
A Lightweight Visual Odometry Based on LK Optical Flow Tracking

Abstract
:1. Introduction
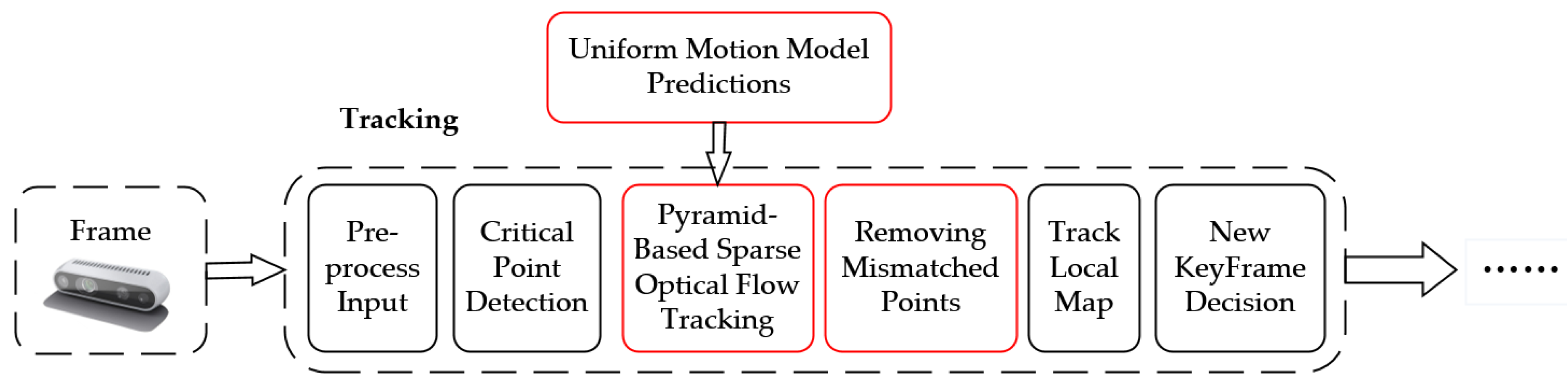
2. System Description
2.1. Algorithm Framework
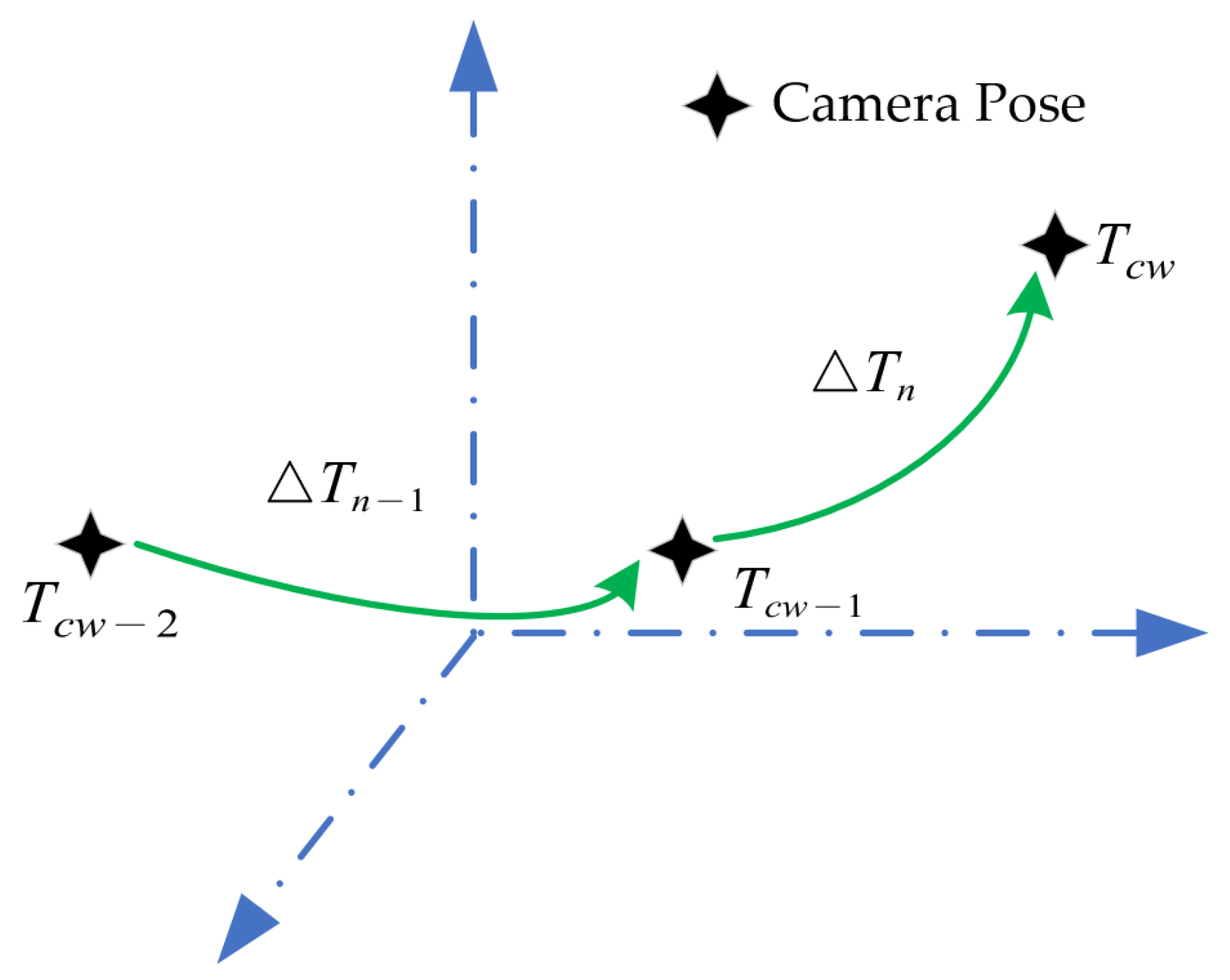
2.2. Prediction of Initial Correspondence of Key Points
2.3. Pyramid-Based Sparse Optical Flow Tracking Matching
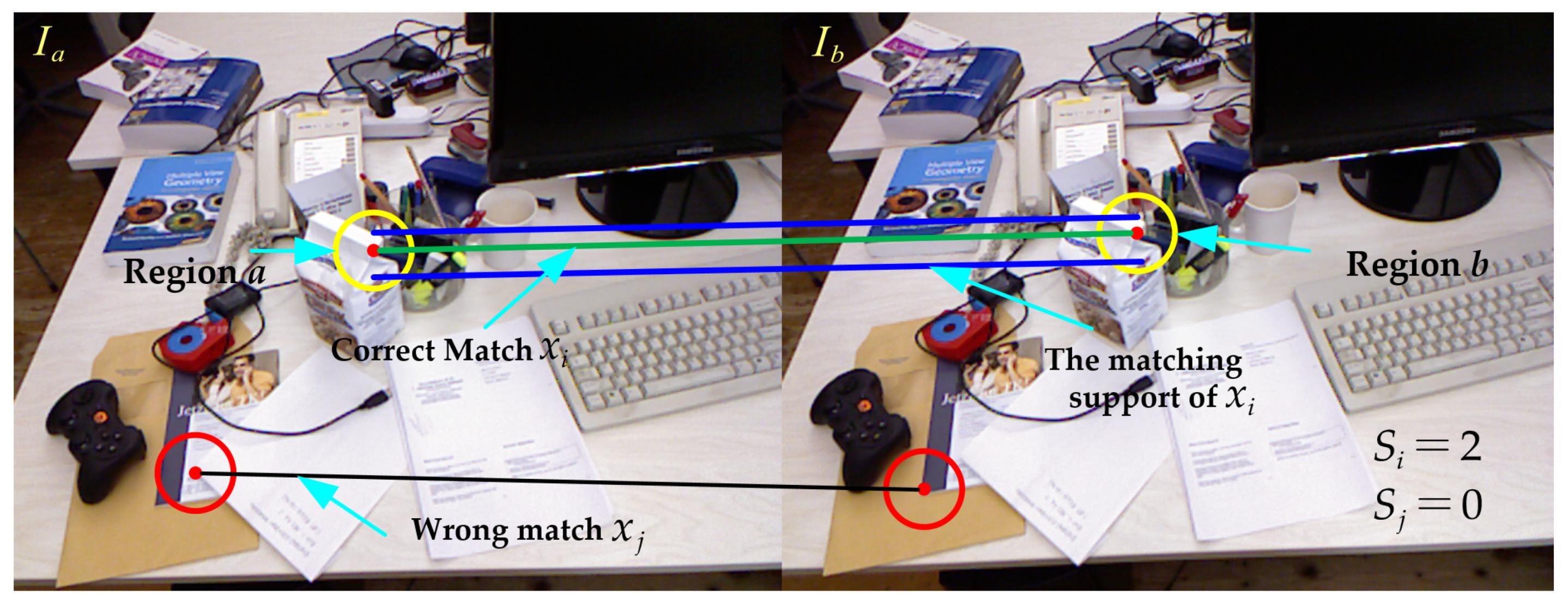
2.4. Strategy for Removing Mismatched Points
- (1)
- Randomly select eight pairs of matching points from the matching points after the preliminary screening, and use the eight-point algorithm to solve the fundamental matrix F.
- (2)
- Calculate the Simpson distance d between the remaining matching point pairs according to Formula (13). If , it is considered that the matching point pair is an internal point. Otherwise, it is considered an external point. Record the number of internal points at this time.
- (3)
- Repeat the above steps. If the number of iterations reaches the set threshold or the ratio of the number of internal points to all matching points reaches the set threshold during an iteration, stop the iteration. Then, select the fundamental matrix with the highest confidence and eliminate all matching points that do not meet the condition of in the matching point set after preliminary screening, to obtain the optimal matching point set.
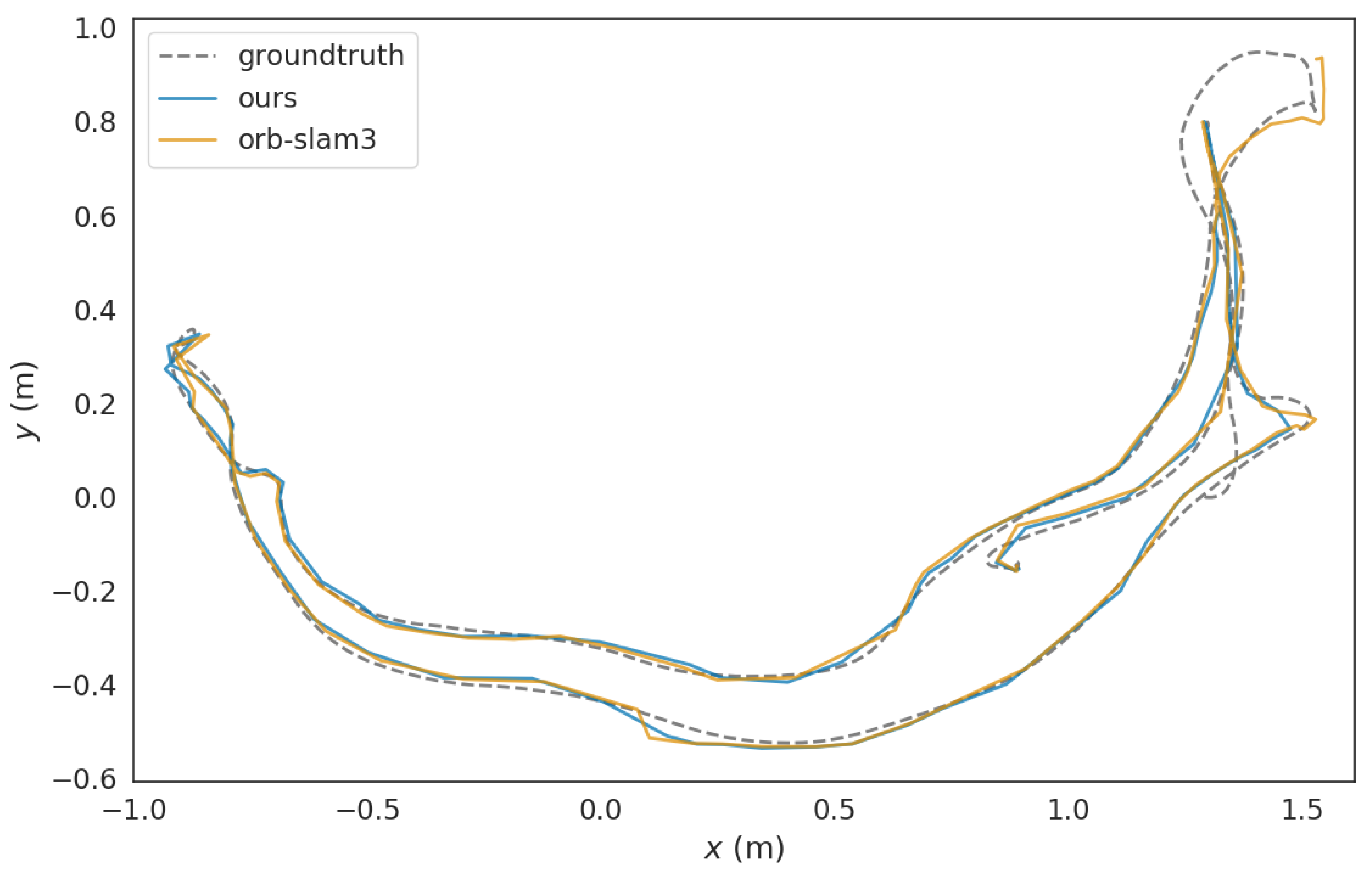
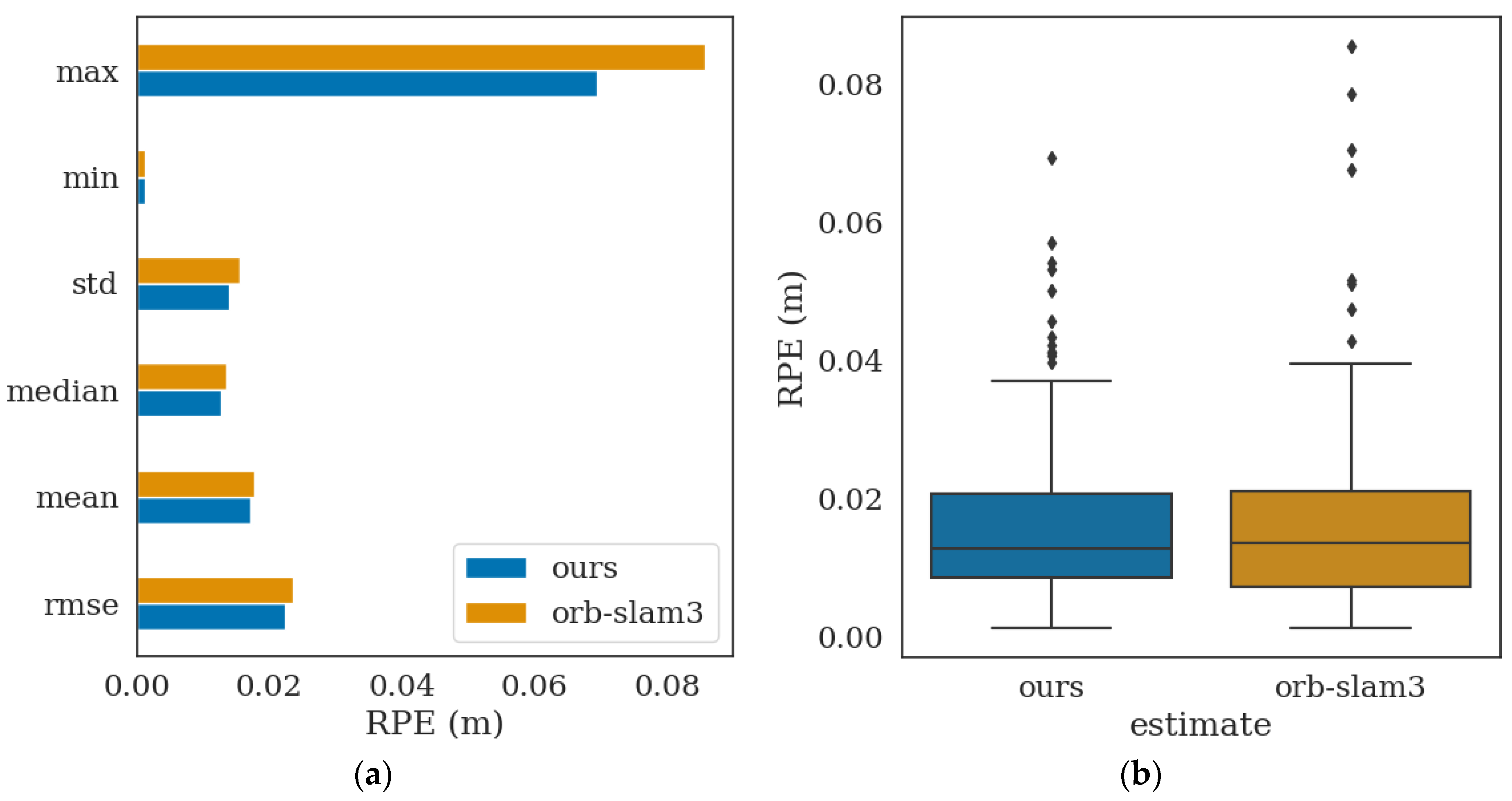
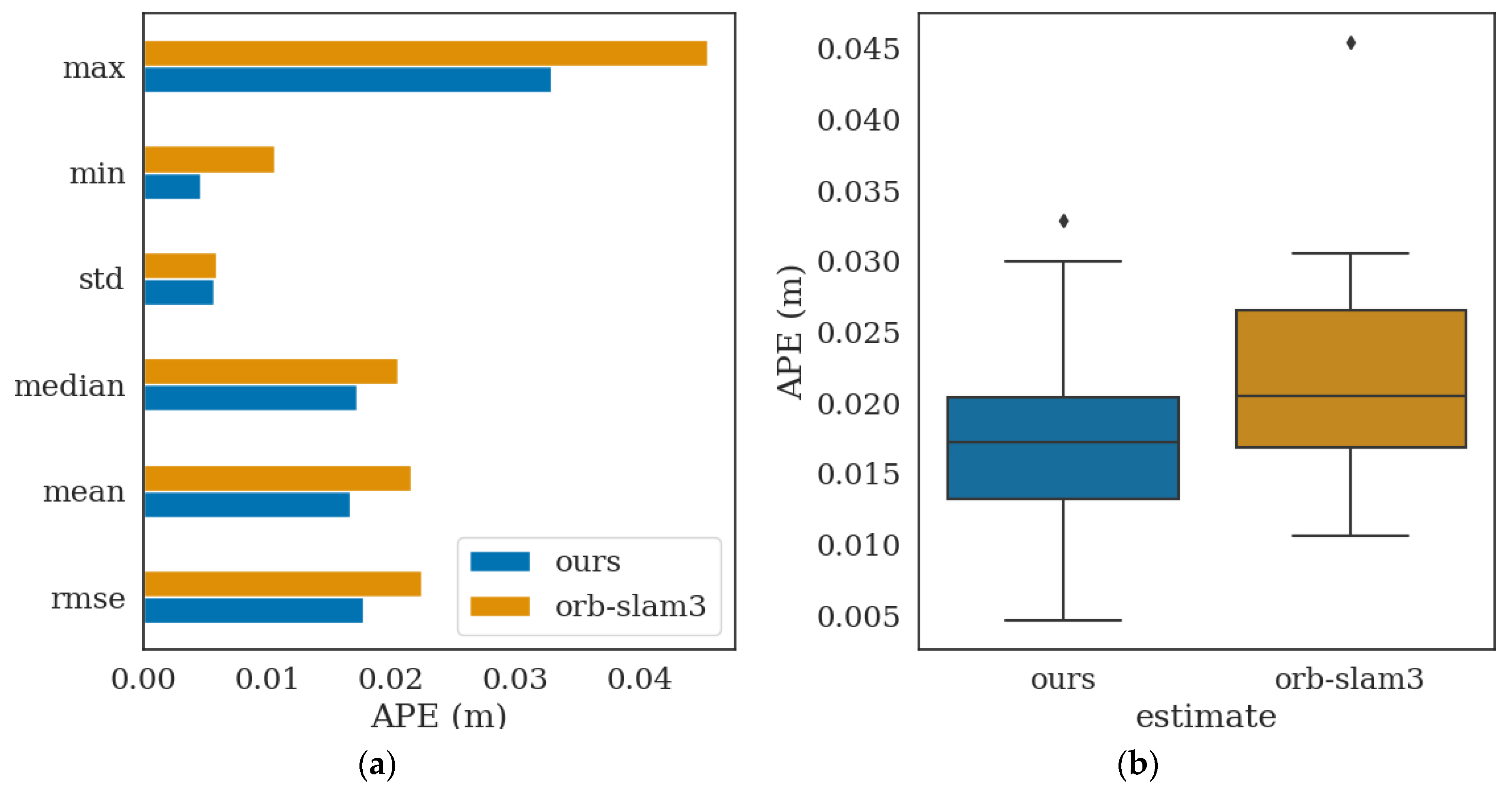
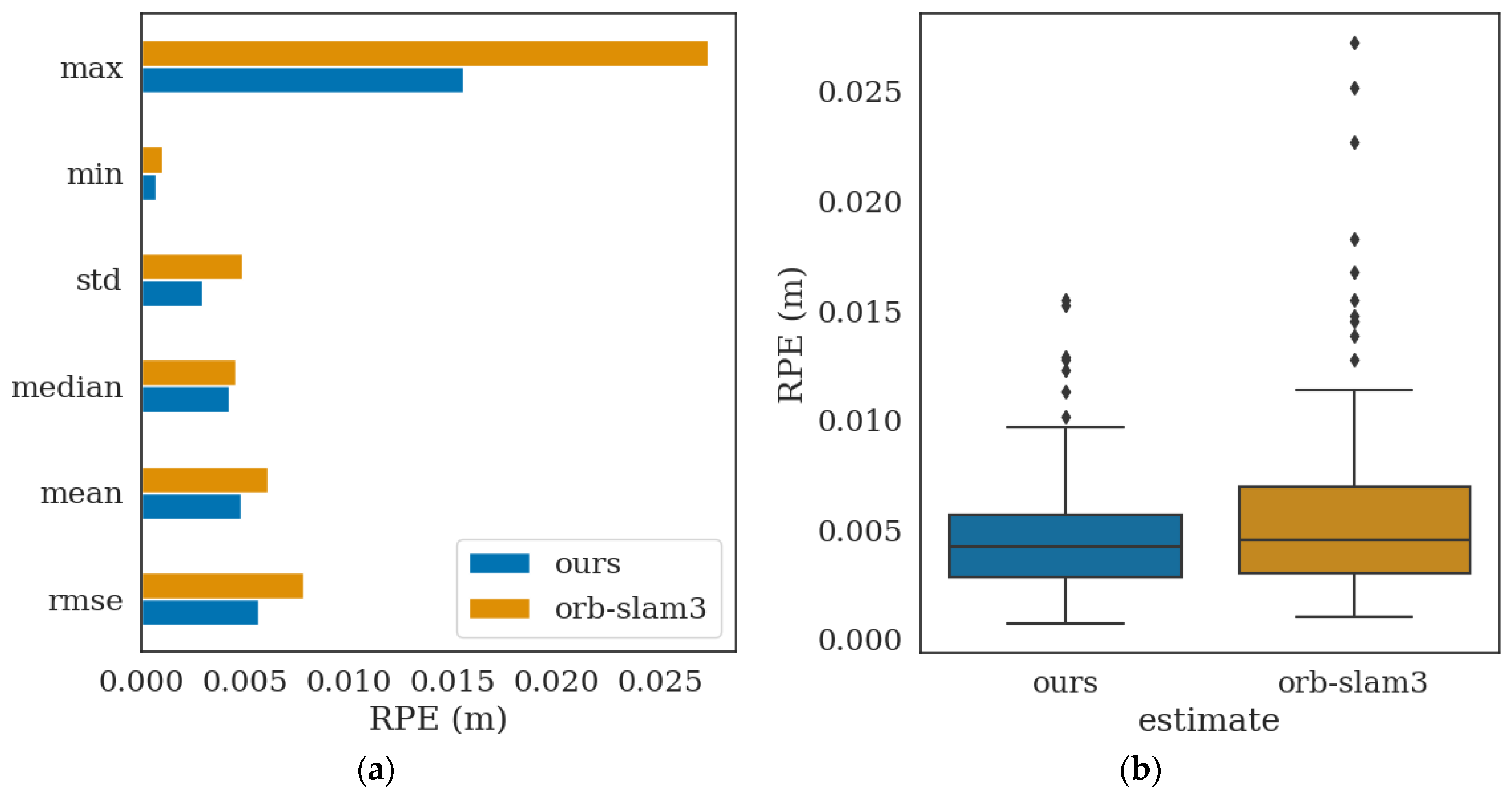
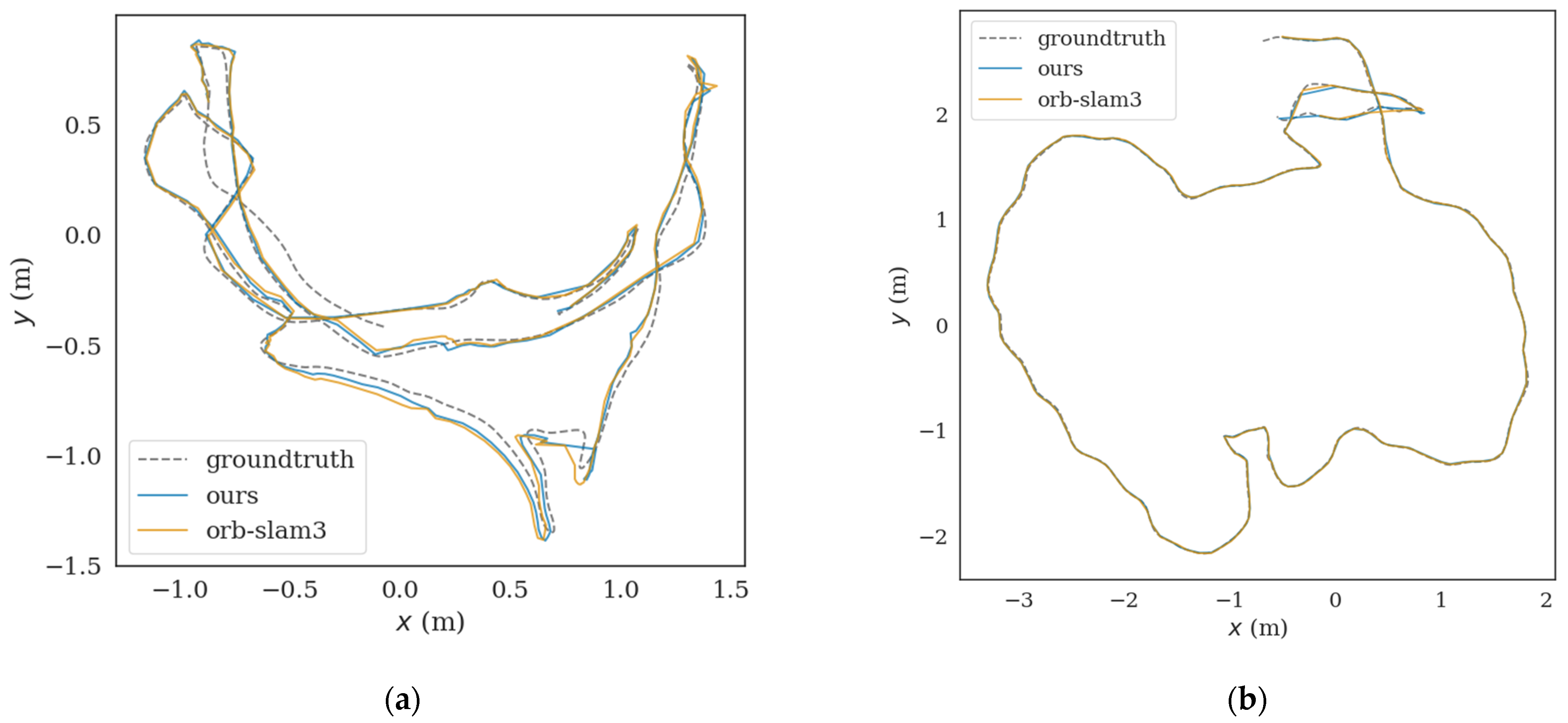
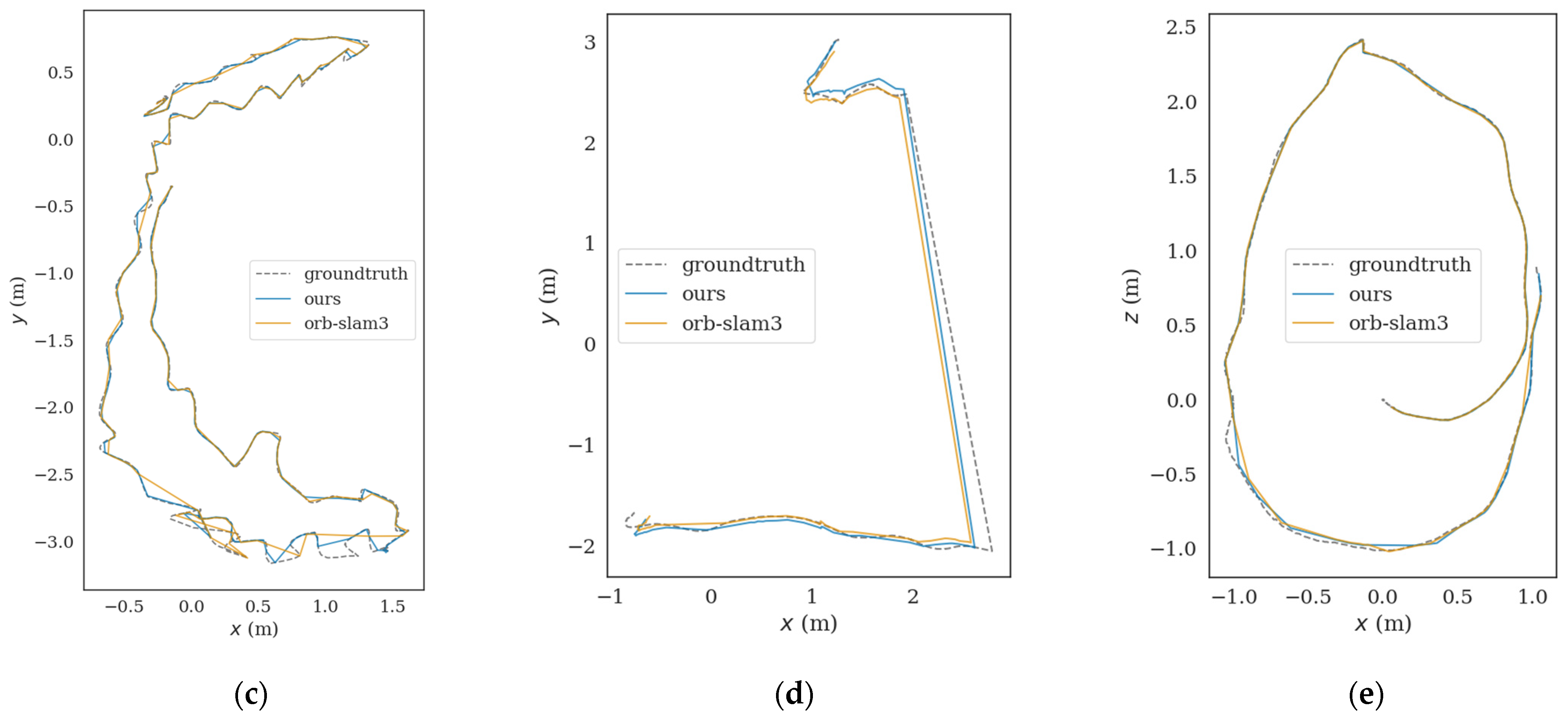
3. Experiment and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leonard, J.J.; Durrant-Whyte, H.F. Simultaneous Map Building and Localization for an Autonomous Mobile Robot. In Proceedings of the IROS ‘91: IEEE/RSJ International Workshop on Intelligent Robots and Systems’91, Osaka, Japan, 3–5 November 1991; IEEE: Osaka, Japan, 1991; pp. 1442–1447. [Google Scholar]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM Algorithms: A Survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 16. [Google Scholar] [CrossRef]
- Li, H.; Zhou, Y.; Dong, Y.; Li, J. Research on Navigation Algorithm of Ros Robot Based on Laser SLAM. World Sci. Res. J. 2022, 8, 581–584. [Google Scholar]
- Chen, Z.; Qi, Y.; Zhong, S.; Feng, D.; Chen, Q.; Chen, H. SCL-SLAM: A Scan Context-Enabled LiDAR SLAM Using Factor Graph-Based Optimization. In Proceedings of the IEEE International Conference on Unmanned Systems (ICUS), Guangzhou, China, 28–30 October 2022; pp. 1264–1269. [Google Scholar]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-Coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Zhou, H.; Yao, Z.; Lu, M. UWB/Lidar Coordinate Matching Method with Anti-Degeneration Capability. IEEE Sens. J. 2021, 21, 3344–3352. [Google Scholar] [CrossRef]
- Camurri, M.; Ramezani, M.; Nobili, S.; Fallon, M. Pronto: A Multi-Sensor State Estimator for Legged Robots in Real-World Scenarios. Front. Robot. AI 2020, 7, 68. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Zheng, C.; Xu, W.; Zhang, F. R2LIVE: A Robust, Real-Time, LiDAR-Inertial-Visual Tightly-Coupled State Estimator and Mapping. IEEE Robot. Autom. Lett. 2021, 6, 7469–7476. [Google Scholar] [CrossRef]
- Lin, J.; Zhang, F. R3LIVE: A Robust, Real-Time, RGB-Colored, LiDAR-Inertial-Visual Tightly-Coupled State Estimation and Mapping Package. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2021. [Google Scholar]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Veh. 2023, 8, 1–13. [Google Scholar] [CrossRef]
- Kim, M.; Zhou, M.; Lee, S.; Lee, H. Development of an Autonomous Mobile Robot in the Outdoor Environments with a Comparative Survey of LiDAR SLAM. In Proceedings of the 22nd International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 27 November–1 December 2022; pp. 1990–1995. [Google Scholar]
- Yang, S.; Zhao, C.; Wu, Z.; Wang, Y.; Wang, G.; Li, D. Visual SLAM Based on Semantic Segmentation and Geometric Constraints for Dynamic Indoor Environments. IEEE Access 2022, 10, 69636–69649. [Google Scholar] [CrossRef]
- Jie, L.; Jin, Z.; Wang, J.; Zhang, L.; Tan, X. A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs. Remote Sens. 2022, 14, 1741. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Washington, DC, USA, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense Tracking and Mapping in Real-Time. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 15–22. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Zhang, H.; Huo, J.; Sun, W.; Xue, M.; Zhou, J. A Static Feature Point Extraction Algorithm for Visual-Inertial SLAM. In Proceedings of the China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 987–992. [Google Scholar]
- Engel, J.; Stückler, J.; Cremers, D. Large-Scale Direct SLAM with Stereo Cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 1935–1942. [Google Scholar]
- Khairuddin, A.R.; Talib, M.S.; Haron, H. Review on Simultaneous Localization and Mapping (SLAM). In Proceedings of the IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–29 November 2015; pp. 85–90. [Google Scholar]
- Guo, G.; Dai, Z.; Dai, Y. Real-Time Stereo Visual Odometry Based on an Improved KLT Method. Appl. Sci. 2022, 12, 12124. [Google Scholar] [CrossRef]
- De Palezieux, N.; Nageli, T.; Hilliges, O. Duo-VIO: Fast, Light-Weight, Stereo Inertial Odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 2237–2242. [Google Scholar]
- Bian, J.-W.; Lin, W.-Y.; Liu, Y.; Zhang, L.; Yeung, S.-K.; Cheng, M.-M.; Reid, I. GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. Int. J. Comput. Vis. 2020, 128, 1580–1593. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Loulé, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A Benchmark for RGB-D Visual Odometry, 3D Reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 1524–1531. [Google Scholar]
- Grupp, M. Evo: Python Package for the Evaluation of Odometry and Slam. Available online: https://github.com/MichaelGrupp/evo (accessed on 14 October 2017).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | RMSE (m) | Improvement | |
|---|---|---|---|
| Ours | ORB-SLAM3 | ||
| fr1-xyz | 0.012 | 0.011 | - |
| fr1-room | 0.042 | 0.045 | 6.67% |
| fr1-desk2 | 0.023 | 0.025 | 8.00% |
| fr2-large | 0.12 | 0.107 | - |
| fr2-rpy | 0.003 | 0.003 | - |
| fr2-person | 0.005 | 0.006 | 16.67% |
| fr3-office | 0.011 | 0.013 | 15.38% |
| fr3-notx-near | 0.018 | 0.021 | 14.29% |
| fr3-tx-near | 0.012 | 0.01 | - |
| office2 | 0.017 | 0.02 | 15.00% |
| office3 | 0.066 | 0.06 | - |
| living2 | 0.021 | 0.019 | - |
| living3 | 0.012 | 0.013 | 7.69% |
| Sequence | Average Time Consumption (s) | Improvement | |
|---|---|---|---|
| Ours | ORB-SLAM3 | ||
| fr1-xyz | 0.024 | 0.029 | 17.24% |
| fr1-room | 0.016 | 0.021 | 23.81% |
| fr1-desk2 | 0.013 | 0.019 | 31.58% |
| fr2-large | 0.015 | 0.022 | 31.82% |
| fr2-rpy | 0.022 | 0.027 | 18.52% |
| fr2-person | 0.024 | 0.034 | 29.41% |
| fr3-office | 0.014 | 0.019 | 26.32% |
| fr3-notx-near | 0.01 | 0.013 | 23.08% |
| fr3-tx-near | 0.022 | 0.029 | 24.14% |
| office2 | 0.015 | 0.021 | 28.57% |
| office3 | 0.017 | 0.023 | 26.09% |
| living2 | 0.015 | 0.022 | 31.82% |
| living3 | 0.018 | 0.027 | 33.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhou, Y.; Yu, G.; Cui, Y. A Lightweight Visual Odometry Based on LK Optical Flow Tracking. Appl. Sci. 2023, 13, 11322. https://doi.org/10.3390/app132011322
Wang X, Zhou Y, Yu G, Cui Y. A Lightweight Visual Odometry Based on LK Optical Flow Tracking. Applied Sciences. 2023; 13(20):11322. https://doi.org/10.3390/app132011322
Chicago/Turabian StyleWang, Xianlun, Yusong Zhou, Gongxing Yu, and Yuxia Cui. 2023. "A Lightweight Visual Odometry Based on LK Optical Flow Tracking" Applied Sciences 13, no. 20: 11322. https://doi.org/10.3390/app132011322
APA StyleWang, X., Zhou, Y., Yu, G., & Cui, Y. (2023). A Lightweight Visual Odometry Based on LK Optical Flow Tracking. Applied Sciences, 13(20), 11322. https://doi.org/10.3390/app132011322