


Deep CNN-Based Materials Location and Recognition for Industrial Multi-Crane Visual Sorting System in 5G Network


 ,
, 
Abstract
1. Introduction
- We design a novel multi-crane visual sorting system that applies deep CNN algorithm for the material location and recognition, and propose a dynamic scheduling method of materials with cloud PLC in 5G network;
- We apply the YOLOv5 algorithm to locate the position of materials in the industry and use a camera calibration method to realize coordinate conversion. Additionally, we explore a Chinese character recognition network (CCRNet) to significantly recognize the class of each object from the original image;
- We propose a dynamic scheduling method of materials, in which the multi-crane is controlled by local PLCs that receive the commands from cloud PLC and sorts the chesses in specified position with minimum time;
- We establish an experimental platform of the multi-crane visual sorting system using cloud PLC in a 5G network for centralized control and low-latency. Furthermore, we collect the dataset and train the deep CNN-based model. The whole performance of the multi-crane visual sorting system is demonstrated by abundant experiments.
2. Materials and System
3. Methodology
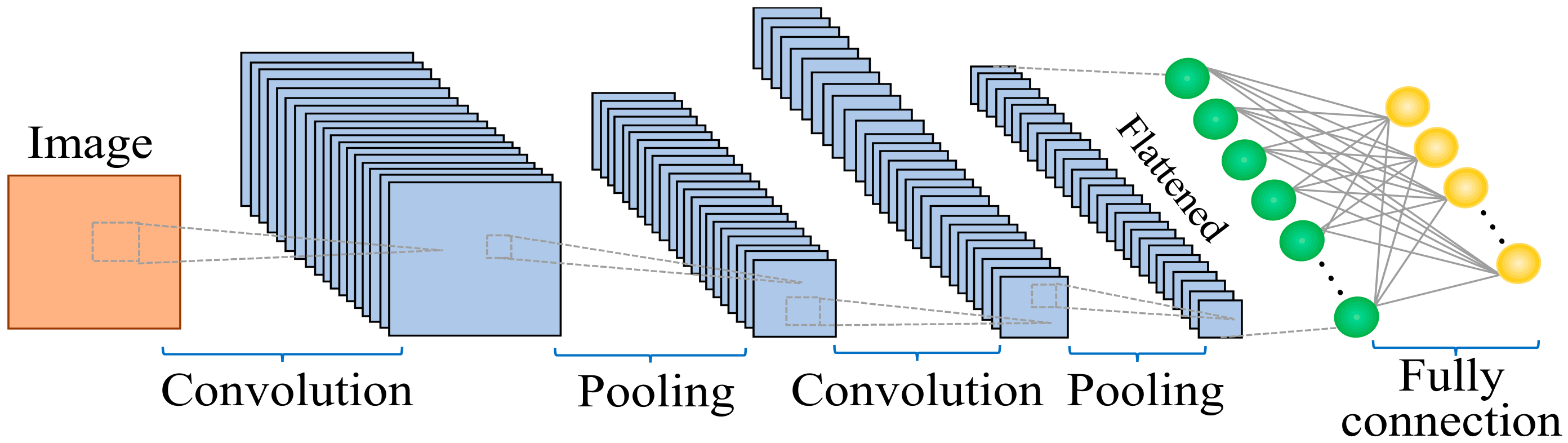
3.1. The Introduction of CNN
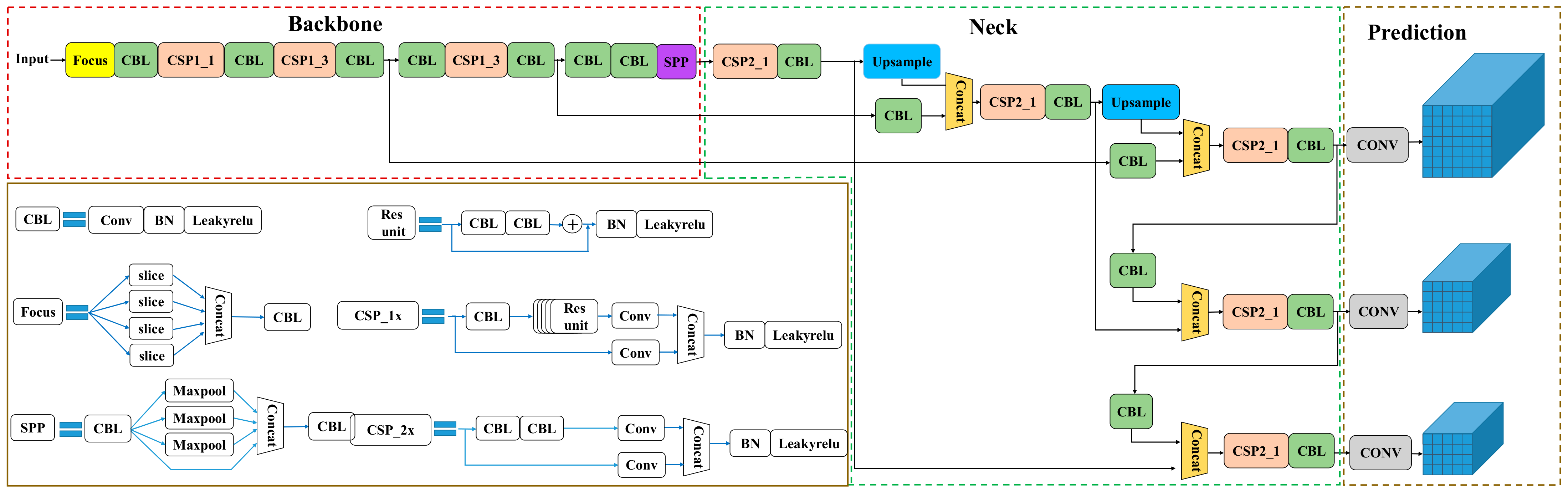
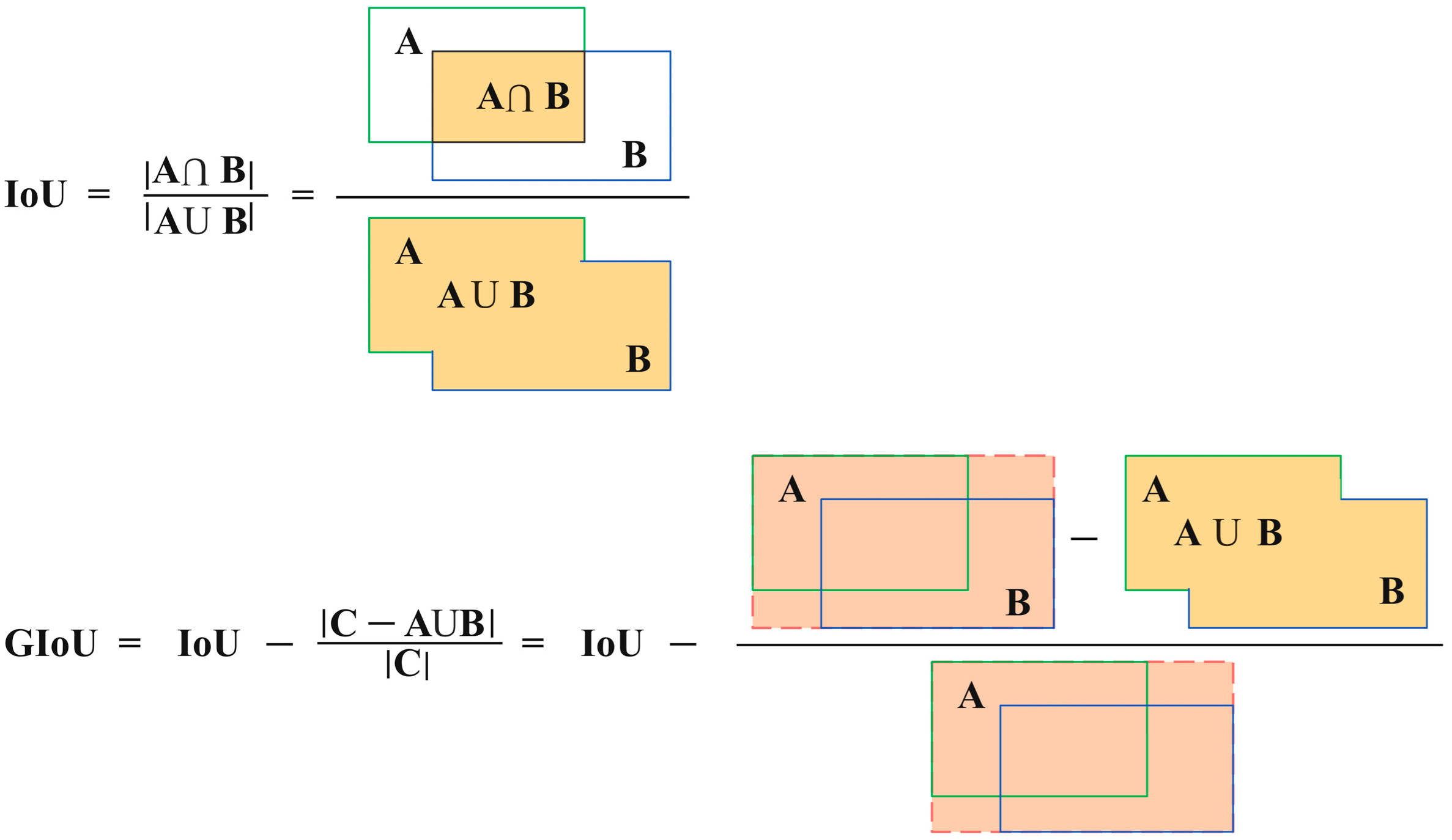
3.2. The Detection Module of Materials
3.3. The Recognition Module of Chinese Characters
3.4. The Control Module Using Dynamic Scheduling Method
| Algorithm 1. Scheduling strategy. |
| input: All cranes All materials Obj. |
| output: The relation between the crane and the object for sorting |
| Initialize multi-crane state |
| for each crane i do Record the initial time and the initial position of each crane |
| for each object do |
| Calculate the arrival time of the ith crane is the running time from the initial position to the object position on the x-axis. Record the crane position at . |
| Calculate the completion time of shipment is the time of shipment. Record the crane position at . |
| Calculate the time of delivery to the target place is the running time from the object position to the target position. Record the crane position at . Calculate . The process is the same with x-axis. |
| Calculate the whole time of the ith crane that transports the jth object: |
| Until all materials are calculated. We get a list T=. Sequence the element in T from small to large. We can get the object’s ID that the ith crane needs to transport. |
| Until all cranes are assigned with materials to be transported. |
4. Results
4.1. The Experimental Results of Detection Module Based on YOLOv5
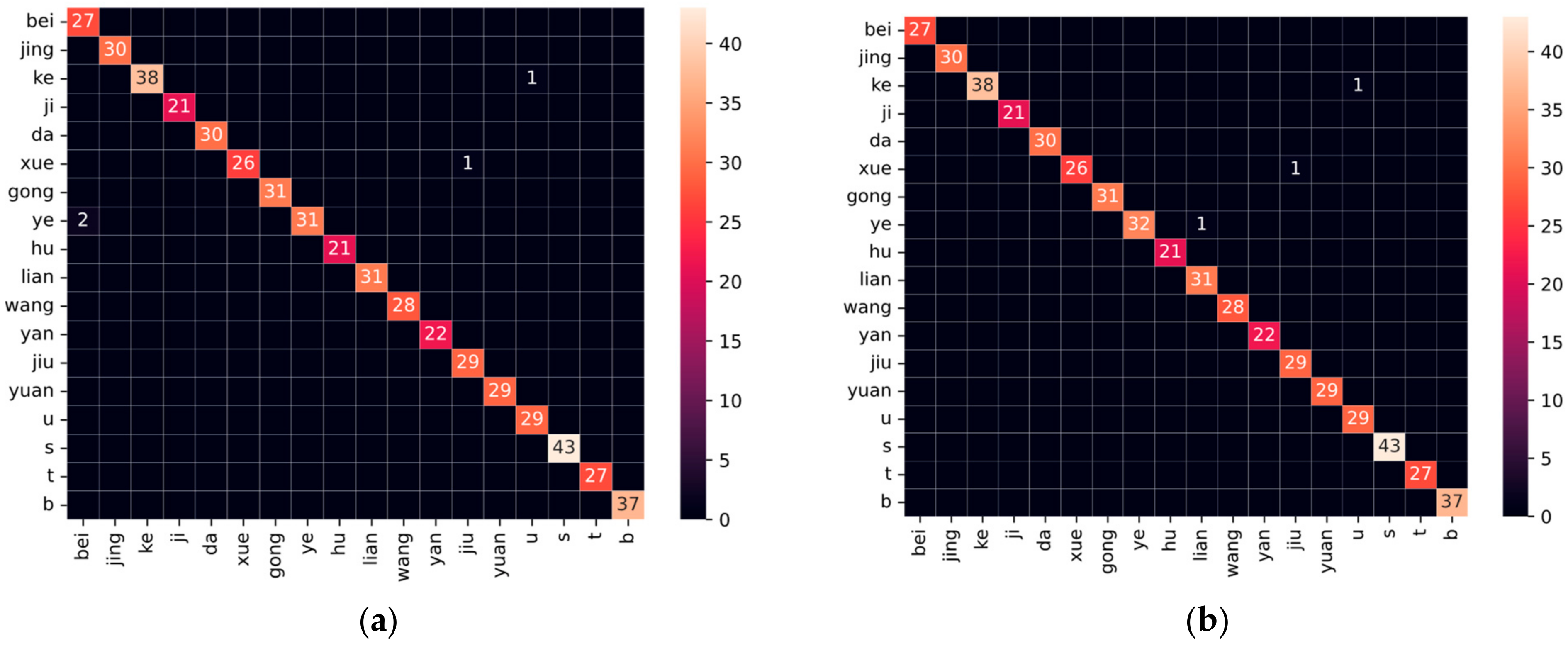
4.2. The Results of CCRNet on Chinese Characters
4.3. The Performance of the Visual Sorting System Using Dynamic Scheduling Method
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhong, R.Y.; Xu, X.; Klotz, E.; Stephen, T.N. Intelligent manufacturing in the context of industry 4.0: A review. Engineering 2017, 3, 616–630. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Zhang, J.; Zhong, R. Big data analytics for intelligent manufacturing systems: A review. J. Manuf. Syst. 2022, 62, 738–752. [Google Scholar] [CrossRef]
- Nain, G.; Pattanaik, K.K.; Sharma, G.K. Towards edge computing in intelligent manufacturing: Past, present and future. J. Manuf. Syst. 2022, 62, 588–611. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Niyato, D.; Dobre, O.; Vincen, P.H. 6G Internet of Things: A comprehensive survey. IEEE Internet Things J. 2022, 9, 359–383. [Google Scholar] [CrossRef]
- Zhang, C.; Lu, Y. Study on artificial intelligence: The state of the art and future prospects. J. Ind. Inf. Integr. 2021, 23, 100224. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 1–38. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, K.; Zou, J.; Peng, T.; Yang, H.Y. A CNN-based visual sorting system with cloud-edge computing for flexible manufacturing systems. IEEE Trans. Ind. Inform. 2019, 16, 4726–4735. [Google Scholar] [CrossRef]
- Han, S.; Liu, X.; Han, X.; Wang, G.; Wu, S.B. Visual sorting of express parcels based on multi-task deep learning. Sensors 2020, 20, 6785. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.W.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Shen, X.; Wu, Y.; Chen, S.; Luo, X. An intelligent garbage sorting system based on edge computing and visual understanding of social internet of vehicles. Mob. Inf. Syst. 2021, 2021, 5231092. [Google Scholar] [CrossRef]
- Song, Y.; Gao, L.; Li, X.; Shen, W. A novel robotic grasp detection method based on region proposal networks. Robot. Comput. -Integr. Manuf. 2020, 65, 101963. [Google Scholar] [CrossRef]
- Jocher, G.; Nishimura, K.; Mineeva, T. yolov5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 30 December 2022).
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Baldominos, A.; Saez, Y.; Isasi, P. A survey of handwritten character recognition with mnist and emnist. Appl. Sci. 2019, 9, 3169. [Google Scholar] [CrossRef]
- Melnyk, P.; You, Z.; Li, K. A high-performance CNN method for offline handwritten Chinese character recognition and visualization. Soft Comput. 2020, 24, 7977–7987. [Google Scholar] [CrossRef]
- Albahli, S.; Nawaz, M.; Javed, A.; Irtaza, A. An improved faster-RCNN model for handwritten character recognition. Arab. J. Sci. Eng. 2021, 46, 8509–8523. [Google Scholar] [CrossRef]
- Cao, Z.; Lu, J.; Cui, S.; Zhang, C. Zero-shot handwritten chinese character recognition with hierarchical decomposition embedding. Pattern Recognit. 2020, 107, 107488. [Google Scholar] [CrossRef]
- Xie, F.; Zhang, M.; Zhao, J.; Yang, J.; Liu, Y.; Yuan, X. A robust license plate detection and character recognition algorithm based on a combined feature extraction model and BPNN. J. Adv. Transp. 2018, 2018, 6737314. [Google Scholar] [CrossRef]
- Caldeira, T.; Ciarelli, P.M.; Neto, G.A. Industrial optical character recognition system in printing quality control of hot-rolled coils identification. J. Control. Autom. Electr. Syst. 2020, 31, 108–118. [Google Scholar] [CrossRef]
- Gang, S.; Fabrice, N.; Chung, D.; Lee, J. Character Recognition of Components Mounted on Printed Circuit Board Using Deep Learning. Sensors 2021, 21, 2921. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Biallas, S.; Brauer, J.; Kowalewski, S. Arcade.PLC: A verification platform for programmable logic controllers. In Proceedings of the 2012 27th IEEE/ACM International Conference on Automated Software Engineering, Essen, Germany, 3–7 September 2012; pp. 338–341. [Google Scholar]
- Park, S.C.; Park, C.M.; Wang, G.N. A PLC programming environment based on a virtual plant. Int. J. Adv. Manuf. Technol. 2008, 39, 1262–1270. [Google Scholar] [CrossRef]
- Park, S.C.; Chang, M. Hardware-in-the-loop simulation for a production system. Int. J. Prod. Res. 2012, 50, 2321–2330. [Google Scholar] [CrossRef]
- Goldschmidt, T.; Murugaiah, M.K.; Sonntag, C.; Schlich, B.; Biallas, S.; Weber, P. Cloud-based control: A multi-tenant, horizontally scalable soft-PLC. In Proceedings of the IEEE 2015 8th International Conference on Cloud Computing, New York City, NY, USA, 27 June–2 July 2015; pp. 909–916. [Google Scholar]
- Kalle, S.; Ameen, N.; Yoo, H.; Ahmed, I. CLIK on PLCs! Attacking control logic with decompilation and virtual PLC. In Proceedings of the Binary Analysis Research Workshop, Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Zhu, Z.Y.; Liu, R.Y. Design of speed reducer testbed based on cloud platform. In Proceedings of the IEEE 2021 5th Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, China, 12–14 March 2021; pp. 53–57. [Google Scholar]
- Ren, H.; Wang, K.; Pan, C. Intelligent reflecting surface-aided URLLC in a factory automation scenario. IEEE Trans. Commun. 2021, 70, 707–723. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Cham, Switzerland; 2016; pp. 198–213. [Google Scholar]
- Kim, Y.; Lee, Y.; Jeon, M. Imbalanced image classification with complement cross entropy. Pattern Recognit. Lett. 2021, 151, 33–40. [Google Scholar] [CrossRef]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the IEEE/ACM 2018 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | ResNet18 | ResNet34 | ResNet50 |
|---|---|---|---|
| Conv1 | (7, 7), 64, stride 2 | ||
| Conv2_x | (3, 3), max pooling, stride 2 | ||
| Conv3_x | |||
| Conv4_x | |||
| Conv5_x | |||
| Average pooling | |||
| Fully connected layer | |||
| Model | Dataset | Number | Precision | Recall Rate | mAP |
|---|---|---|---|---|---|
| YOLOv5 | Training set | 568 | 99.60% | 99.46% | 99.44% |
| Testing set | 79 | 98.49% | 98.81% | 98.85% | |
| Validating set | 142 | 96.55% | 95.40% | 97.80% |
| Model | Dataset | Number | Accuracy |
|---|---|---|---|
| CCRNet_ResNet18 | Training set | 4799 | 99.50% |
| Testing set | 534 | 99.25% | |
| CCRNet_ResNet34 | Training set | 4799 | 99.49% |
| Testing set | 534 | 99.43% | |
| CCRNet_ResNet50 | Training set | 4799 | 99.42% |
| Testing set | 534 | 99.25% |
| Model | Chinese Character Accuracy | English Letter Accuracy |
|---|---|---|
| CCRNet_ResNet18 | 98.99% | 100% |
| CCRNet_ResNet34 | 99.25% | 100% |
| CCRNet_ResNet50 | 98.99% | 100% |
| Time | Prediction Time (s) | Real Time (s) | |
|---|---|---|---|
| 1 | [(1, 2.972), (2, 3.282), (3, 3.301), (4, 3.616)] | 2.756 | 0.216 |
| 2 | [(1, 2.804), (2, 3.179), (3, 3.237), (4, 3.648)] | 3.016 | 0.212 |
| 3 | [(1, 3.146), (2, 3.160), (3, 3.179), (4, 3.398)] | 3.056 | 0.090 |
| 4 | [(1, 2.958), (2, 3.037), (3, 3.055), (4, 3.370)] | 3.064 | 0.106 |
| 5 | [(1, 2.838), (2, 3.179), (3, 3.237), (4, 3.648)] | 3.036 | 0.198 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, M.; Wang, Q.; Wang, J.; Sun, L.; Ma, Z.; Zhang, C.; Guan, W.; Liu, Q.; Wang, D.; Li, W. Deep CNN-Based Materials Location and Recognition for Industrial Multi-Crane Visual Sorting System in 5G Network. Appl. Sci. 2023, 13, 1066. https://doi.org/10.3390/app13021066
Fu M, Wang Q, Wang J, Sun L, Ma Z, Zhang C, Guan W, Liu Q, Wang D, Li W. Deep CNN-Based Materials Location and Recognition for Industrial Multi-Crane Visual Sorting System in 5G Network. Applied Sciences. 2023; 13(2):1066. https://doi.org/10.3390/app13021066
Chicago/Turabian StyleFu, Meixia, Qu Wang, Jianquan Wang, Lei Sun, Zhangchao Ma, Chaoyi Zhang, Wanqing Guan, Qiang Liu, Danshi Wang, and Wei Li. 2023. "Deep CNN-Based Materials Location and Recognition for Industrial Multi-Crane Visual Sorting System in 5G Network" Applied Sciences 13, no. 2: 1066. https://doi.org/10.3390/app13021066
APA StyleFu, M., Wang, Q., Wang, J., Sun, L., Ma, Z., Zhang, C., Guan, W., Liu, Q., Wang, D., & Li, W. (2023). Deep CNN-Based Materials Location and Recognition for Industrial Multi-Crane Visual Sorting System in 5G Network. Applied Sciences, 13(2), 1066. https://doi.org/10.3390/app13021066