Abstract
Transit Signal Priority (TSP) is a system designed to grant right-of-way to buses, yet it can lead to delays for private vehicles. With the rapid advancement of network technology, self-driving buses have the capability to efficiently acquire road information and optimize the coordination between vehicle arrival and signal timing. However, the complexity of arterial intersections poses challenges for conventional algorithms and models in adapting to real-time signal priority. In this paper, a novel real-time signal-priority optimization method is proposed for self-driving buses based on the CACC model and the powerful deep Q-network (DQN) algorithm. The proposed method leverages the DQN algorithm to facilitate rapid data collection, analysis, and feedback in self-driving scenarios. Based on the arrival states of both the bus and private vehicles, appropriate actions are chosen to adjust the current-phase green time or switch to the next phase while calculating the duration of the green light. In order to optimize traffic balance, the reward function incorporates an equalization reward term. Through simulation analysis using the SUMO framework with self-driving buses in Zhengzhou, the results demonstrate that the DQN-controlled self-driving TSP optimization method reduces intersection delay by 27.77% and 30.55% compared to scenarios without TSP and with traditional active transit signal priority (ATSP), respectively. Furthermore, the queue length is reduced by 33.41% and 38.21% compared to scenarios without TSP and with traditional ATSP, respectively. These findings highlight the superior control effectiveness of the proposed method, particularly during peak hours and in high-traffic volume scenarios.
1. Introduction
Transit priority is typically reflected through two methods: dedicated bus lanes [1] and transit signal priority (TSP). Intelligent traffic technology has increasingly been utilized for TSP. Previous studies employed automatic vehicle location (AVL) systems to determine the bus’s position and calculate its headway, fulfilling the requirements of TSP [2]. Currently, advanced self-driving technology has been implemented in public transportation. As illustrated in Figure 1, the vehicle’s on-board unit (OBU) equipped with wireless communication technology (Vehicle to Everything, V2X) obtains real-time vehicle position and movement data at intersections. This capability enables the self-driving bus to dynamically exchange information with the road infrastructure and other vehicles, base stations, and signal lights in the vicinity. By employing holographic environmental perception [3] and real-time road-traffic data acquisition [4], the system can effectively optimize signal timing.
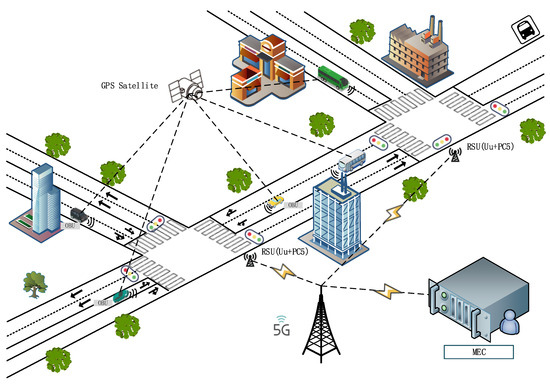
Figure 1.
Vehicle information architecture diagram at intersection.
TSP encompasses three types: passive priority, active priority, and real-time priority. The approaches used for optimizing passive priority and active priority are not well-suited for TSP at arterial intersections [5]. Previous studies on active TSP at arterial intersections predominantly focused on achieving maximum “green wave” and minimizing delay [6]. Conflict between the arterial coordination signal control system and the TSP control system is common [7]. The arterial coordination TSP cannot ensure the continuous normal operation of the original green wave belt, leading to potential delays and TSP failures. Utilizing the bus pre-signal method and queuing theory, the model is solved to minimize delays throughout the entire arterial line [8]. Ma et al. [9] investigated signalized intersection groups in two bus stations and reduced bus delays using a proposed linear programming model. However, in arterial coordinated TSP, the delay at the upstream intersection may decrease the delay of the priority phase due to the downstream red light causing new delays. To minimize vehicle delays in coordinated arterial TSP, other studies have proposed mathematical models targeting bus schedules [10], bus headway [2], and bus priority [11]. The original ATSP factors are bus stops [12], pedestrians [13], and buses [14]. This paper, based on research of the original adaptive transit signal priority, has added the consideration of private vehicles, with the aim of reducing private vehicle delays caused by transit signal priority.
The ATSP method based on the conventional mathematical model cannot ensure real-time calculation performance. In this study, real-time priority is considered to be the optimization objective for TSP, thus satisfying TSP based on arterial coordination and reducing delays for private vehicles. Ling et al. [15] proposed TSP using reinforcement learning and developed a reinforcement learning (RL) agent responsible for determining the optimal duration of each signal phase, reverting to the original phase when the bus passes. ATSP is a complex issue necessitating consideration of various dynamic factors. These factors encompass the routes taken, velocity, traffic conditions, and other variables relevant to buses and other vehicles. Given the continuous variability in these elements, it is imperative that algorithms exhibit swift adaptability and robust learning capabilities. The DQN algorithm, as employed here, excels at the task due to its capacity to iteratively adjust neural network parameters through interactions with the environment. This adaptative learning process allows the algorithm to acquire an optimal strategy for resolving the ATSP. Furthermore, DQN integrates techniques like experience replay, facilitating the storage of prior experiences and associated rewards to update the target Q-value. Consequently, this technology bolsters the algorithm’s stability, diminishes sensitivity to environmental and contextual changes, and ultimately augments the algorithm’s efficiency and practicality. Thus, utilizing the DQN algorithm to investigate the prioritization of adaptive autonomous driving bus signals holds significant promise and numerous advantages.
The remainder of this paper is structured as follows. Section 2 introduces the application of deep reinforcement learning in adaptive signal timing Section 3 begins by introducing the fundamental assumptions of real-time signal priority for self-driving bus lines. Subsequently, a detailed presentation of the DQN algorithm model, designed to control real-time signal priority in self-driving-bus lines, is provided. Section 4 provides an overview of the research site in this study and outlines the parameters employed in the DQN algorithm. In Section 5, the training process and test results of real-time signal prioritization for self-driving-bus arterial lines are presented. The test results include a comparison of real-time signal priority with no-priority and active-priority scenarios, followed by a supplementary discussion. Finally, Section 6 presents the conclusions.
2. Literature Review
The DQN algorithm has been extensively utilized in intersection signal control. In an isolated intersection, Wan et al. [16] defined states and actions using discretization grids and employed cumulative waiting time as a reward for training the DQN model to control agents. This method can dynamically adjust the signal-light switching time based on traffic conditions, aiming to reduce vehicle waiting time and alleviate traffic congestion. Subsequently, Zhang [17] and Xu [18] made further improvements in obtaining real-time traffic information. Zhang [17] employed dedicated short-range communications (DSRC), while Xu [18] used discretization states to define the respective states of vehicles. Tan [19] and Kumar [20] adopted a comprehensive approach to achieve more effective traffic control by defining states based on sensor acquisition and a discretization grid, respectively. Both studies employed the DQN model for training, with actions to either maintain the current signal phase or switch to the next phase. In defining rewards, Tan [19] utilizes the inverse of the product of the output and trade-off coefficient in the lane, as well as the cumulative queue length. On the other hand, Kumar [20] integrates vehicle waiting time, vehicle speed, number of vehicles, vehicle delay, and queue length to create a reward function. These methods can dynamically adjust the signal-light switching time based on traffic conditions, leading to more effective traffic control.
Previous studies on arterial intersections have proposed a method to output appropriate phases based on the traffic-flow state in all directions at the intersection and dynamically adjust the phase length [21]. Li [22] employed the DQN model to predict local state information, including vehicle position, speed, intersection signal phase, and residual signal phase. However, the study did not explore methods to enhance the model’s generalization ability and robustness. Tan [23] proposed a method based on sub-region joint training to enhance the model’s generalization ability and robustness. This approach employed the DQN model to predict queue length and current actions. Experimental results indicate that the sub-region joint training method significantly improves the prediction accuracy of the DQN model. Moreover, joint training of multiple sub-regions through the encoder further enhances the model’s generalization ability. Xie [24] introduced a method for implementing communication based on neural network sharing of information. This approach utilized the DQN model to predict local state information, including waiting time and the number of vehicles. While this method effectively improves prediction accuracy, the collaborative training approach of sharing parameters among agents may cause model instability and performance degradation. Notably, DQN has demonstrated promising results in the study of ATSP, effectively reducing the cumulative delay at intersections [25,26].
The primary focus of this paper is to explore the application of deep reinforcement learning in addressing the real-time signal-priority problem faced by self-driving-bus arterial lines. The central objective, based on the CACC model, is to reduce the average queue length and minimize delays. To facilitate coordination between agents [27] and mitigate learning challenges for the agents [28], the DQN algorithm is employed to devise a real-time signal-priority control method for self-driving-bus arterial lines. To enhance the algorithm’s efficiency, a simplified state, encompassing vehicle and signal light information, is chosen as the input for the agent. In order to identify the most relevant factors that align with the agent’s learning objectives and ensure efficient traffic flow control at intersections, reward and penalty functions are defined, encompassing delay penalty, queue length penalty, and equalization reward. These functions regulate vehicles’ passage through intersections by modifying signal-light timings.
This paper seeks to devise a novel coordinated control methodology for mitigating right-of-way conflicts between self-driving buses and private vehicles. The proposed approach leverages deep Q-network (DQN) techniques to enable real-time prioritization of self-driving-bus signals. This is accomplished through the creation of a collaborative environmental model and the formulation of multi-objective reward and penalty functions. The primary contributions can be summarized as follows:
- In contrast to previous studies on ATSP, this study develops an ATSP model incorporating private vehicles. By optimizing the coordination between private vehicles and self-driving buses under varying traffic flow conditions, integrated control of buses and traffic signals is accomplished.
- A reward and punishment function was designed that considers both buses and private vehicles. This function balances the interests of all parties by punishing delays, queuing, and rewarding balance.
- A DQN algorithm was applied to achieve real-time priority control of bus signals. This method can adjust signal lights in real time based on traffic status, achieving intelligent collaborative control of self-driving buses.
3. Problem Formulation and Modeling
3.1. Problem Description
In scenarios where public transport and private vehicles coexist on the same road sections, the control strategy must account for the efficiency of public transport vehicles and their impact on private vehicles, with the goal of improving overall traffic efficiency. The control strategy will generate a sequence of control actions within the action space, using information from the current-state space. Additionally, it will evaluate whether the current decisions can optimize overall traffic efficiency by employing reward and punishment functions, allowing for adjustments in subsequent decisions.
Studies have adopted the compulsory TSP strategy. In the control strategy for private vehicles, additional rewards and punishments will be introduced, including measures to avoid disruptions to private vehicles and reduce road congestion. This ensures that the priority given to buses does not compromise the overall road network’s performance. Level 4 self-driving has been achieved in laboratory settings [29]. Buses and private vehicles on the road are equipped with CACC technology. Considering the above factors, the following assumptions were formulated:
- It is assumed that buses and private vehicles on the road are equipped with CACC.
- The PATH laboratory proposed the following CACC model [30] after verifying it through small-scale platooning experiments. Consequently, real-time information, such as vehicle speed, vehicle position, vehicle class, vehicle arrival time, and the length and signal time of the private vehicle, can be obtained.
- The buses and the traffic lights are equipped with communication capabilities, enabling them to exchange information with each other.
- The primary control objective of the traffic lights is to minimize the waiting time for private vehicles while ensuring traffic safety and flow.
Based on these fundamental assumptions, the goal of real-time signal-priority control for self-driving-bus arterial lines is to minimize the waiting time for private vehicles by effectively controlling the traffic lights when the bus approaches intersections. This, in turn, enhances the overall efficiency of private vehicles. Specifically, by continuously monitoring and analyzing the state of the bus, the system determines the optimal signal light and green-light durations, allowing the bus to pass through the intersection promptly. This optimization improves the bus’s operating efficiency and reduces the waiting time for private vehicles. Importantly, this approach prioritizes traffic safety and considers the interests of all participants, ensuring a smooth and safe flow of traffic.
3.2. Modeling
Figure 2 shows the complete workflow of the system. The control strategy for the model is structured in the following steps:
- State acquisition: Buses dynamically gather essential information about the road section and intersection using onboard sensors and communication devices. The acquired data includes speed, position, rank, arrival time, lane occupancy, traffic light status, and duration.
- State update: Buses continuously update their own state based on the acquired status information and calculate their current state value .
- Action selection: Buses select the optimal action based on their current state by combining reinforcement-learning algorithms, which involves controlling the maximum and minimum green time of the traffic light to minimize waiting time and reduce energy consumption.
- Action execution: Buses execute the selected action , which involves sending the maximum green time and minimum green time control signals to the traffic control center for scheduling, and continuously updating the state based on the new status information.
- Reward feedback: Based on the action executed by the bus and its current state , the corresponding reward is calculated and fed back to the reinforcement-learning algorithm to update the value function.
- Policy update: Based on the reward , the reinforcement-learning algorithm updates the policy to gradually converge on the optimal action, thereby achieving the control goals of minimizing waiting time and reducing energy consumption.
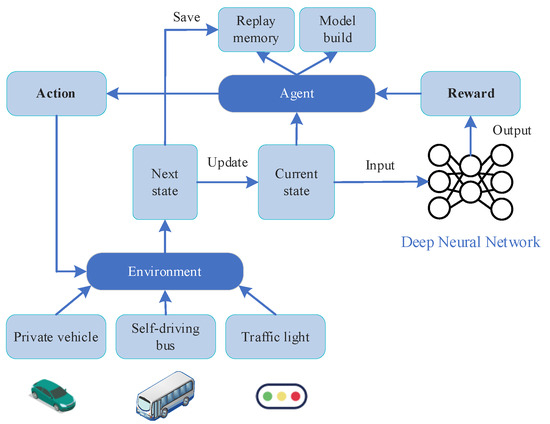
Figure 2.
DQN model training flowchart.
3.2.1. State
Status refers to the current conditions of the self-driving bus, surrounding private vehicles, and signal lights. The state encompasses several aspects, including the following: the status of the autonomous bus, which includes parameters such as vehicle speed, acceleration, and direction; the status of private vehicles, encompassing vehicle type, position, and speed; and the status of signal lights, involving the remaining time of the current phase.
At a given moment , the state of the intersection is represented by , which comprises information such as the number of vehicles in the current lane and the speed of incoming vehicles. This state can be expressed as a vector with elements, where the first element denotes the number of vehicles in the current lane, and the latter element denotes the speed of the incoming vehicle. The state space is composed of the set of all possible states at any given time .
The state space, where real-time signal priority is adjusted based on the vehicle arrival rate, can be represented as a vector comprising elements:
where represents the number of vehicles in the current lane; is the vehicle arrival rate at time .
The adjustment of traffic-light duration based on the vehicle arrival rate is mathematically expressed by Formulas (2) and (3):
where is the traffic-flow response coefficient of the intersection ; represents the target traffic volume.; is the time duration of traffic lights at the intersection .
3.2.2. Actor
The action space is defined as the set of operations involved in adjusting the duration of traffic lights. Each action is considered as a vector, encompassing the duration of traffic lights at each intersection. However, for effective traffic management and to prioritize buses without causing traffic congestion, it is essential to dynamically adjust the action space based on the vehicle arrival rate. Consequently, the action space is expanded to encompass dynamic adjustments of traffic light durations according to varying traffic conditions, enabling more efficient traffic flow control and optimized bus transit times.
In the real-time signal-priority control of self-driving-bus arterial lines, the agent must select an appropriate action based on the current state, specifically adjusting the traffic light state at the present moment. Hence, the action space can be represented as a set comprising multiple elements, with each element corresponding to a traffic light state that the agent can choose as the current one. For the real-time signal-priority control task of self-driving buses, the action space is defined as follows: for each lane of each intersection, there is a set of minimum green time and maximum green time that can be applied. Here, represents the intersection number. Therefore, the size of the action space is determined as , where represents the number of intersections. The pseudocode for the action space is presented in Table 1.

Table 1.
Pseudocode of action space.
To provide a more comprehensive illustration of the issue, the action space for adjusting the signal duration based on traffic flow conditions can be represented as a vector containing intersections, where each element represents the traffic light duration of the -th intersection. At each time , the duration of the traffic light at intersection can be dynamically adjusted in response to the current traffic flow:
where is the maximum duration of traffic lights at the -th intersection; is the minimum duration of traffic lights at the -th intersection; is the action in the action space:
where represents the value of state at time ; represents the value of state at time .
The state can be represented as a vector containing elements, consistent with the state space. The first elements represent the number of vehicles in the current lane, while the last elements represent the speed of incoming vehicles.
3.2.3. Reward
Reward and punishment functions play a critical role in reinforcement-learning algorithms by assessing whether an agent’s behavior aligns with expectations and providing feedback. In the real-time signal-priority control of self-driving-bus lines, the reward and punishment function primarily consists of three components: delay penalty, queue-length penalty, and equalization reward.
- Delay penalty item. In a transportation network, a delay penalty term pertains to the penalty that a vehicle incurs when it takes longer than its expected arrival time to reach its destination, and the penalty is proportional to the duration of the vehicle’s delay. The purpose of this reward function is to incentivize the vehicle to reach the target location expeditiously, reduce the vehicle’s travel time, and enhance traffic efficiency. When the vehicle waits in front of the signal light, a specific delay penalty is incurred:
- 2.
- Queue-length penalty item. In the traffic network, the queue-length penalty refers to a penalty imposed on a vehicle when it waits for the red signal at a traffic light for an extended duration, and the penalty is proportionate to the waiting time. This reward function aims to decrease vehicle waiting times at traffic lights, minimize queuing periods, and subsequently alleviate traffic congestion. When a vehicle waits in front of a signal light, it leads to the formation of a queue of a certain length:
- 3.
- Balance reward items. In a traffic network, the equalization-reward term involves assigning additional rewards to specific roads based on their vehicle distribution, thereby promoting traffic balance and alleviating traffic bottlenecks to enhance overall traffic efficiency. To prevent signal lights from favoring certain lanes or vehicle types, an equalization-reward term is introduced:
The balance coefficient is computed based on the traffic flow in each lane and the maximum traffic flow observed in the lane where the vehicle is currently located. The balance coefficient for each lane should be updated in real time, independently for each lane.
Combining the above three factors, the reward and punishment function is:
Table 2 provides a framework and pseudo-code for the reward–punishment function implemented in the simulation. Among these factors, the larger the value of the queue-length penalty factor (queue_len_factor), the stricter the queuing penalty, and the model tends to reduce the length of vehicle queues. However, if the factor is set too large, it may make the system overly focus on the current queue length and ignore the delay for subsequent arriving vehicles. The larger the value of the delay penalty factor (delay_factor), the stricter the delay penalty, and the model tends to reduce vehicle delay. Nevertheless, if the factor is set too large, it may lead to increased traffic congestion. In addition, the larger the balance reward factor (balance_factor), the more obvious the balance reward, and the model will pay more attention to the balance of traffic flow in different lanes. Nonetheless, if the factor is set too large, it may result in some lanes being given unreasonable priority. Moreover, the weight setting of different reward factors can also affect the results. In this study, the weights of the delay penalty factor and the queue penalty factor are set higher, while the weight of balance reward factor is set lower to achieve a balance between vehicle efficiency and road capacity.
Table 2.
Pseudocode of reward.
4. Case Study
4.1. Selection of Research Location
This study focuses on two intersections in Zhengzhou, China: the intersection of Longhu Inner Ring Road and Longyuan West 3rd Street, and the intersection of Longhu Inner Ring Road and Longyuan West 4th Street. These intersections are integral to the No. 1 self-driving-bus line in Zhengzhou’s East District, and they have been equipped with facilities to accommodate self-driving buses. Figure 3 depicts an information map of the intersections. The minimum green time and maximum green time are set according to the default signal-timing scheme of the intersection. During the model training process, the minimum and maximum green times will be dynamically adjusted within this range, but will not fall below or exceed the maximum value. It is worth noting that the signal timings at both intersections are identical.
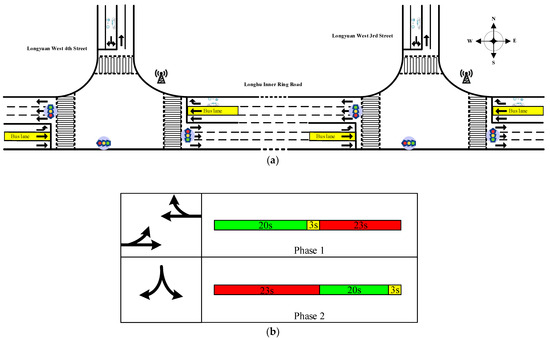
Figure 3.
Intersection information for Longhu Inner Ring Road and Longyuan West 3rd Street, as well as Longhu Inner Ring Road and Longyuan West 4th Street. (a) Channelization diagram of intersection. (b) Phase timing diagram of intersection.
4.2. Simulation Parameter Settings
The DQN algorithm requires the configuration of key parameters, such as the learning rate, discount factor, size of the experience-replay buffer, frequency of target-network updates, initial exploration rate, and decay strategy. The optimal combination of these parameters needs to be determined through experimentation and adjustments, as different scenarios and problems may require specific settings. To identify the best parameter configuration for the optimization model, the network must undergo pre-learning.
To ensure that the agent adequately explores the diverse characteristics of traffic states, the generation of vehicle arrivals follows the Weibull distribution. This distribution generates vehicles with varying probabilities over time, resulting in peaks and valleys in the appearance of vehicles, akin to real-life fluctuations in traffic volume. The probability density is mathematically defined as follows:
where is a random variable; is the proportional coefficient; is a shape parameter.
Table 3 lists the relevant parameters and their values, as used in training.
Table 3.
Parameter settings for DQN agent.
4.3. Sumo Simulation
The simulation scenario is constructed based on the actual intersection, and the lane layout is shown in the intersection channelization diagram in Figure 3a, adopting a single ring intersection network topology structure, including two adjacent intersections. The setting of the basic signal phase is shown in Figure 3b. The implementation of the signal control program is achieved by predefining all possible signal combinations (such as green light stage, yellow light stage, etc.) in the road network file, setting the current stage code through the TraCI interface, and switching the signal light control to green light according to the relevant road-environment status information in Table 4 to meet the requirements of autonomous bus passing.
Table 4.
Road environmental status information.
5. Results and Discussion
The goal of this study is to develop a signal priority control method for self-driving buses to minimize the combined delays from buses and private vehicles. To evaluate the effectiveness of this method, the Results and Discussion section provides a detailed comparative analysis of private-vehicle delay and queue length. The rationale for focusing on private-vehicle performance indicators is that transit signal priority can lead to delays for private vehicles in non-priority phases, while buses will experience reduced delays or even avoid delays entirely thanks to signal priority strategies. Therefore, comparisons of private-vehicle delay and queue length can more intuitively demonstrate the pros and cons of this signal control strategy and its impact on the overall traffic network.
5.1. Training Results
The evaluation of DQN training results typically involves monitoring reward changes throughout the training process. Initially, with randomly initialized model parameters, the rewards are low. As the training advances, the model gradually learns improved strategies, leading to increasing rewards. Throughout the training, the model’s loss change is monitored to ensure convergence.
In the early stages of training, due to the random initialization of parameters, rewards may exhibit significant variation. However, as training progresses, reward variation gradually diminishes, ultimately converging. Subsequently, model performance is assessed using either a test set or real-world scenario tests. Successful performance validates the model’s applicability to real-world situations.
Figure 4 illustrates the average reward results of DQN training. Observing the graph, we note that during the initial 0–20 iterations, the average cumulative reward shows a slight increase, but with noticeable fluctuations. However, as the iteration number reaches 20–60 generations, the model enters a fast learning phase, leading to a significant increase in reward with a reduced fluctuation range. Beyond the 60th iteration, fluctuations nearly vanish, and the reward stabilizes, indicating model convergence and improved training effectiveness.
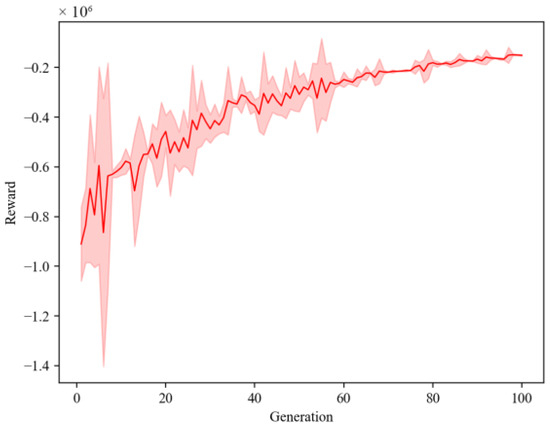
Figure 4.
Average cumulative reward training analysis.
From Figure 5 and Figure 6, it can be observed that as the number of iterations increases, the intersections’ total delay and the average queue length in the training gradually decrease, and fluctuations diminish. This indicates that the model can be applied to real-time signal priority for self-driving buses and effectively reduce queues and delays.
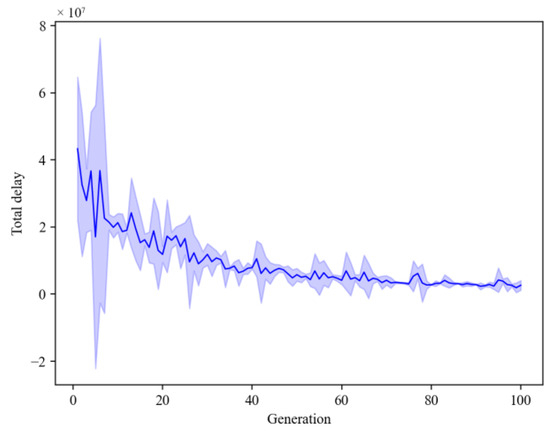
Figure 5.
Total delay training analysis.
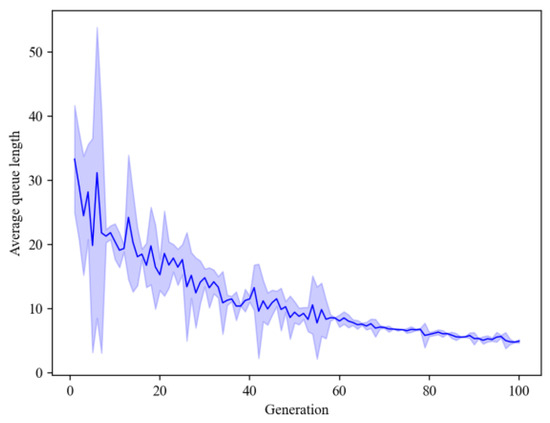
Figure 6.
Average queue length training analysis.
5.2. Testing Results
The testing process of a DQN involves deploying the intelligent agent to a new testing environment after training and evaluating whether the learned strategies can adapt to the new setting while obtaining reasonable rewards. The quality of the test results reflects the agent’s generalization ability and its level of robustness. Throughout the training process of a DQN, the agent interacts with the environment and continually updates its Q-value function and strategy to achieve the objective of maximizing cumulative rewards.
For the simulation of arterial intersections, three scenarios are established: Scenario 1, without the implementation of self-driving TSP; Scenario 2, with traditional ATSP; and Scenario 3, with arterial TSP controlled by the DQN algorithm. These three scenarios are simulated.
The results of the comparison as to the average delay at the intersection are presented in Figure 7, and the comparison for the average queue length at the intersection is shown in Figure 8. The findings indicate that Scenario 3 demonstrates a 27.77% optimization in delay compared to Scenario 1, and a 30.55% optimization compared to Scenario 2. Additionally, the average queue length in Scenario 3 is optimized by 33.41% when compared to Scenario 1, and by 38.21% when compared to Scenario 2.
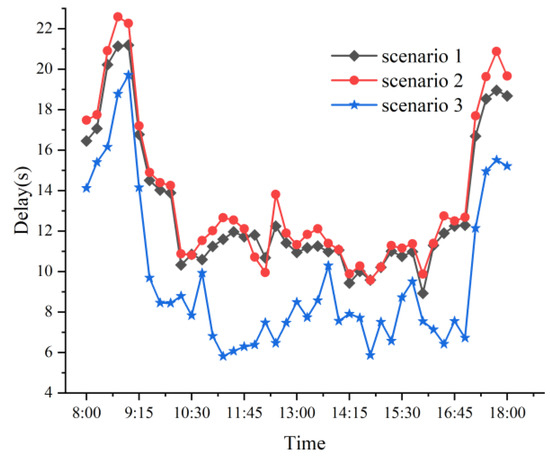
Figure 7.
Comparisons of the intersection delay under different scenarios.
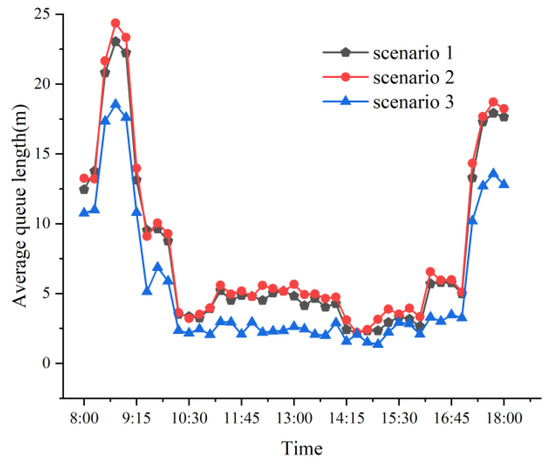
Figure 8.
Comparisons of the average intersection queuing length under different scenarios.
Figure 7 and Figure 8 demonstrate that the real-time signal-priority control of self-driving buses using DQN proves to be particularly effective during the morning and evening peak hours when traffic volume is high. This approach significantly reduces delay and queuing for private vehicles, and importantly, the delay and queuing do not produce excessive fluctuations with varying traffic volumes. This method is suitable for arterial intersections with heavy traffic flow, as it helps alleviate traffic congestion during peak hours and enhances overall road capacity.
6. Conclusions
This paper addresses the critical issue of delays faced by private vehicles due to the prioritization of self-driving buses at arterial intersections. To tackle this challenge, a strategy optimization method utilizing the powerful DQN algorithm is proposed. The method not only achieves real-time signal timing for self-driving buses but also effectively mitigates potential delays for private vehicles caused by TSP. To optimize the algorithm model efficiently, an environment model based on real road network data is utilized during agent training. Through careful design of the state space, action space, and reward function, the DQN model is trained to learn the optimal control strategy. An innovative approach is introduced to enhance the allocation of vehicle road rights in the optimization algorithm model, incorporating an equalization reward component within the reward-and-punishment function. The value of the reward function is optimized through a deep neural network, a well-defined loss function, and an experience-playback buffer area. The experimental results showcase the remarkable effectiveness of this method. Additionally, performing extensive hyperparameter tuning can help optimize the performance of the DQN algorithm, including as to learning rate, batch size, and discount factor, ensuring the identification of the best parameter settings. By implementing the optimized TSP method through DQN control for self-driving, substantial enhancements in TSP effectiveness and overall road network flow are achieved. These significant outcomes contribute valuable insights to the realm of intelligent control for urban public transportation, paving the way for future advancements in efficient traffic management and sustainable mobility solutions.
In this study, the DQN algorithm is utilized for real-time signal priority of self-driving buses, and its effectiveness is validated in simplified scenarios. However, only one reinforcement-learning algorithm is investigated. In the future, more learning algorithms can be studied and compared to improve performance. Additionally, the impacts of different traffic-flow distributions on the model remain unexplored. Further experiments with diverse traffic data could help optimize and generalize the model.
Author Contributions
Conceptualization, H.L. and X.Z.; methodology, H.L. and S.L.; software, S.L.; validation, S.L. and H.L.; formal analysis, S.L.; investigation, S.L. and H.L.; resources, H.L. and S.L.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, H.L., S.L. and X.Z.; visualization, S.L.; supervision, X.Z.; project administration, X.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Tackle Key Problems in Science and Technology Project of Henan Province (222102240052), the Foundation for High-Level Talents of Henan University of Technology (2018BS029), the Doctoral Foundation of Henan University of Technology for Xu Zhang (31400348), and Research Funds for Xu Zhang, Chief Expert of Traffic Engineering (21410003).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tsitsokas, D.; Kouvelas, A.; Geroliminis, N. Modeling and optimization of dedicated bus lanes space allocation in large networks with dynamic congestion. Transp. Res. Part C Emerg. Technol. 2021, 127, 103082. [Google Scholar] [CrossRef]
- Hounsell, N.; Shrestha, B. A new approach for co-operative bus priority at traffic signals. IEEE Trans. Intell. Transp. Syst. 2012, 13, 6–14. [Google Scholar] [CrossRef]
- Wang, M.; Wu, L.; Li, J.; He, L. Traffic signal control with reinforcement learning based on region-aware cooperative strategy. IEEE T. Intell. Transp. 2022, 23, 6774–6785. [Google Scholar] [CrossRef]
- Wang, X.; Ke, L.; Qiao, Z.; Chai, X. Large-scale traffic signal control using a novel multiagent reinforcement learning. IEEE T. Cybern. 2021, 51, 174–187. [Google Scholar] [CrossRef] [PubMed]
- Jiang, T.; Wang, Z.; Chen, F. Urban traffic signals timing at four-phase signalized intersection based on optimized two-stage fuzzy control scheme. Math. Probl. Eng. 2021, 2021, 6693562. [Google Scholar] [CrossRef]
- Hu, J.; Park, B.B.; Lee, Y.J. Coordinated transit signal priority supporting transit progression under connected vehicle technology. Transp. Res. Part C Emerg. Technol. 2015, 55, 393–408. [Google Scholar] [CrossRef]
- He, Q.; Head, K.L.; Ding, J. Multi-modal traffic signal control with priority, signal actuation and coordination. Transp. Res. Part C Emerg. Technol. 2014, 46, 65–82. [Google Scholar] [CrossRef]
- Guler, S.; Menendez, M. Analytical formulation and empirical evaluation of pre-signals for bus priority. Transp. Res. Part B Methodol. 2014, 64, 41–53. [Google Scholar] [CrossRef]
- Ma, W.; Ni, W.; Head, L.; Zhao, J. Effective coordinated optimization model for transit priority control under arterial progression. Transp. Res. Rec. 2013, 2366, 71–83. [Google Scholar] [CrossRef]
- Laporte, G.; Ortega, F.; Pozo, M.; Puerto, J. Multi-objective integration of timetables, vehicle schedules and user routings in a transit network. Transp. Res. Part B Methodol. 2017, 98, 94–112. [Google Scholar] [CrossRef]
- Liu, J.; Lin, P.; Ran, B. A reservation-based coordinated transit signal priority method for bus rapid transit system with connected vehicle technologies. IEEE Intell. Transp. Syst. Mag. 2021, 13, 17–30. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, X.; Wei, J.; Yang, S.; Dai, J.; Qu, S. Cooperative Transit Signal Priority Considering Bus Stops Under Adaptive Signal Control. IEEE Access 2023, 11, 66808–66817. [Google Scholar] [CrossRef]
- Lee, W.; Wang, H. A Person-Based Adaptive traffic signal control method with cooperative transit signal priority. J. Adv. Transp. 2022, 2022, 2205292. [Google Scholar] [CrossRef]
- Wu, B.; Wang, H.; Wang, Y.; Zhai, B.; Yang, H. Transit signal priority method based on speed guidance and coordination among consecutive intersections. Transp. Res. Rec. 2023, 5, 1226–1240. [Google Scholar] [CrossRef]
- Ling, K.; Shalaby, A. Automated transit headway control via adaptive signal priority. J. Adv. Transp. 2004, 38, 45–67. [Google Scholar] [CrossRef]
- Wan, C.; Hwang, M. Value-based deep reinforcement learning for adaptive isolated intersection signal control. IET Intell. Transp. Syst. 2018, 12, 1005–1010. [Google Scholar] [CrossRef]
- Zhang, R.; Ishikawa, A.; Wang, W.; Striner, B.; Tonguz, O. Using reinforcement learning with partial vehicle detection for intelligent traffic signal control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 404–415. [Google Scholar] [CrossRef]
- Xu, M.; Wu, J.; Huang, L.; Zhou, R.; Wang, T.; Hu, D. Network-wide traffic signal control based on the discovery of critical nodes and deep reinforcement learning. J. Intell. Transp. Syst. 2020, 24, 1–10. [Google Scholar] [CrossRef]
- Tan, K.; Sharma, A.; Sarkar, S. Robust deep reinforcement learning for traffic signal control. J. Big Data Anal. Transp. 2020, 2, 263–274. [Google Scholar] [CrossRef]
- Kumar, N.; Rahman, S.; Dhakad, N. Fuzzy inference enabled deep reinforcement learning-based traffic light control for intelligent transportation system. IEEE Trans. Intell. Transp. Syst. 2020, 8, 4919–4928. [Google Scholar] [CrossRef]
- Ma, Z.; Cui, T.; Deng, W.; Jiang, F.; Zhang, L. Adaptive optimization of traffic signal timing via deep reinforcement learning. J. Adv. Transp. 2021, 2021, 6616702. [Google Scholar] [CrossRef]
- Li, S. Multi-agent Deep Deterministic Policy Gradient for Traffic Signal Control on Urban Road Network. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020. [Google Scholar]
- Tan, T.; Bao, F.; Deng, Y.; Jin, A.; Dai, Q.; Wang, J. Cooperative deep reinforcement learning for large-scale traffic grid signal control. IEEE Trans. Cybern. 2019, 50, 2687–2700. [Google Scholar] [CrossRef] [PubMed]
- Xie, D.; Wang, Z.; Cheng, C.; Dong, D. IEDQN: Information Exchange DQN with a Centralized Coordinator for Traffic Signal Control. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Shabestray, S.; Abdulhai, B. Multimodal iNtelligent Deep (MiND) Traffic Signal Controller. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Guo, G.; Wang, Y. An integrated MPC and deep reinforcement learning approach to trams-priority active signal control. Control Eng. Pract. 2021, 110, 104758. [Google Scholar] [CrossRef]
- Mo, Z.; Li, W.; Fu, Y.; Ruan, K.; Di, X. CVLight: Decentralized learning for adaptive traffic signal control with connected vehicles. Transp. Res. Part C Emerg. Technol. 2022, 141, 103728. [Google Scholar] [CrossRef]
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1086–1095. [Google Scholar] [CrossRef]
- Singh, P.; Tabjul, G.; Imran, M.; Nandi, S.; Nandi, S. Impact of security attacks on cooperative driving use case: CACC platooning. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018. [Google Scholar]
- Milanés, V.; Shladovers, S. Modeling cooperative and autonomous adaptive cruise control dynamic responses using experimental data. Transport. Res. Part C Emerg. Technol. 2014, 48, 285–300. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).