The Design of a Video Reflection Removal Method Based on Illumination Compensation and Image Completion Fusion


Abstract
:1. Introduction
- (1)
- We propose a video reflection removal method based on the combination of image complementation and illumination compensation, which has a 5.2% higher reflection region removal accuracy and operation speed than without adding illumination compensation.
- (2)
- We propose an illumination compensation mechanism based on a combination of luminance adjustment and gamma correction for reflective region extraction by joint MSER region matching.
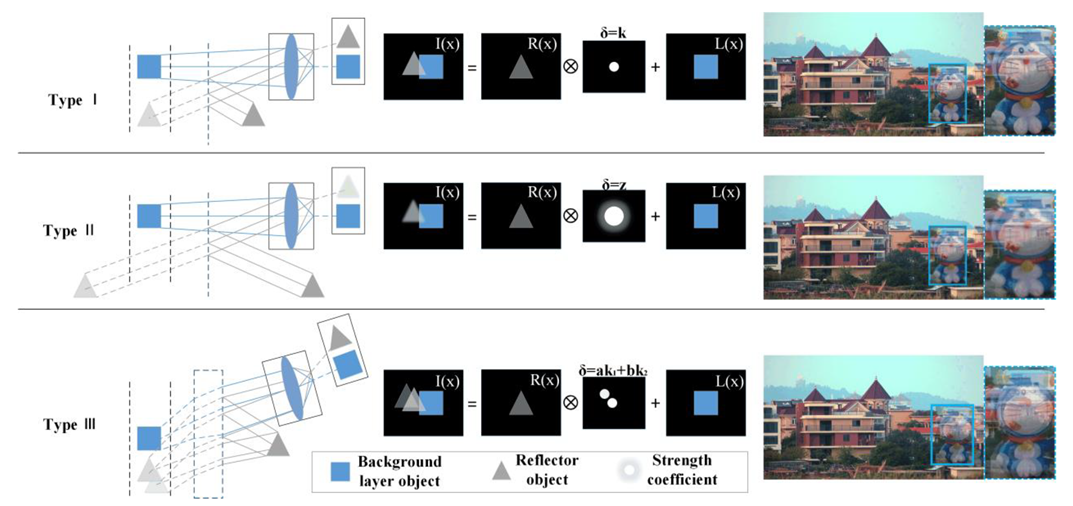
2. Related Works
3. Method
3.1. Light Compensation
3.1.1. Image Gradient Metric
3.1.2. An Illumination Compensation Mechanism Based on Luminance Adjustment and Gamma Correction
3.2. Target Area Extraction
3.3. Reflection Removal
3.3.1. Reflective Region Removal Method Based on Image Complementation
3.3.2. A Reflective Region Removal Method Based on the Combination of Improved Image Complementation and Illumination Compensation
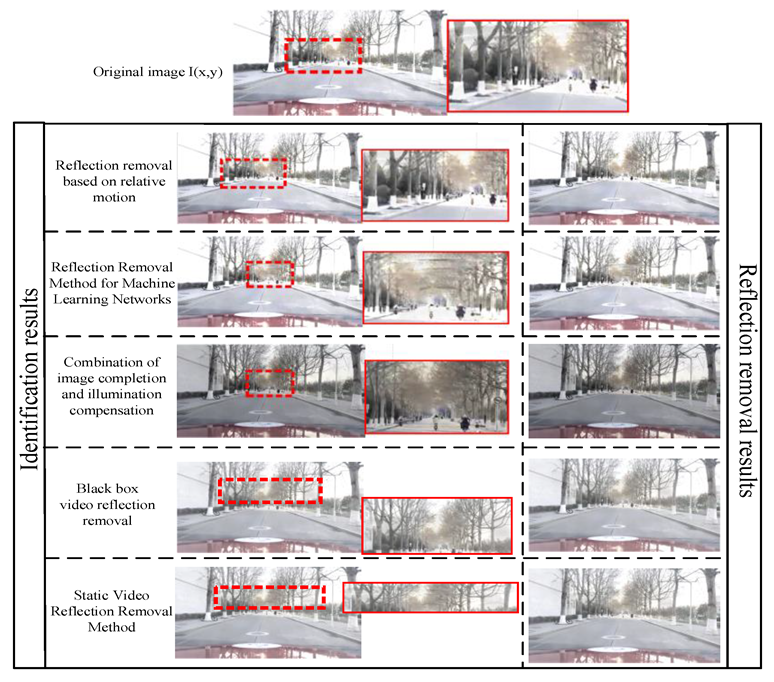
4. Experiments
4.1. Experimental Setup
4.2. Comparison with Advanced Technology
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, J. Single Image Reflection Removal with Camera Calibration. Master’s Thesis, Nanyang Technological University, Singapore, 2021; pp. 1–62. [Google Scholar]
- Levin, A.; Weiss, Y. User assisted separation of reflections from a single image using a sparsity prior. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1647–1654. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Brown, M.S. Single image layer separation using relative smoothness. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2752–2759. [Google Scholar]
- Zhang, Y.N.; Shen, L.; Li, Q. Content and Gradient Model-driven Deep Network for Single Image Reflection Removal. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2021; pp. 6802–6812. [Google Scholar]
- Zheng, Q.; Qiao, X.; Cao, Y.; Guo, S.; Zhang, L.; Lau, R.W. Distilling Reflection Dynamics for Single-Image Reflection Removal. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 11–17 October 2021; pp. 1886–1894. [Google Scholar]
- Han, B.J.; Sim, J.Y. Single image reflection removal using non-linearly synthesized glass images and semantic context. IEEE Access. 2019, 7, 170796–170806. [Google Scholar] [CrossRef]
- Li, T.; Lun, D.P.K. Single-image reflection removal via a two-stage background recovery process. IEEE Signal Process. Lett. 2019, 26, 1237–1241. [Google Scholar] [CrossRef]
- Chi, Z.; Wu, X.; Shu, X.; Gu, J. Single image reflection removal using deep encoder-decoder network. arXiv 2018, arXiv:1802.00094. [Google Scholar]
- Li, Y.; Liu, M.; Yi, Y.; Li, Q.; Ren, D.; Zuo, W. Two-Stage Single Image Reflection Removal with Reflection-Aware Guidance. arXiv 2020, arXiv:2012.00945. [Google Scholar] [CrossRef]
- Chang, Y.C.; Lu, C.N.; Cheng, C.C.; Chiu, W.C. Single image reflection removal with edge guidance, reflection classifier, and recurrent decomposition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 2033–2042. [Google Scholar]
- Fan, Q.; Yang, J.; Hua, G.; Chen, B.; Wipf, D. A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, J.; Gong, D.; Liu, L.; Shi, Q. Seeing deeply and bidirectionally: A deep learning approach for single image reflection removal. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 654–669. [Google Scholar]
- Li, C.; Yang, Y.; He, K.; Lin, S.; Hopcroft, J.E. Single image reflection removal through cascaded refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3565–3574. [Google Scholar]
- Wen, Q.; Tan, Y.; Qin, J.; Liu, W.; Han, G.; He, S. Single image reflection removal beyond linearity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3771–3779. [Google Scholar]
- Ren, W. Low-Light Image Enhancement via a Deep Hybrid Network. IEEE Trans. Image Process. 2019, 28, 4364–4375. [Google Scholar] [CrossRef] [PubMed]
- Aizu, T.; Matsuoka, R. Reflection Removal Using Multiple Polarized Images with Different Exposure Times. In Proceedings of the 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 498–502. [Google Scholar]
- Szeliski, R.; Avidan, S.; Anandan, P. Layer extraction from multiple images containing reflections and transparency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2000, Hilton Head, SC, USA, 15 June 2000; Volume 1, pp. 246–253. [Google Scholar]
- Li, Y.; Brown, M.S. Exploiting reflection change for automatic reflection removal. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2432–2439. [Google Scholar]
- Sun, C.; Liu, S.; Yang, T.; Zeng, B.; Wang, Z.; Liu, G. Automatic reflection removal using gradient intensity and motion cues. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 466–470. [Google Scholar]
- Bonekamp, J. Multi-Image Optimization Based Specular Reflection Removal from Non-Dielectric Surfaces. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2021. [Google Scholar]
- Wan, R.; Shi, B.; Duan, L.Y.; Tan, A.H. Crrn: Multi-scale guided concurrent reflection removal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4777–4785. [Google Scholar]
- Xue, T.; Rubinstein, M.; Liu, C.; Freeman, W.T. A computational approach for obstruction-free photography. ACM Trans. Graph 2015, 34, 1–11. [Google Scholar]
- Cheong, J.Y.; Simon, C.; Kim, C.-S.; Park, I.K. Reflection removal under fast forward camera motion. IEEE Trans. 2017, 26, 6061–6073. [Google Scholar] [CrossRef] [PubMed]
- Iwata, S.; Ogata, K.; Sakaino, S.; Tsuji, T. Specular reflection removal with high-speed camera for video imaging. In Proceedings of the IECON 2015—41st Annual Conference of the IEEE Industrial Electronics Society, Yokohama, Japan, 9–12 November 2015; pp. 001735–001740. [Google Scholar]
- Alayrac, J.B.; Carreira, J.; Zisserman, A. The visual centrifuge: Model-free layered video representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2457–2466. [Google Scholar]
- Li, T.; Lun, D.P.K. A novel reflection removal algorithm using the light field camera. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Lei, C.; Chen, Q. Robust reflection removal with reflection-free flash-only cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14811–14820. [Google Scholar]
- Li, T.; Lun, D.P.K.; Chan, Y.H. Robust reflection removal based on light field imaging. IEEE Trans. Image Process. 2018, 28, 1798–1812. [Google Scholar] [CrossRef] [PubMed]
- Punnappurath, A.; Brown, M.S. Reflection removal using a dual-pixel sensor. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 5–9 June 2019; pp. 1556–1565. [Google Scholar]
- Hong, Y.; Lyu, Y.; Li, S.; Shi, B. Near-infrared image guided reflection removal. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Sheridan, K.; Puranik, T.G.; Mangortey, E.; Pinon, O.J.; Kirby, M.; Mavris, D. An Application of DBSCAN Clustering for Flight Anomaly Detection during the Approach Phase. In Proceedings of the AIAA SciTech Forum, Orlando, FL, USA, 6–10 January 2020; p. 1851. [Google Scholar]
- Jiang, G.; Xu, Y.; Gong, X.; Gao, S.; Sang, X.; Zhu, R.; Wang, L.; Wang, Y.J.J.o.R. An Obstacle Detection and Distance Measurement Method for Sloped Roads Based on VIDAR. J. Robot. 2022, 2022, 5264347. [Google Scholar] [CrossRef]
- Nandoriya, A.; Elgharib, M.; Kim, C.; Hefeeda, M.; Matusik, W. Video reflection removal through spatio-temporal optimization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2411–2419. [Google Scholar]
- Simon, C.; Kyu Park, I. Reflection removal for in-vehicle black box videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4231–4239. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Detection Time/s | Identification Time/s |
|---|---|---|
| Reflection removal based on relative motion compensation | 2.498 | 3.246 |
| Reflection Removal Method for Machine Learning Networks | 2.452 | 2.783 |
| Combination of image completion and illumination | 2.632 | 2.674 |
| Static Video Reflection Removal Method [33] | 2.744 | 2.863 |
| Black box video reflection removal [34] | 2.531 | 2.700 |
| Judgment Basis | Black Box Video Reflection Removal | Static Video Reflection Removal Method | Combination of Image Completion and Illumination Compensation | Reflection Removal Method for Machine Learning Networks | Reflection Removal based on Relative Motion | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Reflection area | Have | None | Have | None | Have | None | Have | None | Have | None | |
| 2126 | 192 () | 2133 | 185 () | 2254 | 64 () | 2218 | 100 () | 2201 | 117 () | ||
| Whether the number of pixels exceeds the threshold | Yes | 2036 ) | 89 | 2048 () | 78 | 2208 () | 23 | 2173 () | 36 | 2123 () | 49 |
| No | 90 () | 103 () | 85 () | 107 () | 46 () | 41 () | 54 () | 55 () | 64 () | 82 () | |
| Check the accuracy | DT | 0.917 | 0.920 | 0.972 | 0.933 | 0.914 | |||||
| RT | 0.956 | 0.954 | 0.982 | 0.976 | 0.965 | ||||||
| NCC | Reflector | 0.89236 | 0.86982 | 0.91563 | 0.90642 | 0.88959 | |||||
| Background layer | 0.86624 | 0.87431 | 0.90875 | 0.90433 | 0.89746 | ||||||
| Sequence | Illuminated | No Light | |||
|---|---|---|---|---|---|
| Method | Reflector | Background Layer | Reflector | Background Layer | |
| Camera calibration removes single image reflections [1] | 0.89873 | 0.90165 | 0.88746 | 0.89647 | |
| Deep single image reflection removal driven by content and a gradient model [4] | 0.87652 | 0.86528 | 0.86773 | 0.85631 | |
| A combination of image completion and illumination | 0.91563 | 0.90875 | 0.90897 | 0.89745 | |
| Static Video Reflection Removal Method [33] | 0.86982 | 0.87431 | 0.86232 | 0.86968 | |
| Black box video reflection removal [34] | 0.89236 | 0.86624 | 0.88746 | 0.86364 | |
| Removing reflections from multiple polarized images with different exposure times [16] | 0.90365 | 0.90369 | 0.89541 | 0.89796 | |
| An edge-guided removal of single image reflections [10] | 0.89677 | 0.90623 | 0.88965 | 0.88943 | |
| The removal of specular reflection from non-dielectric surfaces based on multi-image optimization [20] | 0.88972 | 0.89748 | 0.87644 | 0.89656 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, S.; Xu, Y.; Kong, X.; Shi, S.; Ni, J. The Design of a Video Reflection Removal Method Based on Illumination Compensation and Image Completion Fusion. Appl. Sci. 2023, 13, 10913. https://doi.org/10.3390/app131910913
Ding S, Xu Y, Kong X, Shi S, Ni J. The Design of a Video Reflection Removal Method Based on Illumination Compensation and Image Completion Fusion. Applied Sciences. 2023; 13(19):10913. https://doi.org/10.3390/app131910913
Chicago/Turabian StyleDing, Shaohong, Yi Xu, Xiangcun Kong, Shuyue Shi, and Juan Ni. 2023. "The Design of a Video Reflection Removal Method Based on Illumination Compensation and Image Completion Fusion" Applied Sciences 13, no. 19: 10913. https://doi.org/10.3390/app131910913
APA StyleDing, S., Xu, Y., Kong, X., Shi, S., & Ni, J. (2023). The Design of a Video Reflection Removal Method Based on Illumination Compensation and Image Completion Fusion. Applied Sciences, 13(19), 10913. https://doi.org/10.3390/app131910913