
Multi-Intent Natural Language Understanding Framework for Automotive Applications: A Heterogeneous Parallel Approach


Abstract
:1. Introduction
- (1)
- Addressing the challenges of multi-intent detection in the automotive domain, a Chinese automotive multi-intent dataset CADS was constructed. It contains 13,100 Chinese utterances, seven slots, and thirty intent types. The dataset is composed of multiple data sources, including automotive controls, navigation, and car services, covering diverse language styles and intent types;
- (2)
- An innovative multi-intent joint model specialized for the automotive domain is proposed. Its improvements mainly include three aspects. Firstly, it integrates the Chinese BERT language model and a Gaussian prior attention mechanism within the encoder stage, enhancing the accuracy and precision of semantic feature extraction. Secondly, addressing the tasks of multi-intent detection and slot filling, the model adopts a heterogeneous graph parallel interaction network, thereby further enhancing the exchange of information and interaction between tasks. Lastly, the successful resolution of the challenge of inadequate adaptability in the automotive domain’s multi-intent models is achieved by introducing the cross-entropy loss function;
- (3)
- Thorough experimental evaluations were conducted on the CADS dataset alongside two publicly available datasets. The extensive results illustrated that Auto-HPIF significantly enhances the accuracy of both multi-intent classification and slot-filling tasks. By leveraging pre-training methods, it can adapt to the Chinese language style and facilitate more efficient human–machine interactions in the automotive scenario.
2. Related Works
2.1. Technological Advancements in the Field of NLU
2.2. Multi-Intent Detection and Slot Filling
2.3. Joint Modeling via the Interactive Framework
2.4. Pre-Trained Language Models
3. Corpus Collection and Annotation
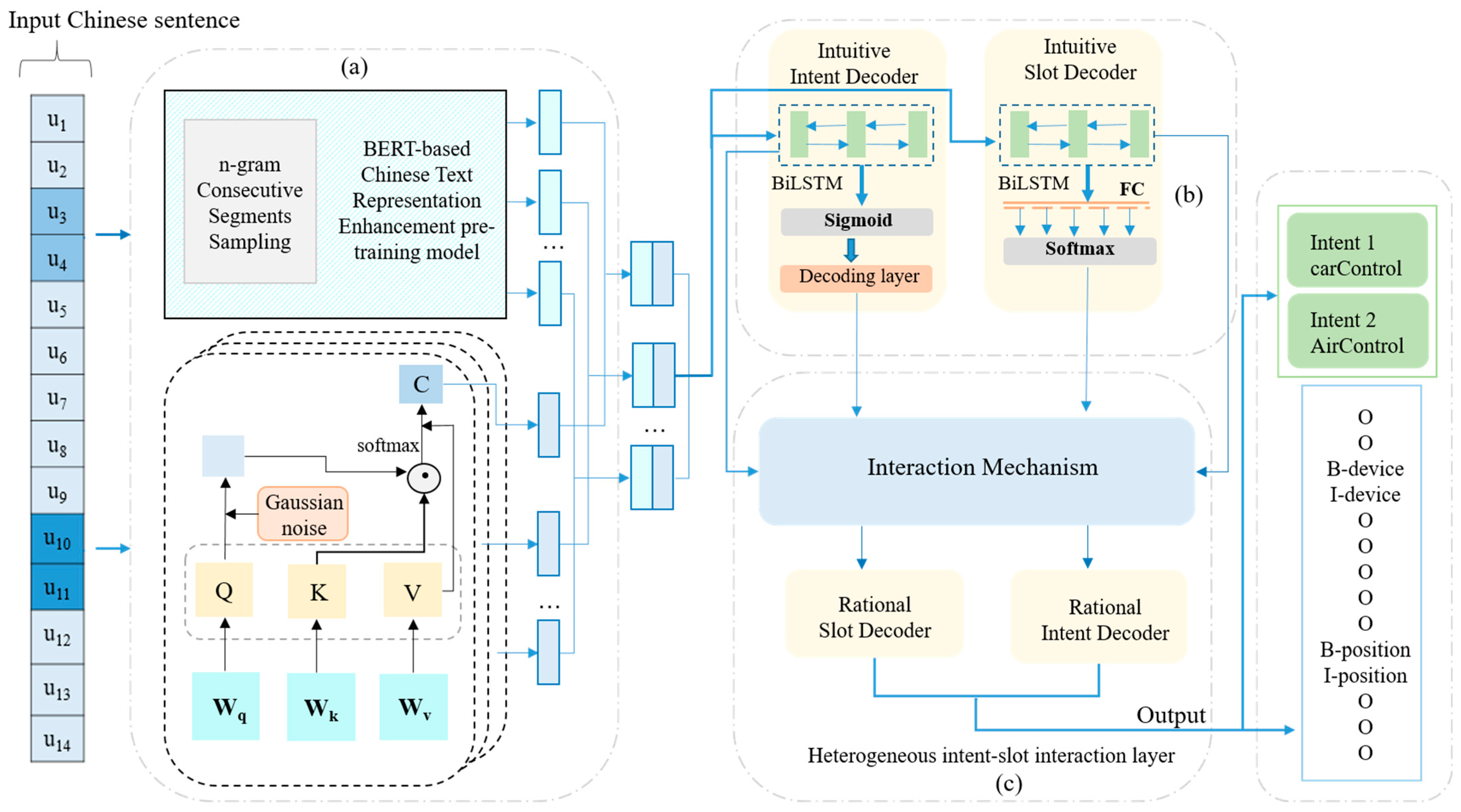
4. Auto-HPIF Modeling Approaches
4.1. Problem Definition
4.2. Common Encoder Module Based on BERT
4.3. Explicit Multi-Intent–Slot Task Module
- Intuitive Multiple-Intent Decoder. In the experiments, a bidirectional LSTM is used as an intuitive intent decoder. The bidirectional LSTM obtains a more comprehensive understanding of the input sequence by inputting the input sequence into two LSTMs in temporal and inverse order, respectively, and combining their outputs in time steps where the hidden vector of the decoder at each decoding time step t is calculated as:
- Intuitive Slot Decoder. Similar to the intuitive intent decoder approach, the intuitive slot decoder uses a bidirectional LSTM. Subsequently, a softmax classifier is employed to produce the slot label distribution for each word. As shown in Equation (9), is the distribution of slot labels generated for each word and is a specific feature of the slot-filling task.
4.4. The Implicit Heterogeneous Intent–Slot Interaction Module
- Heterogeneous Graph Layer. This module combines graph attention [27] and self-attention mechanisms to construct a heterogeneous network graph layer. The heterogeneous network layer is used to learn the relationship between each word in a sentence and calculate the importance of other words related to that word. At the same time, prior knowledge is used to guide the model to learn how to match different types of slot information with the input sentences. By integrating the feature representations of these words with higher importance and the degree of matching with the slot predefined, an embedding vector can be generated for that input sentence, and the corresponding intent category and slot values can be extracted from it. Specifically, the predicted intent labels and slot information output by module (b) and each word-level embedding and representation are considered as three classes of nodes, and three types of edges are defined:
- Adjacency relationship edges between word nodes, representing the contextual information between words in a sentence;
- The relationship edge between the intent label and the word node, indicating the connection between the intent label and each word in the input sentence;
- Relational edges between slot information and word nodes, representing the connection between slot information and each word in the input sentence.
| Algorithm 1. The diagram of heterogeneous graph-based semantic analysis. |
| Input: input_sentence, predicted_intent_label , predicted_slot_information |
| Output: predicted_intent_category , predicted_slot_values /* Create Word Nodes and Initialize Node Representations */ Outputs ← Output of the current sentence for word nodes in input_sentence do /* Compute Attention Weights */ word_attention_weights = compute_attention_weights(word_nodes) /* Compute Importance Scores for Other Words Related to Each Word */ word_importance_scores = compute_importance_scores(word_nodes) end /* Create Intent Label Node and Slot Information Nodes */ /* Create Edges and Initialize Edge Weights */ for edges in the graph do compute_attention_weights(edges) /* Compute Attention Weights for Edges */ aggregate_node_representations(word_nodes, edges) /* Generate Global Context-Aware Embedding Vector */ context_aware_embedding_vector = generate_embedding_vector(word_nodes) /* Extract Intent Category and Slot Values from Embedding Vector */ predicted_intent_category = extract_intent_category(context_aware_embedding_vector) predicted_slot_values = extract_slot_values(context_aware_embedding_vector) end outputs ← predicted_intent_category, predicted_slot_values |
- Rational Multiple-Intent Decoder. Through the heterogeneous graphical layer interaction mechanism, the updated intent node containing the slot information is obtained ; to consider both discourse representation and slot information, this paper continues to use bidirectional LSTM to implement slot information to guide the intent decoder, where it is the encoded hidden state after alignment. is the hidden state of the decoder at the previous sequential phase, is the slot label vector of the current sequential phase, and the LSTM hidden state is updated by computing the input vector of the current time step as follows:
- Rational Slot Decoder. To enhance the final slot filling task, the predicted multi-intent information is further interacted with the slot information by concatenating the slot node containing the characteristics corresponding to each predicted intent label and the aligned encoder hidden state e as input units to obtain a new sequence of slot labels using a method similar to that of the rational multiple-intent decoder.
4.5. Joint Training
5. Experimental Investigations
5.1. Set Up
5.2. Baseline
- Attention BiRNN [32] proposes a joint BiRNN model based on self-attentiveness, which predicts intentions by a weighted sum of hidden states;
- Slot-Gated [33] proposes a slot-gating mechanism that directly considers the relationship between SF and ID;
- Bi-Model [34] introduces a bidirectional model that uses BiRNN to decode the intended task and the slot task separately and shares the hidden state information at each time step between the two decoders;
- SF-ID [35] proposes an architecture that provides a direct connection between intent and slot so that they can facilitate each other;
- Stack-Propagation [36] is a stack-propagation architecture that guides SF tasks by combining decoding intent with encoding information;
- Joint Multiple ID-S [4] is a slot-gating model with attention that uses slot context vectors and intent context vectors as slot-gating;
- AGIF [5] is a GNN-based adaptive intent–slot graph interaction network that uses decoded intent and token sequences as nodes;
- GL-GIN [18] is a fast and accurate non-autoregressive model based on GAT that incorporates global–local graph interaction networks;
- SDJN [37] is a self-distillation architecture that passes intent and slot information to each other for cyclic optimization and implements self-distillation by using decoded slots as soft labels for pre-decoded slots;
- Co-Guiding Net [20] proposes a two-stage framework for joint multi-intent detection and slot-filling models.
5.3. Experiments on CADS
- Experimental Findings: The table observations highlight the following key points: (1) The accuracy of AGIF is 83.27% for overall performance, 90.31% for intent F1 score, and 94.58% for slot-filling F1 score; (2) The improvement in overall accuracy to 84.69% is attributed to the GL-GIN model’s explicit modeling of slot dependencies. This enhancement is achieved through the implementation of a local slot-aware graph interaction layer, facilitating effective interconnection among the hidden states of each slot; (3) Co-Guiding Net introduces a novel co-guiding network based on a two-stage framework. For the overall accuracy and slot-filling F1 score metrics, it showed improvements of approximately 1.07% and 0.42%, respectively, compared to GL-GIN. In terms of the F1 score, Co-Guiding Net demonstrated an increase of around 0.09% relative to GL-GIN.

{kind=link}
{kind=link}
{kind=link}
| Models | CADS | |||
|---|---|---|---|---|
| Overall (Acc) | Slot (F1) | Intent (Acc) | Intent (F1) | |
| AGIF [5] | 83.27 | 94.58 | 90.31 | 96.58 |
| GL-GIN [18] | 84.96 | 95.00 | 90.45 | 98.62 |
| Co-Guiding Net [20] | 85.87 | 95.40 | 90.53 | 98.60 |
| Ours (w/o Chinese-BERT) | 86.26 | 95.90 | 90.57 | 98.18 |
| Auto-HPIF (ours) | 87.94 | 96.80 | 90.61 | 98.90 |
- Analysis of Experimental Results: Compared to most baselines, Auto-HPIF achieved the best results in terms of both slot filling and overall performance. The following is an analysis of the experimental results: (1) In the intent detection task, the overall intent accuracy of Auto-HPIF with Chinese BERT removed outperforms the best baseline model, Co-guiding Net, on the CADS dataset, which indicates that the proposed joint multi-intent detection framework is better adapted to the intent detection task in the in-automotive domain; (2) Auto-HPIF improves the overall accuracy by 2.07% over the best baseline model Co-Guiding Net. This is because Auto-HPIF combines Chinese BERT and Gaussian prior attention mechanism in the shared encoder layer stage, which not only can better learn the semantic information of the input sequence but also, by introducing the Gaussian prior attention mechanism, the model can make full use of the historical information and thus can capture the contextual information of the input sequence more accurately when dealing with the joint multi-intent detection task; (3) The heterogeneous network interaction mechanism introduced by Auto-HPIF allows the slot information and intention information to interact, which also helps to obtain rich intention information and slot semantic representation for the joint multi-intent detection task.
5.4. Experimental on the Public Datasets
- Experimental Findings: The experimental results on the MixATIS dataset showed that Stack-Propagation had lower slot filling F1, intention detection accuracy, and overall accuracy compared to Auto-HPIF (w/o Chinese-BERT) by 2.0%, 3.8%, and 8.5%, respectively. However, some recently proposed models, such as GL-GIN introduced a global–local graph interaction network structure, which improved the overall accuracy to 43.5% and 75.4% on the MixATIS and MixSNIPS datasets, respectively. Another model called SDJN achieved cyclic optimization by exchanging intention and slot information, resulting in an overall accuracy improvement of 1.1% and 0.3% on the MixATIS and MixSNIPS datasets, respectively, relative to GL-GIN. Importantly, Auto-HPIF (w/o Chinese-BERT) achieved the highest intent accuracy of 78.4% and overall accuracy of 47.6% on the MixATIS dataset, surpassing the second-best model by 1.3% and 3.0%, respectively. Additionally, on the MixSNIPS dataset, Auto-HPIF (w/o Chinese-BERT) achieved an overall accuracy of 76.4%, outperforming the second-best model by 0.7%.
| Models | MixATIS | MixSNIPS | ||||
|---|---|---|---|---|---|---|
| Overall (Acc) | Slot (F1) | Intent (Acc) | Overall (Acc) | Slot (F1) | Intent (Acc) | |
| Attention BiRNN [30] | 39.1 | 86.4 | 74.6 | 59.5 | 89.4 | 95.4 |
| Slot-Gated [31] | 35.5 | 87.7 | 63.9 | 55.4 | 87.9 | 94.6 |
| Bi-Model [32] | 34.4 | 83.9 | 70.3 | 63.4 | 90.7 | 95.6 |
| SF-ID [33] | 34.9 | 87.4 | 66.2 | 59.9 | 90.6 | 95.0 |
| Stack-Propagation [34] | 40.1 | 87.8 | 72.1 | 72.9 | 94.2 | 96.0 |
| Joint Multiple ID-SF [4] | 36.1 | 84.6 | 73.4 | 62.9 | 90.6 | 95.1 |
| AGIF [5] | 40.8 | 86.7 | 74.4 | 74.2 | 94.2 | 95.1 |
| GL-GIN [16] | 43.5 | 88.3 | 76.3 | 75.4 | 94.9 | 95.7 |
| SDJN [35] | 44.6 | 88.2 | 77.1 | 75.7 | 94.4 | 96.5 |
| Auto-HPIF (w/o Chinese-BERT) | 47.6 | 88.4 | 78.4 | 76.4 | 95.1 | 96.0 |
- Analysis of Experimental Results: The experimental findings underscore the potential and applicability of the Auto-HPIF model in addressing complex multi-intent detection tasks. From an algorithmic design perspective, considering whether the proposed Auto-HPIF approach is susceptible to the issue of vanishing gradients is of paramount importance. This study observes that the Auto-HPIF model demonstrates robust performance across multiple indicators, indicating its effective training and alleviation of the gradient vanishing problem. This achievement aligns with the findings in reference, which introduces the oriented stochastic loss descent algorithm. This algorithm addresses the challenge of gradient vanishing, enabling deep networks to be trained without encountering the aforementioned issue.
5.5. Ablation Study
- Due to the lack of additional interaction mechanisms, there is insufficient information propagation in the experimental results, leading to poorer performance of the dialogue system. This is because the heterogeneous network interaction mechanism uses different types of nodes and edges in the graph to represent different information, as well as to interact and integrate them to solve tasks. Through the graph attention network (GAT), it achieves interactions between different types of nodes with non-shared weights, accurately capturing node features;
- The self-attention mechanism in the model with the heterogeneous network interaction allows each word to focus on other words in the context and integrate this information into its feature representation, which helps accurately capture features between word-level nodes.
5.6. Error Analysis
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rathore, R.S.; Hewage, C.; Kaiwartya, O.; Lloret, J. In-automotive communication cyber security: Challenges and solutions. Sensors 2022, 22, 6679. [Google Scholar] [CrossRef] [PubMed]
- Murali, P.K.; Kaboli, M.; Dahiya, R. Intelligent in-automotive interaction technologies. Adv. Intell. Syst. 2022, 4, 2100122. [Google Scholar] [CrossRef]
- Ma, J.; Zuo, Y.; Gong, Z. Design of functional application model in automotive infotainment system-taking automotive music application as an example. In Congress of the International Association of Societies of Design Research; Springer: Berlin/Heidelberg, Germany, 2021; pp. 3548–3557. [Google Scholar]
- Gangadharaiah, R.; Narayanaswamy, B. Joint multiple intent detection and slot labeling for goal-oriented dialog. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 564–569. [Google Scholar]
- Qin, L.; Xu, X.; Che, W.; Liu, T. AGIF: An adaptive graph-interactive framework for joint multiple intent detection and slot filling. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 1807–1816. [Google Scholar]
- Cai, F.; Zhou, W.; Mi, F.; Faltings, B. SLIM: Explicit slot-intent mapping with bert for joint multi-intent detection and slot filling. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7607–7611. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT (1) 2019, Minneapolis, MN, USA, 2–7 July 2019; pp. 4171–4186. [Google Scholar]
- Yang, C.; Feng, C. Multi-intention recognition model with combination of syntactic feature and convolution neural network. J. Comput. Appl. 2018, 38, 1839. (In Chinese) [Google Scholar]
- Zheng, Y.; Liu, Y.; Hansen, J.H.L. Intent detection and semantic parsing for navigation dialogue language processing. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Firdaus, M.; Golchha, H.; Ekbal, A.; Bhattacharyya, P. A deep multi-task model for dialogue act classification, intent detection and slot filling. Cogn. Comput. 2021, 13, 626–645. [Google Scholar] [CrossRef]
- Jeong, M.; Lee, G.G. Triangular-chain conditional random fields. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1287–1302. [Google Scholar] [CrossRef]
- Yao, K.; Zweig, G.; Hwang, M.Y.; Shi, Y.; Yu, D. Recurrent neural networks for language understanding. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 2524–2528. [Google Scholar]
- Simonnet, E.; Camelin, N.; Deléglise, P.; Estève, Y. Exploring the use of attention-based recurrent neural networks for spoken language understanding. In Proceedings of the Machine Learning for Spoken Language Understanding and Interaction NIPS 2015 Workshop (NLUNIPS 2015), Montreal, QC, Canada, 11 December 2015. [Google Scholar]
- Zhao, L.; Feng, Z. Improving slot filling in spoken language understanding with joint pointer and attention. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 426–431. [Google Scholar]
- Abro, W.A.; Qi, G.; Aamir, M.; Ali, Z. Joint intent detection and slot filling using weighted finite state transducer and BERT. Appl. Intell. 2022, 52, 17356–17370. [Google Scholar] [CrossRef]
- Heo, S.H.; Lee, W.K.; Lee, J.H. mcBERT: Momentum Contrastive Learning with BERT for Zero-Shot Slot Filling. In Proceedings of the INTERSPEECH, Incheon, Republic of Korea, 18–22 September 2022; pp. 1243–1247. [Google Scholar]
- Chen, Y.; Luo, Z. Pre-trained joint model for intent classification and slot filling with semantic feature fusion. Sensors 2023, 23, 2848. [Google Scholar] [CrossRef] [PubMed]
- Qin, L.; Wei, F.; Xie, T.; Xu, X.; Che, W.; Liu, T. GL-GIN: Fast and accurate non-autoregressive model for joint multiple intent detection and slot filling. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 178–188. [Google Scholar]
- Deng, F.; Chen, Y.; Chen, X.; Li, J. Multi-intent detection and slot filling joint model of improved GL-GIN. Comput. Syst. Appl. 2023, 32, 75–83. (In Chinese) [Google Scholar]
- Xing, B.; Tsang, I.W. Co-guiding Net: Achieving mutual guidances between multiple intent detection and slot filling via heterogeneous semantics-label graphs. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 159–169. [Google Scholar]
- Zhang, Q.; Wang, S.; Li, J. A Heterogeneous Interaction Graph Network for Multi-Intent Spoken Language Understanding. Neural Process. Lett. 2023, 1–19. [Google Scholar] [CrossRef]
- Hao, X.; Wang, L.; Zhu, H.; Guo, X. Joint agricultural intent detection and slot filling based on enhanced heterogeneous attention mechanism. Comput. Electron. Agric. 2023, 207, 107756. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://paperswithcode.com/paper/improving-language-understanding-by (accessed on 3 August 2023).
- Guo, M.; Zhang, Y.; Liu, T. Gaussian transformer: A lightweight approach for natural language inference. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6489–6496. [Google Scholar]
- Zhou, P.; Huang, Z.; Liu, F.; Zou, Y. PIN: A novel parallel interactive network for spoken language understanding. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2950–2957. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 48510–48550. [Google Scholar]
- Su, J.; Zhu, M.; Murtadha, A.; Pan, S.; Wen, B.; Liu, Y. Zlpr: A novel loss for multi-label classification. arXiv 2022, arXiv:2208.02955. [Google Scholar]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS spoken language systems pilot corpus. In Proceedings of the Speech and Natural Language: Proceedings of a Workshop Held, Hidden Valley, PA, USA, 24–27 June 1990. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Wu, D.; Ding, L.; Lu, F.; Xie, J. SlotRefine: A fast non-autoregressive model for joint intent detection and slot filling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1932–1937. [Google Scholar]
- Liu, B.; Lane, I. Attention-based recurrent neural network models for joint intent detection and slot filling. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 685–689. [Google Scholar]
- Goo, C.W.; Gao, G.; Hsu, Y.K.; Chen, Y.N. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 753–757. [Google Scholar]
- Wang, Y.; Shen, Y.; Jin, H. A bi-model based rnn semantic frame parsing model for intent detection and slot filling. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 309–314. [Google Scholar]
- Niu, P.; Chen, Z.; Song, M. A novel bi-directional interrelated model for joint intent detection and slot filling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, July 28–2 August 2019; pp. 5467–5471. [Google Scholar]
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A stack-propagation framework with token-level intent detection for spoken language understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2078–2087. [Google Scholar]
- Chen, L.; Zhou, P.; Zou, Y. Joint multiple intent detection and slot filling via self-distillation. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7612–7616. [Google Scholar]


| Domain | Number of Intents | Number of Utterances | Intent Types | Slot Types |
|---|---|---|---|---|
| Automotive | Single intent | 5000 | 17 | 7 |
| Double intent | 7450 | 9 | 7 | |
| Multiple intents | 650 | 4 | 7 | |
| Total | - | 13,100 | 30 | 7 |
| No. | Intent Label | Sample |
|---|---|---|
| 1 | adjust_ac_temperature_to_number | The air conditioning on the passenger side is set to 25 degrees |
| 2 | adjust_ac_windspeed_to_number | Set the air conditioning fan speed to 2.4 notches |
| 3 | close_ac | Turn off the air conditioning in the car |
| 4 | close_car_device | Could you please close the right rear window a bit? |
| 5 | collect_music | I want to listen to my collection of songs |
| 6 | lower_ac_temperate_little | Lower the air conditioning in all positions |
| 7 | map_control_query | How do I use the navigation system? |
| 8 | music_search_artist_song | Play ‘Big Fish’ by Zhou Shen |
| 9 | navigate_landmark_poi | Are there any ATMs nearby? |
| 10 | navigate_poi | I want to go to Shuncheng Service Center via an unblocked route |
| 11 | open_ac | I’m a bit cold, let me turn on the air conditioning for a while |
| 12 | open_ac_mode | I want to set it to energy-saving mode. |
| 13 | open_car_device | Help me open the trunk |
| 14 | play _collect_music | Play the music from my collection |
| 15 | open _collect_music | Could you please open the collection of songs |
| 16 | raise_ac_temperature_little | Increase the temperature of the front right air conditioning |
| 17 | view_trans | Show the map in 2D mode |
| No. | Multi-Intent Label | Sample |
|---|---|---|
| 1 | close_ac#close_car_device | Turn off the air conditioning in the car, and also close the left rear window |
| 2 | collect_music#lower_ac_temperature_little | This song is nice, then lower the temperature of the driver’s air conditioning a bit |
| 3 | map_control_query#music_search_artist_song | Set the navigation to the destination, and then play ‘Forget the World’ by Li Yugang |
| 4 | open_ac_mode#open_car_device | Switch to recirculation mode and enable the Daytime Running Lights function |
| 5 | collect_music#lower_ac_temperature_little#map_control_query | I want to listen to the online music in my collection. Lower the front air conditioning a bit more, and now start the navigation |
| 6 | open_collect_music#play_collect_music#raise_ac_temperature_little | Open the collection of songs, and then play from the collection. Increase the temperature of the right rear air conditioning a bit |
| Models | CADS | MixATIS | ||||
|---|---|---|---|---|---|---|
| Slot (F1) | Intent (Acc) | Overall (OA) | Slot (F1) | Intent (Acc) | Overall (OA) | |
| (w/o) Chinese BERT encoder | 95.90 | 90.57 | 86.26 | - | - | - |
| (w/o) Gaussian attention mechanism | 96.43 | 90.38 | 87.17 | 87.27 | 76.69 | 46.25 |
| (w/o) Multilabel_crossentropy | 96.37 | 90.53 | 87.02 | 87.49 | 76.84 | 46.89 |
| (w/o) Interaction mechanism | 94.59 | 89.92 | 84.96 | 78.10 | 76.36 | 41.07 |
| Auto-HPIF (ours) | 96.80 | 90.61 | 87.94 | 88.41 * | 77.60 * | 47.63 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhang, L.; Fang, L.; Cao, P. Multi-Intent Natural Language Understanding Framework for Automotive Applications: A Heterogeneous Parallel Approach. Appl. Sci. 2023, 13, 9919. https://doi.org/10.3390/app13179919
Li X, Zhang L, Fang L, Cao P. Multi-Intent Natural Language Understanding Framework for Automotive Applications: A Heterogeneous Parallel Approach. Applied Sciences. 2023; 13(17):9919. https://doi.org/10.3390/app13179919
Chicago/Turabian StyleLi, Xinlu, Lexuan Zhang, Liangkuan Fang, and Pei Cao. 2023. "Multi-Intent Natural Language Understanding Framework for Automotive Applications: A Heterogeneous Parallel Approach" Applied Sciences 13, no. 17: 9919. https://doi.org/10.3390/app13179919
APA StyleLi, X., Zhang, L., Fang, L., & Cao, P. (2023). Multi-Intent Natural Language Understanding Framework for Automotive Applications: A Heterogeneous Parallel Approach. Applied Sciences, 13(17), 9919. https://doi.org/10.3390/app13179919