4.1. Four-Room Game
In the classic four-room reinforcement learning environment, the agent navigates a maze of four rooms connected by four gaps in the walls. In order to receive a reward, the agent must reach the green target square. Both the agent and the goal square are randomly placed in any of the four rooms. The environment is contained in the minigrid [
17] library, which contains a collection of 2D grid world environments that contain goal-oriented tasks. The agents in these environments are red triangular agents with discrete action spaces. These tasks include solving different maze maps and interacting with different objects (e.g., doors, keys, or boxes). The experimental parameter settings for the four-room game are presented in
Table 1.
In the four-room game environment, a single-layer fully connected neural network is employed to estimate the value function. The input dimension is 3, the hidden layer has 100 units, and the output dimension is 4. The neural network is trained using the error backpropagation method. Based on Martin Klissarov’s work [
18], five different values of
were tested. The experimental results indicated that the best performance was achieved with
. Therefore, this parameter value is used directly in this study.
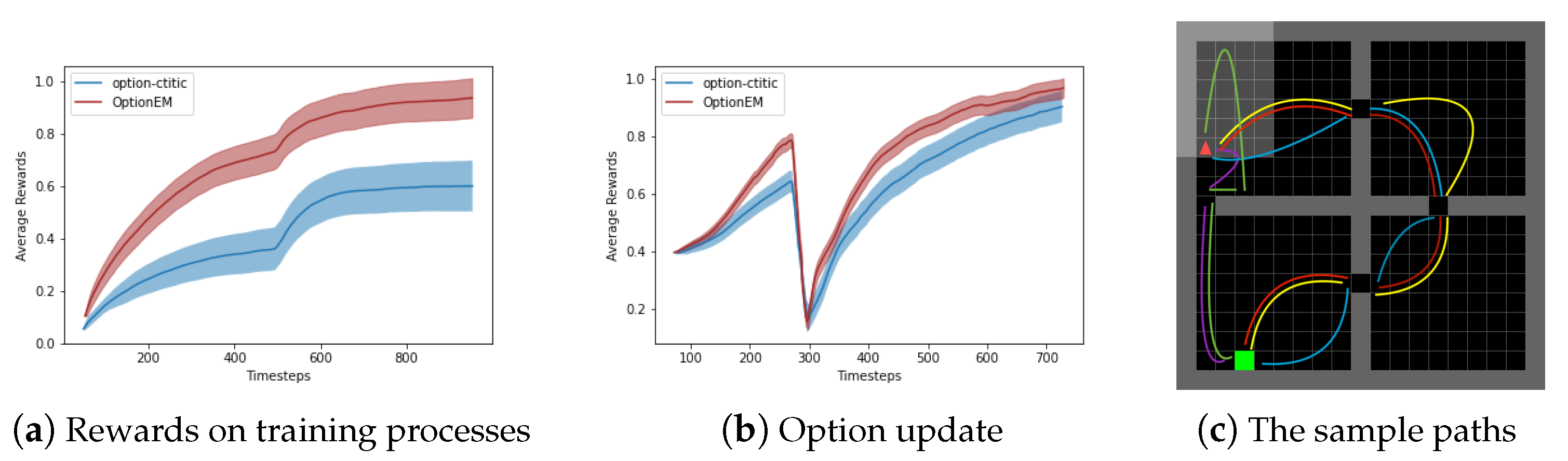
In
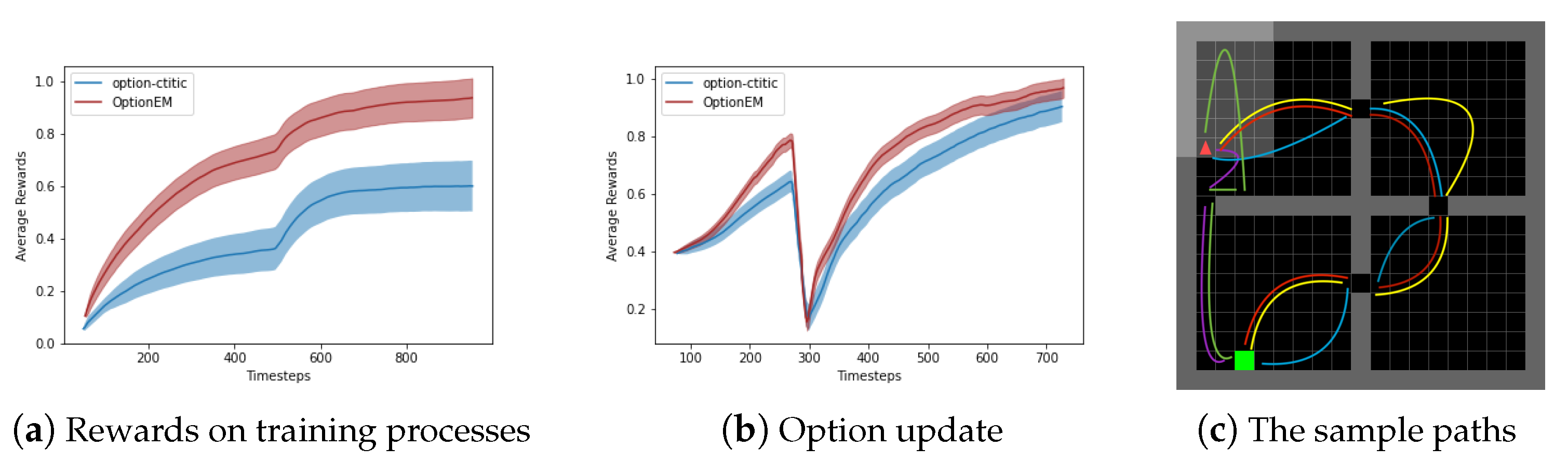
Figure 2, assuming that options have been provided and are kept fixed throughout the learning process, the only element being updated is the option-value function
. The option policy uses this function for selecting among options. The multi-option update rule from Equation (
3) is compared to the case of updating only the sampled option in the state. Four options designed by Sutton et al. are used in this scenario. In this case, the OptionEM method achieves a significantly better sample efficiency, demonstrating how the proposed method accelerates learning the utility of a suitable set of options.
For the case of learning all option parameters, the learning process is conducted using Equation (
4). In this setting, the OptionEM method is compared against the option-critic (OC) algorithm and the actor-critic (AC) algorithm. Both the OC and AC algorithms outperform the baseline algorithm in terms of hierarchical agent performance. However, the agent is able to achieve similar performance to the OC algorithm in approximately half the number of episodes. Additionally, it is noteworthy that OptionEM exhibits lower variance across different runs, which is consistent with the anticipated reduction in variance effect of the expected updates from prior research.
Figure 2 displays five paths taken by the agent in the game, with fixed start and goal points. Training and exploration processes showcase the comparison experiments between OptionEM and the option-critic algorithm. The option-critic algorithm exhibits some imbalance among options, where a single option is consistently preferred by the policy. This imbalance is more pronounced when using tabular value functions, leading to the degradation of the option-critic algorithm into a regular actor-critic algorithm. However, this imbalance is mitigated when using neural networks for value function approximation. Due to the shared information among options, the robustness of learning strategies on both the environment’s stochasticity and option policy learning process is improved, allowing the OptionEM algorithm to achieve a balanced performance based on state space separation.
The
Figure 3 illustrates the option intentions of the OptionEM algorithm and the option-critic algorithm during the testing phase. In order to effectively showcase the learning process of different options, we have chosen to set the game’s background to a white color. In the figure, the green color represents the target location, and the blue portion indicates the current option’s position and distribution. It can be observed that the option-critic algorithm exhibits a noticeable imbalance in the use of options, which might lead to the degradation of the option-critic algorithm into an actor-critic algorithm. The options learned by the OptionEM, using the twin network mechanism, are more balanced compared to the option-critic algorithm. However, there still exists some degradation in option 0 within OptionEM.
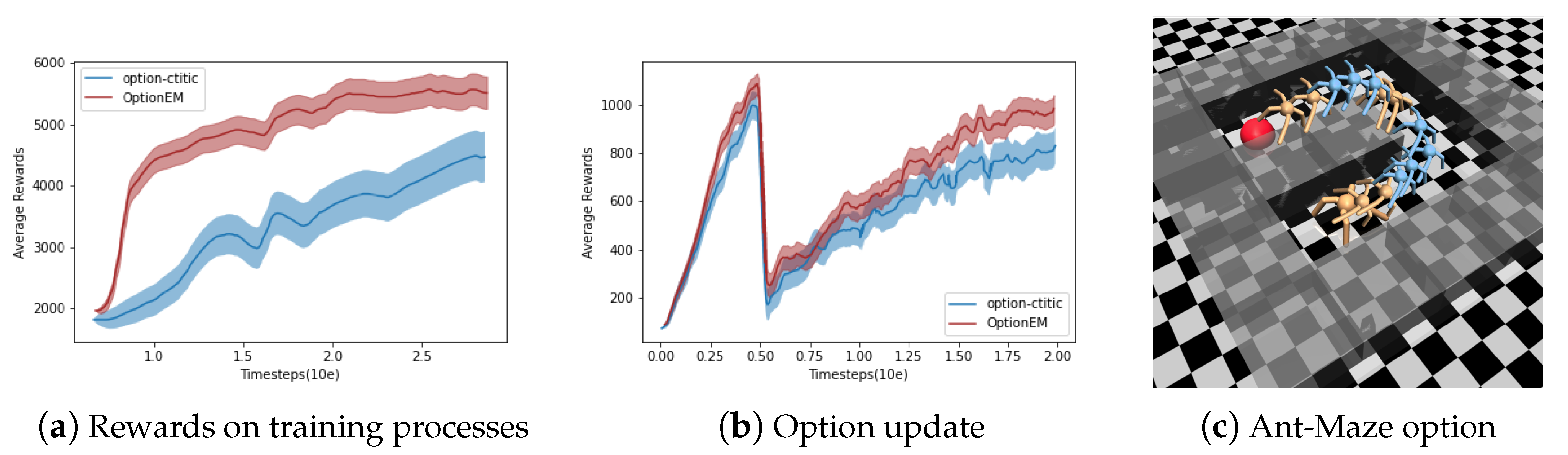
4.2. Mujoco
MuJoCo [
19] (multi-joint dynamics with contact) is a physics simulator for research and development in robotics, biomechanics, graphics and animation, machine learning, and other fields that require fast and accurate simulation of the interaction of articulated structures with their environment. The default Mujoco games do not effectively demonstrate the subgoal or option characteristics of hierarchical reinforcement learning. Therefore, in this section, the Ant-Maze and Ant-Wall environments are used for training and testing. The Ant-Maze game environment utilizes open-source code from GitHub (environment source code:
https://github.com/kngwyu/mujoco-maze.git, accessed on 27 August 2023), while the Ant-Wall game environment is custom-built, featuring randomly initialized walls. In addition to training actions for the ant agent itself, the agent also needs to learn path planning strategies to navigate through mazes or around obstacles/walls. This represents a typical scenario for hierarchical reinforcement learning.
Table 2 presents the parameter settings for the Mujoco games in this section. When the number of options is set to 2, it is evident that, for both the Ant-Maze and Ant-Wall environments, the agent employs one option when it is far from obstacles/walls and another option when it approaches obstacles/walls. Learning methods based on options provide valuable insights for the agent’s long-term learning/planning in such scenarios.
Observing the similarity in path planning between the Ant-Wall and Ant-Corridor games, an attempt was made to transfer the model trained in the Ant-Wall environment to the Ant-Corridor environment.
Figure 4 and
Figure 5 present the qualitative results of the agent’s learned option categories. In this experiment, the performances from six independent runs were averaged. Additionally, the OptionEM algorithm was compared with two option-based algorithm frameworks, and the results for different numbers of options were compared. In
Table 3, it is noteworthy that when using eight options the performance eventually drops significantly. This could be attributed to the lower-dimensional environment of the Mujoco experiments and the simplicity of the environment, making such a high number of options unnecessary and decreasing the sample efficiency. One way to validate this is to apply the same algorithm in a continuous learning environment. Furthermore, due to the distinct update rules of the OptionEM algorithm compared to OC baseline and flexible OC algorithms, it can effectively utilize limited sample data, resulting in a better performance.
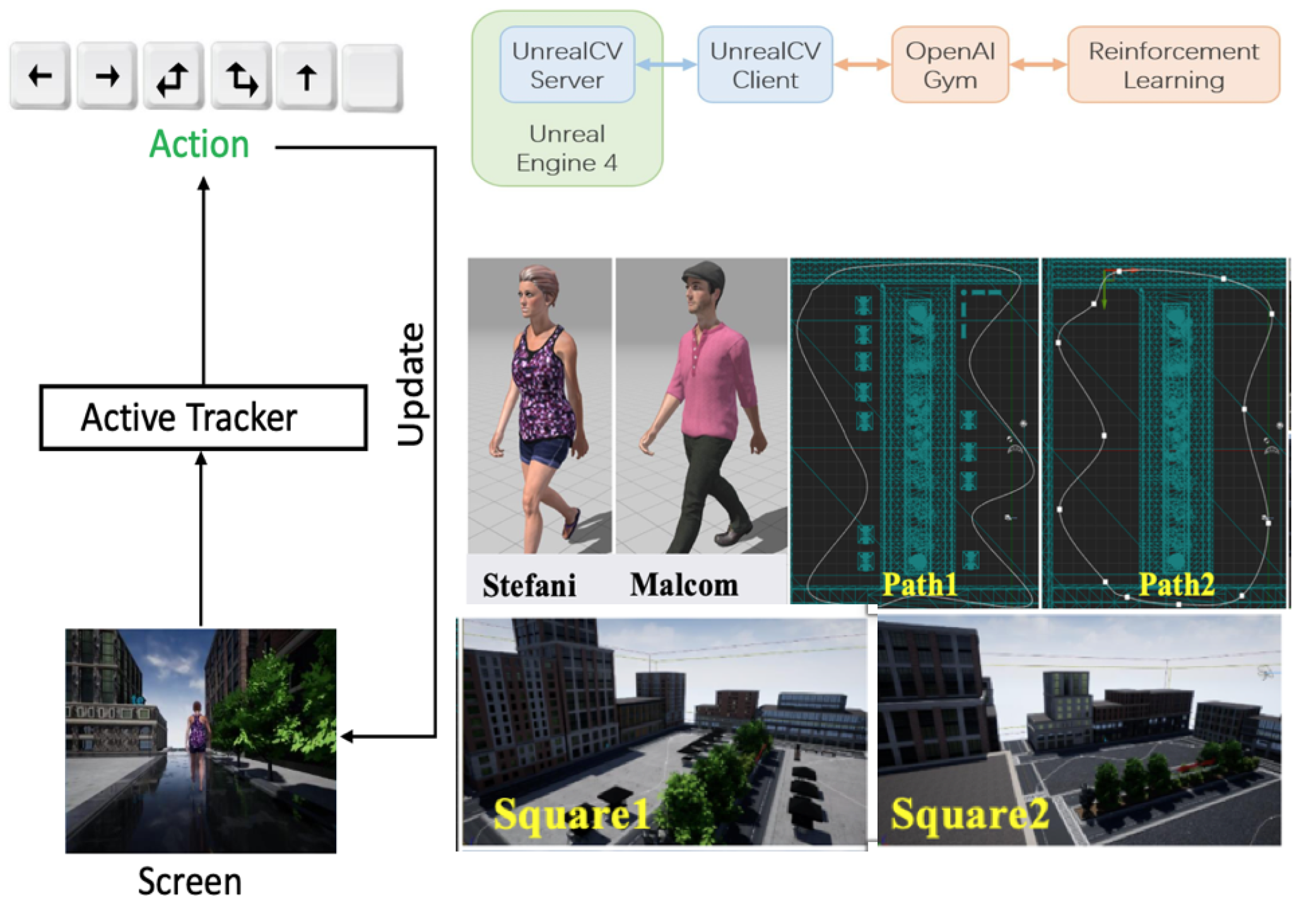
4.3. UE4-Based Active Tracking
The UE4-based target tracking experiment is mainly designed to verify the generalization of the episodic memory module. A highly realistic virtual environment based on Unreal Engine 4 (UE4) is used for independent learning. The virtual environment has a three-layer structure. The bottom layer consists of simulation scenes based on Unreal 4, which contains a rich variety of scene instances, and provides a general communication interaction interface based on UnrealCV [
20], which realizes the communication between the external program and the simulation scene. The agent–environment interaction interface is defined by the specific task, along with the relevant environment elements, such as the reward function, action-state space, etc. The interaction interface design specification is compatible with the OpenAI Gym [
21] environment.
The agent actively controls the movement of the camera based on visual observations in order to follow the target and ensure that it appears in the center of the frame at the appropriate size. A successful tracking is recorded only if the camera continues to follow the target for more than 500 steps. During the tracking process, a collision or disappearance of the target from the frame is recognized as a failed tracking. Accurate camera control requires recognition and localization of the target and reasonable prediction of its trajectory. Each time the environment is reset, the camera will be placed anywhere in the environment and the target counterpart will be placed 3 m directly in front of the camera.
The specific tracker reward is as follows:
For , c is set as a normalized distance. The environment defines the maximum reward to a position where the target is directly in front of the tracker (the tracker is parallel to the target character’s shoulders) at a distance of d. With a constant distance, if the target rotates sideways, the tracker needs to turn behind the target to obtain the maximum reward.
In order to enhance the generalization ability of the model, it is necessary to increase the diversity of the surrounding environment and the target itself as much as possible during the training process. In response to the diversity of the surrounding environment, the environment enhancement in UE4 can be used to easily modify the texture, lighting conditions, and other elements of the surrounding environment, specifically, randomly selecting images from a common image dataset deployed on the surface of the environment and objects to modify the texture and randomly deploy the position, intensity, color, and direction of the light source in the environment to change the scene lighting conditions. The randomization of texture and illumination prevents the tracker from overfitting the specific appearance of the target and background. The diversity requirements of the target itself can be realized by varying the target’s trajectory and speed of movement. The start and end position coordinates of the target can be randomly generated, and the corresponding trajectories are generated using the UE4 engine’s built-in navigation module (the trajectories generated by the built-in navigation module automatically avoid obstacles and do not crash into walls). The motion speed of the target is randomly sampled within the range of (0.1 m/s, 1.5 m/s). The randomization of the target motion trajectory and motion velocity allows the bootstrapped sequence encoder to learn the target motion mode and implicitly encode the motion features, avoiding the situation of a single motion pattern. For the training process, at the beginning of each episode, the target character walks along the planned trajectory from a randomly set start position toward the end position, and the tracker starts walking from a position 3 m directly behind the target character, and the tracker needs to adjust the position and camera parameters to make the target always in the center of the tracker screen. For the testing process, the target character’s movement speed is randomly sampled in the range of (0.5 m/s, 1.0 m/s) to test the generalization ability of the model.
The agent is trained and compared with the A3C [
22] algorithm adopted by Zhong, Fangwei et al. in the paper [
23].The hyper-parameter settings in the experiments are kept the same as in that paper in order to facilitate the comparison. Each game is trained in parallel for six episodes. The seed of the environment is randomly set. The agents are trained from scratch, and, during the training process, the validation is unfolded in parallel. the validation environment is set up in the same way as the training, and the game process with the highest score in the validation environment is selected to report the results for experimental comparison.
An end-to-end conv-lstm network structure is adopted to the tracker agent, which is consistent with the network structure adopted by Luo, Wenhan, Zhong, Fangwei et al. in their paper [
23,
24]. The convolutional layer and the temporal sequencing layer (LSTM) [
25] are not connected by a fully connected layer. The convolutional layer portion uses four layers of convolution and the temporal layer portion uses a single LSTM layer, each containing an ReLU activation layer. The network parameters were updated using the shared Adam optimizer. The observed frame is adjusted to an RGB image of
dimensions, which is input to the conv-lstm network, where the convolutional layer extracts features from the input image, and the fully connected layer transforms the feature representation into a 256-dimensional feature vector. Each layer contains a ReLU activation layer. The sequence encoder is a 256-unit single-layer LSTM that encodes the image features temporally. The output of the previous time step is used as part of the input of the next time step, so that the current time step contains the feature information from all previous time steps.
The environment of the tracking game is directly adopted from the environment setting of Zhong, F. et al. in their paper [
23], as shown in
Figure 6. The game environment consists of a random combination of three elements: character, path, and square.
The effectiveness of the algorithm was tested in four different environments with the combinations S1SP1: Square1StefaniPath1; S1MP1: Square1MalcomPath1; S1SP2: Square1StefaniPath2; and S2MP2: Square2MalcomPath2 and compared with Luo, Wenhan Zhong, Fangwei et al.’s tracker, which was used in their paper [
23] (in their paper, the A3C algorithm was used to train the agents).
The comparison experiments were conducted using bootstrappedEM and OptionEM with the A3C method. The options in OptionEM were set to 4 and 8, denoted as OptionEM(4), OptionEM(8), respectively.
Based on the results in
Table 4, the following conclusions can be drawn.
Compared with S1SP1, S1MP1 changes the target role, and all three algorithms perform well on the generalization results of changing the target appearance. Compared with S1SP1, S1SP2 changes the path, and all three algorithms perform well on the generalization result of changing the path. Compared with S1SP1, S2MP2 changes the map, target, and path at the same time, and the generalization results of all three algorithms for this are slightly insufficient compared to the previous two but can still track the target relatively stably, and the model has some generalization potential, which may need to be improved by migration learning or more environmental enhancements. In most cases, the trackers trained by the bootstrappedEM algorithm and the OptionEM algorithm outperform those trained by A3C. The experimental results of the OptionEM(4) algorithm outperformed OptionEM(8), and the performance of the model was instead reduced with eight options, which also indicates that four options is a more appropriate setting in tracking scenarios.
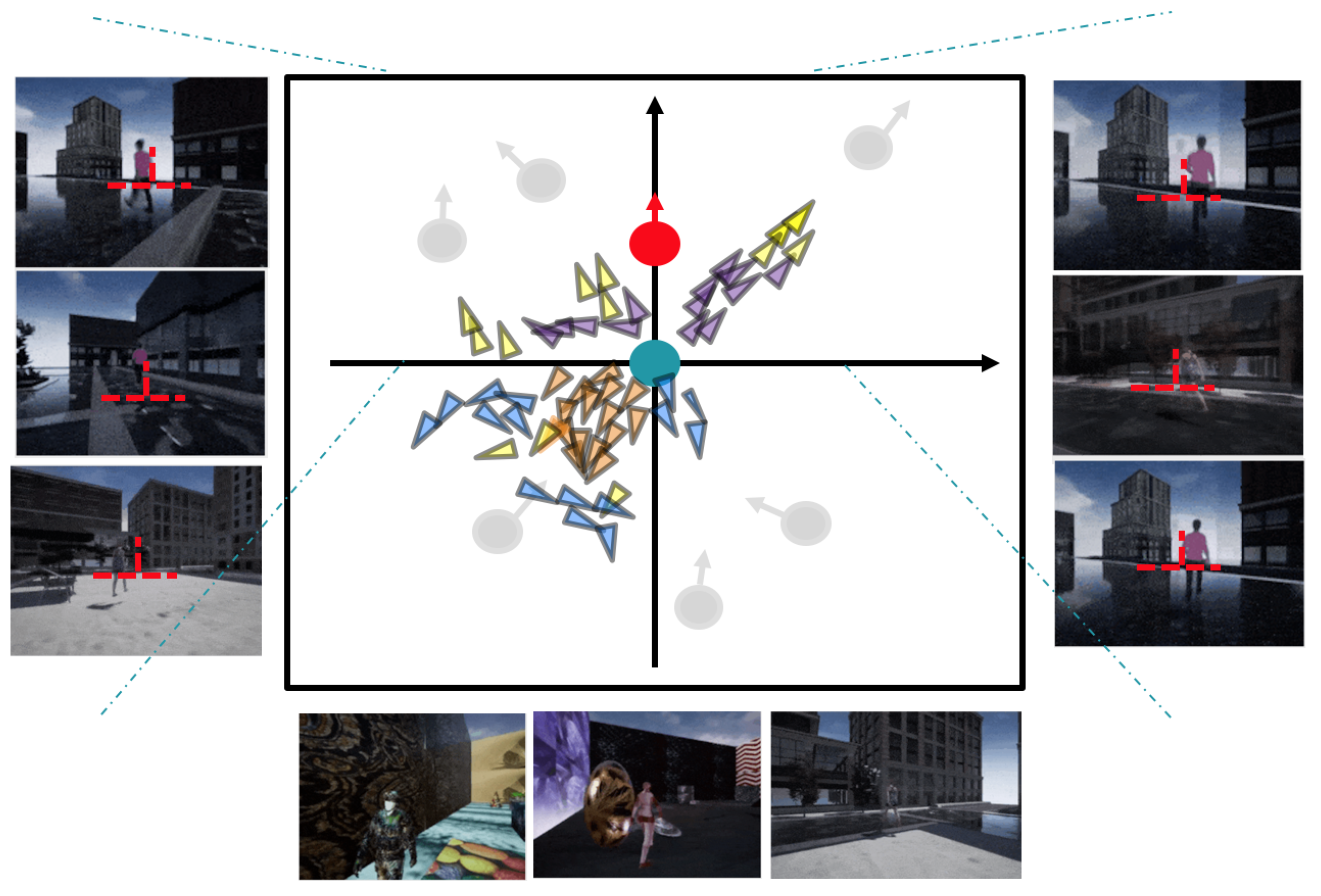
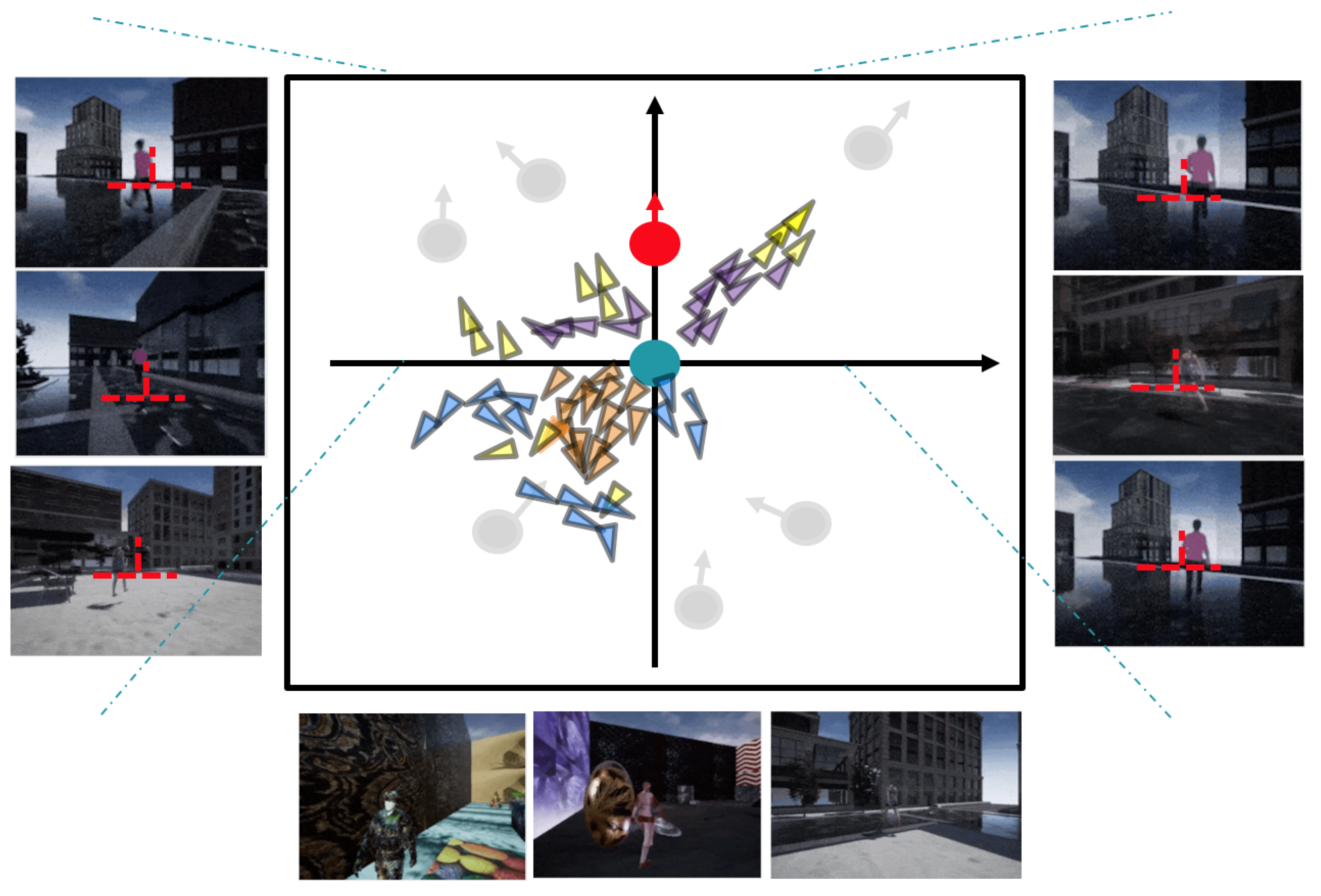
Figure 7 shows the distribution of options learned by the OptionEM algorithm when the number of options is set to four. Observation reveals that the distribution of options can be roughly described as follows: When the target has its back to the tracker and is at a distance, the option with purple marking is selected; when the target has its back to the tracker and is at a closer distance, the option with yellow marking is selected; and when the target is not in the screen or is facing the tracker, there are two possible options. The option with orange marking bootstrapped the tracker to perform a self-rotating motion, while the option with blue marking appears more randomly and the action has no obvious law to be summarized. The model options trained by OptionEM are able to distinguish more clearly between the situation where the target is in the field of view and the situation where the target is lost; when the tracker loses the target in its field of view, the trained options can control the tracker to perform a rotational movement in order to find the lost target as soon as possible. Overall, the distribution of these four options is somewhat consistent with the logic of humans conducting target tracking in real scenes.
Table 5 displays OptionEM alongside other baselines in the UE4-based active tracking task, showcasing the time required to train an agent to achieve a cumulative reward of 800. In comparison to the classical A3C algorithm and other episodic memory algorithms, the proposed OptionEM algorithm demonstrates improved efficiency.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}