
Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple Quantization Index Modulation

Abstract
:Featured Application
Abstract
1. Introduction
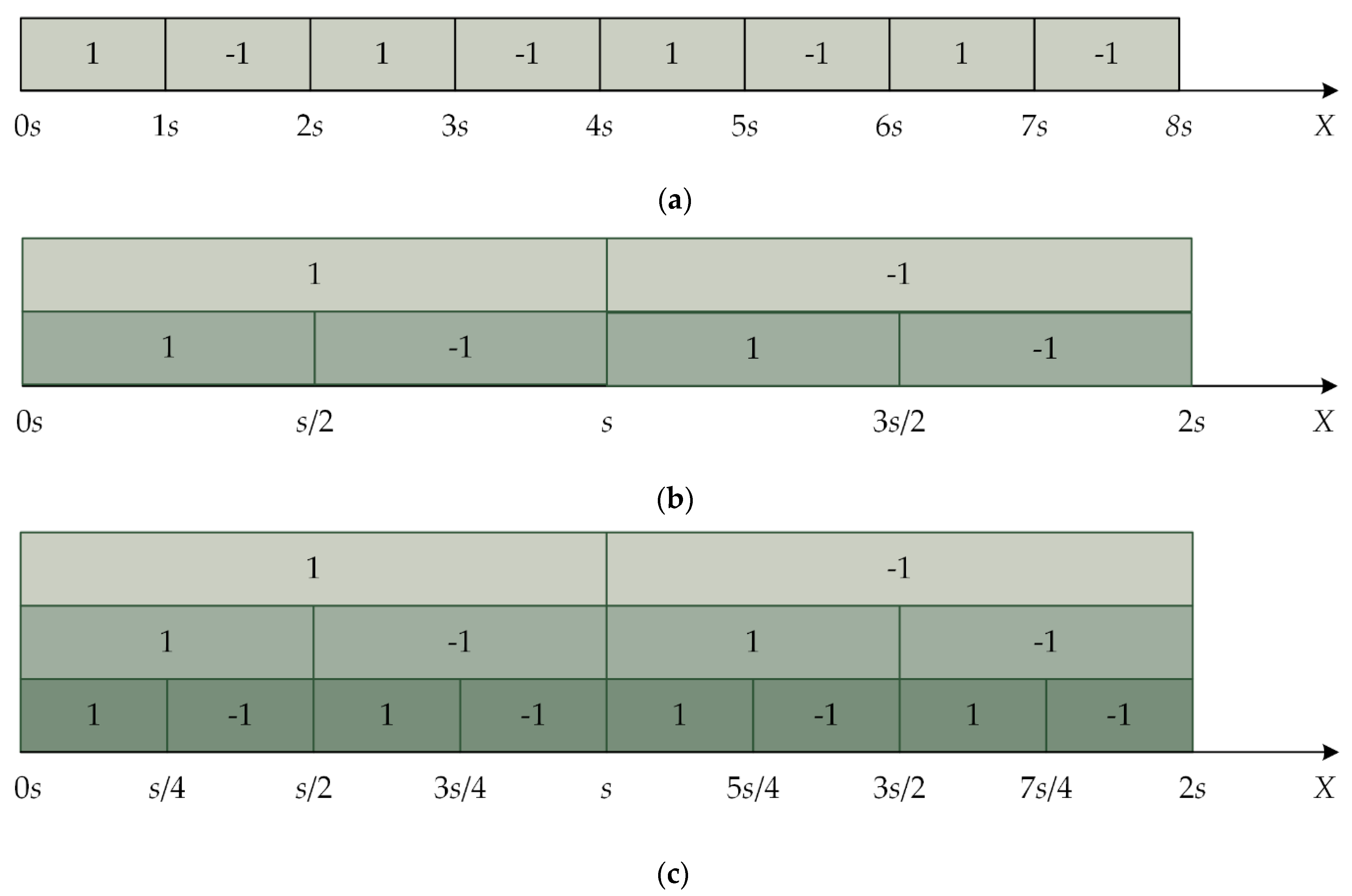
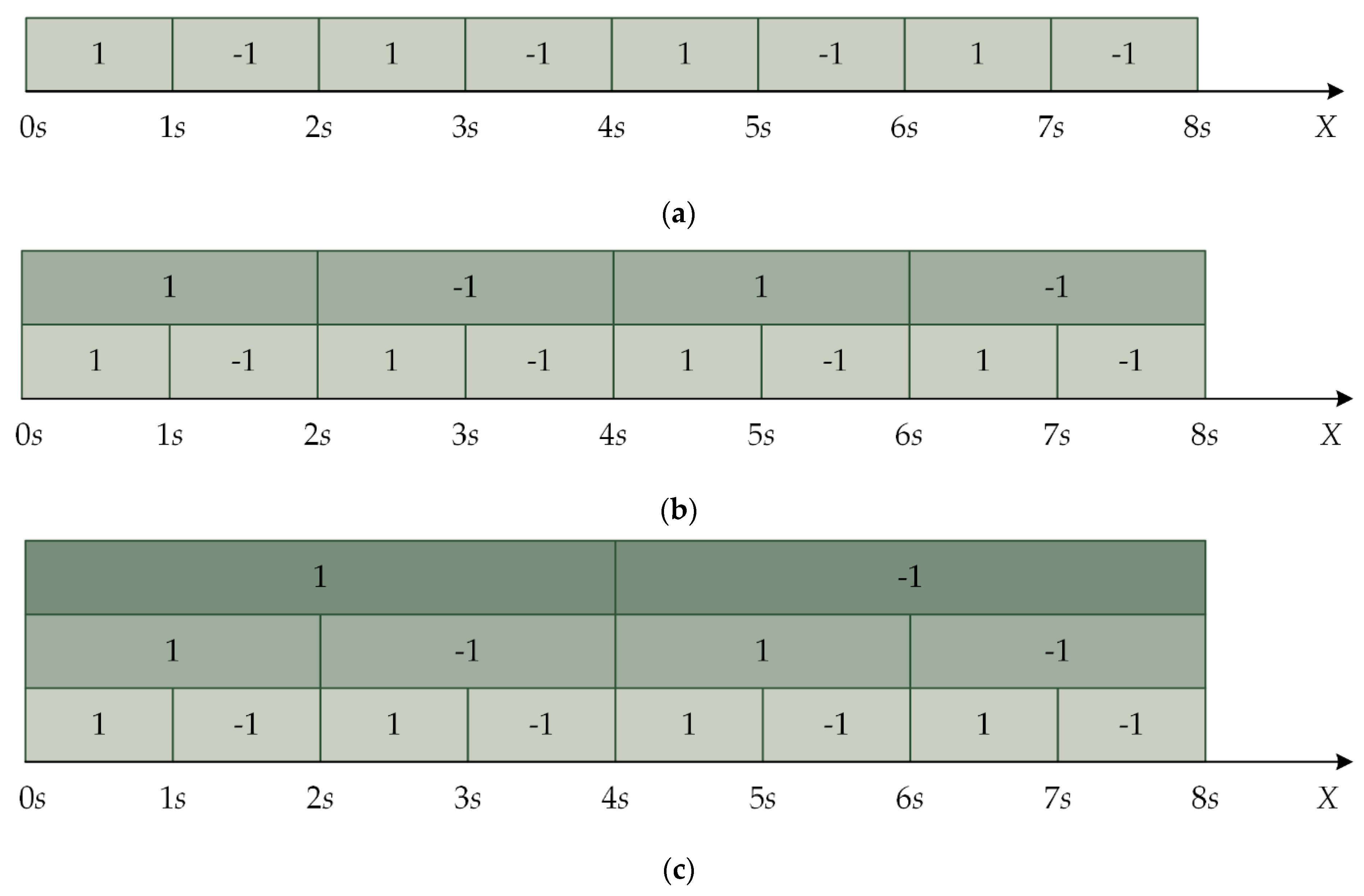
2. QIM and Multiple QIM
3. Proposed Multiple Watermarking Algorithm
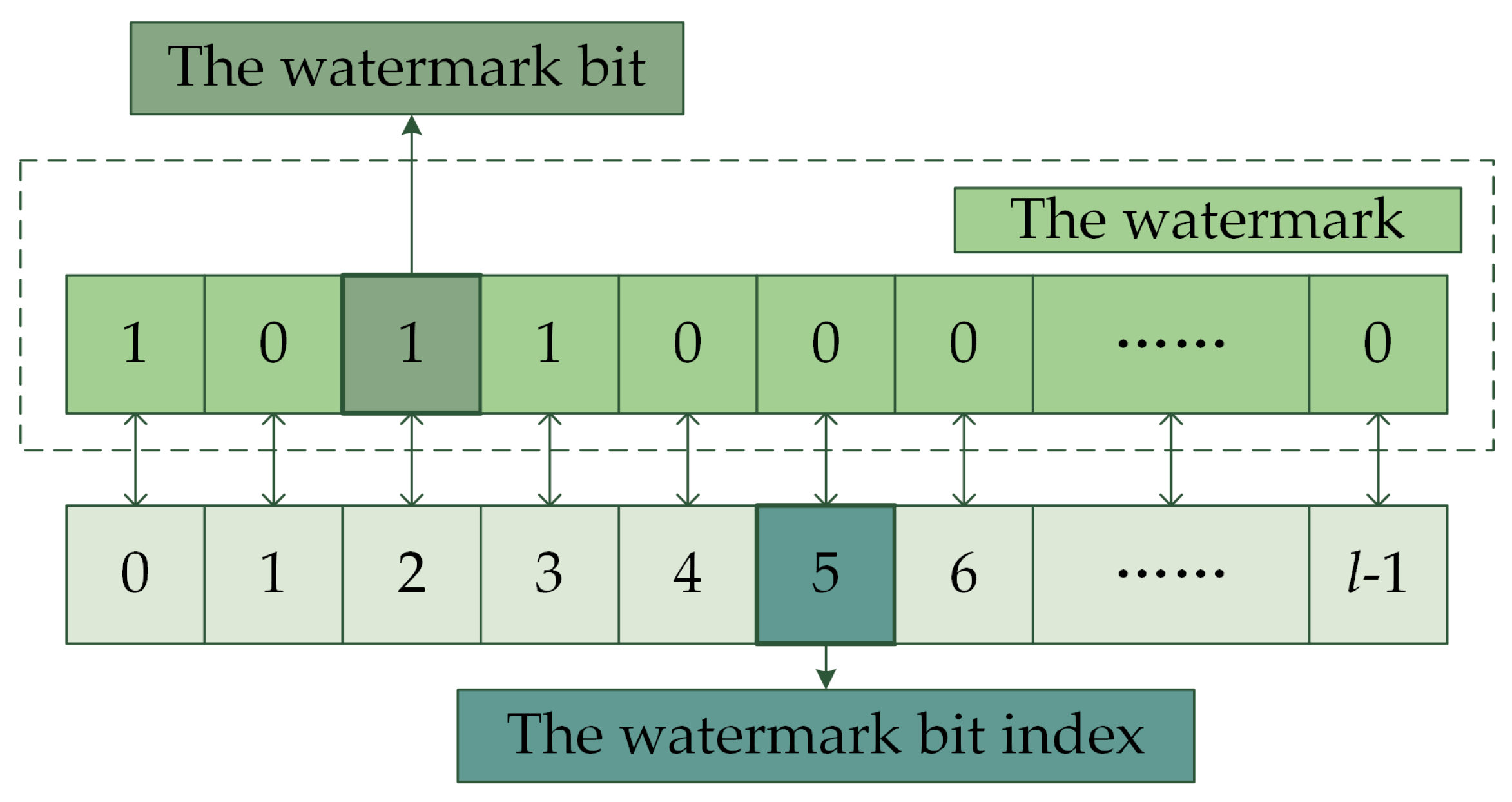
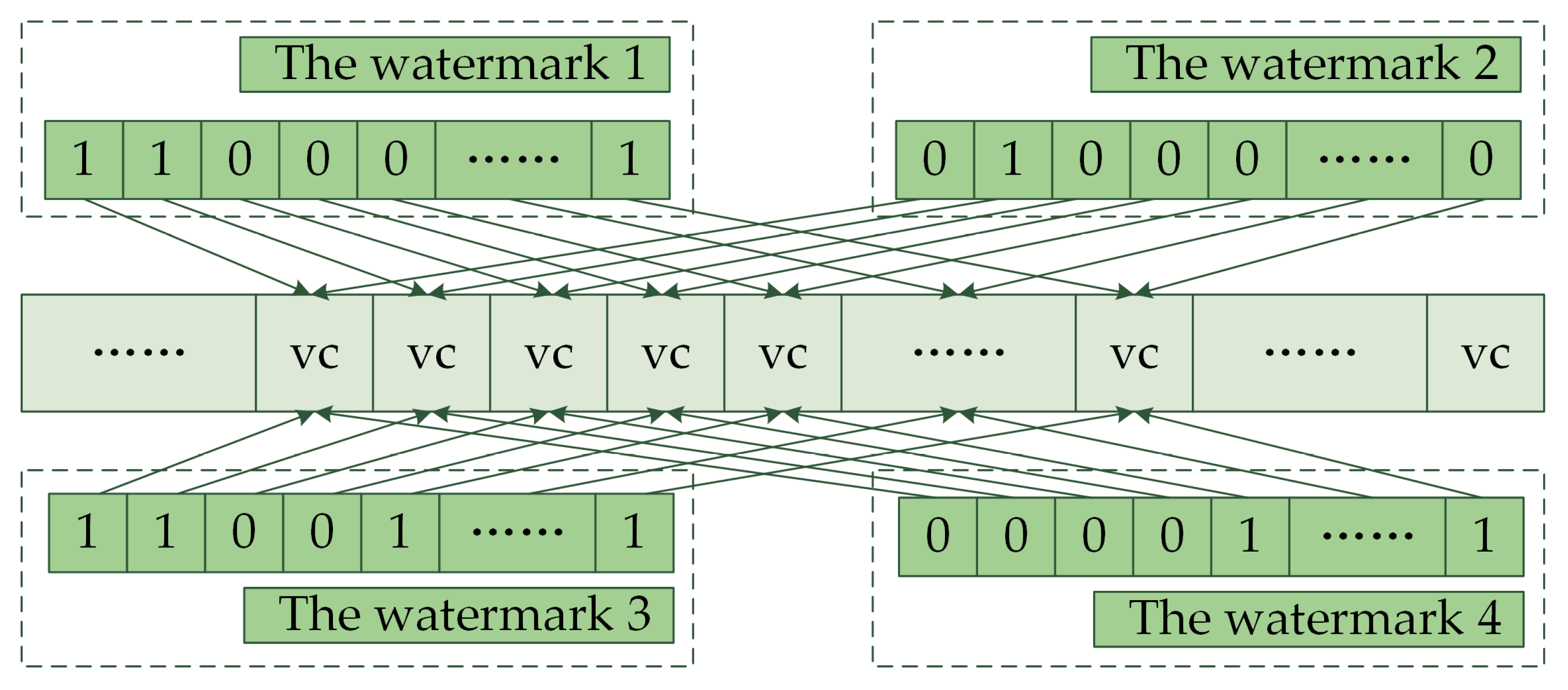
3.1. Watermark Generation
3.2. Watermark Embedding
- (1)
- Let the first quantization step size be , and the number of embedding watermarks be . The watermark index is initialized as , i.e., .
- (2)
- The index of the watermark bit is for the vertices . The index of the embedding watermark bit is .
- (3)
- According to step and the watermark index , the rules of the watermark bit embedding into the vertices are given in Equation (5):where is the coordinate of the th vertex embedded in the watermark corresponding to .
- (4)
- Steps (2) and (3) are not repeated until the watermark, , is embedded in the cover data.
- (5)
- If , the embedding of the watermark is finished; let and skip to Step (2).
3.3. Watermark Extraction and Detection
- (1)
- Let the initialized quantization step size be , and the value in the embedding process . Let the index of the extracting watermark be , and .
- (2)
- Initialize the watermark bits’ storage array, , and let .
- (3)
- For the vertices coordinates , the index of the watermark bit is calculated: .
- (4)
- The potential watermark bits in the vertices, , are extracted according to the following Equation (7):
- (5)
- Save the extracted watermark bits in , and .
- (6)
- For all coordinate vertices, steps (2) to (5) are repeated to extract all watermark sets, .
- (7)
- The relationship between the watermark bits and coordinate vertices is “many to one”, therefore, let if . Let if , and or randomly, if .
- (8)
- The original watermarks are correlated with the extracted watermarks in order to assess whether they are the original watermarks or not. These watermarks are stored if the extracted watermark is the embedded one; otherwise, let and skip to Step (2). The detection is not complete until .
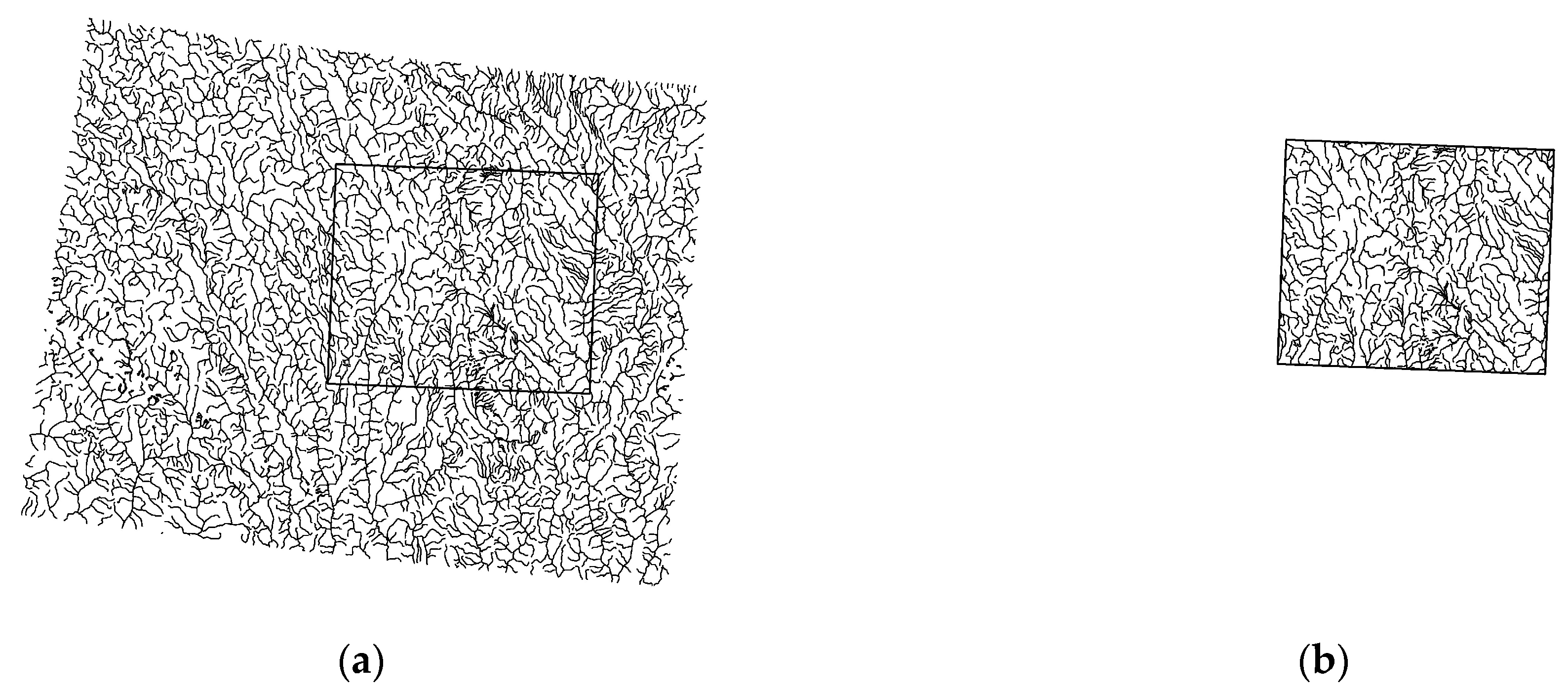
4. Experiments and Results
4.1. Algorithm Robustness
4.2. Algorithm Robustness for Data Containing Fewer Coordinate Vertices
4.3. Multiple Watermark Capacity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neyman, S.N.; Pradnyana, I.N.P.; Sitohang, B. A new copyright protection for vector map using FFT-based watermarking. Telecommun. Comput. Electron. Control 2014, 12, 367–378. [Google Scholar]
- Urvoy, M.; Goudia, D.; Autrusseau, F. Perceptual DFT watermarking with improved detection and robustness to geometrical distortions. IEEE Trans. Inf. Forensics Sec. 2014, 9, 1108–1119. [Google Scholar] [CrossRef]
- Lee, S.-H.; Huo, X.-J.; Kwon, K.-R. Vector watermarking method for digital map protection using arc length distribution. IEICE Trans. Inf. Syst. 2014, 97, 34–42. [Google Scholar] [CrossRef]
- Peng, Z.; Yue, M.; Wu, X.; Peng, Y. Blind watermarking scheme for polylines in vector geo-spatial data. Multimed. Tools Appl. 2015, 74, 11721–11739. [Google Scholar] [CrossRef]
- Wang, N.N.; Zhao, X.J. 2D vector map data hiding with directional relations preservation between points. AEU-Int. J. Electron. Commun. 2017, 71, 118–124. [Google Scholar] [CrossRef]
- Tong, D.; Ren, N.; Shi, W.; Zhu, C. A computational model of watermark algorithmic robustness capable of resisting image cropping for remote sensing images. Sensors 2018, 18, 2096. [Google Scholar] [CrossRef]
- Zhou, Q.; Ren, N.; Zhu, C.; Tong, D. Storage feature-based watermarking algorithm with coordinate values preservation for vector line data. KSII T Internet Inf. 2018, 12, 3475–3496. [Google Scholar]
- Wang, S.; Zhang, L.; Zhang, Q.; Li, Y. A zero-watermarking algorithm for vector geographic data based on feature invariants. Earth Sci Inf. 2023, 16, 1073–1089. [Google Scholar] [CrossRef]
- Ren, N.; Tong, D.; Cui, H.; Zhu, C.; Zhou, Q. Congruence and geometric feature-based commutative encryption-watermarking method for vector maps. Comput. Geosci. 2022, 159, 105009. [Google Scholar] [CrossRef]
- Guo, X.; Jiang, W.; Zhang, Q.; Wang, K. Digital protection technology of cultural heritage based on ARCGIS geographic information technology algorithm. Secur. Commun. Netw. 2022, 2022, 3844626. [Google Scholar] [CrossRef]
- Qu, C.Y.; Xi, X.; Du, J.L.; Wu, T. Robust Watermarking Scheme for Vector Geographic Data Based on the Ratio Invariance of DWT-CSVD Coefficients. ISPRS Int. J. Geo-Inf. 2022, 11, 583. [Google Scholar] [CrossRef]
- Xi, X.; Zhang, X.; Liang, W.; Xin, Q.; Zhang, P. Dual zero-watermarking scheme for two-dimensional vector map based on delaunay triangle mesh and singular value decomposition. Appl. Sci. 2019, 9, 642. [Google Scholar] [CrossRef]
- Wang, B.; Jiawei, S.; Wang, W.; Zhao, P. Image copyright protection based on blockchain and zero-watermark. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2188–2199. [Google Scholar] [CrossRef]
- Chen, T.H.; Hung, T.H.; Horng, G.; Chang, C.M. Multiple watermarking based on visual secret sharing. INT J. Innov. Comput. I 2008, 4, 3005–3026. [Google Scholar]
- Cai, L.J.; Li, R.; Yi, Y.Q. A multiple watermarks algorithm for image content authentication. J. Cent. South Univ. 2012, 19, 2866–2874. [Google Scholar] [CrossRef]
- Bhatnagar, G.; Wu, Q.M.J. A new robust and efficient multiple watermarking scheme. Multimed. Tools Appl. 2015, 74, 8421–8444. [Google Scholar] [CrossRef]
- Liu, J.; Li, J.; Ma, J.; Sadiq, N.; Bhatti, U.A.; Ai, Y. A robust multi-watermarking algorithm for medical images based on DTCWT-DCT and Henon map. Appl. Sci. 2019, 9, 700. [Google Scholar] [CrossRef]
- Wang, K.; Gao, T.; You, D.; Wu, X.; Kan, H. A secure dual-color image watermarking scheme based 2D DWT, SVD and Chaotic map. Multimed. Tools Appl. 2022, 81, 6159–6190. [Google Scholar] [CrossRef]
- Zeng, F.; Bai, H.; Xiao, K. Blind watermarking algorithm combining NSCT, DWT, SVD, and HVS. Secur. Priv. 2022, 5, e223. [Google Scholar] [CrossRef]
- Yuan, X.C.; Li, M. Local multi-watermarking method based on robust and adaptive feature extraction. Signal Process. 2018, 149, 103–117. [Google Scholar] [CrossRef]
- Darwish, S.M.; Hassan, O.F. A new colour image copyright protection approach using evolution-based dual watermarking. J. Exp. Theor. Artif. 2021, 33, 945–967. [Google Scholar] [CrossRef]
- Xiong, L.; Xu, Z.; Xu, Y. A multiple watermarking scheme based on orthogonal decomposition. Multimed. Tools Appl. 2016, 75, 5377–5395. [Google Scholar] [CrossRef]
- Wang, X.; Yuan, X.; Li, M.; Sun, Y.; Tian, J.; Guo, H.; Li, J. Parallel multiple watermarking using adaptive Inter-Block correlation. Expert Syst. Appl. 2023, 213, 119011. [Google Scholar] [CrossRef]
- Zuo, M.J.; Cheng, S.; Gong, L.H. Secure and robust watermarking scheme based on the hybrid optical bi-stable model in the multi-transform domain. Multimed. Tools Appl. 2022, 81, 17033–17056. [Google Scholar] [CrossRef]
- Li, Q.; Min, L.Q.; He, Z.H.; Yang, Y.Q. A solution research on multiple watermark embedding. Sci. Surv. Mapp. 2011, 36, 119–120. [Google Scholar]
- Zhao, X.; Li, L. A multiple watermarking of multi-media for relational databases. Microelectron. Comput. 2013, 30, 122–125. [Google Scholar]
- Zhou, L.M.N.; Wu, H.Z. Multi-party watermark embedding with frequency-hopping sequences. Cryptogr. Commun. 2022, 14, 307–318. [Google Scholar] [CrossRef]
- Peng, Y.W.; Lan, H.; Yue, M.L.; Xue, Y. Multipurpose watermarking for vector map protection and authentication. Multimed. Tools Appl. 2018, 77, 7239–7259. [Google Scholar] [CrossRef]
- Liang, W.; Zhang, X.; Xi, X.; Zhang, P. A multiple watermarking algorithm for vector geographic data based on zero-watermarking and fragile watermarking. Acta Sci. Naturaum Univ. Sunyatseni 2018, 57, 7–14. [Google Scholar]
- Cao, Y.; Xiao, J.; Zhang, W. A multiple watermarking algorithm for vector map based on zero watermark and reversible watermark. J. South China Norm. Univ. (Nat. Sci. Ed.) 2016, 48, 69–74. [Google Scholar]
- Wei, C. A Multiple Watermarking Algorithm for GIS Vector Data. Master’s Thesis, Lanzhou Jiaotong University, Lanzhou, China, 2014. [Google Scholar]
- Zhang, L.M.; Yan, H.W.; Zhu, R.; Du, P. Combinational spatial and frequency domains watermarking for 2D vector maps. Multimed. Tools Appl. 2020, 79, 31375–31387. [Google Scholar] [CrossRef]
- Cao, J.H.; Li, A.B.; Lv, G.N. Study on multiple watermarking scheme for GIS vector data. In Proceedings of the 18th International Conference on Geo-Informatics, Beijing, China, 1 July 2010. [Google Scholar]
- Cui, H.C. Research on the Sharing Security of Vector Geography Data. Ph.D. Thesis, Nanjing Normal University, Nanjing, China, 2013. [Google Scholar]
- Wang, Y.; Yang, C.; Zhu, C. A multiple watermarking algorithm for vector geographic data based on coordinate mapping and domain subdivision. Multimed. Tools Appl. 2018, 77, 19261–19279. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, C.; Zhu, C.; Ding, K. An efficient robust multiple watermarking algorithm for vector geographic data. Information 2018, 9, 296. [Google Scholar] [CrossRef]
- Sun, J.G.; Men, C.G.; Zhang, G.Y. Static dual watermarking of vector maps to anti-interpretation attacks. J. Harbin Eng. Univ. 2010, 31, 488–495. [Google Scholar]
- Qiu, Y.; Duan, H. A novel multi-stage watermarking scheme of vector maps. Multimed. Tools Appl. 2021, 80, 877–897. [Google Scholar] [CrossRef]
- Chen, B.; Wornell, G.W. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory 2001, 47, 1423–1442. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Can. Cart. 1973, 10, 112–122. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Watermarks | Intervals of Cover Coordinate Vertices | Watermark Bits |
|---|---|---|
| First watermark | −1 | |
| 1 | ||
| Second watermark | −1 | |
| 1 | ||
| Third watermark | −1 | |
| 1 |
| Watermarks | Intervals of Cover Coordinate Vertices | Watermark Bits |
|---|---|---|
| First watermark | −1 | |
| 1 | ||
| Second watermark | −1 | |
| 1 | ||
| Third watermark | −1 | |
| 1 |
| Attacks | Attacks Intensity | Detected Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| No attacks | 0% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| Deleting features | 30% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| 50% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 70% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 90% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No.9–10) | √ (No. 1–10) | √ (No. 10) | |
| Cropping | 10–20% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| 40–50% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 70–80% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 80–90% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No.9–10) | √ (No. 1–10) | √ (No. 10) | |
| Adding vertices | 30% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| 50% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 70% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| 90% | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | |
| Attacks | Attacks Intensity | Detected Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| No attacks | 0% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| Deleting vertices | 30% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| 50% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 70% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 90% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 18–20) | |
| Deleting features | 30% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| 50% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 70% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 90% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 18–20) | |
| Cropping | 10–20% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| 40–50% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 70–80% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 80–90% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 19–20) | |
| Compression | 10–20% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| 20–30% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 30–40% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 40–50% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 16–20) | √ (No. 11–20) | √ (No. 17–20) | |
| Adding vertices | 30% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| 50% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 70% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| 90% | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | |
| Attacks | Attacks Intensity | Detected Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| No attacks | 0% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| Deleting vertices | 30% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| 50% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 70% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 90% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 29–30) | |
| Deleting features | 30% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| 50% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 70% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 90% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 28–30) | √ (No. 21–30) | √ (No. 29–30) | |
| Cropping | 10–20% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| 40–50% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 70–80% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 80–90% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 30) | |
| Compression | 10–20% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| 20–30% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 30–40% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 30) | |
| 40–50% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | × | |
| Adding vertices | 30% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| 50% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 70% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| 90% | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | |
| Uniform Noise Attacks | Detected Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| a = −1.0 | b = 1.0 | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| a = −2.0 | b = 2.0 | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) |
| a = −3.0 | b = 3.0 | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | × | √ (No. 1–10) | × |
| a = −4.0 | b = 4.0 | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | × | × | × | × |
| a = −5.0 | b = 5.0 | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | √ (No. 1–10) | × | × | × | × |
| Uniform Noise Attacks | Detected Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| a = −1.0 | b = 1.0 | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| a = −2.0 | b = 2.0 | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) |
| a = −3.0 | b = 3.0 | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 19–20) | √ (No. 11–20) | √ (No. 19–20) |
| a = −4.0 | b = 4.0 | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | × | × | × |
| a = −5.0 | b = 5.0 | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | √ (No. 11–20) | × | × | × | × |
| Uniform Noise Attacks | Detected Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| a = −1.0 | b = 1.0 | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| a = −2.0 | b = 2.0 | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) |
| a = −3.0 | b = 3.0 | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 18–30) | √ (No. 21–30) | √ (No. 30) |
| a = −4.0 | b = 4.0 | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | × | × | × |
| a = −5.0 | b = 5.0 | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | √ (No. 21–30) | × | × | × | × |
| No. | Data Type | Data Size | No. | Data Type | Data Size | No. | Data Type | Data Size | No. | Data Type | Data Size |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Point | 437 | 6 | Point | 1191 | 11 | Polyline | 2486 | 16 | Polygon | 2108 |
| 2 | Point | 511 | 7 | Point | 2797 | 12 | Polyline | 3541 | 17 | Polygon | 2301 |
| 3 | Point | 756 | 8 | Point | 3568 | 13 | Polyline | 4653 | 18 | Polygon | 3246 |
| 4 | Point | 1158 | 9 | Point | 4972 | 14 | Polyline | 4977 | 19 | Polygon | 4983 |
| 5 | Point | 1514 | 10 | Point | 5657 | 15 | Polyline | 5321 | 20 | Polygon | 5269 |
| Attacks | Attacks Intensity | Detected Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| No attacks | 0 | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) |
| Deleting vertices | 15% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) |
| 30% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | |
| 45% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 9, 10, 13, 14, 15, 19, 20) | √ (No. 1–20) | √ (No. 9, 10, 14, 15, 19, 20) | |
| 60% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | × | √ (No. 1–20) | × | √ (No. 1–20) | × | |
| Cropping | 10–20% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) |
| 20–30% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | |
| 30–40% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | × | √ (No. 1–20) | √ (No. 9, 10, 14, 15, 19, 20) | |
| 40–50% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | × | √ (No. 1–20) | × | √ (No. 1–20) | × | |
| Adding vertices | 30% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) |
| 60% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | |
| 100% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | |
| 200% | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | |
| Uniform Noise Attacks | Detected Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Watermark 1 | Watermark 2 | Watermark 3 | Watermark 4 | ||||||
| Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | Proposed Algorithm | Reference [35] Algorithm | ||
| a = −1.0 | b = 1.0 | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) |
| a = −2.0 | b = 2.0 | √ (No. 1–20) | √ (No. 1–20) | √ (No. 1–20) | × | √ (No. 1–20) | × | √ (No. 1–20) | × |
| a = −3.0 | b = 3.0 | × | × | × | × | × | × | × | × |
| a = −4.0 | b = 4.0 | × | × | × | × | × | × | × | × |
| a = −5.0 | b = 5.0 | × | × | × | × | × | × | × | × |
| No. | Data Type | Data Size | Multiple Watermark Capacity | |
|---|---|---|---|---|
| Proposed Algorithm | Reference [36] Algorithm | |||
| 1 | Point | 437 | ≥16 | 1 |
| 2 | Point | 511 | ≥16 | 1 |
| 3 | Point | 756 | ≥16 | 2 |
| 4 | Point | 1158 | ≥16 | 3 |
| 5 | Point | 1514 | ≥16 | 4 |
| 6 | Point | 1911 | ≥16 | 5 |
| 7 | Polygon | 2108 | ≥16 | 5 |
| 8 | Polygon | 2301 | ≥16 | 6 |
| 9 | Point | 2797 | ≥16 | 7 |
| 10 | Polygon | 3246 | ≥16 | 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yang, C.; Ding, K. Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple Quantization Index Modulation. Appl. Sci. 2023, 13, 12390. https://doi.org/10.3390/app132212390
Wang Y, Yang C, Ding K. Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple Quantization Index Modulation. Applied Sciences. 2023; 13(22):12390. https://doi.org/10.3390/app132212390
Chicago/Turabian StyleWang, Yingying, Chengsong Yang, and Kaimeng Ding. 2023. "Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple Quantization Index Modulation" Applied Sciences 13, no. 22: 12390. https://doi.org/10.3390/app132212390
APA StyleWang, Y., Yang, C., & Ding, K. (2023). Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple Quantization Index Modulation. Applied Sciences, 13(22), 12390. https://doi.org/10.3390/app132212390