
Towards Robust Neural Rankers with Large Language Model: A Contrastive Training Approach


Abstract
:1. Introduction
- We assume that the representations of the original query and the corresponding query variations in the latent space should be similar while being distant from other queries. To train a robust IR model against adversarial query attacks, we propose a novel contrastive training approach that contains tasks of ranking and intent alignment.
- This study conducts experiments on two public datasets, and the results demonstrate the effectiveness of the proposed training approach. Our method not only improves the query robustness of the models but also ensures that retrieval performance does not suffer significant losses, and even outperforms the original models in some metrics.
2. Related Work
2.1. Robustness of IR
2.2. Contrastive Learning for IR
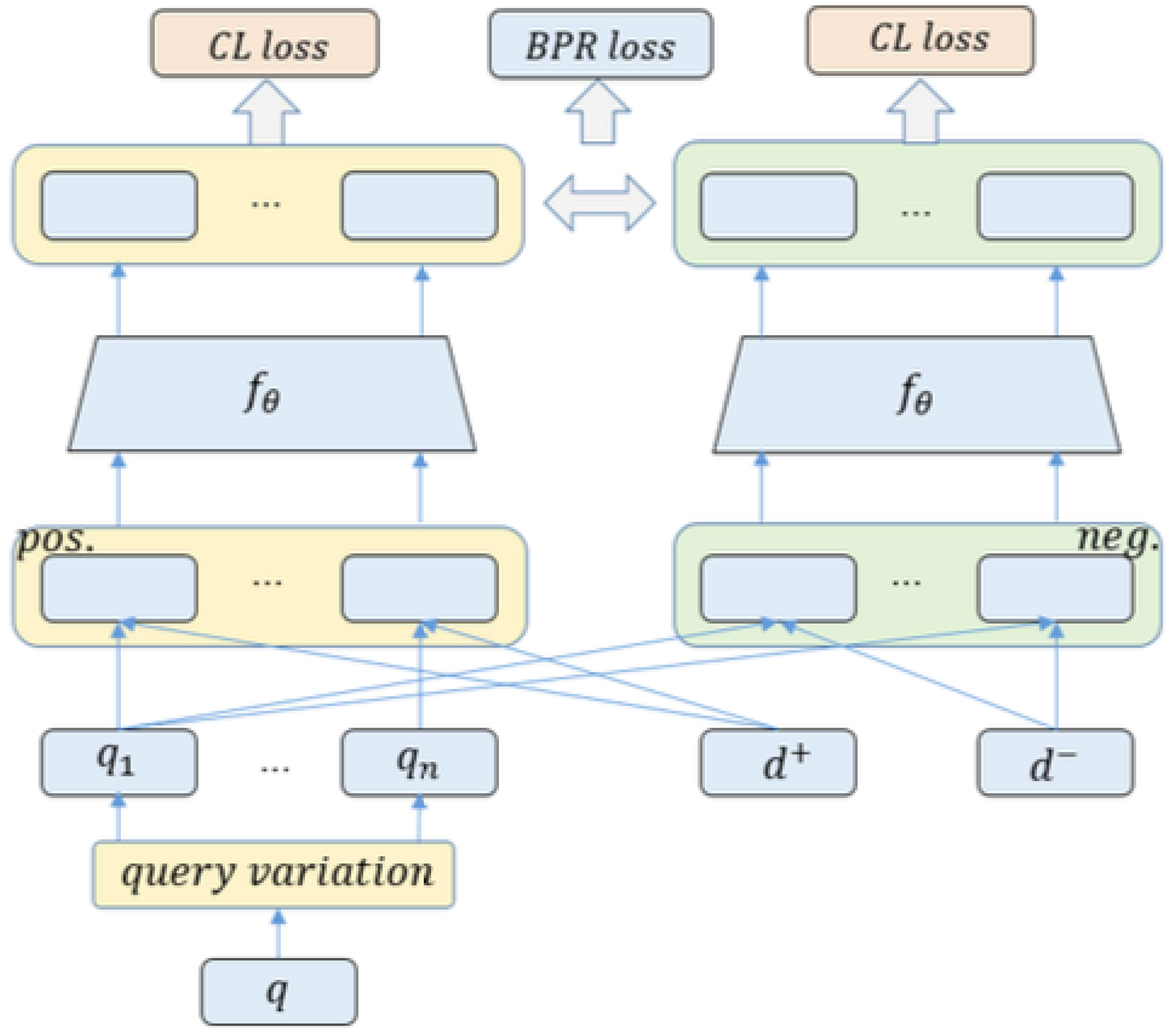
3. Methodology
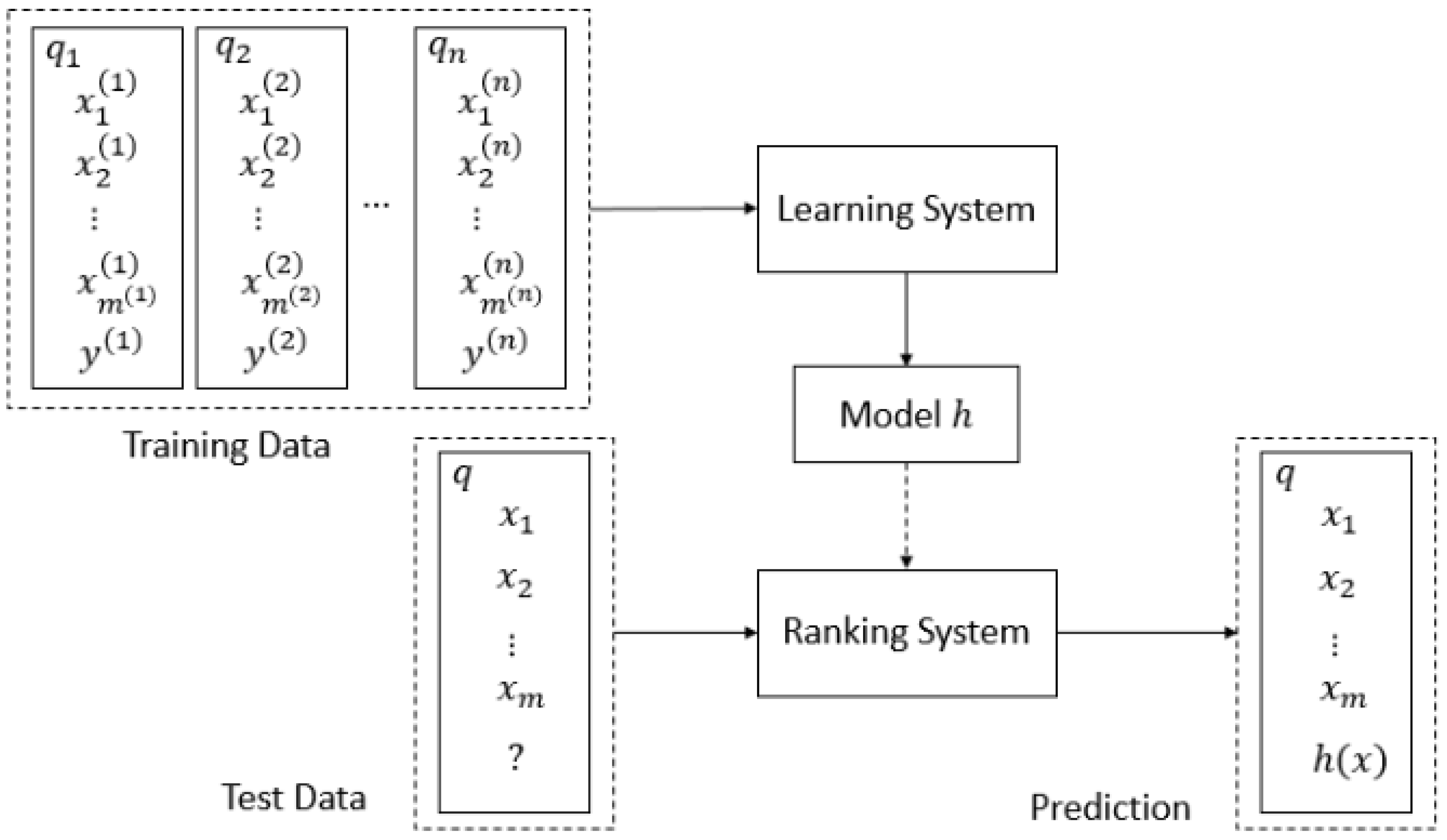
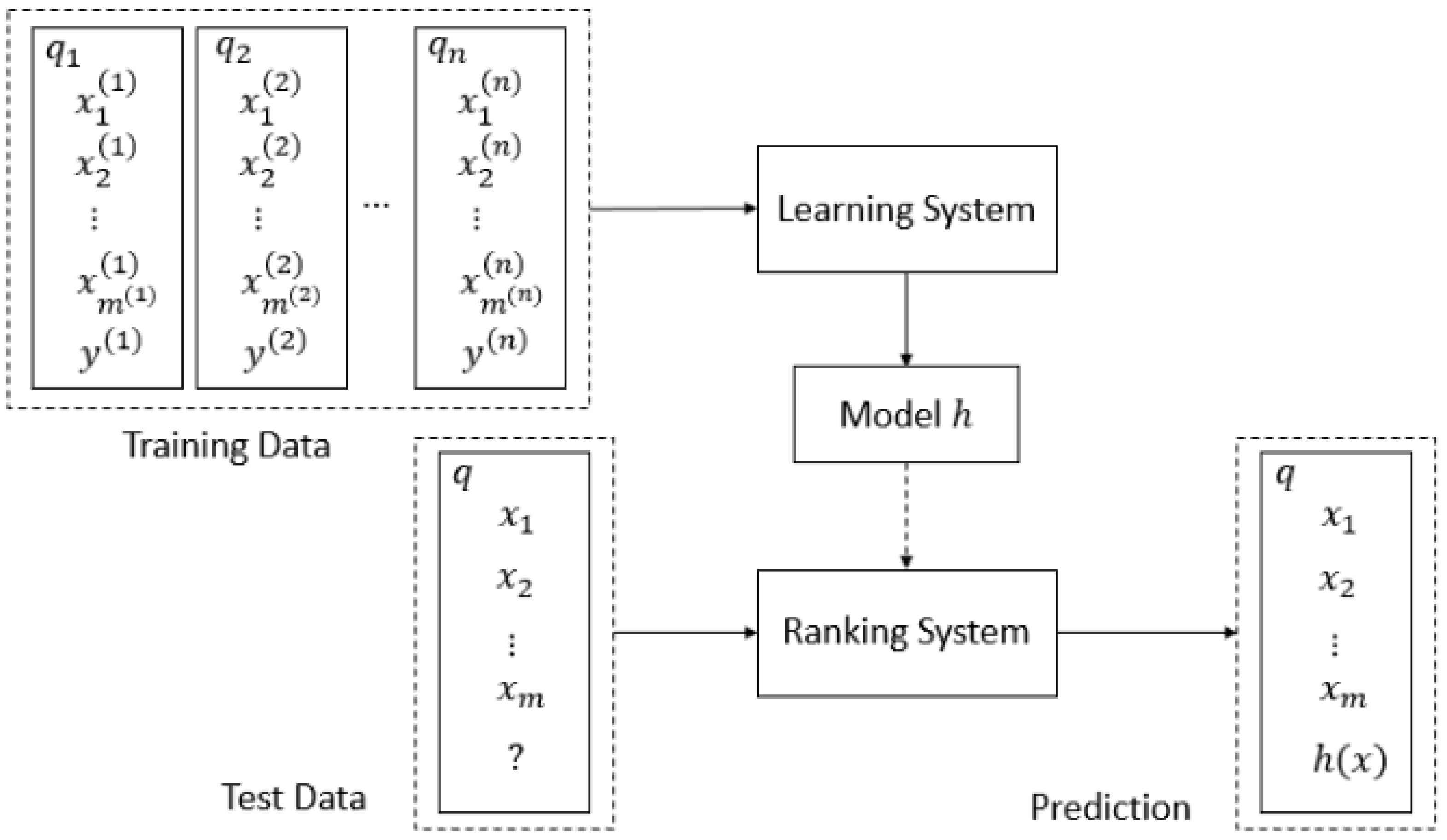
3.1. Problem Formulation
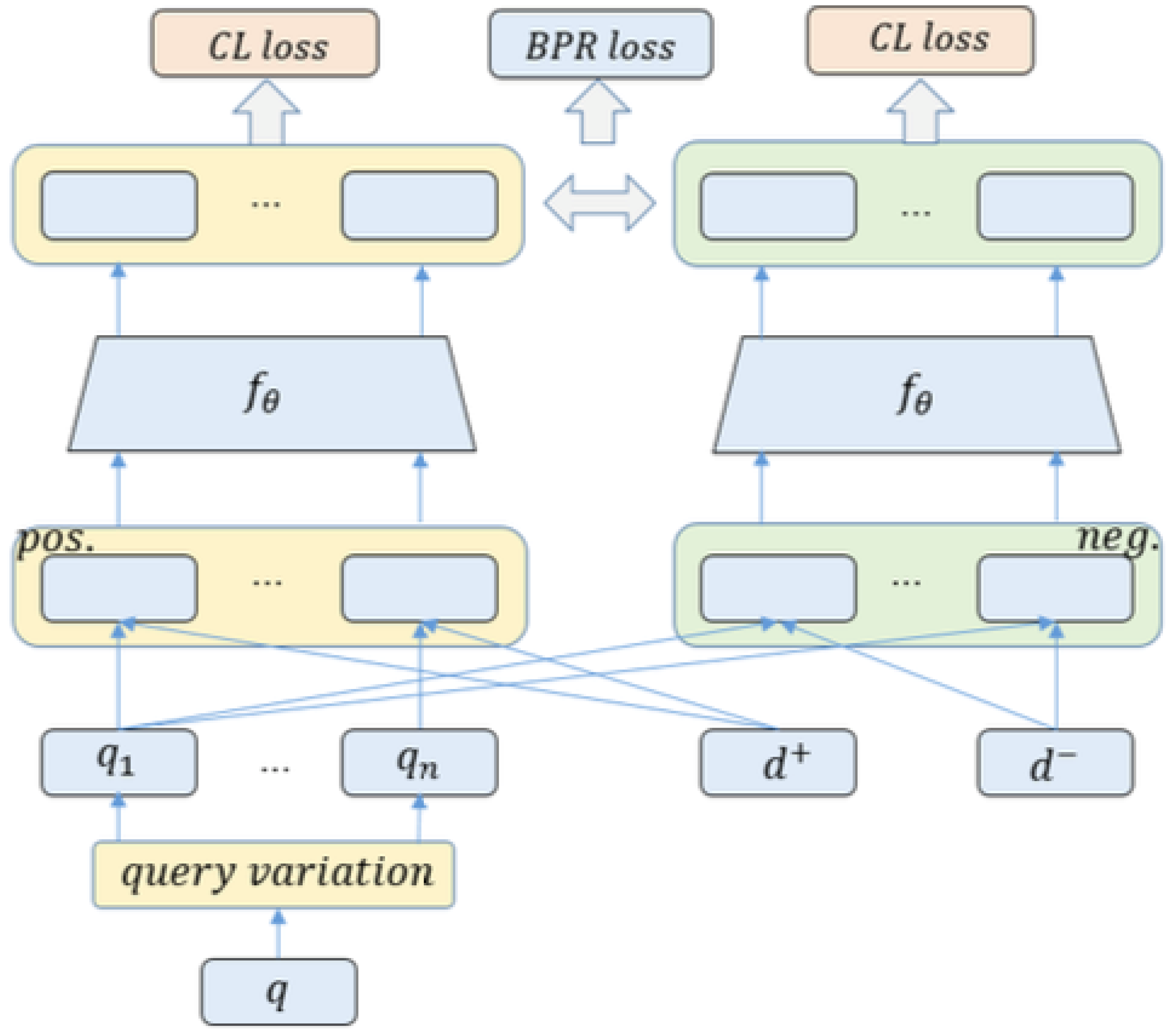
3.2. Main Framework
| Algorithm 1 Pseudocode for the proposed approach |
|
3.2.1. LLM-Based Query Generation
3.2.2. Ranking Training
3.2.3. Query Intent Alignment
4. Experiment
4.1. Dataset
- WikiQA [41]: the WikiQA corpus is a public dataset of question and sentence pairs collected and annotated for research on open-domain question answering. The dataset uses Bing query logs as the question source and includes 3047 questions and 29,258 sentences, where 1473 sentences were labeled answer sentences to their corresponding questions. Because the task is to find the answer for a given query and the label set is , we could regard it as an IR task that the IR model learns to retrieve the answer sentence from the candidate sentences when given a query.
- ANTIQUE [42]: ANTIQUE is an open field non-factoid question and answer dataset collected from community question and answer services. The collected data has a variety of categories, it contains 2626 open domain non-factor questions and 34,011 manual relevance annotations. These questions were asked by real users of the question and answer service: Yahoo! Answers and the relevance of all answers to each question is annotated by crowd-sourcing. Although candidate answers have four levels of relevance labels, we follow previous research [42,57], assuming that labels 3 and 4 are relevant labels, while labels 1 and 2 are irrelevant labels, which converts the four levels of relevance labels to two levels of relevance labels.
Paraphrase the following query and provide 5 different versions that convey the same meaning. Make sure each version is grammatically correct and clearly written.Query: HOW AFRICAN AMERICANS WERE IMMIGRATED TO THE US
4.2. Evaluation Metrics
4.3. Baselines
4.4. Implementation Details
5. Evaluation Result
5.1. Analysis of the Retrieval Effectiveness
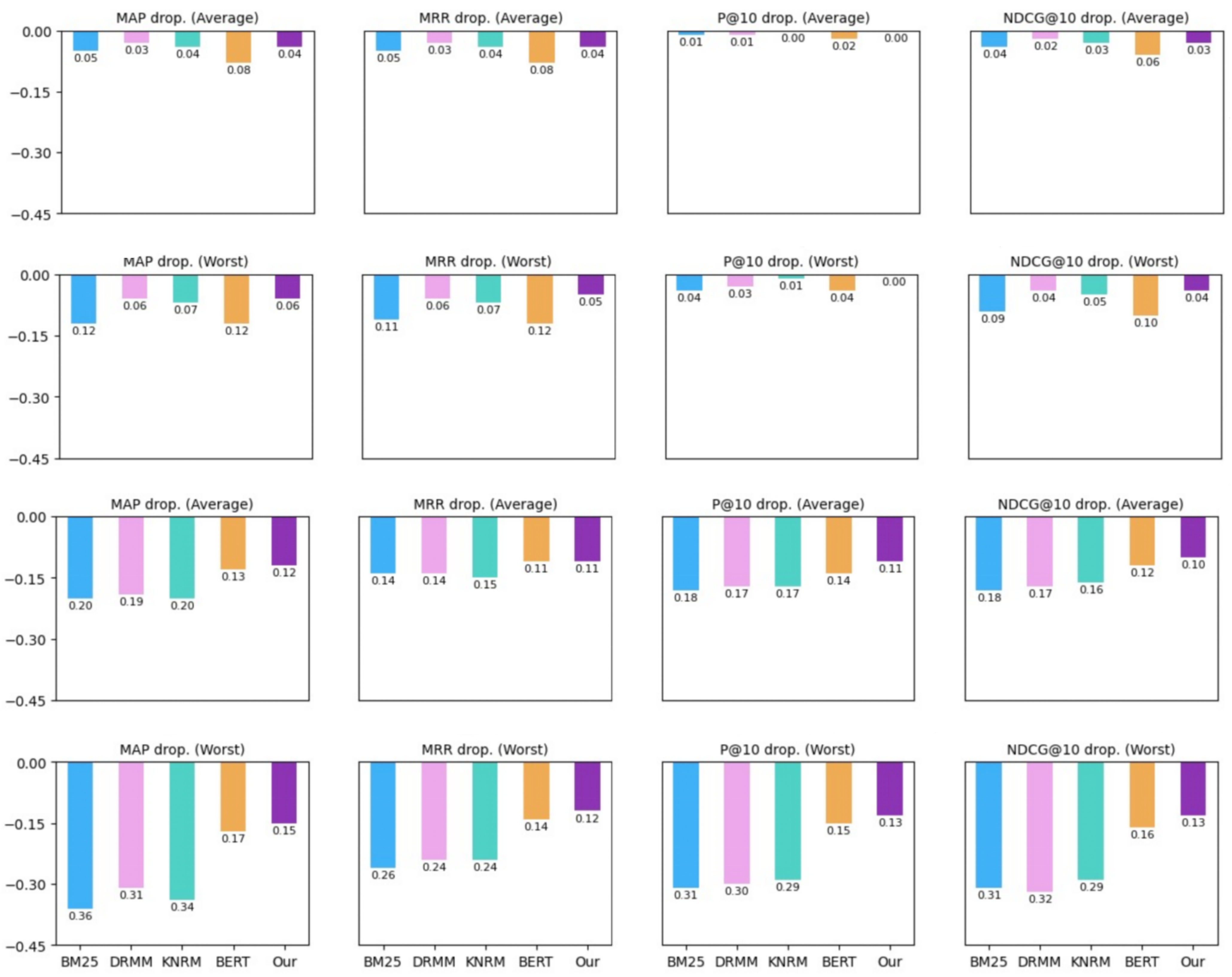
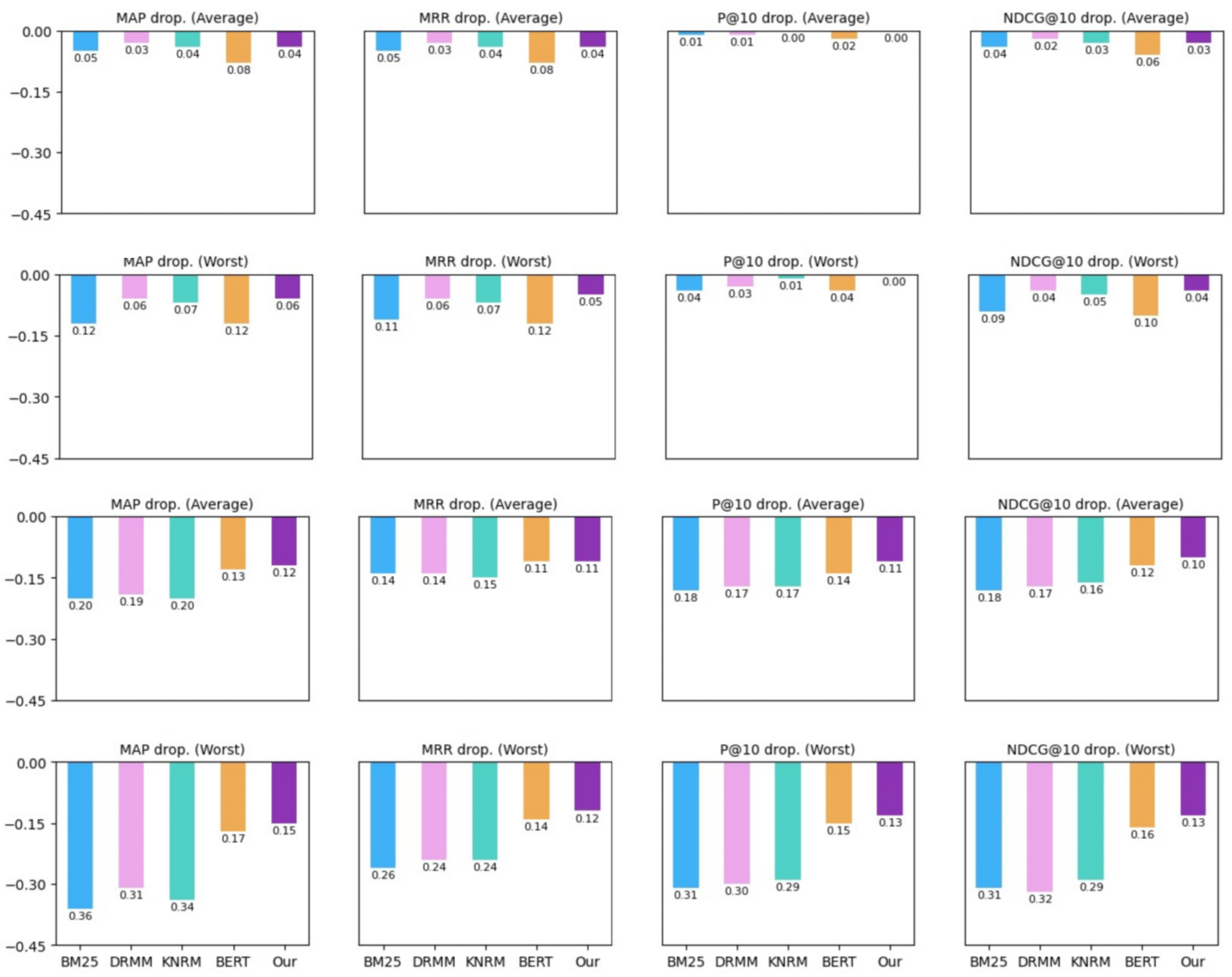
5.2. Analysis of the Retrieval Robustness
5.2.1. Comparison Analysis on Retrieval Robustness of Different IR Models
5.2.2. Comparison Analysis on Retrieval Robustness of Different Robustness Training Approaches
5.3. Case Study
6. Discussion
6.1. Limitations and Future Work
6.2. Ethical Considerations
6.3. Real-World Applicability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Fan, Y.; Xie, X.; Cai, Y.; Chen, J.; Ma, X.; Li, X.; Zhang, R.; Guo, J. Pre-training Methods in Information Retrieval. Found. Trends® Inf. Retr. 2022, 16, 178–317. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, R.; Guo, J.; Fan, Y.; Cheng, X. Are Neural Ranking Models Robust? ACM Trans. Inf. Syst. 2022, 41, 1–36. [Google Scholar] [CrossRef]
- Sidiropoulos, G.; Kanoulas, E. Analysing the Robustness of Dual Encoders for Dense Retrieval Against Misspellings. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2022; pp. 2132–2136. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhuang, S.; Zuccon, G. Dealing with Typos for BERT-based Passage Retrieval and Ranking. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2836–2842. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Xiong, C.; Liu, Z. More Robust Dense Retrieval with Contrastive Dual Learning. In Proceedings of the ICTIR ’21: The 2021 ACM SIGIR International Conference on the Theory of Information Retrieval, Virtual, 11 July 2021; pp. 287–296. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial Attacks on Deep-Learning Models in Natural Language Processing: A Survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Morris, J.X.; Lifland, E.; Yoo, J.Y.; Grigsby, J.; Jin, D.; Qi, Y. TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. arXiv 2020, arXiv:2005.05909. [Google Scholar]
- Li, J.; Ji, S.; Du, T.; Li, B.; Wang, T. TextBugger: Generating Adversarial Text Against Real-world Applications. In Proceedings of the Proceedings Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Gao, L.; Dai, Z.; Callan, J. Rethink Training of BERT Rerankers in Multi-Stage Retrieval Pipeline. In Proceedings of the Advances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, 1 April–28 March 2021; pp. 280–286. [Google Scholar] [CrossRef]
- Gao, L.; Dai, Z.; Chen, T.; Fan, Z.; Van Durme, B.; Callan, J. Complement Lexical Retrieval Model with Semantic Residual Embeddings. In Proceedings of the Advances in Information Retrieval; Hiemstra, D., Moens, M.F., Mothe, J., Perego, R., Potthast, M., Sebastiani, F., Eds.; Springer: Cham, Switzerland, 2021; pp. 146–160. [Google Scholar]
- Crammer, K.; Singer, Y. Pranking with Ranking. In Proceedings of the Advances in Neural Information Processing Systems; Dietterich, T., Becker, S., Ghahramani, Z., Eds.; MIT Press: Cambridge, MA, USA, 2001; Volume 14. [Google Scholar]
- Shashua, A.; Levin, A. Ranking with Large Margin Principle: Two Approaches. In Proceedings of the Advances in Neural Information Processing Systems; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2002; Volume 15. [Google Scholar]
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to Rank Using Gradient Descent. In Proceedings of the 22nd International Conference on Machine Learning, New York, NY, USA, 7–11 August 2005; pp. 89–96. [Google Scholar] [CrossRef]
- Burges, C.; Ragno, R.; Le, Q. Learning to Rank with Nonsmooth Cost Functions. In Proceedings of the Advances in Neural Information Processing Systems; Schölkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; Volume 19. [Google Scholar]
- Joachims, T. Optimizing Search Engines Using Clickthrough Data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 23–26 July 2002; pp. 133–142. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to Rank: From Pairwise Approach to Listwise Approach. In Proceedings of the 24th International Conference on Machine Learning, New York, NY, USA, 20–24 June 2007; pp. 129–136. [Google Scholar] [CrossRef]
- Xu, J.; Li, H. AdaRank: A Boosting Algorithm for Information Retrieval. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 23–27 July 2007; pp. 391–398. [Google Scholar] [CrossRef]
- Wu, Q.; Burges, C.J.C.; Svore, K.M.; Gao, J. Adapting boosting for information retrieval measures. Inf. Retr. 2010, 13, 254–270. [Google Scholar] [CrossRef]
- Arslan, A.; Dinçer, B.T. A selective approach to index term weighting for robust information retrieval based on the frequency distributions of query terms. Inf. Retr. J. 2019, 22, 543–569. [Google Scholar] [CrossRef]
- Gangi Reddy, R.; Yadav, V.; Arafat Sultan, M.; Franz, M.; Castelli, V.; Ji, H.; Sil, A. Towards Robust Neural Retrieval Models with Synthetic Pre-Training. arXiv 2021, arXiv:2104.07800. [Google Scholar] [CrossRef]
- Prakash, P.; Killingback, J.; Zamani, H. Learning Robust Dense Retrieval Models from Incomplete Relevance Labels. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 1728–1732. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9726–9735. [Google Scholar]
- Zhang, Y.; He, R.; Liu, Z.; Lim, K.; Bing, L. An Unsupervised Sentence Embedding Method by Mutual Information Maximization. In Proceedings of the Conference on Empirical Methods in Natural Language Processing—EMNLP 2020, Online, 16–20 November 2015. [Google Scholar] [CrossRef]
- Cheng, P.; Hao, W.; Yuan, S.; Si, S.; Carin, L. FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders. In Proceedings of the 9th International Conference on Learning Representations—ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Qu, Y.; Shen, D.; Shen, Y.; Sajeev, S.; Chen, W.; Han, J. CoDA: Contrast-enhanced and Diversity-promoting Data Augmentation for Natural Language Understanding. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 3980–3990. [Google Scholar] [CrossRef]
- Izacard, G.; Caron, M.; Hosseini, L.; Riedel, S.; Bojanowski, P.; Joulin, A.; Grave, E. Towards Unsupervised Dense Information Retrieval with Contrastive Learning. arXiv 2021, arXiv:2112.09118. [Google Scholar]
- Deng, Y.; Zhang, W.; Lam, W. Learning to Rank Question Answer Pairs with Bilateral Contrastive Data Augmentation. In Proceedings of the Seventh Workshop on Noisy User-Generated Text, W-NUT 2021, Online, 11 November 2021; Xu, W., Ritter, A., Baldwin, T., Rahimi, A., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 175–181. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 16 April 2023).
- Wang, J.; Hu, X.; Hou, W.; Chen, H.; Zheng, R.; Wang, Y.; Yang, L.; Huang, H.; Ye, W.; Geng, X.; et al. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. arXiv 2023, arXiv:2302.12095. [Google Scholar]
- Penha, G.; Câmara, A.; Hauff, C. Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators. In Proceedings of the Advances in Information Retrieval: 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, 10–14 April 2022; pp. 397–412. [Google Scholar] [CrossRef]
- Fan, A.; Bhosale, S.; Schwenk, H.; Ma, Z.; El-Kishky, A.; Goyal, S.; Baines, M.; Celebi, O.; Wenzek, G.; Chaudhary, V.; et al. Beyond English-Centric Multilingual Machine Translation. J. Mach. Learn. Res. 2021, 22, 107:1–107:48. [Google Scholar]
- Yang, Y.; Yih, W.; Meek, C. WikiQA: A Challenge Dataset for Open-Domain Question Answering. In Proceedings of the Conference on Empirical Methods in Natural Language Processing—EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; Màrquez, L., Callison-Burch, C., Su, J., Pighin, D., Marton, Y., Eds.; The Association for Computational Linguistics: Toronto, ON, Canada, 2015; pp. 2013–2018. [Google Scholar] [CrossRef]
- Hashemi, H.; Aliannejadi, M.; Zamani, H.; Croft, W.B. ANTIQUE: A Non-factoid Question Answering Benchmark. In Proceedings of the Advances in Information Retrieval—42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Jose, J.M., Yilmaz, E., Magalhães, J., Castells, P., Ferro, N., Silva, M.J., Martins, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12036, pp. 166–173. [Google Scholar] [CrossRef]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB: Massive Text Embedding Benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–4 May 2023; pp. 2014–2037. [Google Scholar]
- BAAI. Bge-Large-En. 2023. Available online: https://huggingface.co/BAAI/bge-large-en (accessed on 27 August 2023).
- BAAI. Bge-Base-En. 2023. Available online: https://huggingface.co/BAAI/bge-base-en (accessed on 27 August 2023).
- Su, H.; Shi, W.; Kasai, J.; Wang, Y.; Hu, Y.; Ostendorf, M.; Yih, W.t.; Smith, N.A.; Zettlemoyer, L.; Yu, T. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 1102–1121. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, X.; Zhang, Y.; Long, D.; Xie, P.; Zhang, M. Towards General Text Embeddings with Multi-stage Contrastive Learning. arXiv 2023, arXiv:2308.03281. [Google Scholar]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.t. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6769–6781. [Google Scholar] [CrossRef]
- Xiong, W.; Li, X.; Iyer, S.; Du, J.; Lewis, P.; Wang, W.Y.; Mehdad, Y.; Yih, S.; Riedel, S.; Kiela, D.; et al. Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Arlington, VA, USA, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder—Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Ji, S.; Yun, H.; Yanardag, P.; Matsushima, S.; Vishwanathan, S.V.N. WordRank: Learning Word Embeddings via Robust Ranking. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 658–668. [Google Scholar] [CrossRef]
- Otegi, A.; San Vicente, I.; Saralegi, X.; Peñas, A.; Lozano, B.; Agirre, E. Information retrieval and question answering: A case study on COVID-19 scientific literature. Knowl. Based Syst. 2022, 240, 108072. [Google Scholar] [CrossRef] [PubMed]
- Ulukus, S.; Avestimehr, S.; Gastpar, M.; Jafar, S.A.; Tandon, R.; Tian, C. Private Retrieval, Computing, and Learning: Recent Progress and Future Challenges. IEEE J. Sel. Areas Commun. 2022, 40, 729–748. [Google Scholar] [CrossRef]
- Wang, H.; Jia, Y.; Wang, H. Interactive Information Retrieval with Bandit Feedback. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 2658–2661. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv 2020, arXiv:1911.05722. [Google Scholar]
- MacAvaney, S. OpenNIR: A Complete Neural Ad-Hoc Ranking Pipeline. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; 2020; pp. 845–848. [Google Scholar] [CrossRef]
- Robertson, S.E.; Walker, S. Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 3–6 July 1994; pp. 232–241. [Google Scholar]
- Lavrenko, V.; Croft, W.B. Relevance Based Language Models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; Association for Computing Machinery: New York, NY, USA, 2001; pp. 120–127. [Google Scholar] [CrossRef]
- Guo, J.; Fan, Y.; Ai, Q.; Croft, W.B. A Deep Relevance Matching Model for Ad-Hoc Retrieval. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–18 October 2016; pp. 55–64. [Google Scholar] [CrossRef]
- Xiong, C.; Dai, Z.; Callan, J.; Liu, Z.; Power, R. End-to-End Neural Ad-hoc Ranking with Kernel Pooling. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar] [CrossRef]
- Macdonald, C.; Tonellotto, N. Declarative Experimentation in Information Retrieval Using PyTerrier. In Proceedings of the ACM SIGIR on International Conference on Theory of Information Retrieval, Virtual, 14–17 September 2020; pp. 161–168. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Original Query | Query Variation Generated by ChatGPT | Level |
|---|---|---|
| what are mormens? ANTIQUE: #2180086 | 1. Could you tell me about the Mormon religion? | Character |
| 2. What is the Mormon faith all about? | ||
| 3. I’m a bit confused about Mormons—can you explain? | ||
| 4. Can you enlighten me about the beliefs of Mormon? | ||
| 5. I’ve heard about Mormon, but I’m not entirely sure what they are—can you help me understand? | ||
| >what is masturbat? ANTIQUE: #1971899 | 1. What does the term masturbation refer to? | Word |
| 2. Can you define the act of masturbation? | ||
| 3. Could you provide an explanation of masturbation? | ||
| 4. What is the definition of masturbation? | ||
| 5. How would you describe masturbation? | ||
| what is Carbon 14 dating is a type of ? WikiQA: Q2325 | 1. What type of dating is Carbon-14 dating? | Sentence |
| 2. What is the classification of Carbon-14 dating? | ||
| 3. Categorically speaking, what is Carbon-14 dating? | ||
| 4. In what category does Carbon-14 dating belong? | ||
| 5. To what genre does Carbon-14 dating pertain? |
| Character-Level | Word-Level | Sentence-Level | LLM | |||||
|---|---|---|---|---|---|---|---|---|
| WikiQA | ANTIQUE | WikiQA | ANTIQUE | WikiQA | ANTIQUE | WikiQA | ANTIQUE | |
| bge-large-en [44] | 96.04% | 94.48% | 93.22% | 91.44% | 95.59% | 96.73% | 92.02% | 95.08% |
| bge-base-en [45] | 93.75% | 94.24% | 94.36% | 92.28% | 97.50% | 96.88% | 95.29% | 94.64% |
| instructor_xl [46] | 91.94% | 93.51% | 90.57% | 87.49% | 95.84% | 95.03% | 92.26% | 92.25% |
| instructor_large [46] | 96.19% | 96.82% | 95.75% | 94.17% | 98.04% | 97.58% | 96.81% | 96.93% |
| gtr-t5-xl [47] | 89.09% | 90.78% | 86.60% | 81.45% | 93.82% | 92.21% | 89.20% | 88.57% |
| gtr-t5-xxl [47] | 89.89% | 91.14% | 87.14% | 81.96% | 93.97% | 92.36% | 88.89% | 88.43% |
| Sentence Length | Jaccard Similarity | Levenshtein Distance | ||||
|---|---|---|---|---|---|---|
| WikiQA | ANTIQUE | WikiQA | ANTIQUE | WikiQA | ANTIQUE | |
| Original query | 36.89 | 47.59 | - | - | - | - |
| Character-level query variation | 36.44 | 44.76 | 71.80% | 72.68% | 1.85 | 4.42 |
| Word-level query variation | 21.00 | 23.45 | 43.45% | 34.05% | 18.31 | 26.21 |
| Sentence-level query variation | 36.27 | 43.12 | 56.71% | 63.54% | 9.07 | 11.97 |
| LLM query variation | 58.48 | 68.66 | 17.72% | 21.08% | 34.56 | 40.07 |
| Model | MAP | MRR@10 | MRR | nDCG@10 | P@10 |
|---|---|---|---|---|---|
| BM25 | 0.569 | 0.575 | 0.601 | 0.659 | 0.110 |
| RM3 | 0.575 | 0.586 | 0.587 | 0.672 | 0.113 |
| DRMM | 0.612 | 0.617 | 0.620 | 0.698 | 0.113 |
| KNRM | 0.645 | 0.657 | 0.659 | 0.723 | 0.112 |
| DR | 0.781 | 0.792 | 0.793 | 0.833 | 0.115 |
| Reranker | 0.830 | 0.843 | 0.848 | 0.873 | 0.117 |
| Our (DR) | 0.785 | 0.801 | 0.801 | 0.841 | 0.117 |
| Our (Reranker) | 0.845 | 0.862 | 0.862 | 0.888 | 0.119 |
| Model | MAP | MRR@10 | MRR | nDCG@10 | P@10 |
|---|---|---|---|---|---|
| BM25 | 0.192 | 0.506 | 0.509 | 0.510 | 0.238 |
| RM3 | 0.176 | 0.433 | 0.437 | 0.488 | 0.228 |
| DRMM | 0.187 | 0.515 | 0.530 | 0.404 | 0.234 |
| KNRM | 0.203 | 0.574 | 0.579 | 0.443 | 0.255 |
| DR | 0.438 | 0.677 | 0.679 | 0.578 | 0.317 |
| Reranker | 0.511 | 0.747 | 0.752 | 0.654 | 0.363 |
| Our (DR) | 0.438 | 0.677 | 0.681 | 0.558 | 0.310 |
| Our (Reranker) | 0.529 | 0.770 | 0.771 | 0.659 | 0.367 |
| Model Type | Method | MAP | MRR | nDCG@10 | P@10 |
|---|---|---|---|---|---|
| DR | Original | 0.781(4.1%/12.3%) | 0.793(4.1%/11.8%) | 0.833(2.9%/8.6%) | 0.115(0.0%/0.0%) |
| Typo-aware | 0.779(2.8%/4.6%) | 0.791(2.7%/4.1%) | 0.832(1.9%/3.0%) | 0.116(0.0%/0.4%) | |
| Dual contrastive | 0.789(3.9%/7.9%) | 0.802(3.9%/6.7%) | 0.843(2.8%/5.5%) | 0.117(0.3%/0.7%) | |
| Our | 0.785(3.6%/5.9%) | 0.801(3.7%/5.4%) | 0.841(2.7%/4.0%) | 0.117(0.1%/0.3%) | |
| Reranker | Original | 0.830(7.8%/12.2%) | 0.848(8.3%/12.3%) | 0.873(6.2%/9.7%) | 0.117(1.7%/3.6%) |
| Typo-aware | 0.819(4.9%/11.5%) | 0.832(4.9%/10.6%) | 0.866(3.7%/8.3%) | 0.117(0.4%/1.1%) | |
| Our | 0.845(3.7%/7.2%) | 0.862(3.6%/6.7%) | 0.888(2.7%/5.0%) | 0.119(0.1%/0.7%) |
| Model Type | Method | MAP | MRR | nDCG@10 | P@10 |
|---|---|---|---|---|---|
| DR | Original | 0.438(17.0%/24.1%) | 0.679(15.3%/23.6%) | 0.578(15.7%/22.3%) | 0.316(18.1%/24.7%) |
| Typo-aware | 0.427(12.4%/17.5%) | 0.671(11.0%/16.5%) | 0.565(11.4%/16.3%) | 0.312(13.3%/18.0%) | |
| Dual contrastive | 0.437(17.4%/24.1%) | 0.689(15.7%/22.7%) | 0.578(15.8%/21.5%) | 0.314(17.2%/22.9%) | |
| Our | 0.438(10.2%/12.7%) | 0.682(8.9%/12.1%) | 0.558(9.1%/11.8%) | 0.313(9.3%/13.1%) | |
| Reranker | Original | 0.511(13.0%/16.5%) | 0.752(10.8%/14.5%) | 0.654(13.7%/15.1%) | 0.363(12.1%/16.2%) |
| Typo-aware | 0.527(13.1%/16.6%) | 0.776(10.9%/13.0%) | 0.652(11.2%/14.2%) | 0.360(11.8%/14.7%) | |
| Our | 0.529(11.9%/15.2%) | 0.771(10.6%/12.9%) | 0.659(10.5%/13.7%) | 0.368(10.2%/13.2%) |
| Real Query and Its Relevant Document | Original (MAP/MRR) | Our (MAP/MRR) |
|---|---|---|
| Q: How can I keep my rabit indoors? #4473331 | 0.050/0.142 | 0.245/0.333 |
| D: just bring the cage indoors and keep it clean…Oh, and don’t confuse the cocoa puffs with the rabbit droppings!! | ||
| Q: why do my baked potatos never taste near as good as when I get them in a nice restaurant? #402514 | 0.295/1.000 | 0.612/1.000 |
| D: Due to the cooking time a lot of restaurants bake potatos twice. Wrap them in foil, with some course sea salt for the first bake. Allow them to cool, unwrap them and bake again. | ||
| Q: how do I go about getting copies of letters of commendation prsented to me from city of san diego? #100653 | 0.159/0.250 | 0.336/0.333 |
| D: Use a copy machine. Or scan the letter into your computer and print it out in color mode to pick up any logos on the original letterhead. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Z.; Fan, K.; Liu, R.; Li, D. Towards Robust Neural Rankers with Large Language Model: A Contrastive Training Approach. Appl. Sci. 2023, 13, 10148. https://doi.org/10.3390/app131810148
Pan Z, Fan K, Liu R, Li D. Towards Robust Neural Rankers with Large Language Model: A Contrastive Training Approach. Applied Sciences. 2023; 13(18):10148. https://doi.org/10.3390/app131810148
Chicago/Turabian StylePan, Ziyang, Kangjia Fan, Rongyu Liu, and Daifeng Li. 2023. "Towards Robust Neural Rankers with Large Language Model: A Contrastive Training Approach" Applied Sciences 13, no. 18: 10148. https://doi.org/10.3390/app131810148
APA StylePan, Z., Fan, K., Liu, R., & Li, D. (2023). Towards Robust Neural Rankers with Large Language Model: A Contrastive Training Approach. Applied Sciences, 13(18), 10148. https://doi.org/10.3390/app131810148