Abstract
Studying domain adaptation is a recent research trend. Generally, many generative models that researchers have studied perform well on training data from a specific domain. However, their ability to be generalized to other domains might be limited. Therefore, a growing body of research has utilized domain adaptation techniques to address the problem of generative models being vulnerable to input from other domains. In this paper, we focused on generative models and representation learning. Generative models have received a lot of attention for their ability to generate various types of data such as images, music, and text. In particular, studies utilizing generative adversarial neural networks (GANs) and autoencoder structures have received a lot of attention. In this paper, we solved the domain adaptation problem by reconstructing real image data using an autoencoder structure. In particular, reconstructed image data, considered a type of noisy image data, are used as input data. How to reconstruct data by extracting features and selectively transforming them in order to reduce differences in characteristics between domains entails representative learning. Considering these research trends, this paper proposed a novel methodology combining bidirectional feature learning and generative networks to innovatively approach the domain adaptation problem. It could improve the adaptation ability by accurately simulating the real data distribution. The experimental results show that the proposed model outperforms the traditional DANN and ADDA. This demonstrates that combining bidirectional feature learning and generative networks is an effective solution in the field of domain adaptation. These results break new ground in the field of domain adaptation. They are expected to provide great inspiration for future research and applications. Finally, through various experiments and evaluations, we verify that the proposed approach outperforms the existing works. We conducted experiments for representative generative models and domain adaptation techniques and found that the proposed approach was effective in improving data and domain robustness. We hope to contribute to the development of domain-adaptive models that are robust to the domain.
1. Introduction
The field of domain adaptation is currently witnessing rapid progress in innovative research to address the problem of data mobility across different domains. In particular, recent advances in machine learning and deep learning techniques have attracted attention on how to overcome distributional differences between domains and improve the generalization performance of models [1,2,3,4,5,6].
In particular, a growing body of research has focused on the relationship between domain adaptation and generative models. This research seeks to understand why gaps between adversarial domains occur and how to counteract them in order to make models more robust. There has been a large body of research showing that approaches using generative models are useful for improving a model’s generalization performance across domains [7]. Generative models mimic real-world data distributions to generate data in the target domain for adaptation, especially using generative adversarial neural networks (GANs) or autoencoder structures [7,8,9,10,11,12,13].
This paper utilizes an autoencoder structure in the generation model to reconstruct and utilize real image data. At this time, reconstructed image data can be treated as a kind of noisy image data caused by reconstruction error. They are used as input data. In addition, representation learning is a field that studies how to reconstruct data through feature extraction and selective feature transformation to address differences in features across domains. In view of these recent trends and research developments, this paper is expected to play an important role in presenting a new methodology that utilizes cross-domain bidirectional feature learning and generative networks to solve domain adaptation problems and overcome the limitations of existing studies.
That is how I came across the model shown in panel (a) in Figure 1. This model is described in an interesting paper that allowed the authors to start studying domain adaptation. It is called DANN [1] for short, and it is a great paper to look at alongside its successor, the ADDA model [7], shown in panel (b) of Figure 1. Both models are adversarial models, but there is a difference. While DANN behaves adversarially when computing loss, the ADDA model initially learns to associate a discriminator with two domains to determine domain labels. If the domains had completely different characteristics, the loss would be extremely high at the beginning of training. However, the more the model is trained, the better the model will perform, i.e., it will be a better design. With this in mind, we wanted to build a model that is adversarial and has a bit more complexity.
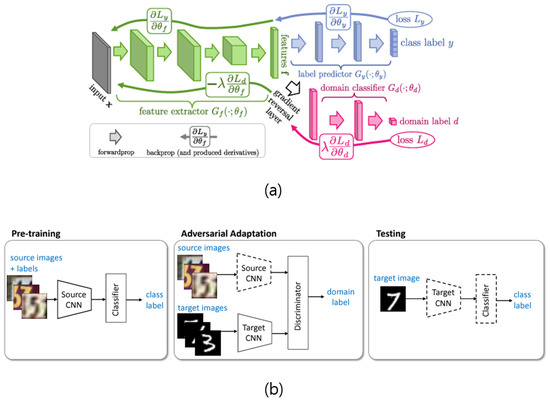
Figure 1.
The different structures of DANN (a) and ADDA (b).
Table 1 summarizes what DANN and ADDA have in common and their differences from the model we propose in this paper. The reason why this table is important is because everything we will introduce in this paper is in this table. It starts with the question of whether there is a generative network or not. Then, there is adversarial learning, bidirectional feature learning, using a pretrained network (this is also related to training time, which works a little differently in this work and will be discussed later), sharing weights, using a hyperparameter, etc.

Table 1.
Comparison of recent methods (o denotes method is used in model; x denotes it is not used).
In the modern world, the rapid growth of data has led to the production of many different kinds of data in many different fields. However, these data often originate from different domains, each with unique characteristics and statistical distributions. This makes it difficult for machine learning models to generalize to new domains, which hinders the effective application of models in the real world. In response, domain adaptation research has gained increasing importance. In particular, recent research trends have explored innovative methods to address the problem of cross-domain portability. These approaches are mainly centered on generative models and representation learning [14,15]. Generative models focus on overcoming distributional differences while generating data in the target domain. Studies utilizing generative adversarial neural networks (GANs) or autoencoder structures have received much attention. Representation learning also focuses on performing adaptation in a way that reduces differences in characteristics between domains through feature extraction and transformation. However, most of the existing research has focused on unidirectional feature transformations. In the learning processes of previous studies that learn by transforming features themselves, limitations and problems arise when trying to adapt the target domain to a model trained on the source domain. In contrast, this paper explores the domain adaptation problem from a new angle by combining a bidirectional feature learning process and generative network and proposes an innovative methodology to perform adaptation while mutually preserving features between two domains. It is expected to more accurately consider the distribution of real data, overcome the limitations of existing methods in effectively solving the domain adaptation problem, deepen our understanding of the relationship between generative models and domain adaptation and features, and contribute to the development of more robust and stable models.
The starting point of this paper is the need for domain adaptation and the current state of research. The problem of the cross-domain mobility of data collected from various fields limits the performance of machine learning models. As a solution, existing research has mainly focused on unidirectional feature transformations. However, starting from the idea that the relationship between domains could be bi-directional, we tried to introduce a bi-directional feature learning process. We found that the bi-directional feature learning method, which is the training method of our proposed model, has been used in several studies. However, the most important concepts in the field of domain adaptation are learning in the direction of minimizing empirical risk [16], feature conversion using image-to-image translation [10,17], transfer learning [18,19,20,21], reducing the gap between domains with generalization and robustness of the model and generative networks [12], adversarial learning with discriminators, adversarial learning without discriminators [22], pseudo-labeling for domain adaptation in the absence of discriminative classifiers [23], and so on, all of which seem to be similar to domain adaptation. However, they have slightly different contributions. Thus, there is still a lot of potential for further development. To advance this idea, it is necessary to strengthen the role of generative networks. Generative models need to be improved to simulate more realistic data distributions. Although such research studies have been ongoing, they have not been able to move beyond a one-way learning process. To this end, we propose a model combining generative networks and bidirectional feature learning processes to perform both functions together [24]. Furthermore, bidirectional feature learning can serve as a potential way to enforce interdependence between two domains. In this way, we devised a novel network architecture that could achieve good adaptation while preserving features between the two domains. From the perspective of generative models, new ideas can be generated on how to reconfigure different data to adapt to new domains. This will allow the model to acquire generalization capabilities that allow it to adapt in more diverse situations or in different environments. Through this process of idea generation, the model proposed in this paper can be further enriched and innovated.
This paper proposes a novel approach in the field of domain adaptation by combining bidirectional feature learning and generative networks. The main idea is to enhance cross-domain adaptation through bidirectional feature learning and to improve the adaptation ability by more accurately simulating actual data distribution through generative networks.
Based on the evaluation results, the proposed model demonstrated significantly higher accuracy than existing models such as DANN and ADDA. Through experiments, it was found that the proposed model exhibited outstanding performance in domain adaptation. These results strongly indicate that combining bidirectional feature learning and generation networks is an effective method for domain adaptation. As a major contribution and result, this paper not only presents an innovative solution in the domain adaptation field, but also provides a model that is superior to existing models such as DANN and ADDA. Thus, this research breaks new ground in domain adaptation and provides significant inspiration for future research and applications. Furthermore, the experimental results demonstrated that the proposed approach could minimize performance degradation of the generative model while aiding in the generation of desired outputs. This indicates the effectiveness of this paper in improving the stability and reliability of the generative model simultaneously. These evaluation results are of great significance in presenting the validity and practicality of the proposed approach in the paper. They are expected to contribute to research aimed at enhancing the security and robustness of generative models.
The primary contribution of this paper is the development of a novel approach for domain adaptation in generative models and representation learning. By combining bidirectional feature learning and generative networks, we significantly improve the adaptation ability, accurately simulating the real data distribution. The experimental results showcase the superiority of our approach over traditional methods, marking a substantial advancement in the field of domain adaptation and enhancing the data and domain robustness in generative models.
This article is structured into five sections. The first section introduces the background, the problem statement, the derivation process, and a brief summary of the idea. The second section presents a summary of previous research and relevant techniques. The third section provides an overall description of the proposed model. The fourth section explains and presents the results of experiments conducted to evaluate the model’s performance.
2. Related Work
This section describes the background of the previous research that leads to the proposal of this paper.
2.1. Adversarial Domain Adaptation
Domain adaptation is an important topic to address the problem of reducing the generalization ability of a model due to differences in the data distribution between different domains. Domain adaptation is a type of transfer learning, which can be viewed as a transfer of knowledge from one domain to another when there is a gap between two domains with different characteristics, and closing the gap to make them similar. However, there is a limitation, in that a model trained on one domain usually does not perform as well as expected when tested on data from a domain other than the one it was trained on due to differences in the trained domain. Therefore, researchers have been thinking about how to make a model perform well in a domain that is completely different from the domain it was trained on. This was how domain adaptation was approached.
When there are two completely different datasets or two datasets with some similarity, if the similarity between the two domains is not large, it is expressed as how much domain shift has occurred when quantified. Therefore, in the field of domain adaptation, a lot of research studies have been conducted to study and solve this domain shift as much as possible. Also, when the domain shift is reduced as much as possible and the performance is good even in different domains, we say that the generalization is good. In other words, domain adaptation is the process of generalizing a model as much as possible.
Recent advances in machine learning and deep learning techniques have attracted attention on how to overcome distributional differences between domains and improve the generalization performance of models. In the field of domain adaptation, two main approaches have been used to solve the problem.
First, models that transform features between domains in a way that minimizes distributional differences between domains have been widely studied. This approach attempts to achieve adaptation by transforming data from the target domain into a distribution similar to the source domain. There are various approaches to this method. First of all, many models such as BDA [3], JAN [19], ADDA, and so on can calculate the MMD, which is the difference in probability distribution. They can also learn by reducing the distribution difference between domains as much as possible [24]. If the probability distribution difference between domains is previously calculated and learned, there are also models that can transform features themselves or directly use features to reduce the gap between domains. There are also models that can use a generative model to generate the target data and then let domains adapt and check performances of discriminators by calculating how similar they are.
Second, instead of addressing distributional differences, a common approach is to train the model to adapt to the target domain. This approach allows the model to overcome differences between domains while still being able to recognize and utilize characteristics of the target domain. To this end, research has focused on training models using labeled information from the target domain, typically using classifiers or regression models.
In these domain adaptation studies, various methods were used to reduce the gap between two domains or make them similar. Among them, the method of learning adversarially using the class label of the domain and the relationship with the domain label is mainly used [1,2,5,7,11,22]. Therefore, this method is usually referred to as adversarial domain adaptation or domain adversarial adaptation.
2.2. Bidirectional Feature Learning
Bidirectional feature learning aims to transform features between the source and target domains in both directions while preserving information. To achieve this, it is mainly studied by combining a generative network and a feature transformation process, which is a key strategy used to enhance the adaptive ability while mutually preserving characteristics between domains.
Bidirectional feature learning provides better adaptive capabilities than traditional unidirectional feature transformation. In other words, when the model performs a conversion from one domain to another, the key point is to achieve conversion while preserving features between the two domains [25,26]. In particular, recent attempts have been made to develop more powerful adaptive models by combining bidirectional feature learning with self-supervised learning, meta-learning, and so on. This can be seen as an effort to overcome the limitations of existing methods and provide more practical domain adaptation solutions. Such bidirectional feature learning can act as a potential way to strengthen the interdependence between two domains. In this way, we have devised a new network architecture that can preserve features between the two domains and still achieve good adaptation. This methodology uses an approach that deepens our understanding of the relationship between domains and trains the model to more effectively translate characteristics between the two domains while minimizing the loss of information.
However, unlike other studies, bidirectional feature learning works a little differently in this paper. Although the fields of application are different, even a comparison with one of the existing studies, bidirectional LSTM [27], shows that the LSTM is doubly connected to learn effectively. However, in this paper, extracted features are not intertwined, but simply used to calculate two loss functions. Thus, it is expressed that it is based on the bidirectional feature learning process. In this respect, the role of the bidirectional feature learning process, which is used slightly differently in this paper, can be seen through a comparison of evaluation indicators.
2.3. Generative Network
Generative models play an important role in this work. They are models that can simulate or generate distributions of real-world data. In particular, with recent advances in deep learning, generative models have attracted attention for overcoming distributional differences between domains and generating or transforming data in new domains. In the past, various generative networks such as Variational Auto-Encoders (VAEs) [8] and Generative Adversarial Networks (GANs) [10,28] have been introduced in related research. VAEs are used to learn the distribution of data in a latent space to generate different variations, while GANs use a competitive network of generators and discriminators to produce data mimicking the actual data distribution.
Autoencoder has been used in many fields for a while because it has a wide range of applications, such as utilizing convolutional layers for its application and having deep hidden layers by stacking multiple layers. In this paper, we used convolutional autoencoder (CAE), an autoencoder that utilizes convolutional layers [4]. In addition, GANs generate fake data that is almost indistinguishable from real data through competitive learning between generators and discriminators, which has the great advantage of reducing distribution differences between domains, and converting while maintaining features of the data. As a result, GANs have become a key tool in the field of domain adaptation. Recent research trends are moving towards combining GANs with VAE or CAE to develop more robust generative models. In addition, various variants that take into account characteristics of the data and the relationship between domains are proposed, which are utilized to better simulate distributional differences between domains and perform data transformations.
This paper emphasizes the role and importance of generative networks and proposes a new methodology to apply to the domain adaptation problem. In this paper, we combined autoencoder and GAN to develop a generative model considering the distribution of real data. We then applied it to the domain adaptation problem to overcome the distribution difference between the domains. In this way, realistic and stable adaptation results were obtained. The effectiveness of the proposed method was demonstrated through comparison with related studies. As a result, the accuracy of the generative network on the dataset was 98.5∼99.23%, which showed a very high classification accuracy. An error of 0.77∼1.5% was assumed to be some noise. The model was designed and tested to be robust against noise. This shows an innovative solution in the field of domain adaptation. It is expected to provide an important direction for strengthening the stability and generalization ability of models not only in domains, but also in the face of noise.
3. BiFLP-AdvDA
3.1. Model Overview
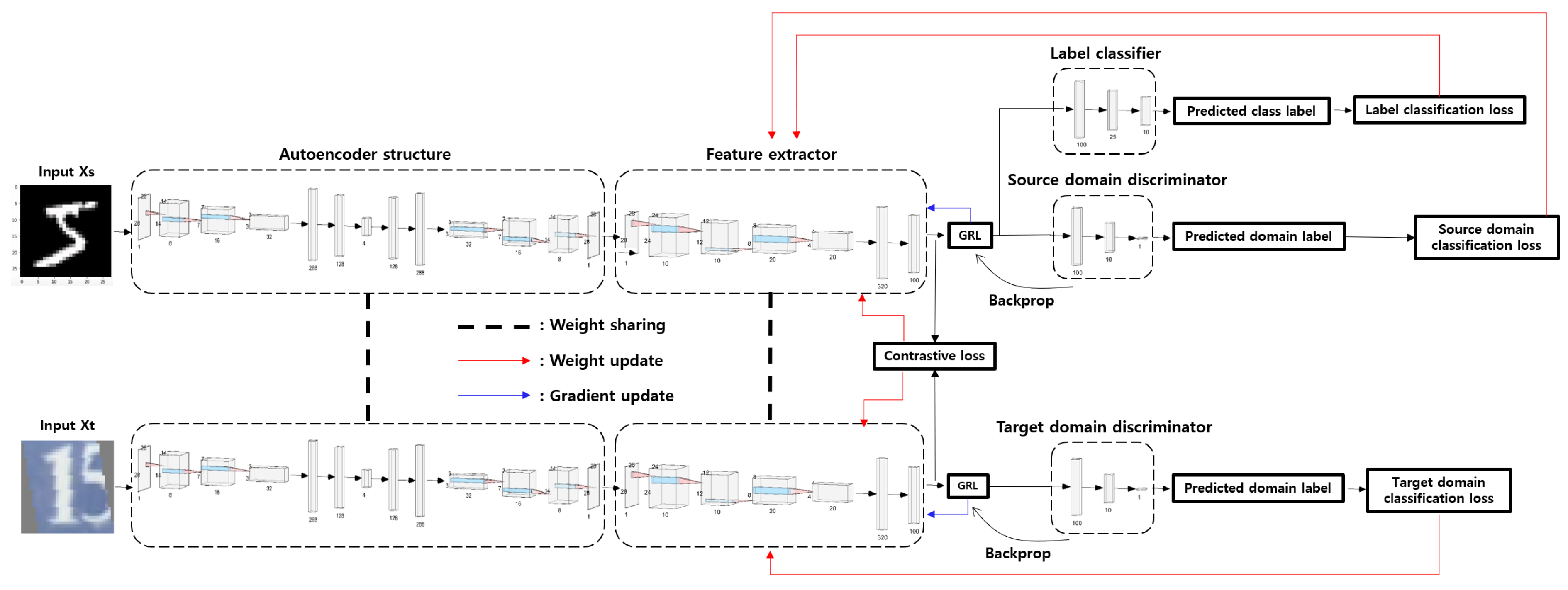
This paper is a model for performing adversarial domain adaptation. The architecture of the proposed model is shown in Figure 2. First, for preprocessing the existing dataset and constructing the model, we pretrained a generative model with a convolutional autoencoder structure on the input data which is from source domain. And the other input data is which is from target domain. We then loaded and used the pretrained model. The inputs and are passed through the pretrained generative network to reconstruct the input image data and generate a theoretically identical image. However, in practice, they are not identical. For example, if you apply the generative network that is customized to the MNIST dataset to the SVHN dataset, which is an RGB image dataset, the same image cannot be generated. Thus, results may vary depending on the source domain. However, results may change when adjusting parameters. In this paper, the classification accuracy of the generative network was 98.5∼99.23%. Images were generated by the well-trained generative model. The image data , of the generated source domain and target domain were taken as input data and features of those images were extracted with the feature extractor. This prepared us to perform the adversarial domain adaptation (AdvDA) problem. Weights were shared for consistency in experiments [29].
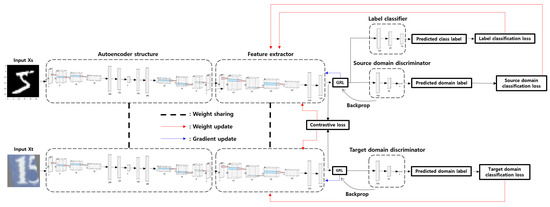
Figure 2.
The architecture of our proposed model BiFLP-AdvDA.
For the input layer, we used a convolutional autoencoder structure, and used three convolutional layers for the encoder and decoder parts, and encoded by increasing the number of channels from 1 channel to 8 channels, 16 channels, and 32 channels, and reconstructed by returning to 32 channels, 16 channels, 8 channels, and 1 channel. The amount of error in this process is considered as noise for the robustness of the model and data in this paper. After that, the rest of the learning process proceeds through the feature extractor.
It trains a label classifier with features extracted from the source domain to classify the class label of the source data. In the process, it calculates the label loss, or label classification loss, which shows how badly it classifies the label. Label classification loss uses cross-entropy loss as a general classification loss function. Therefore, this paper learns to maximize the performance of the label classifier by minimizing the label classification loss and learns a domain discriminator to determine the source domain or target domain using features. As this paper is a domain adaptation problem, it is a problem for the target domain to learn well without label information for the model learned for the source domain. Therefore, it can be said that this part is adversarial, in that the domain discriminator learns to distinguish the source domain and the target domain as well as possible, while learning to extract domain-invariant features that fool the domain discriminator into not distinguishing as well as possible with features extracted with the feature extractor. Therefore, if the label classifier has a classification loss, the domain discriminator uses the same general classification loss as the label classifier as a domain classification loss. A single device is required to classify the label of the source domain well despite a difference in distribution between the source domain and the target domain and to prevent the two domains (i.e., the source domain and the target domain) from being distinguished.
The device is the gradient reversal layer (GRL) [2] proposed in the DANN paper. This GRL acts as an intermediary between the feature extractor and the domain discriminator. When learning, it still passes linearly when forward. However, when performing backpropagation, it reverses the direction of the gradient by reversing the sign of the gradient. The inverted gradient is inserted between the domain classifier and the feature extractor. This plays a role in training the feature extractor to minimize the domain information while minimizing the domain classification loss. This allows the feature extractor to extract features with minimal domain information. The hyperparameter alpha, which controls how much domain information to include, is not a trainable parameter. In this paper, it takes the form of bidirectional feature learning, in addition to mutually conservative learning, in the direction of minimizing similarity difference between features while preserving characteristics between domains by including very little domain information.
In addition to learning methods limited to a single domain, the model in this paper induces smooth learning for a series of domains with completely different characteristics such as their distribution. In addition to reducing the gap between domains, the data itself is subjected to a slight noise effect using a pretrained generative network. By reconstructing the input image data, we propose a method to improve the robustness of both the domains and data.
3.2. Loss Functions
This paper aims to reduce the gap between domains and improve the robustness of the model using a generative model with an autoencoder structure and an adversarial domain adaptation (BiFLP-AdvDA) approach based on bidirectional feature learning to extract features that can finally be learned regardless of the domain. This study also aims to perform domain adaptation to minimize the gap between domains so that characteristics of domains become similar. For these purposes, four loss functions and a total of five loss functions are used until total loss using all of them. Formulas and brief descriptions of the loss functions are presented below.
Label classification loss was used to perform a classification task using data from the source domain and to minimize the difference between the actual and predicted labels. The following is the formula for label classification loss:
where y denotes actual classified class labels of the source domain, which can be binary or multi-class depending on the problem; denotes predicted class labels of the source domain containing probabilities for each class; i denotes an index variable representing classes, varying depending on the number of possible classes in a classification task; denotes the value corresponding to class i in the actual label vector, the value of ; and i in the log function corresponds to class i in the predicted probability vector, representing the likelihood of belonging to that class.
Domain classification loss was used to train the domain discriminator to misclassify the domain as much as possible. This helps the feature extractor to extract features that the domain discriminator will use to prevent the domain discriminator from classifying as well as possible. As a loss function, unlike label classification loss, we used binary cross-entropy loss (BCE loss) because the task was to classify into one of two domains. The following is the formula for domain classification loss:
For the source domain,
For the target domain,
where indicates the source domain classification loss function; denotes the actual classified source domain labels obtained using the domain discriminator; denotes the predicted source domain labels; i denotes the index variable for the elements in one batch of source data; denotes the target domain classification loss function; indicates a binary value of 0 or 1 and indicates whether the domain is the source or target; denotes the predicted domain labels of the target domain; and i denotes the index variable for the elements in one batch of the target data.
Adversarial loss was used to train the domain discriminator to not discriminate between features extracted from the feature extractor. In this way, it learns to reduce the gap between domains. Here is the formula for adversarial loss:
For the source domain,
For the target domain,
where denotes the classification loss for the source domain; denotes the source domain classification loss; alpha denotes a hyperparameter representing the weight or importance given to the source loss in the combination; denotes the classification loss for the source domain, as already mentioned; and denotes the target domain’s classification loss.
The adversarial loss function, represented by Equations (4) and (5), was calculated by utilizing Equations (1) and (2) or Equation (3) as appropriate. First of all, Equation (1) is a task to classify the label of the source domain as best as possible, as mentioned earlier, and the corresponding loss function is learned to be maximized; while Equations (2) and (3) are the main tasks to learn to distinguish whether the input data are from the source domain or the target domain as much as possible. Corresponding loss functions are learned to be minimized. In this respect, it is similar to the existing minmax loss. Thus, it is called adversarial loss. In addition, the alpha value of GRL, borrowed from the model proposed for the domain adaptation task, which is the subject of this paper, is multiplied by the domain classification loss to adjust how much to use characteristics of the domain. Contrastive loss is a loss function to measure similarity between two features [30,31], which is defined as the Euclidean distance between two features with the following formula:
where f indicates the feature extraction function mapping the input data to feature embeddings; and denotes the original source data and the original target data reconstructed by the pretrained autoencoder; indicates the Euclidean distance, obtained by measuring the distance of features between the source data and the target data using the feature embeddings generated by the function; f and n denote the size of one batch of the source and target domains and the number of data points within that batch; i and j denote the index variables of the source and target data; denotes the ith data point of one batch of ; denotes the jth data point of one batch of ; the means of D are different for each loss function. One of the D’s, in Equations (2) and (3), indicates the domain discriminator and the other, in Equations (6) and (7), indicates the Euclidean distance; y denotes a binary label that takes the value 0 or 1, 1 if the two features are similar and 0 if they are different, for example, in traditional research, the loss function is computed in such a way that if a pair of data enters as input a pair of data of the same class, the value of y is 1, while if a pair of data enters as input a pair of data of a different class, the value of y is 0; and m denotes the margin value. This hyperparameter m is not learnable. However, it can be tuned to an appropriate value through experimentation.
The total loss function is calculated by summing the loss functions of all components. After all, minimizing it is the goal of generalizing the model across domains and guiding it to extract similar features. Here is the formula for the total loss function.
In the learning process of the model proposed in this paper, the loss function is finally composed of adversarial loss and contrastive loss, which are arbitrarily configured for the model as in Equation (8). By learning the loss function for the source domain and the target domain adversarially, the feature extractor extracts domain-invariant features that work well in both domains, i.e., features with similar characteristics to both domains. The contrastive loss is calculated according to the Euclidean distance between the two extracted features so that the similarity of the data points in the vector space increases. Eventually, the boundary between the two domains is blurred.
4. Experimental Results
In this paper, we examine the effectiveness of a domain adaptation method based on bidirectional feature learning with generative networks by comparing it with various domain adaptation methods. This allows us to clearly identify its superiority and strengths. In this section, we first describe the model implementation and experimental environment, followed by experimental results and quantitative and qualitative evaluations, including the datasets used in the experiments. We also provide various evaluation metrics to prove that it performs well compared to existing studies. We use MNIST, USPS, SVHN, and EMNIST as datasets. MNIST is a validated dataset. However, the SVHN dataset is a sparse dataset with varying results depending on the preprocessing. In some cases, it does not learn at all. Thus, we need to pay attention to the preprocessing for datasets other than MNIST. More details on these experiments will be discussed in the following sections.
4.1. Experiment Configurations
To implement the model proposed in this paper, the author built the following experimental environment, which is introduced in Table 2.
Table 2.
Experimental configuration of experiments for adversarial domain adaptation.
In this paper, two experimental environments were used. The hardware environments, such as CPU, GPU, and operating system, were different, but the software environments for learning were mostly the same. First of all, we used Python version 3.10 in common and implemented and experimented with Pytorch-based models. The version of Pytorch does not matter much. We used 2.01+cu118, the most recent updated version at the time of the experiment. Other libraries included NumPy for data preprocessing and image processing and matplotlib, sklearn, and torchvision for the visualization of results.
4.2. Datasets
The Mixed National Institute of Standards and Technology (MNIST) is a dataset of handwritten digit images widely used in machine learning and computer vision. As shown in Figure 3, the dataset consists of images of handwritten digits from 0 to 9. Each image is a monochrome image with a size of 28 × 28 pixels. Each image is a 28 × 28 pixel grayscale image represented by a pixel value between 0 and 255. The entire dataset consists of a total of 70,000 images, of which 60,000 belong to the training set and the remaining 10,000 belong to the test set. This dataset is used as a representative benchmark for number recognition problems. It is widely used to compare and evaluate the performance of machine learning algorithms. Since it has already been widely used, it performs well for classification tasks. Therefore, we thought it would perform well for domain adaptation. The number of data was too large for training.

Figure 3.
Samples of MNIST dataset.
The United States Postal Service (USPS) dataset is a dataset of handwritten digit images collected from the United States Postal Service. This dataset is primarily used for recognizing handwritten zip codes. As shown in Figure 4, the data contains digit images similar in shape and organization to the aforementioned MNIST, consisting of black and white images with a size of 16 × 16. The entire dataset contains a total of 9298 images, of which 7291 belong to the training set and the remaining 2007 belong to the test set. This dataset is used in applications such as address recognition and mail sorting. It can also be utilized for domain adaptation tasks.

Figure 4.
Samples of USPS dataset.
The Street View House Numbers (SVHN) dataset is a dataset of house number images taken in a street environment, as shown in Figure 5. This dataset is a collection of images containing numerical numbers of houses. It addresses the problem of number recognition in a realistic environment. The entire dataset consists of 604,388 images, of which 73,257 belong to the training set, 26,032 belong to the validation set, and the remaining 26,032 belong to the test set. The images were taken in a variety of street conditions, including complex backgrounds and lighting variations. The SVHN dataset is used to evaluate performance under realistic conditions. It is one of the most important datasets in the field of digit recognition.

Figure 5.
Samples of SVHN dataset.
This dataset is a good dataset for number recognition. Thus, it was also selected in this study. However, since the dataset itself is taken from real photos, even though it is labeled, the performance of the dataset may vary depending on the preprocessing.
The EMNIST (extended MNIST) dataset is a dataset of handwritten alphabet letters and numeric images. This dataset has a similar organization to MNIST, with a total of 814,255 images. Of these, 814,255 images are in the training set. The EMNIST dataset is used to recognize handwritten alphabet letters and numbers. It is commonly used to solve the problem of handwriting recognition. It is one of the most important datasets that can be applied to the problem of recognizing various alphabetic characters and numbers.
As can be seen in Figure 6, it is an extension of the MNIST dataset. Thus, the number of data is very large compared to MNIST. The reason is that it consists of grayscale images that are easy to classify, such as numeric data from 0 to 9, letters from a to z, and so on. Therefore, it was thought that it would be best to run a domain adaptation experiment with MNIST.

Figure 6.
Samples of EMNIST dataset.
4.3. Performance Metrics
In machine learning and pattern recognition tasks, performance evaluation metrics play a key role in quantifying and comparing the performance of models. In this section, we will take a closer look at the main performance metrics used to evaluate the performance of classification models: precision, recall, and F1 score [32].
First, precision is a metric that indicates the percentage of samples that a model predicts as true that are actually true. More specifically, precision indicates how many results the model predicts as positive classes that are actually positive. This metric is represented by the following formula:
where true positives refers to the number of samples that the model predicts are true and are actually true, while false positives refers to the number of samples that the model predicts are false but are actually true. Precision is a measure of how reliable a model’s positive predictions are, which is important for reducing unnecessary misdiagnoses.
Recall is a metric that shows the percentage of samples that the model predicts as true out of those that are actually true. In other words, recall shows how many of the true positive samples in a positive class the model correctly detects. Recall is calculated with the following formula:
Recall indicates how well the model detects true positives. It is particularly important for ensuring that positive cases are not missed.
The F1 score is a metric calculated as the harmonic mean of the precision and recall, which balances the accuracy and precision of the model. It is a useful metric for evaluating a model’s performance from different angles. The F1 score is calculated using the following formula:
The F1 score represents a balance between precision and recall, as shown in Equation (11). It evaluates a model’s performance by considering both the accuracy of its positive class predictions and the detection rate of actual positive samples. This provides a more comprehensive view of a model’s performance than considering accuracy alone. This concludes our detailed discussion of performance evaluation metrics. These metrics can be used to evaluate the performance of a model. They can help us to select and refine the right model for a particular problem.
4.4. Results
In this section, we will describe experiments conducted using a bidirectional-feature-learning-based domain adaptation method with a generative network. We will also provide the overall experimental environment and experimental results. As a quantitative evaluation, we have tried to prove the validity of this paper by comparing the proposed model with the DANN and ADDA models that already exist. To prove how well the domain adaptation is achieved, in addition to the comparison between models, the proposed model was trained only in the source domain and the test accuracy was measured and compared. This shows that it is an effective way to realize better model adaptation. By using the loss function, which was not included in the models implemented in the previous studies mentioned above, the interaction between the generative network and the feature conversion process could reduce the difference in the distribution of data, increase the similarity of the extracted features, and strengthen the interdependence between the two domains. This approach was successfully implemented through numerical comparison of several evaluation indicators. As a qualitative evaluation, the comparison of data points in the source and target domains before and after learning provided a visualization of how well the domain adaptation was achieved. This suggests that bidirectional feature learning can effectively reduce distributional differences between datasets, significantly reducing the distance between unadapted and adapted data.
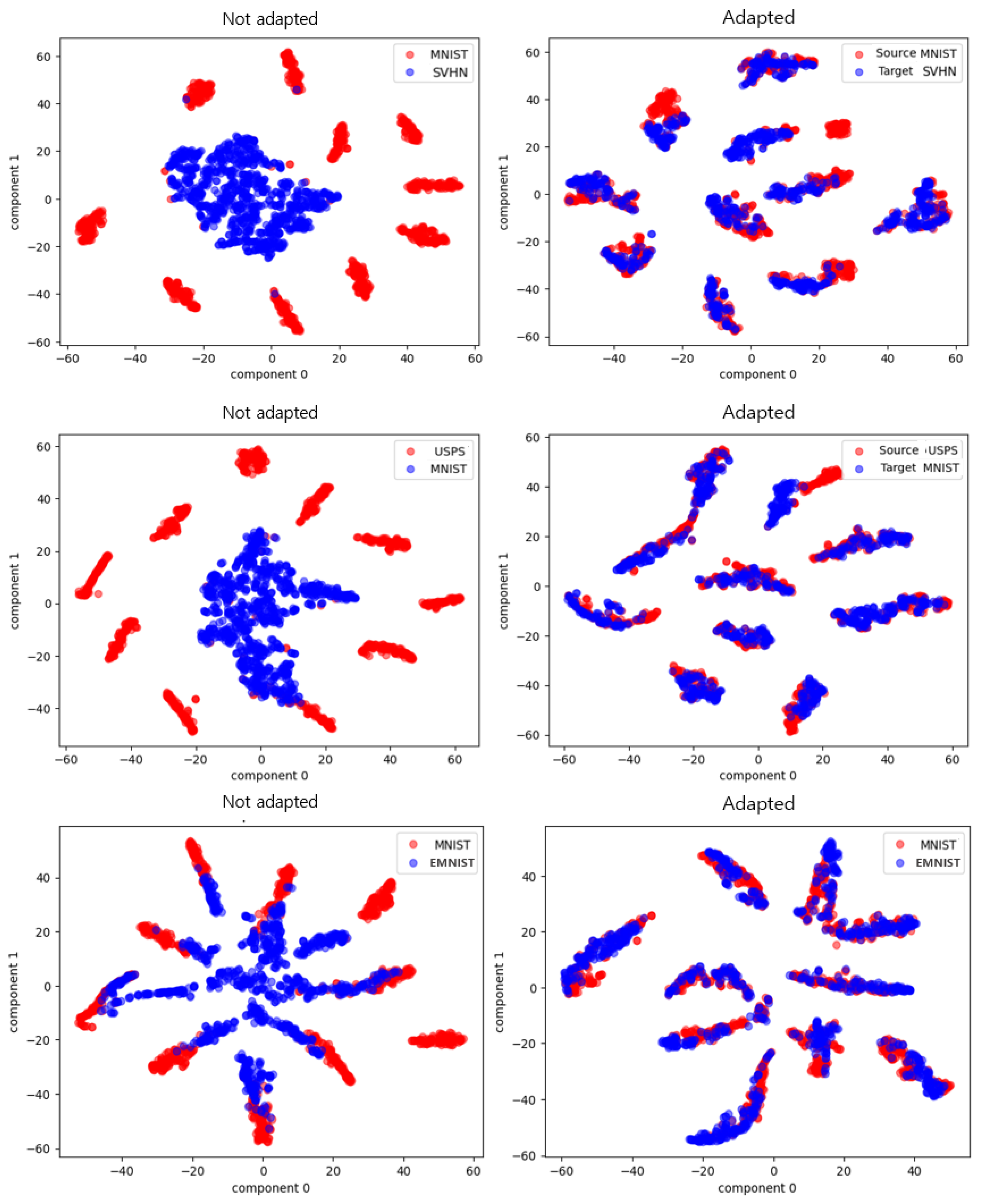
Figure 7 shows a visualization of data points without adaptation and with adaptation. It could be seen from actual experiments that the two-way feature-learning-based domain adaptation method with a generative network outperformed the traditional one-way feature conversion method. Compared to traditional domain adaptation techniques, the method proposed in this paper showed higher accuracy and stability in quantitative evaluation. Each row shows the results of experiments conducted on different datasets divided into source and target domains, with red indicating the target domain and blue indicating the source domain. From the top, each row was organized in the following order: MNIST USPS, SVHN MNIST, EMNIST MNIST. In addition, each column could be divided into cases without domain adaptation and with domain adaptation in each experimental environment. From the left, column 1 represents the case without domain adaptation and column 2 represents the case with domain adaptation. It can be seen from Figure 7 that the model proposed in this study performed well in domain adaptation.
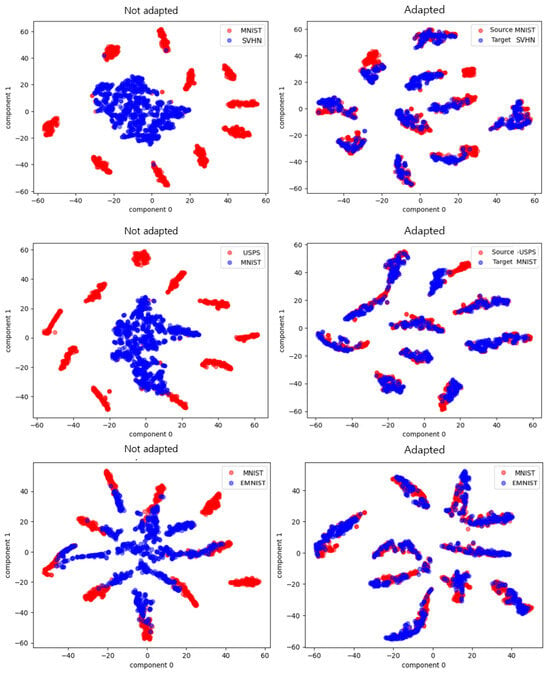
Figure 7.
Visualization of data points without domain adaptation and with domain adaptation.
The domain adaptation results in this paper are shown in Table 3. We can see that the proposed method outperformed other methods by a large margin, except for the SVHN to MNIST experimental results. This figure shows the test accuracy of the experiments, which is a value between 0 and 1. The maximum value of 1 indicates 100% accuracy. Therefore, the results of this model showed a high accuracy, of more than 90%, except for the one case mentioned above. Even the comparison of figures with existing studies and the results of learning and testing only the source domain showed a lot of differences. This indicates that the two-way approach of feature transformation and feature learning through generative networks can improve the generalization ability of the model by more effectively reducing distributional differences between domains.
Table 3.
Test accuracy of adversarial domain adaptation between other models for target to source domain.
Furthermore, Table 4, Table 5 and Table 6 show that the ADDA paper is part of a follow-up study published after the DANN paper. It does not change the fact that it performs better than DANN to some extent. However, the moment when the DANN model has a higher accuracy value than the ADDA model is the EMNIST to MNIST experiment shown in Table 3. On the other hand, the proposed model has a value of more than 0.98 for evaluation metrics, with the highest value close to 0.998, which means that the performance is good. We focused on finding the optimal value for the number of epochs through multiple experiments and set the number of epochs to 150. As a result, the main model took 1 h and 14 min, the ADDA model took 42 min by pretraining a CNN on the source domain to reduce the time, and the DANN model took 55 min.
Table 4.
Adversarial domain adaptation for MNIST (target domain) to USPS (source domain) dataset.
Table 5.
Adversarial domain adaptation for SVHN (target domain) to MNIST (source domain) dataset.
Table 6.
Adversarial domain adaptation for EMNIST (target domain) to MNIST (source domain) dataset.
The qualitative results also show the superiority of bidirectional feature learning in a visual quality evaluation. Figure 7 shows a visualization of the experimental results when only the source domain was trained and tested, on the left, and when the entire model was trained and tested, on the right. Comparing the two, it can be seen that the proposed model achieved excellent results in domain adaptation. This can be attributed to the fact that the generated network reflected the actual distribution of the data well. The effect of the bidirectional feature transformation also strengthened the interdependence between the two domains.
Taken together, these experimental results show that the use of generative models and bidirectional feature learning can significantly improve the performance compared to various existing domain adaptation studies. It is an effective way to achieve better model adaptation capabilities. This suggests that using interaction between the generative network and the feature transformation process is a successful approach to reduce distributional differences in the data and enhance interdependence between the two domains.
4.5. Discussion
In this section, we present the effectiveness of domain adaptation based on the proposed bidirectional feature learning method with generative networks through experimental results. We also describe our main contributions through comparison with existing domain adaptation techniques. The quantitative evaluation showed that the bidirectional feature learning method had higher accuracy and stability than the one-way feature conversion method. Domain adaptation results between various datasets confirmed that the bidirectional feature learning with generative network outperformed previous studies such as DANN and ADDA. Although it might not be possible to conclude that the robustness of the model was improved based on the experimental results alone, considering the flow of minimizing domain information, increasing similarity between features, and reducing gaps from one-way learning to two-way learning, it is clear that bidirectional feature learning with a generative network in the field of domain adaptation is effective because the accuracy and various evaluation metrics recorded higher values than for previous domain adaptation studies.
The visual quality evaluation visually confirmed that the bidirectional feature learning method produced good results in domain adaptation. This was determined to be a result of the generative network more accurately reflecting the actual distribution of the data. The effect of the bidirectional feature transformation strengthened the interdependence between the two domains. Taken together, this study clearly demonstrates that the combination of the bidirectional feature learning method and generative network shows higher performance than various other domain adaptation techniques. It is an effective method for reducing distribution difference between datasets and improving the adaptive ability of the model.
The limitations of this study are discussed in this section. We believe that there are four main limitations of this paper. First, this paper proposed a method to solve the domain adaptation problem by reconstructing real image data, but when the variability in the domain is high, the quality and generalization ability of the reconstructed image data may be limited. In particular, it is necessary to discuss how to overcome the limitations for the adaptation problem between complex and diverse domains. Second, the proposed method relies on the amount of training data. In the absence of a sufficient amount of labeled data, the generalization ability of the model may suffer. This is a common problem in real-world scenarios, and we need to discuss how to develop effective models even with small amounts of data. Third, although the reconstructed image data were considered as noisy image data, the performance of the model may fluctuate depending on the degree and shape of the noise. This may cause the model to be sensitive to noise, and ways to improve this instability are needed. Fourth, the proposed method can take a long time to learn and infer, and there may be issues with scalability on large datasets. There is a need to develop more efficient learning and inference methods to increase their practical applicability.
5. Conclusions and Outlook
This study proposes a domain adaptation based on a bidirectional feature learning method with a generative network. The main idea that it introduces outperforms the traditional one-way feature transformation method in the domain adaptation problem. Bidirectional feature learning can improve the efficiency of domain adaptation through an approach that reduces distributional differences in the data and strengthens the interdependence between the two domains through the interaction of the generative network and the feature transformation process. This idea emphasizes the common features between datasets. The role of the generative network is to learn the true distribution of the data more accurately, which improves the performance of the adaptation model and increases the robustness of the model to noise.
As a future direction of this research, we would like to develop domain adaptation techniques with higher performance and generalization ability. To this end, we plan to explore adaptation across more diverse datasets and domains to maximize the generalization ability of the model and study its applicability in various domains in the real world. We also want to develop more robust and reliable domain adaptation techniques by conducting research for optimizing network architecture and learning strategies with the effective combination of generative networks and feature transformations. Finally, we plan to explore the feasibility of using bidirectional feature learning in applications other than domain adaptation so that it can be applied to a wider variety of problems.
Author Contributions
Conceptualization, C.H.; methodology, C.H.; software, C.H.; validation, C.H.; formal analysis, C.H.; investigation, C.H.; resources, C.H.; data curation, C.H.; writing—original draft preparation, C.H.; writing—review and editing, C.H.; visualization, C.H.; supervision, H.C. and J.J.; project administration, H.C. and J.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the SungKyunKwan University and the BK21 FOUR (Graduate School Innovation). It was also funded by the Ministry of Education (MOE, Korea) and National Research Foundation of Korea (NRF).
Data Availability Statement
Four public datasets of the MNIST database of handwritten digits (https://www.kaggle.com/datasets/hojjatk/mnist-dataset), accessed on 1 March 2023), SVHN dataset (http://ufldl.stanford.edu/housenumbers/, accessed on 1 March 2023), and two Pytorch datasets of EMNIST Dataset (https://pytorch.org/vision/main/generated/torchvision.datasets.EMNIST.html, accessed on 1 March 2023), and USPS dataset (https://pytorch.org/vision/main/generated/torchvision.datasets.USPS.html, accessed on 1 March 2023).
Acknowledgments
This research was supported by the SungKyunKwan University and the BK21 FOUR (Graduate School Innovation) and funded by the Ministry of Education (MOE, Korea) and National Research Foundation of Korea (NRF). Moreover, this research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ICT Creative Consilience Program (IITP-2023-2020-0-01821) supervised by the IITP (Institute for Information & communications Technology Planning & Evaluation).
Conflicts of Interest
The authors have no conflict of interest relevant to this study to disclose.
References
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on International Conference on Machine Learning-ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 1180–1189. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced Distribution Adaptation for Transfer Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 1129–1134. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Ma, S.; Gao, S.-H.; Gao, Y. Baochang Zhang End-to-End Label-Constraint Adaptation for Adversarial Domain Alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, S.; Li, T.; Zhang, H.; Zhang, R.; Zhang, H. Graph-Based Domain Adaptation with Attention-Guided Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Maggipinto, M.; Masiero, C.; Beghi, A.; Susto, G.A. A Convolutional Autoencoder Approach for Feature Extraction in Virtual Metrology. Procedia Manuf. 2018, 17, 126–133. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 95–104. [Google Scholar]
- Volpi, R.; Morerio, P.; Savarese, S.; Murino, V. Adversarial Feature Augmentation for Unsupervised Domain Adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5495–5504. [Google Scholar]
- Hou, J.; Ding, X.; Deng, J.D.; Cranefield, S. Unsupervised Domain Adaptation using Deep Networks with Cross-Grafted Stacks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 28–29 October 2019; pp. 3257–3264. [Google Scholar]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain separation networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona Spain, 5–10 December 2016; pp. 343–351. [Google Scholar]
- Kim, T.; Jeong, M.; Kim, S.; Choi, S.; Kim, C. Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12448–12457. [Google Scholar]
- Huang, L.; Zhang, C.; Zhang, H. Self-adaptive training: Beyond empirical risk minimization. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS’20), Virtual, 6–12 December 2020. Article 1624. [Google Scholar]
- Murez, Z.; Kolouri, S.; Kriegman, D.; Ramamoorthi, R.; Kim, K. Image to Image Translation for Domain Adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4500–4509. [Google Scholar]
- Long, M.; Cao, Y.; Cao, Z.; Wang, J.; Jordan, M.I. Transferable Representation Learning with Deep Adaptation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 3071–3085. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2208–2217. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Liu, M.; Li, J.; Li, G.; Pan, P. Cross Domain Recommendation via Bi-directional Transfer Graph Collaborative Filtering Networks. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM ’20), Online, 19–23 October 2020; pp. 885–894. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T. Asymmetric Tri-training for Unsupervised Domain Adaptation. In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2988–2997. [Google Scholar]
- Baktashmotlagh, M.; Harandi, M.T.; Lovell, B.C.; Salzmann, M. Unsupervised Domain Adaptation by Domain Invariant Projection. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 769–776. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional Learning for Domain Adaptation of Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6929–6938. [Google Scholar]
- Cai, Y.; Yang, Y.; Zheng, Q.; Shen, Z.; Shang, Y.; Yin, J.; Shi, Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 190. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Rozantsev, A.; Salzmann, M.; Fua, P. Beyond Sharing Weights for Deep Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 801–814. [Google Scholar] [CrossRef] [PubMed]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent a New Approach to Self-Supervised Learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS’20), Online, 6–12 December 2020. Article 1786. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified Deep Supervised Domain Adaptation and Generalization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Van Rijsbergen, C.J. Information Retrieval, 2nd ed.; Butterworth: London, UK; Boston, MA, USA, 1979. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).