1. Introduction
With the progression of human evolution, there has been an inconsistent degradation of jawbones in comparison to teeth, resulting in relatively smaller bone sizes when compared to tooth sizes. As a consequence, there is often inadequate space in the mandible to accommodate all the teeth, leading to the common occurrence of impacted teeth [
1]. Among impacted teeth, mandibular third molars are the most frequently encountered [
2]. The incidence of impacted wisdom teeth is particularly high, with approximately 72% of individuals aged 20–30 in Sweden having at least one impacted third molar [
3]. The occurrence of impacted mandibular third molars can easily lead to pericoronitis, and in severe cases, it can even result in secondary infections such as maxillary space infection or osteomyelitis. These conditions are known to be directly or indirectly associated with various oral, jaw, and facial diseases, including caries, pericoronitis, cystic lesions, periodontal disease, tumors, or root resorption [
4,
5,
6,
7]. Consequently, the extraction of third molars has become one of the most frequently performed surgical procedures by oral and maxillofacial surgeons [
8].
The position of the impacted mandibular third molar presents unique challenges. It is situated in close proximity to important anatomical structures and is closely associated with adjacent teeth, making extraction surgery often difficult [
9]. Additionally, surgical procedures can easily lead to complications such as reactive pain and swelling after tooth extraction [
10]. Therefore, it is necessary to develop an appropriate and comprehensive surgical plan prior to the procedure. The impacted mandibular third molar can be categorized into different positions, including vertical, mesioangular, and horizontal positions, among others. Each position presents varying difficulties for tooth extraction. Consequently, preoperative evaluation of the position of the third molar plays an important role in determining the specific surgical plan [
11].
Usually, oral health professionals can determine the position of the impacted mandibular third molar by analyzing panoramic radiographs. However, the traditional way for oral health professionals to analyze panoramic radiographs increases their daily workload and reduces their diagnostic and treatment efficiency. What is more, the determination of the position of mandibular impacted third molars is also susceptible to subjective factors such as experience level and fatigue level, resulting in many uncertainties. Therefore, an automated, low-cost, accurate, and rapid model for the detection and classification of impacted third molars is urgently needed.
Artificial intelligence (AI) was founded by McCarthy et al. in the 1950s [
12], referring to a branch of computer science in which predictions are made using machine methods to mimic what humans may do in the same situation. Deep learning is a special form of machine learning based on artificial neural networks (ANNs) inspired by the human nervous system [
13]. It is a subfield of artificial intelligence that uses neural networks inspired by human brain structures to learn from a large amount of data. A deep learning algorithm can automatically recognize and extract the features of the original data (such as images, sounds, and texts) and use them for prediction or decision-making [
14].
With the continuous development of deep learning, it has been widely used in many fields of medical treatment. Deep learning shows excellent performance in many tasks, such as brain disease detection and classification, COVID-19 diagnosis, dental segmentation, and so on, and effectively shortens the treatment time of patients [
15,
16,
17]. In stomatology, deep learning is applied to orthodontics, cariology, endodontics, periodontology, implantology, oral and maxillofacial surgery, and other studies [
13]. Judging the impacted type of the third molar by panoramic radiographs is one of the most common tasks in stomatology. At present, there are few applications of deep learning in this task. Celik ME (2022) used YOLOv3 and Faster RCNN to detect and classify impacted third molars on a dataset of 440 panoramic radiographs [
18]. It was shown that YOLOv3 had excellent performance for the detection. It is worth mentioning that Celik used Winter’s classification approach, which is classified based on the angle between the long axes of the third and second molars. However, the rectangular box, when tagging the data set, includes only the third molars, which may cause the target detection model to fail to learn the association between the third molars and the second molars. In addition, he only considered the mesioangular position and horizontal position of the mandibular third molars. Therefore, in view of the problems existing in the previous research, such as small datasets, inconsistent classification and labeling methods, and older models, this study established a dataset containing 1645 panoramic radiographs, and the rectangular box included both the third molars and the second molars. And this paper used all six categories of Winter’s classification when tagging. At the same time, this paper combined a more novel target detection model with knowledge distillation to ensure the accuracy of detection and classification as well as the light weight of the model in order to obtain a high-precision and lightweight third molar impacted detection and classification model. Our model is designed to provide oral health professionals with an auxiliary diagnostic tool. It can help oral health professionals reduce their workload, reduce mistakes, and devote more energy to clinical treatment. At the same time, it can also be used in intern education.
The remainder of this paper is organized as follows.
Section 2 introduces, in detail, the dataset used in this study, YOLOv5 target detection model, knowledge distillation, experimental environment, and evaluation indicators of the model. In
Section 3, the performance of the YOLOv5s-x algorithm obtained by YOLOv5 combined with knowledge distillation is evaluated through experiments. The results of the discussion are given in
Section 4. Finally, the fifth part summarizes the work of this study.
2. Materials and Methods
2.1. Ethical Statement
This study was conducted with the approval of the Ethics Committee of School of Stomatology, Lanzhou University, under approval number LZUKQ-2020-031.
2.2. Dataset Acquisition and Labeling
2.2.1. Data Acquisition and Preprocessing
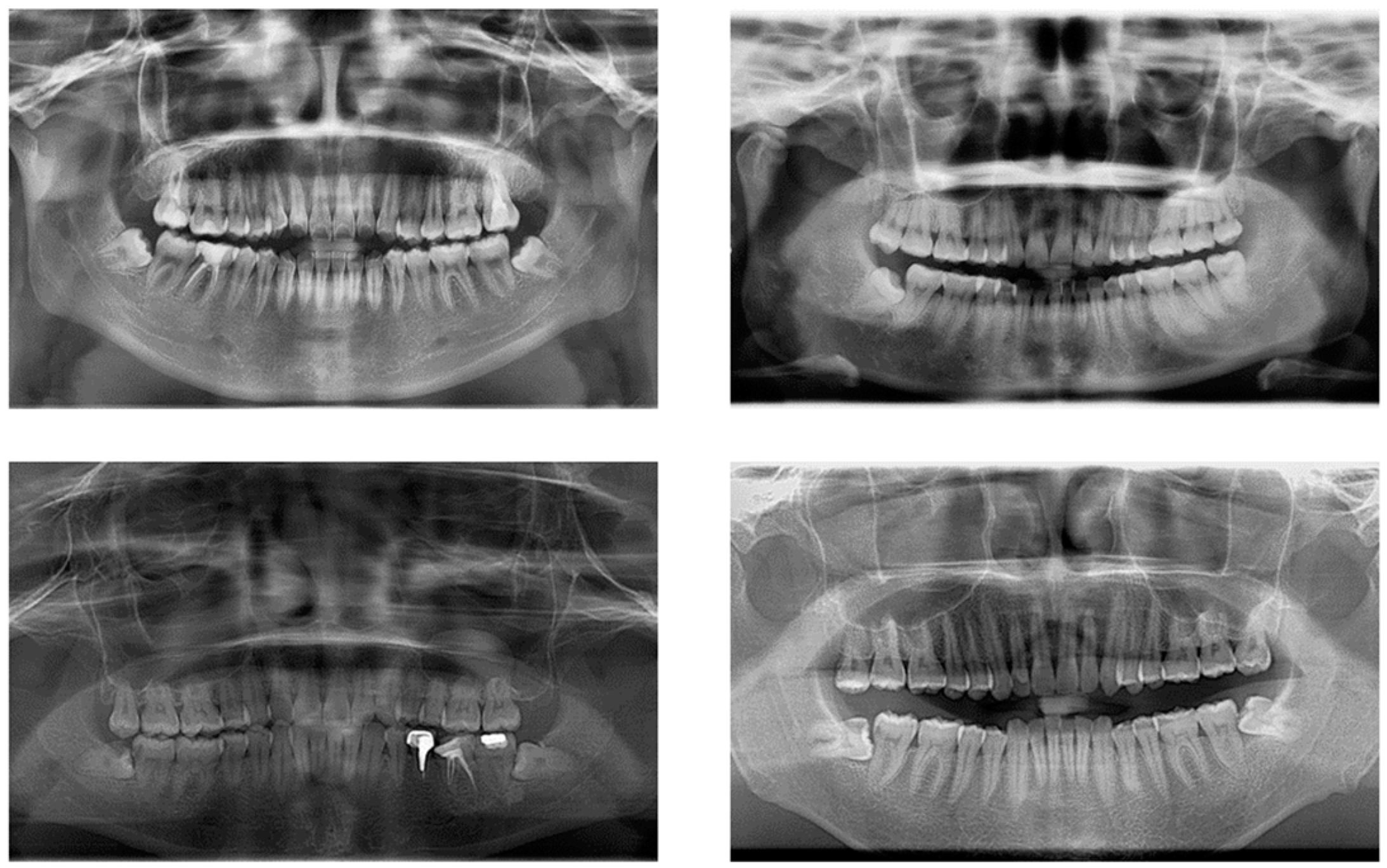
The impacted mandibular third molar dataset constructed for this study came from the School of Stomatology, Lanzhou University, with 2146 images; all the images were collected by Gendex Orthoralix 9200 DDE panoramic X-ray machine. After removing panoramic radiographs with artefacts, underdeveloped roots (which mean that the apical foramen has not been completely closed), and distorted positions, 1347 qualified images were finally obtained. The original images were in DCM format, and we used Python to convert them to JPG format; the size of the converted image is 2720 × 1444, and the converted images are shown in
Figure 1.
2.2.2. Definition of the Classification of Impacted Third Molars
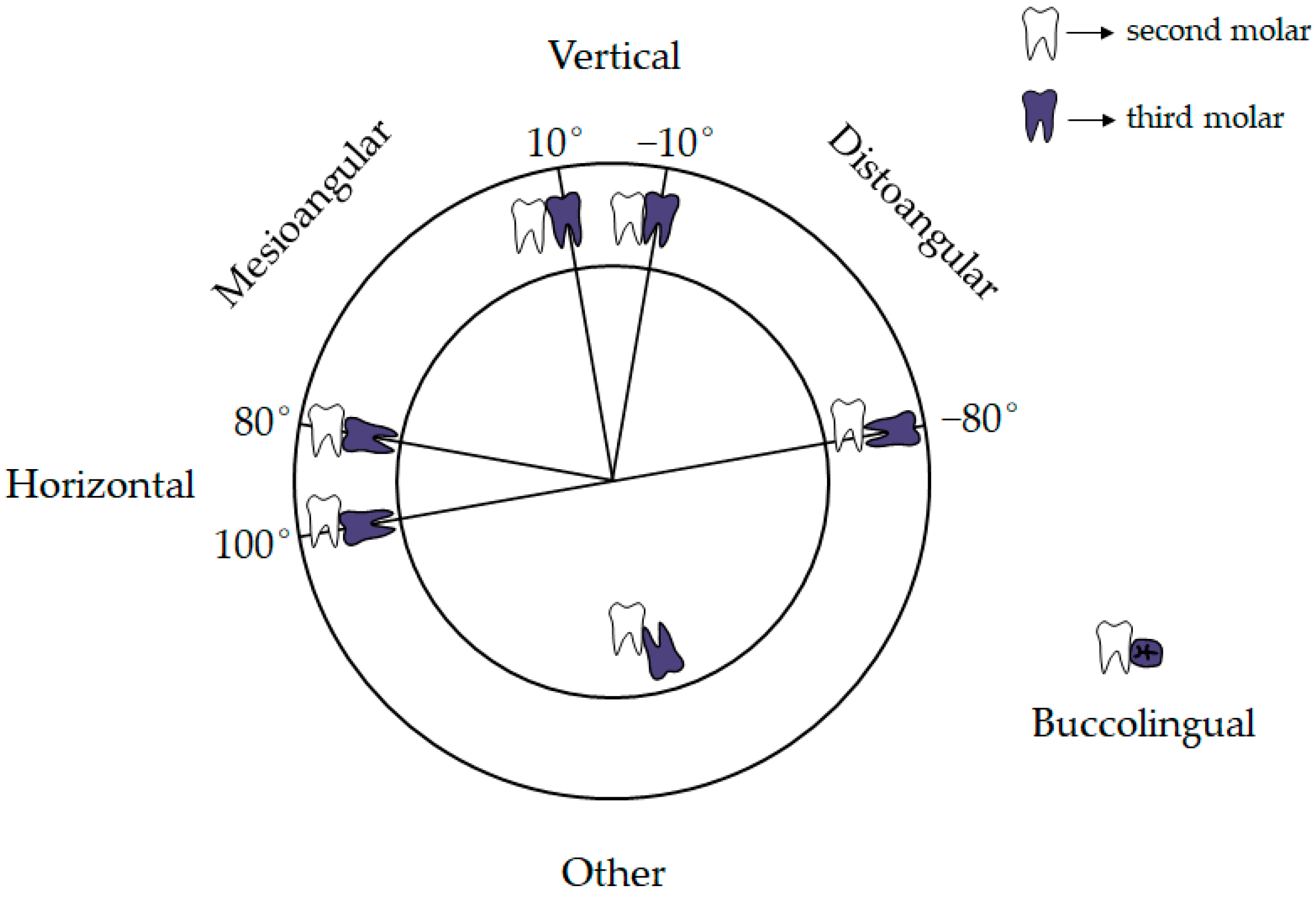
According to the relationship between the long axis of the impacted third molar and the long axis of the second molar, Winter divided the impacted position of the third molar into seven categories: vertical impaction, horizontal impaction, mesioangular impaction, distoangular impaction, buccoangular impaction, linguoangular impaction, and inverted impaction [
19]. Based on Winter’s classification, considering that the imaging features of buccoangular and linguoangular impaction are similar, this paper classified the types of impacted mandibular third molars into six categories according to the angle of the third molar to the second molar, namely Vertical position (10° to −10°), Mesioangular position (11° to 79°), Horizontal position (80° to 100°), Distoangular position (−11° to −79°), Other (101° to −80°), and Buccolingual position (which refers to any tooth oriented in a buccolingual direction with crown overlapping the roots), as shown in
Figure 2 and
Figure 3.
2.2.3. Data Labeling
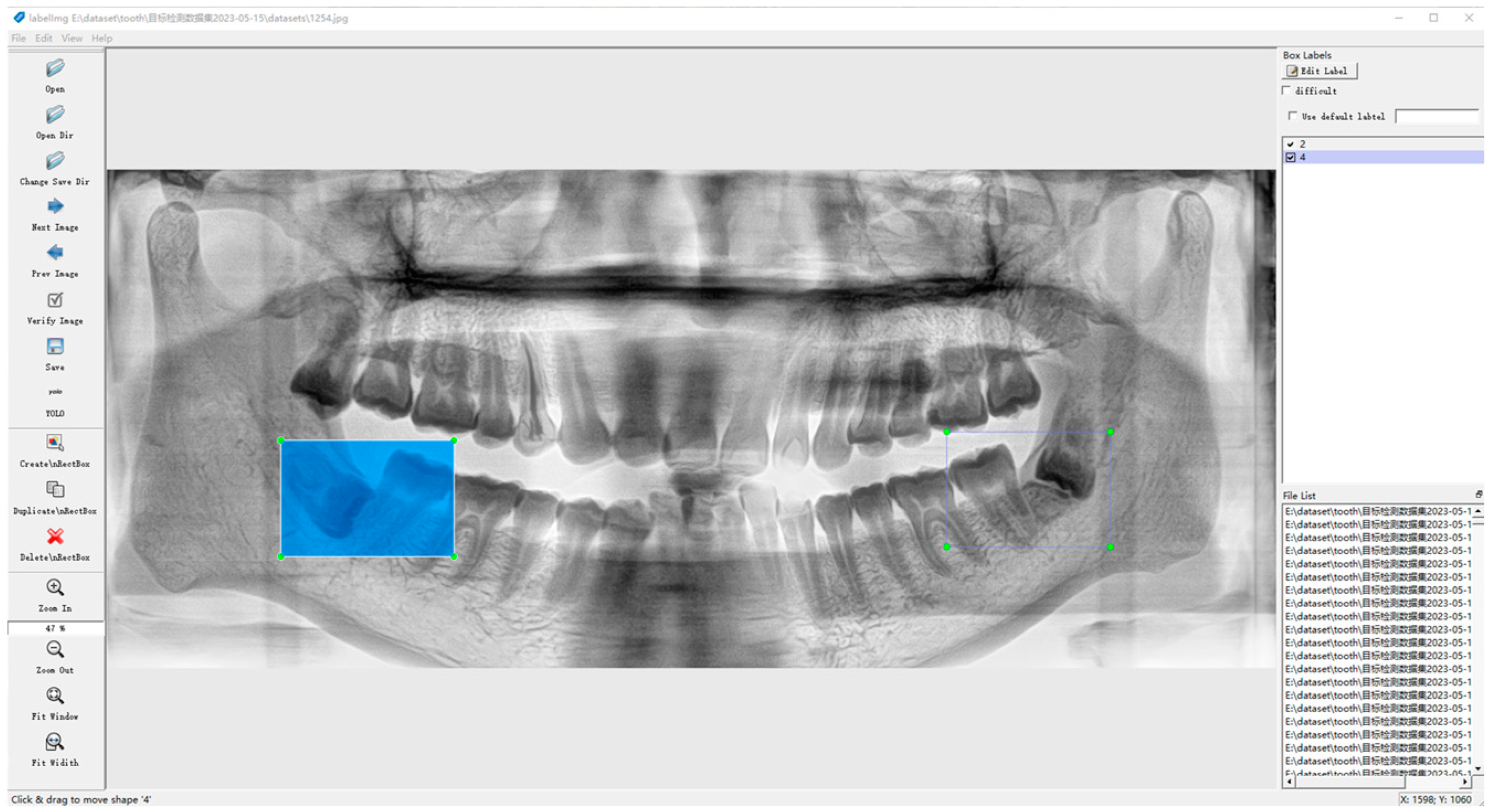
The dataset was labeled using the open-source script LabelImg from
https://github.com/HumanSignal/labelImg (accessed on 9 July 2023), a rectangular box containing both the crowns and roots of the second and third molars, as shown in
Figure 4.
2.3. Data Enhancement
Neural networks usually require a large amount of data for training, and in real-life scenarios, there are often insufficient training samples available due to acquisition costs and other issues. Due to the small number of patients with Buccolingual and Distoangular positions, there is a data imbalance in the dataset of this paper, so it is particularly important to use data enhancement methods to make the model have better generalization.
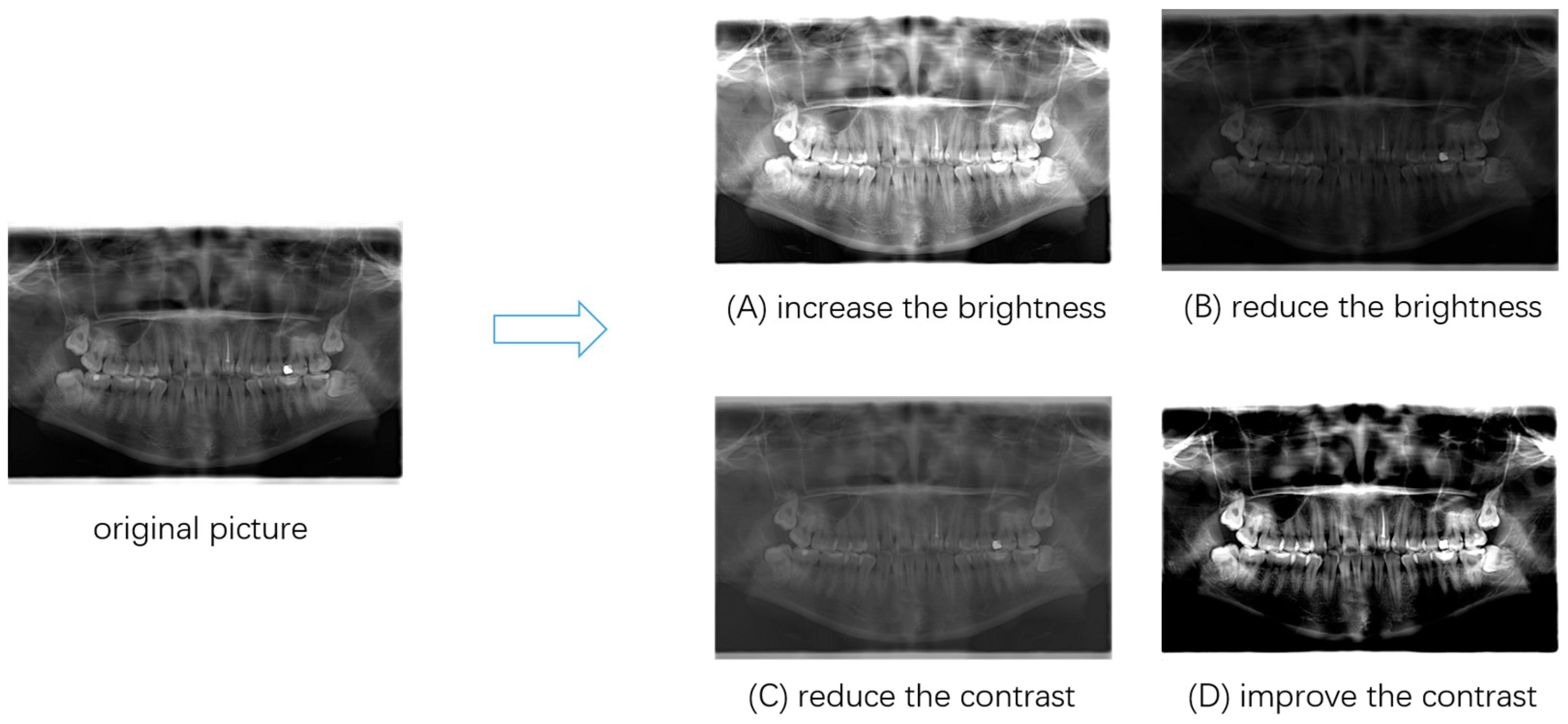
Considering the specificity of medical images, this paper adopted the data enhancement method of adjusting the contrast and brightness. The effect of data enhancement is shown in
Figure 5. After data enhancement, the final experimental dataset was formed, with a total of 1645 images. This study divided the dataset into a training set, a test set, and a validation set according to the ratio of 8:1:1.
2.4. YOLOv5
Target detection is a fundamental research area in deep learning techniques, consisting primarily of single-stage and two-stage methods. The YOLO (You Only Look Once) algorithm family is among the prominent examples of single-stage target detection algorithms and has significantly impacted the field of computer vision [
20,
21,
22,
23,
24,
25,
26]. Over time, the YOLO algorithm has undergone continuous improvement and evolution and has now evolved to YOLOv8.
YOLO transforms the target detection task into a single regression problem, returning the location and class label of the target directly, enabling end-to-end target detection without the need for an additional candidate region extraction step, compared to the two-stage target detection algorithms represented by the Faster RCNN, the algorithm of choice for many applications.
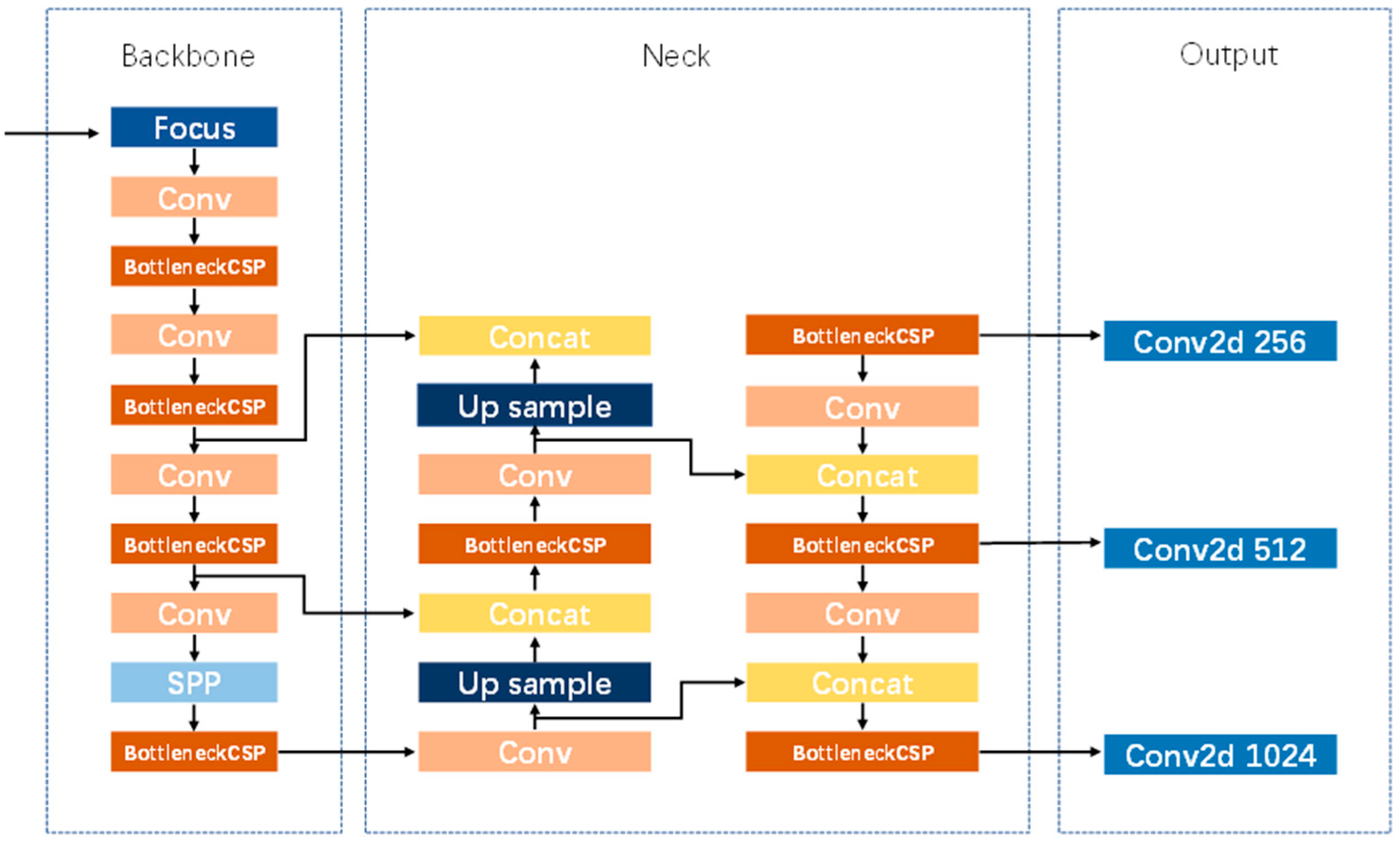
YOLOv5 was proposed in 2020 and is widely used for a variety of target detection tasks [
27]. YOLOv5 consists of four versions, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. YOLOv5 uses CSPNet as the backbone to extract feature information, the SPP module to extract multi-scale depth features, and then the feature pyramid constructed by PANet to fuse the different scales. The network architecture of YOLOv5 is the same for all four versions, and the size of the network structure is controlled by two parameters: depth_multiple and width_multiple. The network structure of YOLOv5 is shown in
Figure 6.
Among the four versions of YOLOv5, YOLOv5s has the smallest number of parameters and the largest model size, and YOLOv5x has the largest number of parameters and the largest model size. Along with this, the detection accuracy of YOLOv5x is better than that of YOLOv5s, and YOLOv5s is chosen as the benchmark model for this study due to the need for a lightweight model.
2.5. Knowledge Distillation
Larger models can often be used to achieve higher accuracy in the same dataset, and in many computer vision tasks, including target detection and semantic segmentation, larger models can often give better performance. However, larger models are often accompanied by high hardware resource requirements and the disadvantage of long model inference times, which pose many obstacles to practical applications. Therefore, improving the accuracy of models while keeping them lightweight has become a key research direction and is the basis for their application on the ground.
Knowledge distillation is one of the common methods to reduce model size [
28]. Unlike pruning and quantized model compression methods, knowledge distillation involves constructing a small, lightweight model and using a larger model with better performance to guide this small model so that the output of the small model is close to that of the large model, with a view to achieving better performance and accuracy. It aims to improve the accuracy of the small model without changing the computational efficiency.
The aim of this study is to ensure that the third molar detection and classification model is lightweight while improving the accuracy of the third molar detection classification model. Therefore, this paper chose YOLOv5x, which has the largest number of parameters and the highest detection accuracy among the four versions of YOLOv5, as the teacher network for knowledge distillation, and YOLOv5s, which has the smallest number of parameters, as the student network for knowledge distillation, so that the detection accuracy of YOLOv5s can be improved while ensuring the lightweight.
2.6. Experimental Environment
The experiment was conducted on Windows 10 based on the Pytorch framework; Python version: 3.6.13; Torch version 1.8.0; and the server configuration used was an Inter Xeon Gold 5218 CPU, an NVIDIA RTX 3080ti graphics card, and 128 G RAM.
2.7. Evaluation Indicators
Three commonly used evaluation metrics for target detection, mean Average Precision (mAP), parameters, and Giga Floating-point Operations Per Second (GFLOPs), were used as evaluation metrics for this study.
mAP is a widely accepted evaluation metric for target detection tasks. mAP takes values between 0 and 1, with higher mAP indicating higher model detection accuracy.
mAP@0.5 refers to the mAP value when IoU = 0.5, and many algorithms, including YOLO and Faster-RCNN, use mAP@0.5 as an evaluation index to evaluate model performance.
The number of parameters refers to the number of trainable parameters for the model. These parameters are trained by the model from data to optimize the performance and accuracy of the model. In general, the larger the number of parameters, the better the performance of the model, but it also means higher computational load and more memory consumption.
GFLOPs are a measure of the computational efficiency of a model. The lower the GFLOPs, the better the computational efficiency under the same training conditions.
3. Results
3.1. Comparison with YOLOv5s
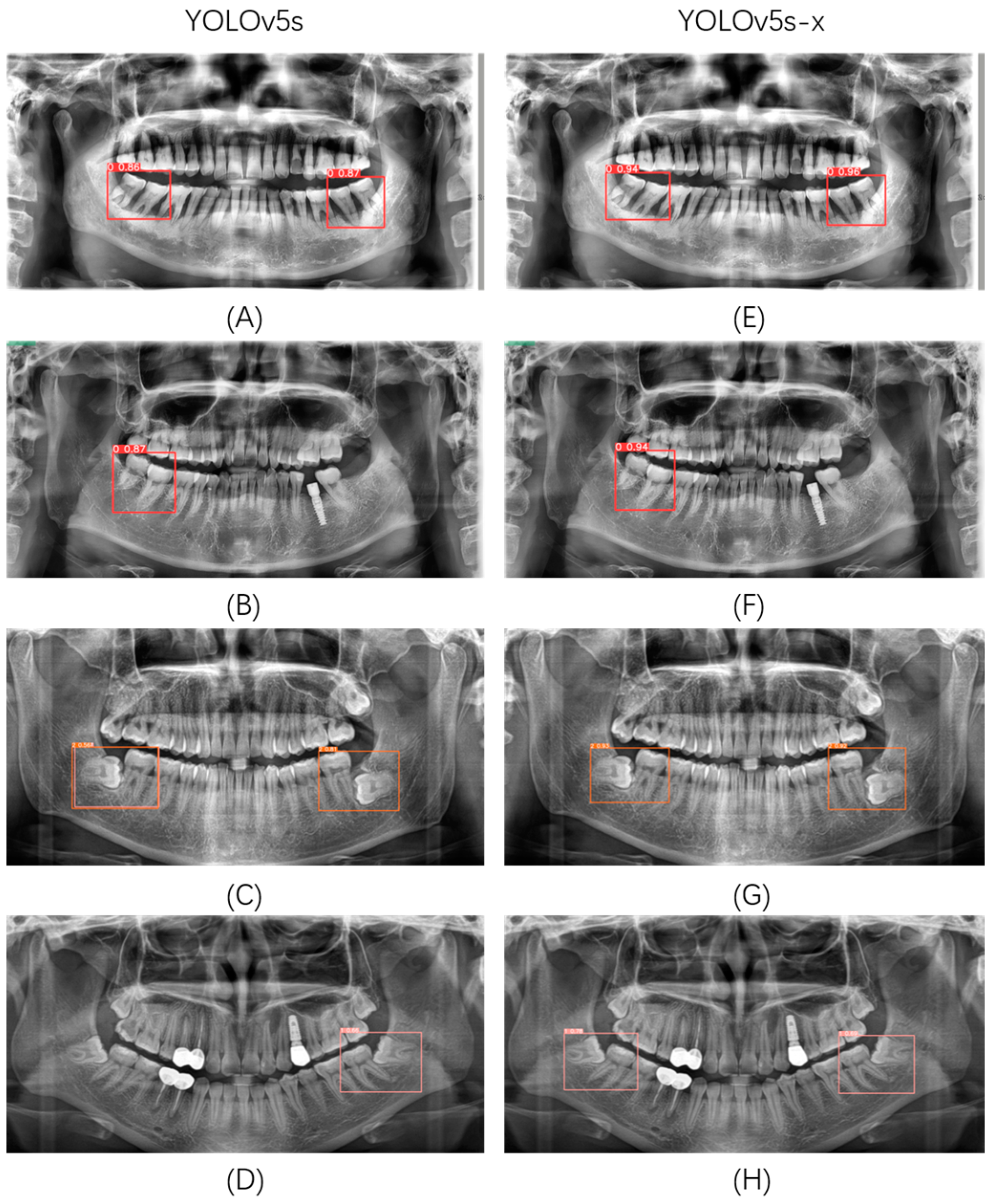
Compared with the original YOLOv5s, YOLOv5s with YOLOv5x as the teacher model (YOLOv5s-x) has a significant advantage in the impacted mandibular third molar detection and classification task. YOLOv5s-x has a 2.9% improvement in mAP, while the number of model parameters and GFLOPs is somewhat reduced. This paper randomly selected several images in the validation set for detection and classification in YOLOv5s and YOLOv5s-x, and the results are shown in
Figure 7. It can be seen that YOLOv5s-x alleviates, to a certain extent, the problems of missed, multiple, and wrong detections that exist in YOLOv5s and has a higher detection classification accuracy.
3.2. Comparison with Mainstream Networks
In order to verify the superiority of YOLOv5s-x in terms of accuracy, number of parameters, and model size, six different target detection models were trained and tested on the dataset, namely YOLOv5s, YOLOv5s-x, YOLOv7, YOLOv8n, YOLOv8s, DETR [
29]. The experimental results are shown in
Table 1, and the relationship between the mAP of each model and parameters, GFLOPs, and model size for each model are shown in
Figure 8. This study used mAP as an evaluation metric for the accuracy of detection and classification tasks and used the number of parameters, GFLOPs, and model size as evaluation metrics for model complexity.
According to
Table 1, it can be seen that among the six different target detection models, YOLOv5s-x has the highest mAP of 0.925, surpassing the newly introduced YOLOv8n and YOLOv8s. The mAP of YOLOv7 is closest to that of YOLOv5s-x, but the number of parameters of YOLOv7 is 5.3 times higher than that of YOLOv5s-x. YOLOv7 has 6.7 times the GFLOPs of YOLOv5s-x, and the model size of YOLOv7 is 5.2 times that of YOLOv5s-x. YOLOv8n has the smallest number of parameters and GFLOPs, with 0.43 times the number of parameters, 0.51 times the GFLOPs of YOLOv5s-x, and a model size of YOLOv5s-x by a factor of 0.45, but the mAP is 1.2% lower than YOLOv5s-x.
Although YOLOv5s-x is not optimal in terms of a number of parameters, GFLOPs, and model size, it has a much lower number of parameters, GFLOPs, and model size than most models, while YOLOv5s-x has the best mAP performance of all models. Therefore, YOLOv5s-x is easier to deploy and achieves better detection and classification results in practical applications. These results suggest that it is reasonable to use YOLOv5s as the baseline model and perform knowledge distillation and that the YOLOv5s-x model is more suitable for the detection and classification of the impacted mandibular third molar.
4. Discussion
The aim of this paper is to investigate the use of computer vision-related techniques for the detection and classification of impacted mandibular third molar and to improve the accuracy of the model while ensuring that the model is lightweight through the technique of knowledge distillation. In our study, we used YOLOv5x as the teacher model and YOLOv5s as the student model, resulting in a 2.9% improvement in the accuracy of the final model and some reduction in the number of model parameters and computational effort. This paper also compares our model with mainstream target detection networks, and the experimental results show that the proposed method performs best. Regarding the feasibility of the proposed method, this paper discusses the following.
Firstly, panoramic radiography is more suitable for the application of grass-roots hospitals because of its low-dose radiation and low price, so panoramic radiographs are chosen as the dataset of this study. Compared with CBCT, panoramic radiographs can only reflect the two-dimensional anatomical relationship between the root and the inferior alveolar canal. CBCT can finely display the relationship between the mandibular impacted third molar and the inferior alveolar canal, including buccal and lingual position and the presence of bone septum, so as to predict the possibility of injury to the inferior alveolar nerve during the operation. However, the price of CBCT is high, and most impaction cases can be correctly judged by panoramic radiographs. Therefore, this study chooses panoramic radiographs as the dataset, which has better universality. To sum up, the auxiliary diagnosis method should be selected according to the specific situation in the clinic. In the future, we will do further research on the application of deep learning in CBCT.
Secondly, our model is based on YOLOv5s, which has the advantage of being lightweight with a smaller model size and shorter training time, allowing it to perform excellent detection and classification tasks with limited resources. YOLOv5s is less demanding in terms of hardware requirements, which makes it more convenient for oral health professionals to deploy and apply, and has better generalizability.
Thirdly, this paper used knowledge distillation techniques on top of YOLOv5s to transfer the knowledge from YOLOv5x to the YOLOv5s model, which improves the mAP of YOLOv5s by 2.9% while ensuring the model is lightweight. Our experimental results show that the YOLOv5s-x model outperforms mainstream target monitoring networks such as DETR, YOLOv7, and YOLOv8. Although DETR, YOLOv7, and YOLOv8 are all newer detection models than YOLOv5, they also have some problems. DETR has the largest and largest model size and the lowest accuracy rate for detection classification. YOLOv7 has the smallest accuracy difference from YOLOv5 but is still inferior to our model in terms of a number of parameters and computational effort. This study also found that YOLOv8n had the smallest number of parameters and computational effort, but the mAP was 1.2% lower than YOLOv5s-x. YOLOv8s was slightly worse than YOLOv5s-x in all metrics. In summary, the YOLOv5s-x model is more suitable for the detection and classification of impacted mandibular third molars.
Finally, although our model has improved in performance, there are still some issues that need further improvement. Firstly, the mAP of our model is 0.925, which still has more room for improvement. Secondly, the performance of our model varies in different environments, and therefore further optimization is needed. Finally, there is still room for our model to further reduce the number of model parameters and computational effort, making the benefits of making a model lightweight more prominent.
In summary, our study demonstrates the feasibility of utilizing YOLOv5 for the detection and classification of impacted mandibular third molars, with the potential to enhance model performance through the application of knowledge distillation techniques. Our model surpasses mainstream target detection networks, yet there remains additional potential for improvement. We are confident that our study can contribute to the development of enhanced detection tools for dental professionals and patients, thereby facilitating improved oral health outcomes for a broader population.
5. Conclusions
In this study, a new method for detecting and classifying mandibular impacted third molars was proposed. YOLOv5, combined with knowledge distillation technology, can ensure the light weight of the model and effectively improve the accuracy of the model. Experimental results show that our model outperforms current mainstream networks. Not only does our method improve the accuracy of detection and classification, but it also has fewer model parameters and computational effort, suggesting that our model can provide a more accurate and reliable detection tool for oral health professionals and patients.
However, the study of this paper still has some limitations. Due to the influence of equipment and other factors, the panoramic radiographs of different people may have differences in shape, color, brightness, and so on. These differences may affect the performance of the model. At present, all the datasets in this paper are obtained from the School of Stomatology, Lanzhou University. Although this study has enhanced the data, there are still some deficiencies in the diversity of datasets. Improving the quality and diversity of datasets will be one of the following important works of this research. In the future, this study will not only improve the accuracy of the model but also combine with semantic segmentation to form a lightweight two-stage impacted third molar detection, classification, and contour extraction model.
Overall, the method proposed in this paper can be a viable method for classifying impacted mandibular third molar detection, ensuring that the model is lightweight while improving detection accuracy. Through this study, we hope to provide oral health professionals and patients with a more accurate, reliable, and efficient detection tool to help more people achieve a healthy mouth. We believe that with continued technological innovation, we can further refine and optimize our model to achieve an even more accurate and efficient classification of impacted mandibular third molar detection.
Author Contributions
Conceptualization, Y.L. and X.C.; methodology, Y.L.; software, Y.L., R.T. and Y.W.; validation, Y.L., X.C. and R.T.; formal analysis, Y.W.; investigation, X.C.; resources, B.Z.; data curation, Y.L., X.C. and B.Z.; writing—original draft preparation, Y.L. and X.C.; writing—review and editing, Y.W.; visualization, Y.W.; supervision, B.Z.; project administration, B.Z. and Y.L.; funding acquisition, B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Gansu Science and Technology Foundation Oral Disease Clinical Research Center under Grant 20JR10FA670 and the Clinical Research Foundation of Western Stomatology of Chinese Stomatological Association under Grant CSA-W2021-06.
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the School of Stomatology, Lanzhou University, under approval number LZUKQ-2020-031.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Due to privacy restrictions, we cannot make datasets public. Corresponding authors can be contacted if needed.
Acknowledgments
We thank Wu Tao, Director of Imaging Department, School of Stomatology, Lanzhou University for his assistance in this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Silvestri, A.R., Jr.; Singh, I. The unresolved problem of the third molar: Would people be better off without it? J. Am. Dent. Assoc. 2003, 134, 450–455. [Google Scholar] [CrossRef]
- Lima, C.J.; Silva, L.C.; Melo, M.R.; Santos, J.A.; Santos, T.S. Evaluation of the agreement by examiners according to classifications of third molars. Med. Oral Patol. Oral Cir. Buccal 2012, 17, e281–e286. [Google Scholar] [CrossRef]
- Dodson, T.B.; Susarla, S.M. Impacted wisdom teeth. BMJ Clin. Evid. 2014, 2014, 1302. [Google Scholar]
- Nazir, A.; Akhtar, M.U.; Ali, S. Assessment of different patterns of impacted mandibular third molars and their associated pathologies. J. Adv. Med. Dent. Sci. Res. 2014, 2, 14–22. [Google Scholar]
- Wahid, A.; Mian, F.I.; Bokhan, S.A.; Moazzam, A.; Kramat, A.; Khan, F. Prevalence of impacted mandibular and maxillary third molars: A radiographic study in patients reporting Madina teaching hospital, Faisal abad. JUMDC 2013, 4, 22–31. [Google Scholar]
- Sujon, M.K.; Alam, M.K.; Enezei, H.H.; Rahman, S.A. Third molar impaction and agenesis: A review. Int. J. Pharma Bio Sci. 2015, 6, 1215–1221. [Google Scholar]
- Olasoji, H.O.; Odusanya, S.A. Comparative study of third molar impaction in rural and urban areas of South-Western Nigeria. Odonto-Stomatol. Trop. 2000, 23, 26–30. [Google Scholar]
- Ahlqwist, M.; Grondahl, H.-G. Prevalence of impacted teeth and associated pathology in middle-aged and older Swedish women. Community Dent. Oral Epidemiol. 1991, 19, 116–119. [Google Scholar] [CrossRef]
- Ye, Z.X.; Yang, C.; Ge, J. Adjacent tooth trauma in complicated mandibular third molar surgery: Risk degree classification and digital surgical simulation. Sci. Rep. 2016, 6, 39126. [Google Scholar] [CrossRef]
- Candotto, V.; Oberti, L.; Gabrione, F.; Scarano, A.; Rossi, D.; Romano, M. Complication in third molar extractions. J. Biol. Regul. Homeost. Agents 2019, 33 (Suppl. 1), 169–172. [Google Scholar]
- Renton, T. Prevention of iatrogenic inferior alveolar nerve injuries in relation to dental procedures. S. Afr. Dent. J. 2010, 65, 342–351. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, J.; Minsky, M.L.; Shannon, C.E. A proposal for the Dartmouth summer research project on artificial intelligence, August 31, 1955. AI Mag. 2006, 27, 12–14. [Google Scholar]
- Mohammad-Rahimi, H.; Rokhshad, R.; Bencharit, S.; Krois, J.; Schwendicke, F. Deep learning: A primer for dentists and dental researchers. J. Dent. 2023, 130, 104430. [Google Scholar] [CrossRef] [PubMed]
- Vodanović, M.; Subašić, M.; Milošević, D.; Savić Pavičin, I. Artificial Intelligence in Medicine and Dentistry. Acta Stomatol. Croat. 2023, 57, 70–84. [Google Scholar] [CrossRef] [PubMed]
- Yousaf, F.; Iqbal, S.; Fatima, N.; Kousar, T.; Rahim, M.S.M. Multi-class disease detection using deep learning and human brain medical imaging. Biomed. Signal Process. Control 2023, 85, 104875. [Google Scholar] [CrossRef]
- Ucar, F.; Korkmaz, D. COVIDiagnosis-Net: Deep Bayes-SqueezeNet based diagnosis of the coronavirus disease 2019 (COVID-19) from X-ray images. Med. Hypotheses 2020, 140, 109761. [Google Scholar] [CrossRef]
- da Silva Rocha, É.; Endo, P.T. A Comparative Study of Deep Learning Models for Dental Segmentation in Panoramic Radiograph. Appl. Sci. 2022, 12, 3103. [Google Scholar] [CrossRef]
- Celik, M.E. Deep Learning Based Detection Tool for Impacted Mandibular Third Molar Teeth. Diagnostics 2022, 12, 942. [Google Scholar] [CrossRef]
- Winter, G. Impacted Mandibular Third Molars; American Medical Book Co.: St Louis, MO, USA, 1926. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Guan, Y.; Lei, Y.; Zhu, Y.; Li, T.; Xiang, Y.; Dong, P.; Jiang, R.; Luo, J.; Huang, A.; Fan, Y.; et al. Face recognition of a Lorisidae species based on computer vision. Glob. Ecol. Conserv. 2023, 45, e02511. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part I 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}