
A Review of Image Inpainting Methods Based on Deep Learning

 , ,
, , 
Abstract
:1. Introduction
2. Datasets and Evaluation Metrics
2.1. Datasets
2.2. Evaluation Metrics
3. Traditional Inpainting Techniques
- Simulation of Basic Techniques: The purpose of inpainting is to modify an image in an undetectable manner. Bertalmio et al. [10] introduced a new digital image restoration algorithm that attempts to simulate the basic techniques used by professional restorers.
- Combining Texture Synthesis and Inpainting Techniques: Criminisi et al. [11] proposed a new algorithm to remove large objects from digital images. It combines the advantages of texture synthesis algorithms and inpainting techniques, implementing a best-first algorithm to simultaneously propagate texture and structural information, achieving efficient image restoration.
- Inpainting Based on Mathematical Models: developed general mathematical models for local inpainting of non-textured images. The inpainting techniques involved in this method, when restoring edges, adopt a variational model closely related to the classic total variation (TV) denoising model proposed by Rudin, Osher, and Fatemi.
- Combining PDE and Texture Synthesis: Grossauer et al. [12] introduced a new algorithm that combines inpainting based on PDE and texture synthesis approaches, treating each distinct region of the image separately.
- Image Completion Based on a Large Database: Hays et al. [13] introduced a new image completion algorithm powered by a vast database of photographs collected from the Web. The main insight of this method is that while the space of images is virtually infinite, the space of semantically distinguishable scenes is not that large.
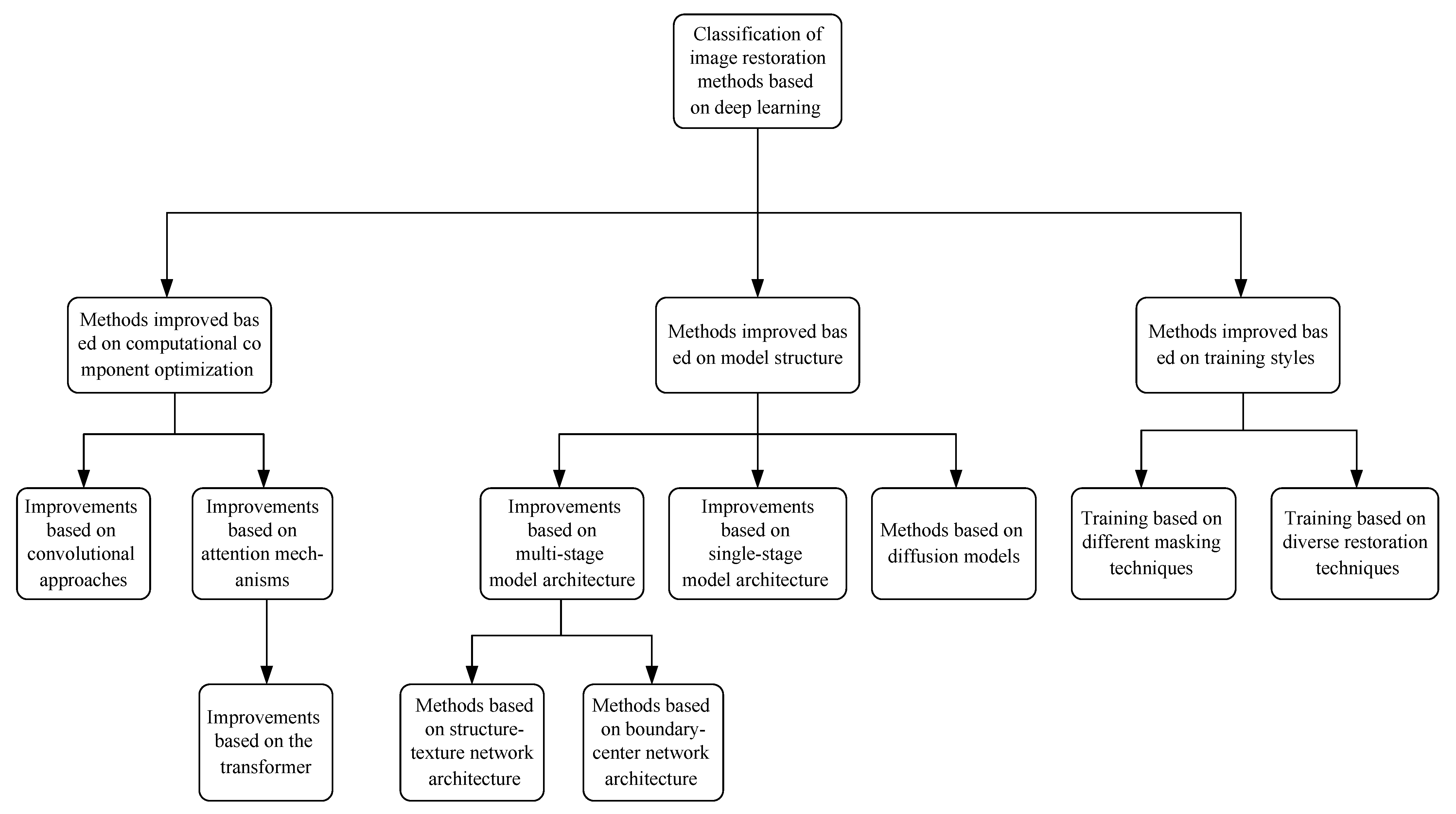
4. Deep-Learning-Based Image Inpainting Algorithm
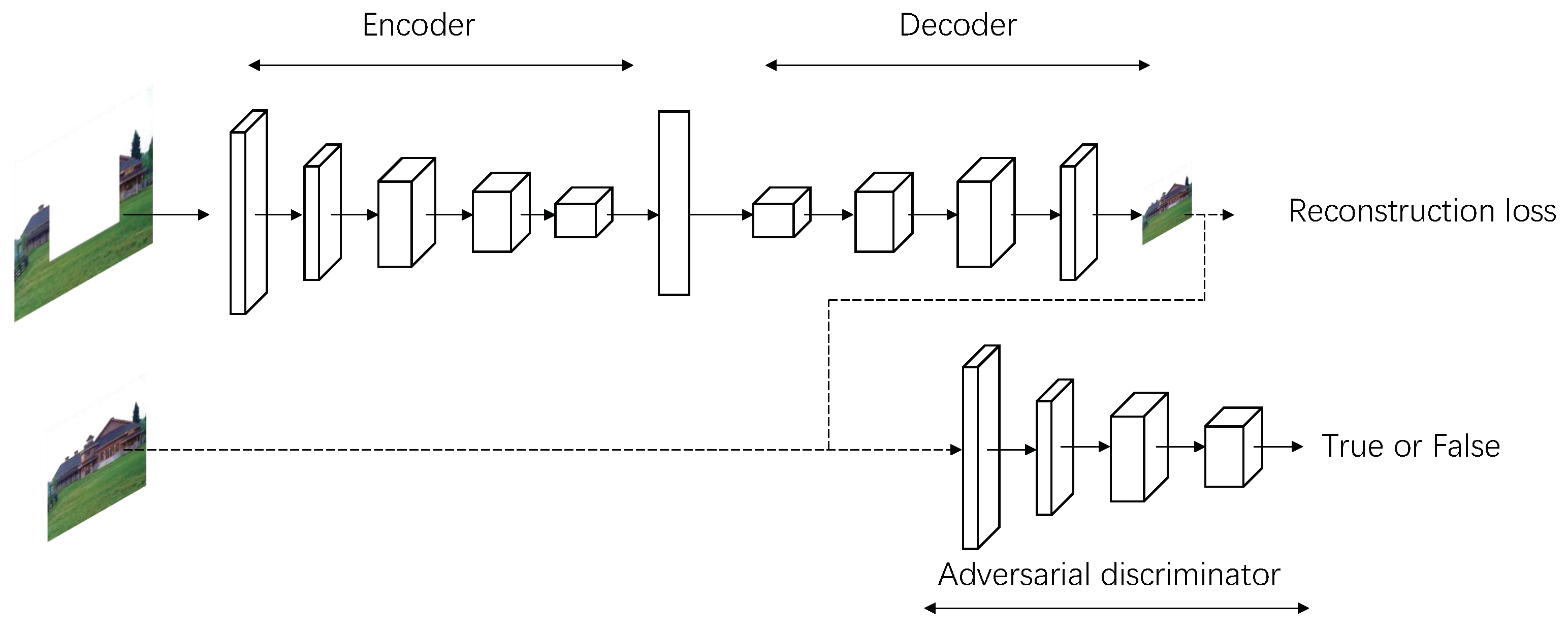
4.1. Deep-Learning-Based Image Restoration Process
4.2. Computational Component Optimization
4.2.1. Convolution Method
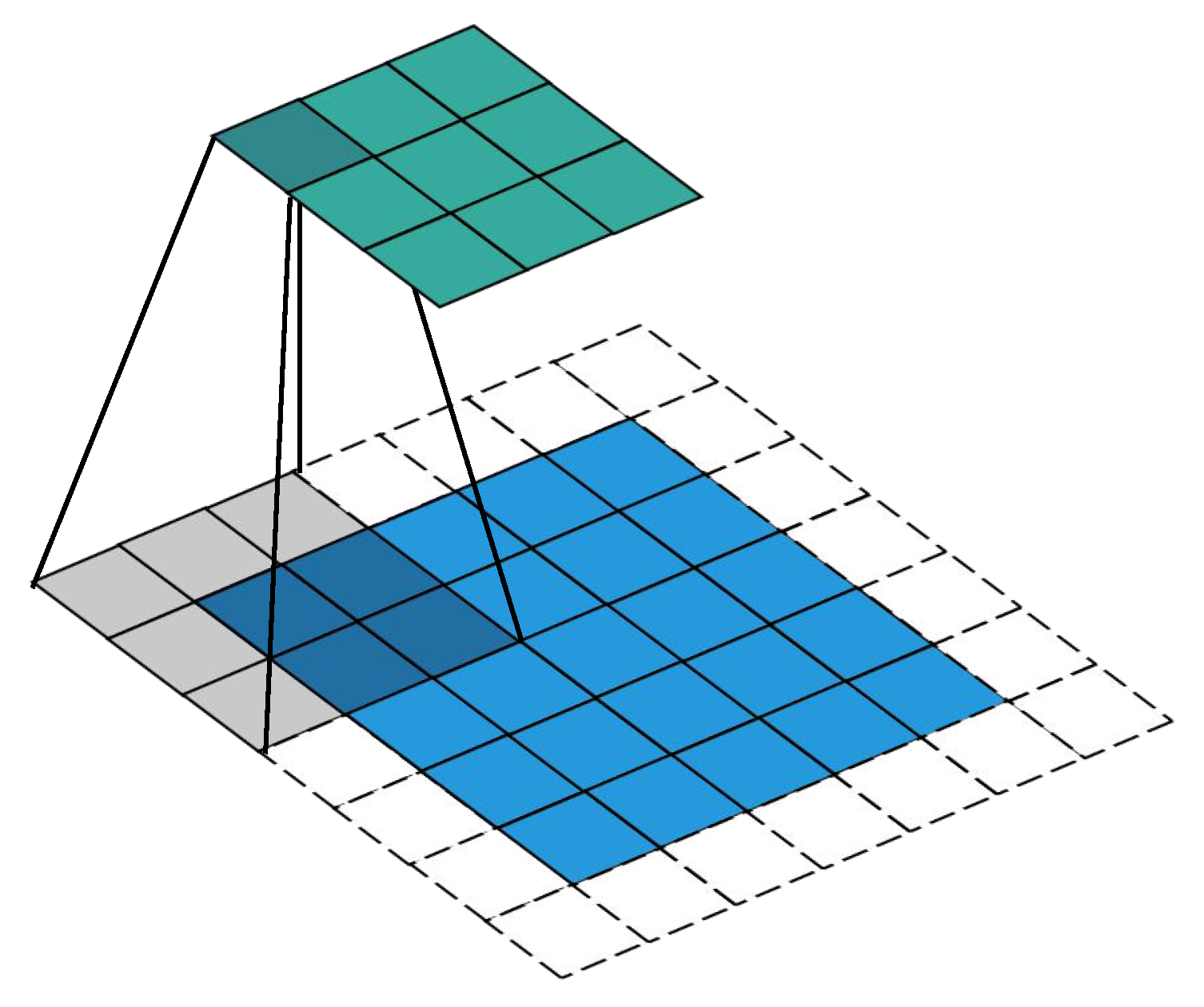
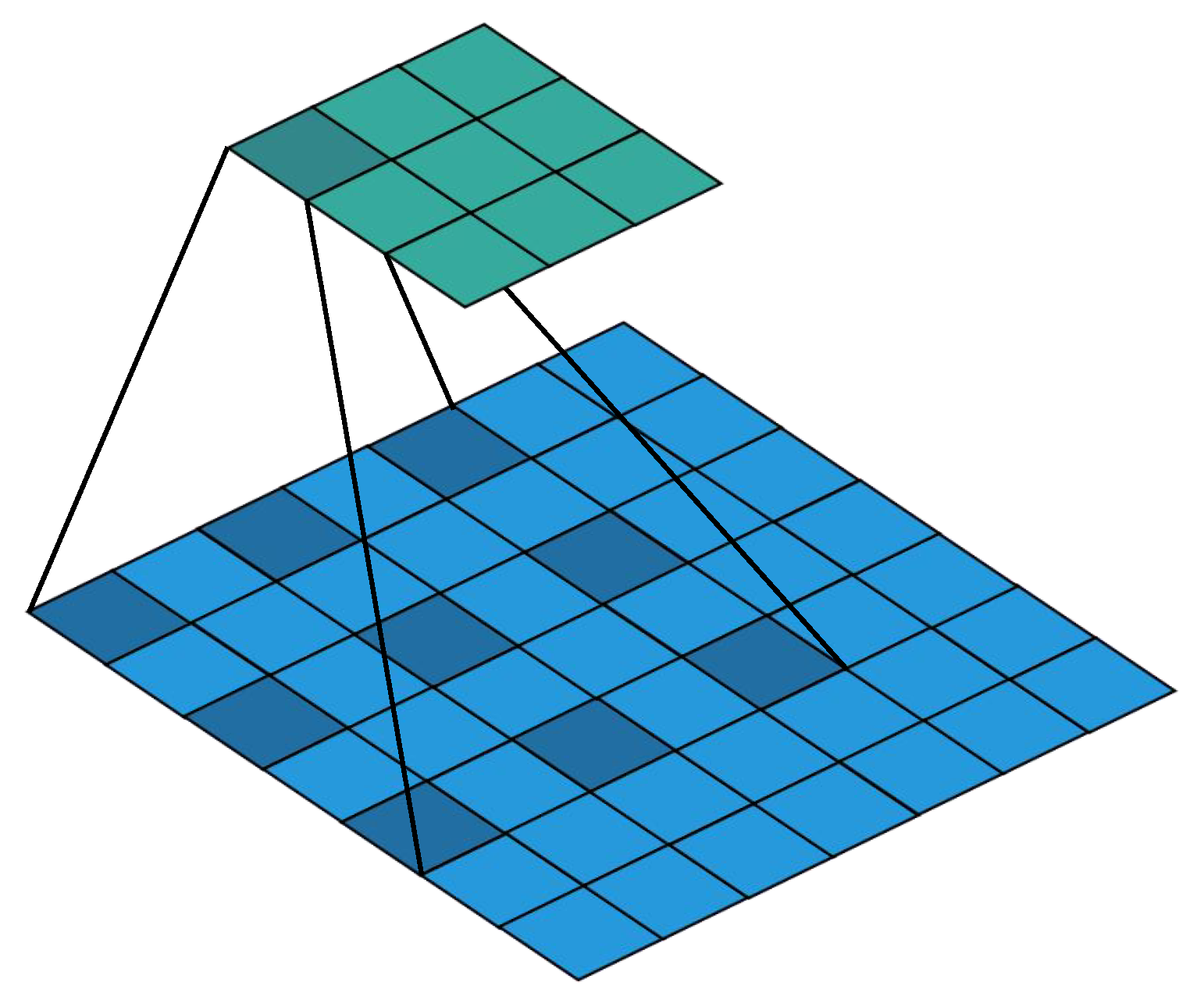
4.2.2. Dilated Convolution
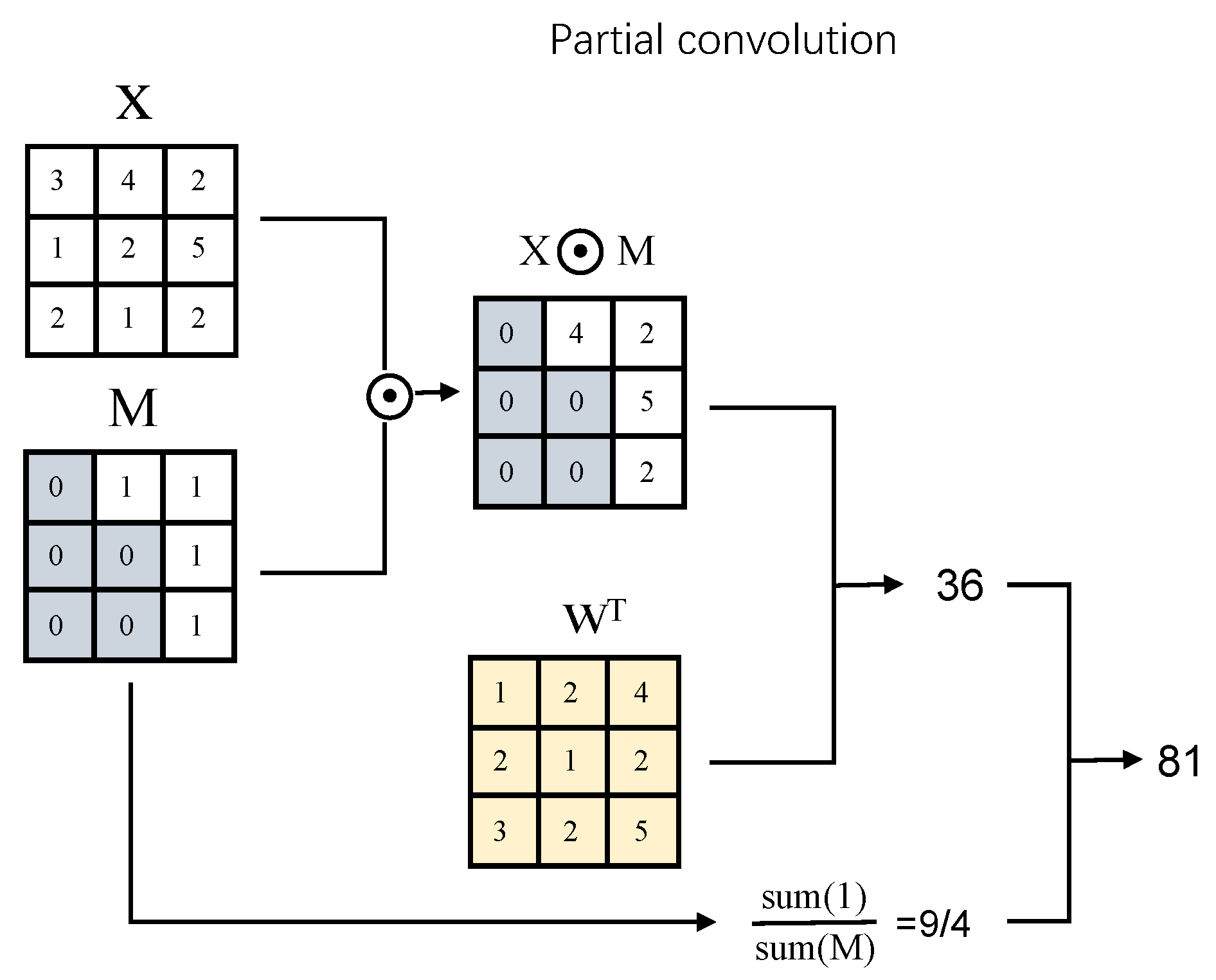
4.2.3. Partial Convolution
4.2.4. Gated Convolution
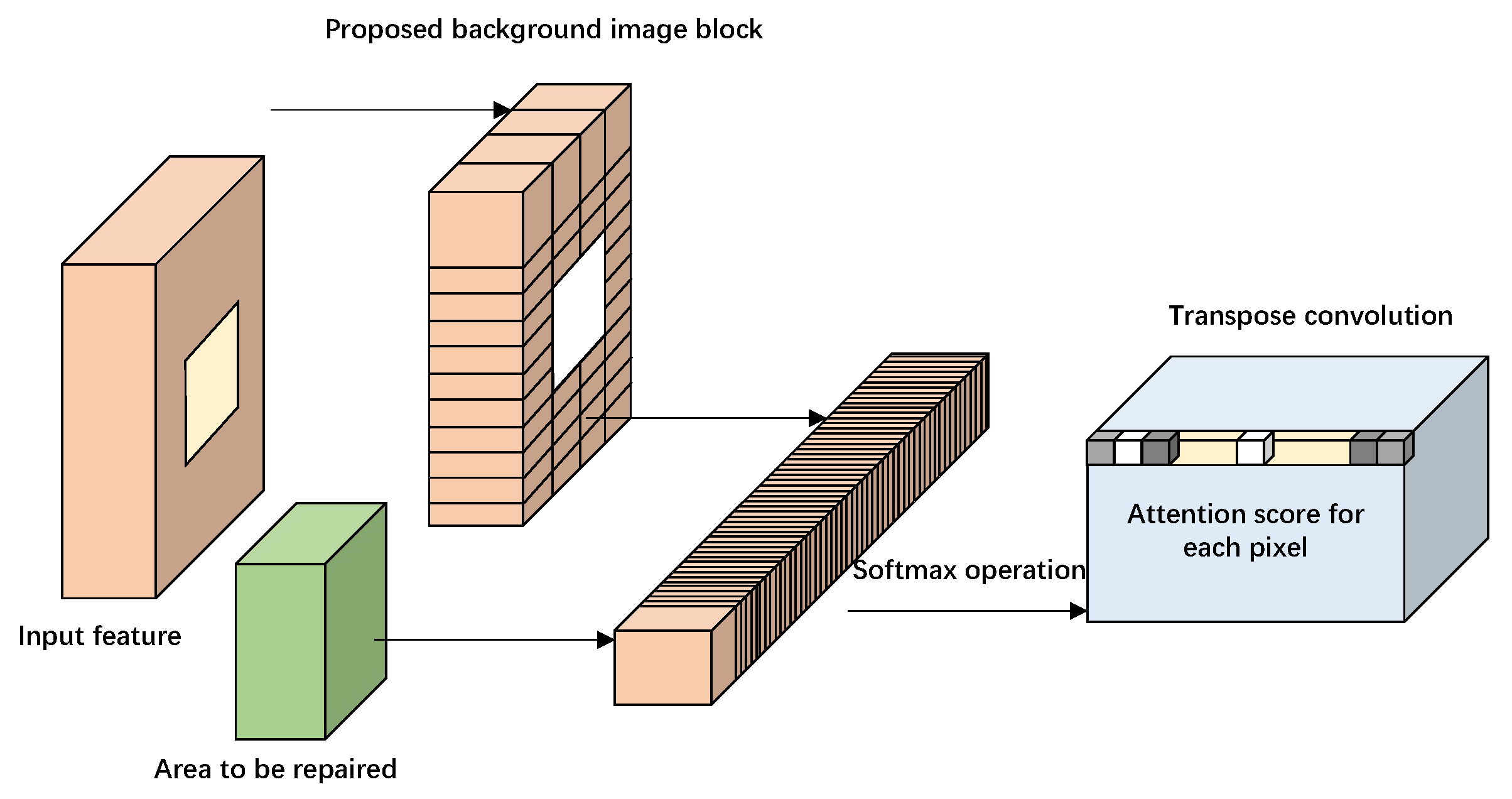
4.3. Attention Mechanism
4.3.1. Attention
4.3.2. Transformer
4.4. Model Structure
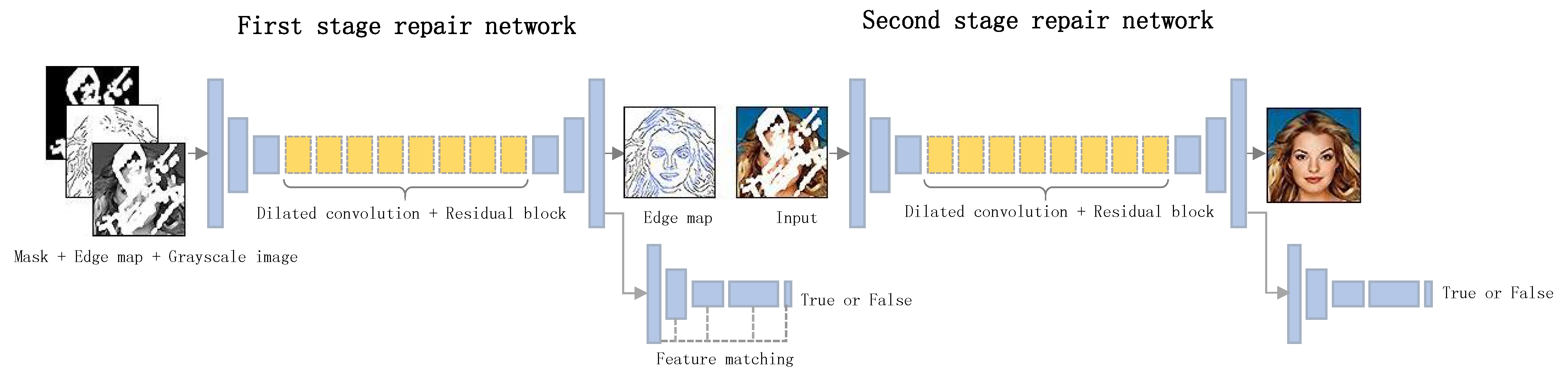
4.4.1. Multistage Network Structure
Structure–Texture Method
Boundary-Center Inpainting Method
4.4.2. Single-Stage Network Structure
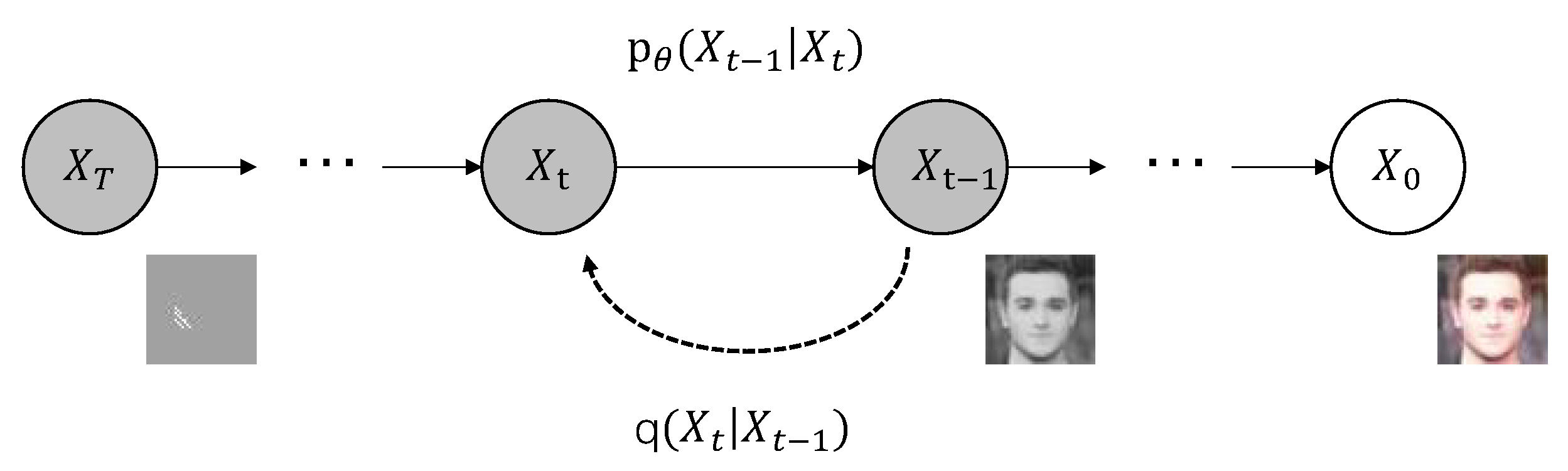
4.4.3. Diffusion Models
4.5. Training Methods
4.5.1. Different Masking Techniques
4.5.2. Diverse Inpaintings
5. Applications
5.1. Object Removal
5.1.1. General Image Object Removal
5.1.2. Remote Sensing Image Object Removal
5.1.3. Image Desensitization
5.2. Image Inpainting
5.3. Facial Inpainting
6. Comparison of the Latest Techniques
7. Ethical Considerations of Image Inpainting Techniques
- Transparency: Whenever an image is modified using inpainting techniques, it is imperative to clearly annotate the altered sections. Additionally, providing the original image as a point of reference can maintain the integrity of the content.
- Education and training: Offering training sessions for image processing experts and journalists can equip them with a comprehensive understanding of the potential risks and ethical implications associated with these techniques.
- Technological constraints: The development of innovative algorithms and tools dedicated to detecting and preventing image forgery is crucial. These tools can act as a deterrent, ensuring that the technology is used responsibly.
- Legal and policy frameworks: The formulation and enforcement of pertinent laws and policies can serve as a robust mechanism to penalize those who misuse inpainting techniques. Such legal frameworks can act as a deterrent, ensuring that individuals and organizations think twice before manipulating images unethically.
8. Outlook and Challenges
- Computational complexity: Deep learning models typically demand substantial computational resources, which might not be feasible for certain real-time applications.
- Real-time requirements: For specific applications, such as real-time video streams or gaming, instantaneous image restoration is paramount, setting a higher bar for the technology.
- Restoration quality: In certain intricate scenarios, prevailing techniques might fall short of achieving the desired restoration outcomes.
- Model lightweighting: The development of more streamlined models that not only ensure restoration quality but also meet real-time requirements.
- Adaptive learning: Enabling models to adaptively learn and restore based on varying scenarios and content.
- Multimodal fusion: Incorporating multiple sources of information (e.g., depth and semantics) for image restoration to enhance accuracy and robustness. The promise of these directions stems from their potential to tackle the core issues of current technologies while aligning with the evolving trends in computer vision and machine learning.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miao, Y.R. Research on Spine Tumor CT Image Inpainting Method Based on Deep Learning. Ph.D. Thesis, University of Chinese Academy of Sciences (Shenzhen Institutes of Advanced Technology, CAS), Shenzhen, China, 2020. [Google Scholar]
- Zhao, M.Y. Research on Cloud Removal Methods for Remote Sensing Images. Ph.D. Thesis, Tianjin University of Science & Technology, Tianjin, China, 2016. [Google Scholar]
- Zhang, S.Y.; Li, C.L. Aerial Image Thick Cloud Inpainting Based on Improved Criminisi Algorithm. Prog. Laser Optoelectron. 2018, 55, 275–281. [Google Scholar]
- Dong, X.Y. Extraction of Architectural Objects and Recovery of Occlusion Information in Slant Remote Sensing Images. Ph.D. Thesis, Harbin Engineering University, Harbin, China, 2021. [Google Scholar]
- Yang, Q.Y. Kriging Inpainting of Mountain Shadow Loss in Peak Cluster Depression Remote Sensing Image. Remote Sens. Land Resour. 2012, 4, 112–116. [Google Scholar]
- Yang, Y. Lafin: Generative landmark guided face inpainting. arXiv 2019, arXiv:1911.11394. [Google Scholar]
- Shen, Z.; Lai, W.S.; Xu, T.; Kautz, J.; Yang, M.H. Deep semantic face deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, X.; Wang, X.; Shi, C.; Yan, Z.; Li, X.; Kong, B.; Lyu, S.; Zhu, B.; Lv, J.; Yin, Y. DE-GAN: Domain Embedded GAN for High Quality Face Image Inpainting. Pattern Recognit. 2021, 124, 108415. [Google Scholar] [CrossRef]
- Lahiri, A.; Jain, A.K.; Agrawal, S. Prior guided gan based semantic inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000. [Google Scholar]
- Criminisi, A.; Perez, P.; Toyama, K. Region Filling and Object Removal by Exemplar-Based Image Inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Shen, J.; Chan, T.F. Mathematical Models for Local Nontexture Inpaintings. SIAM J. Appl. Math. 2002, 62, 1019–1043. [Google Scholar] [CrossRef]
- Grossauer, H. A combined PDE and texture synthesis approach to inpainting. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Hays, J.; Efros, A.A. Scene completion using millions of photographs. Acm Trans. Graph. 2007, 26, 4-es. [Google Scholar] [CrossRef]
- Li, J.; He, F.; Zhang, L.; Du, B.; Tao, D. Progressive reconstruction of visual structure for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liao, L.; Xiao, J.; Wang, Z.; Lin, C.-W.; Satoh, S. Guidance and evaluation: Semantic-aware image inpainting for mixed scenes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Cai, J.; Li, C.; Tao, X.; Tai, Y.W. Image Multi-Inpainting via Progressive Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zheng, C.; Cham, T.-J.; Cai, J. Pluralistic image completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Chu, T.H. Research on Image Inpainting and Recognition Methods of Contaminated License Plates Based on Machine Vision. Ph.D. Thesis, North China University of Technology, Beijing, China, 2021. [Google Scholar]
- Li, Y.; Leng, S.Y.; Lei, M.; Zou, L. Scratch Detection and Removal Methods for Coal Rock Microscopic Images. Ind. Min. Autom. 2021, 47, 95–100. [Google Scholar]
- Zhang, X.; Zhang, M.; Xiao, X.L.; Luo, L.; Yang, Y.Q.; Cui, W.P. Image Inpainting Method for Whole Well Electrical Imaging in Complex Stratum. Geophys. Prospect. Pet. 2018, 57, 148–153. [Google Scholar]
- Lv, C. Research on Removal and Inpainting Algorithm of Digital Image Mirror Reflection. Ph.D. Thesis, Xiamen University, Xiamen, China, 2017. [Google Scholar]
- Li, S. Research on Mobile Robot Semantic Map Building System. Ph.D. Thesis, Beijing University of Technology, Beijing, China, 2018. [Google Scholar]
- Zheng, C. Research on Vision Road Detection and Tracking Algorithm for Micro-Robots. Ph.D. Thesis, Nanjing University of Science & Technology, Nanjing, China, 2006. [Google Scholar]
- Li, Y. Gait Recognition under Occlusion Based on Deep Learning. Ph.D. Thesis, Harbin Engineering University, Harbin, China, 2021. [Google Scholar]
- Chen, Y.; Zhao, D. Automatic Image Inpainting Algorithm for Apple Picking Robot Vision Based on LBM. J. Agric. 2010, 41, 153–157+162. [Google Scholar]
- Huang, Y. Application Research of Image Inpainting Technology in Environmental Art Design. Mod. Electron. Technol. 2018, 41, 50–54. [Google Scholar]
- Liu, J. Research on Ancient Mural Image Protection and Intelligent Inpainting Technology. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2010. [Google Scholar]
- Chen, Y.; Tao, M. A Review of Digital Inpainting Methods for Dunhuang Murals. Softw. Guide 2021, 20, 237–242. [Google Scholar]
- Li, X. Research on Virtual Inpainting Technology for Ancient Murals. Ph.D. Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2014. [Google Scholar]
- Chen, G. Application of Digital Image Inpainting Technology in Cultural Relic Protection. Orient. Collect. 2021, 7, 76–77. [Google Scholar]
- Li, C. Automatic Marking and Virtual Inpainting of Mud Spots Diseases on Ancient Murals. Ph.D. Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2015. [Google Scholar]
- Duan, Y. Research on Irregular Interference Inpainting Algorithm for Ancient Stone Carved Documents. Ph.D. Thesis, Kunming University of Science and Technology, Kunming, China, 2021. [Google Scholar]
- Yang, X.; Zhang, R.X.; Yang, F.W.; Ma, Q.; Liu, Q.; Li, Z.F. Exploration of Image Inpainting Algorithm Based on Maijishan Grottoes Relics. J. Longdong Univ. 2022, 33, 48–52. [Google Scholar]
- Jiang, J.; Wang, L.Y.; Wang, C.X.; Zhuo, G.; Nie, T.Y.; Feng, J.S. Research on Digital Image Inpainting Technology of Tibetan Murals Based on CDD Model. Electron. Des. Eng. 2014, 22, 177–179. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Fei-Fei, L. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Doersch, C.; Singh, S.; Gupta, A.; Sivic, J.; Efros, A.A. What makes paris look like paris? ACM Trans. Graph. 2012, 31, 1–9. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Qiang, Z.P.; He, L.B.; Chen, X.; Xu, D. Survey on deep learning image inpainting methods. J. Image Graph. 2019, 24, 447–463. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Akbari, Y. Image Inpainting: A Review. Neural Process. Lett. 2019, 51, 2007–2028. [Google Scholar] [CrossRef]
- Qin, Z.; Zeng, Q.; Zong, Y.; Xu, F. Image inpainting based on deep learning: A review. Displays 2021, 69, 102028. [Google Scholar] [CrossRef]
- Zhao, L.; Shen, L.; Hong, R. A Survey on Image Inpainting Research Progress. Comput. Sci. 2021, 48, 14–26. [Google Scholar]
- Liu, K.; Li, J.; Bukhari, S.S.H. Overview of Image Inpainting and Forensic Technology. Secur. Commun. Netw. 2022, 2022, 1–27. [Google Scholar] [CrossRef]
- Ul Hassan, M. Alexnet Imagenet Classification with Deep Convolutional Neural Networks. 2018. Available online: https://neurohive.io/en/popular-networks/alexnet-imagenet-classification-with-deep-convolutional-neural-networks/ (accessed on 28 August 2023).
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Zeng, Y.; Lin, Z.; Lu, H.; Patel, V.M. Cr-fill: Generative image inpainting with auxiliary contextual reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xiao, Q.; Li, G.; Chen, Q. Deep inception generative network for cognitive image inpainting. arXiv 2018, arXiv:1812.01458. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated Contextual Transformations for High-Resolution Image Inpainting. IEEE Trans. Vis. Comput. Graph. 2022, 29, 3266–3280. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Song, Y.; Yang, C.; Lin, Z.; Liu, X.; Huang, Q.; Li, H.; Kuo, C.C.J. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mohite, T.A.; Phadke, G.S. Image inpainting with contextual attention and partial convolution. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing (AISP), Amaravati, India, 10–12 January 2020. [Google Scholar]
- Xie, C.; Liu, S.; Li, C.; Cheng, M.M.; Zuo, W.; Liu, X.; Ding, E. Image inpainting with learnable bidirectional attention maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sagong, M.C.; Shin, Y.G.; Kim, S.W.; Park, S.; Ko, S.J. Pepsi: Fast image inpainting with parallel decoding network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shin, Y.G.; Sagong, M.C.; Yeo, Y.J.; Kim, S.W.; Ko, S.J. Pepsi++: Fast and lightweight network for image inpainting. IEEE Trans. Neural Netw. Learn. 2020, 32, 252–265. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Jiang, B.; Xiao, Y.; Yang, C. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- He, X.; Cui, X.; Li, Q. Image Inpainting Based on Inside–Outside Attention and Wavelet Decomposition. IEEE Access 2020, 8, 62343–62355. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Tang, Z.; Qin, A.K.; Li, H.; Jiang, F. Deep Image Inpainting with Enhanced Normalization and Contextual Attention. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6599–6614. [Google Scholar] [CrossRef]
- Wang, C.; Shao, M.; Meng, D.; Zuo, W. Dual-Pyramidal Image Inpainting with Dynamic Normalization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5975–5988. [Google Scholar] [CrossRef]
- Wang, N.; Li, J.; Zhang, L.; Du, B. MUSICAL: Multi-Scale Image Contextual Attention Learning for Inpainting. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Wang, X.; Chen, Y.; Yamasaki, T. Spatially adaptive multi-scale contextual attention for image inpainting. Multimed. Tools Appl. 2022, 81, 31831–31846. [Google Scholar] [CrossRef]
- Liu, H.; Jiang, B.; Song, Y.; Huang, W.; Yang, C. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Learning pyramid-context encoder network for high-quality image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J.; Phung, D. Bridging Global Context Interactions for High-Fidelity Image Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zeng, Y.; Lin, Z.; Yang, J.; Zhang, J.; Shechtman, E.; Lu, H. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Yi, Z.; Tang, Q.; Azizi, S.; Jang, D.; Xu, Z. Contextual residual aggregation for ultra high-resolution image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Qiu, J.; Gao, Y.; Shen, M. Semantic-SCA: Semantic Structure Image Inpainting with the Spatial-Channel Attention. IEEE Access 2021, 9, 12997–13008. [Google Scholar] [CrossRef]
- Quan, W.; Zhang, R.; Zhang, Y.; Li, Z.; Wang, J.; Yan, D.M. Image inpainting with local and global refinement. IEEE Trans. Image Process. 2022, 31, 2405–2420. [Google Scholar] [CrossRef]
- Uddin, S.N.; Jung, Y.J. SIFNet: Free-form image inpainting using color split-inpaint-fuse approach. Comput. Vis. Image Underst. 2022, 221, 103446. [Google Scholar] [CrossRef]
- Manickam, A.; Jiang, J.; Zhou, Y. Deep image inpainting via contextual modelling in ADCT domain. IET Image Process. 2022, 16, 3748–3757. [Google Scholar] [CrossRef]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Lempitsky, V. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dong, Q.; Cao, C.; Fu, Y. Incremental transformer structure enhanced image inpainting with masking positional encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liu, Q.; Tan, Z.; Chen, D.; Chu, Q.; Dai, X.; Chen, Y.; Yu, N. Reduce Information Loss in Transformers for Pluralistic Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Li, W.; Lin, Z.; Zhou, K.; Qi, L.; Wang, Y.; Jia, J. MAT: Mask-Aware Transformer for Large Hole Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Cao, C.; Dong, Q.; Fu, Y. Learning Prior Feature and Attention Enhanced Image Inpainting. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Ren, Y.; Yu, X.; Zhang, R.; Li, T.H.; Liu, S.; Li, G. Structureflow: Image inpainting via structure-aware appearance flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wei, Z.; Min, W.; Wang, Q.; Liu, Q.; Zhao, H. ECNFP: Edge-constrained network using a feature pyramid for image inpainting. Expert Syst. Appl. 2022, 207, 118070. [Google Scholar] [CrossRef]
- Xiong, W.; Yu, J.; Lin, Z.; Yang, J.; Lu, X.; Barnes, C.; Luo, J. Foreground-aware image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yang, J.; Qi, Z.; Shi, Y. Learning to Incorporate Structure Knowledge for Image Inpainting. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12605–12612. [Google Scholar] [CrossRef]
- Yamashita, Y.; Shimosato, K.; Ukita, N. Boundary-Aware Image Inpainting with Multiple Auxiliary Cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Song, Y.; Yang, C.; Shen, Y.; Wang, P.; Huang, Q.; Kuo, C.C.J. Spg-net: Segmentation prediction and guidance network for image inpainting. arXiv 2018, arXiv:1805.03356. [Google Scholar]
- Li, J.; Wang, N.; Zhang, L.; Du, B.; Tao, D. Recurrent feature reasoning for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kim, S.Y.; Aberman, K.; Kanazawa, N.; Garg, R.; Wadhwa, N.; Chang, H.; Liba, O. Zoom-to-Inpaint: Image Inpainting with High-Frequency Details. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Guo, Z.; Chen, Z.; Yu, T.; Chen, J.; Liu, S. Progressive image inpainting with full-resolution residual network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Zhang, H.; Hu, Z.; Luo, C.; Zuo, W.; Wang, M. Semantic image inpainting with progressive generative networks. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Hui, Z.; Li, J.; Wang, X.; Gao, X. Image fine-grained inpainting. arXiv 2020, arXiv:2002.02609. [Google Scholar]
- Yu, Y.; Du, D.; Zhang, L.; Luo, T. Unbiased Multi-modality Guidance for Image Inpainting. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Kawar, B.; Elad, M.; Ermon, S.; Song, J. Denoising diffusion Inpainting models. arXiv 2022, arXiv:2201.11793. [Google Scholar]
- Press, W.H. Numerical Recipes 3rd Edition: The Art of Scientific Computing; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Theis, L.; Salimans, T.; Hoffman, M.D.; Mentzer, F. Lossy compression with gaussian diffusion. arXiv 2022, arXiv:2206.08889. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Choi, J.; Kim, S.; Jeong, Y.; Gwon, Y.; Yoon, S. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv 2021, arXiv:2108.02938. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 1–10 July 2022. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ma, Y.; Liu, X.; Bai, S.; Wang, L.; Liu, A.; Tao, D.; Hancock, E.R. Regionwise Generative Adversarial Image Inpainting for Large Missing Areas. IEEE Trans. Cybern. 2022, 53, 5226–5239. [Google Scholar] [CrossRef] [PubMed]
- Jo, Y.; Park, J. Sc-fegan: Face editing generative adversarial network with user’s sketch and color. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lu, Z.; Jiang, J.; Huang, J.; Wu, G.; Liu, X. GLaMa: Joint Spatial and Frequency Loss for General Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Sun, H.; Li, W.; Duan, Y.; Zhou, J.; Lu, J. Learning Adaptive Patch Generators for Mask-Robust Image Inpainting. IEEE Trans. Multimed. 2022, 5, 1. [Google Scholar] [CrossRef]
- Liu, H.; Wan, Z.; Huang, W.; Song, Y.; Han, X.; Liao, J. Pd-gan: Probabilistic diverse gan for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021. [Google Scholar]
- Zhao, L.; Mo, Q.; Lin, S.; Wang, Z.; Zuo, Z.; Chen, H.; Lu, D. Uctgan: Diverse image inpainting based on unsupervised cross-space translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wan, Z.; Zhang, J.; Chen, D.; Liao, J. High-fidelity pluralistic image completion with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, F. Sensitive Information Replacement Technology for Oil and Gas Exploration Images Based on Deep Learning. Ph.D. Thesis, Xi’an Shiyou University, Xi’an, China, 2021. [Google Scholar]
- Zhang, J.; Fukuda, T.; Yabuki, N. Automatic Object Removal with Obstructed Façades Completion Using Semantic Segmentation and Generative Adversarial Inpainting. IEEE Access 2021, 9, 117486–117495. [Google Scholar] [CrossRef]
- Zhao, S.; Cui, J.; Sheng, Y.; Dong, Y.; Liang, X.; Chang, E.I.; Xu, Y. Large scale image completion via co-modulated generative adversarial networks. arXiv 2021, arXiv:2103.10428. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Concept | Definition and Description |
|---|---|
| CNN (convolutional neural network) | A deep learning model particularly suited for processing image data. Through convolution operations, it captures local features in images. |
| Attention mechanism | Used to allocate higher weights to important information in data, allowing the model to focus more on significant details, thereby achieving efficient resource allocation. |
| Transformer | A deep learning model that abandons RNN and CNN structures, adopting a full attention mechanism. It is adept at handling long-sequence data dependencies. |
| Convolution | A key operation in neural networks for processing of image data, allowing the network to understand related pixel values in images. |
| Dilated convolution | A specialized convolution operation that adjusts the dilation rate to alter the receptive field size, enabling the model to “see” a larger area of the input image. |
| Partial convolution | A specialized convolution operation that convolves only conditionally valid pixels, enabling image restoration models to repair any irregular area. |
| Gated convolution | Similar to partial convolution but using a soft filtering mechanism. Its parameters can be learned from the data. It learns a dynamic selection mechanism acting on the feature map for each channel and spatial position. |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Paris Street View | [9] | 17.59 | - | - | 10.33 | 128 × 128 | Central area regular mask (25%) |
| [19] | 25.25 | 0.7790 | - | 1.88 | 512 × 512 | Irregular mask (20~30%) | |
| Places2 | [18] | 23.36 | 0.8462 | 2.908 | 2.63 | 256 × 256 | Central area regular mask (25%) |
| [24] | 26.03 | 0.890 | 1.57 | 2.11 | 512 × 512 | Irregular mask (20~30%) |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Places2 | [29] | 18.91 | - | - | 8.6 | 256 × 256 | Regular mask (25%) |
| [41] | - | 0.7809 | 15.19 | 9.94 | 256 × 256 | Central area regular mask (25%) | |
| [31] | 25.59 | 0.7850 | - | 1.93 | 256 × 256 | Irregular mask [73] (20~30%) | |
| [43] | 19.69 | 0.8063 | - | 3.84 | 256 × 256 | Central area regular mask (25%) | |
| 24.7 | 0.8744 | - | 2.2 | Random mask [75] | |||
| [44] | - | 0.8840 | 4.898 | 5.44 | 512 × 512 | Random mask [75] | |
| [42] | 25.1 | 0.8686 | 15.28 | 256 × 256 | Irregular mask [73] (20~30%) | ||
| 22.89 | 0.8063 | 19.99 | Irregular mask [73] (30~40%) | ||||
| 21.22 | 0.7391 | 25.88 | Irregular mask [73] (40~50%) | ||||
| [35] | 32.45 | 0.962 | 1.15 | 128 × 128 | Irregular mask [73] (20~30%) | ||
| 26.13 | 0.913 | 2.44 | Irregular mask [73] (30~40%) | ||||
| 24.36 | 0.874 | 3.26 | Irregular mask [73] (40~50%) | ||||
| [77] | 25.69 | 0.861 | 15.72 | 256 × 256 | Irregular mask [73] (20~30%) | ||
| 24.57 | 0.807 | 22.08 | Irregular mask [73] (30~40%) | ||||
| 22.28 | 0.712 | 28.74 | Irregular mask [73] (40~50%) | ||||
| [82] | 21.69 | 0.8130 | 3.057 | 256 × 256 | Central area regular mask (25%) | ||
| Image Net | [13] | 20.1 | - | - | 12.91 | 256 × 256 | Central area regular mask (25%) |
| [35] | - | 0.5600 | - | 15.61 | 512 × 512 | Central area regular mask (20%) | |
| Paris Street View | [34] | 18 | - | - | 10.01 | 128 × 128 | Central area regular mask (25%) |
| [36] | 26.51 | 0.9 | - | - | 256 × 256 | Central area regular mask (25%) | |
| Celeb A | [37] | 26.54 | 0.9310 | - | 1.83 | 256 × 256 | Central area regular mask (25%) |
| 32.58 | 0.982 | - | 0.94 | Irregular mask [73] (20~30%) | |||
| [40] | 26.32 | 0.9100 | 25.51 | - | 256 × 256 | Central area regular mask (25%) | |
| [83] | 29.91 | 0.9345 | 0.959 | 0.98 | 256 × 256 | Irregular mask [73] (20~30%) | |
| Celeb A-HQ | [38] | 25.6 | 0.9010 | - | - | 256 × 256 | Regular mask (25%) |
| 28.6 | 0.9290 | - | - | Random mask [75] | |||
| [39] | 25.5 | 0.8980 | - | - | 256 × 256 | Regular mask (25%) | |
| 28.5 | 0.9280 | - | - | Random mask [75] | |||
| [58] | 26.5 | 0.8932 | - | - | 256 × 256 | Central area regular mask (25%) |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Places2 | [19] | 25.1 | 0.8686 | 15.28 | 256 × 256 | Irregular mask (20–30%) | |
| 22.89 | 0.8063 | 19.99 | Irregular mask (30–40%) | ||||
| 21.22 | 0.7391 | 25.88 | Irregular mask (40–50%) | ||||
| [67] | 24.42 | 0.87 | 1.47 | 256 × 256 | Irregular mask (40–50%) | ||
| [69] | 24.49 | 0.806 | 22.121 | 256 × 256 | Irregular mask (50–60%) |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Places2 | [30] | 21.75 | 0.8230 | 8.16 | 3.86 | 256 × 256 | Regular mask (25%) |
| 24.92 | 0.8610 | 4.91 | 2.59 | Irregular mask (20~30%) | |||
| [46] | 25.22 | 0.9026 | 7.035 | - | 256 × 256 | Irregular mask (20~40%) | |
| Celeb A | [47] | 26.82 | 0.9270 | 1.654 | 2.08 | 256 × 256 | Regular mask (25%) |
| 33.19 | 0.9600 | 1.227 | 1.47 | Irregular mask | |||
| [71] | 26.28 | 0.912 | 256 × 256 | Irregular mask (30–40%) | |||
| Paris Street View | [71] | 30.99 | 0.954 | 256 × 256 | Irregular mask (10–20%) | ||
| [65] | 31.07 | 26.32 | 1.08 | 228 × 228 | Irregular mask (10–20%) | ||
| Cityscapes | [44] | 18.03 | 0.75 | 39.93 | 256 × 256 | Irregular mask | |
| [85] | 34.26 | 0.96 | 256 × 256 | Irregular mask |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Places2 | [41] | 26.44 | 0.862 | 2.75 | 256 × 256 | Irregular mask (30~40%) | |
| [45] | 25.66 | 0.914 | 256 × 256 | Irregular mask (20~30%) | |||
| [52] | 26.29 | 0.898 | 1.56 | 256 × 256 | Irregular mask (20~30%) | ||
| 24.01 | 0.842 | 2.38 | Irregular mask (30~40%) | ||||
| [73] | 34.78 | 0.975 | 0.36 | 256 × 256 | Irregular mask | ||
| 27.71 | 0.920 | 1.31 | Irregular mask | ||||
| Paris Street View | [26] | 19.72 | 8.11 | 128 × 128 | Central area regular mask (25%) |
| Dataset | Reference | PSNR↑ | SSIM↑ | FID↓ | L1↓/% | Image Resolution | Mask Type |
|---|---|---|---|---|---|---|---|
| Places2 | [12] | 0.7809 | 15.19 | 9.94 | 256 × 256 | Central area regular mask (25%) | |
| Paris Street View | [25] | 25 | 0.8563 | 256 × 256 | Central area regular mask (25%) | ||
| Celeb A | [40] | 26.32 | 0.9100 | 25.51 | 256 × 256 | Central area regular mask (25%) | |
| Celeb A-HQ | [38] | 25.6 | 0.9010 | - | - | 256 × 256 | Regular mask (25%) |
| 28.6 | 0.9290 | - | - | Random mask [75] | |||
| [39] | 25.5 | 0.8980 | - | - | 256 × 256 | Regular mask (25%) | |
| 28.5 | 0.9280 | - | - | Random mask [75] |
| Application Scenario | Description | Possible Deep Learning Methods |
|---|---|---|
| Object Removal | ||
| Conventional Image Object Removal | Used for scene restoration, environmental impact assessment, urban mapping, etc. Examples include gait recognition, robots detecting apples, and automatic removal of clutter after photography. | GAN models, self-attention mechanism, and transformer |
| Remote Sensing Image Object Removal | Used for filling and repairing of obstructed parts in remote sensing images, such as clouds, mountains, buildings, etc. | GAN models, self-attention mechanism, transformer, and multistage inpainting |
| Image Desensitization | Used to replace sensitive information in images, such as oil and gas exploration images. | GAN models and custom datasets |
| Image Restoration | ||
| Ancient Mural and Cultural Relic Image Restoration | Used for image restoration in ancient murals and cultural relics, which is crucial for the restoration of ancient culture and the study of ancient artifacts. | GAN models and self-attention mechanism |
| Modern Life and Industrial Image Restoration | Examples include license plate restoration from dirt and damage, scratch repair in coal rock micrographs, wellbore electrical image restoration, digital image repair affected by mirror reflection, etc. | GAN models, self-attention mechanism, transformer, and single-stage restoration |
| Face Inpainting | ||
| Criminal Investigation Face Inpainting | Used for facial recognition when the facial image of a criminal suspect is obstructed or damaged. | GAN models and diffusion models |
| Facial Feature and Expression Inpainting | Used to restore facial features and expressions in facial images, making them more realistic. | GAN models and diffusion models |
| Reference | Main Features | Advantages | Limitations |
|---|---|---|---|
| [53] | Classification of existing techniques | Provides comprehensive classification | Only a classification |
| [63] | Subkernel convolution | Enhances image understanding | Requires more computational resources |
| [76] | Selective latent space mapping | Improves prediction quality | Increases model complexity |
| [77] | Hierarchical pyramid convolution | Enhances multiscale features | Requires more parameters |
| [79] | Spatially adaptive attention score | Computes scores for each pixel | Requires more computational resources |
| [82] | Separate handling of effective and defective areas | Achieves high-quality results | Increases model complexity |
| [89] | Fourier transform as an alternative to self-attention | High parameter efficiency | Interpretation of periodic signals remains a question |
| [91] | Transformer in low-resolution sketch space | Handles large image sizes | Might sacrifice details |
| [92] | Autoencoder based on image blocks | No information loss | Requires more computational resources |
| [93] | Large hole inpainting model | Uses partially valid data | Increases model complexity |
| [94] | Pretrained transformer model | Better inpainting results | High computational load |
| [100] | Uses depth cues | Improves RGB inpainting quality | Requires depth information |
| [103] | Increasing the size of the missing area | Enhances high-frequency details | Requires more training time |
| [120] | Seven mask-generating strategies | Achieves superior results | Increases model complexity |
| [121] | Decomposition of complex mask region | Sequentially repairs each patch | Requires more computational resources |
| [21] | Progressive learning of SA-Patch GAN | Achieves high-quality results | Requires more training time |
| [110] | Unsupervised posterior estimation | Demonstrates the potential of diffusion models | Might not be suitable for all images |
| [113] | Replaces the reverse diffusion process in diffusion models | Handles irregular damage | Requires more parameters |
| [117] | Denoising process in latent space | Achieves more realistic inpainting results | Increases model complexity |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Zhang, X.; Chen, W.; Yao, M.; Liu, J.; Xu, T.; Wang, Z. A Review of Image Inpainting Methods Based on Deep Learning. Appl. Sci. 2023, 13, 11189. https://doi.org/10.3390/app132011189
Xu Z, Zhang X, Chen W, Yao M, Liu J, Xu T, Wang Z. A Review of Image Inpainting Methods Based on Deep Learning. Applied Sciences. 2023; 13(20):11189. https://doi.org/10.3390/app132011189
Chicago/Turabian StyleXu, Zishan, Xiaofeng Zhang, Wei Chen, Minda Yao, Jueting Liu, Tingting Xu, and Zehua Wang. 2023. "A Review of Image Inpainting Methods Based on Deep Learning" Applied Sciences 13, no. 20: 11189. https://doi.org/10.3390/app132011189
APA StyleXu, Z., Zhang, X., Chen, W., Yao, M., Liu, J., Xu, T., & Wang, Z. (2023). A Review of Image Inpainting Methods Based on Deep Learning. Applied Sciences, 13(20), 11189. https://doi.org/10.3390/app132011189