
A Chinese–Kazakh Translation Method That Combines Data Augmentation and R-Drop Regularization


Abstract
:1. Introduction
- Parallel corpus augmentation: We successfully expanded the parallel corpus required for the Chinese–Kazakh machine translation task by utilizing phrase replacement techniques. By introducing more variations and diversities, we increased the richness of the training data, providing more information and context for training machine translation models.
- Joint data augmentation: To improve the quality of low-resource language machine translation, we adopted a combination of various data augmentation methods. In addition to generating pseudo-parallel corpora through phrase replacement, other data augmentation methods, such as random phrase replacement and deletion flipping, were also employed. By combining different data augmentation methods, we further increased the diversity of the training data, enhancing the model’s adaptability to various scenarios.
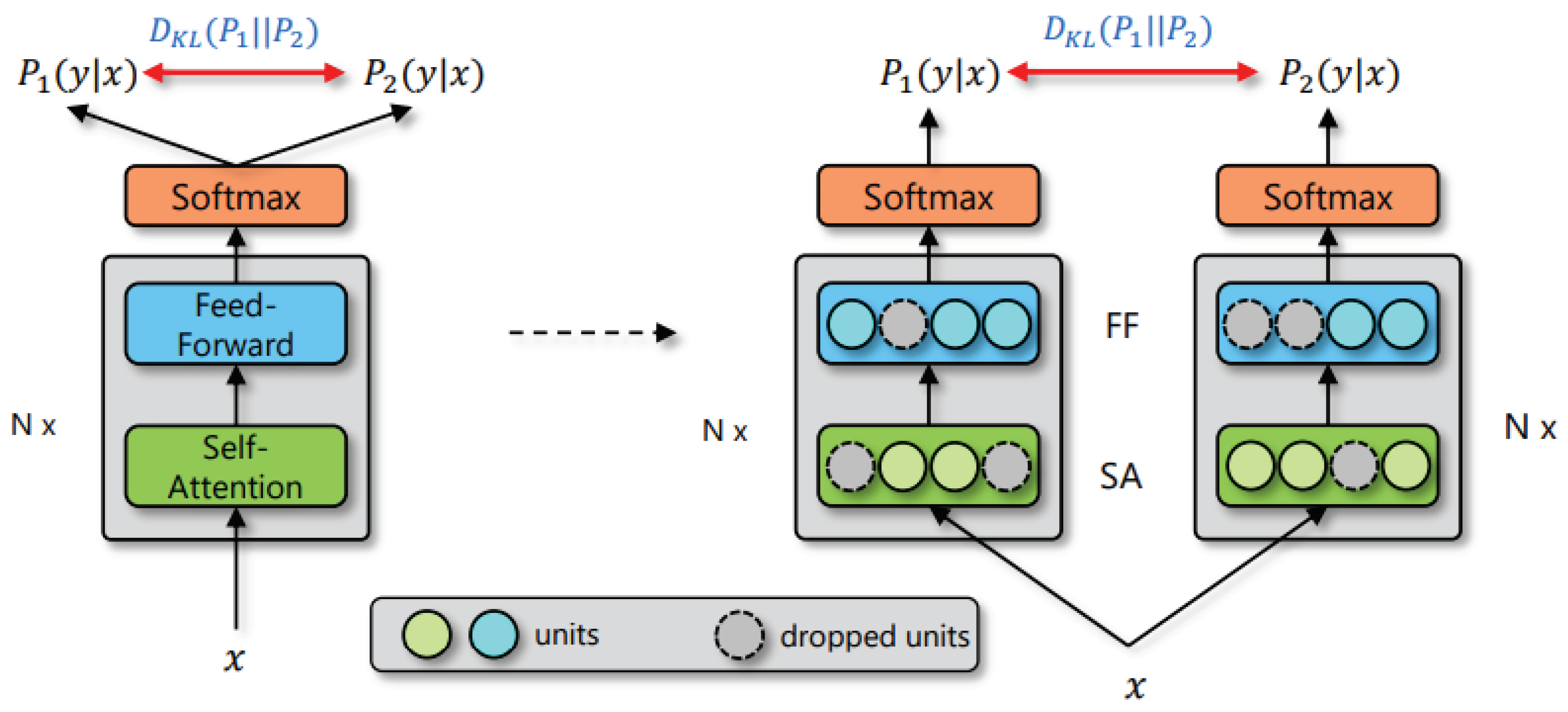
- Introducing the R-Drop regularization method: By introducing the R-Drop regularization method, we effectively enhanced the robustness of the model. R-Drop ensures consistency between the outputs of two sub-models by minimizing the bidirectional Kullback–Leibler (KL) divergence. During training, R-Drop regularizes the outputs of two sub-models randomly sampled from dropout. This alleviates the inconsistency between the training and inference stages, strengthening the model’s generalization ability and adaptability to unknown data.
2. Related Work
3. Method
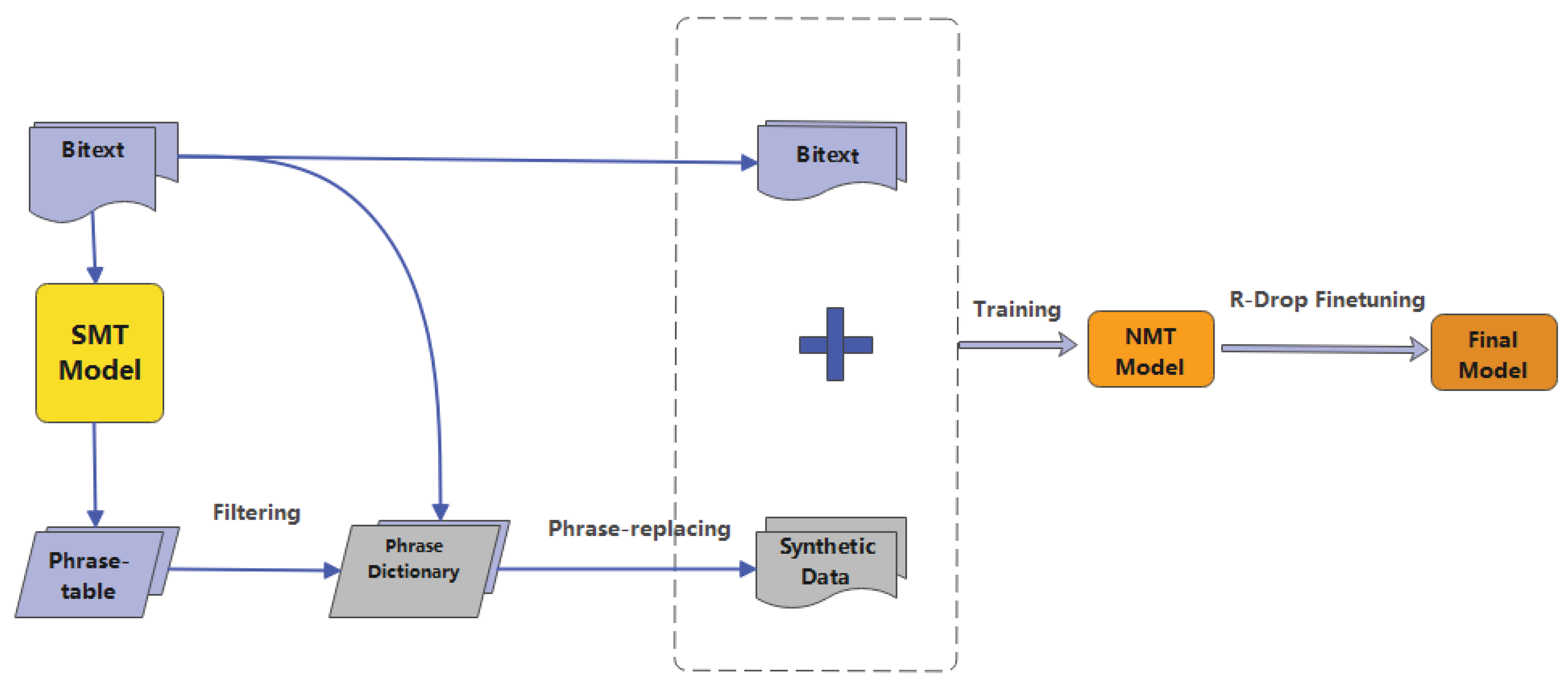
3.1. Generating a High-Quality Phrase Table
- The phrase translation probability (f|e);
- The lexical weighting lex(f|e);
- The phrase inverse translation probability (e|f);
- The inverse lexical weighting lex(e|f);
- The phrase penalty, currently always e = 2.718.
3.2. Generating Pseudo-Parallel Data Using a Phrase Table
3.3. Utilizing R-Drop for Model Fine-Tuning
4. Experiments
4.1. Data and Preprocessing
4.2. System Environment and Model Parameters
4.3. Results and Discussion
4.3.1. Baseline
4.3.2. Result
4.3.3. Combining Multiple Augmentation Methods
4.3.4. Fine-Tuning Using R-Drop
4.4. Qualitative Analysis
5. Analyses
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Wang, R.; Tan, X.; Luo, R.; Qin, T.; Liu, T.-Y. A survey on low-resource neural machine translation. arXiv 2021, arXiv:2107.04239. [Google Scholar]
- Shi, S.; Wu, X.; Su, R.; Huang, H. Low-resource neural machine translation: Methods and trends. ACM Trans. Asian-Low-Resour. Lang. Inf. Process. 2022, 21, 1–22. [Google Scholar] [CrossRef]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. arXiv 2016, arXiv:1604.02201. [Google Scholar]
- Kocmi, T.; Bojar, O. Trivial transfer learning for low-resource neural machine translation. arXiv 2018, arXiv:1809.00357. [Google Scholar]
- Kim, Y.; Petrov, P.; Petrushkov, P.; Khadivi, S.; Ney, H. Pivot-based transfer learning for neural machine translation between non-English languages. arXiv 2019, arXiv:1909.09524. [Google Scholar]
- Aji, A.F.; Bogoychev, N.; Heafield, K.; Sennrich, R. In Neural Machine Translation, What Does Transfer Learning Transfer? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7701–7710. [Google Scholar]
- Li, Z.; Liu, X.; Wong, D.F.; Lidia, S.C.; Min, Z. Consisttl: Modeling consistency in transfer learning for low-resource neural machine translation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 3rd ed.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 8383–8394. [Google Scholar]
- Turganbayeva, A.; Tukeyev, U. The solution of the problem of unknown words under neural machine translation of the Kazakh language. J. Inf. Telecommun. 2021, 5, 214–225. [Google Scholar] [CrossRef]
- Khayrallah, H.; Koehn, P. On the impact of various types of noise on neural machine translation. arXiv 2018, arXiv:1805.12282. [Google Scholar]
- Sperber, M.; Niehues, J.; Waibel, A. Toward robust neural machine translation for noisy input sequences. In Proceedings of the 14th International Conference on Spoken Language Translation, Tokyo, Japan, 14–15 December 2017; pp. 90–96. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 86–96. [Google Scholar]
- Hoang, V.C.D.; Koehn, P.; Haffari, G.; Cohn, T. Iterative back-translation for neural machine translation. In Proceedings of the 2nd Workshop on Neural Machine Translation and Generatio, Melbourne, Australia, 15–20 July 2018; pp. 18–24. [Google Scholar]
- Caswell, I.; Chelba, C.; Grangier, D. Tagged back-translation. arXiv 2019, arXiv:1906.06442. [Google Scholar]
- Li, B.; Hou, Y.; Che, W. Data augmentation approaches in natural language processing: A survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Behr, D. Assessing the use of back translation: The shortcomings of back translation as a quality testing method. Int. J. Soc. Res. Methodol. 2017, 20, 573–584. [Google Scholar] [CrossRef]
- Wu, L.; Li, J.; Wang, Y.; Meng, Q.; Qin, T.; Chen, W.; Zhang, M.; Liu, T.-Y. R-drop: Regularized dropout for neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 10890–10905. [Google Scholar]
- Al-Onaizan, Y.; Curin, J.; Jahr, M.; Knight, K.; Lafferty, J.; Melamed, D.; Och, F.-J.; Purdy, D.; Smith, N.A.; Yarowsky, D. Statistical machine translation. Final Report. Proceedings of the JHU Summer Workshop. 1999, Volume 30, pp. 98–157. Available online: https://aclanthology.org/www.mt-archive.info/JHU-1999-AlOnaizan.pdf (accessed on 10 August 2023).
- Koehn, P. Statistical Machine Translation; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Bugliarello, E.; Okazaki, N. Enhancing machine translation with dependency-aware self-attention. arXiv 2019, arXiv:1909.03149. [Google Scholar]
- Cheng, Y.; Liu, Y.; Yang, Q.; Sun, M.; Xu, W. Neural machine translation with pivot languages. arXiv 2016, arXiv:1611.04928. [Google Scholar]
- Chen, Y.; Liu, Y.; Li, V. Zero-resource neural machine translation with multi-agent communication game. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Gulcehre, C.; Firat, O.; Xu, K.; Cho, K.; Barrault, L.; Lin, H.C.; Bougares, F.; Schwenk, H.; Bengio, Y. On using monolingual corpora in neural machine translation. arXiv 2015, arXiv:1503.03535. [Google Scholar]
- Lample, G.; Conneau, A.; Denoyer, L.; Ranzato, M.A. Unsupervised machine translation using monolingual corpora only. arXiv 2017, arXiv:1711.00043. [Google Scholar]
- Zhang, Z.; Liu, S.; Li, M.; Zhou, M.; Chen, E. Joint training for neural machine translation models with monolingual data. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Pham, N.L.; Pham, T.V. A Data Augmentation Method for English-Vietnamese Neural Machine Translation. IEEE Access 2023, 11, 28034–28044. [Google Scholar] [CrossRef]
- Sen, S.; Hasanuzzaman, M.; Ekbal, A.; Bhattacharyya, P.; Way, A. Neural machine translation of low-resource languages using SMT phrase pair injection. Nat. Lang. Eng. 2021, 27, 271–292. [Google Scholar] [CrossRef]
- Batheja, A.; Bhattacharyya, P. Improving machine translation with phrase pair injection and corpus filtering. arXiv 2022, arXiv:2301.08008. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, 24–29 June 2007; pp. 177–180. [Google Scholar]
- Johnson, H.; Martin, J.; Foster, G.; Kuhn, R. Improving translation quality by discarding most of the phrasetable. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 967–975. [Google Scholar]
- Baldi, P.; Sadowski, P.J. Understanding dropout. In Advances in Neural Information Processing Systems 26; 2013; Available online: https://proceedings.neurips.cc/paper_files/paper/2013/file/71f6278d140af599e06ad9bf1ba03cb0-Paper.pdf (accessed on 10 August 2023).
- Jieba. Available online: https://github.com/fxsjy/jieba (accessed on 10 August 2023).
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Subword Neural Machine Translation. Available online: https://github.com/rsennrich/subword-nmt (accessed on 10 August 2023).
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A fast, extensible toolkit for sequence modeling. arXiv 2019, arXiv:1904.01038. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Post, M. A call for clarity in reporting BLEU scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar]
- Popović, M. chrF++: Words helping character n-grams. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 612–618. [Google Scholar]
- Fadaee, M.; Bisazza, A.; Monz, C. Data augmentation for low-resource neural machine translation. arXiv 2017, arXiv:1705.00440. [Google Scholar]
- Xie, Z.; Wang, S.I.; Li, J.; Lévy, D.; Nie, A.; Jurafsky, D.; Ng, A.Y. Data noising as smoothing in neural network language models. arXiv 2017, arXiv:1703.02573. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E.; Cho, K. Unsupervised neural machine translation. arXiv 2017, arXiv:1710.11041. [Google Scholar]
- Currey, A.; Miceli-Barone, A.V.; Heafield, K. Copied monolingual data improves low-resource neural machine translation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 148–156. [Google Scholar]
- Voita, E.; Sennrich, R.; Titov, I. Analyzing the source and target contributions to predictions in neural machine translation. arXiv 2020, arXiv:2010.10907. [Google Scholar]

{kind=link}
{kind=link}
| Zh–Kk | Kk–Zh | |||
|---|---|---|---|---|
| BLEU | chrF++ | BLEU | chrF++ | |
| Transformer | 49.47 | 0.745 | 52.04 | 0.463 |
| Back-translation | 49.93 | 0.746 | 54.21 | 0.478 |
| Replace | 49.90 | 0.747 | 57.15 | 0.514 |
| Token | 49.26 | 0.744 | 56.99 | 0.512 |
| Swap | 48.91 | 0.742 | 57.15 | 0.513 |
| Source | 48.93 | 0.742 | 52.14 | 0.462 |
| Reverce | 49.81 | 0.750 | 57.85 | 0.516 |
| Phrase-substitution | 50.15 | 0.752 | 57.35 | 0.514 |
| Zh–Kk | Kk–Zh | |||
|---|---|---|---|---|
| BLEU | chrF++ | BLEU | chrF++ | |
| Phrase-sub.+Rev. | 50.42 | 0.756 | 58.74 | 0.530 |
| Phrase-sub.+Rev.+Token | 50.55 | 0.756 | 58.99 | 0.532 |
| Phrase-sub.+Rev.+Swap | 51.46 | 0.761 | 58.58 | 0.527 |
| Zh–Kk | Kk–Zh | |||||
|---|---|---|---|---|---|---|
| BLEU | chrF++ | Time | BLEU | chrF++ | Time | |
| 0.3 | 53.56 | 0.771 | 3.11 h | 59.53 | 0.539 | 4.49 h |
| 0.4 | 54.46 | 0.777 | 4.48 h | 60.15 | 0.544 | 5.46 h |
| 0.5 | 54.45 | 0.776 | 5.35 h | 59.59 | 0.538 | 3.35 h |
| 0.6 | 54.29 | 0.774 | 5.96 h | 59.28 | 0.535 | 3.05 h |
| 0.7 | 54.44 | 0.777 | 6.38 h | 59.74 | 0.539 | 5.64 h |
| Method | Translations from Chinese to Kazakh |
|---|---|
| Source Sentence | 。认真解决群众反映强烈的商业促销噪音污染、占道经营阻碍交通等信访投诉问题 (Seriously address the strong public complaints regarding commercial promotion noise pollution, obstruction of traffic due to road occupation, and other petition issues.) |
| Reference | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدا ارقىلى ساتۋدى جەبەۋ شۋىلى لاستاۋ ، جولدى يەلەپ الىپ تيجارات جۇرگىزۋ قاتىناس سياقتى ارىز - ارمان ، ارىز - شاعىم ماسەلەلەرىن مۇقيات شەشۋ كەرەك. (Seriously address the strong public complaints regarding commercial promotion noise pollution, obstruction of traffic due to road occupation, and other petition issues.) |
| Baseline | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدا ارقىلى ساتۋدى جەبەۋ شۋىلدىڭ لاستانۋى ، جولدى يەلەپ تيجارات جۇرگىزۋ كەدەرگىگە ۇشىراۋ قاتىناس سياقتى ارىز - ارمان ايتۋ ماسەلەسىن مۇقيات شەشۋ كەرەك. (Seriously address the issues raised by the masses regarding problems such as noise pollution caused by commercial promotions, obstructed traffic due to business operations occupying roads, and other petitions.) |
| Phrase-substitution | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدا ارقىلى ساتۋدى جەبەۋ شۋىلدىڭ لاستانۋى ، جول يەلەيتىن تيجاراتقا كەدەرگى بولاتىن قاتىناس سياقتى ارىز - ارمان ، ارىز - شاعىم ماسەلەلەرىن مۇقيات شەشۋ كەرەك . (Seriously address the petitions and complaints raised by the public regarding the strong impact of noise pollution caused by commercial promotions and the obstruction of traffic due to business operations occupying public spaces.) |
| Mixed Enhancement | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدا ساتۋدى جەبەۋ شۋىلدىڭ لاستانۋ ، جولدى يەلەپ تيجارات جۇرگىزۋىنە كەدەرگى بولاتىن قاتىناس سياقتى ارىز - ارمان ماسەلەلەرىن مۇقيات شەشۋ كەرەك . (Seriously address the petitions and complaints raised by the public regarding the strong impact of noise pollution caused by sales promotions and the obstruction of traffic due to business operations occupying roadways.) |
| Mixed Enhancement+R-Drop | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدالىق ساتۋدى جەبەۋ شۋىلدىڭ لاستانۋى ، جولدى يەلەپ تيجارات جۇرگىزۋىنە كەدەرگى بولاتىن قاتىناس سياقتى ارىز - ارمان ، ارىز - شاعىم ماسەلەلەرىن مۇقيات شەشۋ كەرەك . (Seriously address the petitions and complaints raised by the public regarding the strong impact of noise pollution caused by commercial sales promotions and the obstruction of traffic due to businesses occupying roadways.) |
| Method | Translations from Kazakh to Chinese |
|---|---|
| Source Sentence | بۇقارانىڭ اڭىسى كۇشتى بولعان ساۋدا ارقىلى ساتۋدى جەبەۋ شۋىلى لاستاۋ ، جولدى يەلەپ الىپ تيجارات جۇرگىزۋ قاتىناس سياقتى ارىز - ارمان ، ارىز - شاعىم ماسەلەلەرىن مۇقيات شەشۋ كەرەك. (Seriously address the strong public complaints regarding commercial promotion noise pollution, obstruction of traffic due to road occupation, and other petition issues.) |
| Reference | 认真解决群众反映强烈的商业促销噪音污染、占道经营阻碍交通等信访投诉问题。(Seriously address the strong public complaints regarding commercial promotion noise pollution, obstruction of traffic due to road occupation, and other petition issues.) |
| Baseline | 要认真解决群众反映强烈的贸易促进噪声污染、道路占用经营交通等信访问题。(Address the trade promotion noise pollution, road occupation, business traffic, and other petition issues that have been strongly complained by the public.) |
| Phrase-substitution | 要认真解决群众反映强烈的以商促销噪音污染、占道经营交通等诉求、诉讼问题。(Seriously address the strong public concerns regarding issues such as noise pollution caused by promotional activities conducted through commerce, traffic congestion due to roadside business operations, and related demands and litigation problems.) |
| Mixed Enhancement | 认真解决群众反映强烈的营商促销噪声污染、占路经营交通等信访投诉问题。(Seriously address the public complaints regarding noise pollution caused by commercial promotion activities, road occupation for business operations, and other petition issues.) |
| Mixed Enhancement+R-Drop | 认真解决群众反映强烈的以商促销噪声污染、占道经营交通等信访投诉问题。(Seriously address the public complaints regarding noise pollution caused by commercial promotions, road occupation for business operations, and other petition issues.) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Silamu, W.; Li, Y. A Chinese–Kazakh Translation Method That Combines Data Augmentation and R-Drop Regularization. Appl. Sci. 2023, 13, 10589. https://doi.org/10.3390/app131910589
Liu C, Silamu W, Li Y. A Chinese–Kazakh Translation Method That Combines Data Augmentation and R-Drop Regularization. Applied Sciences. 2023; 13(19):10589. https://doi.org/10.3390/app131910589
Chicago/Turabian StyleLiu, Canglan, Wushouer Silamu, and Yanbing Li. 2023. "A Chinese–Kazakh Translation Method That Combines Data Augmentation and R-Drop Regularization" Applied Sciences 13, no. 19: 10589. https://doi.org/10.3390/app131910589
APA StyleLiu, C., Silamu, W., & Li, Y. (2023). A Chinese–Kazakh Translation Method That Combines Data Augmentation and R-Drop Regularization. Applied Sciences, 13(19), 10589. https://doi.org/10.3390/app131910589