullah, A.M.; Alalwan, A.A.; Lal, B.; Dwivedi, Y.K. Artificial Intelligence-Based Public Healthcare Systems: G2G Knowledge-Based Exchange to Enhance the Decision-Making Process. Gov. Inf. Q. 2022, 39, 101618. [Google Scholar] [CrossRef]
- Ju, J.; Meng, Q.; Sun, F.; Liu, L.; Singh, S. Citizen Preferences and Government Chatbot Social Characteristics: Evidence from a Discrete Choice Experiment. Gov. Inf. Q. 2023, 40, 101785. [Google Scholar] [CrossRef]
- Parent, M.; Vandebeek, C.A.; Gemino, A.C. Building Citizen Trust Through E-Government. Gov. Inf. Q. 2005, 22, 720–736. [Google Scholar] [CrossRef]
- Song, Y.; Li, Z.; He, J.; Li, Z.; Fang, X.; Chen, D. Employing Auto-Annotated Data for Government Document Classification. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence (ICIAI ‘19), Association for Computing Machinery, New York, NY, USA, 15–18 March 2019; Part F148152. pp. 121–125. [Google Scholar]
- Iroju, O.G.; Department of Computer Science, Adeyemi College of Education, Ondo, Nigeria; Olaleke, J. O. A Systematic Review of Natural Language Processing in Healthcare. Int. J. Inf. Technol. Comput. Sci. 2015, 7, 44–50. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, J.; Zhang, Y.; Wu, Y. Sentiment Analysis of China’s Education Policy Online Opinion Based on Text Mining. In Proceedings of the 2021 9th International Conference on Information and Education Technology (ICIET), Okayama, Japan, 27–29 March 2021; pp. 73–77. [Google Scholar]
- Iriberri, A.; Navarrete, C.J. E-Government Services: Design and Evaluation of Crime Reporting Alternatives. Electron. Gov. 2013, 10, 171–188. [Google Scholar] [CrossRef]
- Anand, T.; Singh, V.; Bali, B.; Sahoo, B.M.; Shivhare, B.D.; Gupta, A.D. Survey Paper: Sentiment Analysis for Major Government Decisions. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 104–109. [Google Scholar]
- Addo, A.; Senyo, P.K. Advancing E-Governance for Development: Digital Identification and Its Link to Socioeconomic Inclusion. Gov. Inf. Q. 2021, 38, 101568. [Google Scholar] [CrossRef]
- Lee, T.; Lee-Geiller, S.; Lee, B.-K. A Validation of the Modified Democratic E-Governance Website Evaluation Model. Gov. Inf. Q. 2021, 38, 101616. [Google Scholar] [CrossRef]
- Verma, S. Sentiment Analysis of Public Services for Smart Society: Literature Review and Future Research Directions. Gov. Inf. Q. 2022, 39, 101708. [Google Scholar] [CrossRef]
- Sheikhalishahi, S.; Miotto, R.; Dudley, J.T.; Lavelli, A.; Rinaldi, F.; Osmani, V. Natural Language Processing of Clinical Notes on Chronic Diseases: Systematic Review. JMIR Med. Inform. 2019, 7, e12239. [Google Scholar] [CrossRef]
- Locke, S.; Bashall, A.; Al-Adely, S.; Moore, J.; Wilson, A.; Kitchen, G.B. Natural Language Processing in Medicine: A Review. Trends Anaesth. Crit. Care 2021, 38, 4–9. [Google Scholar] [CrossRef]
- Bozyiit, F.; Kln, D. Practices of Natural Language Processing in the Finance Sector; Springer: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 157–170. [Google Scholar]
- Nazir, F.; Butt, W.H.; Anwar, M.W.; Khan Khattak, M.A. The Applications of Natural Language Processing (NLP) for Software Requirement Engineering—A Systematic Literature Review. In Proceedings of the Information Science and Applications 2017; Kim, K., Joukov, N., Eds.; Springer: Singapore, 2017; pp. 485–493. [Google Scholar]
- Gelbukh, A. Natural Language Processing. In Proceedings of the Fifth International Conference on Hybrid Intelligent Systems (HIS’05), Rio de Janerio, Brazil, 6–9 November 2005; p. 1. [Google Scholar]
- Chowdhury, G.G. Natural Language Processing. Annu. Rev. Inf. Ence Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural Language Processing: An Introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2022, 82, 3713–3744. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in Natural Language Processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Chopra, A.; Prashar, A.; Sain, C. Natural Language Processing. Int. J. Technol. Enhanc. Emerg. Eng. Res. 2013, 1, 131–134. [Google Scholar]
- Ramos, J. Using TF-IDF to Determine Word Relevance in Document Queries. Proc. First Instr. Conf. Mach. Learn. 2003, 242, 29–48. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Zhou, H. Research of Text Classification Based on TF-IDF and CNN-LSTM. J. Phys. Conf. Ser. 2022, 2171, 012021. [Google Scholar] [CrossRef]
- Liu, H.; Chen, X.; Liu, X. A Study of the Application of Weight Distributing Method Combining Sentiment Dictionary and TF-IDF for Text Sentiment Analysis. IEEE Access 2022, 10, 32280–32289. [Google Scholar] [CrossRef]
- Lin, K.-P.; Chen, M.-S. On the Design and Analysis of the Privacy-Preserving SVM Classifier. IEEE Trans. Knowl. Data Eng. 2011, 23, 1704–1717. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Yang, Y. The Research of the Fast SVM Classifier Method. In Proceedings of the 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2015; pp. 121–124. [Google Scholar]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Zhang, Y. Using Word2Vec to Process Big Text Data. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October—1 November 2015; pp. 2895–2897. [Google Scholar]
- Reshamwala, A.; Mishra, D.; Pawar, P. Review on Natural Language Processing. IRACST Eng. Sci. Technol. Int. J. 2013, 3, 113–116. [Google Scholar]
- Mutawa, M.A.; Rashid, H. Comprehensive Review on the Challenges That Impact Artificial Intelligence Applications in the Public Sector. In Proceedings of the 5th NA International Conference on Industrial Engineering and Operations Management, Detroit, MI, USA, 10–14 August 2020; Volume 10. [Google Scholar]
- Medaglia, R.; Gil-Garcia, J.R.; Pardo, T.A. Artificial Intelligence in Government: Taking Stock and Moving Forward. Soc. Sci. Comput. Rev. 2021, 41, 123–140. [Google Scholar] [CrossRef]
- Gomes de Sousa, W.; Pereira de Melo, E.R.; De Souza Bermejo, P.H.; Sousa Farias, R.A.; Oliveira Gomes, A. How and Where Is Artificial Intelligence in the Public Sector Going? A Literature Review and Research Agenda. Gov. Inf. Q. 2019, 36, 101392. [Google Scholar] [CrossRef]
- Lommatzsch, A. A next Generation Chatbot-Framework for the Public Administration; Communications in Computer and Information Science. In Proceedings of the Innovations for Community Services: 18th International Conference, I4CS 2018, Žilina, Slovakia, 18–20 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 863, pp. 127–141. [Google Scholar]
- Lommatzsch, A.; Katins, J. An Information Retrieval-Based Approach for Building Intuitive Chatbots for Large Knowledge Bases. In Proceedings of the Conference on “Lernen, Wissen, Daten, Analysen”, Berlin, Germany, 30 September–2 October 2019; Volume 2454. [Google Scholar]
- Alguliyev, R.M.; Aliguliyev, R.M.; Niftaliyeva, G.Y. Extracting Social Networks from E-Government by Sentiment Analysis of Users’ Comments. Electron. Gov. Int. J. 2019, 15, 91–106. [Google Scholar] [CrossRef]
- Corallo, A.; Fortunato, L.; Matera, M.; Alessi, M.; Camillò, A.; Chetta, V.; Giangreco, E.; Storelli, D. Sentiment Analysis for Government: An Optimized Approach. In Proceedings of the Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 98–112. [Google Scholar]
- Mahadzir, N.H.; Omar, M.F.; Nawi, M.N.M. Towards Sentiment Analysis Application in Housing Projects. In Proceedings of the International Conference on Applied Science and Technology 2016 (ICAST’16), Kedah, Malaysia, 11–13 April 2016; AIP Publishing: College Park, MD, USA; 2016; p. 020060. [Google Scholar]
- Tayal, D.K.; Yadav, S.K. Sentiment Analysis on Social Campaign “Swachh Bharat Abhiyan” Using Unigram Method. AI Soc. 2017, 32, 633–645. [Google Scholar] [CrossRef]
- Madanian, S.; Airehrour, D.; Samsuri, N.A.; Cherrington, M. Twitter Sentiment Analysis in Covid-19 Pandemic. In Proceedings of the 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Online (Virtual), 27–30 October 2021; pp. 399–405. [Google Scholar]
- Kitchenham, B.; Pearl Brereton, O.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic Literature Reviews in Software Engineering—A Systematic Literature Review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Kitchenham, B.; Madeyski, L.; Budgen, D. SEGRESS: Software Engineering Guidelines for REporting Secondary Studies. IEEE Trans. Softw. Eng. 2023, 49, 1273–1298. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. Syst. Rev. 2021, 10, 89. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Hao, Z.; Zhao, S.; Gong, J.; Yang, F. Artificial Intelligence in Health Care: Bibliometric Analysis. J. Med. Internet Res. 2020, 22, e18228. [Google Scholar] [CrossRef] [PubMed]
- Vrijhoef, H.; Steuten, L. How to Write an Abstract. Eur. Diabetes Nurs. 2007, 4, 124–127. [Google Scholar] [CrossRef]
- Jiang, Y.; Pang, P.C.-I.; Ang, W.W.; Lau, Y. A Proposed Method of Literature Analysis Based on Natural Language Processing and Network Analysis. In Proceedings of the 2022 10th International Conference on Information Technology: IoT and Smart City; Association for Computing Machinery: New York, NY, USA, 2023; pp. 29–35. [Google Scholar]
- Scholl, H.J. The Digital Government Reference Library (DGRL) and Its Potential Formative Impact on Digital Government Research (DGR). Gov. Inf. Q. 2021, 38, 101613. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Hagberg, A.; Swart, P.S.; Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Andreas Mueller. WordCloud for Python Documentation. Available online: http://amueller.github.io/word_cloud/ (accessed on 13 October 2023).
- Hagen, L.; Uzuner, O.; Kotfila, C.; Harrison, T.M.; LaManna, D. Understanding Citizens’ Direct Policy Suggestions to the Federal Government: A Natural Language Processing and Topic Modeling Approach. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 2134–2143. [Google Scholar]
- Iriberri, A. Natural Language Processing and Psychology in E-Government Services: Evaluation of a Crime Reporting and Interviewing System. Int. J. Electron. Gov. Res. 2015, 11, 1–17. [Google Scholar] [CrossRef]
- Metsker, O.; Trofimov, E.; Grechishcheva, S. Natural Language Processing of Russian Court Decisions for Digital Indicators Mapping for Oversight Process Control Efficiency: Disobeying a Police Officer Case. In Communications in Computer and Information Science; CCIS; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1135, p. 307. [Google Scholar]
- Aitamuro, T.; Chen, K.; Cherif, A.; Saldivar, J.; Santana, L. Civic CrowdAnalytics: Making Sense of Crowdsourced Civic Input with Big Data Tools. In Proceedings of the ACM Academic Mindtrek’16: Proceedings of the 20th International Academic Mindtrek Conference, Tampere, Finland, 17 October 2016; pp. 86–94. [Google Scholar] [CrossRef]
- Garg, S.; Panwar, D.S.; Gupta, A.; Katarya, R. A Literature Review on Sentiment Analysis Techniques Involving Social Media Platforms. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 254–259. [Google Scholar]
- Hasbullah, S.S.; Maynard, D.; Wan Chik, R.Z.; Mohd, F.; Noor, M. Automated Content Analysis: A Sentiment Analysis on Malaysian Government Social Media. 2016.
- Messaoudi, C.; Guessoum, Z.; Ben Romdhane, L. Opinion Mining in Online Social Media: A Survey. Soc. Netw. Anal. Min. 2022, 12, 25. [Google Scholar] [CrossRef]
- Alzamil, Z.; Appelbaum, D.; Nehmer, R. An Ontological Artifact for Classifying Social Media: Text Mining Analysis for Financial Data. Int. J. Account. Inf. Syst. 2020, 38, 100469. [Google Scholar] [CrossRef]
- Eckhard, S.; Patz, R.; Schönfeld, M.; van Meegdenburg, H. International Bureaucrats in the UN Security Council Debates: A Speaker-Topic Network Analysis. J. Eur. Public Policy 2021, 30, 214–233. [Google Scholar] [CrossRef]
- Vannoni, M.; Ash, E.; Morelli, M. Measuring Discretion and Delegation in Legislative Texts: Methods and Application to US States. Polit. Anal. 2021, 29, 43–57. [Google Scholar] [CrossRef]
- Prell, C. Social Network Analysis: History, Theory and Methodology; Sage Publications Ltd.: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Androutsopoulou, A.; Karacapilidis, N.; Loukis, E.; Charalabidis, Y. Transforming the Communication between Citizens and Government through AI-Guided Chatbots. Gov. Inf. Q. 2019, 36, 358–367. [Google Scholar] [CrossRef]
- Darko, A.; Chan, A.P.; Adabre, M.A.; Edwards, D.J.; Hosseini, M.R.; Ameyaw, E.E. Artificial Intelligence in the AEC Industry: Scientometric Analysis and Visualization of Research Activities. Autom. Constr. 2020, 112, 103081. [Google Scholar] [CrossRef]
- Both, A.; Heinze, P.; Perevalov, A.; Bartsch, J.R.; Iudin, R.; Herkner, J.R.; Schrader, T.; Wunsch, J.; Gürth, R.; Falkenhain, A.K. Quality Assurance of a German COVID-19 Question Answering Systems Using Component-Based Microbenchmarking. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1561–1564. [Google Scholar]
- Samadi, M.; Mousavian, M.; Momtazi, S. Deep Contextualized Text Representation and Learning for Fake News Detection. Inf. Process. Manag. 2021, 58, 102723. [Google Scholar] [CrossRef]
- Segura-Tinoco, A.; Holgado-Sánchez, A.; Cantador, I.; Cortés-Cediel, M.E. A Conversational Agent for Argument-Driven e-Participation. In Proceedings of the Conference: DG.O 2022: The 23rd Annual International Conference on Digital Government Research, Online (Virtual), 15–17 June 2022; pp. 191–205. [Google Scholar] [CrossRef]
- Futia, G.; Cairo, F.; Morando, F.; Leschiutta, L. Exploiting Linked Open Data and Natural Language Processing for Classification of Political Speech; Edition Donau-Universität Krems; Danube University: Krems, Austria, 2014; pp. 349–360. [Google Scholar]
- Guo, K.; Jiang, T.; Zhang, H. Knowledge Graph Enhanced Event Extraction in Financial Documents. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1322–1329. [Google Scholar]
- Papadopoulos, T.; Charalabidis, Y. What Do Governments Plan in the Field of Artificial Intelligence? Analysing National AI Strategies Using NLP. In Proceedings of the ICEGOV 2020: 13th International Conference on Theory and Practice of Electronic Governance, Athens, Greece, 23–25 September 2020; pp. 100–111. [Google Scholar] [CrossRef]
- Ha, S.; Marchetto, D.J.; Dharur, S.; Asensio, O.I. Topic Classification of Electric Vehicle Consumer Experiences with Transformer-Based Deep Learning. Patterns 2021, 2, 100195. [Google Scholar] [CrossRef] [PubMed]
- Pardo, T.A.; Nam, T.; Burke, G.B. E-Government Interoperability: Interaction of Policy, Management, and Technology Dimensions. Soc. Sci. Comput. Rev. 2012, 30, 7–23. [Google Scholar] [CrossRef]
- Nikoli, V.; Markoski, B.; Kuk, K.; Ranelovi, D.; Isar, P. Modelling the System of Receiving Quick Answers for E-Government Services: Study for the Crime Domain in the Republic of Serbia. Acta Polytech. Hung. 2017, 14, 143–163. [Google Scholar] [CrossRef]
- Misra, A.; Misra, D.P.; Mahapatra, S.S.; Biswas, S. Digital Transformation Model: Analytic Approach on Participatory Governance & Community Engagement in India. In Proceedings of the 19th Annual International Conference on Digital Government Research, Delft, The Netherlands, 30 May–1 June 2018. [Google Scholar] [CrossRef]
- Gupta, P.; Kumar, S.; Suman, R.R.; Kumar, V. Sentiment Analysis of Lockdown in India during COVID-19: A Case Study on Twitter. IEEE Trans. Comput. Soc. Syst. 2021, 8, 939–949. [Google Scholar] [CrossRef]
- Lamba, A.; Yadav, D.; Lele, A. CitizenPulse: A Text Analytics Framework for Proactive e-Governance—A Case Study of Mygov. in. In Proceedings of the IKDD Conference on Data Science, 2016, Pune, India, 13–16 March 2016. [Google Scholar] [CrossRef]
- Adikari, A.; Alahakoon, D. Understanding Citizens’ Emotional Pulse in a Smart City Using Artificial Intelligence. IEEE Trans. Ind. Inform. 2020, 17, 2743–2751. [Google Scholar] [CrossRef]
- Choudrie, J.; Patil, S.; Kotecha, K.; Matta, N.; Pappas, I. Applying and Understanding an Advanced, Novel Deep Learning Approach: A COVID-19, Text Based, Emotions Analysis Study. Inf. Syst. Front. 2021, 23, 1431–1465. [Google Scholar] [CrossRef]
- Rezk, M.A.; Ojo, A.; Khayat, G.; Hussein, S. A Predictive Government Decision Based on Citizen Opinions: Tools & Results. In Proceedings of the 11th International Conference, ICEGOV ‘18: Proceedings of the 11th International Conference on Theory and Practice of Electronic Governance; Galway, Ireland, 4–6 April 2018, pp. 712–714. [CrossRef]
- Shah, N.; Srivastava, G.; Savage, D.W.; Mago, V. Assessing Canadians Health Activity and Nutritional Habits Through Social Media. Front. Public Health 2020, 7, 400. [Google Scholar] [CrossRef]
- Maguen, S.; Holder, N.; Madden, E.; Li, Y.; Seal, K.H.; Neylan, T.C.; Lujan, C.; Patterson, O.V.; DuVall, S.L.; Shiner, B. Evidence-Based Psychotherapy Trends among Posttraumatic Stress Disorder Patients in a National Healthcare System, 2001–2014. Depress. Anxiety 2020, 37, 356–364. [Google Scholar] [CrossRef]
- Lima, S.; Teran, L.; Portmann, E. A Proposal for an Explainable Fuzzy-Based Deep Learning System for Skin Cancer Prediction. In Proceedings of the 2020 Seventh International Conference on eDemocracy & eGovernment (ICEDEG), Buenos Aires, Argentina, 22–24 April 2020; pp. 29–35. [Google Scholar]
- Tan, H.; Peng, S.-L.; Zhu, C.-P.; You, Z.; Miao, M.-C.; Kuai, S.-G. Long-Term Effects of the COVID-19 Pandemic on Public Sentiments in Mainland China: Sentiment Analysis of Social Media Posts. J. Med. Internet Res. 2021, 23, e29150. [Google Scholar] [CrossRef]
- Liew, T.M.; Lee, C.S. Examining the Utility of Social Media in COVID-19 Vaccination: Unsupervised Learning of 672,133 Twitter Posts. JMIR Public Health Surveill. 2021, 7, e29789. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Jiang, W.; Pu, G.; Chan, K.-S.; Lau, Y. Social Media Engagement in Two Governmental Schemes during the COVID-19 Pandemic in Macao. Int. J. Environ. Res. Public. Health 2022, 19, 8976. [Google Scholar] [CrossRef]
- Greyling, T.; Rossouw, S. Positive Attitudes towards COVID-19 Vaccines: A Cross-Country Analysis. PLoS ONE 2022, 17, e0264994. [Google Scholar] [CrossRef]
- Guo, Y.; Li, Y.; Qian, Y. Local Government Debt Risk Assessment: A Deep Learning-Based Perspective. Inf. Process. Manag. 2022, 59, 102948. [Google Scholar] [CrossRef]
- Li, C.; Jiang, Y. Joint Learning for Disaster Event Extraction. In Proceedings of the 6th International Workshop on Advanced Algorithms and Control Engineering (IWAACE 2022), Qingdao, China, 8–10 July 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12350, pp. 745–752. [Google Scholar]
- Arianto, R.; Warnars, H.L.H.S.; Gaol, F.L.; Trisetyarso, A. Mining Unstructured Data in Social Media for Natural Disaster Management in Indonesia. In Proceedings of the 2018 Indonesian Association for Pattern Recognition International Conference (INAPR), Jakarta, Indonesia, 7–8 September 2018; pp. 192–196. [Google Scholar]
- Cecilia, J.M.; Cano, J.-C.; Calafate, C.T.; Manzoni, P.; Perinan-Pascual, C.; Arcas-Tunez, F.; Munoz-Ortega, A. WATERSensing: A Smart Warning System for Natural Disasters in Spain. IEEE Consum. Electron. Mag. 2021, 10, 89–96. [Google Scholar] [CrossRef]
- Kosaka, N.; Koyama, A.; Kokogawa, T.; Maeda, Y.; Koumoto, H.; Suzuki, S.; Yamaguchi, K.; Inui, K. Disaster Information System Using Natural Language Processing. J. Disaster Res. 2017, 12, 67–78. [Google Scholar] [CrossRef]
- Lydiri, M.; El Mourabit, Y.; El Habouz, Y.; Fakir, M. A Performant Deep Learning Model for Sentiment Analysis of Climate Change. Soc. Netw. Anal. Min. 2022, 13, 8. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, Technology, and Applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Nirala, K.K.; Singh, N.K.; Purani, V.S. A Survey on Providing Customer and Public Administration Based Services Using AI: Chatbot. Multimed. Tools Appl. 2022, 81, 22215–22246. [Google Scholar] [CrossRef]
- Amiri, P.; Karahanna, E. Chatbot Use Cases in the COVID-19 Public Health Response. J. Am. Med. Inform. Assoc. 2022, 29, 1000–1010. [Google Scholar] [CrossRef] [PubMed]
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Pang, P.C.-I.; Xiao, Y.; Wong, D. Changes in Doctor–Patient Relationships in China during COVID-19: A Text Mining Analysis. Int. J. Environ. Res. Public. Health 2022, 19, 13446. [Google Scholar] [CrossRef] [PubMed]
- Li, Z. Forecast and Simulation of the Public Opinion on the Public Policy Based on the Markov Model. Complexity 2021, 2021, 9936965. [Google Scholar] [CrossRef]
- Leelavathy, S.; Nithya, M. Public Opinion Mining Using Natural Language Processing Technique for Improvisation towards Smart City. Int. J. Speech Technol. 2021, 24, 561–569. [Google Scholar] [CrossRef]
- Sovrano, F.; Palmirani, M.; Vitali, F. Combining Shallow and Deep Learning Approaches against Data Scarcity in Legal Domains. Gov. Inf. Q. 2022, 39, 101715. [Google Scholar] [CrossRef]
- Ittoo, A.; Szirbik, N.B.; Huitema, G.B.; Wortmann, J.C. Simulation Gaming and Natural Language Processing for Modelling Stakeholder Behavior in Energy Investments. In Proceedings of the ISC 2013, the 11th Industrial Simulation Conference, Ghent, Belgium, 22–24 May 2013; pp. 23–27. [Google Scholar]
- Aoki, N. An Experimental Study of Public Trust in AI Chatbots in the Public Sector. Gov. Inf. Q. 2020, 37, 101490. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | Search Terms |
|---|---|
| Natural language processing | “Natural Language Processing” OR “NLP” |
| AND | |
| Government | “government” OR “governance” OR “public sector” OR “public administration” OR “public policy” |
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| sentiment analysis | social media | 199 |
| sentiment analysis | 135 | |
| sentiment analysis | tweet | 120 |
| machine learning | sentiment | 92 |
| machine learning | social media | 86 |
| deep learning | government | 75 |
| classification | government | 65 |
| machine learning | public | 64 |
| classification | document | 61 |
| machine learning | tweet | 58 |
| Word | Frequency | Eigenvector Centrality | Degree Centrality | Closeness Centrality |
|---|---|---|---|---|
| government | 603 | 0.216 | 1.000 | 1.000 |
| social media | 410 | 0.183 | 0.972 | 0.973 |
| nlp | 406 | 0.135 | 1.000 | 1.000 |
| policy | 354 | 0.185 | 0.986 | 0.986 |
| COVID-19 | 298 | 0.161 | 0.901 | 0.910 |
| public | 270 | 0.132 | 0.986 | 0.986 |
| document | 248 | 0.065 | 0.901 | 0.910 |
| sentiment analysis | 218 | 0.085 | 0.951 | 0.953 |
| sentiment | 216 | 0.107 | 0.944 | 0.947 |
| tweet | 184 | 0.105 | 0.880 | 0.893 |
| people | 182 | 0.133 | 0.993 | 0.993 |
| machine learning | 179 | 0.063 | 1.000 | 1.000 |
| health | 169 | 0.352 | 0.958 | 0.959 |
| social | 169 | 0.255 | 0.972 | 0.973 |
| 164 | 0.084 | 0.930 | 0.934 | |
| service | 161 | 0.150 | 0.937 | 0.940 |
| development | 152 | 0.079 | 0.993 | 0.993 |
| issue | 152 | 0.082 | 0.986 | 0.986 |
| citizen | 144 | 0.068 | 0.972 | 0.973 |
| opinion | 136 | 0.066 | 0.915 | 0.922 |
| work | 135 | 0.137 | 0.965 | 0.966 |
| patient | 134 | 0.362 | 0.810 | 0.840 |
| pandemic | 129 | 0.087 | 0.859 | 0.877 |
| platform | 126 | 0.057 | 0.965 | 0.966 |
| impact | 124 | 0.059 | 0.944 | 0.947 |
| organization | 118 | 0.040 | 0.958 | 0.959 |
| online | 114 | 0.051 | 0.937 | 0.940 |
| community | 109 | 0.245 | 0.951 | 0.953 |
| value | 106 | 0.197 | 0.930 | 0.934 |
| communication | 102 | 0.082 | 0.937 | 0.940 |
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| deep learning | government | 75 |
| classification | government | 65 |
| classification | document | 61 |
| sentiment analysis | work | 44 |
| deep learning | detection | 35 |
| chatbot | service | 33 |
| machine learning | policy | 31 |
| extraction | government | 30 |
| machine learning | platform | 28 |
| chatbot | government | 26 |
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| sentiment analysis | social media | 199 |
| sentiment analysis | 135 | |
| sentiment analysis | tweet | 120 |
| machine learning | sentiment | 92 |
| machine learning | social media | 86 |
| machine learning | public | 64 |
| machine learning | tweet | 58 |
| opinion mining | social | 48 |
| machine learning | 48 | |
| classification | social media | 46 |
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| identification | patient | 55 |
| topic modeling | vaccine | 35 |
| identification | impact | 31 |
| sentiment analysis | vaccine | 28 |
| deep learning | pandemic | 24 |
| machine learning | vaccination | 22 |
| machine learning | pandemic | 20 |
| sentiment analysis | vaccination | 19 |
| data mining | health | 17 |
| extraction | health | 16 |
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| machine learning | organization | 28 |
| identification | value | 24 |
| machine learning | world | 23 |
| deep learning | real world | 22 |
| sentiment analysis | value | 18 |
| machine learning | state | 18 |
| classification | disaster | 18 |
| sentiment analysis | world | 13 |
| identification | state | 13 |
| machine learning | market | 13 |
| # | Category | Description |
|---|---|---|
| 1 | Governance and Policy | Efficiently extract and analyse documents and policies; obtain insights for better governances and services |
| 2 | Understanding Citizen and Public Opinion | Evaluating citizens’ sentient and public opinions; understanding attitudes regarding policies |
| 3 | Medical and Healthcare | Measuring the reception of health policies; clarifying the situations and the efficiency of public health measures during the pandemic |
| 4 | Economic and Environment | Retrieving the reactions of markets; identifying risks and threats in economics |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Pang, P.C.-I.; Wong, D.; Kan, H.Y. Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review. Appl. Sci. 2023, 13, 12346. https://doi.org/10.3390/app132212346
Jiang Y, Pang PC-I, Wong D, Kan HY. Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review. Applied Sciences. 2023; 13(22):12346. https://doi.org/10.3390/app132212346
Chicago/Turabian StyleJiang, Yunqing, Patrick Cheong-Iao Pang, Dennis Wong, and Ho Yin Kan. 2023. "Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review" Applied Sciences 13, no. 22: 12346. https://doi.org/10.3390/app132212346
APA StyleJiang, Y., Pang, P. C.-I., Wong, D., & Kan, H. Y. (2023). Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review. Applied Sciences, 13(22), 12346. https://doi.org/10.3390/app132212346