
Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages

 , , , , ,
, , , , ,  ,
,  , and
, and
Abstract
:1. Introduction
- We investigate different scenarios for monolingual, cross-lingual, and multilingual SER using datasets for Amharic and three other languages (English, German, and Urdu).
- We experiment with a novel approach in which a model is trained on data in several non-Amharic languages before being tested on Amharic. We show that training on two non-Amharic languages gives a better result than training on just one.
- We present a comparison of deep learning techniques in these tasks: AlexNet, ResNet50, and VGGE.
- To the best of our knowledge, this is the first work that shows the performance tendencies of Amharic SER utilizing several languages.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
| Ref | Methods Employed | Feature Extraction | Databases and Languages | Expts | Classes |
|---|---|---|---|---|---|
| [13] | SVM | Prosodic | EMO-DB (German) DES (Danish), ENT (English), SA (Afrikaans) | XM | 3 |
| [9] | SVM, SC, EPC | Prosodic Various MFCC | RML (Mandarin, English, Italian Persian, Punjabi, Urdu) | X | 6 |
| [14] | SMO | Various MFCC | CDESD (Mandarin), EMO-DB, DES | X | Arousal Appraisal Space |
| [15] | SVM | Various MelSpec | EU-EmoSS (English, French, German, Spanish), VESD (Chinese), CASIA (Chinese) | X | Arousal Valence Plane |
| [16] | DBN, MLP | Low-level Acoustic | KSUEmotions (Arabic), EPST (English) | X | 2 |
| [17] | SVM | eGeMAPS | SAVEE (English), EMOVO (Italian), EMO-DB, URDU (Urdu) | XM | 2 |
| [18] | DBN | eGeMAPS | FAU-AIBO (German), IEMOCAP (English) EMO-DB, SAVEE, EMOVO | X | 2 |
| [19] | GAN | eGeMAPS Various | EMO-DB, SAVEE, EMOVO, URDU | XM | 2 |
| [20] | LSTM, LR, SVM | ISO9 | EMOVO, EMO-DB, SAVEE, IEMOCAP, MASC (Chinese) | X | 5 |
| [23] | CNN and Wav2Vec2-XLSR | prosody | IEMOCAP, CREMA-D (English), ESD (English), Synpaflex (French), Oreau (French), EMO-DB, EMOVO, emoUERJ (Portuguese) | X | 4 |
| [24] | AG-TFNN | MelSpec | EMO-DB, eNTERFACE (English), IITKGP-SEHSC (Hindi), IITKGP-SESC (Telugu), ShEMO-DB (Persian) | M | 2 |
| [22] | SMO, RF, J48, Ensemble | Spectral Prosodic eGeMAPS | SAVEE, URDU, EMO-DB, EMOVO | X | 2 |
3. Approach
3.1. Speech Emotion Databases
| Aspect | ASED | RAVDESS | EMO-DB | URDU |
|---|---|---|---|---|
| Language | Amharic | English | German | Urdu |
| Recordings | 2474 | 1440 | 535 | 400 |
| Sentences | 27 | 2 | 10 | - |
| Participants | 65 | 24 | 10 | 38 |
| Emotions | 5 | 8 | 7 | 4 |
| Positive valence | Neutral, Happy | Neutral, Happy, Calm, Surprise | Neutral, Happiness | Neutral, Happy |
| Negative valence | Fear, Sadness, Angry | Fear, Sadness, Angry, Disgust | Anger, Sadness, Fear, Disgust, Boredom | Angry, Sad |
| References | [10] | [27] | [29] | [17] |
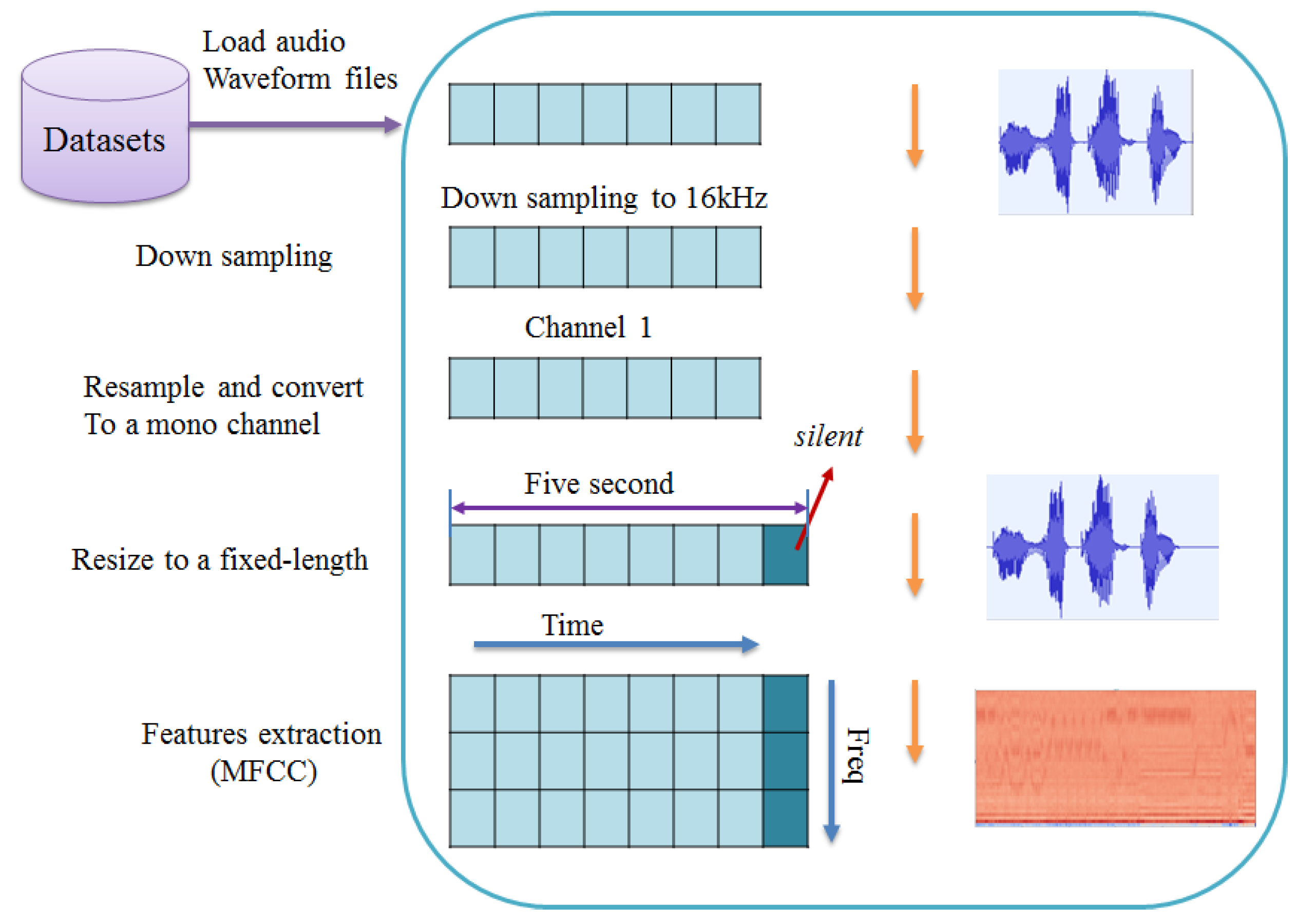
3.2. Data Preprocessing
3.3. Feature Extraction for SER
4. Architectures and Settings
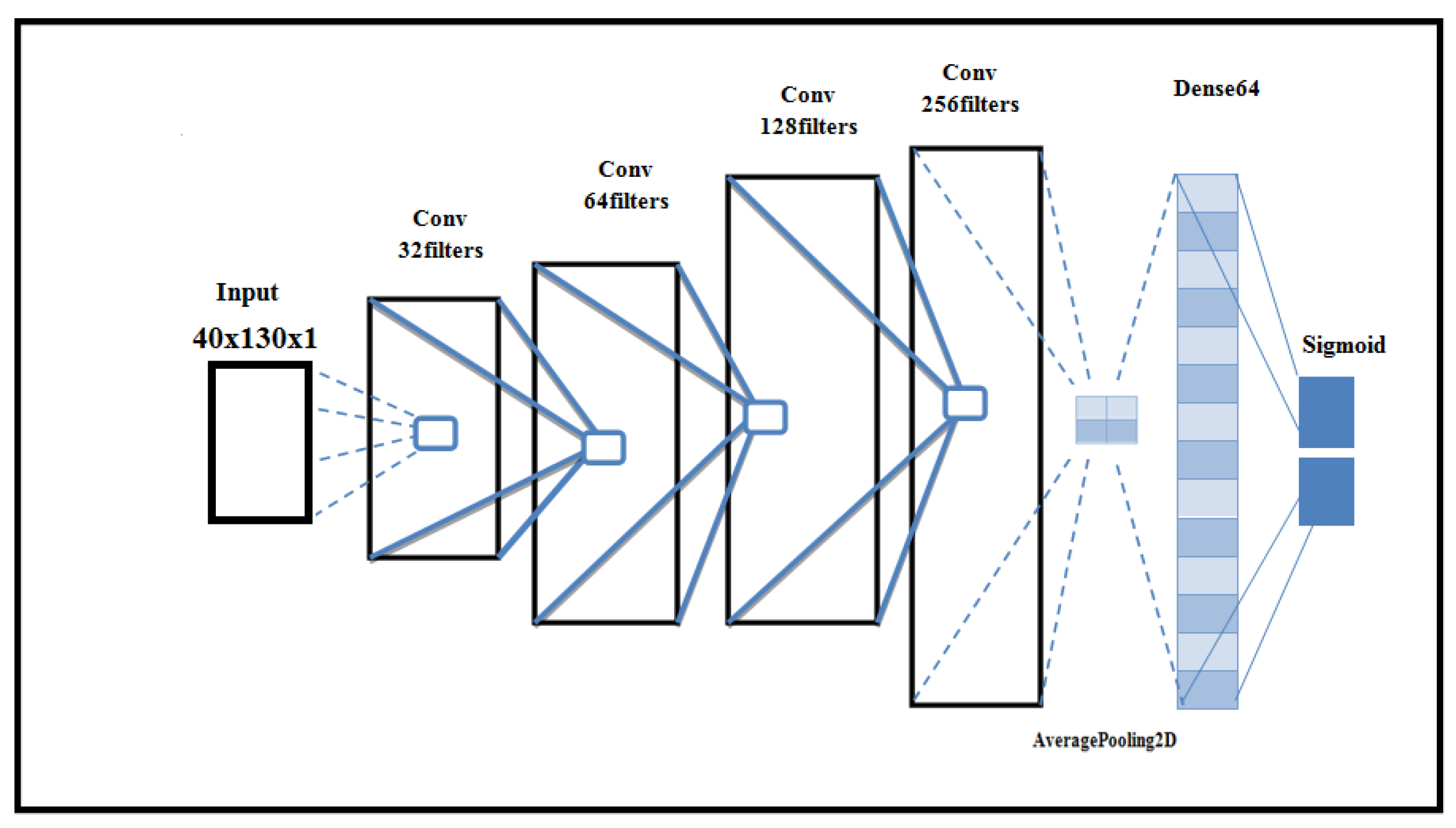
- VGG [39] appeared in 2014, created by the Oxford Robotics Institute. It is well known that the early CNN layers capture the general features of sounds such as wavelength, amplitude, etc., and later layers capture more specific features such as the spectrum and the cepstral coefficients of waves. This makes a VGG-style model suitable for the SER task. After some experimentation, we found that a model based on VGG but using four layers gave the best performance. We call this proposed model VGGE and use it for our experiments. Figure 1 shows the settings for VGGE.
5. Experiments
6. Experiment 1: Comparison of SER Methods for Monolingual SER
6.1. Outline
6.2. Experiment 1.1: Independence of Speakers
6.3. Experiment 1.2: Independence of Sentences
7. Experiment 2: Comparison of SER Methods for Amharic Cross-Lingual SER
8. Experiment 3: Multilingual SER
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zvarevashe, K.; Olugbara, O. Ensemble learning of hybrid acoustic features for speech emotion recognition. Algorithms 2020, 13, 70. [Google Scholar] [CrossRef]
- Khan, M.U.; Javed, A.R.; Ihsan, M.; Tariq, U. A novel category detection of social media reviews in the restaurant industry. Multimed. Syst. 2020, 29, 1–14. [Google Scholar] [CrossRef]
- Zhang, B.; Provost, E.M.; Essl, G. Cross-corpus acoustic emotion recognition from singing and speaking: A multi-task learning approach. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5805–5809. [Google Scholar]
- Zhang, Z.; Weninger, F.; Wöllmer, M.; Schuller, B. Unsupervised learning in cross-corpus acoustic emotion recognition. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, Waikoloa, HI, USA, 11–15 December 2011; pp. 523–528. [Google Scholar]
- Wang, D.; Zheng, T.F. Transfer learning for speech and language processing. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 1225–1237. [Google Scholar]
- Wöllmer, M.; Stuhlsatz, A.; Wendemuth, A.; Rigoll, G. Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar]
- Mossie, Z.; Wang, J.H. Social network hate speech detection for Amharic language. Comput. Sci. Inf. Technol. 2018, 41–55. [Google Scholar]
- Mengistu, A.D.; Bedane, M.A. Text Independent Amharic Language Dialect Recognition using Neuro-Fuzzy Gaussian Membership Function. Int. J. Adv. Stud. Comput. Sci. Eng. 2017, 6, 30. [Google Scholar]
- Albornoz, E.M.; Milone, D.H. Emotion recognition in never-seen languages using a novel ensemble method with emotion profiles. IEEE Trans. Affect. Comput. 2015, 8, 43–53. [Google Scholar] [CrossRef]
- Retta, E.A.; Almekhlafi, E.; Sutcliffe, R.; Mhamed, M.; Ali, H.; Feng, J. A new Amharic speech emotion dataset and classification benchmark. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–22. [Google Scholar] [CrossRef]
- Sailunaz, K.; Dhaliwal, M.; Rokne, J.; Alhajj, R. Emotion detection from text and speech: A survey. Soc. Netw. Anal. Min. 2018, 8, 1–26. [Google Scholar] [CrossRef]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef]
- Lefter, I.; Rothkrantz, L.J.; Wiggers, P.; Van Leeuwen, D.A. Emotion recognition from speech by combining databases and fusion of classifiers. In International Conference on Text, Speech and Dialogue; Springer: Berlin/Heidelberg, Germany, 2010; pp. 353–360. [Google Scholar]
- Xiao, Z.; Wu, D.; Zhang, X.; Tao, Z. Speech emotion recognition cross language families: Mandarin vs. western languages. In Proceedings of the 2016 International Conference on Progress in Informatics and Computing (PIC), Shanghai, China, 23–25 December 2016; pp. 253–257. [Google Scholar]
- Sagha, H.; Matejka, P.; Gavryukova, M.; Povolnỳ, F.; Marchi, E.; Schuller, B.W. Enhancing Multilingual Recognition of Emotion in Speech by Language Identification. Interspeech 2016, 2949–2953. [Google Scholar]
- Meftah, A.; Seddiq, Y.; Alotaibi, Y.; Selouani, S.A. Cross-corpus Arabic and English emotion recognition. In Proceedings of the 2017 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 18–20 December 2017; pp. 377–381. [Google Scholar]
- Latif, S.; Qayyum, A.; Usman, M.; Qadir, J. Cross lingual speech emotion recognition: Urdu vs. western languages. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 88–93. [Google Scholar]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Cross corpus speech emotion classification-an effective transfer learning technique. arXiv 2018, arXiv:1801.06353. [Google Scholar]
- Latif, S.; Qadir, J.; Bilal, M. Unsupervised adversarial domain adaptation for cross-lingual speech emotion recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 732–737. [Google Scholar]
- Goel, S.; Beigi, H. Cross lingual cross corpus speech emotion recognition. arXiv 2020, arXiv:2003.07996. [Google Scholar]
- Bhaykar, M.; Yadav, J.; Rao, K.S. Speaker dependent, speaker independent and cross language emotion recognition from speech using GMM and HMM. In Proceedings of the 2013 National conference on communications (NCC), New Delhi, India, 15–17 February 2013; pp. 1–5. [Google Scholar]
- Zehra, W.; Javed, A.R.; Jalil, Z.; Khan, H.U.; Gadekallu, T.R. Cross corpus multi-lingual speech emotion recognition using ensemble learning. Complex Intell. Syst. 2021, 7, 1845–1854. [Google Scholar] [CrossRef]
- Duret, J.; Parcollet, T.; Estève, Y. Learning Multilingual Expressive Speech Representation for Prosody Prediction without Parallel Data. arXiv 2023, arXiv:2306.17199. [Google Scholar]
- Pandey, S.K.; Shekhawat, H.S.; Prasanna, S.R.M. Multi-cultural speech emotion recognition using language and speaker cues. Biomed. Signal Process. Control 2023, 83, 104679. [Google Scholar] [CrossRef]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse autoencoder-based feature transfer learning for speech emotion recognition. In Proceedings of the 2013 humaine association conference on affective computing and intelligent interaction, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2015, 7, 190–202. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Stanislavski, C. An Actor Prepares (New York). Theatre Art. 1936, 38. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Gangamohan, P.; Kadiri, S.R.; Yegnanarayana, B. Analysis of emotional speech—A review. In Toward Robotic Socially Believable Behaving Systems-Volume I; Springer: Berlin/Heidelberg, Germany, 2016; pp. 205–238. [Google Scholar]
- Fairbanks, G.; Hoaglin, L.W. An experimental study of the durational characteristics of the voice during the expression of emotion. Commun. Monogr. 1941, 8, 85–90. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech emotion recognition using deep learning techniques: A review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Dey, N.A.; Amira, S.M.; Waleed, S.N.; Nhu, G. Acoustic sensors in biomedical applications. In Acoustic Sensors for Biomedical Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–47. [Google Scholar]
- Almekhlafi, E.; Moeen, A.; Zhang, E.; Wang, J.; Peng, J. A classification benchmark for Arabic alphabet phonemes with diacritics in deep neural networks. Comput. Speech Lang. 2022, 71, 101274. [Google Scholar] [CrossRef]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Shaw, A.; Vardhan, R.H.; Saxena, S. Emotion recognition and classification in speech using Artificial neural networks. Int. J. Comput. Appl. 2016, 145, 5–9. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. A CNN-assisted enhanced audio signal processing for speech emotion recognition. Sensors 2020, 20, 183. [Google Scholar]
- Kumbhar, H.S.; Bhandari, S.U. Speech Emotion Recognition using MFCC features and LSTM network. In Proceedings of the 2019 5th International Conference On Computing, Communication, Control And Automation (ICCUBEA), Pune, India, 19–21 September 2019; pp. 1–3. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- George, D.; Shen, H.; Huerta, E.A. Deep Transfer Learning: A new deep learning glitch classification method for advanced LIGO. arXiv 2017, arXiv:1706.07446. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sajjad, M.; Kwon, S. Clustering-based speech emotion recognition by incorporating learned features and deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Sharmin, R.; Rahut, S.K.; Huq, M.R. Bengali Spoken Digit Classification: A Deep Learning Approach Using Convolutional Neural Network. Procedia Comput. Sci. 2020, 171, 1381–1388. [Google Scholar] [CrossRef]
- Shinde, A.S.; Patil, V.V. Speech Emotion Recognition System: A Review. SSRN 3869462. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3869462 (accessed on 10 October 2023).
- Deb, S.; Dandapat, S. Multiscale amplitude feature and significance of enhanced vocal tract information for emotion classification. IEEE Trans. Cybern. 2018, 49, 802–815. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Su, G.; Liu, L.; Wang, S. Wavelet packet analysis for speaker-independent emotion recognition. Neurocomputing 2020, 398, 257–264. [Google Scholar] [CrossRef]
- Swain, M.; Sahoo, S.; Routray, A.; Kabisatpathy, P.; Kundu, J.N. Study of feature combination using HMM and SVM for multilingual Odiya speech emotion recognition. Int. J. Speech Technol. 2015, 18, 387–393. [Google Scholar] [CrossRef]
- Kuchibhotla, S.; Vankayalapati, H.D.; Anne, K.R. An optimal two stage feature selection for speech emotion recognition using acoustic features. Int. J. Speech Technol. 2016, 19, 657–667. [Google Scholar] [CrossRef]
| Duration (s) | ASED | EMO-DB | RAVDESS | URDU |
|---|---|---|---|---|
| 1–2.0 | 126 | |||
| 2–3.0 | 850 | 224 | 200 | |
| 3.0–4 | 1624 | 136 | 1440 | 200 |
| 4.0–5 | 24 | |||
| 5.0–6 | 20 | |||
| 6.0–7 | 3 | |||
| 7.0–8 | 1 | |||
| 8.0–9 | 1 | |||
| STD | 0.444 | 1.067 | 0 | 0.5 |
| Mean | 2.967 | 2.267 | 3 | 2.5 |
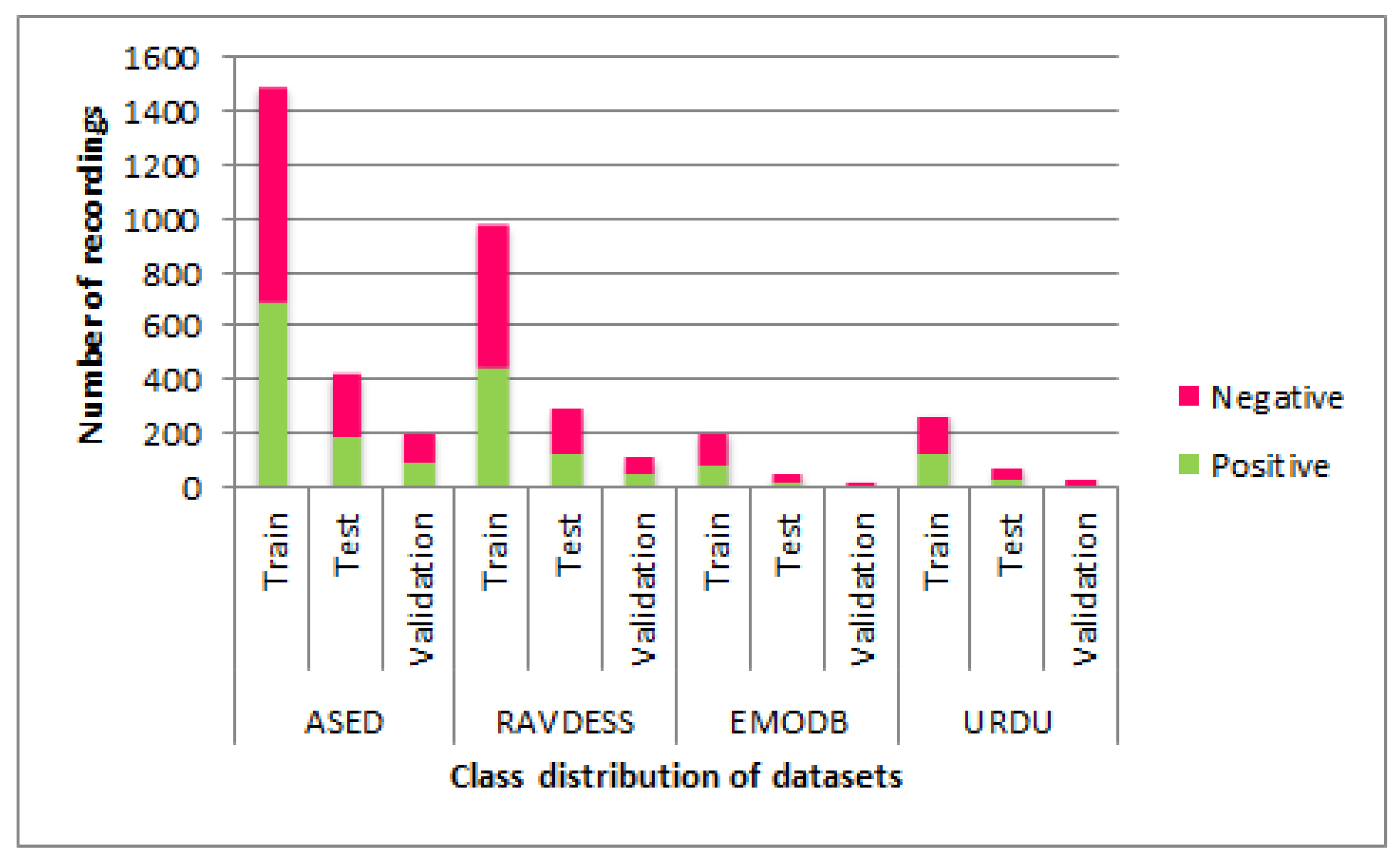
| Datasets | Train | Test | Validation | |||
|---|---|---|---|---|---|---|
| Labels | Positive | Negative | Positive | Negative | Positive | Negative |
| ASED | 693 | 804 | 199 | 230 | 99 | 115 |
| EMODB | 95 | 118 | 27 | 34 | 14 | 17 |
| RAVDESS | 456 | 524 | 140 | 160 | 56 | 64 |
| URDU | 140 | 138 | 40 | 40 | 20 | 22 |
| Model | ASED | EMO-DB | RAVDESS | URDU |
|---|---|---|---|---|
| AlexNet | 78.71 | 68.52 | 80.63 | 93.75 |
| VGGE | 84.76 | 85.19 | 83.13 | 70.00 |
| ResNet50 | 84.13 | 79.63 | 84.38 | 90.00 |
| Average | 82.53 | 77.78 | 82.71 | 84.58 |
| Model | ASED | EMO-DB | RAVDESS |
|---|---|---|---|
| AlexNet | 80.93 | 55.74 | 82.22 |
| VGGE | 86.63 | 70.49 | 83.33 |
| ResNet50 | 85.82 | 73.77 | 77.78 |
| Average | 84.46 | 66.67 | 81.11 |
| Model | Training | Testing | Accuracy | F1-Score |
|---|---|---|---|---|
| AlexNet | ASED | EMO-DB | 65.80 | 56.85 |
| EMO-DB | ASED | 62.39 | 58.53 | |
| ASED | RAVDESS | 66.00 | 53.17 | |
| RAVDESS | ASED | 65.87 | 55.57 | |
| ASED | URDU | 60.00 | 56.28 | |
| URDU | ASED | 50.67 | 48.45 | |
| Average | 61.79% | 54.81% | ||
| VGGE | ASED | EMO-DB | 66.67 | 52.55 |
| EMO-DB | ASED | 64.22 | 58.53 | |
| ASED | RAVDESS | 59.25 | 51.85 | |
| RAVDESS | ASED | 61.43 | 62.75 | |
| ASED | URDU | 59.69 | 56.34 | |
| URDU | ASED | 60.00 | 53.94 | |
| Average | 61.88% | 55.99% | ||
| ResNet50 | ASED | EMO-DB | 64.06 | 50.42 |
| EMO-DB | ASED | 58.72 | 45.94 | |
| ASED | RAVDESS | 61.75 | 48.68 | |
| RAVDESS | ASED | 64.16 | 52.66 | |
| ASED | URDU | 61.56 | 62.06 | |
| URDU | ASED | 61.33 | 60.03 | |
| Average | 61.93% | 53.30% |
| Model | Training | Testing | Accuracy | F1-Score |
|---|---|---|---|---|
| AlexNet | EMO-DB + RAVDESS | ASED | 69.06 | 61.28 |
| EMO-DB + URDU | ASED | 57.23 | 48.38 | |
| RAVDESS + URDU | ASED | 62.46 | 51.27 | |
| EMO-DB + RAVDESS + URDU | ASED | 69.77 | 62.30 | |
| Average | 64.63% | 55.81% | ||
| VGGE | EMO-DB + RAVDESS | ASED | 60.50 | 61.12 |
| EMO-DB + URDU | ASED | 69.94 | 65.26 | |
| RAVDESS + URDU | ASED | 66.89 | 64.56 | |
| EMO-DB + RAVDESS + URDU | ASED | 68.41 | 60.17 | |
| Average | 66.44% | 62.78% | ||
| ResNet50 | EMO-DB + RAVDESS | ASED | 61.33 | 43.52 |
| EMO-DB + URDU | ASED | 46.24 | 44.57 | |
| RAVDESS + URDU | ASED | 64.51 | 56.17 | |
| EMO-DB + RAVDESS + URDU | ASED | 63.18 | 62.32 | |
| Average | 58.82% | 51.65% |
| Training | Testing | AlexNet | VGGE | ResNet50 | Average Accuracy |
|---|---|---|---|---|---|
| EMO-DB + RAVDESS | ASED | 69.06 | 60.5 | 61.33 | 63.63 |
| EMO-DB + URDU | ASED | 57.23 | 69.94 | 46.24 | 57.80 |
| RAVDESS + URDU | ASED | 62.46 | 66.89 | 64.51 | 64.62 |
| EMO-DB + RAVDESS + URDU | ASED | 69.77 | 68.41 | 63.18 | 67.12 |
| Training | Testing | AlexNet | VGGE | ResNet50 | Average F1-Score |
| EMO-DB + RAVDESS | ASED | 61.00 | 61.21 | 43.44 | 55.31 |
| EMO-DB + URDU | ASED | 48.57 | 65.98 | 38.96 | 52.74 |
| RAVDESS + URDU | ASED | 51.64 | 64.63 | 56.23 | 57.33 |
| EMO-DB + RAVDESS + URDU | ASED | 62.45 | 60.28 | 62.99 | 59.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Retta, E.A.; Sutcliffe, R.; Mahmood, J.; Berwo, M.A.; Almekhlafi, E.; Khan, S.A.; Chaudhry, S.A.; Mhamed, M.; Feng, J. Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages. Appl. Sci. 2023, 13, 12587. https://doi.org/10.3390/app132312587
Retta EA, Sutcliffe R, Mahmood J, Berwo MA, Almekhlafi E, Khan SA, Chaudhry SA, Mhamed M, Feng J. Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages. Applied Sciences. 2023; 13(23):12587. https://doi.org/10.3390/app132312587
Chicago/Turabian StyleRetta, Ephrem Afele, Richard Sutcliffe, Jabar Mahmood, Michael Abebe Berwo, Eiad Almekhlafi, Sajjad Ahmad Khan, Shehzad Ashraf Chaudhry, Mustafa Mhamed, and Jun Feng. 2023. "Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages" Applied Sciences 13, no. 23: 12587. https://doi.org/10.3390/app132312587
APA StyleRetta, E. A., Sutcliffe, R., Mahmood, J., Berwo, M. A., Almekhlafi, E., Khan, S. A., Chaudhry, S. A., Mhamed, M., & Feng, J. (2023). Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages. Applied Sciences, 13(23), 12587. https://doi.org/10.3390/app132312587