1. Introduction
Anomaly detection in time series data has been a significant research topic for a number of applications such as intrusion detection in cybersecurity [
1], fraud detection in finance [
2], and damage detection in manufacturing [
3]. Anomalies in time series data can be classified into point-wise and segment-wise anomalies [
4]. Point-wise anomalies refer to unexpected events that occur at individual time points, typically having extreme values compared to the rest of the time points, or relatively deviated values from their neighboring points. In contrast, segment-wise anomalies typically are anomalous subsequences.
The time series anomaly detection task is to identify where a given time series (a sequence of real values) , where T is the length of X, contains any anomalous events. This is commonly carried out by producing an output label sequence , where indicates whether its corresponding value is anomalous or not.
Various methods have been developed for the task, which can be categorized into five approaches: statistical [
5,
6,
7,
8,
9], signal analysis (SA) [
10,
11,
12], system-modeling-based [
13], machine learning (ML) [
14,
15,
16,
17,
18,
19], and deep learning (DL) [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43]. The statistical approach involves the creation of a statistical model by calculating distributions and measures such as mean, variance, median, quantile, and others. The SA-based approach utilizes time–frequency domain analysis techniques like the Fourier transform, to identify anomalies. The system-modeling-based approach constructs a mathematical model such as a Bayesian dynamic linear model [
13] that simulates the latent process to produce the time series of interest. The ML-based approach constructs a trained model for anomaly detection using unlabeled and/or labeled data. The DL-based approach, which has recently gained significant attention, makes use of DL models for anomaly detection, and has found widespread adoption, achieving numerous successes across diverse application domains. Despite the successes of DL models in various applications, the performance of DL-based anomaly methods in the time series domain has not yet been as convincing as expected. To date, DL-based anomaly methods still suffer from the data scarcity problem caused by rare anomalous events and rare labeled data.
Instead of using supervised learning techniques based on labeled data, the DL-based anomaly methods usually employ one of three unsupervised or self-supervised techniques: forecasting-based, reconstruction-based, or one-class classifier techniques. Forecasting-based techniques involve forecasting the value for the next time point from the preceding data. Any significant deviation between the predicted and actual value suggests an anomaly. Reconstruction-based techniques build a model to reconstruct the output similar to its input; discrepancies between the model’s output and the actual data can indicate anomalies. One-class classifier techniques construct a classifier model for only normal data and leverage this model to determine if a given value of interest belongs to the normal class or not, thus enabling anomaly detection.
Contrastive learning on unlabeled data has emerged as an effective technique for learning representations useful to downstream tasks. The learning technique has shown potential in anomaly detection task for time series data [
44,
45,
46], especially when available training data does not include anomaly events. The performance of contrastive learning is strongly affected by the approach used to generate positive and negative samples from available unlabeled data. In time series data anomaly detection, it is also challenging to find out an appropriate sample generation method.
Motivated by the successes of reconstruction-based learning techniques and the potential of contrastive learning for unlabeled data, we propose a novel method for anomaly detection in time-series data, called CL-TAD (Contrastive-Learning-based method for Times series Anomaly Detection). The key aspects of the proposed method are as follows:
The CL-TAD method is comprised of two main components: positive sample generation and contrastive-learning-based representation learning. The first component plays role of generating positive samples from normal time series data. This is accomplished through a reconstruction process that tries to recover the original data from masked data. This reconstruction-based sampling is expected to augment a scarce original dataset into a robust and large training dataset that retains the essential information of normal patterns. The second component applies a contrastive learning technique to both the generated samples and the original data to produce their representations. Instead of directly producing the representations for generated samples, a transformation function with learnable parameters is applied to those samples to extract more meaningful information. The employed learnable transformation is attributed to learning more effective representations for anomaly detection.
The CL-TAD method employs a temporal convolutional network (TCN) [
47] for temporal feature extraction within time series data. The TCN is used in both positive sample generation and representation learning components.
The proposed method uses a reconstruction-based data augmentation for the normal time series dataset to generate a sufficient amount of training data. On training the model for anomaly detection, it uses only the original data and their augmented data, and hence it is a nonsupervised learning approach that does not require the labeling task over the training data.
To evaluate the effectiveness of our proposed method, we conducted some experiments on the following well-known nine benchmark datasets for time series anomaly detection: Power demand [
21,
27], ECG and 2D-Gesture [
21,
27], UCR and SMD [
43], PSM [
42], MSL [
43], SWaT [
42], and WADI [
42]. The performance of the proposed method has been compared with those of 10 recently developed anomaly detection methods: MAD-GAN [
32], DAGMM [
22], MSCRED [
36], CAE-M [
28], OmiAnomaly [
30], TranAD [
42], GDN [
29], Anomaly Transformer [
42], MTAD-GAT [
38], and USAD [
39]. The experimental results have demonstrated that the proposed method achieved competitive performance on all of these datasets. Notably, the proposed method achieved the best performance on the following nine benchmark datasets: Power Demand, UCR, ECG, 2D-Gesture, PSM, SMD, MSL, SWaT, and WADI.
The remainder of the paper is organized as follows:
Section 2 describes some related works on time series anomaly detection.
Section 3 presents the proposed anomaly detection method in detail. In
Section 4, we present the experimental results of the proposed method, comparing it with several recent anomaly detection methods using nine benchmark datasets. Finally,
Section 5 draws conclusions about the proposed method.
2. Related Works
This section first briefly describes the deep-learning-based approaches to time series anomaly detection. Then it delves into how contrastive learning techniques can be used in time series anomaly detection. After that, it presents the temporal convolutional network (TCN) that is used in the proposed method.
2.1. Deep-Learning-Based Approaches to Time Series Anomaly Detection
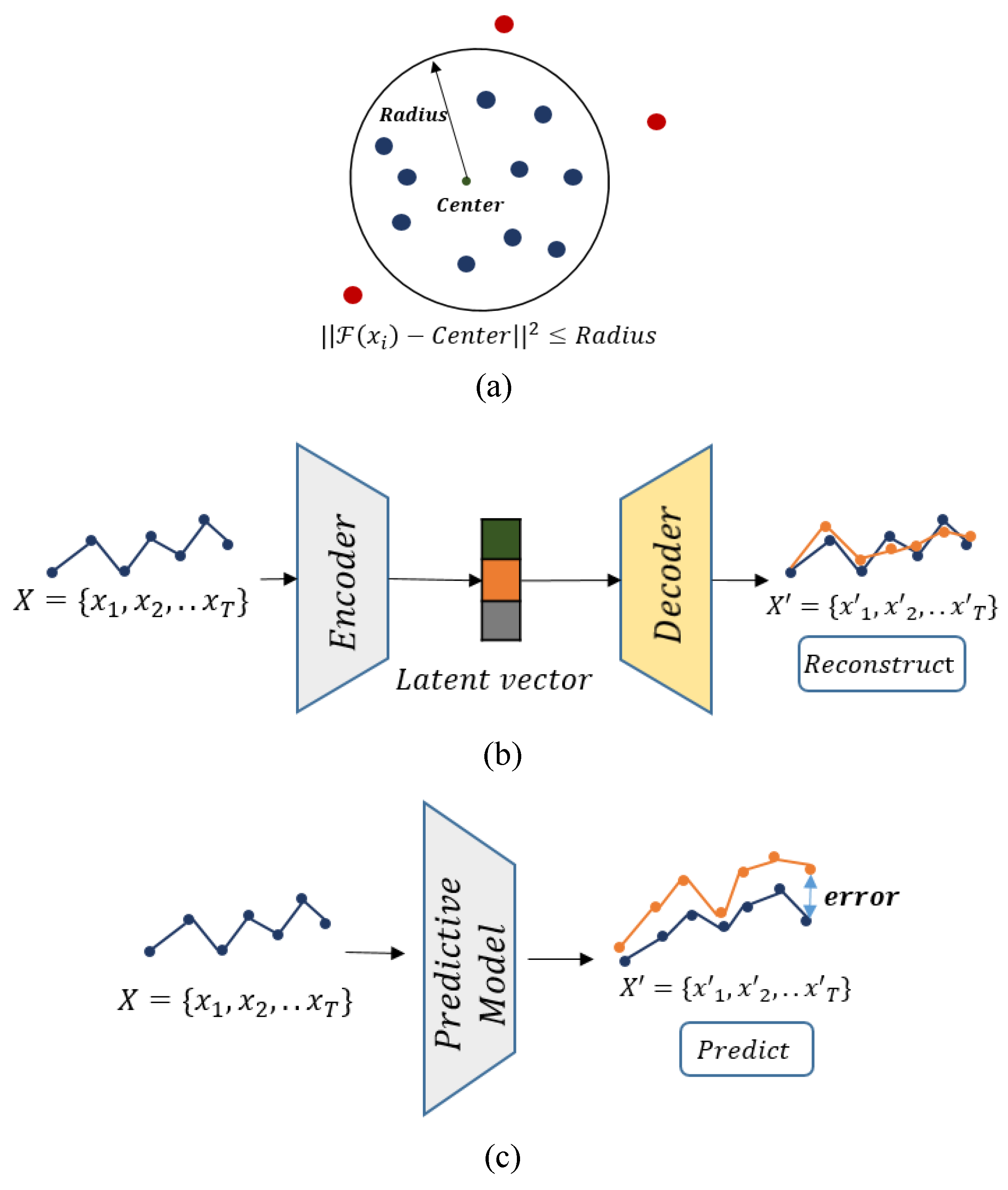
As illustrated in
Figure 1, the existing anomaly detection methods for time series data can be categorized into three primary approaches: one-class-classification-based, reconstruction-based, and prediction-based. One-class-classification-based methods employ a one-class classifier to identify anomalies. These methods define a latent hypersphere, where points falling inside the hypersphere are considered normal, while anomalies reside outside of it. The one-class classifier learns to differentiate between normal and anomalous data points, enabling the detection of anomalies in the time series data.
Reconstruction-based methods in time series anomaly detection often leverage the effectiveness of encoder–decoder models or their variants, which have achieved notable successes in solving reconstruction problems in computer vision. These methods aim to reconstruct the input time series data using an encoder–decoder architecture, where the quality of the reconstructed output serves as an indicator of anomalies. That is, the deviations or discrepancies of the input and reconstructed data can be used to identify anomalies, the larger difference, the higher the possibility of anomalies at the corresponding time points.
Lastly, prediction-based methods aim to forecast future values by training a predictive model. The predicted values are then compared with the actual values, allowing the identification of anomalies based on the discrepancies between them. By detecting significant deviations between the predicted and actual values, anomalies in the time series can be identified.
In both reconstruction-based and prediction-based methods, a predefined threshold, denoted as
, is commonly employed to determine whether a specific time point is anomalous. During the inference phase to identify anomaly events, the label
of a new data point at time step
t is assigned to an anomaly if the corresponding anomaly score
exceeds the threshold
, as described in Equation (
1).
where
represents the label assigned to the
t-th data point,
quantifies the degree of abnormality or deviation of a data point from the normal patterns, and
is a prespecified threshold.
DL-based approaches have significantly pushed up performance levels, yet they still fall short of the benchmark required for deployment in various real-world applications. One key reason for this unsatisfactory performance lies in the scarcity of time series training data. In time series anomaly detection, the quantity of time series data illustrating normal patterns is sometimes insufficient, let alone the severe lack of data representing anomalous events.
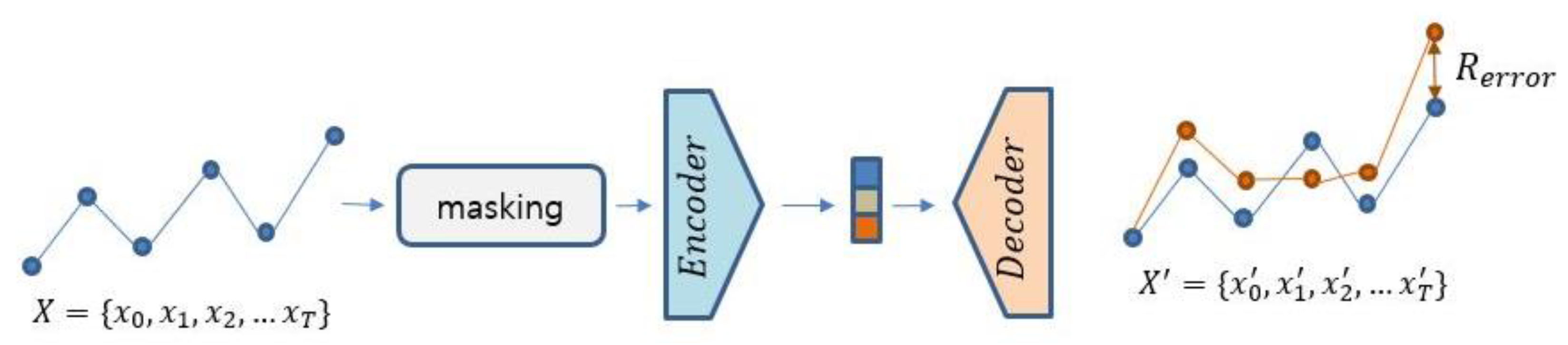
To tackle the issue of data scarcity, data augmentation techniques have been employed in deep learning, particularly in computer vision tasks. A reconstruction-based approach can leverage a masking technique to augment the training data available for building a reconstruction model. Deep-FIB [
21] exemplifies such a method; it trains a reconstruction model using masked time series data. As illustrated in
Figure 2, this method utilizes an encoder–decoder model to reconstruct the original time series from its masked series. Once such a model is trained, it is used to reconstruct the given input and then the reconstructed value is compared with its actual input to determine its anomaly. In the reconstruction-based approach, the masking strategy is important in building a model to extract meaningful characteristics for reconstruction. There are two main issues to be considered in the masking strategy: The first issue involves determining the amount of masking portion for input time series. Either overmasking or undermasking can cause a negative effect on the reconstruction capability of the model. Striking the right balance is crucial to ensure high performance. The second issue is about the masking value to be filled in the masked locations. Normalization of input time series sometimes needs to be applied. This normalization can affect the masking value for the normalized time series data.
2.2. Contrastive Learning for Unlabeled Data
Contrastive learning is a self-supervised approach that can be used for representation learning of unlabeled data. An early application of contrastive learning was to learn representations of image data by contrasting similar and dissimilar samples [
48].
Figure 3 shows how a contrastive learning method usually works for image data: The method begins with generating positive images by applying predefined transformation functions
T to the original images in the initial dataset. Typical operations for transformation include color jitter, flipping, and rotation, as these operations are supposed to preserve the characteristic information about the image label. Negative samples are chosen randomly from the original image dataset, which are different from the anchor image. An encoder module
E is subsequently trained to make the representations of pairs of an anchor data sample and a positive sample similar while creating a substantial difference between the representations of pairs of an anchor data sample and a negative sample. However, in the time series domain, finding suitable transformation functions for all types of time series data is challenging as the transformation functions need to preserve the intrinsic temporal properties of the data.
Inspired by contrastive learning techniques that have been successful in computer vision, several contrastive learning methods have been proposed for time series analysis tasks (anomaly detection task [
44,
45,
46,
49], classification task [
50], and forecasting task [
51]). In time series anomaly detection tasks, contrastive-learning-based models are trained typically on a normal dataset that does not include anomaly events. They might differ in how to obtain similar (positive) and dissimilar (negative) samples from the dataset. It is important to use a sampling method appropriate to the application domain.
TS2Vec [
44] employs a contrastive-learning-based technique to obtain effective representations for anomaly detection. It randomly samples fixed-length subsequences from a time series dataset and projects them into a latent space using a learnable affine transformation. The projected vectors are then randomly masked and fed to a TCN (temporal convolutional network) [
47] to produce their representations. TS2Vec samples the overlapped subsequences and considers the adjacent subsequences as positive pairs. Additionally, it considers pairs of samples, generated by applying different transformation functions such as jitter, scaling, and permutation to a subsequence, as positive samples. Conversely, it treats as negative samples, the non-overlapped and non-adjacent samples from a time series instance and the pairs of subsequences from different time series instances. It trains an encoder model to produce the representations in a way that increases the similarities of the representations for anchor and positive pairs and decreases those of the representations of anchor and negative pairs. Experiments showed that the performance of representation learning is influenced by the employed transformation functions.
The COCA method [
45] builds a one-class classifier model for time series anomaly detection. It uses a contrastive learning technique to produce a latent space representation for normal data. To augment a training dataset, it applies transformation functions like jitter and scaling, the hyperparameters of which should be carefully chosen. It trains a TCN and LSTM-based encoder–decoder model to produce representations of time series data. On training the model, the pairs of original time series and their transformed series are used as positive pairs to enforce their latent representations to be sufficiently close with a contrastive learning technique. The COCA model is trained to minimize both the reconstruction loss of the encoder–decoder model and increase the similarities among the representations of the positive samples. It does not use negative pairs to train the model. The model is basically a deep SVDD model for a one-class classifier, and hence, it inherits the constraints of SVDD models.
Neutral AD [
46] is another contrastive-learning-based method used for anomaly detection in time series data. It employs learnable neural transformations to augment time series data instead of predefined transformations like jitter and scale. The transformation is implemented by a trainable feed-forward neural network. The original samples and their transformed samples are then fed into an encoder to map them into a latent space. The transformed samples are regarded as positive samples to their original sample, while all other transformed samples are regarded as negative samples. The parameters of both the transformation network and the encoder are trained to maximize the similarities between an original sample and a positive sample and minimize those between an original sample and a negative sample. The developers of Neutral AD have claimed that the learnable transformations of original data are valuable for data augmentation in time series applications.
In reconstruction-based anomaly detection for time series data, having an effective tool for augmenting training data is crucial. Proper sampling and transformation techniques play a significant role in enhancing the performance of time series anomaly detection. In our proposed method, we introduce a novel strategy to address this challenge and improve the overall process.
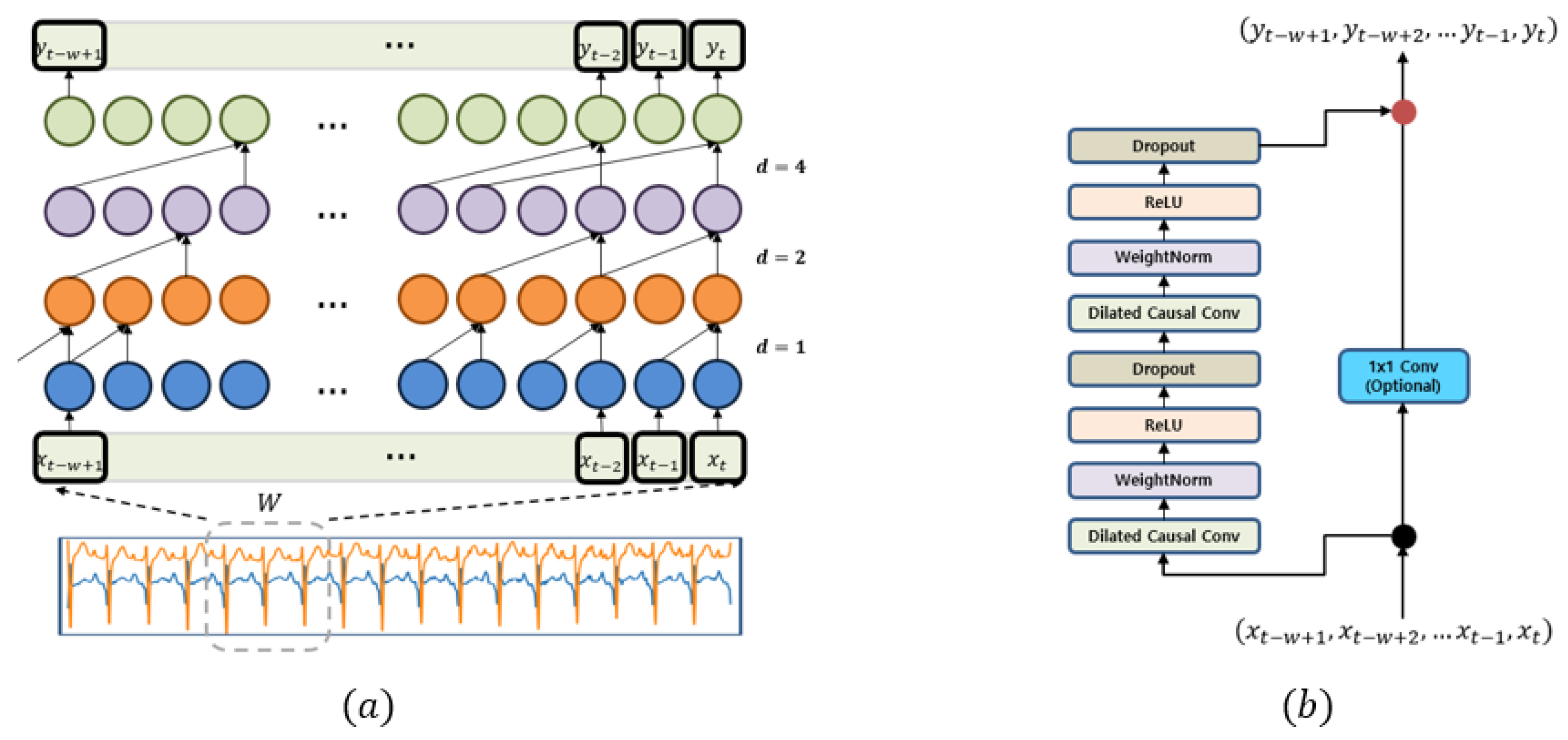
2.3. Temporal Convolution Network
Motivated by the successes of CNNs in high-level feature extraction for image data, 1D-CNNs have been employed in the time series domain [
20,
21]. It has been observed that 1D-CNNs are not good enough to extract long-dependency features [
47]. To address this issue, the Temporal Convolutional Neural Network (TCN) [
47] has been introduced; it is shown in
Figure 4. A TCN model consists of stacked residual blocks, each of which is a block of dilated and causal 1D convolutional layers with a skip connection. In a TCN model, higher layers have large dilation steps, so that higher layers receive more global features than lower layers. It is worth noting that TCN uses causal 1D convolutions that do not refer to future information. Our proposed method uses the TCN architecture to extract features from time series data.
3. The Proposed Method for Time Series Anomaly Detection: CL-TAD
This section starts with the problem definition of interest in time series anomaly detection. It then provides an overview of the architecture of our proposed method and presents its components in detail. Finally, it describes the training and testing strategy employed by the method.
3.1. Problem Definition
A time series data can be expressed in a sequence of length T, where is the d-dimensional data point at time step i. If , this indicates that X is univariate, whereas if , this implies that X is multivariate. The time series anomaly detection task aims to produce a new output sequence , where indicates whether the corresponding input value is an anomaly event. This means that we are concerned with point anomalies in time series data.
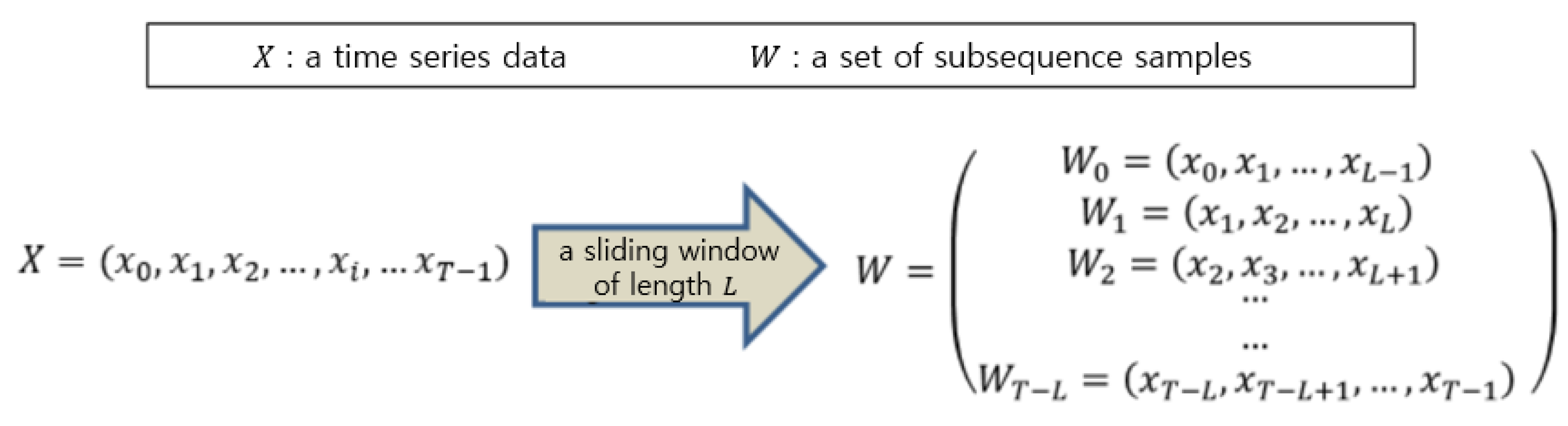
Similarly to many other deep-learning-based methods, we create a training dataset comprising subsequence samples
W of length
L from the time series data
X. This is achieved by sliding a window of size
L over
X with a step size of 1, as depicted in
Figure 5. The generated sequence samples are denoted by
, where
L is the length of samples and
T is the length of the input time series data.
3.2. The Architecture for Representation Learning of CL-TAD
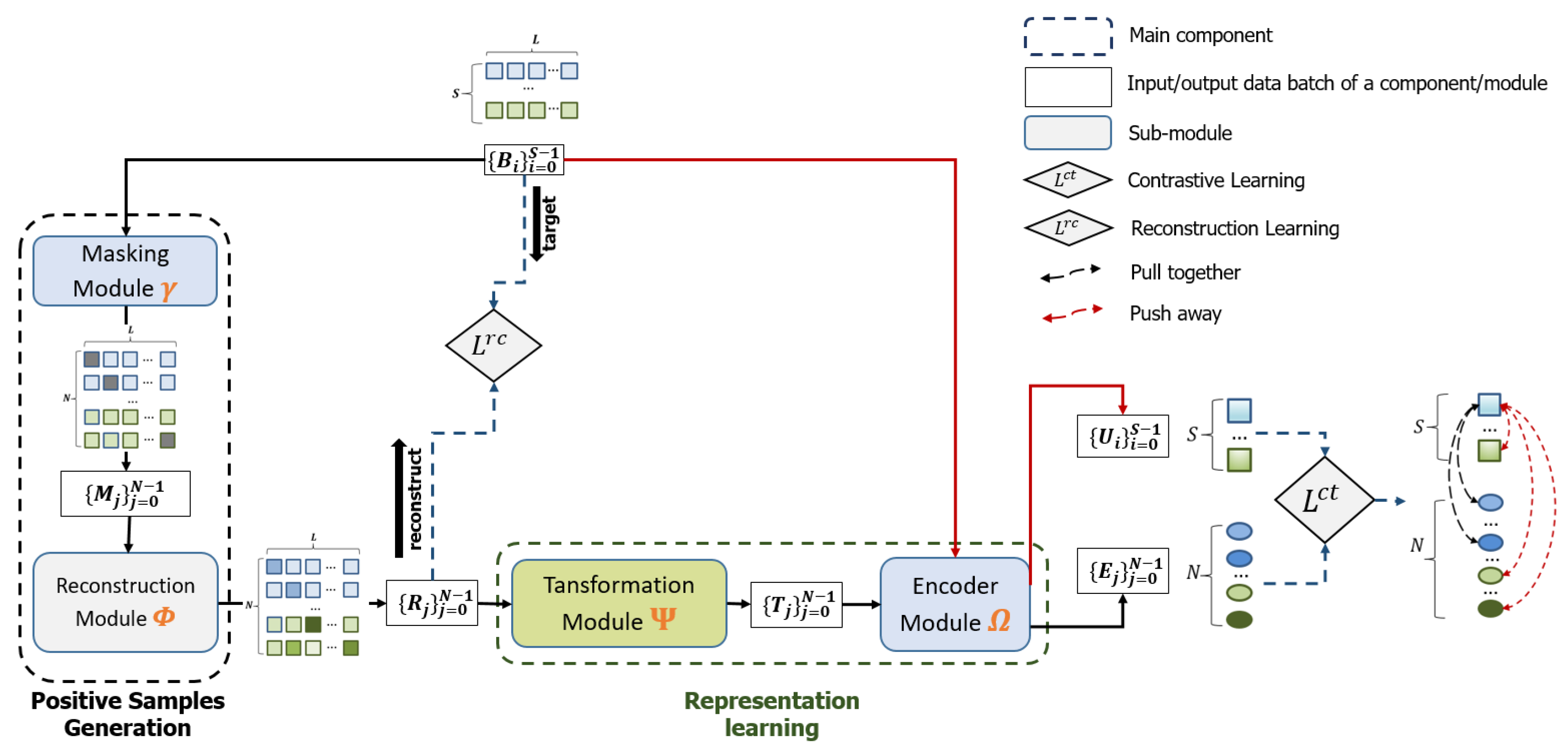
We propose a novel contrastive-learning-based anomaly detection method for time series data, which first augments the training data with an encoder–decoder-based reconstruction module using randomly masked samples, and then trains a contrastive-learning-based representation learning module using those samples and original data. For anomaly detection, the anomaly scores are evaluated by calculating the differences between the representations of the original data with those of their corresponding reconstructed data. We refer to this proposed method as CL-TAD (Contrastive-Learning-based Time series Anomaly Detection).
CL-TAD is conducted in two sequential stages: the representation learning stage and the anomaly scoring stage. In the representation learning stage, latent representations for fixed-length subsequences of time series and their augmented subsequences are generated by a contrastive-learning-based representation learning module. In the anomaly scoring phase, the anomaly score for each time step is calculated by comparing the representations of two subsequences: The first is the original subsequence that ends at the time step, and the second is the subsequence that is reconstructed from the first subsequence of which the last time step is masked.
Figure 6 illustrates the architecture used for representation learning in CL-TAD, which consists of two main components: reconstruction-based positive sample generation and contrastive-learning-based representation learning.
The first component plays the role of generating positive samples by leveraging a reconstruction-based encoder–decoder network, which recovers masked samples of the original time series data. Its reconstruction-based learning approach with a masking strategy facilitates the generalization of a robust and large positive training dataset. The representation learning component then uses both the created positive samples and the original samples for training. The whole network for sample generation and representation generation is trained in an end-to-end manner.
Some contrastive-learning-based methods [
44,
45] employ pre-defined transformation functions to augment original time series data. Conversely, a method discussed in [
46] adopts a learnable transformation function for the same purpose. In our approach, we integrate a learnable transformation module that pre-processes the augmented data prior to feeding them into the contrastive learning module.
3.3. Generation of Positive Samples
The component for positive sample generation is designed to create positive samples corresponding to each input subsequence sample. It consists of the masking module
and the reconstruction-based encoder–decoder module
. From a given time series data
X, the set
W of the original subsequence samples is generated, as depicted in
Figure 5. In each learning iteration of the component, we first randomly choose from
X a batch of
S subsequence samples, each having a length of
L. This batch is represented as
. The masking module
produces a new batch of
N masked samples,
where
, from the batch
B. For each
i-th subsequence of length
L in
, a collection of
L masked samples is created by masking the value at each time step individually. Let
denote the data produced by masking the value at the
k-th time step of the
i-th sampled sequence
.
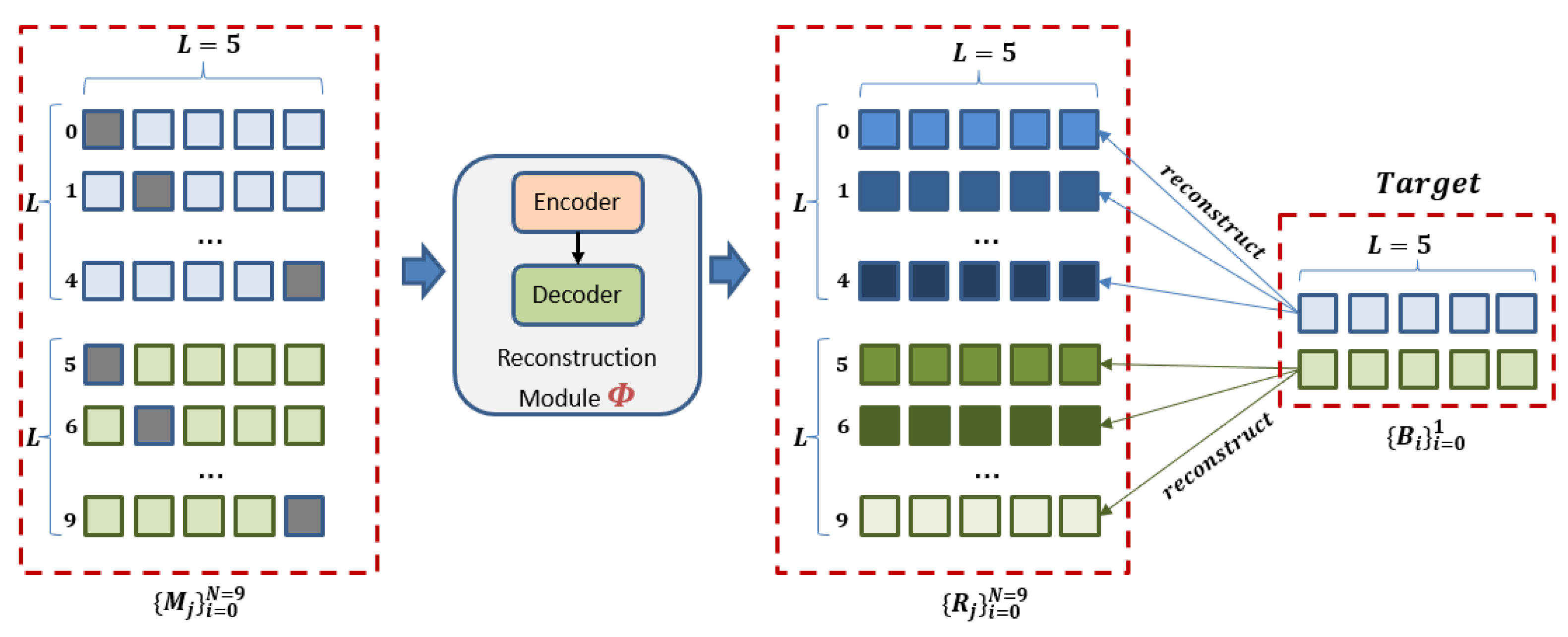
Figure 7 illustrates the process of creating a batch of 10 masked data,
, from a batch of two subsequence samples
, each with a length of
. Please refer to Algorithm A1 in
Appendix A for the detailed implementation.
The batch of generated masked samples
is then fed into the module
for the reconstruction of its original sample, as shown in
Figure 8. For the reconstruction task, the module
uses an encoder–decoder architecture to reconstruct original input samples
from masked samples
. Specifically, the batch of masked samples
is fed into the module
to generate reconstructed samples
, each of which is expected to be similar to
. In the module
, we use a TCN network for the encoder and a linear layer for the decoder.
To train the module
, we use the average difference between the reconstructed samples and their original samples as the loss function
, as shown in Equation (
2). Please refer to Algorithm A2 in
Appendix A for a detailed implementation of the reconstruction learning procedure.
where
N is the number of output samples,
L is the length of each sample, ⌊.⌋ represents the floor function,
is the
j-th sample in
, and
is the original sample of the reconstructed sample
.
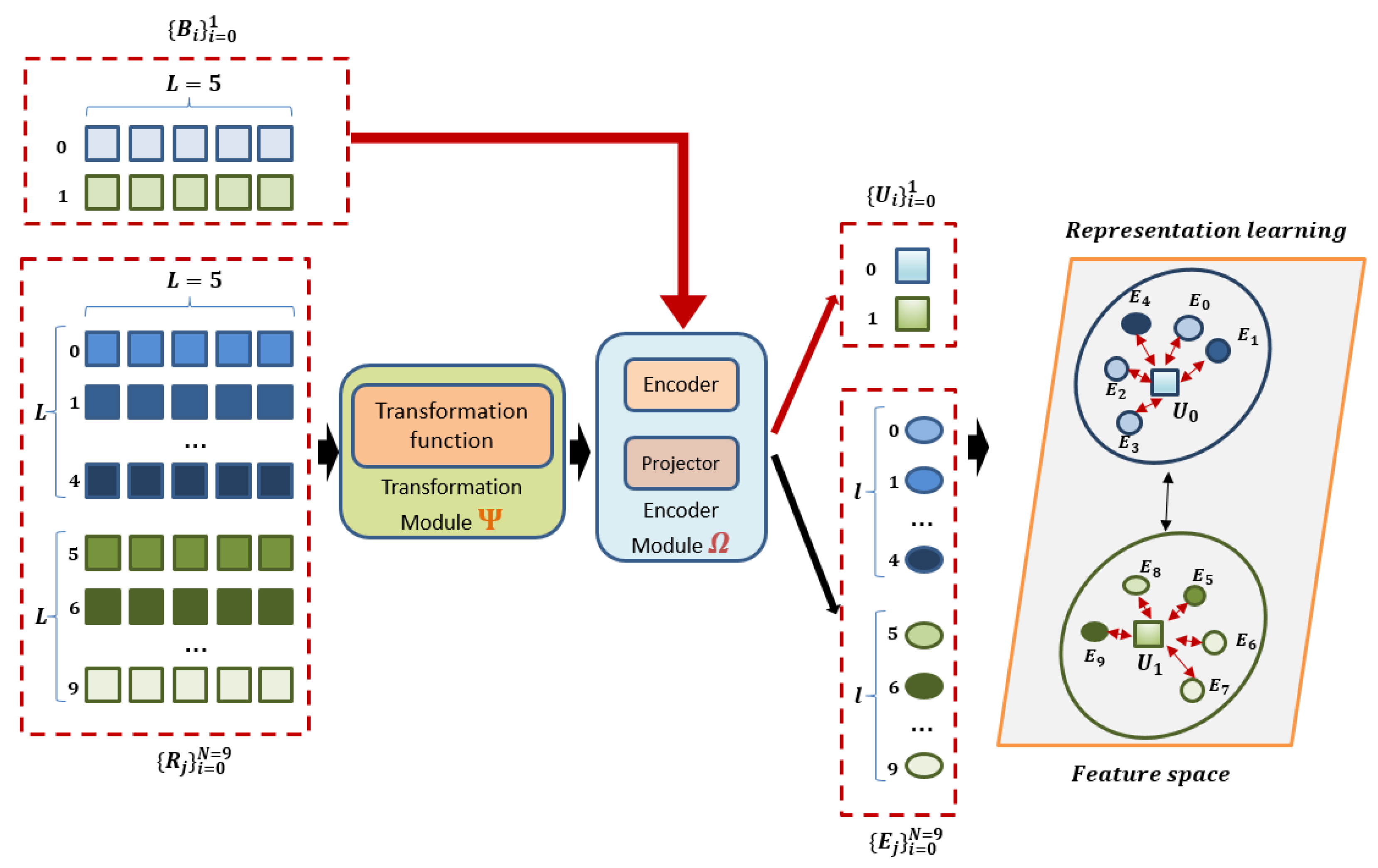
3.4. Contrastive-Learning-Based Representation Learning
To generate the representations for anomaly evaluation, the proposed method uses a contrastive-learning-based component that consists of a learnable transformation module
and its following encoder module
, as shown in
Figure 9.
Both the original samples and the reconstructed samples serve as the training data for the contrastive-learning-based component. The original samples are processed directly by the encoder module . Conversely, the reconstructed samples go first through the transformation module , with their outputs subsequently being supplied to the encoder module . The encoder module consists of an encoder and a projector. The input to the encoder module is first delivered to the encoder and then the output of the encoder is passed to the projector to create its corresponding representation. The representations of the original samples are denoted by , while those of the reconstructed samples are denoted by . In the representation learning component, we employ a linear layer network for the learnable transformation module , a TCN for the encoder of the encoder module , and a fully connected network for its projector.
The contrastive-learning-based representation learning component is trained to generate similar representations for pairs of an original sample and its corresponding similar sample (i.e., positive example), and dissimilar representations for pairs of an original sample and a different sample (i.e., negative example). For any given original sample, its associated reconstructed samples are regarded as positive examples, while both other original samples, as well as the reconstructed samples derived from them, are regarded as negative examples. For a sample within , the representations of its corresponding reconstructed samples, denoted as , thus form a set of L positive examples associated with . Meanwhile, the representations of the other samples , as well as their reconstructed samples , constitute a set of negative examples for .
The representation learning component is trained to draw the representation,
, of
and its positive examples
closer, while simultaneously pushing the negative examples further away from
. To evaluate the similarity between two representations,
and
, we can use a similarity score function
defined as follows:
where
and
indicate vectorized representations for subsequence samples, while
is the temperature hyperparameter that controls the sensitivity of the loss function in relation to the trained representations [
52].
In practical applications, pinpointing an ideal value for
could be complicated. To address this challenge, we integrate the TaU method [
53] to dynamically adjust the
parameter within the loss function. Previously proven effective in the visual domain, the TaU method offers a solution to this issue. Leveraging the capabilities of the TaU method, we propose a modified pairwise similarity score function, denoted as
, as follows:
where
is the uncertainty parameter of
and
denotes the sigmoid function. It should be noted that the uncertainty parameter
is fine-tuned during the representation learning phase.
Using the pairwise similarity score, the loss
is computed between the representation
of the original sample
and the representation
of a positive example
from the set
as follows:
where
signifies that
is used if the condition
is satisfied; otherwise the value 0 is applied.
indicates the contrastive loss associated with an original sample
.
Next, the loss
is defined between the representation
of a positive example
and the representation
of its associated original sample
, where
, as follows:
Finally, the average loss
over all pairs is computed as follows:
where the first term indicates the average loss between an input sample
and its corresponding positive example
and the second term indicates the average loss between a representation
and its corresponding positive sample
.
3.5. Training of Representation Learning Model for the CL-TAD Method
In the representation generation stage, the CL-TAD method follows a two-step process. Firstly, it leverages the masking module combined with the reconstruction module to create positive samples. Secondly, it generates the representations of these samples using the transformation module and the encoder module . The modules , and , together with the loss function , encompass the learnable parameters. Those modules are implemented with neural network models.
These modules are jointly trained in an end-to-end manner using the combined loss function
. This function amalgamates the reconstruction loss
from Equation (
2) with the contrastive learning loss
from Equation (
7). Such integration facilitates holistic learning and optimization of the modules throughout the training process.
The CL-TAD method trains the representation learning model on a time series dataset without any abnormal events. Original samples are generated by applying a sliding window of length L across the given time series data.
For a particular batch of samples, each sample undergoes the masking process using the module , resulting in masked samples. These masked samples are then reconstructed via the reconstruction module . The original samples directly enter the encoder module . In contrast, the reconstructed samples are first passed through the transformation module before being processed by the encoder module . The subsequent original and reconstructed samples are paired to form positive and negative samples for contrastive learning.
The optimization of the model is then driven by the loss function
, which is computed based on these paired arrangements. Such a comprehensive training approach ensures that the model effectively learns and refines representations. For a detailed description of the training procedure, please refer to Algorithm A3 in
Appendix A.
3.6. Anomaly Score Evaluation
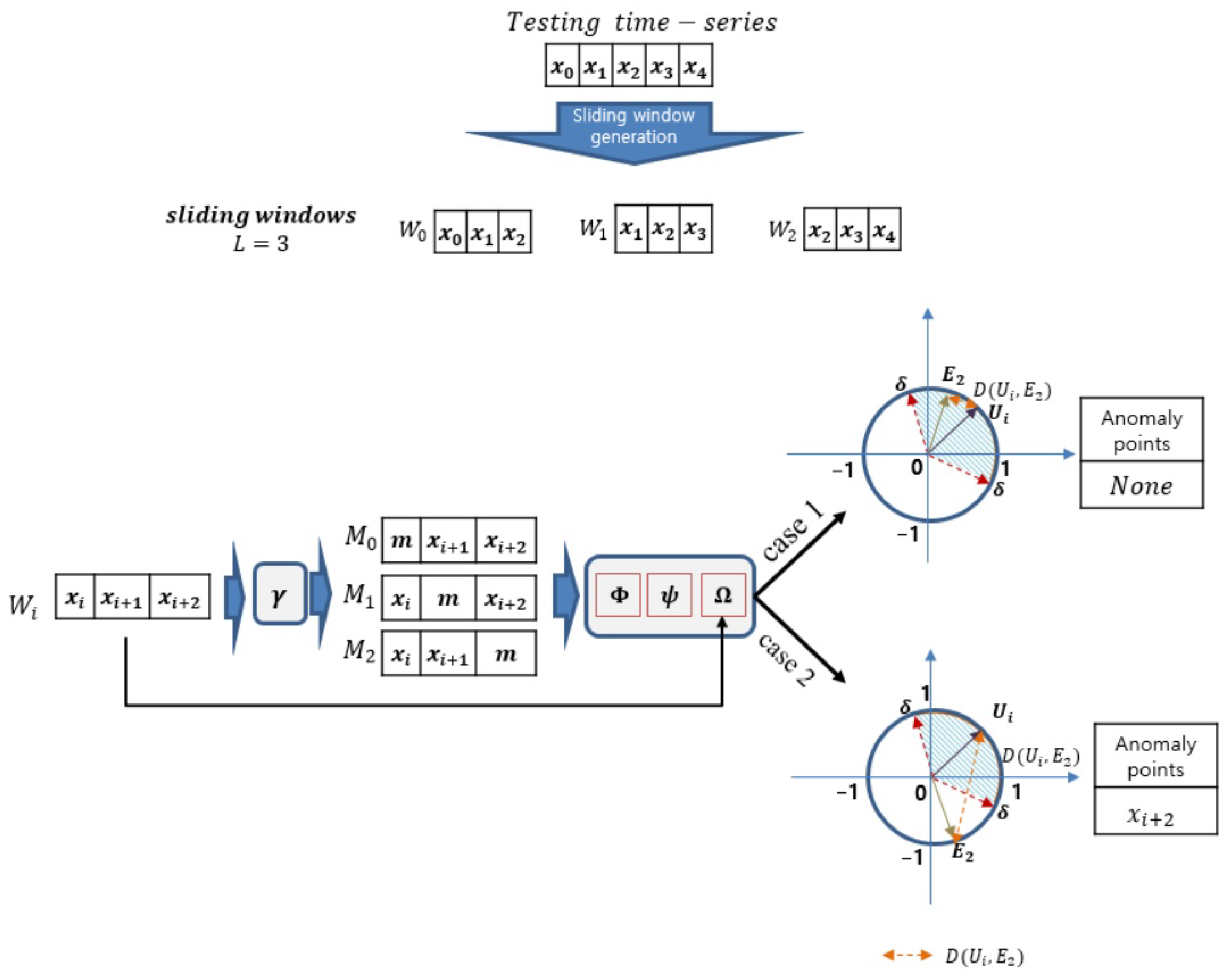
For a given test time series data , its anomaly score for each time step is computed to ascertain its potential status. The CL-TAD method employs a distance-based mechanism to determine these scores. The procedure begins by forming subsequences with a length of L derived from the given data Z. This is achieved by shifting a window of length L over Z. It is crucial to maintain this window length L consistent with what was adopted during the training phase. To compute the anomaly score associated with the last time step of , the value at the last time step is masked, yielding the masked subsequence denoted by .
The original subsequence is processed through the encoder module to yield its representation . In parallel, the masked subsequence undergoes sequential processing through the reconstruction module , transformation module , and the encoder module to derive its representation .
The normalized Euclidean distance function is used to compute the distance
between the representation
of the original subsequence
and the representation
of the reconstructed subsequence
as follows:
The data point at the last time step in
, specifically
, is designated as anomalous only when the distance
exceeds the pre-specified threshold
.
Figure 10 illustrates the process of generating and comparing the representations for the anomaly score calculation.
The selection of the threshold value
is based on the examination of the
scores across a set of potential threshold values, uniformly distributed from 0 to the maximum representation distances observed on a held-out test dataset containing anomaly events. The value that produces the highest
score is chosen as the threshold
. It is noteworthy that the distance distributions associated with anomalous events can differ depending on real-world applications. Algorithm A5 in
Appendix A describes how the list of candidate thresholds is constructed.
This thresholding approach has been adopted in several anomaly detection methods, including RAMED [
27], OmniAnomaly [
30], DeepFIB [
21], MAD-GAN [
32], and others. The
score is derived from precision and recall, and is defined as follows:
Refer to Algorithm A5 in
Appendix A used to generate the list of thresholds. For datasets consisting of multiple time series, the final performance is evaluated by computing the average
scores over all sub-time series.
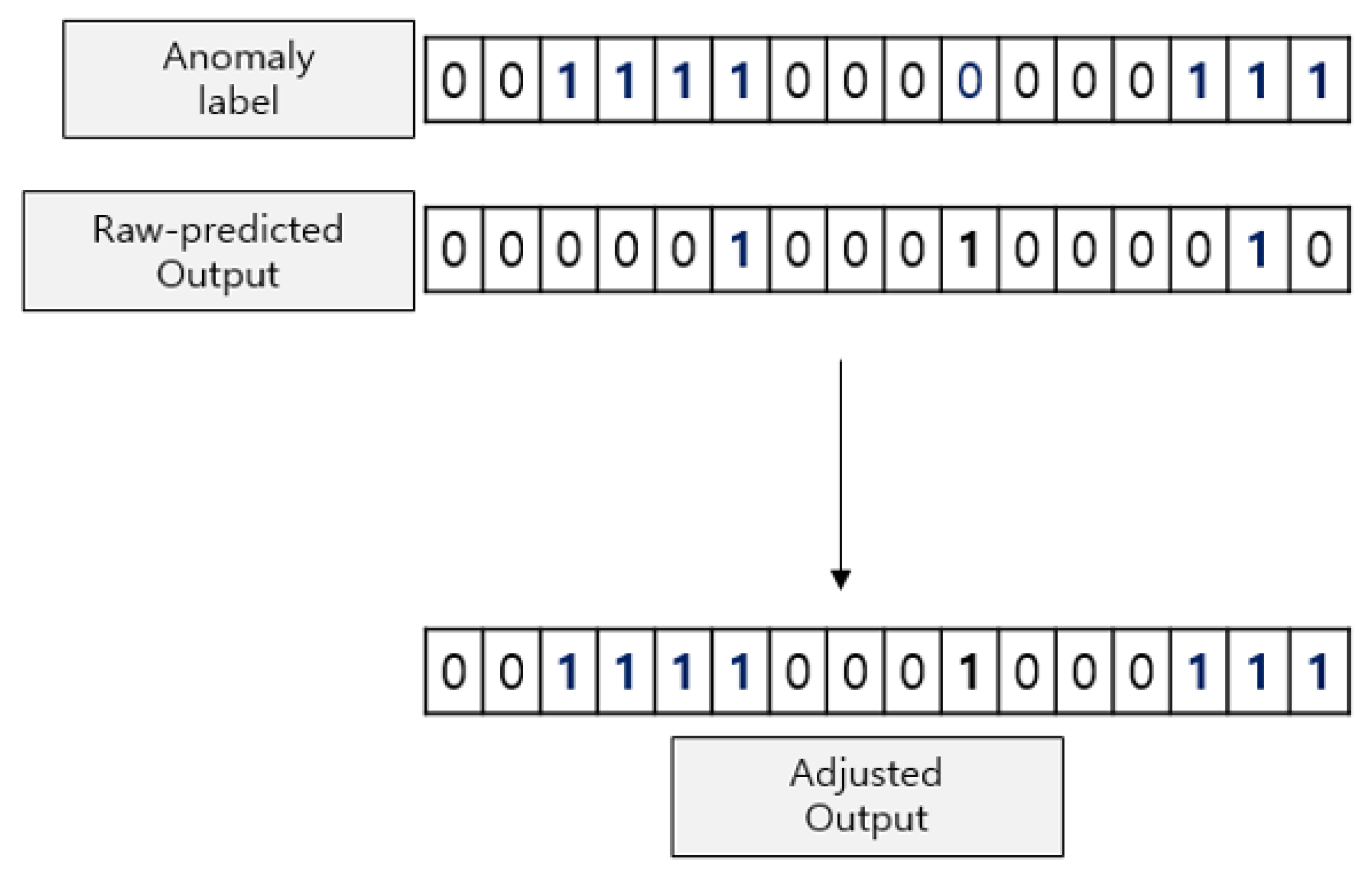
Moreover, the proposed method incorporates the point adjustment technique [
11] after performing threshold-based anomaly determination. Following this technique, once an individual time step within an anomalous segment is identified as anomalous, the entire segment is then considered as anomalous. This modification has demonstrated its effectiveness in practical scenarios, as recognizing an anomaly at a specific time step typically signals an alarm, bringing attention to its corresponding entire anomalous window. The point adjustment technique is visually presented in
Figure 11. In this figure, the
Anomaly label represents the ground truth, with 1 signifying the presence of an anomaly event at a given time step and 0 denoting regular activity. The
Raw-predicted Output displays the preliminary anomaly labels generated through threshold-based anomaly identification. Meanwhile, the
Adjusted Output portrays the results after applying the point adjustment technique.
Algorithm A6 in
Appendix A shows the entire procedure to conduct the best
-score-based performance evaluation.
4. Experiments and Discussions
This section outlines the results obtained from a series of experiments conducted to evaluate the effectiveness of our proposed model. These experiments were conducted on nine different datasets, widely recognized as benchmark datasets in the field. First, it briefly presents the dataset used for the experiments. Next, it describes how the proposed method has been implemented for the experiments. Subsequently, it shows the performance outcomes achieved by our method. Finally, it presents the outcomes of an ablation study.
4.1. Benchmark Datasets
The proposed method was tested on a combination of two univariate datasets—UCR and Power Demand—as well as seven multivariate datasets, namely ECG, 2D-Gesture, PSM, SMD, MSL, SWaT, and WADI. Power Demand [
21,
27,
54] is a univariate dataset that records the yearly power demand at a Dutch research facility. The UCR (HexagolML) dataset [
43,
55] was a part of the KDD-21 competition and serves as a univariate anomaly detection benchmark. It is divided into four subsets: 135_, 136_, 137_, and 138_.
The ECG dataset [
21,
27,
54], consisting of two-dimensional electrocardiogram readings, is further segmented into six sub-problems: chfdb_chf01_275 (ECG-A), chfdb_chf13_45590 (ECG-B), chfdbchf15 (ECG-C), ltstdb_20221_43 (ECG-D), ltstdb_20321_240 (ECG-E), and mitdb_100_180 (ECG-F). The 2D-Gesture dataset [
21,
27,
54] records two-dimensional X–Y coordinates of hand gestures captured in videos. The PSM dataset [
42,
56], with 25 dimensions, logs data from various application server nodes at eBay. The SMD dataset [
43,
57] is a 38-dimensional dataset capturing five weeks of resource utilization across 28 computers. Only the non-trivial traces labeled as
machine1-1, 2-1, 3-2, 3-7 were used in our experiments as per [
43,
57]. The MSL dataset [
43,
58], 55-dimensional in nature, comprises soil samples from the NASA Mars rover. Only the non-trivial trace,
C2, was considered for anomaly detection, consistent with [
43,
58]. The SWaT dataset [
42,
59] has 51 dimensions and was gathered over a week of regular operations and four days of irregular operations at a real-world water treatment plant. Lastly, WADI [
42,
59] is an extended version of SWaT, boasting 127 dimensions, and encompasses data from a broader array of sensors and actuators.
Table 1 presents the statistics of those datasets.
All datasets have been normalized to fit within the range
. For datasets comprising multiple time series, each series underwent independent normalization. The normalization method is elaborated upon in Algorithm A7 located in
Appendix A.
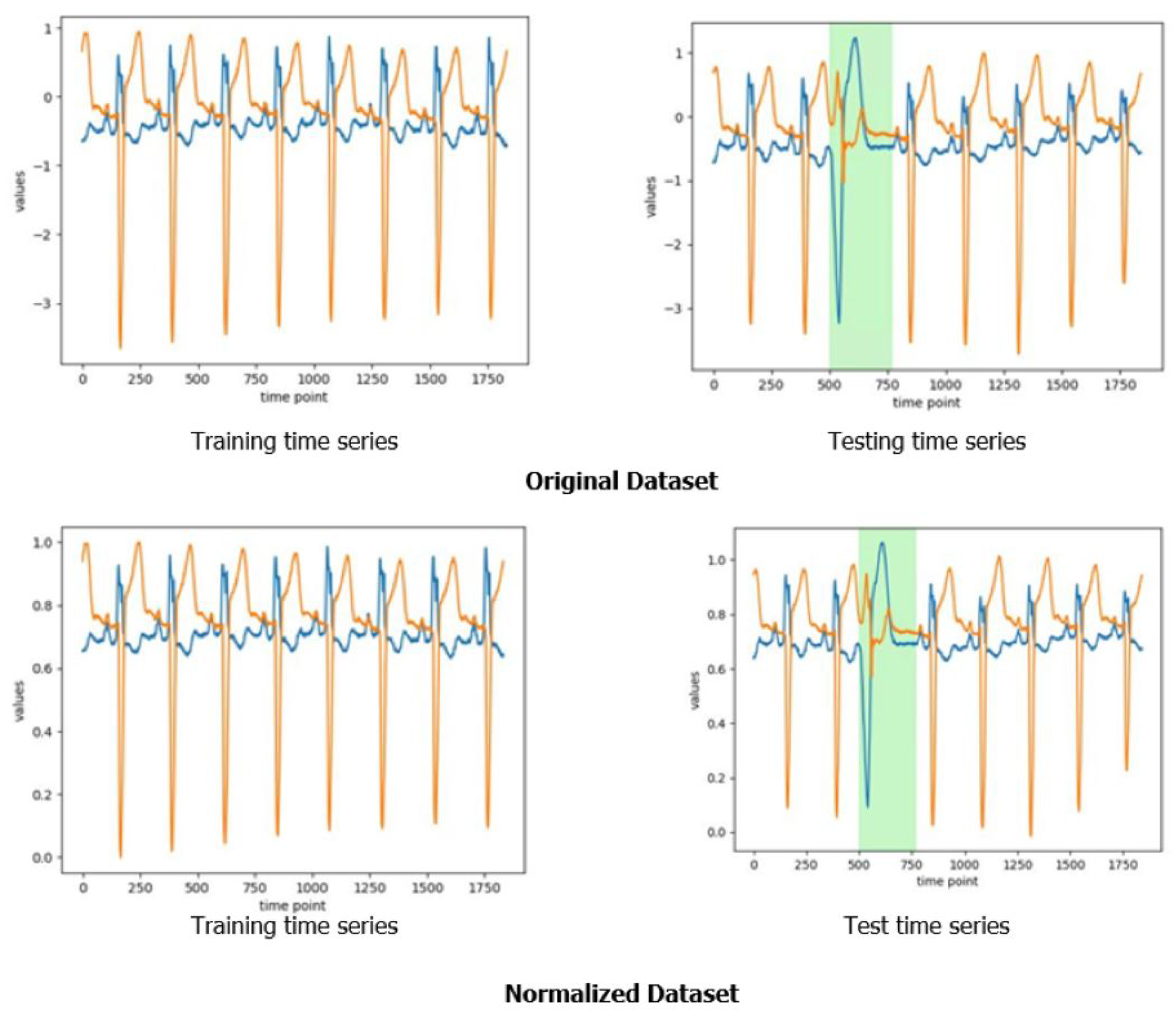
Figure 12 offers a visual representation of the normalization for a time series from the two-dimensional ECG dataset. The green sections in the figure mark an anomalous event.
4.2. The Implemented Model Architecture and Its Training
For anomaly detection on the benchmark datasets, we implemented a deep neural network model corresponding to the architecture shown in
Figure 6. The reconstruction module
comprises an encoder, built using a six-layer TCN (temporal convolution network), and a decoder realized with a linear layer. For the representation learning component, the transformation module
was implemented with a linear layer. In contrast, the encoder of the encoder module
was implemented with a six-layer TCN, and the projector was realized with a two-layer fully connected network.
Table 2 presents the hyperparameter values used in the experiments. For the training of our designed network model, we employed the Adam [
60] optimizer with the LARS wrapper [
61]. To adjust the learning rate, we utilized the cosine annealing technique with a linear warmup of 10 epochs, starting with a learning rate of
. Furthermore, the hyperparameter
was set to
. The entire model was implemented using Pytorch 2.0.1 and executed on an NVIDIA Geforce RTX 2080 Ti GPU.
4.3. Experiment Results and Comparison
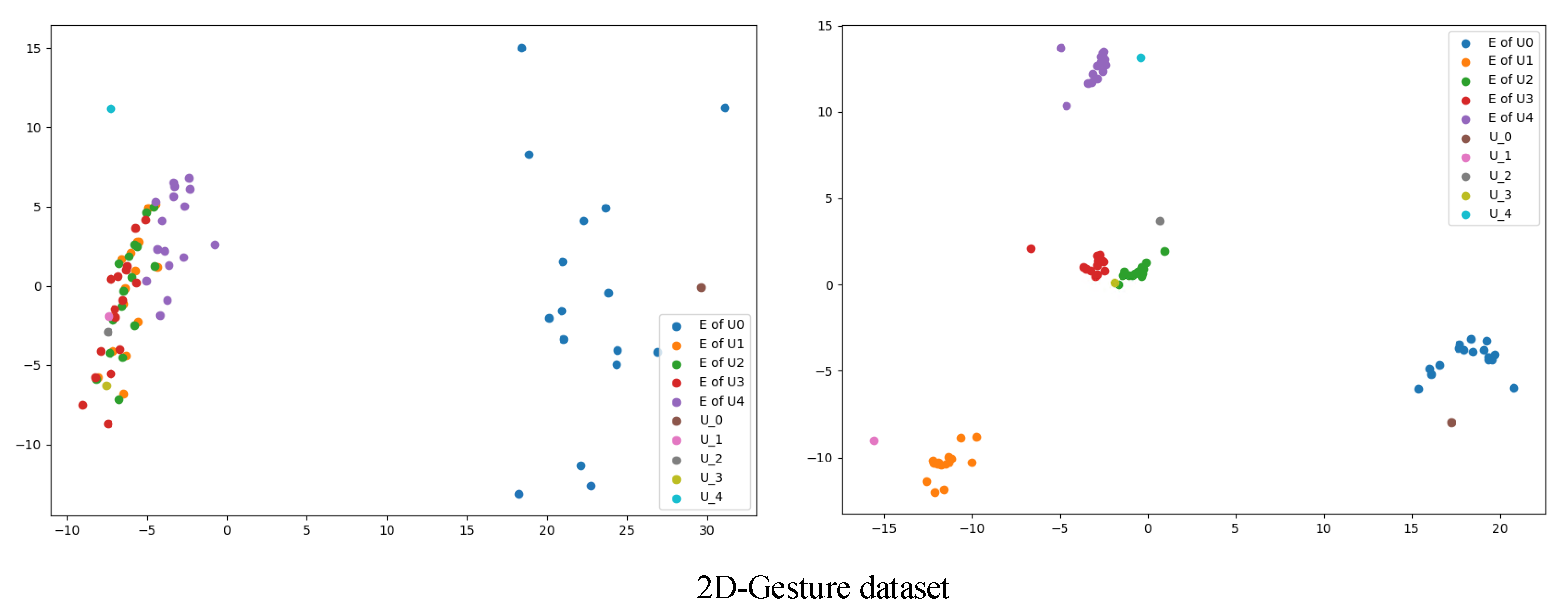
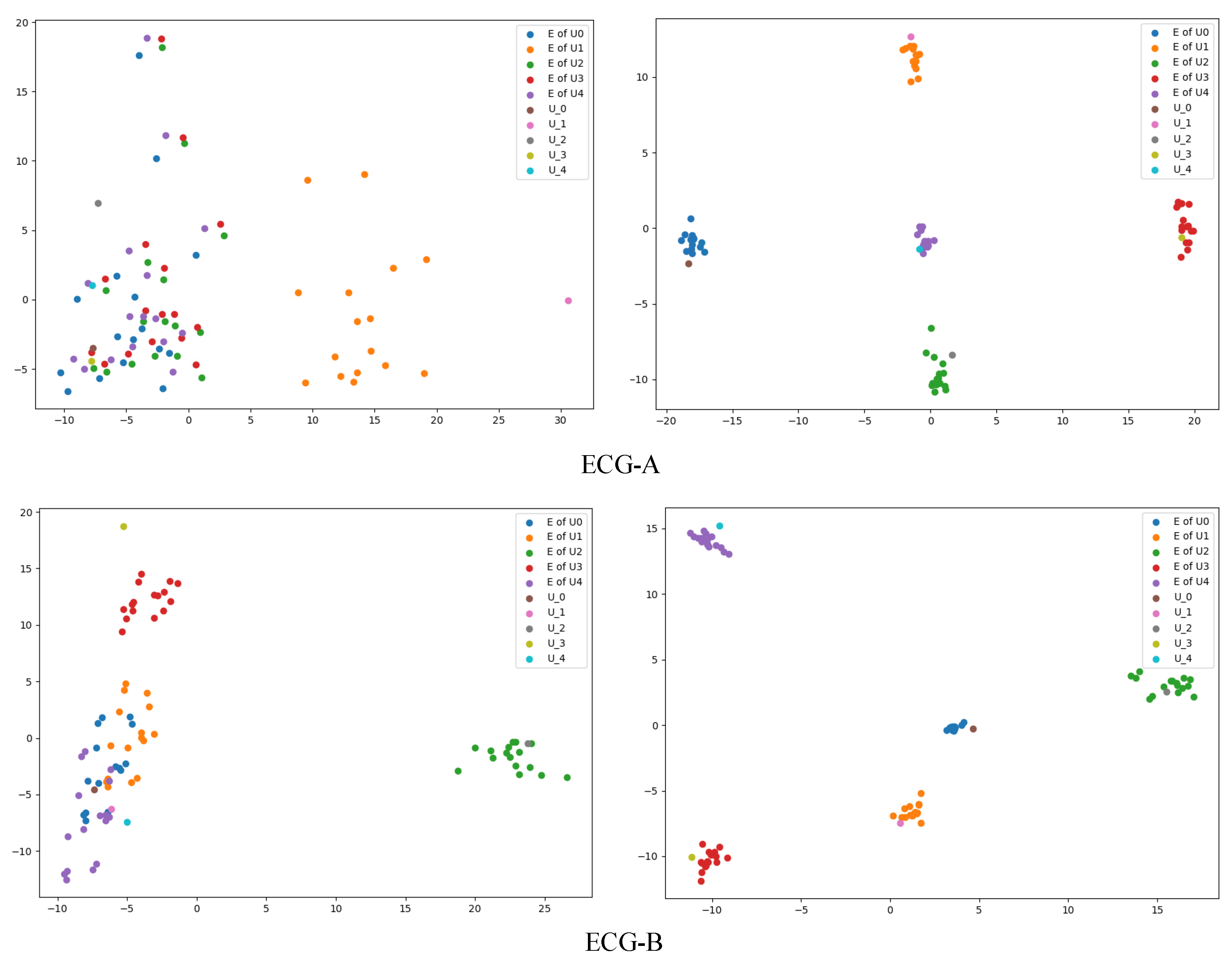
To gain insight into how the proposed method forms the representations of samples, the distribution of representations was visualized for some examples from the ECG and 2D-Gesture datasets. This was done for both pre-training and post-training, as depicted in
Figure 13 and
Figure 14. To ensure understandable visualization, we employed the PCA technique to project these representations into a two-dimensional space. From the figures to show post-training results, it is clear that the positive samples cluster closely together while the negative samples are dispersed further away. This observation shows that our proposed method can generate meaningful representations.
Table 3 presents the experimental outcomes achieved by our proposed method on the benchmark datasets. We employed performance metrics such as precision, recall, and
score for the evaluation. For datasets that are split into several sub-datasets, we have provided an in-depth performance breakdown for each sub-dataset in
Table A1,
Table A2 and
Table A3 located in
Appendix B. For datasets such as ECG, UCR, and SMD, which are divided into multiple sub-datasets, the
scores were averaged across all the sub-datasets to give a consolidated score.
To further show the effectiveness of our proposed method, we have compared its
score performance with that of several state-of-the-art methods, as presented in
Table 4, for the identical benchmark datasets. We made comparisons with the following methods: MAD-GAN [
32], DAGMM [
22], MSCRED [
36], CAE-M [
28], OmniAnomaly [
30], TranAD [
43], GDN [
29], MTAD-GAT [
38], and USAD [
39]. The numbers in bold indicate the top-performing results for each benchmark dataset. Each compared method has achieved its best performance by using its curated optimal hyperparameters. We have utilized superscripts to indicate the source from which each performance score was derived: (1) refers to the model’s original paper, (2) is sourced from [
21], (3) from [
42], (4) from [
43], and (5) represents the performance scores that we obtained running the datasets through the models using codes available from the developers’ GitHub repositories [
62,
63,
64]. Scores that carry a (6) superscript represent performances derived from evaluating the entire dataset.
As seen in
Table 4, our proposed method outperformed others in five out of the nine benchmark datasets. It exhibited superior performance over both univariate datasets. When examining multivariate datasets, our method took the lead in the 2D-Gesture, SMD, and MSL datasets.
For the UCR dataset, which comprises four sub-datasets, detailed results of our method can be found in
Table A1 in
Appendix B. The ECG dataset consists of six sub-datasets and the performances on these sub-datasets are available in
Table A2 in
Appendix B. Regarding the SMD dataset, all the performance scores in
Table 4 were evaluated on the sub-dataset ‘machine1-1’ of the SMD dataset. For the performance of our method on the entire SMD dataset, refer to
Table A3 in
Appendix B. For the MSL dataset, the performance was evaluated on its sub-dataset ‘C-1’. Finally, for the SWaT dataset, there are two versions of the training datasets as shown in
Table 5. We tested our method on both versions, resulting in similar performances across both.
The experiments on the nine benchmark datasets showed that the CL-TAD outperformed other compared methods on five datasets, and achieved competitive performance on two datasets. It did not achieve excellent performance on high-dimensional multivariate time series data like WADI. The CL-TAD produces effective representations on a feature space by incorporating the transformation module and the TCN-based encoder into its encoding process and making use of the contrastive-learning-based training. For high-dimensional time series data like WADI of dimension 127, it appears to struggle in deriving appropriate representations for anomaly detection.
4.4. Ablation Study
We undertook additional experiments to better understand the characteristics of our method. Specifically, we tried to answer the following three questions: (Q1) Is our method efficient on a limited-sized dataset? (Q2) How efficient is our method with different transformation functions? (Q3) Is a TCN-based architecture the right choice for feature extraction in our method?
4.4.1. Q1: Is Our Method Efficient on a Limited-Sized Dataset?
To ascertain the performance of our method on constrained datasets, we undertook evaluations using just 20% of the available training data for two benchmarks: 2D-Gesture and ECG. The results were promising. As presented in
Table 6, our method delivered an
score of 99.93 on the 2D-Gesture benchmark and 90.64 on the ECG benchmark. Such high scores, despite limited training data, suggest that our approach is resilient to data scarcity and can be effective in real-world scenarios with limited training datasets.
4.4.2. Q2: How Efficient Is Our Method with Different Transformation Functions?
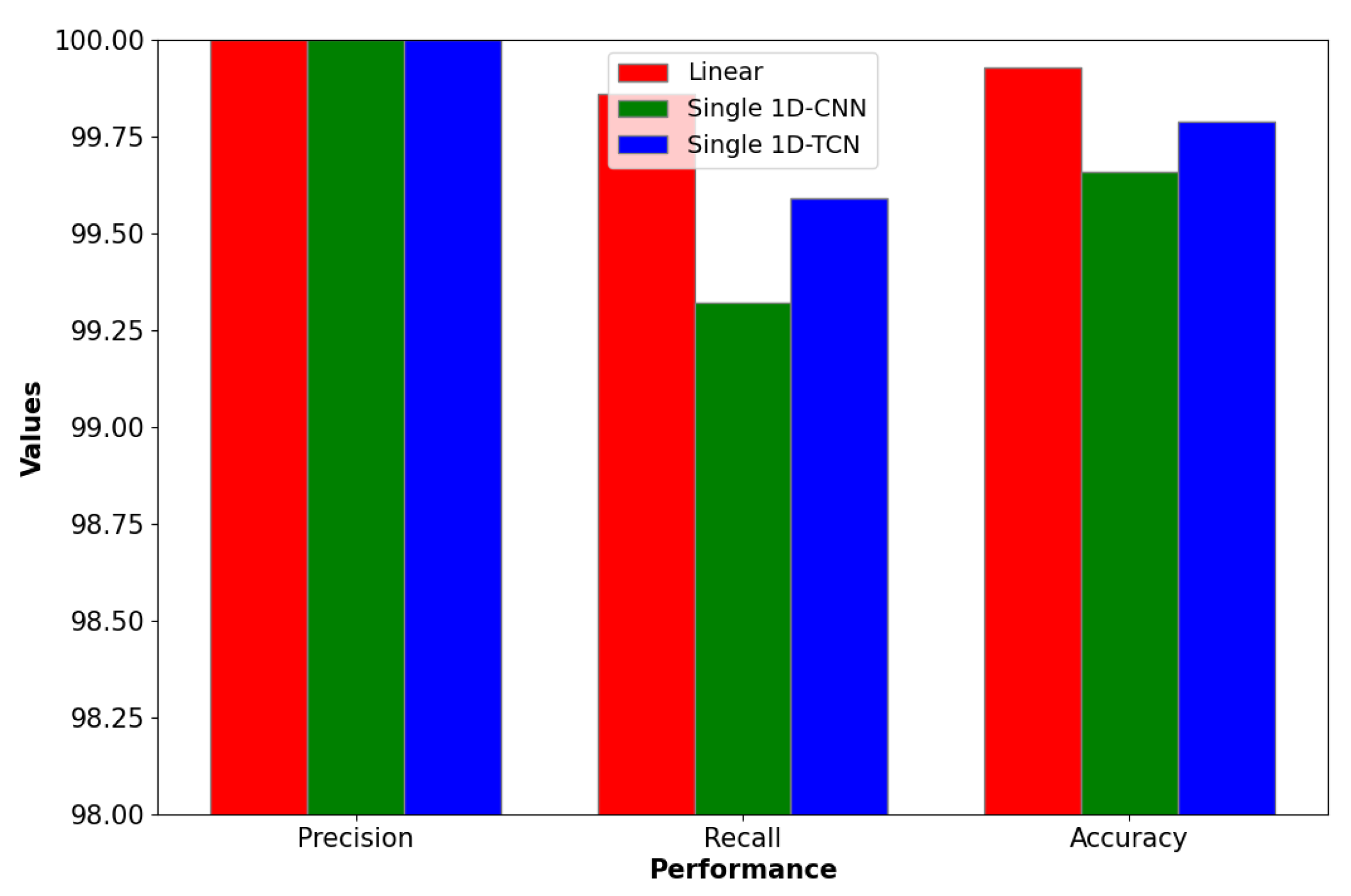
To explore the adaptability of our model to various transformation functions, we assessed its performance on the 2D-Gesture benchmark using transformation functions other than a linear transformation. As shown in
Table 7, our model impressively achieved
scores of 99.66 and 99.79 when leveraging a singular 1D-CNN and a TCN, respectively, as the transformation functions. This underscores the flexibility and efficiency of our approach across diverse transformation functions. Furthermore,
Figure 15 visually compares the accuracy across different transformation functions, further highlighting the performance of a linear transformation in our model.
4.4.3. Q3: Is aTCN-based Architecture the Right Choice for Feature Extraction in Our Model?
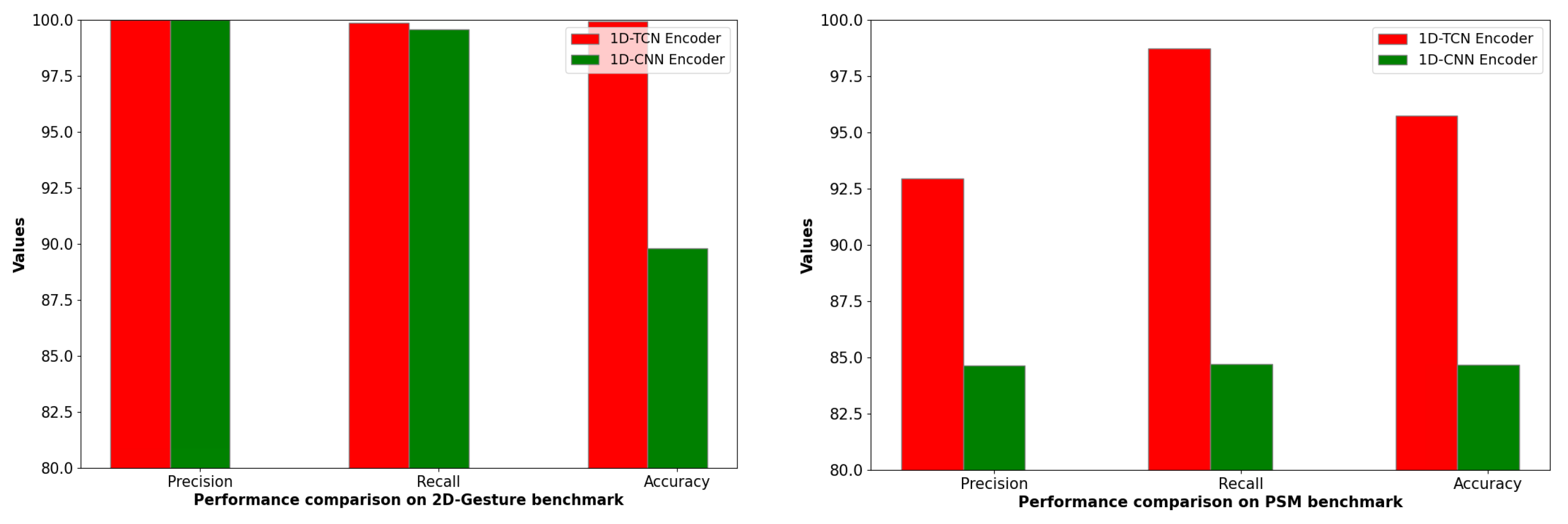
To explore the effectiveness of different architectures in the encoders of our model, we employed a six-layer 1D-CNN as a substitute for our standard setup. The results, detailed in
Figure 16 and
Table 8, show that the TCN-based encoders consistently outperformed the 1D-CNN-based counterparts, achieving higher
scores on datasets like 2D-Gesture and PSM. Such findings suggest that the 1D-TCN architecture is more robust than the 1D-CNN architecture in the proposed method when it comes to temporal feature extraction for anomaly detection.
5. Conclusions
The time series anomaly detection task has recently gained increasing attention in diverse sectors including manufacturing, banking, and healthcare. In this paper, we introduced CL-TAD, a novel contrastive-learning-based method for time series anomaly detection. In our method, we augment the normal data with a combination of a masking technique and a TCN-based encoder–decoder module. Subsequently, a representation generation network is trained using a contrastive learning technique for both the original normal samples and the augmented samples. The training process relies solely on normal time series data without any anomaly events. This characteristic is particularly beneficial for anomaly detection, with the challenges associated with collecting datasets rich in anomalies. For the determination of anomaly score thresholds, we deploy an approach that searches for the value that maximizes the score for a designated held-out dataset. The CL-TAD is potentially quite useful in industries such as manufacturing, finance, and healthcare for which it is time-consuming and expensive to label training time series data because the CL-TAD does not require labeled data. To evaluate the performance of our method, we applied it to the nine well-known benchmark datasets. It outperformed other approaches in five out of the nine benchmarks in terms of performance. In the experiments, the CL-TAD achieved excellent performances on univariate time series data as well as multivariate time series data of which the number of dimensions is not high. The experiments showed that the effective representation could be found for time series data anomaly detection by the proposed method only with normal data. It is practically useful in practical applications for which it is hard to obtain labeled training data.
The reliance on normal data during the training phase renders our approach highly applicable to situations with a scarcity of labeled data. Moreover, our empirical evaluations demonstrated that CL-TAD maintained its robust performance even with limited training data. This means that CL-TAD can be used as a valuable tool for time series anomaly detection, showcasing its potential to address real-world challenges effectively.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}