


Investigating Highway–Rail Grade Crossing Inventory Data Quality’s Role in Crash Model Estimation and Crash Prediction


Abstract
:Featured Application
Abstract
1. Introduction
2. Literature Review
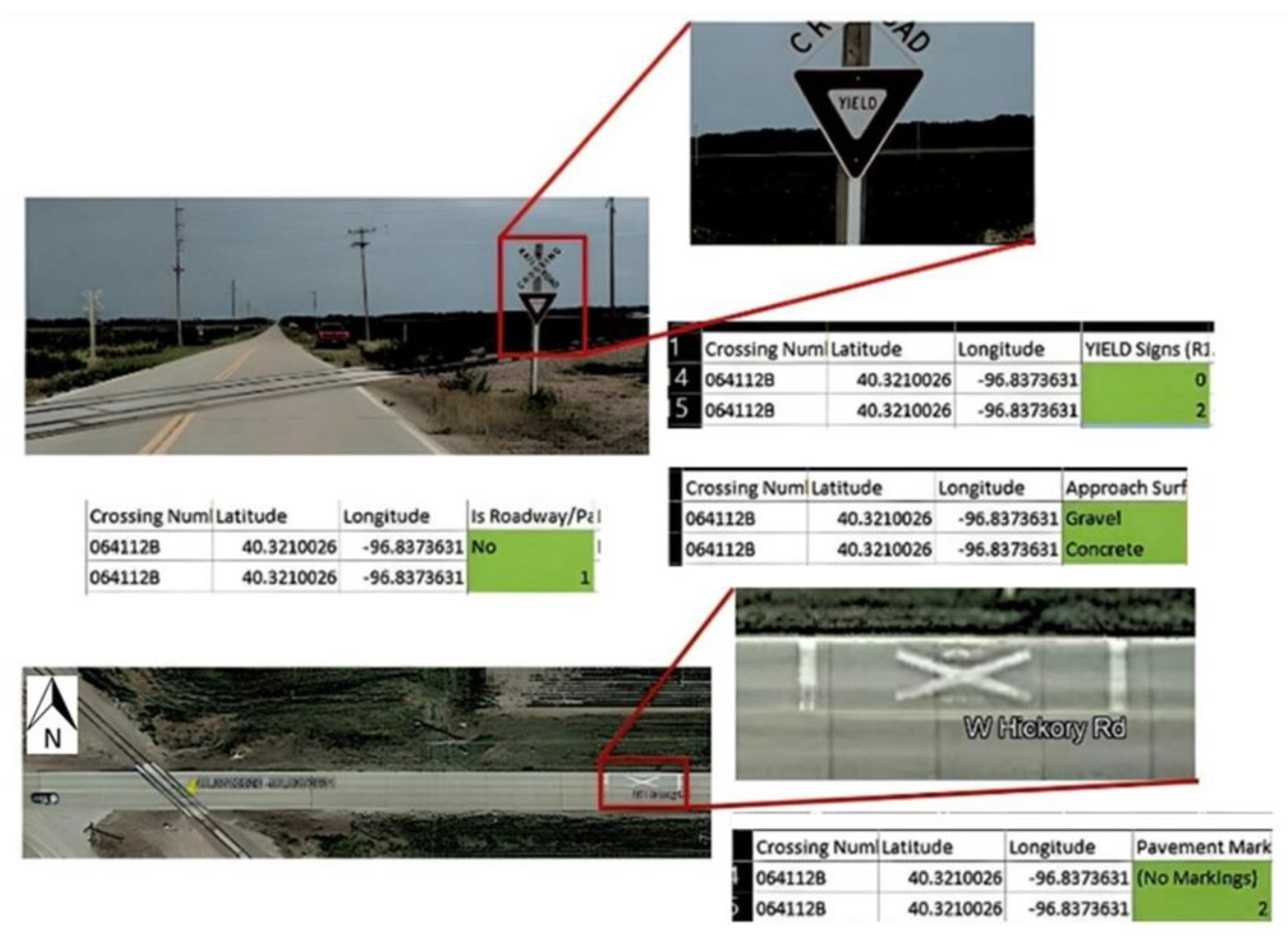
3. Data
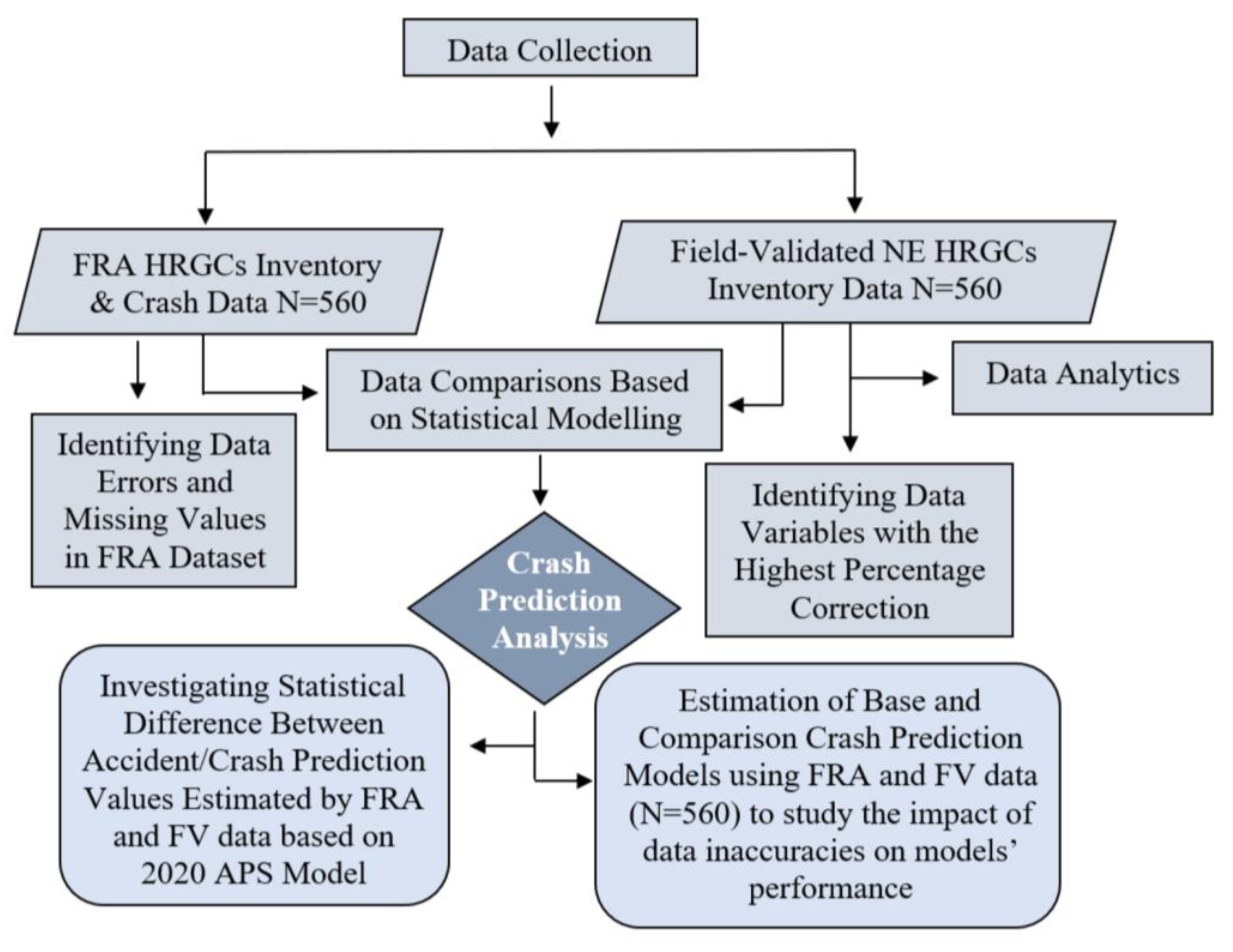
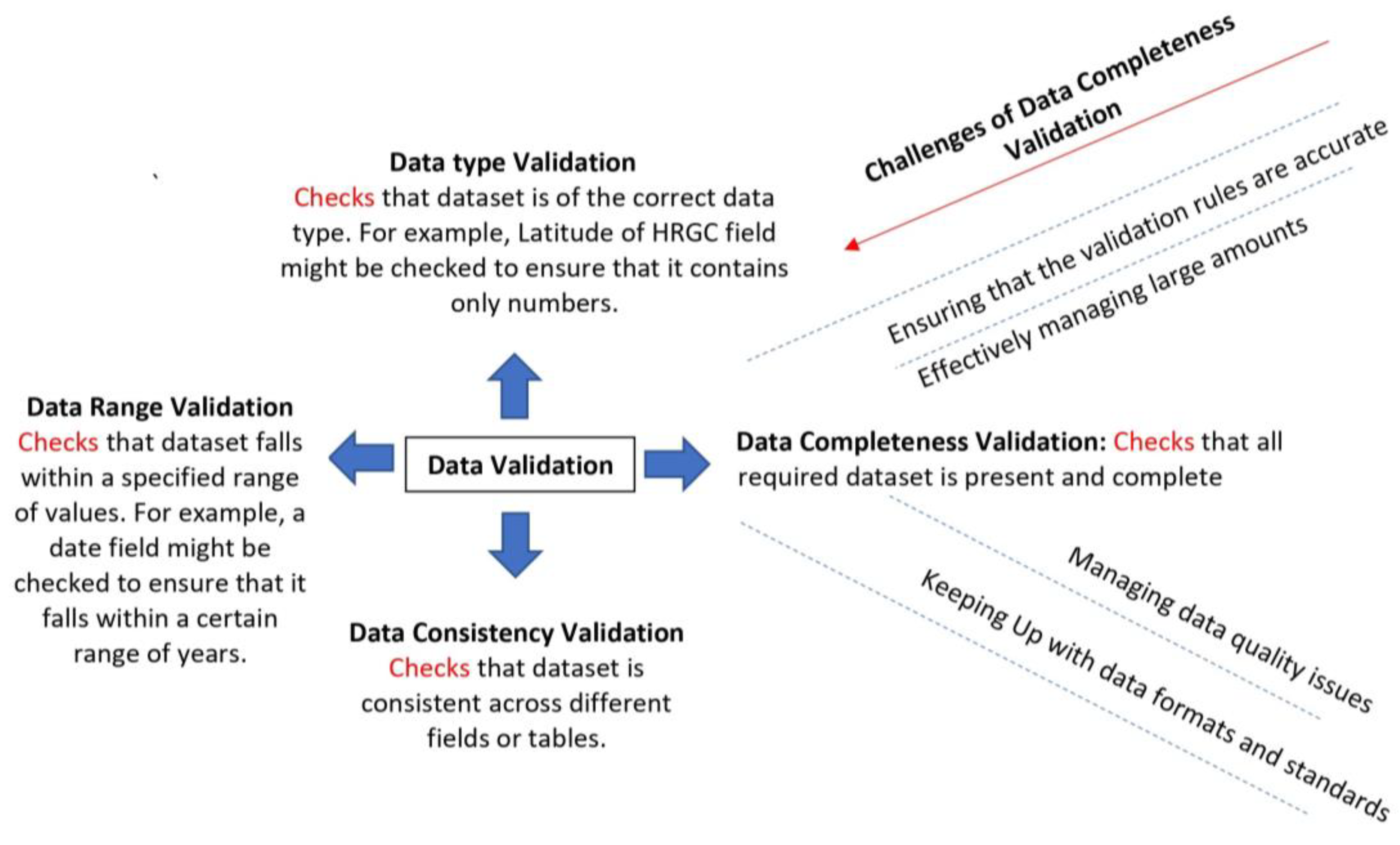
4. Methodology
- (i)
- H0 = There is no difference in the expected crashes estimated by utilizing FRA and field-validated data (α = 5%).
- (ii)
- H0 = There is no difference in the estimated parameters’ coefficients of new crash frequency prediction models from the two datasets (FRA Vs field-validated) (α = 5%).
5. Results and Discussion
Comparative Analysis of Estimated Models
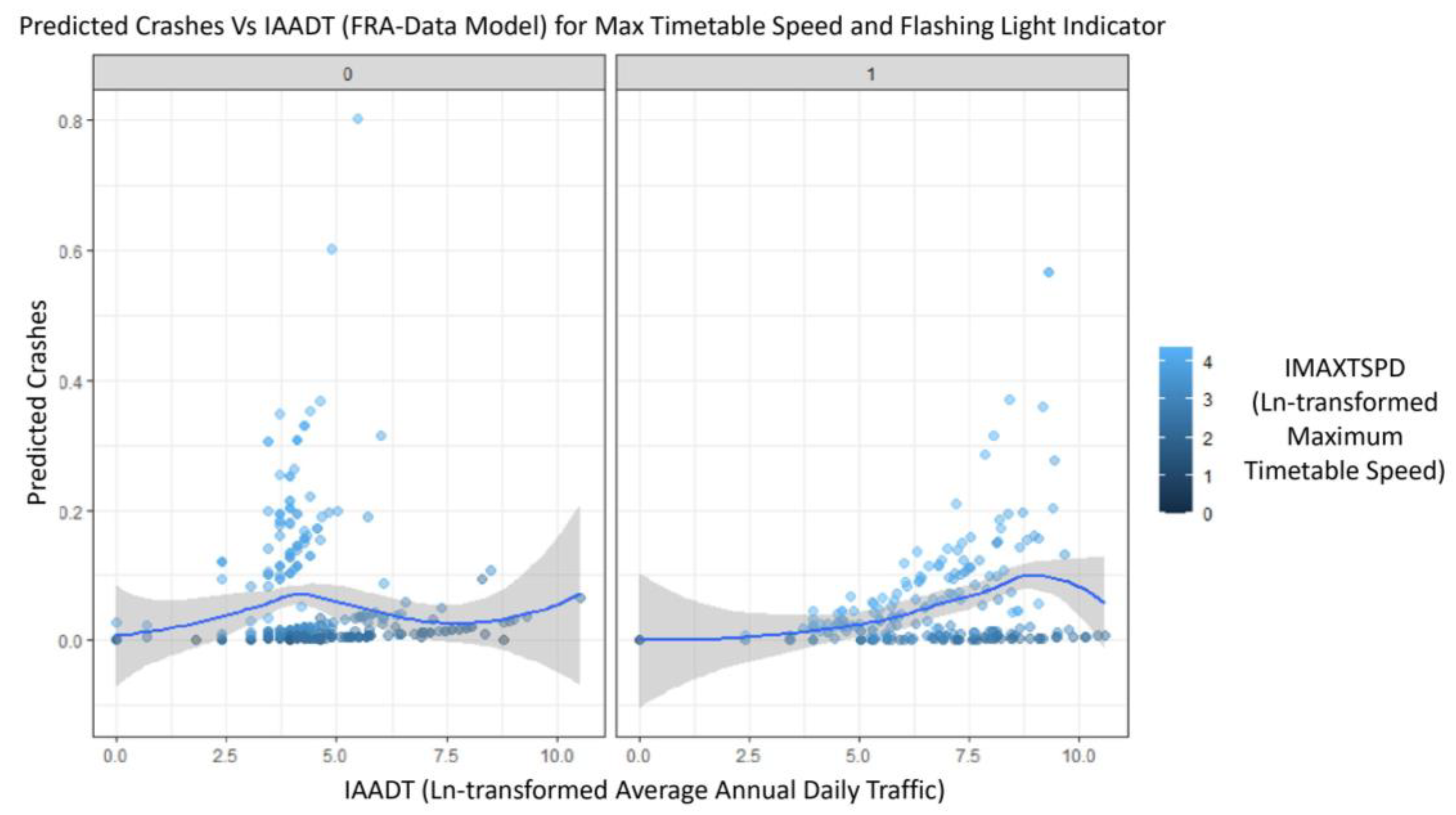
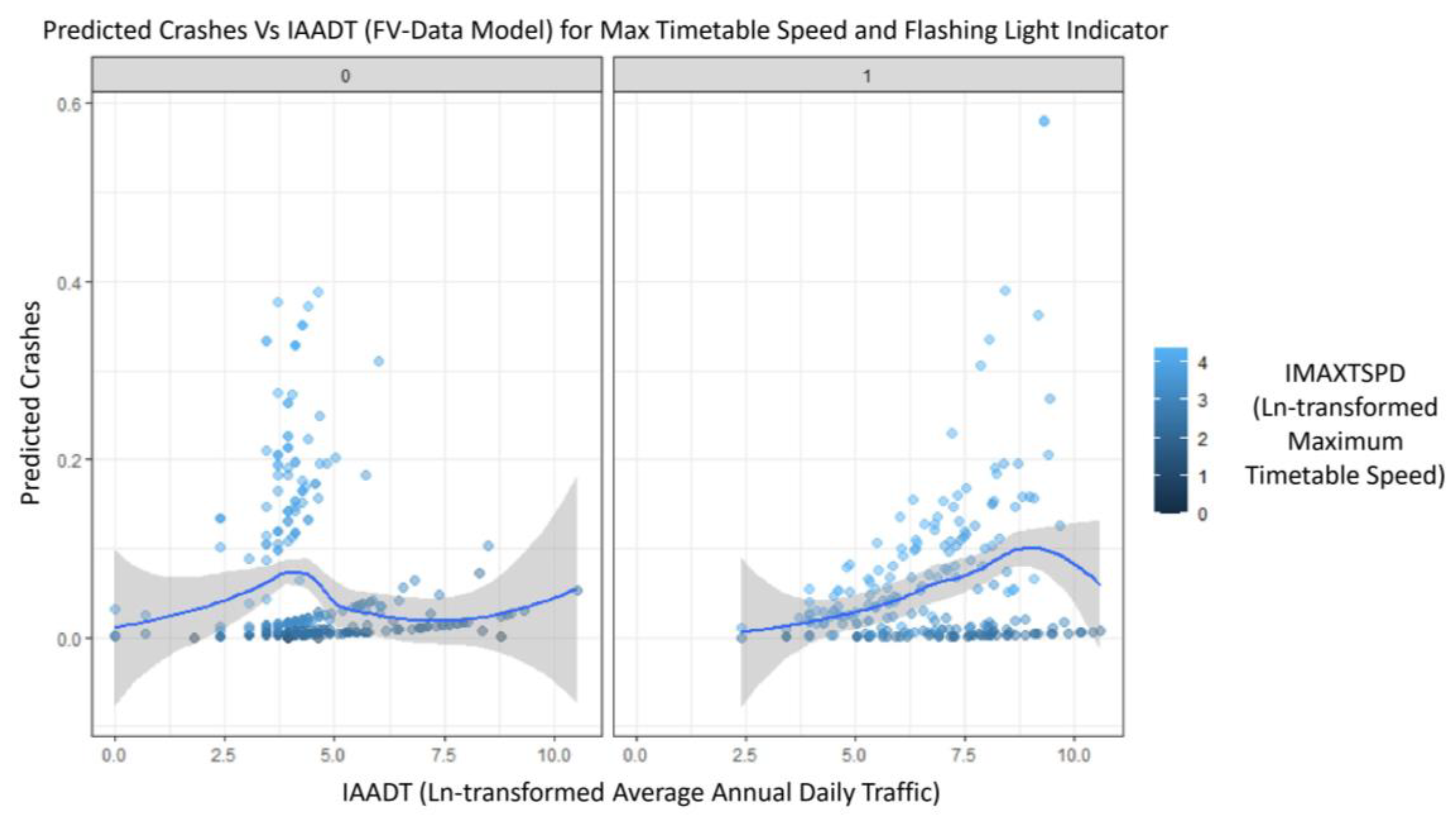
- The coefficients for Natural log-transformed Maximum Timetable Speed (IMAXTSPD) and Natural log-transformed Average Annual Daily Traffic (IAADT) exhibited positive signs in both models. However, the expected magnitude differed in both models, where the base model gave a higher coefficient expected magnitude for IAADT compared to the comparison model. Moreover, for IMAXTSPD, the comparison model gave a higher coefficient expected magnitude. The average marginal effect estimates presented in Table 8 show that a unit change in IAADT increases predicted crashes by 0.02681 in the base model and 0.02546 in the comparison model.
- The coefficients for warning-device-type flashing lights (WDTLIT) were negative for both models (i.e., compared to passive devices, warning flashing lights reduce predicted crashes). However, the coefficient expected magnitudes and average marginal effects (Table 8) of WDTLITs differ in both models, where the base model estimated a higher negative value compared to the comparison model.
- The coefficients of Ln-transformed total daily trains (ITDTRAINS) in the zero-inflated part in both the base and comparison models were negative, indicating that the probability of excess zeros decreases with the number of trains, as expected. However, the coefficient expected magnitudes of ITDTRAINS differed in both models.
- All the coefficients retained in both models indicated strong statistical significance. However, as shown in Table 9, the results of hypothesis tests revealed that the regression coefficients were not statistically significantly different when utilizing the two inventory datasets.
6. Conclusions
- Erroneous and missing data in the unaltered FRA HRGCs inventory database led to statistically different crash predictions (expected crashes) compared to corrected and complete (field-validated) HRGCs inventory data. These predictions also affected the crash hazard ranking of crossings based on the two datasets.
- Estimated crash prediction model parameters and their corresponding marginal values appeared to differ when comparing models based on the unaltered FRA HRGCs inventory database and the corrected and complete (field-validated) HRGCs inventory data. However, from a statistical standpoint, they did not exhibit significant differences. Nevertheless, the Zero-inflated Negative Binomial (ZINB) crash prediction model, utilizing the accurate inventory dataset, demonstrated superior performance according to fitness criteria such as the Akaike information criterion (AIC) and BIC (Bayesian information criterion).
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Federal Railroad Administration (FRA). Safety Data and Reporting. Available online: https://railroads.dot.gov/safety-data (accessed on 3 July 2022).
- Farooq, M.U. The Effects of Inaccurate and Missing Highway-Rail Grade Crossing Inventory Data on Crash and Severity Model Estimation and Prediction. Ph.D. Thesis, The University of Nebraska-Lincoln, Lincoln, Nebraska, 1 May 2023. [Google Scholar]
- Brod, D.; Gillen, D.; Decisiontek, L.L.C. A New Model for Highway-Rail Grade Crossing Acczident Prediction and Severity (No. DOT/FRA/ORD-20/40). United States. Department of Transportation. Federal Railroad. Administration. Available online: https://railroads.dot.gov/elibrary/new-model-highway-rail-grade-crossing-accident-prediction-and-severity (accessed on 25 October 2020).
- Yan, X.; Richards, S.; Su, X. Using hierarchical tree-based regression model to predict train–vehicle crashes at passive highway-rail grade crossings. Accid. Anal. Prev. 2010, 42, 64–74. [Google Scholar] [CrossRef] [PubMed]
- Naderan, A.; Shahi, J. Aggregate crash prediction models: Introducing crash generation concept. Accid. Anal. Prev. 2010, 42, 339–346. [Google Scholar] [CrossRef] [PubMed]
- Lu, P.; Zheng, Z.; Ren, Y.; Zhou, X.; Keramati, A.; Tolliver, D.; Qang, Y. A gradient boosting crash prediction approach for highway-rail grade crossing crash analysis. J. Adv. Transp. 2020, 1, 6751728. [Google Scholar] [CrossRef]
- Oh, J.; Washington, S.P.; Nam, D. Accident prediction model for railway-highway interfaces. Accid. Anal. Prev. 2006, 38, 346–356. [Google Scholar] [CrossRef]
- Kasalica, S.; Obradović, M.; Blagojević, A.; Jeremić, D.; Vuković, M. Models for ranking railway crossings for safety improvement. Oper. Res. Eng. Sci. Theory Appl. 2020, 3, 84–100. [Google Scholar] [CrossRef]
- Hu, S.R.; Li, C.S.; Lee, C.K. Assessing casualty risk of railroad-grade crossing crashes using zero-inflated Poisson models. J. Transp. Eng. 2011, 137, 527–536. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The statistical analysis of crash-frequency data: A review and assessment of methodological alternatives. Transp. Res. Part A Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef]
- Lu, P.; Tolliver, D. Accident prediction model for public highway-rail grade crossings. Accid. Anal. Prev. 2016, 90, 73–81. [Google Scholar] [CrossRef]
- Hilbe, J.M. Modeling Count Data; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Zheng, Z.; Lu, P.; Pan, D. Predicting highway–rail grade crossing collision risk by neural network systems. J. Transp. Eng. Part A Syst. 2019, 145, 410–433. [Google Scholar] [CrossRef]
- Zhang, X.; Waller, S.T.; Jiang, P. An ensemble machine learning-based modeling framework for analysis of traffic crash frequency. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 258–276. [Google Scholar] [CrossRef]
- Saccomanno, F.F.; Ren, C.; Fu, L. Collision Prediction models for Highway-Rail Grade Crossings in Canada. In Proceedings of the 82nd Annual Meeting of the Transportation Research Board, Washington, DC, USA, 12–16 January 2003. [Google Scholar]
- Khan, I.U.; Lee, E.; Khan, M.A. Developing a highway rail grade crossing accident probability prediction model: A North Dakota case study. Safety 2018, 4, 22. [Google Scholar] [CrossRef]
- Nam, D.; Lee, J. Accident frequency model using zero probability process. Transp. Res. Rec. J. Transp. Res. Board 2006, 1973, 142–148. [Google Scholar] [CrossRef]
- Keramati, A.; Lu, P.; Tolliver, D.; Wang, X. Geometric effect analysis of highway-rail grade crossing safety performance. Accid. Anal. Prev. 2020, 138, 105–170. [Google Scholar] [CrossRef] [PubMed]
- Khattak, A.J.; Kang, Y.; Liu, H.; Nebraska Rail Crossing Safety Research. Final Report to Nebraska Department of Transportation, University of Nebraska-Lincoln Report SPR-P1M091. Available online: https://rosap.ntl.bts.gov/view/dot/55869 (accessed on 31 December 2020).
- Gao, J.; Xie, C.; Tao, C. Big Data Validation and Quality Assurance—Issuses, Challenges, and Needs. In Proceedings of the 2016 IEEE Symposium on Service-Oriented System Engineering (SOSE), Oxford, UK, 29 March–2 April 2016; pp. 433–441. [Google Scholar] [CrossRef]
- Yau, K.K.; Wang, K.; Lee, A.H. Zero-inflated negative binomial mixed regression modeling of over-dispersed count data with extra zeros. Biom. J. J. Math. Methods Biosci. 2003, 45, 437–452. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, M.; Li, W.; Sharma, A. Multivariate random parameters zero-inflated negative binomial regression for analyzing urban midblock crashes. Anal. Methods Accid. Res. 2018, 17, 32–46. [Google Scholar] [CrossRef]
- Mathew, J.; Benekohal, R.F. Highway-rail grade crossings accident prediction using Zero Inflated Negative Binomial and Empirical Bayes method. J. Saf. Res. 2021, 79, 211–236. [Google Scholar] [CrossRef]
- Sharma, S.; Pulugurtha, S.S. Modeling crash risk at rail-highway grade crossings by track class. J. Transp. Technol. 2019, 9, 261–283. [Google Scholar] [CrossRef]
- R Programming. Available online: https://www.r-project.org/about.html (accessed on 1 January 2021).
- Chatterjee, S.; Hadi, A.S. Regression Analysis by Example; John Wiley & Sons. Inc.: New York, NY, USA, 2006. [Google Scholar]
- Yap, B.W.; Sim, C.H. Comparisons of various types of normality tests. J. Stat. Comput. Simul. 2011, 81, 2141–2155. [Google Scholar] [CrossRef]
- Lam, F.C.; Longnecker, M.T. A modified Wilcoxon rank sum test for paired data. Biometrika 1983, 70, 510–513. [Google Scholar] [CrossRef]
- Clogg, C.C.; Petkova, E.; Haritou, A. Statistical methods for comparing regression coefficients between models. Am. J. Sociol. 1995, 100, 1261–1293. [Google Scholar] [CrossRef]
- Chhotu, A.K.; Suman, S.K. Prediction of Fatalities at Northern Indian Railways’ Road–Rail Level Crossings Using Machine Learning Algorithms. Infrastructures 2023, 8, 101–121. [Google Scholar] [CrossRef]
- Lim, K.K. Analysis of Railroad Accident Prediction using Zero-truncated Negative Binomial Regression and Artificial Neural Network Model: A Case Study of National Railroad in South Korea. KSCE J. Civ. Eng. 2023, 27, 333–344. [Google Scholar] [CrossRef]
- Yang, X.; Li, J.Q.; Zhang, A.; Zhan, Y. Modeling the accident prediction for at-grade highway-rail crossings. Intell. Transp. Infrastruct. 2022, 1, 342–367. [Google Scholar] [CrossRef]
- Heydari, S.; Fu, L.; Lord, D.; Mallick, B.K. Multilevel Dirichlet process mixture analysis of railway grade crossing crash data. Anal. Methods Accid. Res. 2016, 1, 27–43. [Google Scholar] [CrossRef]
- Cao, Y.; An, Y.; Su, S.; Xie, G.; Sun, Y. A statistical study of railway safety in China and Japan 1990–2020. Accid. Anal. Prev. 2022, 1, 106–124. [Google Scholar] [CrossRef]
- Kyriakidis, M.; Pak, K.T.; Majumdar, A. Railway accidents caused by human error: Historic analysis of UK railways, 1945 to 2012. Transp. Res. Rec. 2015, 2476, 126–136. [Google Scholar] [CrossRef]

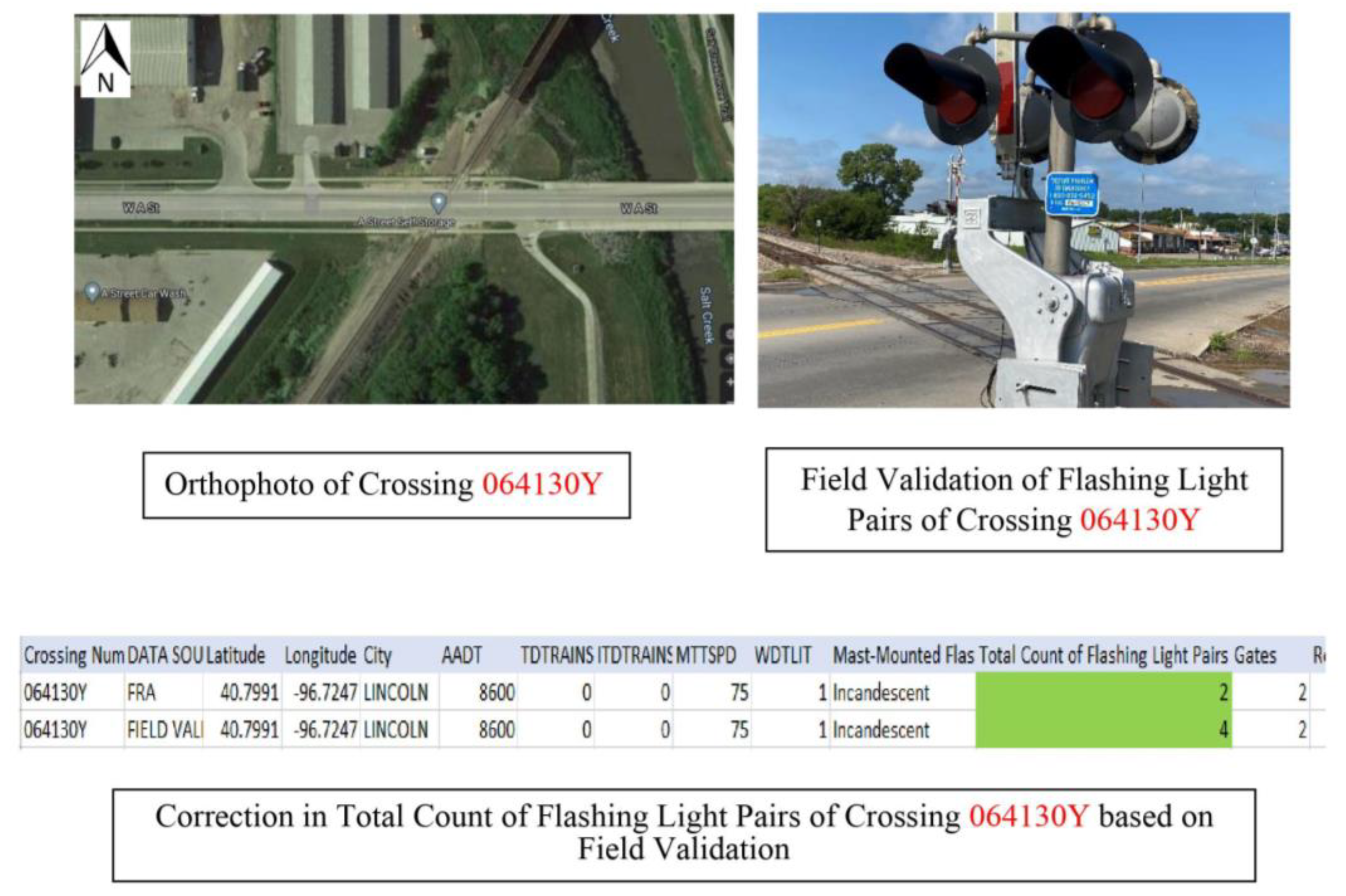


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Authors | No of Observations | Data Type | Location | Context | Method Used | Types of Explanatory Variables |
|---|---|---|---|---|---|---|---|
| 2003 | Saccomanno et al. [15] | 10,456 HRGCs crashes | Canadian Public HRGCs data | Canada | Collision prediction models for highway–rail grade crossings in Canada | Negative Binomial Regression | Female highway users, higher train speeds, very old drivers, open areas, concrete road surface types, and railroad equipment striking highway users before crash. |
| 2006 | Oh et al. [7] | Crash data of 162 HRGCs | 1998–2002 Korean National Railroad (KNR) accident database | South Korea | Accident prediction model for railway–highway interfaces | Poisson Model, Gamma model, and Zero-inflated Poisson Model | Traffic volume, average daily train volumes, the proximity of crossings to commercial areas, time duration between the activation of warning signals and gates, and the distance of the train detector from crossings. |
| 2006 | Nam and Lee [17] | 100 highway–rail grade crossings crash data | Korean National Railroad accident database | South Korea | Accident frequency model using zero probability process | Zero-inflated Models | Roadway characteristics, guardrails, number of tracks, control device indicator, warning time. |
| 2010 | Yan at al. [4] | 6244 train–vehicle crashes | 27 years of FRA HRGCs database (1980–2006) | United States | Using hierarchical tree-based model to predict train–vehicle crashes at passive HRGCs | Hierarchical Tree-Based Regression Model | Crossbucks only, and crossbucks combined with stop signs, and Stop sign treatment. |
| 2016 | Lu and Tolliver [11] | 344 HRGCs crash data from 1996 to 2014 in North Dakota | FRA HRGC incident and inventory data | North Dakota, United States | Accident prediction model for public highway–rail grade crossings | Conway–Maxwell–Poisson Model, Bernoulli model, Hurdle Poisson Model | Warning devices, highway pavement condition, appearance of pavement markings, appearance of interconnection/pre-emption, smallest crossing angle, appearance of pullout lane, functional classifications of highway, train traffic density, highway user types, weather conditions, track conditions, highway traffic density, maximum train speed, and location. |
| 2019 | Khan et al. [16] | Crash Data from 2000 to 2016 in North Dakota Involving HRGCs | North Dakota DOT crash data | United States | Developing a Highway Rail Grade Crossing Accident Probability Prediction Model: A North Dakota Case Study | Binary Logit Regression Model | AADT, exposure, crossing angle, gates, and pavement markings. |
| 2019 | Zheng et al. [13] | Past 19 years 354 crashes on 5713 HRGCs | FRA HRGCs incident and inventory data | North Dakota, United States | Predicting Highway–Rail Grade Crossing Collision Risk by Neural Network Systems | Neural Network (NN) Model | AADT, presence of flashing lights, highway stop signs, and presence of crossbuck signs. |
| 2020 | Lu et al. [6] | Past 19 years crashes on 5713 HRGCs | FRA HRGC incident and inventory data | North Dakota, United States | A Gradient Boosting Crash Prediction Approach for Highway–Rail Grade Crossing Crash Analysis | Gradient Boosting (GB) Model | Traffic exposure factors such as, highway traffic volume, railway traffic volume, and train travel speed. |
| 2020 | Keramati et al. [18] | 3310 HRGCs, with 475 crash records | FRA HRGCs incident and inventory data | North Dakota, United States | A Simultaneous Safety Analysis of Crash Frequency and Severity for Highway–Rail Grade Crossings: The Competing Risks Method | Competing Risks Method | Crash information, type of train service, train detection, availability of commercial power, and distance to nearby roadway intersection. |
| 2020 | Brod et al. [3] | Crash and Inventory data of 9870 HRGCs | FRA HRGC incident/accident and inventory data | United States | New Model for Highway–Rail Grade Crossing Accident Prediction and Severity | Zero-inflated Negative Binomial Model and Ordered Logit Model | Exposure, average annual daily traffic, maximum timetable train speed, total trains, surface-type, warning flashing lights, and gates. |
| County | Number of Corrected Values | Number of Missing Values Added | HRGCs Visited | Abandoned/Non-Existent HRGCs (Excluding Private Crossings) | Percent Corrected and Added Missing Values |
|---|---|---|---|---|---|
| Cass | 307 | 83 | 56 | 0 | 7.1 |
| Douglas | 286 | 108 | 67 | 4 | 5.9 |
| Gage | 115 | 347 | 41 | 0 | 11.3 |
| Jefferson | 174 | 25 | 45 | 0 | 4.3 |
| Lancaster | 376 | 657 | 112 | 0 | 9.2 |
| Otoe | 285 | 46 | 77 | 2 | 4.2 |
| Saline | 119 | 37 | 61 | 0 | 4.1 |
| Sarpy | 144 | 59 | 25 | 0 | 8.1 |
| Saunders | 435 | 370 | 76 | 0 | 10.6 |
| Total | 2241 | 1732 | 560 | 6 | 7.4 |
| Variables | Variable Coding |
|---|---|
| Discrete Variables | |
| Warning flashing lights | 1 if there are flashing lights at crossing, 0 otherwise |
| Gates | 1 if there are gates at crossing, 0 otherwise |
| Rural/urban classification | 1 if crossing is in urban area, 0 if crossing is in rural area |
| Pavement markings | 1 if there are pavement markings near crossing, 0 otherwise |
| Crossing surface type | Timber = 1, Asphalt = 2, Asphalt and Timber or Concrete or Rubber = 3, Concrete and Rubber = 4, other = 5 |
| Crossing illuminated | 1 if crossing is illuminated, 0 otherwise |
| Crossing angle | 1 = 0–29°, 2 = 30–59°, 3 = 60–90° |
| Continuous Variables | |
| Number of bells | Count |
| Number of crossbucks | Count |
| Number of total tracks | Count |
| Ln AADT | Natural Log-transformed count |
| Ln Total daily trains | Natural Log-transformed count |
| Ln Maximum timetable speed | Natural Log-transformed count |
| Number of traffic lanes | Count |
| Tests Performed | ||
|---|---|---|
| Shapiro–Wilk Normality Test | ||
| Variable | W | p-value |
| Original FRA data crash predictions | 0.87519 | 2.2 × 10−16 |
| Field-validated data crash predictions | 0.84692 | 2.2 × 10−16 |
| Wilcoxon Rank Sum Test for Differences in Expected Crashes | ||
| Original FRA Vs FV data crash predictions | 122,640 | 3.622 × 10−10 |
| Alternative hypothesis | True location shift is not equal to 0 | |
| Crossing ID | 2020 AP Ranking Using Original FRA Inventory Data | Crossing ID | 2020 AP Ranking Using Field-Validated Inventory Data |
|---|---|---|---|
| 074952M | 1 | 064128X | 1 |
| 074945C | 2 | 064129E | 2 |
| 064128X | 3 | 074929T | 3 |
| 064129E | 4 | 073326S | 4 |
| 074929T | 5 | 074938S | 5 |
| 073326S | 6 | 073456N | 6 |
| 816859H | 7 | 816859H | 7 |
| 073456N | 8 | 073342B | 8 |
| 074938S | 9 | 073345W | 9 |
| 073342B | 10 | 073455G | 10 |
| Variable (Code Name) | Estimate | Std. Error | Z-Value | p-Value | ||
|---|---|---|---|---|---|---|
| Constant (_cons) | −8.7615 | 2.5845 | −3.39 | 0.000 | ||
| Ln-transformed AADT (IAADT) | 0.47160 | 0.1674 | 2.81 | 0.004 | ||
| Warning flashing lights (WDTLITs) | −2.1517 | 0.6984 | −3.08 | 0.002 | ||
| Ln-transformed max train speed (IMAXTSPD) | 1.40840 | 0.5615 | 2.508 | 0.012 | ||
| Log (theta) | 10.0436 | 107.89 | 0.093 | 0.925 | ||
| ZINB regression zero-inflation coefficients (binomial with logit link) | ||||||
| Constant (_cons) | 2.2206 | 1.0151 | 2.188 | 0.028 | ||
| Ln-transformed total daily trains (ITDTRAINS) | −0.9539 | 0.3596 | −2.652 | 0.007 | ||
| Pearson Residuals | ||||||
| Min | 1Q | Median | 3Q | Max | ||
| −0.72413 | −0.21093 | −0.11057 | −0.05989 | 26.92213 | ||
| Summary Statistics | ||||||
| Number of observations = 555 | ||||||
| Theta = 23,008.3433 | ||||||
| Number of iterations = 85 | ||||||
| Log-likelihood = −97.36 | ||||||
| Degrees of freedom = 7 | ||||||
| Inflation model = logit | ||||||
| AIC = 210.0122 | ||||||
| BIC = 240.2197 | ||||||
| Variable (Code Name) | Estimate | Std. Error | Z-Value | p-Value | ||
|---|---|---|---|---|---|---|
| Constant (_cons) | −8.9899 | 2.5874 | −3.47 | 0.000 | ||
| Ln-transformed AADT (IAADT) | 0.4422 | 0.1648 | 2.68 | 0.007 | ||
| Warning flashing lights (WDTLITs) | −2.0443 | 0.6982 | −2.92 | 0.003 | ||
| Ln-transformed max train speed (IMAXTSPD) | 1.5135 | 0.5667 | 2.67 | 0.007 | ||
| Log (theta) | 10.4522 | 129.44 | 0.81 | 0.936 | ||
| ZINB regression zero-inflation coefficients (binomial with logit link) | ||||||
| Constant (_cons) | 2.1266 | 1.0165 | 2.092 | 0.036 | ||
| Ln-transformed total daily trains (ITDTRAINS) | −0.8793 | 0.3484 | −2.524 | 0.011 | ||
| Pearson Residuals | ||||||
| Min | 1Q | Median | 3Q | Max | ||
| −0.55149 | −0.22451 | −0.11469 | −0.05974 | 26.7747 | ||
| Summary Statistics | ||||||
| Number of observations = 555 | ||||||
| Theta = 34,620.8247 | ||||||
| Number of iterations = 84 | ||||||
| Log-likelihood = −98.01 | ||||||
| Degrees of freedom = 7 | ||||||
| Inflation model = logit | ||||||
| AIC = 208.7160 | ||||||
| BIC = 239.0117 | ||||||
| Model Type | Variable | Effect | Std. Error | Z-Value | p-Value |
|---|---|---|---|---|---|
| Base model (based on original FRA inventory data) | IAADT | 0.02681 | 0.01099 | 2.440 | 0.0146774 |
| WDTLITs | −0.12232 | 0.04714 | −2.595 | 0.0094708 | |
| IMAXTSPD | 0.08008 | 0.03567 | 2.245 | 0.0247619 | |
| ITDTRAINS | 0.02431 | 0.01124 | 2.391 | 0.0166414 | |
| Comparison model (based on field-validated inventory data) | IAADT | 0.02546 | 0.01082 | 2.353 | 0.018636 |
| WDTLITs | −0.11768 | 0.04713 | −2.497 | 0.012539 | |
| IMAXTSPD | 0.08714 | 0.03704 | 2.352 | 0.018663 | |
| ITDTRAINS | 0.02383 | 0.01124 | 2.2912 | 0.021725 |
| Comparing Regression Coefficients of the Base and Comparison ZINB Models H0: There is no Statistically Significant Difference between Coefficients of the Two Models | ||
|---|---|---|
| Compared Parameters | Z statistic | p Values |
| IAADT | 0.00802 | 0.9935 |
| WDTLITs | −0.10875 | 0.9134 |
| IMAXTSPD | 0.13174 | 0.8951 |
| ITDTRAINS | −0.14899 | 0.8815 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farooq, M.U.; Khattak, A.J. Investigating Highway–Rail Grade Crossing Inventory Data Quality’s Role in Crash Model Estimation and Crash Prediction. Appl. Sci. 2023, 13, 11537. https://doi.org/10.3390/app132011537
Farooq MU, Khattak AJ. Investigating Highway–Rail Grade Crossing Inventory Data Quality’s Role in Crash Model Estimation and Crash Prediction. Applied Sciences. 2023; 13(20):11537. https://doi.org/10.3390/app132011537
Chicago/Turabian StyleFarooq, Muhammad Umer, and Aemal J. Khattak. 2023. "Investigating Highway–Rail Grade Crossing Inventory Data Quality’s Role in Crash Model Estimation and Crash Prediction" Applied Sciences 13, no. 20: 11537. https://doi.org/10.3390/app132011537
APA StyleFarooq, M. U., & Khattak, A. J. (2023). Investigating Highway–Rail Grade Crossing Inventory Data Quality’s Role in Crash Model Estimation and Crash Prediction. Applied Sciences, 13(20), 11537. https://doi.org/10.3390/app132011537