
A Cross-Modal Hash Retrieval Method with Fused Triples

Abstract
:1. Introduction
2. Related Work
3. Description of Existing Cross-Modal Retrieval Methods
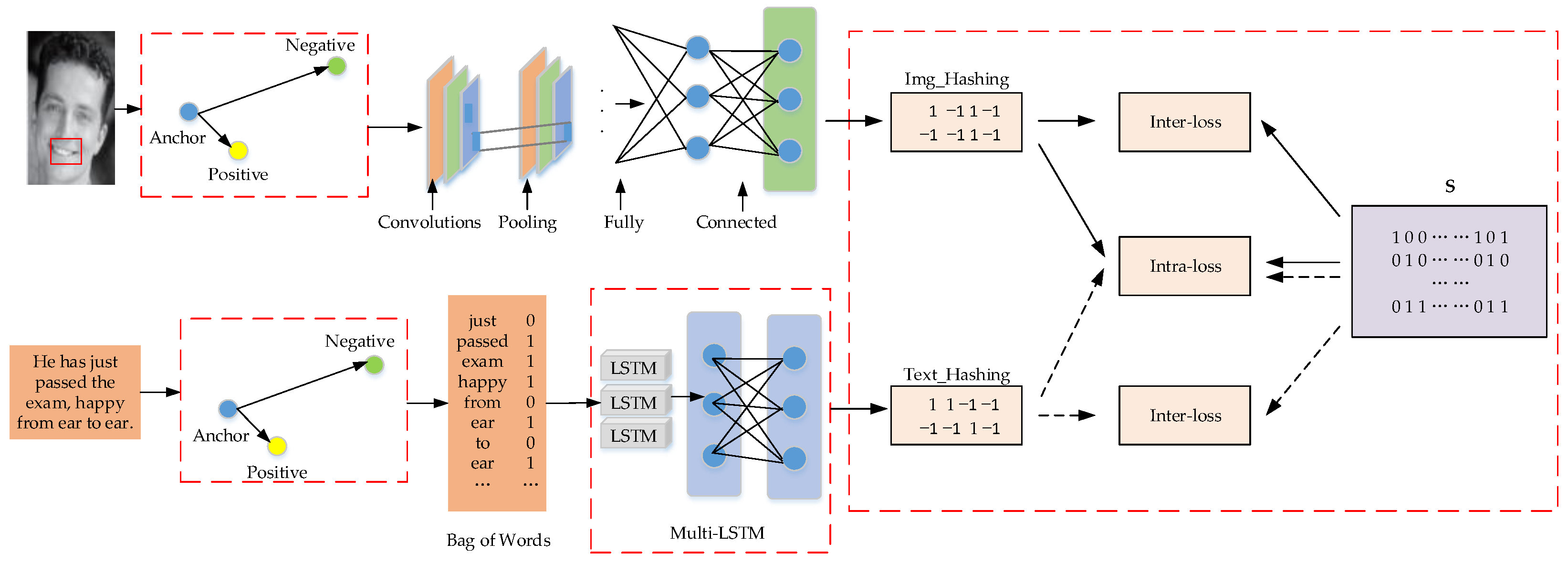
4. A Cross-Modal Hash Retrieval Method with Fused Triples
4.1. Model Framework
4.2. Feature Extraction
4.3. Hash Learning
4.3.1. Hamming Distance Loss
4.3.2. Single-Mode Internal Loss
4.3.3. Cross-Modal Losses
4.3.4. Quantifying Losses
5. Experiment
5.1. Experimental Programme
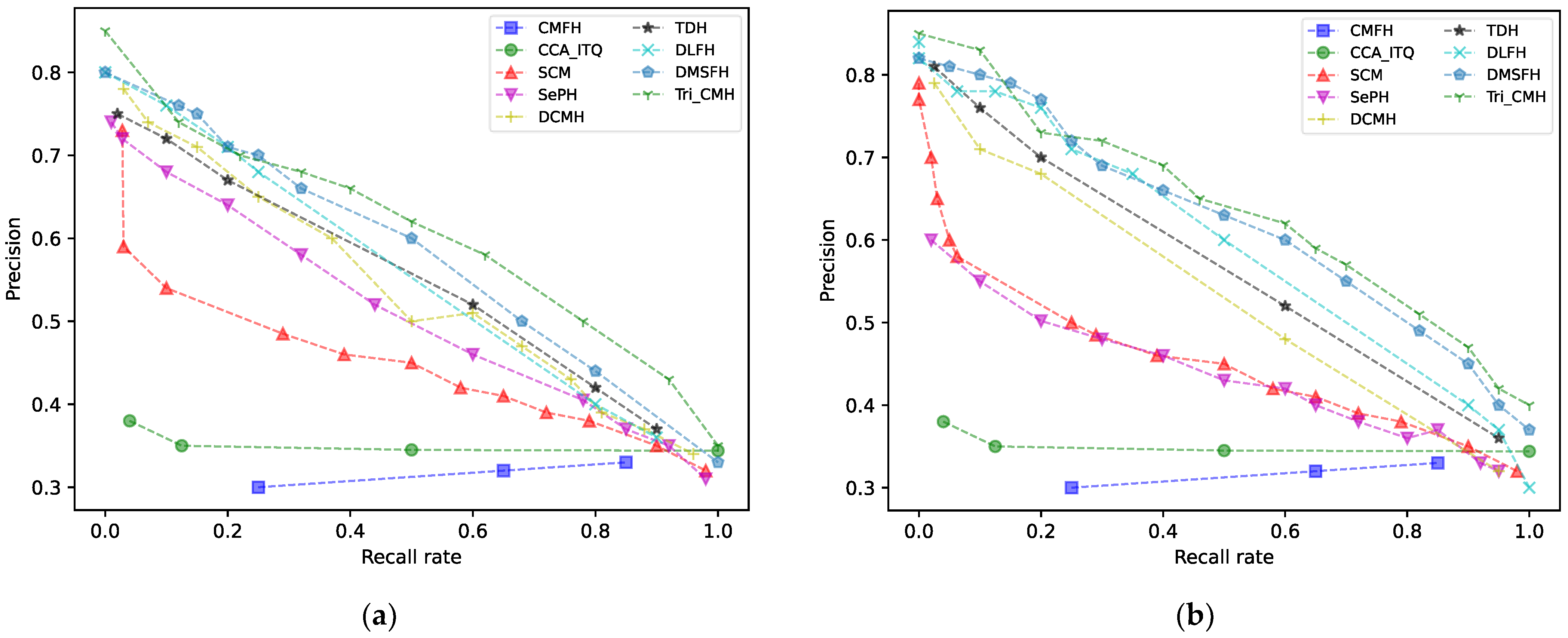
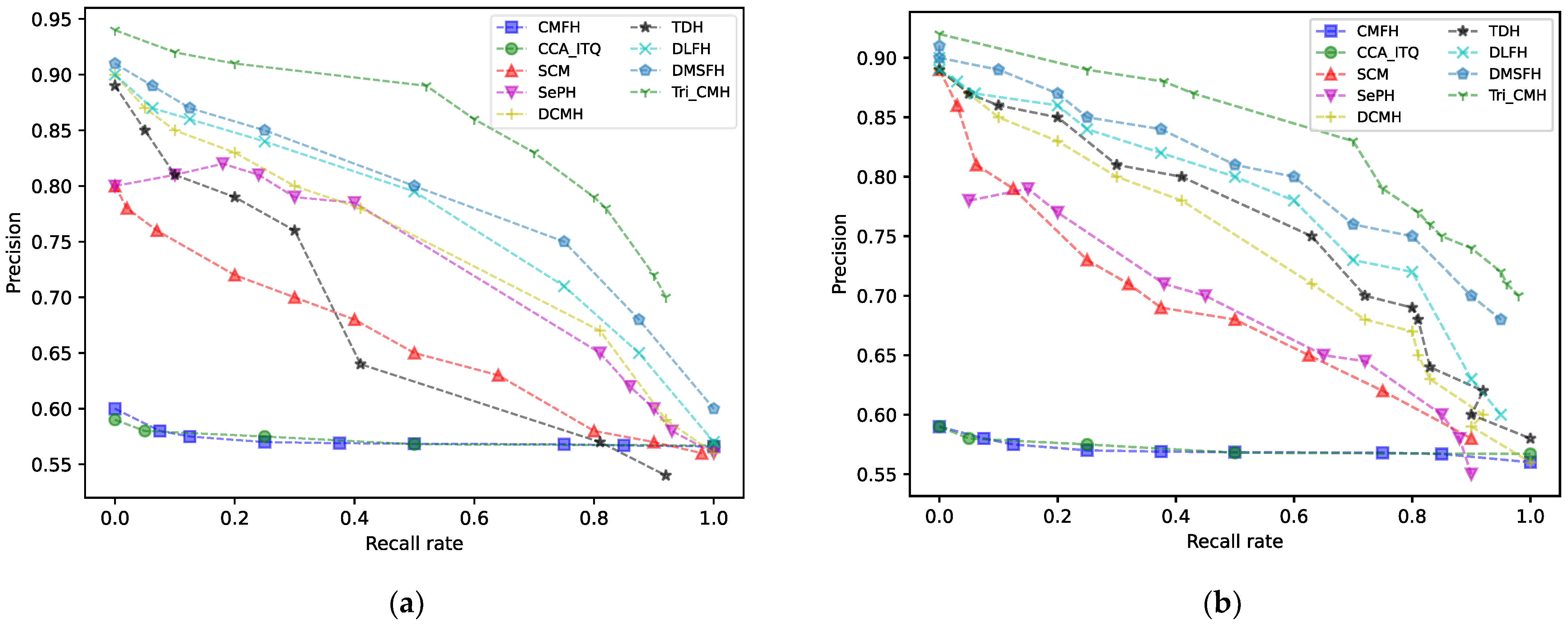
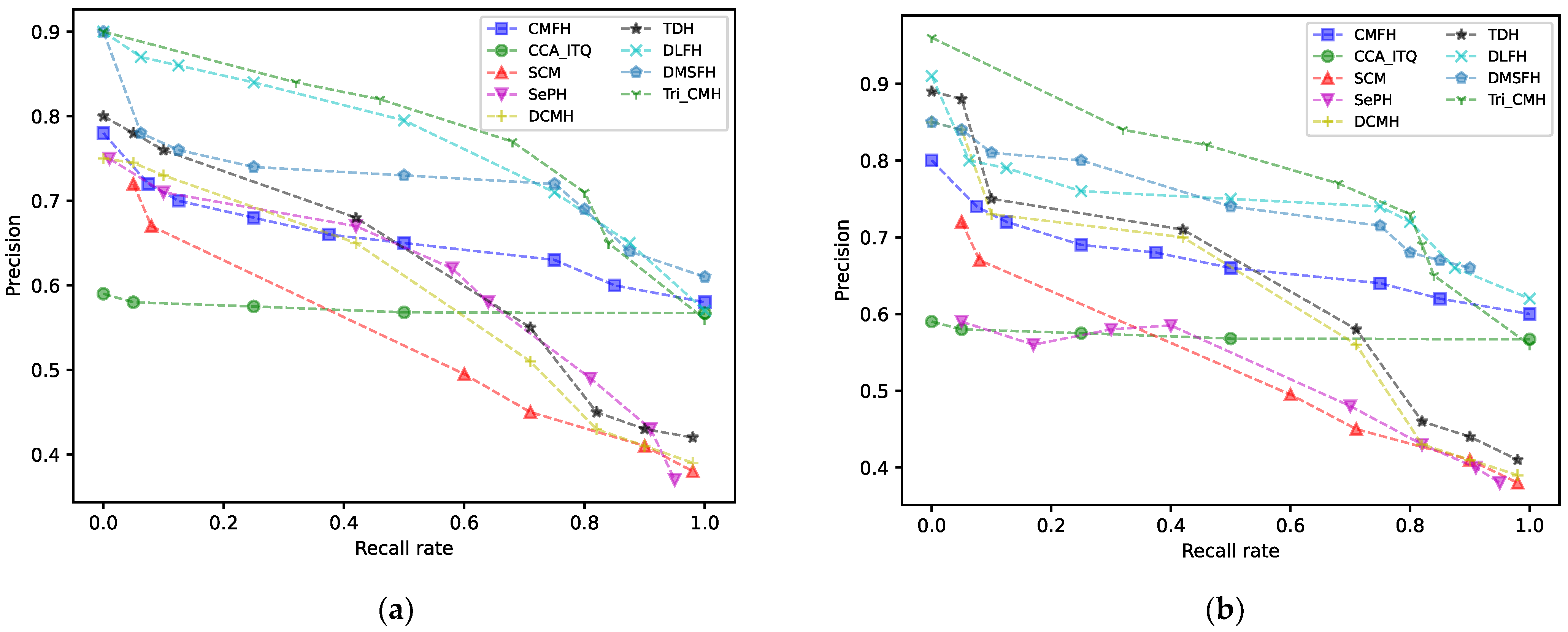
5.2. Experimental Results and Analysis
5.3. Training Time
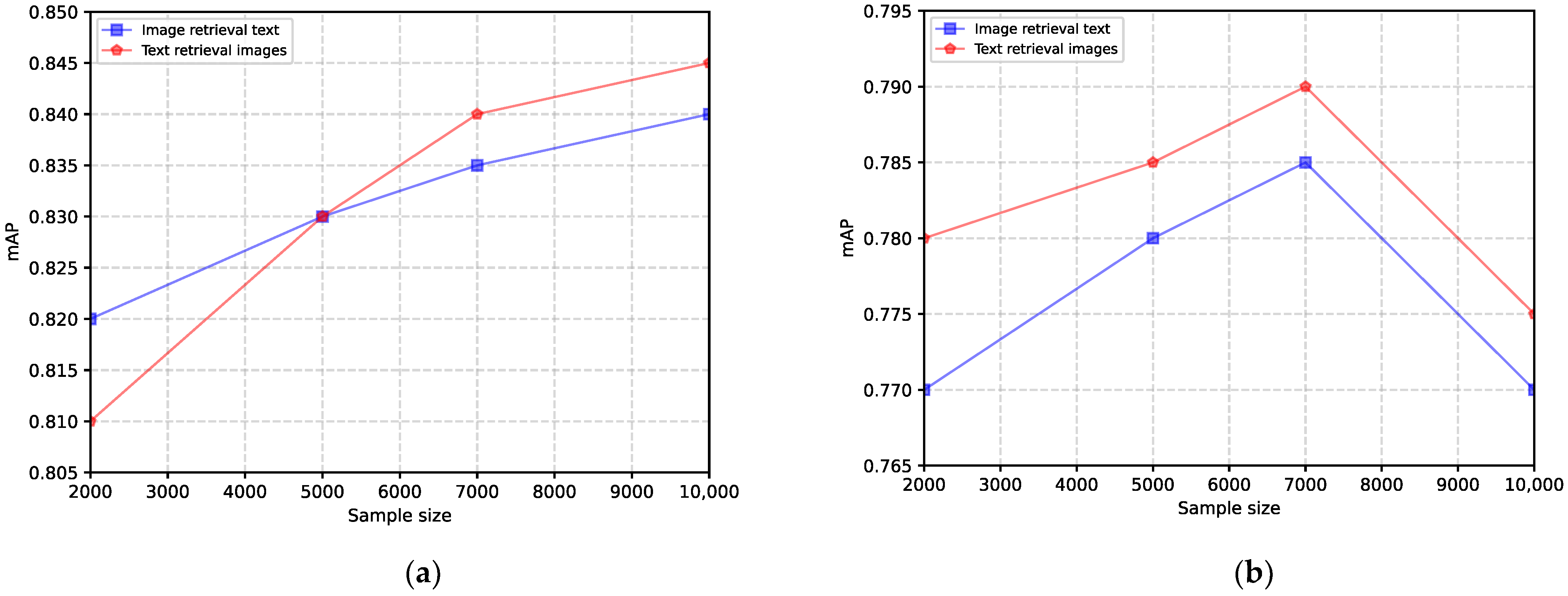
5.4. Sample Adaptability Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, K.; Yin, Q.; Wang, W.; Wu, S.; Wang, L. A comprehensive survey on cross-modal retrieval. arXiv 2016, arXiv:1607.06215. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Discrete latent factor model for cross-modal hashing. IEEE Trans. Image Process. 2019, 28, 3490–3501. [Google Scholar] [CrossRef] [PubMed]
- Zhen, L.; Hu, P.; Peng, X.; Goh RS, M.; Zhou, J.T. Deep supervised cross-modal retrieval. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 2019, 33, 10394–10403. [Google Scholar]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral hashing. Adv. Neural Inf. Process. Syst. 2008, 21, 8–11. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person reidentification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Wang, D.; Cui, P.; Ou, M.; Zhu, W. Deep multimodal hashing with orthogonal regularization. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2291–2297. [Google Scholar]
- Zhang, D.; Li, W.J. Large-scale supervised multimodal hashing with semantic correlation maximization. Proc. AAAI Conf. Artif. Intell. 2014, 28, 2177–2183. [Google Scholar] [CrossRef]
- Shen, H.T.; Liu, L.; Yang, Y.; Xu, X.; Huang, Z.; Shen, F.; Hong, R. Exploiting subspace relation in semantic labels for cross-modal hashing. IEEE Trans. Knowl. Data Eng. 2020, 33, 3351–3365. [Google Scholar] [CrossRef]
- Chamberlain, J.D.; Bowman, C.R.; Dennis, N.A. Age-related differences in encoding-retrieval similarity and their relationship to false memory. Neurobiol. Aging 2022, 113, 15–27. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Yang, Y.; Lian, T. SemSeq4FD: Integrating global semantic relationship and local sequential order to enhance text representation for fake news detection. Expert Syst. Appl. 2021, 166, 114090. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zou, X.; Bakker, E.M.; Wu, S. Self-constraining and attention-based hashing network for bit-scalable cross-modal retrieval. Neurocomputing 2020, 400, 255–271. [Google Scholar] [CrossRef]
- Liu, F.; Gao, M.; Zhang, T.; Zou, Y. Exploring semantic relationships for image captioning without parallel data. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 439–448. [Google Scholar]
- Wang, H.; Sahoo, D.; Liu, C.; Lim, E.P.; Hoi, S.C. Learning cross-modal embeddings with adversarial networks for cooking recipes and food images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11572–11581. [Google Scholar]
- Khan, A.; Hayat, S.; Ahmad, M.; Wen, J.; Farooq, M.U.; Fang, M.; Jiang, W. Cross-modal retrieval based on deep regularized hashing constraints. Int. J. Intell. Syst. 2022, 37, 6508–6530. [Google Scholar] [CrossRef]
- Jiang, Q.Y.; Li, W.J. Deep cross-modal hashing. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3232–3240. [Google Scholar]
- Ma, L.; Li, H.; Meng, F.; Wu, Q.; Ngan, K.N. Global and local semantics-preserving based deep hashing for cross-modal retrieval. Neurocomputing 2018, 312, 49–62. [Google Scholar] [CrossRef]
- Hu, P.; Zhu, H.; Lin, J.; Peng, D.; Zhao, Y.P.; Peng, X. Unsupervised contrastive cross-modal hashing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3877–3889. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef] [PubMed]
- Ding, G.; Guo, Y.; Zhou, J. Collective matrix factorization hashing for multimodal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–24 June 2014. [Google Scholar]
- Shu, Z.; Bai, Y.; Zhang, D.; Yu, J.; Yu, Z.; Wu, X.J. Specific class center guided deep hashing for cross-modal retrieval. Inf. Sci. 2022, 609, 304–318. [Google Scholar] [CrossRef]
- Mandal, D.; Chaudhury, K.N.; Biswas, S. Generalized semantic preserving hashing for n-label cross-modal retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4076–4084. [Google Scholar]
- Zhen, Y.; Yeung, D.Y. A probabilistic model for multimodal hash function learning. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 12 August 2012; pp. 940–948. [Google Scholar]
- Lin, Z.; Ding, G.; Hu, M.; Wang, J. Semantics-preserving hashing for cross-view retrieval. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2015; pp. 3864–3872. [Google Scholar]
- Kumar, S.; Udupa, R. Learning hash functions for cross-view similarity search. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011; pp. 1360–1365. [Google Scholar]
- Zhu, X.; Cai, L.; Zou, Z.; Zhu, L. Deep Multi-Semantic Fusion-Based Cross-Modal Hashing. Mathematics 2022, 10, 430. [Google Scholar] [CrossRef]
- Cao, Y.; Long, M.; Wang, J.; Yang, Q.; Yu, P.S. Deep visual-semantic hashing for cross-modal retrieval. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016. [Google Scholar]
- Deng, C.; Chen, Z.; Liu, X.; Gao, X.; Tao, D. Triplet-based deep hashing network for cross-modal retrieval. IEEE Trans. Image Process. 2018, 27, 3893–3903. [Google Scholar] [CrossRef] [PubMed]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Xu, M.; Du, J.; Xue, Z.; Guan, Z.; Kou, F.; Shi, L. A scientific research topic trend prediction model based on multi-LSTM and graph convolutional network. Int. J. Intell. Syst. 2022, 37, 6331–6353. [Google Scholar] [CrossRef]
- Escalante, H.J.; Hernández, C.A.; Gonzalez, J.A.; López-López, A.; Montes, M.; Morales, E.F.; Sucar, L.E.; Villaseñor, L.; Grubinger, M. The segmented and annotated IAPR TC-12 benchmark. Comput. Vis. Image Underst. 2010, 114, 419–428. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Lew, M.S. The mir flickr retrieval evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information, New York, NY, USA, 30–31 October 2008; pp. 39–43. [Google Scholar]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of Singapore. In Proceedings of the ACM International Conference On Image and Video Retrieval, New York, NY, USA, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 198–213. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation; European Conference Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Structure |
|---|---|
| Conv1 | f.64 × 11 × 11; s.4 × 4, pad0, LRN, ×2 pool |
| Conv2 | f.256 × 5 × 5; s.1 × 1, pad2, LRN, ×2 pool |
| Conv3 | f.256 × 3 × 3; s.1 × 1, pad1 |
| Conv4 | f.256 × 3 × 3; s.1 × 1, pad1 |
| Conv5 | f.256 × 3 × 3; s.1 × 1, pad1, ×2 pool |
| full6 | 4096 |
| full7 | 4096 |
| full8 | Hash code length c |
| Method | IAPR TC-12 | |||
|---|---|---|---|---|
| 16 Bit | 32 Bit | 64 Bit | ||
| I→T | CMFH | 0.310 | 0.325 | 0.308 |
| CCA-ITQ | 0.342 | 0.331 | 0.324 | |
| SCM | 0.387 | 0.397 | 0.410 | |
| SePH | 0.449 | 0.452 | 0.471 | |
| DCMH | 0.453 | 0.473 | 0.484 | |
| TDH | 0.462 | 0.477 | 0.498 | |
| DLFH | 0.450 | 0.468 | 0.527 | |
| DMSFH | 0.536 | 0.512 | 0.561 | |
| Tri-CMH | 0.629 | 0.637 | 0.648 | |
| T→I | CMFH | 0.325 | 0.330 | 0.319 |
| CCA-ITQ | 0.342 | 0.332 | 0.324 | |
| SCM | 0.364 | 0.361 | 0.369 | |
| SePH | 0.446 | 0.458 | 0.473 | |
| DCMH | 0.518 | 0.537 | 0.546 | |
| TDH | 0.535 | 0.584 | 0.569 | |
| DLFH | 0.481 | 0.509 | 0.602 | |
| DMSFH | 0.589 | 0.612 | 0.615 | |
| Tri-CMH | 0.631 | 0.642 | 0.653 | |
| Methods | MIRFLICKR-25 | |||
|---|---|---|---|---|
| 16 Bit | 32 Bit | 64 Bit | ||
| I→T | CMFH | 0.576 | 0.574 | 0.569 |
| CCA-ITQ | 0.576 | 0.574 | 0.569 | |
| SCM | 0.639 | 0.651 | 0.685 | |
| SePH | 0.718 | 0.722 | 0.723 | |
| DCMH | 0.741 | 0.746 | 0.750 | |
| TDH | 0.750 | 0.762 | 0.762 | |
| DLFH | 0.761 | 0.780 | 0.789 | |
| DMSFH | 0.815 | 0.819 | 0.831 | |
| Tri-CMH | 0.838 | 0.848 | 0.856 | |
| T→I | CMFH | 0.578 | 0.579 | 0.577 |
| CCA-ITQ | 0.576 | 0.571 | 0.577 | |
| SCM | 0.655 | 0.670 | 0.698 | |
| SePH | 0.727 | 0.732 | 0.738 | |
| DCMH | 0.782 | 0.790 | 0.793 | |
| TDH | 0.802 | 0.825 | 0.844 | |
| DLFH | 0.825 | 0.851 | 0.870 | |
| DMSFH | 0.807 | 0.823 | 0.856 | |
| Tri-CMH | 0.842 | 0.851 | 0.872 | |
| Method | NUS-WIDE | |||
|---|---|---|---|---|
| 16 Bit | 32 Bit | 64 Bit | ||
| I→T | CMFH | 0.384 | 0.390 | 0.406 |
| CCA-ITQ | 0.396 | 0.382 | 0.370 | |
| SCM | 0.522 | 0.548 | 0.556 | |
| SePH | 0.610 | 0.616 | 0.628 | |
| DCMH | 0.590 | 0.603 | 0.609 | |
| TDH | 0.661 | 0.687 | 0.692 | |
| DLFH | 0.674 | 0.695 | 0.705 | |
| DMSFH | 0.697 | 0.722 | 0.731 | |
| Tri-CMH | 0.768 | 0.780 | 0.791 | |
| T→I | CMFH | 0.374 | 0.382 | 0.389 |
| CCA-ITQ | 0.390 | 0.378 | 0.368 | |
| SCM | 0.516 | 0.540 | 0.549 | |
| SePH | 0.578 | 0.605 | 0.626 | |
| DCMH | 0.638 | 0.651 | 0.657 | |
| TDH | 0.728 | 0.743 | 0.752 | |
| DLFH | 0.780 | 0.802 | 0.821 | |
| DMSFH | 0.709 | 0.752 | 0.766 | |
| Tri-CMH | 0.778 | 0.805 | 0.818 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Mei, H.; Li, Y.; Yu, J.; Zhang, X.; Xue, X.; Wang, J. A Cross-Modal Hash Retrieval Method with Fused Triples. Appl. Sci. 2023, 13, 10524. https://doi.org/10.3390/app131810524
Li W, Mei H, Li Y, Yu J, Zhang X, Xue X, Wang J. A Cross-Modal Hash Retrieval Method with Fused Triples. Applied Sciences. 2023; 13(18):10524. https://doi.org/10.3390/app131810524
Chicago/Turabian StyleLi, Wenxiao, Hongyan Mei, Yutian Li, Jiayao Yu, Xing Zhang, Xiaorong Xue, and Jiahao Wang. 2023. "A Cross-Modal Hash Retrieval Method with Fused Triples" Applied Sciences 13, no. 18: 10524. https://doi.org/10.3390/app131810524
APA StyleLi, W., Mei, H., Li, Y., Yu, J., Zhang, X., Xue, X., & Wang, J. (2023). A Cross-Modal Hash Retrieval Method with Fused Triples. Applied Sciences, 13(18), 10524. https://doi.org/10.3390/app131810524