
Surgical Instrument Recognition Based on Improved YOLOv5

Abstract
:1. Introduction
2. Materials and Methods
2.1. Images Dataset and Augmentation
2.2. YOLOv5 and Improve Methods
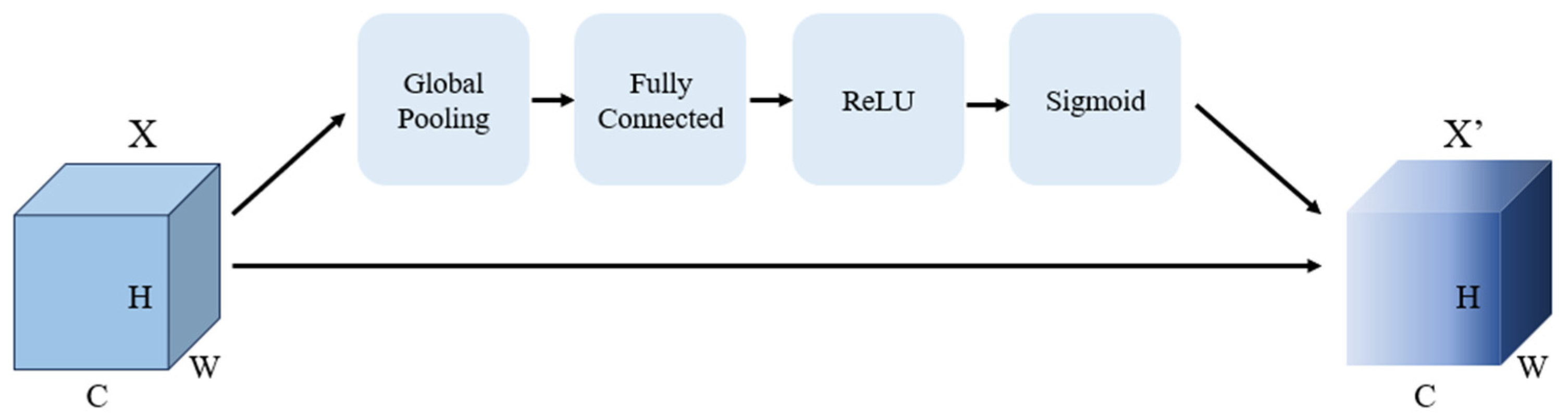
2.2.1. Squeeze-and-Excitation Attention Mechanism
2.2.2. IoU, GIoU, and Wise-IoU
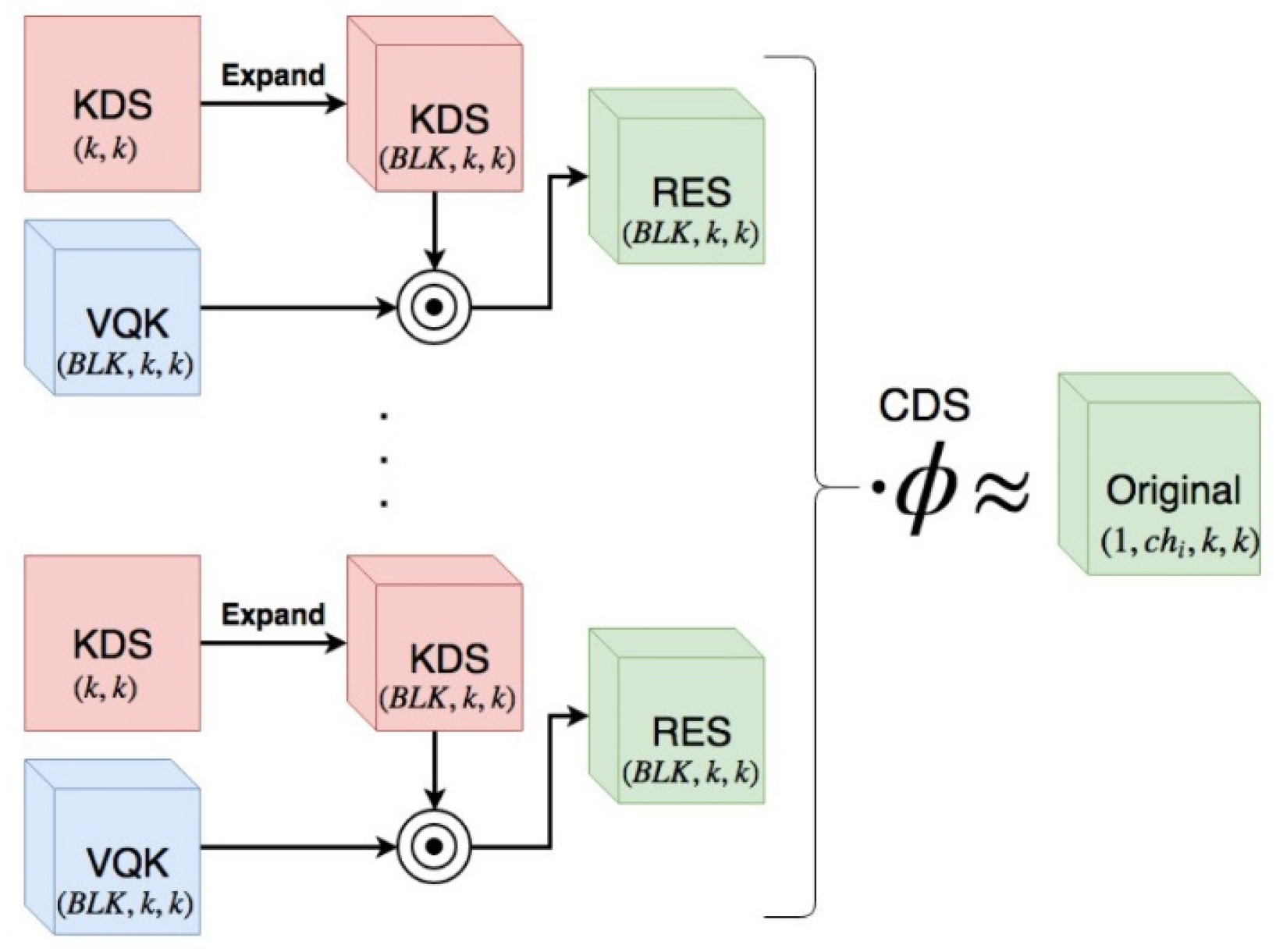
2.2.3. Distribution Shifting Convolution
3. Ablation Experiment
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Tong, X.; Mao, Y.; Griffin, W.B.; Kannan, B.; DeRose, L.A. A vision-Guided Robot Manipulator for Surgical Instrument Singulation in A Cluttered Environment. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 3517–3523. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Ahuja, U.; Kumar, M. Face mask detection using YOLOv3 and faster R-CNN models: COVID-19 environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerlan, 2016. [Google Scholar]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Ghiasi, G.; Lin, T.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Kletz, S.; Schoeffmann, K.; Benois-Pineau, J.; Husslein, H. Identifying Surgical Instruments in Laparoscopy Using Deep Learning Instance Segmentation. In Proceedings of the 2019 International Conference on Content-Based Multimedia Indexing (CBMI), Dublin, Ireland, 4–6 September 2019; pp. 1–6. [Google Scholar]
- Wang, S.; Raju, A.; Huang, J. Deep Learning Based Multi-Label Classification for Surgical Tool Presence Detection in Laparoscopic Videos. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 620–623. [Google Scholar]
- Sugimori, H.; Sugiyama, T.; Nakayama, N.; Yamashita, A.; Ogasawara, K. Development of a Deep Learning-Based Algorithm to Detect the Distal End of a Surgical Instrument. Appl. Sci. 2020, 10, 4245. [Google Scholar] [CrossRef]
- Koskinen, J.; Torkamani-Azar, M.; Hussein, A.; Huotarinen, A.; Bednarik, R. Automated Tool Detection with Deep Learning for Monitoring Kinematics and Eye-Hand Coordination in Microsurgery. Comput. Biol. Med. 2022, 141, 105121. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. Available online: https://arxiv.org/pdf/1804.02767.pdf (accessed on 17 February 2023).
- Glenn, J.; Alex, S.; Jirka, B. Ultralytics/Yolov5. Available online: https://github.com/ultralytics/Yolov5 (accessed on 17 February 2023).
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Kim, J.-H.; Kim, N.; Park, Y.W.; Won, C.S. Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. J. Mar. Sci. Eng. 2022, 10, 377. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia (MM ‘16), Association for Computing Machinery, New York, NY, USA, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Tong, Z.; Chen, Y. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. Available online: https://arxiv.org/pdf/2301.10051.pdf (accessed on 24 January 2023).
- Gennari, M.; Fawcett, R. DSConv: Efficient Convolution Operator. Available online: https://arxiv.org/pdf/1901.01928.pdf (accessed on 7 January 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | The Original Dataset | The Augmentation Dataset | Total |
|---|---|---|---|
| Hemostat | 512 | 3072 | 3854 |
| Speculum | 389 | 2334 | 2723 |
| Napkintong | 375 | 2250 | 2625 |
| Scissors | 336 | 2016 | 2352 |
| Tweezers | 338 | 2028 | 2366 |
| Colposcope | 309 | 1854 | 2163 |
| Attractor | 330 | 1980 | 2310 |
| Stripper | 388 | 2328 | 2716 |
| Detection Index | The Original YOLOv5 | SE | DSC | Wise-IoU | SE + DSC | SE + Wise-IoU | DSC + Wise-IoU |
|---|---|---|---|---|---|---|---|
| Hemostat’s AP (%) | 93.4 | 94.9 | 94.6 | 94.7 | 94.3 | 94 | 94.9 |
| Speculum’s AP (%) | 94.1 | 93.4 | 92 | 92.9 | 92.1 | 92.5 | 92.3 |
| Napkintong’s AP (%) | 92.2 | 94.3 | 95.1 | 95 | 95.2 | 95.2 | 95 |
| Scissors’ AP (%) | 90.9 | 94.2 | 92.2 | 93.3 | 93.2 | 92.9 | 92.1 |
| Tweezers’ AP (%) | 76 | 75.7 | 76.4 | 76.1 | 77.1 | 77.5 | 77.4 |
| Colposcope’s AP (%) | 96.7 | 97 | 96.4 | 96.1 | 96.9 | 97.3 | 96.4 |
| Attractor’s AP (%) | 75.8 | 77.2 | 79.5 | 79.2 | 79.2 | 79.1 | 78.8 |
| Stripper’s AP (%) | 75.9 | 78.2 | 76.4 | 77.2 | 78.4 | 77.9 | 79.6 |
| mAP (%) | 86.9 | 88.1 | 87.8 | 88 | 88.3 | 88.3 | 88.3 |
| FLOPs (G) | 16.9 | 16.9 | 10.3 | 16.9 | 10.3 | 16.9 | 10.3 |
| Detection Index | The Improved YOLOv5 | The Original YOLOv5 | SSD |
|---|---|---|---|
| Hemostat’s AP (%) | 94.4 | 93.4 | 71.8 |
| Speculum’s AP (%) | 92.7 | 94.1 | 68.1 |
| Napkintong’s AP (%) | 95.2 | 92.2 | 74.1 |
| Scissors’ AP (%) | 94.6 | 90.9 | 74.6 |
| Tweezers’ AP (%) | 77.1 | 76 | 67.7 |
| Colposcope’s AP (%) | 97.6 | 96.7 | 71.0 |
| Attractor’s AP (%) | 78.9 | 75.8 | 74.2 |
| Stripper’s AP (%) | 78.8 | 75.9 | 66.0 |
| mAP (%) | 88.7 | 86.9 | 71.0 |
| FLOPs (G) | 16.9 | 10.3 | 47.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, K.; Pan, S.; Yang, L.; Yu, J.; Lin, Y.; Wang, H. Surgical Instrument Recognition Based on Improved YOLOv5. Appl. Sci. 2023, 13, 11709. https://doi.org/10.3390/app132111709
Jiang K, Pan S, Yang L, Yu J, Lin Y, Wang H. Surgical Instrument Recognition Based on Improved YOLOv5. Applied Sciences. 2023; 13(21):11709. https://doi.org/10.3390/app132111709
Chicago/Turabian StyleJiang, Kaile, Shuwan Pan, Luxuan Yang, Jie Yu, Yuanda Lin, and Huaiqian Wang. 2023. "Surgical Instrument Recognition Based on Improved YOLOv5" Applied Sciences 13, no. 21: 11709. https://doi.org/10.3390/app132111709
APA StyleJiang, K., Pan, S., Yang, L., Yu, J., Lin, Y., & Wang, H. (2023). Surgical Instrument Recognition Based on Improved YOLOv5. Applied Sciences, 13(21), 11709. https://doi.org/10.3390/app132111709